
4 Things No One Tells You About Git
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
In any SDLC task or Devops task, working with version control is inevitable.
People often focus on DSA, database, networking and various other fundamentals which are important but learning version control tools like git is a skill which is as important as any other fundamentals.
This blog talks about the everyday use cases with git which every developer or DevOps engineer will likely face during their projects and the purpose of this blog is to help you learn from my experience which I faced when I started working. ( I learned it the hard way, hope it helps in your learning journey) ?
In the end, please check out how DevOps engineers use git for their day-to-day tasks.❤️
Prequisites
- Understanding of why we need version control?
- Understanding of git (how to play around with basic commands and concepts like staging).
Use Cases
1) When another developer pushes their changes to the same branch on remote
Scenario: You and your teammate is working on the same branch, however, he/she pushed their commit changes to remote. You are still working on your local, and when you try to push your changes to remote; you simply can't!
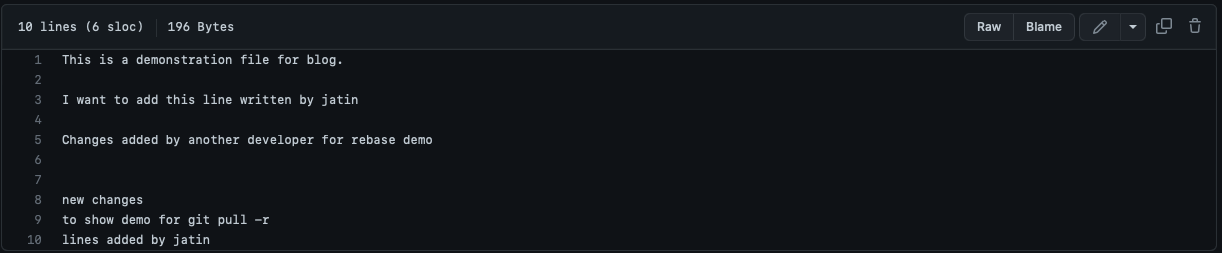
- Here in the branch
rebase-demoother developers commit their changes first and as a result we won't be able to push our changes until we pull the changes of remote.
A Bad Solution: Running git push -f on your local would definitely solve the issue but it will surely mess up your commit history and overwrites other users' commit.
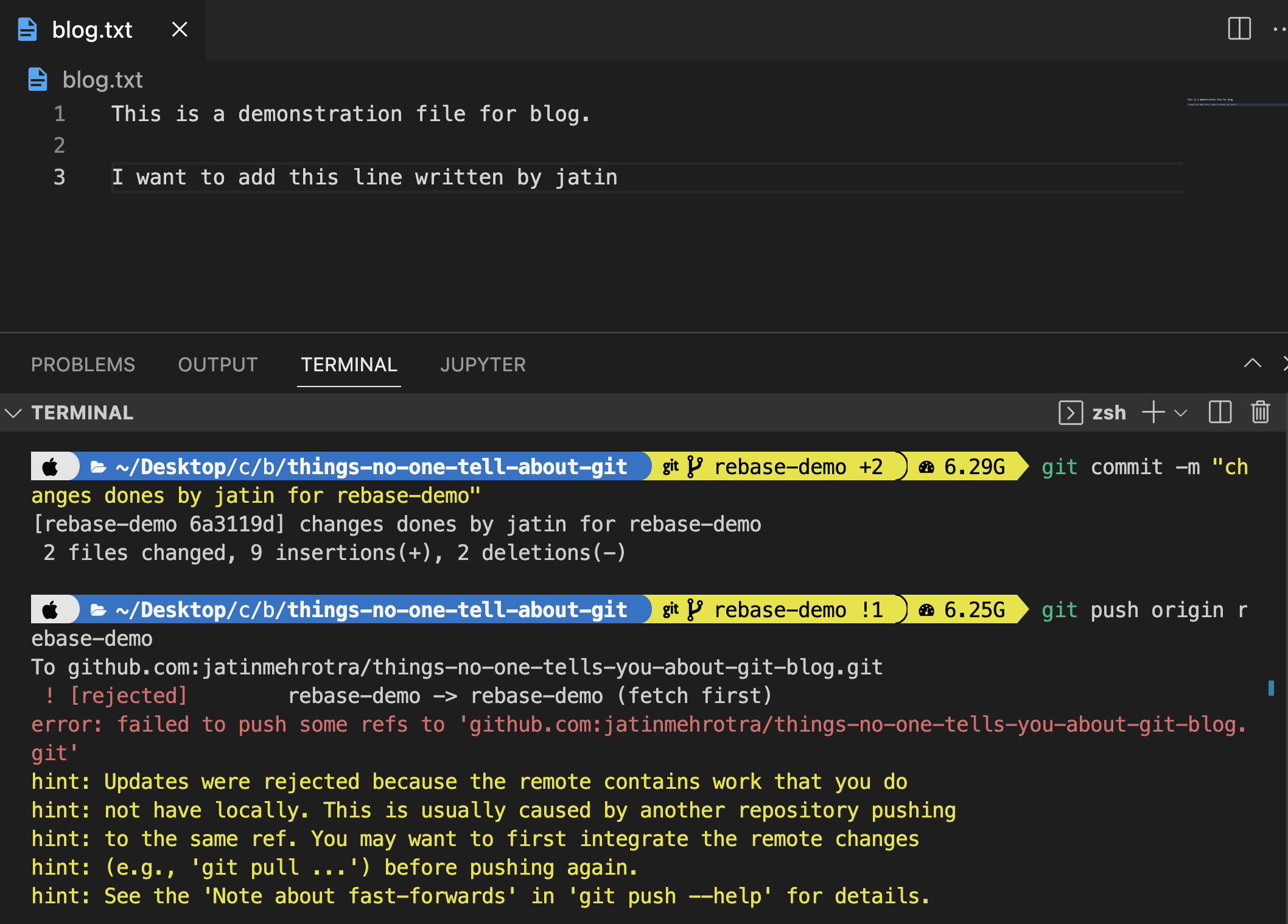
Solution: Do a rebase. It pulls changes from remote and stacks our local changes on top of that, hence avoiding an extra commit and leading to cleaner commit history.
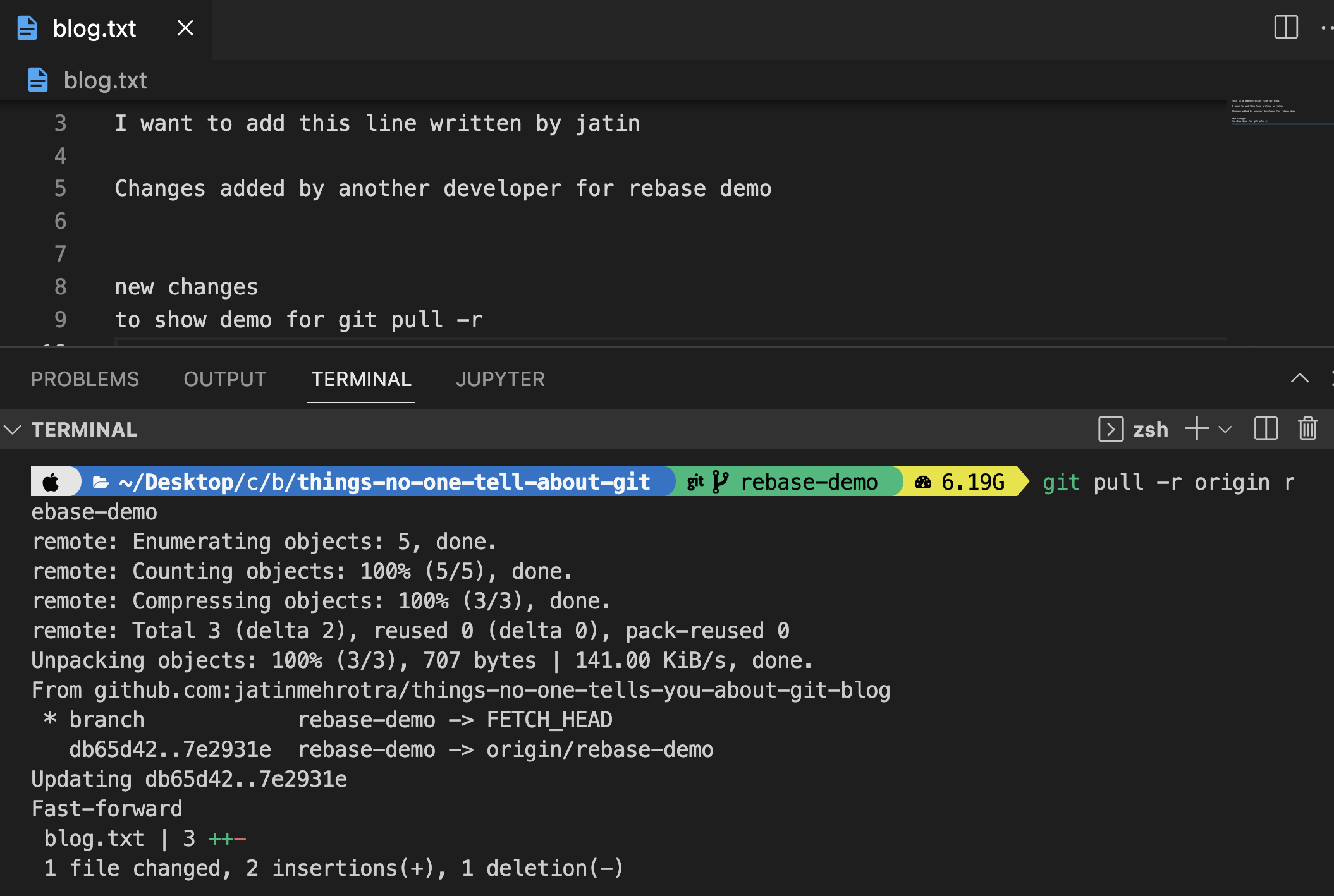
git pull -r

2) There is a bug in the code, how to find the cause?
