n8nのAIエージェントにおいてCloud StorageからJSONを読み込むツールがエラーになるのをなんとかしたい
BigQueryのデータをn8nのAIエージェントを使って自然言語からクエリを組み立てて結果を返す という実験をしようとしていたのですが、スキーマの情報などをエージェントに与えるためにJSONファイルに保存したスキーマ情報を読み取らせる仕組みをにしていました。
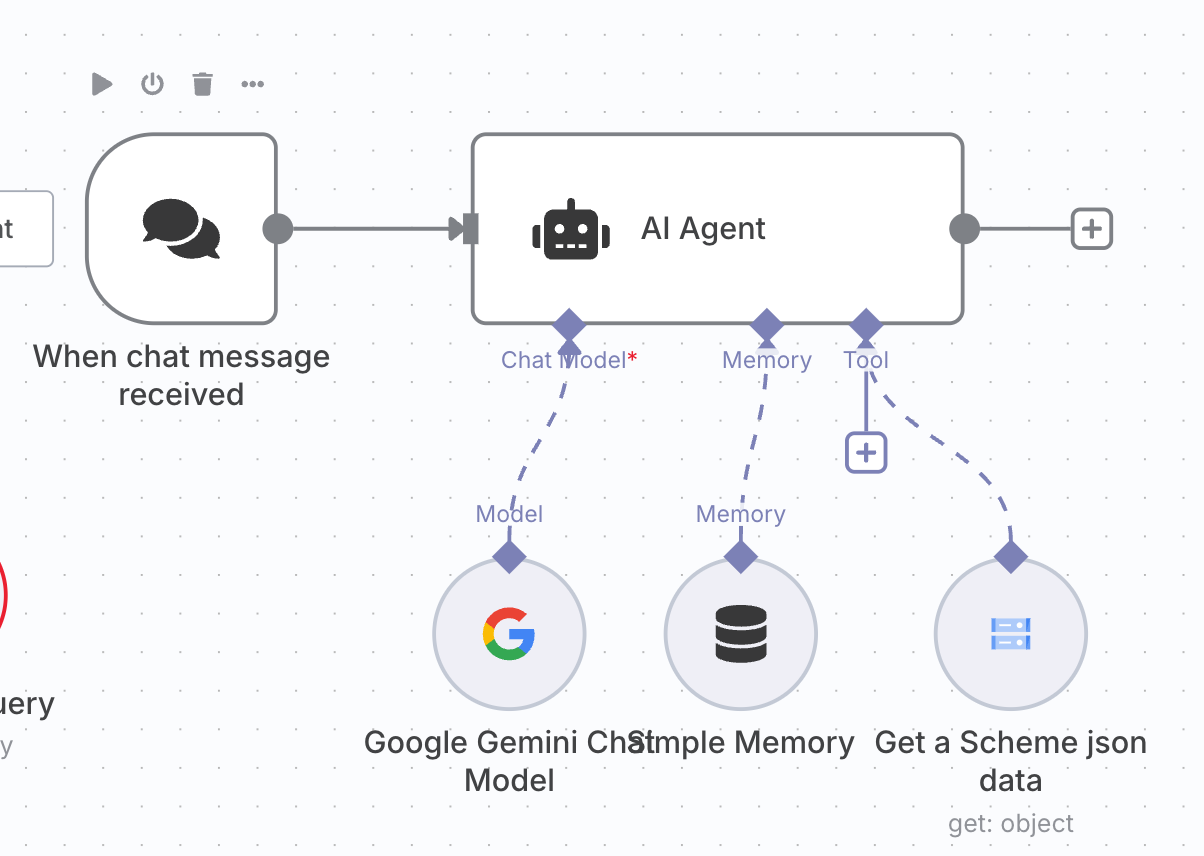
上記の画像のようにGoogle Cloud Storage Tool というノードを使い、JSONデータを取得しようとしました。
ですが、このノードを実行してみると、
