
AWS Advanced JDBC Wrapper 4.0.1 の Remote Query Cache Plugin で Aurora PostgreSQL のクエリ結果を ElastiCache for Valkey に自動キャッシュしてみた
クラウド事業本部の石川です。AWS Advanced JDBC Wrapper 4.0.1 で追加された Remote Query Cache Plugin を使うと、SQL コメントヒントを付けるだけで SELECT 結果を Amazon ElastiCache for Valkey に自動キャッシュできるとのことで、Aurora PostgreSQL を相手に試してみました。
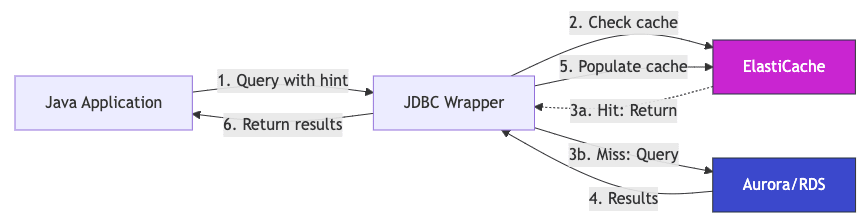
2026 年 5 月 19 日に AWS Database Blog から「Automated JDBC query caching with the AWS Advanced JDBC Wrapper」が公開されました。AWS Advanced JDBC Wrapper 4.0.1 で導入された Remote Query Cache Plugin の紹介記事で、アプリケーション側のコードはほぼそのまま、SQL に /* CACHE_PARAM(ttl=...) */ というコメントを付け加えるだけで、その結果を Amazon ElastiCache for Valkey にキャッシュできるようになっています。
これまでクエリ結果のキャッシングは、Jedis や Lettuce などの Redis クライアントを呼び出すコードを業務ロジックに混ぜ込む実装になりがちで、対象クエリの選定もアプリ側のリファクタリングも重い作業でした。Remote Query Cache Plugin は JDBC Wrapper のプラグインとして接続層に組み込まれるため、Statement を実行する側のコードに手を入れずにキャッシュ層を追加できる点が特徴とされています。
Remote Query Cache Plugin とは
Remote Query Cache Plugin は、JDBC Wrapper の wrapperPlugins に remoteQueryCache を指定するだけで有効になる読み取りスルー型のキャッシュプラグインです。SQL に /* CACHE_PARAM(ttl=300s) */ のようなコメントヒントを書くと、その SELECT の結果セットをデータベースユーザー名・スキーマ名・SQL 文字列をキーにして Valkey に格納し、次回以降の同一クエリは Valkey から直接返します。キャッシュバックエンドが応答しない場合はデータベースにフォールバックして結果を取得する設計です。
公式ドキュメントから読み取れる主要な仕様は次のとおりです。
- 対応データベース: PostgreSQL / MySQL / MariaDB(JDBC 経由)
- TTL の上限は 180 日(無期限キャッシュは不可)
- CLOB / BLOB の取得には未対応
- IAM 認証、TLS 接続、ヘルスチェック、CloudWatch ライクなメトリクスが組み込み
プラグイン本体に加えて、ランタイム依存として io.valkey:valkey-glide 2.3.0 以上と org.apache.commons:commons-pool2 2.11.1 以上をクラスパスに別途追加する必要があります。
やってみた
前提条件
- AWS アカウント(検証は東京リージョン ap-northeast-1)
- 同一 VPC 内に Aurora PostgreSQL(今回は Serverless v2、engine 16.4、0.5〜1.0 ACU)と ElastiCache for Valkey Serverless(engine 8)
- アプリケーションは VPC 内の EC2(t3.small、Amazon Linux 2023)から実行
- ビルド・実行は OpenJDK 21 + Maven 3.8.4(コンパイラは Java 17 ターゲット)
検証は性能比較を主目的としないため、Aurora と Valkey は最小構成、データは 100 行の products テーブルで進めます。
検証済み: Aurora と Valkey の準備
Aurora クラスター、Aurora インスタンス、ElastiCache Valkey サーバーレスを順次作成しました。検証用なのでバックアップ保持や削除保護は無効化しています。
% aws rds create-db-cluster \
--db-cluster-identifier blog-jdbc-aurora \
--engine aurora-postgresql --engine-version 16.4 \
--master-username blogadmin --master-user-password '***' \
--database-name sampledb \
--db-subnet-group-name blog-jdbc-dbsng \
--vpc-security-group-ids sg-xxxxxxxx \
--serverless-v2-scaling-configuration MinCapacity=0.5,MaxCapacity=1.0 \
--no-deletion-protection --backup-retention-period 1 --storage-encrypted
% aws rds create-db-instance \
--db-instance-identifier blog-jdbc-aurora-1 \
--db-cluster-identifier blog-jdbc-aurora \
--engine aurora-postgresql --db-instance-class db.serverless
% aws elasticache create-serverless-cache \
--serverless-cache-name blog-jdbc-cache \
--engine valkey --major-engine-version 8 \
--security-group-ids sg-xxxxxxxx \
--subnet-ids subnet-xxxxxxxx subnet-yyyyyyyy
EC2 にログインして PostgreSQL クライアントから接続できることを確認したうえで、検証用テーブルを作成します。
dev=# CREATE TABLE products (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
price INTEGER NOT NULL
);
CREATE
dev=# INSERT INTO products (id, name, price)
SELECT
g,
'product-' || lpad(g::text, 4, '0'),
(g * 17 + 100)
FROM generate_series(1, 100) AS g;
INSERT 0 100
row_count
-----------
100
(1 row)
検証済み: Maven プロジェクトと Java サンプル
Maven プロジェクトの pom.xml には JDBC Wrapper 本体に加えて PostgreSQL ドライバ、commons-pool2、valkey-glide を宣言します。最初は valkey-glide を忘れていて起動時に ClassNotFoundException: glide.api.GlideClient が出たので、ここは必ず追加する必要があります。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0">