Scenario: We don't know which commit caused the bug, in order to find the cause and perform our testing to ensure the bug was caused by a particular commit, git allows us to go back in time; to go back to that specific version of the project i.e to checkout the commit which is in question.
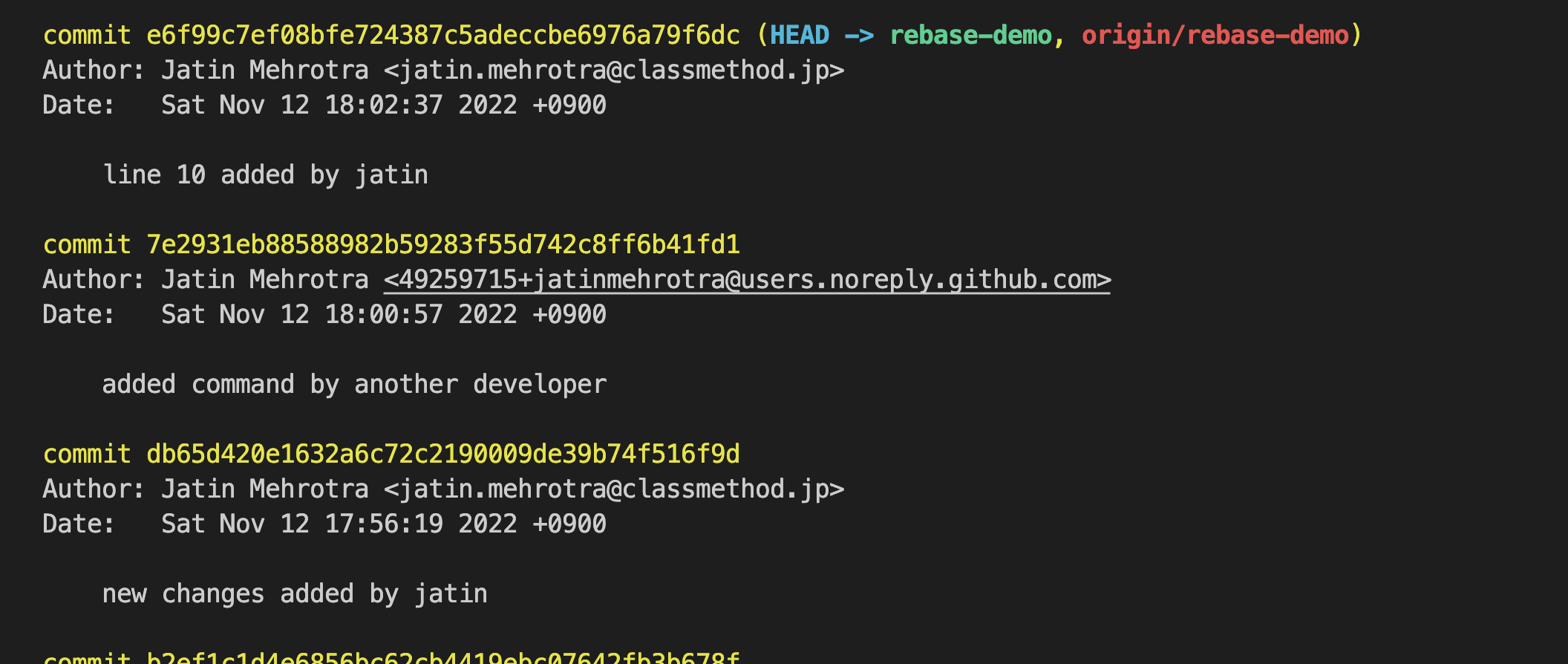
- Now suppose I think the
added command by another developercommit is the cause of the bug. I can copy its hash and go back in time to this commit.
git log
git checkout 7e2931eb88588982b59283f55d742c8ff6b41fd1
Solution:- Git allows us to view the history of a commit using the
git logcommand and using the hash of the commit we cancheckoutto a specific time in code and verify/test the cause.
