
Amazon S3 Tables と Iceberg マテリアライズドビューの権限を「単一IAMポリシー」で管理できる Streamlined Permissions を試してみた
クラウド事業本部の石川です。昨年のre:Invent 2025でApache Iceberg ベースのマテリアライズドビューをサポートしました。2026 年 3 月に、AWS Glue Data Catalog が Amazon S3 Tables と Iceberg マテリアライズドビュー向けに IAM ベースの認可(Streamlined Permissions) をサポートしました。今日はまとめて検証します。
これまで「S3 Tables」「Glue カタログ」「クエリエンジン(Athena/EMR/Redshift)」のそれぞれにバラバラに権限を定義する必要がありましたが、この機能により 1 つの IAM ポリシーでストレージ・カタログ・コンピュート層を横断した権限定義 ができるようになります。
IcebergのIAM ベースの認可(Streamlined Permissions)
これまで S3 Tables 上の Iceberg テーブルを複数の分析サービスから扱うには、以下のような複数レイヤーの権限定義が必要でした。
- S3 Tables 側:
s3tables:GetTables3tables:PutTableDataなどのアクション - Glue Data Catalog 側:
glue:GetTableglue:CreateTableなどのアクション - Lake Formation 側: データベース/テーブル単位の grant
- 各クエリエンジン側: Athena workgroup や EMR ロールの個別設定
Streamlined Permissions では、これらを 1 つの IAM ポリシー に集約できます。ブログ記事の表現を借りると「ストレージ・カタログ・コンピュート全体の権限を、単一の IAM ポリシーで定義できる」ということです。
アーキテクチャ
今回の検証構成は次のとおりです。
検証環境
- AWS リージョン: ap-northeast-1(東京)
- AWS Glue Version: 5.1
- 関連サービス: Amazon S3 Tables、AWS Glue Data Catalog、Amazon Athena、AWS IAM、AWS Lake Formation
やってみた
Step 1: S3 Tables バケットと Namespace の作成
BUCKET_NAME="blog-mv-perm-630d3629"
REGION="ap-northeast-1"
# S3 Tables バケットを作成
aws s3tables create-table-bucket \
--name ${BUCKET_NAME} \
--region ${REGION}
# Namespace を作成
TABLE_BUCKET_ARN="arn:aws:s3tables:${REGION}:${ACCOUNT_ID}:bucket/${BUCKET_NAME}"
aws s3tables create-namespace \
--table-bucket-arn ${TABLE_BUCKET_ARN} \
--namespace sales
バケット作成後、aws glue get-catalog --catalog-id "<ACCOUNT_ID>:s3tablescatalog/<BUCKET_NAME>" で確認すると、S3 Tables バケットが Glue Federation の 子カタログとして自動マウント されていることが分かります。
~ $ aws glue get-catalog --catalog-id "<AWS_ACCOUNT_ID>:s3tablescatalog/blog-mv-perm-630d3629"
