![[技術解説] Apple Silicon ネイティブの文字起こしツール MacScribe を設計、MLX Whisper の 5 モデルを M4 で実測してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-5285ca250d0503bc4e8ca44630ac36f2/a5da264e8e8b2da687153a6b18c0c8db/eyecatch_openai?w=3840&fm=webp)
[技術解説] Apple Silicon ネイティブの文字起こしツール MacScribe を設計、MLX Whisper の 5 モデルを M4 で実測してみた
クラウド事業本部の石川です。Apple Silicon の Neural Engine をフル活用するローカル文字起こしサンプルアプリケーション MacScribe を作成しました。MLX Whisper をベースに、CLI と Streamlit Web UI の構成で 5 種類のモデルサイズに対応しています。
本記事では、モデル選定の設計判断、Apple M4 での実測ベンチマークまでをまとめてご紹介します。クラウドへ音声を送らずに高速・高精度な文字起こしを実現したい方の参考になれば幸いです。
主な機能
主な変更点ではなく、初回公開のため機能一覧として整理します。
- 2 つのインターフェース — 同一のコア (
src/macscribe/core/) を 2 つのフロントエンドが共有しています。macscribe: 動画・音声ファイルのバッチ文字起こし CLImacscribe-web: Streamlit ベースの Web UI
- 複数の出力フォーマット —
txt/srt/vtt/jsonの 4 形式をサポートし、--formatを複数回指定すれば一度に複数フォーマットへ出力できます。 - VAD による発話区間検出 —
onnxruntime経由で Silero VAD を呼び出し、無音区間をスキップしながらストリーミング処理します。軽量な RMS しきい値モードへのフォールバックも実装済みです。 - モデルサイズの選択 —
tiny/base/small/medium/largeの 5 段階。デフォルトはmediumです。すべてmlx-communityの 8 ビット量子化版を採用し、サイズと精度のバランスを取っています。 - 多言語 UI — Web UI のサイドバーで 英語 / 日本語 / 韓国語 / 中国語 / インドネシア語 / ヒンディー語 の 6 言語を切り替え可能です。READMEも同じ 6 言語で用意しています。
動作環境
- macOS (Apple Silicon: M1 / M2 / M3 / M4)
- Python 3.11 以上
uv(依存解決とランチャースクリプトで使用)ffmpeg(システム CLI としてPATHに必要)
料金への影響
Hugging Face からのモデルダウンロード以外、ランタイムで外部サービスを呼び出さないため、利用料金は発生しません。Whisper の推論は端末のリソースを使うのみです。
インストールと使い方
リポジトリ直下にある 3 つのランチャースクリプトは、いずれも uv run を介して該当のエントリーポイントを呼び出すだけのシンプルなラッパーです。
コマンドラインで文字起こししたい場合は以下の要領で実行します。
# バッチ CLI
./macscribe input.mp4
./macscribe input.mp4 --model medium --language ja
./macscribe input.mp4 --format txt --format srt --format vtt
./macscribe --list-models
./macscribe --list-languages
おすすめなのは、Web UIです。
# Web UI (Streamlit)
./macscribe-web
Web UIの実行例
./macscribe-webを実行すると、を初回に実行すると .venv が作られ、mlx-whisper・streamlit・onnxruntime・huggingface-hub などすべての実行時依存が一括で導入されます。
macscribe % ./macscribe-web
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.1.148:8501
For better performance, install the Watchdog module:
$ xcode-select --install
$ pip install watchdog