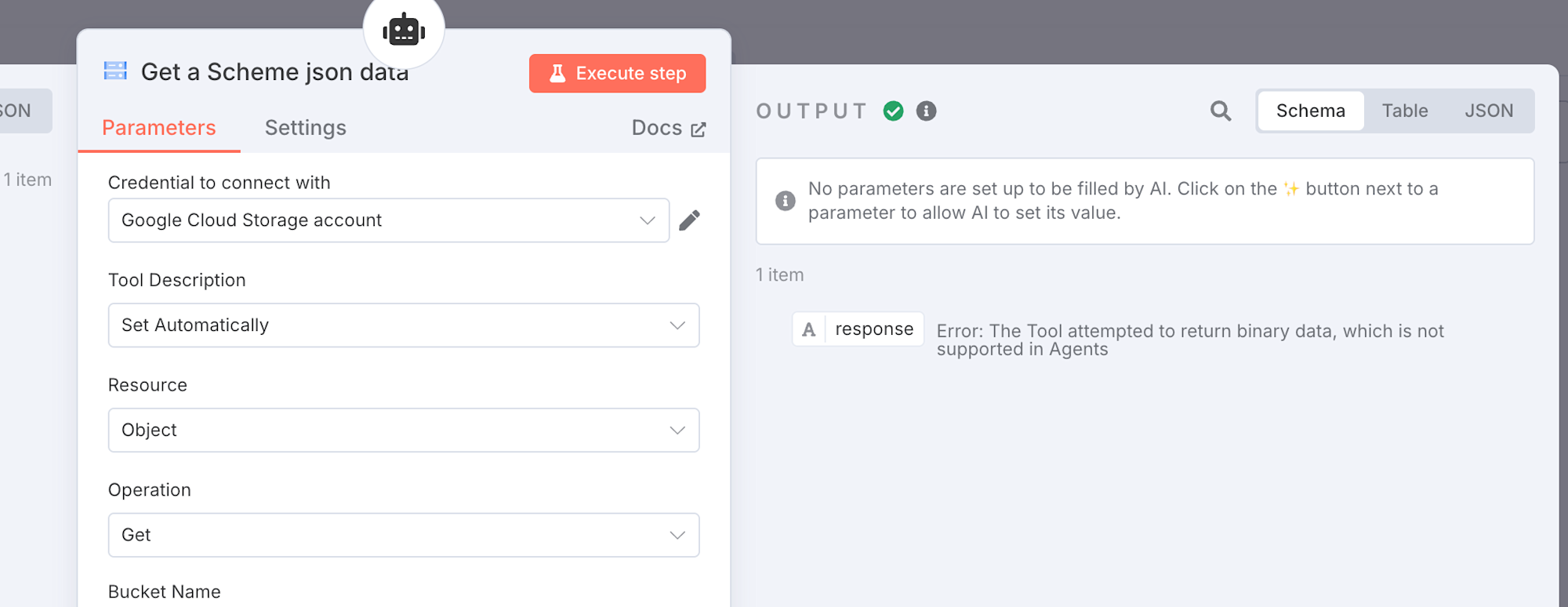
The Tool attempted to return binary data, which is not supported in Agents というエラーになっています。
期待していたJSONのデータは返ってきませんでした。
AIエージェントのツールではなく、Google Cloud Storageの単体ノードではこのようなエラーにはならず、
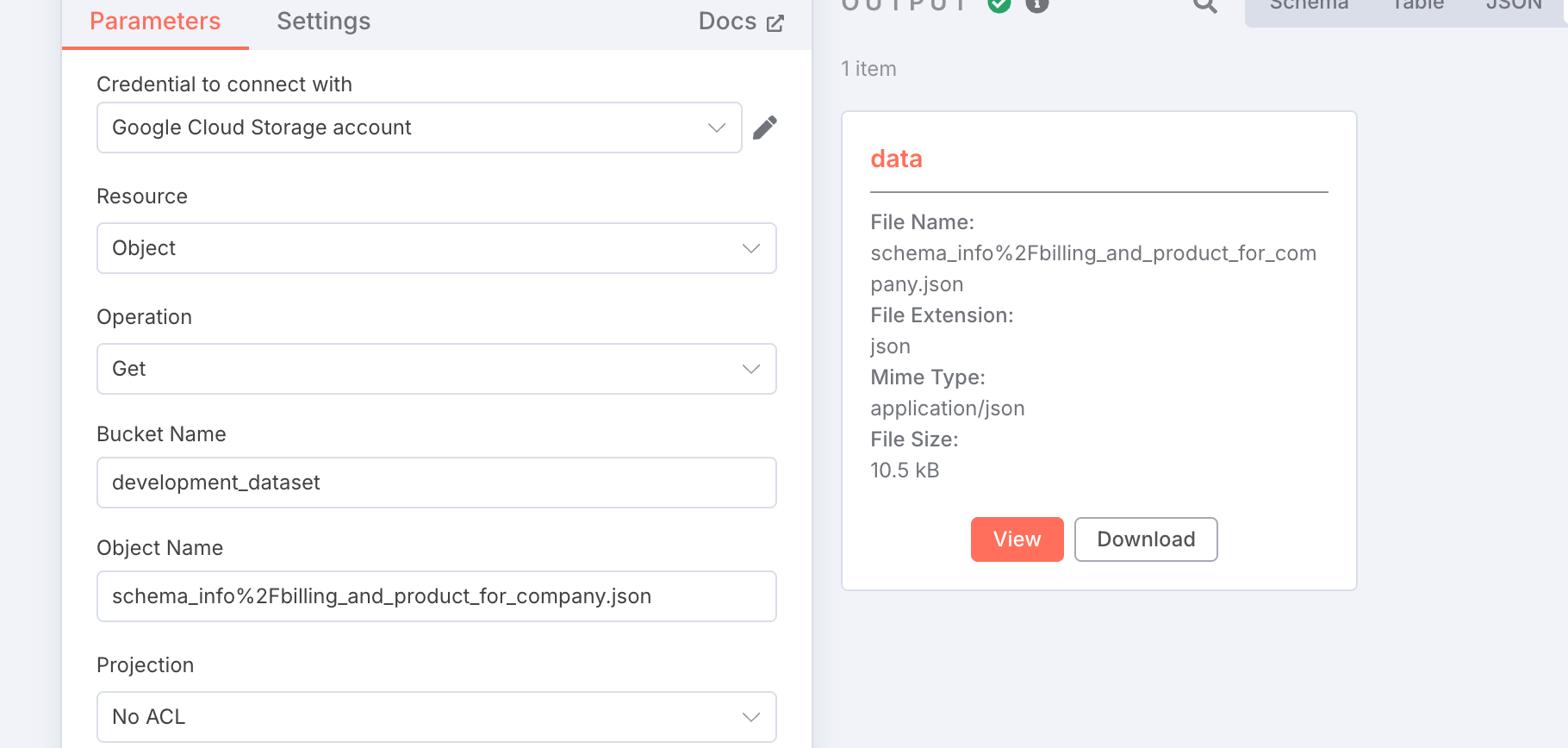
このようにデータが返ってきています。
エラーの原因とツールの動き
The Tool attempted to return binary data, which is not supported in Agents ですが、これは