{
"Catalog": {
"CatalogId": "<AWS_ACCOUNT_ID>:s3tablescatalog/blog-mv-perm-630d3629",
"Name": "blog-mv-perm-630d3629",
"ResourceArn": "arn:aws:glue:ap-northeast-1:<AWS_ACCOUNT_ID>:catalog/s3tablescatalog/blog-mv-perm-630d3629",
"CreateTime": "2026-05-12T12:14:18.112000+00:00",
"FederatedCatalog": {
"Identifier": "arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:bucket/*",
"ConnectionName": "aws:s3tables",
"ConnectionType": "aws:s3tables"
},
"CatalogProperties": {},
"CreateTableDefaultPermissions": [],
"CreateDatabaseDefaultPermissions": []
}
}
Step 2: Athena から Iceberg ベーステーブルを作成
Athena からは、Catalog を s3tablescatalog/<bucket> 形式、Database を namespace 名にして QueryExecutionContext で指定します。SQL 内で 4 パートカタログ名を直接書こうとすると MALFORMED_QUERY エラーになるため注意が必要です。
aws athena start-query-execution \
--query-string "CREATE TABLE orders (
id INT,
customer_name STRING,
amount DECIMAL(10,2),
order_date DATE
)" \
--query-execution-context "Catalog=s3tablescatalog/${BUCKET_NAME},Database=sales" \
--result-configuration "OutputLocation=s3://${AUX_BUCKET}/athena-results/"
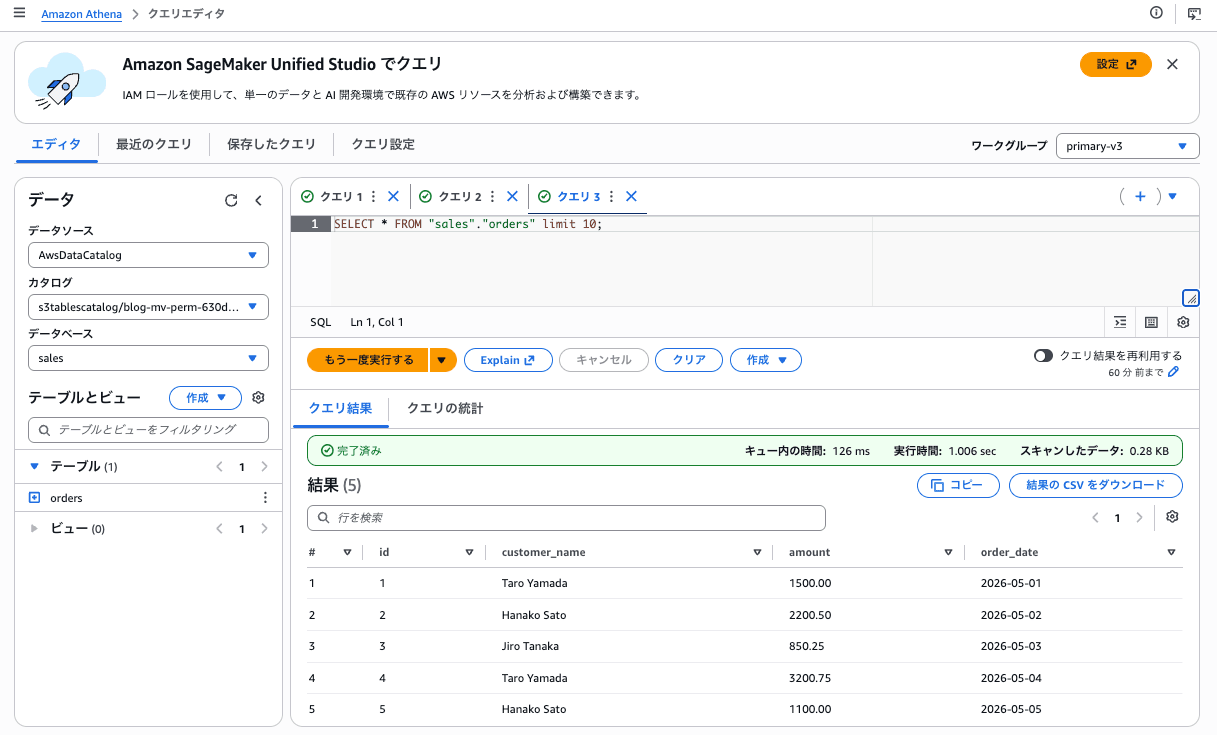
続いてサンプルデータを INSERT し、5 件のレコードを格納しました。
INSERT INTO orders VALUES
(1, 'Taro Yamada', DECIMAL '1500.00', DATE '2026-05-01'),
(2, 'Hanako Sato', DECIMAL '2200.50', DATE '2026-05-02'),
(3, 'Jiro Tanaka', DECIMAL '850.25', DATE '2026-05-03'),
(4, 'Taro Yamada', DECIMAL '3200.75', DATE '2026-05-04'),
(5, 'Hanako Sato', DECIMAL '1100.00', DATE '2026-05-05');
Step 3: Streamlined Permissions の IAM ポリシーを作成
ここが本機能の中核です。S3 Tables・Glue カタログ・Lake Formation を 横断する 1 つの IAM ポリシー を作成します。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"glue:GetCatalog",
"glue:GetCatalogs",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:CreateDatabase",