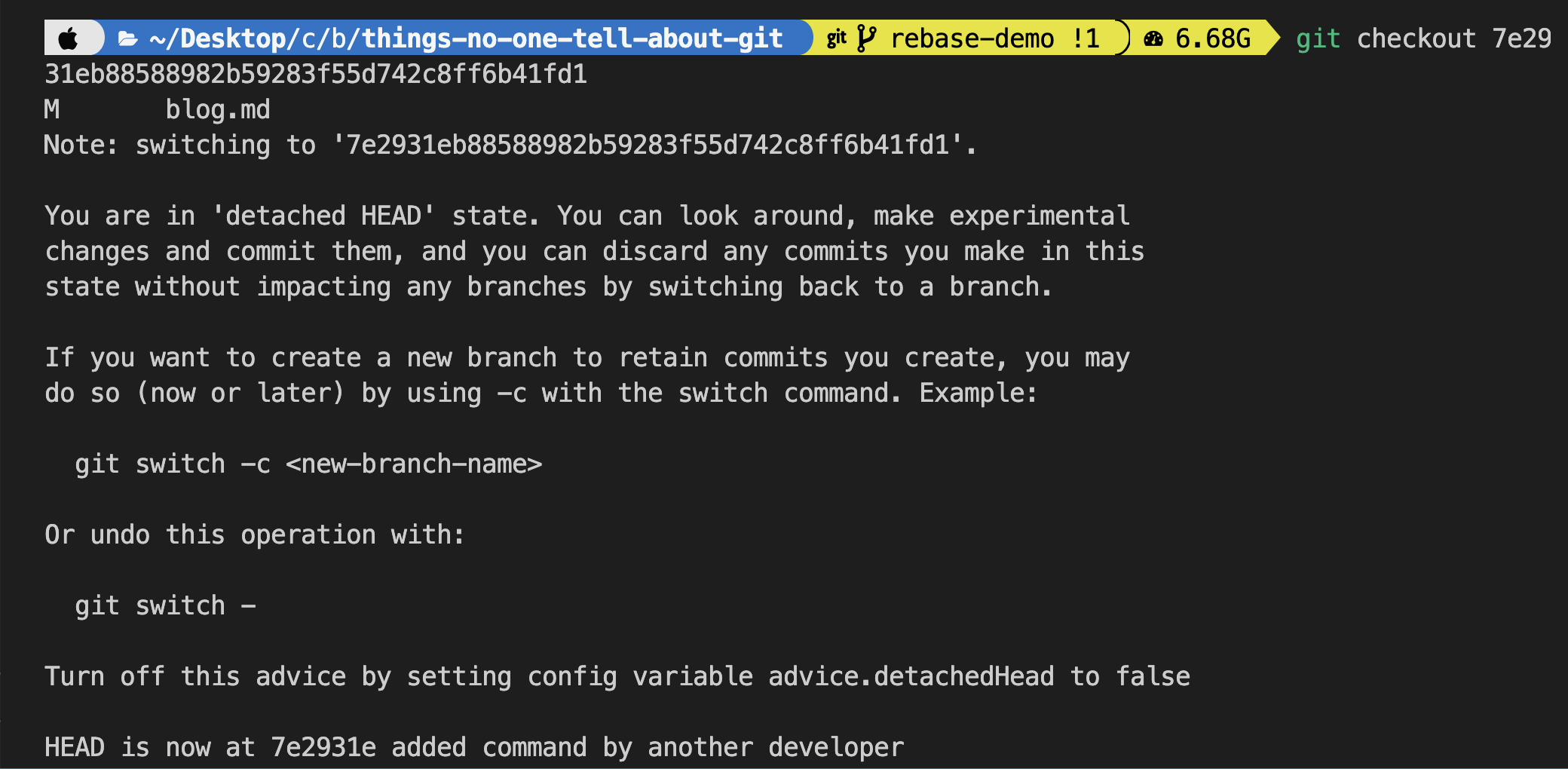
- We will be in a detached
HEAD stateand the prompts will also change. Here we can see line 10 which is the current state of remote is not in local. From this state, we can either create a new branch and replicate the bug and test it.