<modelVersion>4.0.0</modelVersion>
<groupId>example</groupId>
<artifactId>jdbc-cache-demo</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>software.amazon.jdbc</groupId>
<artifactId>aws-advanced-jdbc-wrapper</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>io.valkey</groupId>
<artifactId>valkey-glide</artifactId>
<classifier>linux-x86_64</classifier>
<version>2.3.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>3.4.1</version>
<configuration>
<mainClass>example.App</mainClass>
</configuration>
</plugin>
</plugins>
</build>
</project>
検証用の Java コードはシンプルで、wrapperPlugins=remoteQueryCache を指定した接続を 1 本作り、ヒントなしの SELECT を 2 回、ヒント付きの SELECT を 2 回流すだけの実装です。
package example;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.Properties;
public class App {
public static void main(String[] args) throws Exception {
String jdbcUrl = System.getenv("JDBC_URL");
String dbUser = System.getenv("DB_USER");
String dbPassword = System.getenv("DB_PASSWORD");
String cacheEndpoint = System.getenv("CACHE_ENDPOINT");
Properties props = new Properties();
props.setProperty("user", dbUser);
props.setProperty("password", dbPassword);
props.setProperty("wrapperPlugins", "remoteQueryCache");
props.setProperty("cacheEndpointAddrRw", cacheEndpoint);
props.setProperty("cacheUseSSL", "true");
props.setProperty("cacheConnectionTimeoutMs", "10000");
try (Connection conn = DriverManager.getConnection(jdbcUrl, props)) {
String hintQuery =
"/* CACHE_PARAM(ttl=300s) */ SELECT id, name, price FROM products WHERE id < 10 ORDER BY id";
String plainQuery =
"SELECT id, name, price FROM products WHERE id < 10 ORDER BY id";
System.out.println("=== Query A (no hint, executed twice) ===");
runAndReport(conn, plainQuery, "A-1");
runAndReport(conn, plainQuery, "A-2");
System.out.println();
System.out.println("=== Query B (CACHE_PARAM hint, executed twice) ===");
runAndReport(conn, hintQuery, "B-1 (miss expected)");
Thread.sleep(1500);
runAndReport(conn, hintQuery, "B-2 (hit expected)");
}
}
private static void runAndReport(Connection conn, String sql, String label) throws Exception {
long t0 = System.nanoTime();
int rows = 0;
try (Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql)) {
while (rs.next()) {
rows++;
}
}
long elapsedMs = (System.nanoTime() - t0) / 1_000_000;
System.out.printf("[%s] rows=%d elapsed=%d ms%n", label, rows, elapsedMs);
}
}
Maven ビルドと実行
依存解決とコンパイルを行います。初回は Maven Central から JDBC Wrapper や valkey-glide を取りに行くので 3〜5 分かかります。
cd /opt/jdbc-cache-demo
mvn -q -DskipTests dependency:resolve compile
ビルドエラーが出ずプロンプトに戻ってくれば成功です。
JDBC URL のスキームは jdbc:aws-wrapper:postgresql://... で、wrapperPlugins=remoteQueryCache と cacheEndpointAddrRw を Properties に渡せばプラグインが有効になります。環境変数が export 済みであることを確認したうえで実行します。
echo "JDBC_URL=${JDBC_URL}"
mvn -q exec:java
検証済み: プラグイン動作の確認
EC2 上で mvn exec:java を 2 回実行した結果は以下のとおりです。各行の elapsed はクライアント側で System.nanoTime() 差分から算出したミリ秒値です。
=== Query A (no hint, executed twice) ===
[A-1] rows=9 elapsed=36 ms
[A-2] rows=9 elapsed=2 ms
=== Query B (CACHE_PARAM hint, executed twice) ===
WARNING: [HEALTHY?SUSPECT] blog-jdbc-cache-xxxxx.serverless.apne1.cache.amazonaws.com:6379 READ failed: CONNECTION - glide.api.models.exceptions.TimeoutException: Request timed out
WARNING: Failed to read result from cache. Treating it as a cache miss.