"glue:GetTable",
"glue:GetTables",
"glue:CreateTable",
"glue:UpdateTable",
"glue:DeleteTable",
"glue:StartMaterializedViewRefreshTaskRun",
"glue:GetMaterializedViewRefreshTaskRun",
"glue:ListMaterializedViewRefreshTaskRuns"
],
"Resource": [
"arn:aws:glue:ap-northeast-1:<AWS_ACCOUNT_ID>:catalog",
"arn:aws:glue:ap-northeast-1:<AWS_ACCOUNT_ID>:catalog/s3tablescatalog",
"arn:aws:glue:ap-northeast-1:<AWS_ACCOUNT_ID>:catalog/s3tablescatalog/blog-mv-perm-630d3629",
"arn:aws:glue:ap-northeast-1:<AWS_ACCOUNT_ID>:database/s3tablescatalog/blog-mv-perm-630d3629/sales",
"arn:aws:glue:ap-northeast-1:<AWS_ACCOUNT_ID>:table/s3tablescatalog/blog-mv-perm-630d3629/sales/*"
],
"Effect": "Allow",
"Sid": "GlueCatalogAccess"
},
{
"Action": [
"s3tables:GetTableBucket",
"s3tables:GetNamespace",
"s3tables:GetTable",
"s3tables:GetTableData",
"s3tables:GetTableMetadataLocation",
"s3tables:UpdateTableMetadataLocation",
"s3tables:UpdateTable",
"s3tables:PutTableData",
"s3tables:CreateTable",
"s3tables:DeleteTable",
"s3tables:ListNamespaces",
"s3tables:ListTables",
"s3tables:PutTableMaintenanceConfiguration"
],
"Resource": [
"arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:bucket/blog-mv-perm-630d3629",
"arn:aws:s3tables:ap-northeast-1:<AWS_ACCOUNT_ID>:bucket/blog-mv-perm-630d3629/*"
],
"Effect": "Allow",
"Sid": "S3TablesAccess"
},
{
"Action": [
"lakeformation:GetDataAccess"
],
"Resource": "*",
"Effect": "Allow",
"Sid": "LakeFormationDataAccess"
},
{
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::blog-mv-perm-aux-630d3629-<AWS_ACCOUNT_ID>",
"arn:aws:s3:::blog-mv-perm-aux-630d3629-<AWS_ACCOUNT_ID>/*"
],
"Effect": "Allow",
"Sid": "AuxS3AccessForGlue"
},
{