ツールが直接バイナリデータを返そうとしているために発生しています。
n8nのAIエージェントのツールは以下のような流れで動作します。
- エージェントがツールを呼び出す決定をする: ユーザーのプロンプトに基づいて、AIモデルが特定のツール(関数)を呼び出すべきだと判断します。
- ツールが実行される: n8nワークフロー内のツールとして設定された部分が実行されます。この部分がCloud StorageからのJSONファイル読み込み処理を担当します。
- ツールが結果を返す: ツールは処理結果をAIエージェントに返します。この時、返されるデータはテキストである必要があります。
- エージェントが結果を受け取り、次の行動を決定する: AIモデルがツールの結果をプロンプトとして受け取り、次の応答や行動を生成します
体験した現象ですが、3つ目のテキストベースの情報を返すことを想定している箇所でのエラーとなってしまっているようでした。
ツールとして実行する場合の回避方法
正常に動かすには、
JSONファイルの中身をテキスト文字列として読み込み、それをツールからの戻り値として返す必要があります。
別のワークフロー作成
方法の一つとして考えられるのが、
Cloud StorageからJSONを読み込む独立したワークフローを作成し、それをAIエージェントのツールとして公開 することです。
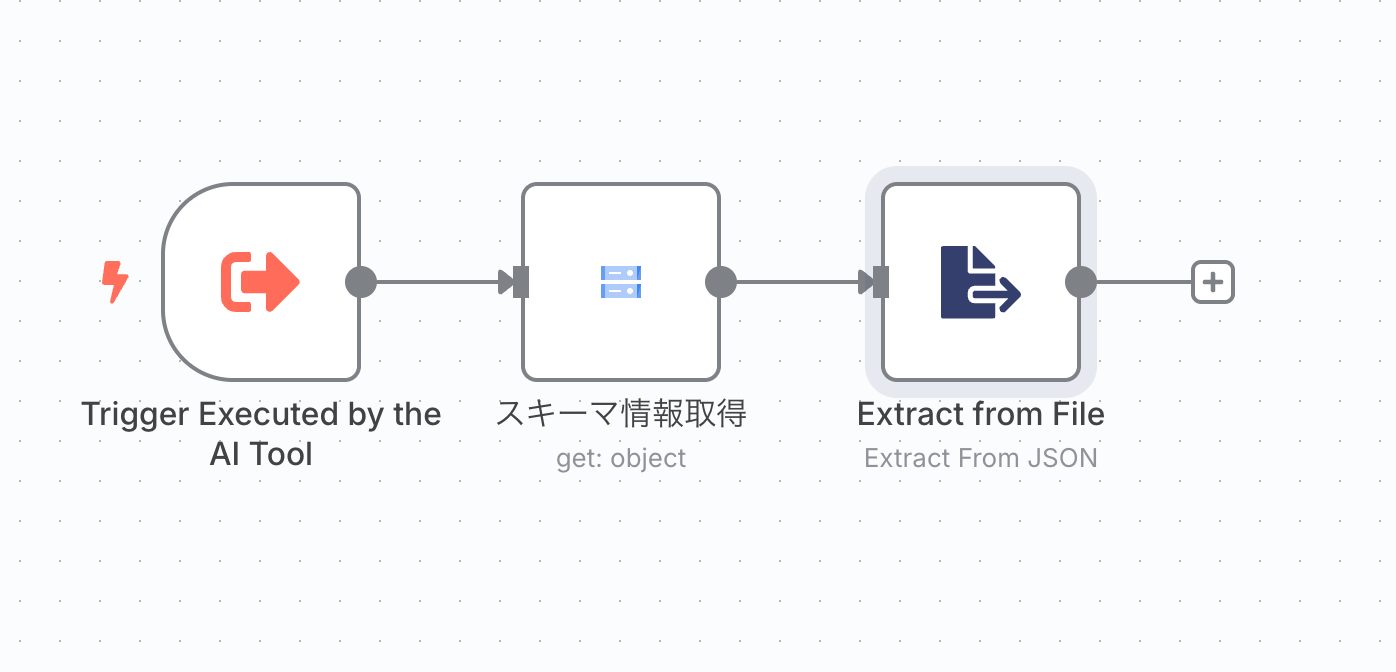
- 別のワークフローから実行するトリガー
- このノードがツールの開始点になります。エージェントがこのトリガーノードを呼び出します。
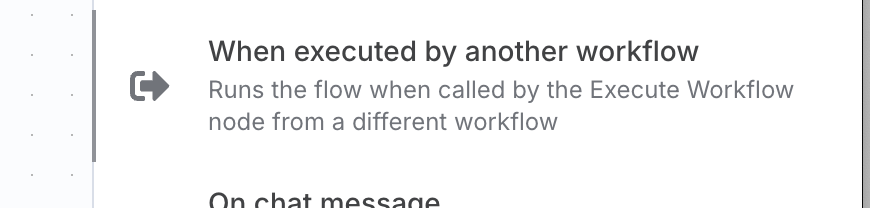
- このノードがツールの開始点になります。エージェントがこのトリガーノードを呼び出します。
- Google Cloud Storage ノード
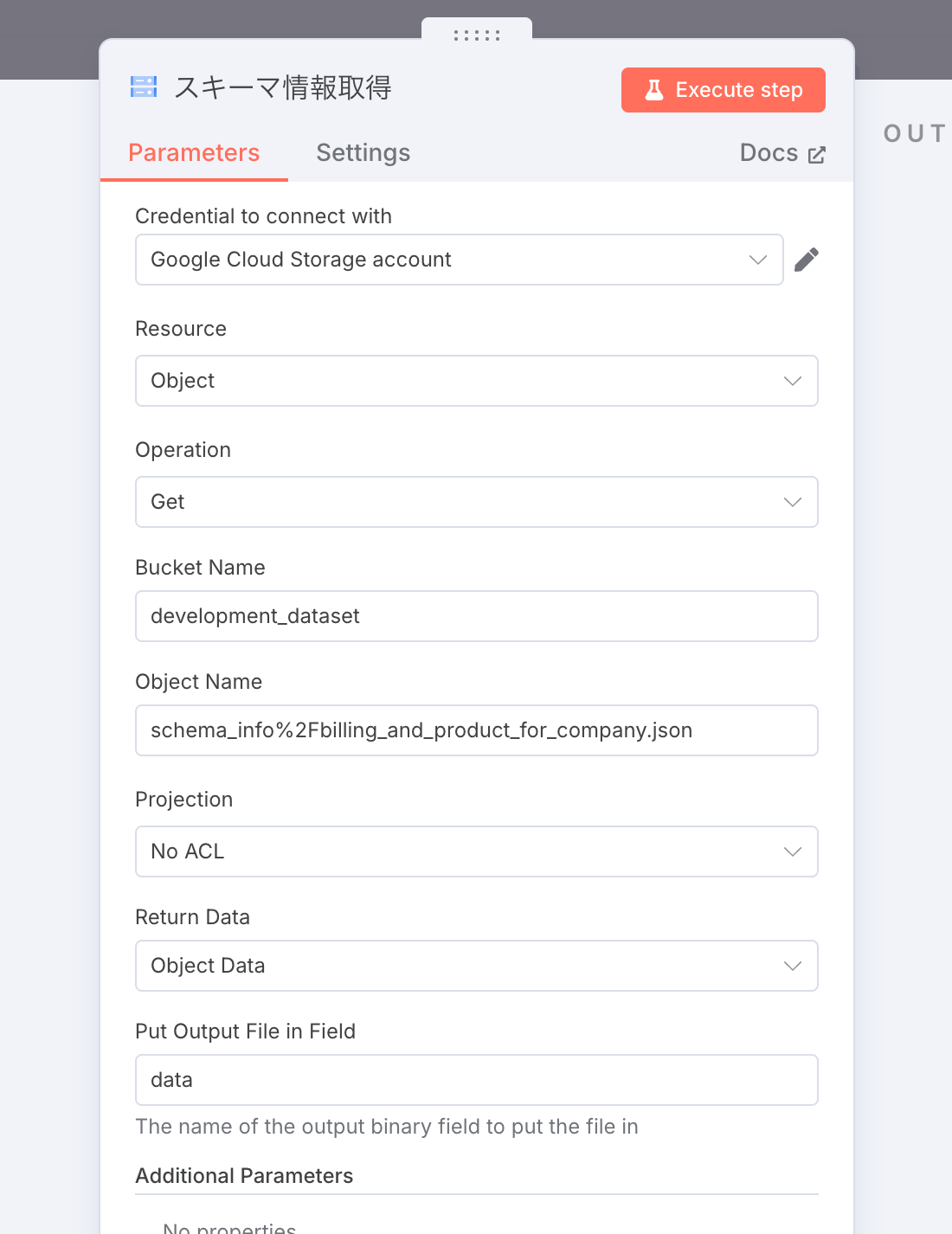
- 認証情報、バケット名,オブジェクト名を通常通り設定します
- Return Data を
Object Dataに設定します。