- We can return back to the current state by
git checkout
git checkout rebase-demo
3) Undo your commits
Scenario: There are so many ways to undo a commit, google pulls a lot of different posts on StackOverflow but which one to use for which case? Let's demystify this.
Solution: Either use reset, amend or revert commands.
Let's make some bad changes and try to fix them.
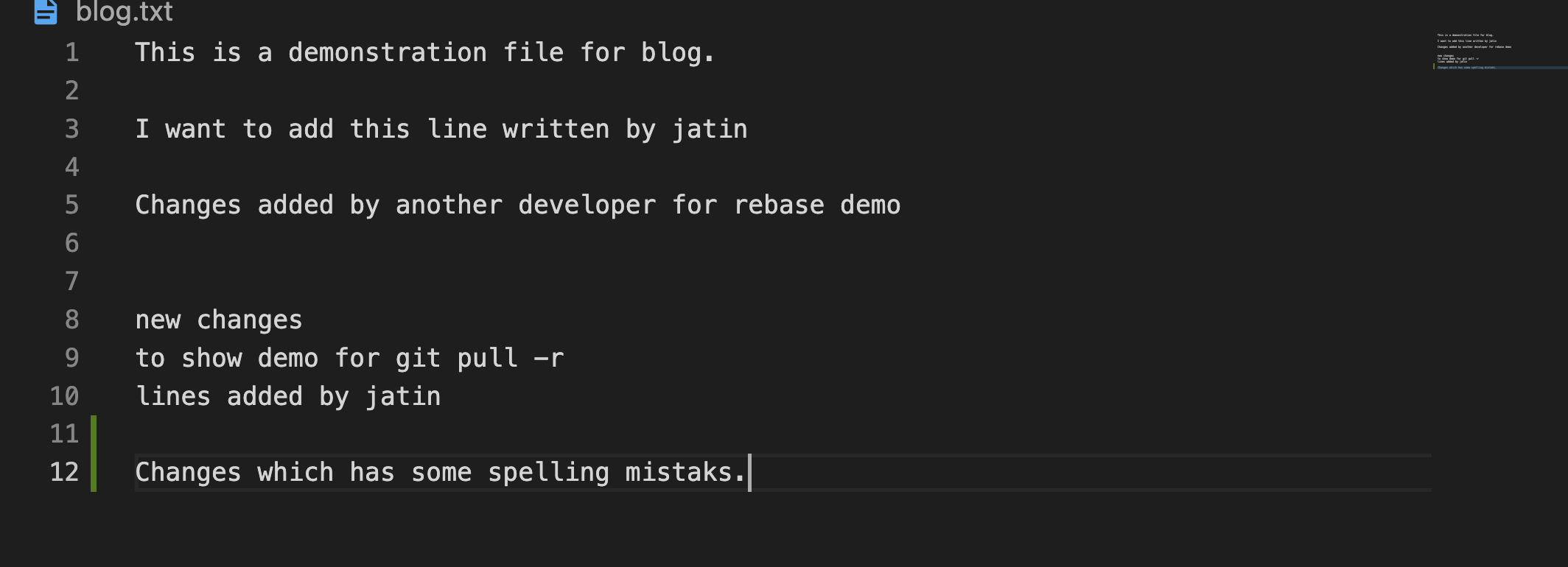
- There is a change on
line 12change and I want to revert that. - HEAD represents the pointer to the last commit. In order to revert it we specify
HEAD~nwhere n stands for the number of commits we want to revert.