初回起動後は、お好みの言語に変更してください。
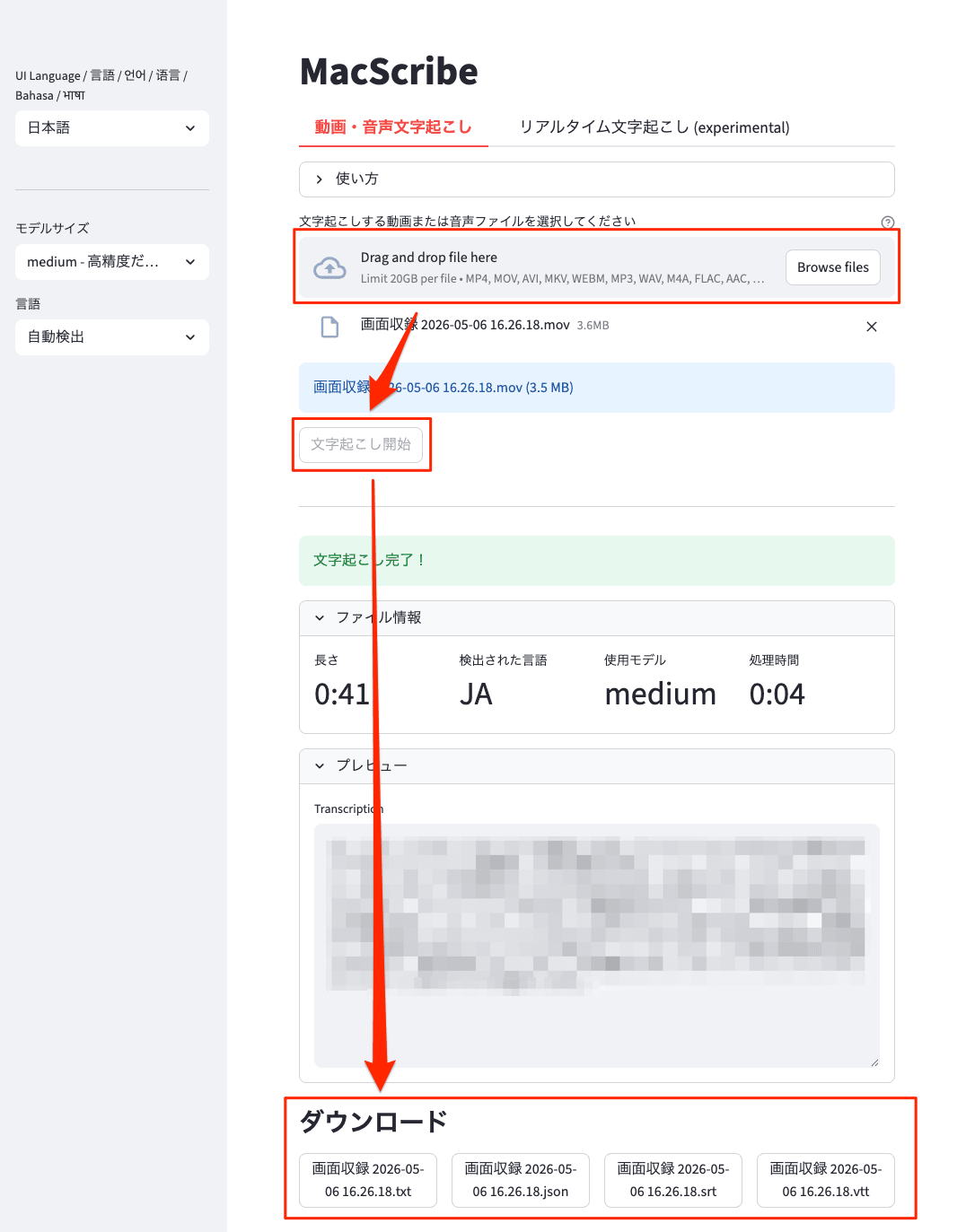
文字起こしする動画または音声ファイルをドラッグ&ドロップすると、音声データを取り出しが始まります。[文字起こし開始] ボタンを押すと文字起こしが完了すると、文字起こしファイルがダウンロードできる状態になります。
内部構成
ディレクトリ構成はシンプルです。
macscribe/
├── macscribe # バッチ CLI ランチャー
├── macscribe-realtime # リアルタイム CLI ランチャー
├── macscribe-web # Streamlit ランチャー
├── pyproject.toml
├── src/
│ └── macscribe/
│ ├── cli.py # バッチ CLI のエントリポイント
│ ├── realtime_cli.py # リアルタイム CLI のエントリポイント
│ ├── app.py # Streamlit アプリ本体
│ ├── config.py # 設定 / 多言語翻訳辞書
│ ├── core/ # transcriber / audio / VAD / streaming / models
│ └── formatters/ # txt / srt / vtt / json
└── tests/
src/macscribe/core/transcriber.py が文字起こしの中核で、mlx-whisper の呼び出し・モデル管理・スレッドロックを担います。MLX は Metal コマンドキューが並列コミットでクラッシュする挙動があるため、プロセス内で threading.Lock により直列化しています。
なぜ MLX Whisper を選んだのか
OpenAIのWhisper Large V3モデル、Whisper Large V3 Turboなど、継続的に文字起こしアプリを作成していました。
OpenAI Whisper には派生実装が複数存在しますが、Apple Silicon 上で素直に高速化を享受するには mlx-whisper が現状ベストだと判断しました。
| 観点 | OpenAI Whisper(PyTorch) | MLX Whisper | whisper.cpp |
|---|---|---|---|
| Apple Silicon 最適化 | △(MPS 経由) | ◎(ネイティブ) | ○(CPU 中心) |
| Neural Engine 活用 | × | ○ | × |
| Unified Memory 活用 | × | ○ | × |
| 量子化標準サポート | × | ○(8bit / 4bit) | ○(GGML) |
| Python API 親和性 | ◎ | ◎ | △ |
特に Unified Memory Architecture (UMA) と Metal バックエンド によって、CPU と GPU 間のメモリコピーを排除できるのが MLX の強みです。実測でも PyTorch + MPS 構成より明確に高速でした。
モデル選定の設計判断
mlx-community 配布の 8bit 量子化版に統一
採用するリポジトリは、mlx-community 名前空間で配布されている 8bit 量子化版に揃えました。
| モデル | リポジトリ | 量子化 | パラメータ | 実ディスクサイズ |
|---|---|---|---|---|
tiny |
mlx-community/whisper-tiny-mlx-8bit |
8bit | 39M | 56 MB |
base |
mlx-community/whisper-base-mlx-8bit |
8bit | 74M | 98 MB |
small |
mlx-community/whisper-small-mlx-8bit |
8bit | 244M | 282 MB |
medium(デフォルト) |
mlx-community/whisper-medium-mlx-8bit |
8bit | 769M | 825 MB |
large |
mlx-community/whisper-large-v3-mlx-8bit |
8bit | 1550M | 1628 MB |
ここで重要な技術的制約がひとつあります。mlx-whisper 0.4.x の load_model は weights.npz または weights.safetensors という固定ファイル名しか認識しない という挙動があり、新しい命名規則の model.safetensors だけを配布しているリポジトリは [load_npz] Input must be a zip file エラーで読み込めません。