[B-1 (miss expected)] rows=9 elapsed=10381 ms
[B-2 (hit expected)] rows=9 elapsed=7 ms
ヒントなしの Query A はキャッシュを経由せず素の JDBC として実行され、ウォームアップ後の 2 回目は 2 ms と Aurora の素の応答性に近い値が出ています。
ヒントありの Query B は、初回の B-1 で Glide クライアントの初回接続セットアップに時間がかかり、cacheConnectionTimeoutMs を 10 秒に延ばしてもキャッシュ読み出しがタイムアウトしました。タイムアウト後は WARNING ログが出るだけでアプリケーションには例外を投げず、データベースから結果を取得して返すフォールバック動作が観測できました。次の B-2 では 7 ms で結果が返っており、B-1 の裏で非同期に書き込まれたエントリを読み出していると考えられます。
ここで注目したいのは、ウォームアップ済み Aurora の 2 ms に対し、Valkey ヒット時の B-2 が 7 ms と逆に遅くなっている点です。これは「キャッシュなら必ず速くなる」とは限らないことを示しています。考察セクションで深掘りします。
検証済み: CloudWatch メトリクス
Valkey 側の CloudWatch メトリクス(AWS/ElastiCache、dimensions は clusterId=blog-jdbc-cache)を確認すると、検証時刻帯に CacheMisses と CacheHits がそれぞれ 2 件記録されていました。
## Valkey CacheHits (per minute)
| Sum | Time |
+-----+------------------------------+
| 2.0| 2026-05-20T03:13:00+09:00 |
## Valkey CacheMisses (per minute)
| Sum | Time |
+-----+------------------------------+
| 2.0| 2026-05-20T03:12:00+09:00 |
run を 2 回実行した結果、B-1 が 2 回 (= ミス 2)、B-2 が 2 回 (= ヒット 2) と数も一致しており、プラグインから Valkey に書き込み・読み出しが行われていることが確認できました。NewConnections は分あたり 14〜19 件記録されており、JVM 起動ごとに Glide が複数 TCP 接続を確立する挙動も見えています。
未検証: IAM 認証 / Spring Boot 連携 / 本格的なロードテスト
今回は検証時間とサンプル規模の都合で本記事執筆時点では検証できませんでした。公式ドキュメントによると、cacheName cacheIamRegion cacheUsername を指定することで ElastiCache の IAM 認証に対応し、また Spring Boot アプリケーションでも application.yml の JDBC URL とプロパティを差し替えるだけで利用できる、とのことです。
aws-samples の jdbc-caching-demo には Spring Boot 3.4 と React 18 を組み合わせた性能比較 UI が用意されているので、より本格的なロードテストを行う場合はそちらが参考になります。
考察
キャッシュ経由のほうが遅くなった結果をどう読むか
今回のレイテンシ計測は以下のとおりでした。
| 計測 | 経路 | 観測値 |
|---|---|---|
| A-2 | Aurora 直接(ウォーム後) | 2 ms |
| B-2 | Valkey 経由(キャッシュヒット) | 7 ms |
A-2 のほうが速く、Remote Query Cache Plugin を入れた B-2 はむしろ 5 ms ほどオーバーヘッドが増えています。これはプラグインの欠陥ではなく、検証用クエリが「Aurora 単体で十分速いクエリ」だったための当然の結果と考えます。
このクエリは 100 行テーブルから 9 行を返す SELECT で、A-1 実行時点で Aurora のバッファプール、プランキャッシュ、コネクションが全てウォームになっています。A-2 で Aurora が返す 2 ms はほぼ「VPC 内の RTT + 結果セットのシリアライズ時間」に等しく、これより速い経路を作るのは構造上難しい状態です。一方で、キャッシュヒット時は次のオーバーヘッドが追加されます。
- プラグインによるキャッシュキー計算(user / catalog / SQL のハッシュ)