git reset --hard HEAD~1
reset --hardnot only delete the changes but removes the commit from the commit history. line 13 will be deleted previous commit will become the current (HEAD will point to this), be very cautious with the --hard option as you can lose all your changes depending on the value ofn,
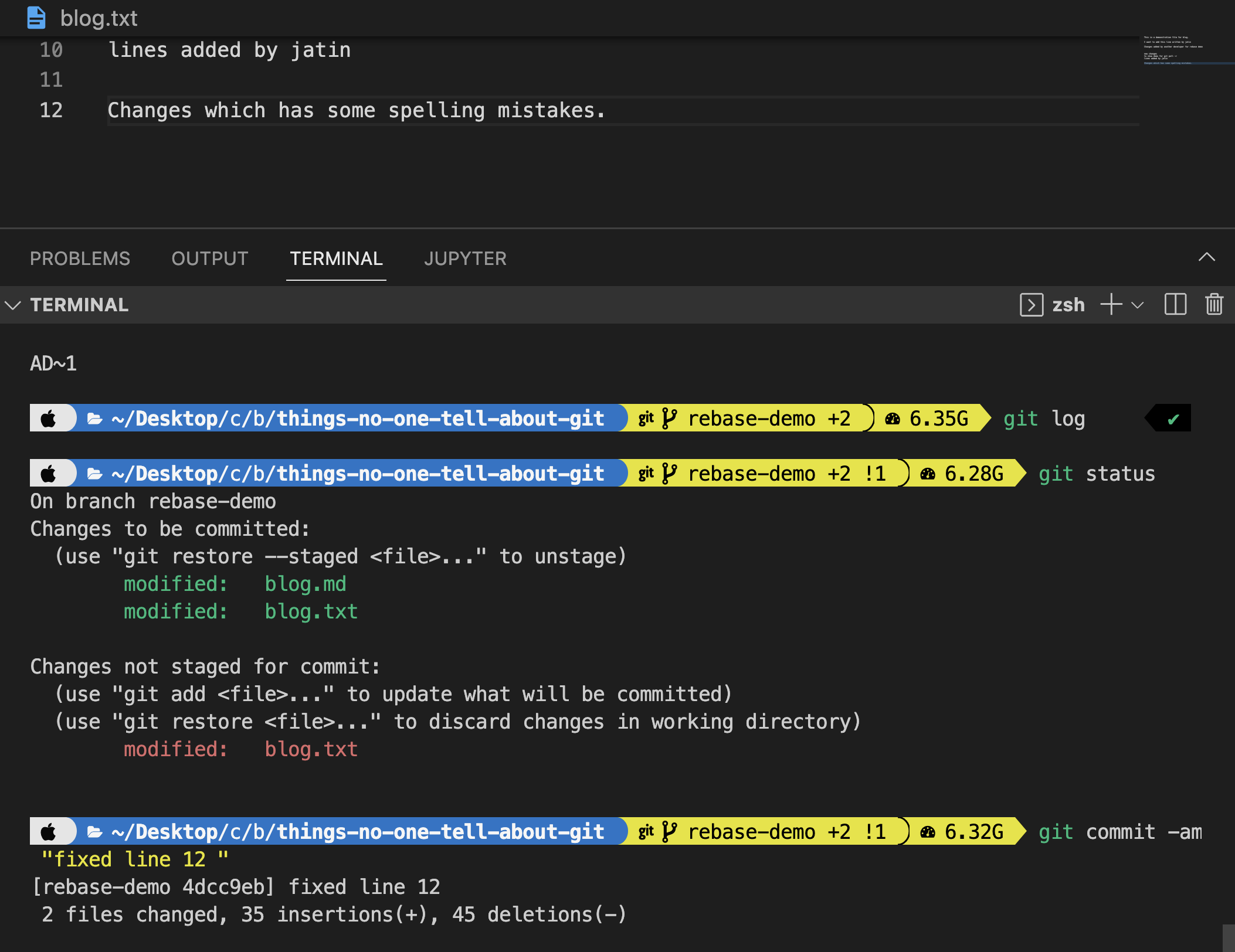
Scenario: Now I don't want to delete the changes, but instead fix them or change them, for such a use case
--softwill be used. Let's make some changes and fix them with the --soft option
- Here on line 12 there is a typo.
git reset --soft HEAD~1
Solution:-
reset --softsimply deletes the commit from the commit history and stage the commit which allows us to edit or fix them.
Scenario: There are some more changes which need to be done and they belong to the previous commit, instead of adding a new commit or doing git reset --soft and then committing again we can simply
amendthe commit.
- Let's delete line 12 and commit it.

- But now I want to also delete line 10, ideally, it belongs to the commit of the previous commit because I am doing the same operation of deleting the line.
Solution:- Just add them to the
staging areaand use theamendoption.
git commit --amend
- This will add line 10 deletion changes to the line 12 commit by confirmation to change the previous commit message or remain the same.

Scenario: Your changes are in remote and now you want to revert them in remote, use git revert which creates a commit in commit history to undo the previous commit. It uses a hash of the commit which is being reversed.