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:ap-northeast-1:<AWS_ACCOUNT_ID>:*",
"Effect": "Allow",
"Sid": "CloudWatchLogsAccess"
},
{
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<AWS_ACCOUNT_ID>:role/BlogMVGlueRole-630d3629",
"Effect": "Allow",
"Sid": "PassRoleForMVDefiner"
}
]
}
ポイントは次の点です。
- 1 つのポリシードキュメント内に
glue:*とs3tables:*の両方のアクションを記述 - リソース ARN は
s3tablescatalog/<bucket>/<namespace>/*のような階層パスで指定 lakeformation:GetDataAccessも同居(クエリ実行時のクレデンシャル取得用)- MV definer ロールとして自身を記録するため
iam:PassRoleが必要(これがハマりポイント)
ポリシーを作成し、Glue Job 用ロールに添付します。
aws iam create-policy \
--policy-name BlogMVStreamlinedPolicy-630d3629 \
--policy-document file://streamlined_policy.json
aws iam create-role \
--role-name BlogMVGlueRole-630d3629 \
--assume-role-policy-document file://trust_policy.json
aws iam attach-role-policy \
--role-name BlogMVGlueRole-630d3629 \
--policy-arn arn:aws:iam::<AWS_ACCOUNT_ID>:policy/BlogMVStreamlinedPolicy-630d3629
Step 4: Glue ETL Job で MV を作成
MV の CREATE MATERIALIZED VIEW 文は Athena では実行できず、AWS Glue 5.1 以上の Spark ETL Job が必要です(公式ドキュメントの "Configuring Spark to use materialized views" 参照)。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
print("=== Step A: Base table orders count (initial) ===")
spark.sql("SELECT COUNT(*) AS count FROM s3t_catalog.sales.orders").show()
print("=== Step B: Drop existing MV if any ===")
try:
spark.sql("DROP MATERIALIZED VIEW s3t_catalog.sales.customer_summary")
print("Dropped existing MV")
except Exception as e:
print(f"No existing MV to drop: {type(e).__name__}: {str(e)[:200]}")
print("=== Step C: Create MV ===")
spark.sql("""
CREATE MATERIALIZED VIEW s3t_catalog.sales.customer_summary
AS
SELECT
customer_name,
COUNT(*) AS order_count,