そのため、量子化のバリエーションが豊富にあっても全てが利用可能というわけではなく、weights.npz を確実に同梱しているリポジトリ に絞って採用しました。
large は turbo ではなく v3 フル版を採用
実は mlx-community/whisper-large-v3-turbo(pruning + finetuning で約 5 倍高速化された変種)も実装上は読み込み可能です。しかし、調査の結果以下の劣化が公式に明示されていました。
"Across languages, the
turbomodel performs similarly tolarge-v2, though it shows larger degradation on some languages like Thai and Cantonese."
(OpenAI Whisper Discussion #2363)
具体的なベンチマークでは、タイ語が WER 5.8 → 20.8、広東語が 10.8 → 46.1 と 3〜4 倍の劣化 を示します。多言語対応を謳う以上、フル多言語版の whisper-large-v3 を選ぶほうが筋が良いと判断しました。
デフォルトモデルは medium
精度と速度のバランスを取り、デフォルトを medium に設定しています。uv run macscribe input.mp4 のようにモデル指定を省略すると medium が走ります。
Apple M4 での実測ベンチマーク
実際の処理性能を把握するため、38 分 54 秒(433 MB)の MOV ファイル を入力に、5 モデルすべての処理時間を計測しました。計測対象は mlx_whisper.transcribe() の呼び出し時間のみで、モデルダウンロードや音声抽出は除外しています。
| モデル | 処理時間 | 1 時間動画相当 | リアルタイム倍率 | 出力文字数 |
|---|---|---|---|---|
| tiny | 59.80 秒 | 1.54 分 | 39.04x | 11,327 |
| base | 54.64 秒 | 1.40 分 | 42.73x | 10,961 |
| small | 75.28 秒 | 1.93 分 | 31.01x | 10,539 |
| medium | 215.73 秒 | 5.55 分 | 10.82x | 11,153 |
| large | 678.58 秒 | 17.44 分 | 3.44x | 11,397 |
実機環境:Apple M4 / 32 GB unified memory / macOS 26.4.1 / mlx-whisper 0.4.3
考察
1. base が tiny より速い
直感に反して base(74M)が tiny(39M)よりわずかに速い結果となりました。これはデコーダーが広いほどハルシネーションや繰り返しループが減り、結果的にデコードステップ数が短くなるためです。文字数を比較すると tiny は 11,327 文字、base は 10,961 文字となっており、tiny 側に重複セグメントが含まれていた可能性があります。
2. large(v3 フル)でも 3.44x realtime
フル多言語版の large-v3(1550M パラメータ・8bit 量子化)でも、38 分の音声を 11.3 分で処理できました。Apple M4 では実用範囲です。インタラクティブな確認用途にも十分使えます。
3. README の見積もりは保守的
実測値は、M1 / M2 想定の従来見積もりより約 2 倍速い結果でした。世代が進むほど MLX の恩恵が大きくなる印象です。
最後に
MacScribe は MLX Whisper を中核に、Apple Silicon の性能を素直に引き出すローカル文字起こしツールです。要点を整理すると以下のとおりです。
- MLX Whisper + 8bit 量子化 で精度と効率のバランスを取る設計
largeは v3 フル版を採用 し、多言語精度を最優先(turbo は意図的に不採用)- Apple M4 では
largeでも 3.44x realtime、mediumで 10x realtime と実用範囲 - CLI と Streamlit Web UI のデュアルインターフェースで用途に応じて使い分け可能
クラウド API に音声を投げず、ローカルで完結したい場面では有力な選択肢になります。社内議事録や顧客との打ち合わせなど、機密性が問われるコンテンツの文字起こしを検討している方は、ぜひ手元で試してみてはいかがでしょうか。