- Using
git logcopy the hash.
git revert 9e1c475e1b676b5af99245ba2bafa5d43a84bac9

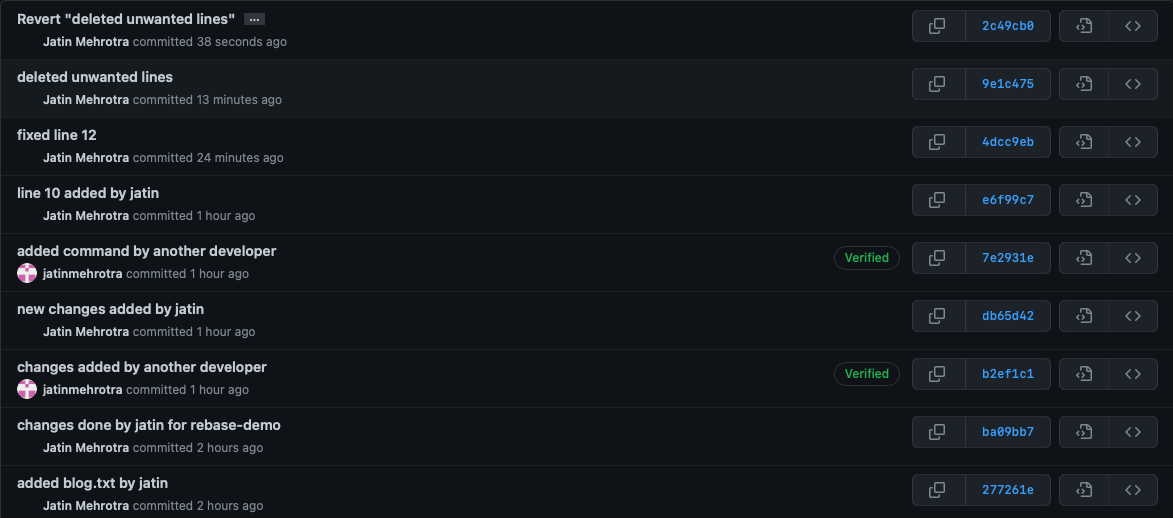
- This revert the deleted line and now lines 10 and 12 are back.
4) Remote file added to .gitignore is still being tracked by git
Scenario: There is a file which exists in remote and we want to remove it from being tracked in other words ignore it.
- Let's push a file to remote and later ignore it by adding it to the
.gitignorefile.
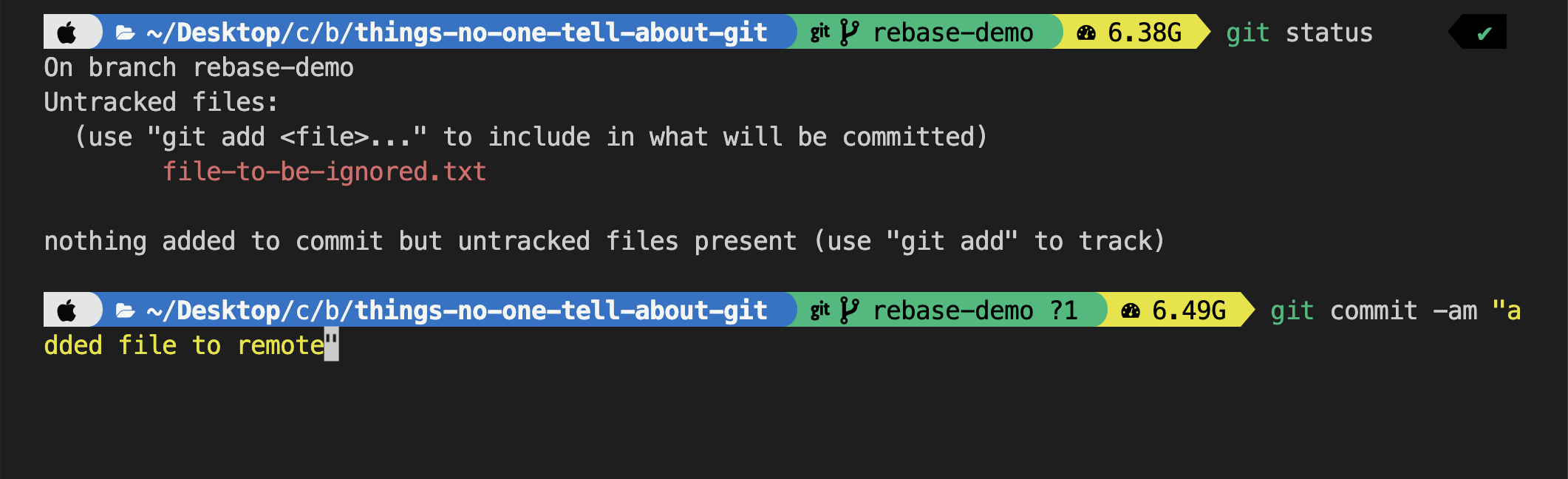
- change some content to
file-to-be-ignored.txt -
If we do
git status, we can still see the file being tracked even though it was added in the .gitignore file.