SUM(amount) AS total_amount
FROM s3t_catalog.sales.orders
GROUP BY customer_name
""")
print("MV created successfully")
print("=== Step D: MV initial data ===")
spark.sql("SELECT * FROM s3t_catalog.sales.customer_summary ORDER BY customer_name").show()
print("=== Step E: MV metadata (DESCRIBE EXTENDED) ===")
spark.sql("DESCRIBE EXTENDED s3t_catalog.sales.customer_summary").show(truncate=False, n=100)
job.commit()
print("Job completed successfully")
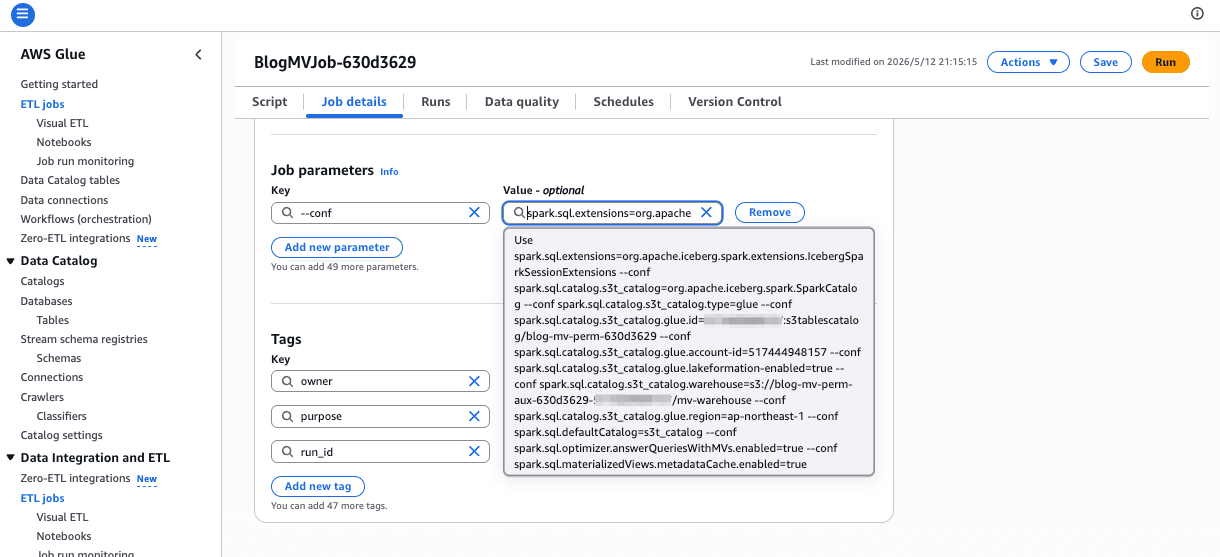
Glue Job の主要設定(--conf 引数):
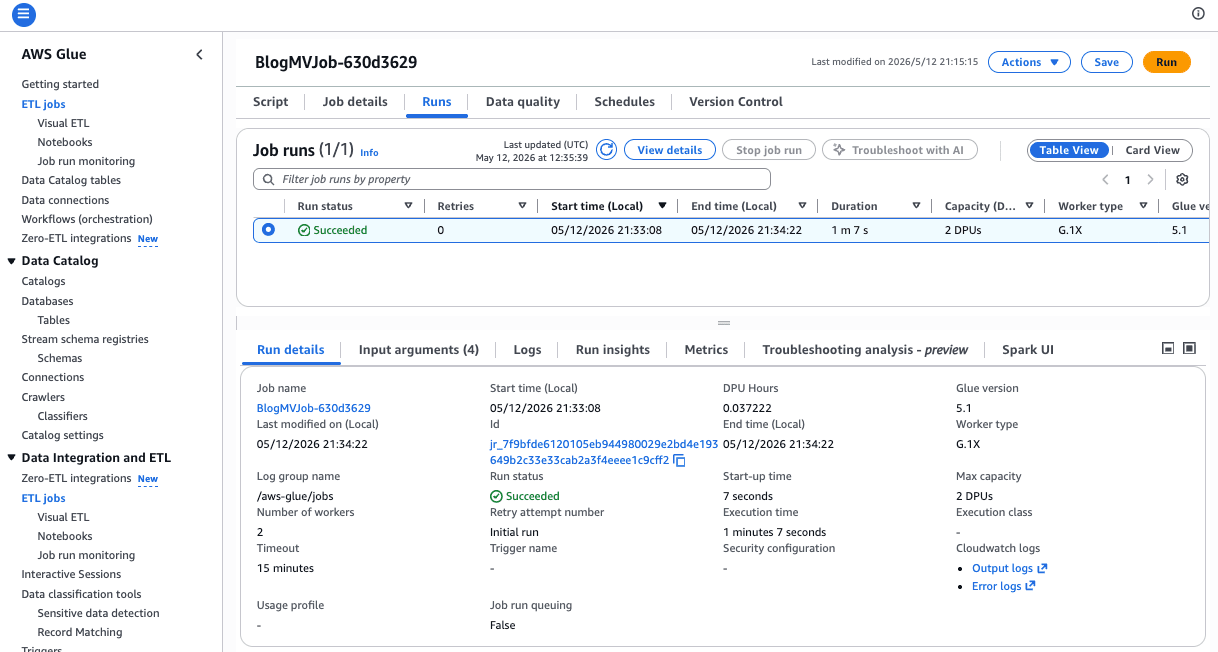
Job 実行は約 1分7秒で完了し、MV が S3 Tables バケット側にも自動登録されました。
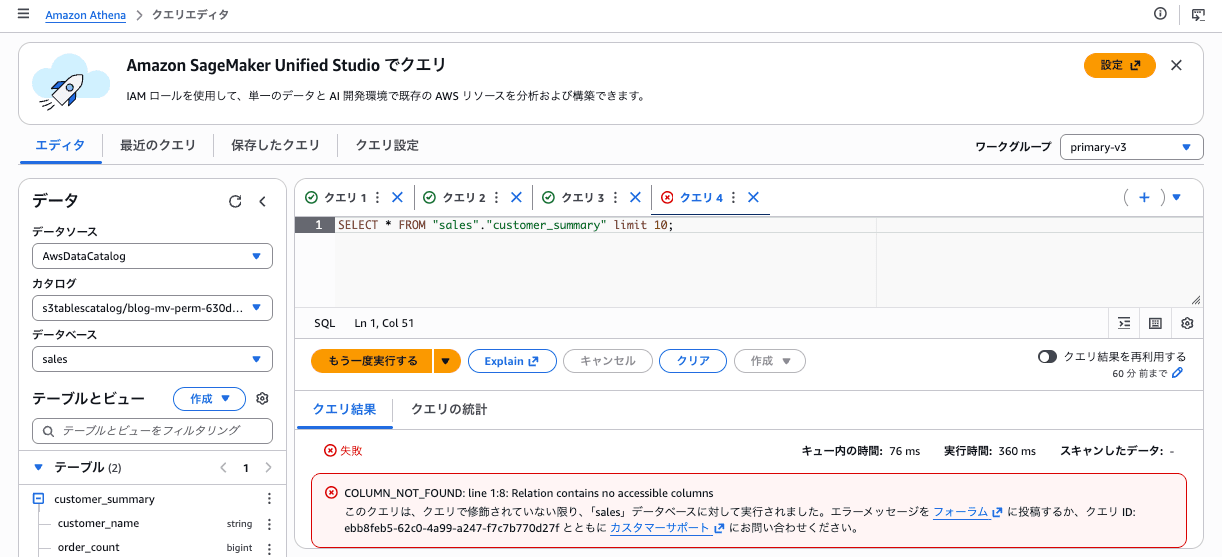
Step 5: Athena から MV を SELECT
MV 作成後、Athena から通常のテーブルと同様に SELECT すると、COLUMN_NOT_FOUND: line 1:8: Relation contains no accessible columnsでエラーになりました。
Lake Formation の挙動として、s3tablescatalog の子カタログ配下に新規作成されたテーブルには CreateTableDefaultPermissions が自動適用されない。明示的に MV へ grant を付与した。
~ $ aws lakeformation grant-permissions \
> --principal DataLakePrincipalIdentifier=IAM_ALLOWED_PRINCIPALS \
> --resource '{"Table":{"CatalogId":"<AWS_ACCOUNT_ID>:s3tablescatalog/blog-mv-perm-630d3629","DatabaseName":"sales","Name":"customer_summary"}}' \
> --permissions ALL \
> --region ap-northeast-1
MV 作成後、Athena から通常のテーブルと同様に SELECT できます。
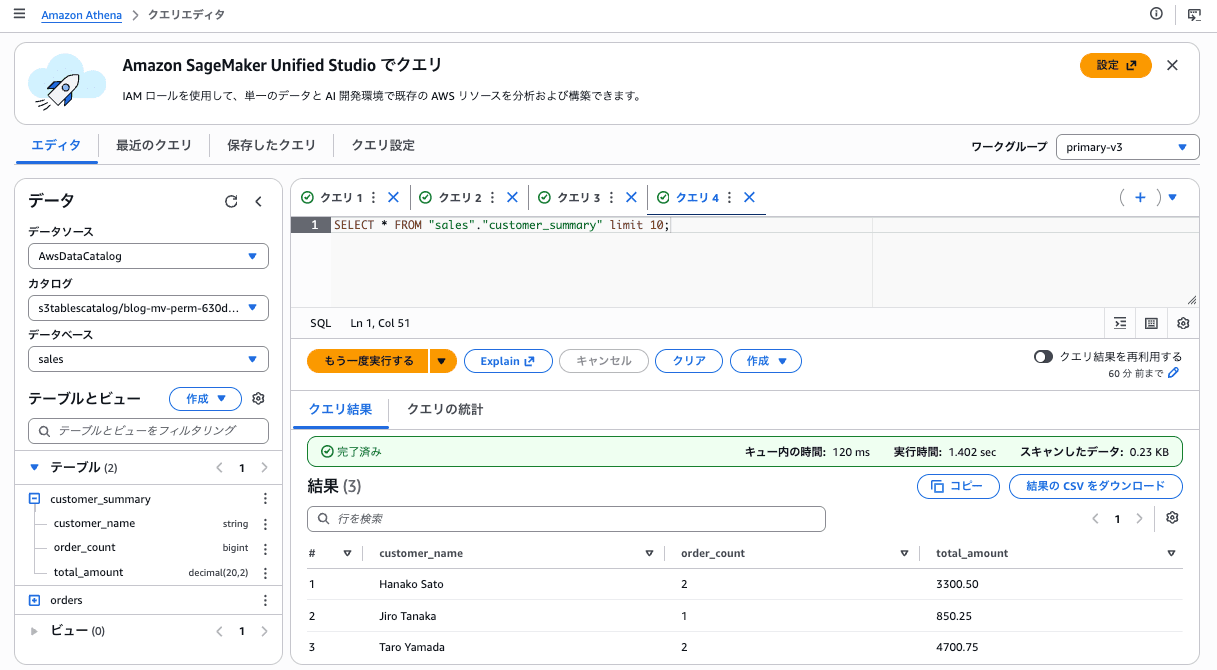
結果: 5 件の orders から 3つの顧客に集約
| customer_name | order_count | total_amount |
|---|---|---|
| Hanako Sato | 2 | 3300.50 |
| Jiro Tanaka | 1 | 850.25 |
| Taro Yamada | 2 | 4700.75 |
Step 6: ベーステーブルへ追加 INSERT して MV をリフレッシュ
ベーステーブルへ 3 件追加 INSERT すると、MV は古いまま(リフレッシュされるまで自動更新されない)。
INSERT INTO orders VALUES
(6, 'Saburo Suzuki', DECIMAL '500.00', DATE '2026-05-06'),
(7, 'Taro Yamada', DECIMAL '1750.00', DATE '2026-05-07'),