- TLS 上で Valkey に GET 発行
- Glide の非同期処理ラッパ通過
- 取り出したバイト列を JDBC
ResultSet互換オブジェクトへデシリアライズ
これらの和が 5 ms 程度になり、A-2 を上回ったというのが今回の数字の素直な解釈です。逆に言うと、Aurora 単体での応答が 5 ms を大きく超えるクエリでなければ、プラグインは導入のメリットを出しづらいということです。
Remote Query Cache Plugin が効くケースと効かないケース
公式ドキュメントの記載とあわせて整理すると、適合するのは次のようなクエリです。
Remote Query Cache Plugin が効くケース
- 実行コストが重い(複数テーブルの JOIN、集計、ソート、ウィンドウ関数、フルテーブルスキャンが避けられないもの)
- 結果セットが大きく、Aurora 側の I/O やネットワーク転送が支配項になる
- 同時実行数が多く、Aurora のリーダーインスタンスを増やすコストを抑えたい
- TTL 内に同一クエリが繰り返し発行される(マスタ系・設定系の参照クエリなど)
- アプリケーションが Aurora と AZ/リージョン的に離れていて、DB ラウンドトリップ自体が長い
Remote Query Cache Plugin が逆に効かない/むしろ遅くなるケース
- 今回のように Aurora が数ミリ秒で返せる軽量 SELECT
- 結果セットが極端に小さく、シリアライズ/デシリアライズのコストが応答時間の大半を占めるクエリ
- 結果が毎回変わるクエリ(キャッシュヒット率が下がる)
- CLOB / BLOB を含むクエリ(ドキュメントで非対応と明記)
- TTL 180 日を超える長期キャッシュ要件
導入時には「キャッシュさえ入れれば速くなる」と考えず、まず素の Aurora で観測してボトルネックになっているクエリを抽出し、その中から CACHE_PARAM の対象を選ぶという順序が現実的です。
その他の運用上の留意点
- 初回 B-1 で発生した Glide のタイムアウトは
cacheConnectionTimeoutMsを 2 秒から 10 秒に拡大しても再現したので、JVM 起動直後(コールドスタート)にはキャッシュへのアクセスが間に合わないケースが想定されます。ただし WARNING を出してデータベースにフォールバックする設計のおかげでアプリ側からは結果取得できているのは安心材料です。 - 依存ライブラリの宣言ミスは
ClassNotFoundExceptionで気付けますが、valkey-glideのclassifierを OS に合わせて指定する必要がある点はトラブルの種になりやすいので、CI/CD のベースイメージや実行環境ごとに classifier を切り替える運用を準備したほうが良さそうです。 - 今回は無認証で接続したため起動時に「For better security, please use user/password based auth or IAM auth.」という WARNING が出ました。本番では IAM 認証または user/password の利用が前提になります。
最後に
AWS Advanced JDBC Wrapper 4.0.1 の Remote Query Cache Plugin を、Aurora PostgreSQL Serverless v2 + ElastiCache for Valkey Serverless の構成で試してみました。このようなJDBCドライバの間に挟むデコレータアプローチでクエリ結果をキャッシュする仕組みは、かなり前からありました。しかし、アプリ側のコード変更が wrapperPlugins の指定と SQL ヒントの追加だけで済むのは大きなメリットで、変更頻度の低いマスタ系クエリの応答性改善には素直に効きそうです。
JDBC Wrapper の他プラグイン(フェイルオーバー、リードライト分割、Secrets Manager)と組み合わせて利用できる構成も魅力的で、Aurora をバックエンドにしたエンタープライズアプリケーションでは特に検討する価値があると感じました。
ここだけの話、Amazon RedshiftServerlessのキャッシュ層に使えないかも検討したのですが、PostgreSQL JDBC Driver が startup packet で送る extra_float_digits=3 が Redshift Serverless で拒否されるため、Wrapper や Plugin の機能が動く以前にハンドシェイクで失敗してしまいました。この記事がどなたかのお役に立てば幸いです。