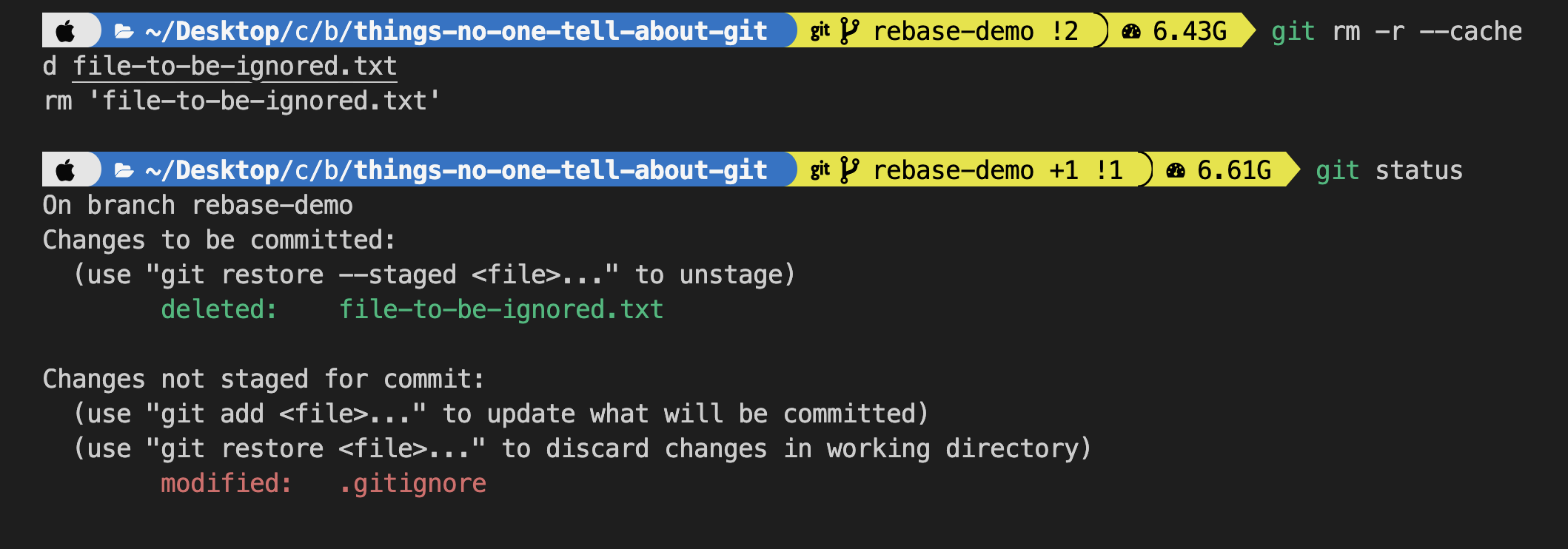
Solution:- Because it is already committed to remote, git is tracking it, so every change in the file will be tracked by git. To solve this remove it from cache.
git rm -r --cached file-to-be-ignored.txt
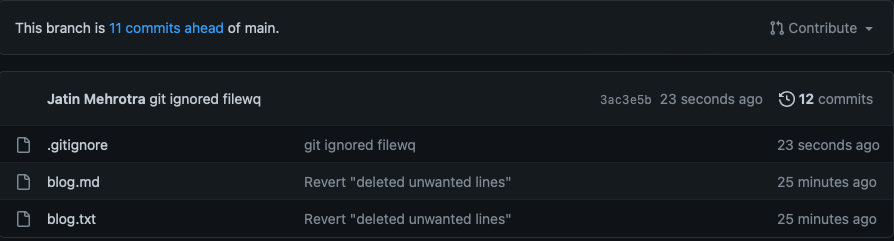
 - if we push our changes, we can see the file is removed from the remote.
- if we push our changes, we can see the file is removed from the remote.
From DevOps Perspective
- When would we need it for our DevOps tasks?
-
For Infrastructure as Code:- There will be many configuration files related to Kubernetes, terraform, and shell scripts which need to be tracked in order to know what has been changed over time and for collaboration with developers in secure. central storage.
- For CI/CD pipeline and build automation:- Usually for pipeline we need to check out the code, test and build an application that requires knowledge of git commands usually build an automation tool that requires integration with the git repository and knowing git is essential.
Till then, Happy Learning!