(8, 'Hanako Sato', DECIMAL '950.25', DATE '2026-05-08');
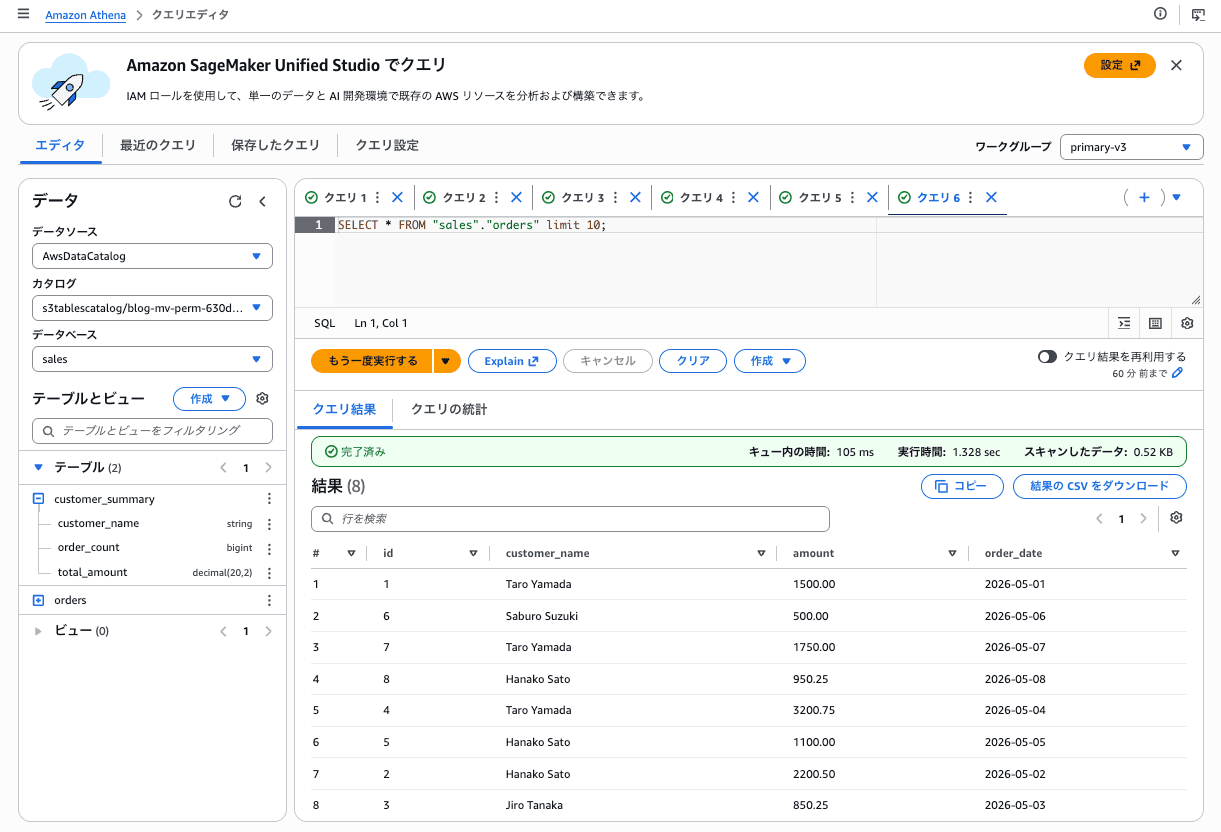
ベーステーブルが更新されたのでMVもリフレッシュします。 aws glue start-materialized-view-refresh-task-run API でリフレッシュをトリガーします。
~ $ aws glue start-materialized-view-refresh-task-run \
> --catalog-id "<AWS_ACCOUNT_ID>:s3tablescatalog/blog-mv-perm-630d3629" \
> --database-name sales \
> --table-name customer_summary \
> --no-full-refresh
{
"MaterializedViewRefreshTaskRunId": "744a736a-563a-4630-a0ea-1e39a4e3654e"
}
返却される MaterializedViewRefreshTaskRunId を使い、状態を確認します。
~ $ aws glue get-materialized-view-refresh-task-run \
> --catalog-id "<AWS_ACCOUNT_ID>:s3tablescatalog/blog-mv-perm-630d3629" \
> --materialized-view-refresh-task-run-id 744a736a-563a-4630-a0ea-1e39a4e3654e
{
"MaterializedViewRefreshTaskRun": {
"CustomerId": "<AWS_ACCOUNT_ID>",
"MaterializedViewRefreshTaskRunId": "744a736a-563a-4630-a0ea-1e39a4e3654e",
"DatabaseName": "sales",
"TableName": "customer_summary",
"CatalogId": "<AWS_ACCOUNT_ID>:s3tablescatalog/blog-mv-perm-630d3629",
"Role": "arn:aws:iam::<AWS_ACCOUNT_ID>:role/BlogMVGlueRole-630d3629",
"Status": "RUNNING",
"CreationTime": "2026-05-12T12:58:51+00:00",
"LastUpdated": "2026-05-12T12:58:51+00:00",
"DPUSeconds": 0.0
}
}
約3〜4分で完了(May 12, 2026 at 12:58 PM 〜 May 12, 2026 at 1:02 PM):
{
"MaterializedViewRefreshTaskRun": {
"CustomerId": "<AWS_ACCOUNT_ID>",
"MaterializedViewRefreshTaskRunId": "744a736a-563a-4630-a0ea-1e39a4e3654e",
"DatabaseName": "sales",
"TableName": "customer_summary",
"CatalogId": "<AWS_ACCOUNT_ID>:s3tablescatalog/blog-mv-perm-630d3629",
"Role": "arn:aws:iam::<AWS_ACCOUNT_ID>:role/BlogMVGlueRole-630d3629",
"Status": "SUCCEEDED",
"CreationTime": "2026-05-12T12:58:51+00:00",
"LastUpdated": "2026-05-12T13:02:40+00:00",
"EndTime": "2026-05-12T13:02:39+00:00",
"DPUSeconds": 240.3,
"RefreshType": "FULL",
"ProcessedBytes": 1490
}
}
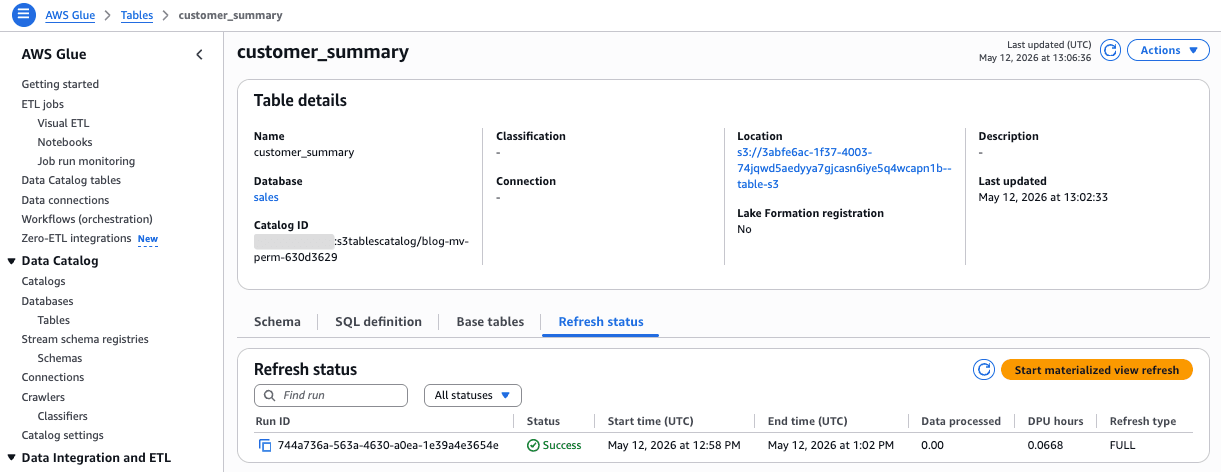
リフレッシュ後の MV を再 SELECT すると、4顧客に集約されていることが確認できました。
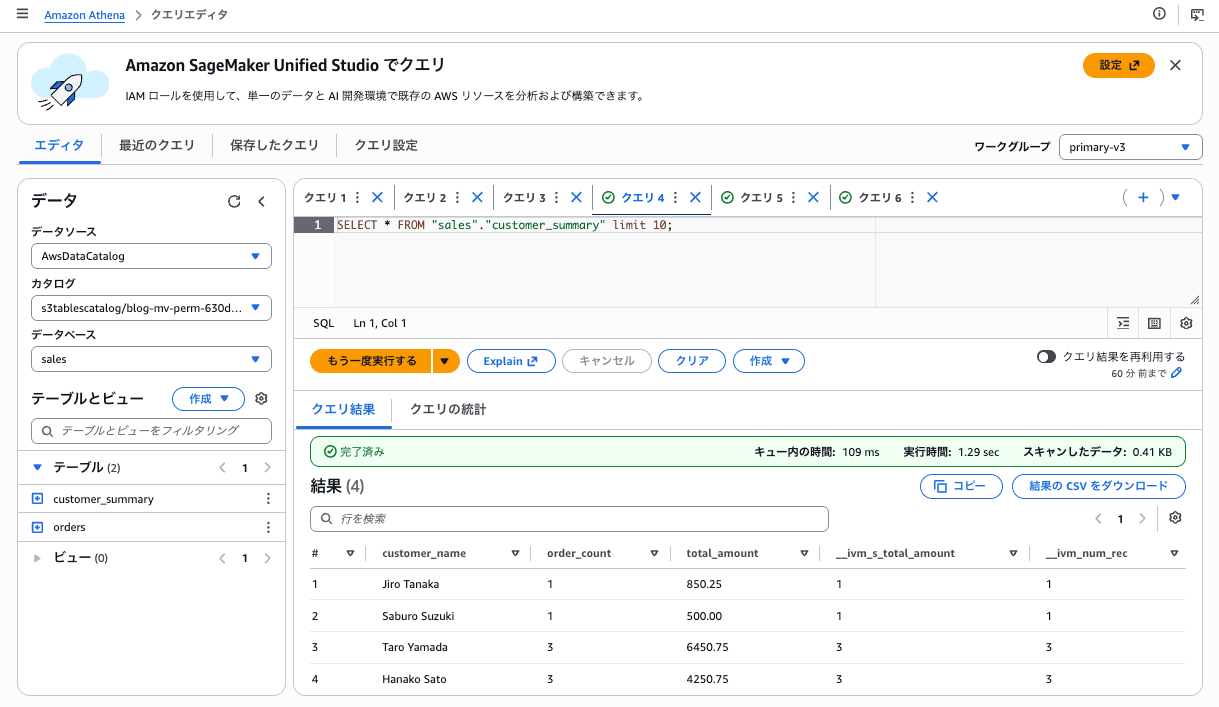
考察
単一 IAM ポリシーで複数サービスの権限を統一できる
最大の収穫は、glue:* と s3tables:* を 同じポリシードキュメントの異なる Statement にまとめられたことです。これまで Glue 用ロールと S3 Tables 用ロールを分離するか、複数のポリシーを束ねる運用が必要でしたが、Streamlined Permissions では 1 ポリシーで完結します。とくにマルチエンジン分析基盤の権限設計が大きく簡素化されます。
MV のストレージは S3 バケット内に自動配置される
検証中の最大の発見は、warehouse パラメータで補助 S3 バケットを指定していたにもかかわらず、MV の実体は S3 バケット内のディレクトリバケット(xxx--table-s3 命名)に格納されたことです。
Glue Catalog のテーブル詳細を見ると Location は次のとおりでした:
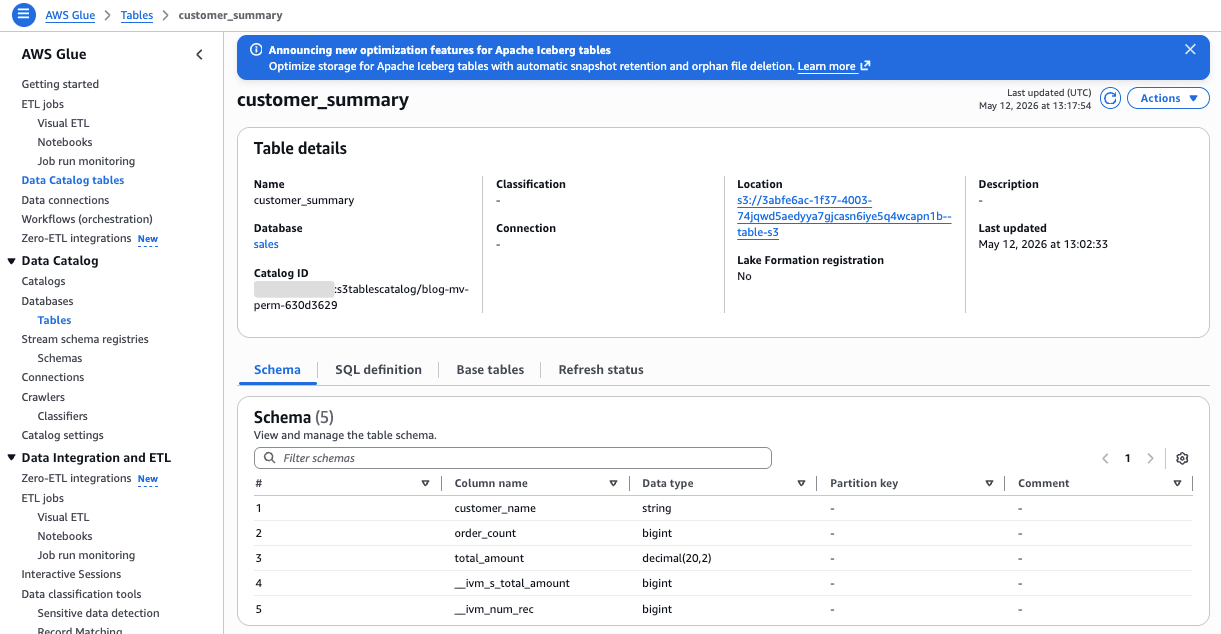
s3://3abfe6ac-1f37-4003-74jqwd5aedyya7gjcasn6iye5q4wcapn1b--table-s3のリンクをクリックするとS3バケットの画面に遷移するけど、本来見えてはいけないものが見えて、「不明なエラー」になっている気がする。
iam:PassRole 権限が必須
CREATE MATERIALIZED VIEW 実行時、Glue Data Catalog は MV 自動リフレッシュ機能のために definer ロールの ARN を MV メタデータに記録 します。このため、Job ロール自身が自身を PassRole する権限を持っていないと次のエラーが発生します。
User: ...BlogMVGlueRole-630d3629... is not authorized to perform:
iam:PassRole on resource: arn:aws:iam::...:role/BlogMVGlueRole-630d3629
Streamlined Permissions ポリシーには、必ず以下の Statement を含めてください:
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<AWS_ACCOUNT_ID>:role/BlogMVGlueRole-630d3629"
}
--no-full-refresh でも条件次第で FULL に切り替わる
上記でも見られたように、--no-full-refresh で incremental refresh を要求しましたが、結果は RefreshType: FULL でした。公式ドキュメントには「インクリメンタル更新は SELECT-FROM-WHERE-GROUP BY-HAVING の単一ブロックに限定」とあるほか、Spark セッションで spark.sql.optimizer.incrementalMVRefresh.enabled=true の設定が必要です。今回の検証では条件を満たさなかったため、自動的に FULL に切り替わったと考えられます。
__ivm_* システム列の存在
Athena や Glue からSELECT * で MV を取得すると、ユーザー定義列の他に __ivm_s_<col>、__ivm_num_rec といったシステム列が露出します。

これは Incremental View Maintenance のための内部列で、公式ドキュメントにも「__ivm プレフィックスのカラムはシステム予約」と明記されています。プロダクション利用時は SELECT * ではなく、ユーザー定義列を明示的に指定することを強くおすすめします。
Lake Formation の Catalog DESCRIBE 権限は別途必要(私の環境)
Streamlined Permissions IAM ポリシーだけでは、Glue Catalog 側の Lake Formation チェックを通過できませんでした。検証アカウントでは Required Describe on Catalog エラーが発生し、別途 Lake Formation で Catalog/Database レベルの grant が必要でした。
aws lakeformation grant-permissions \
--principal DataLakePrincipalIdentifier=IAM_ALLOWED_PRINCIPALS \
--resource '{"Table":{"CatalogId":"<AWS_ACCOUNT_ID>:s3tablescatalog/blog-mv-perm-630d3629","DatabaseName":"sales","Name":"customer_summary"}}' \
--permissions ALL \
--region ap-northeast-1
これは既存環境の Lake Formation 設定(s3tablescatalog の旧仕様マウント)に依存している可能性があり、新規に S3 Tables 統合を設定する場合は不要かもしれません。新規環境での挙動は引き続き検証していきたいところです。
コラム: 本家 Apache Iceberg の MV 仕様
本家 Apache Iceberg でも、マテリアライズドビュー仕様が Iceberg Improvement Proposal(Issue #10043)として提案されており、エンジン間で共有可能な共通メタデータフォーマットを定義することを目的としています。現在は PR #11041(JanKaul 氏)として View Spec への追加セクションの形で実装が進められています。
最後に
今日のAWS Big Data Blog の内容が、まさにこの内容だったのですが、検証にお金がかかりそうな構成だったので後半はオリジナルに書き換えています。
- Streamlined Permissions により、S3 Tables + Glue Catalog + Iceberg MV の権限定義を 1 つの IAM ポリシーに集約できる
- MV 作成は Glue 5.1 以上の Spark ETL Job が必要(Athena からの
CREATE MATERIALIZED VIEWは不可) aws glue start-materialized-view-refresh-task-runAPI でリフレッシュをトリガーできる(手動運用が現実的)- ハマりポイントは
iam:PassRole、warehouse の自動配置、--no-full-refreshの自動 FULL 切り替え、__ivm_*システム列の露出
複数の分析エンジンから S3 Tables を活用する設計をしているチームにとって、権限管理の複雑さは大きな運用負担でした。Streamlined Permissions は、その負担を実用レベルまで引き下げてくれる重要なアップデートです。手動リフレッシュ運用を組み込めば、Iceberg MV による集計の事前計算もすぐに本番投入できそうです。
合わせて読みたい