- Extract From File(JSON) ノード
- 前のGoogle Cloud Storageノードがバイナリデータを返すため、それをテキストに変換できるノードを設置します。
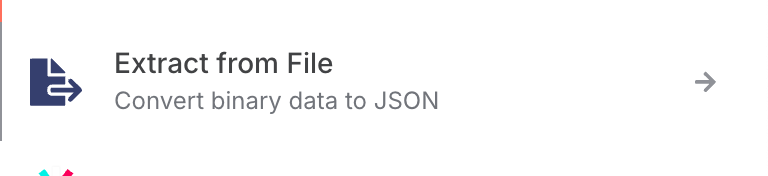
- Input Binary Field 、Destination Output Fieldを
dataに設定します。 - ステップを実行すると、JSONの中身がOUTPUTに表示されるはずです。
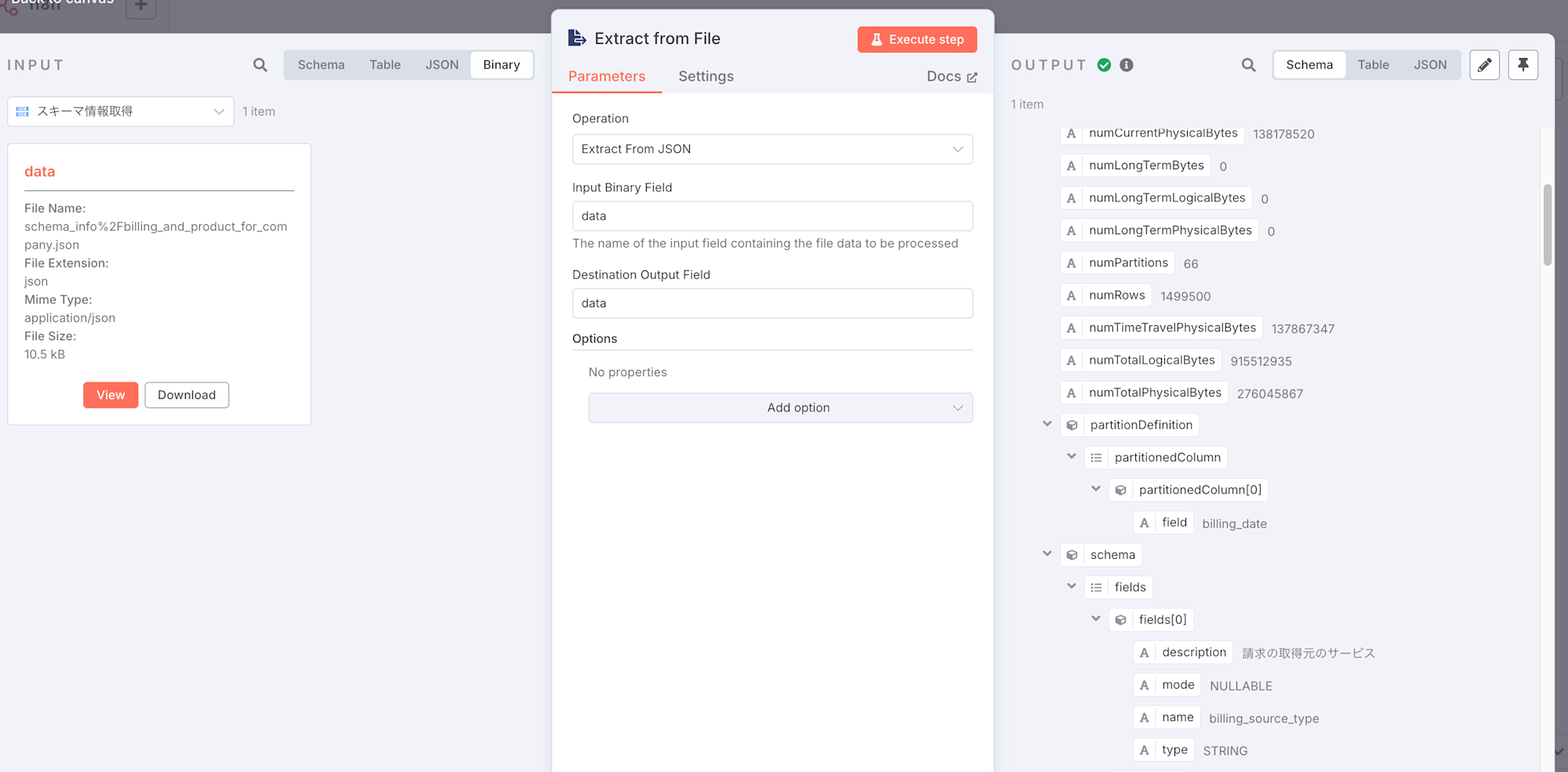
- 前のGoogle Cloud Storageノードがバイナリデータを返すため、それをテキストに変換できるノードを設置します。
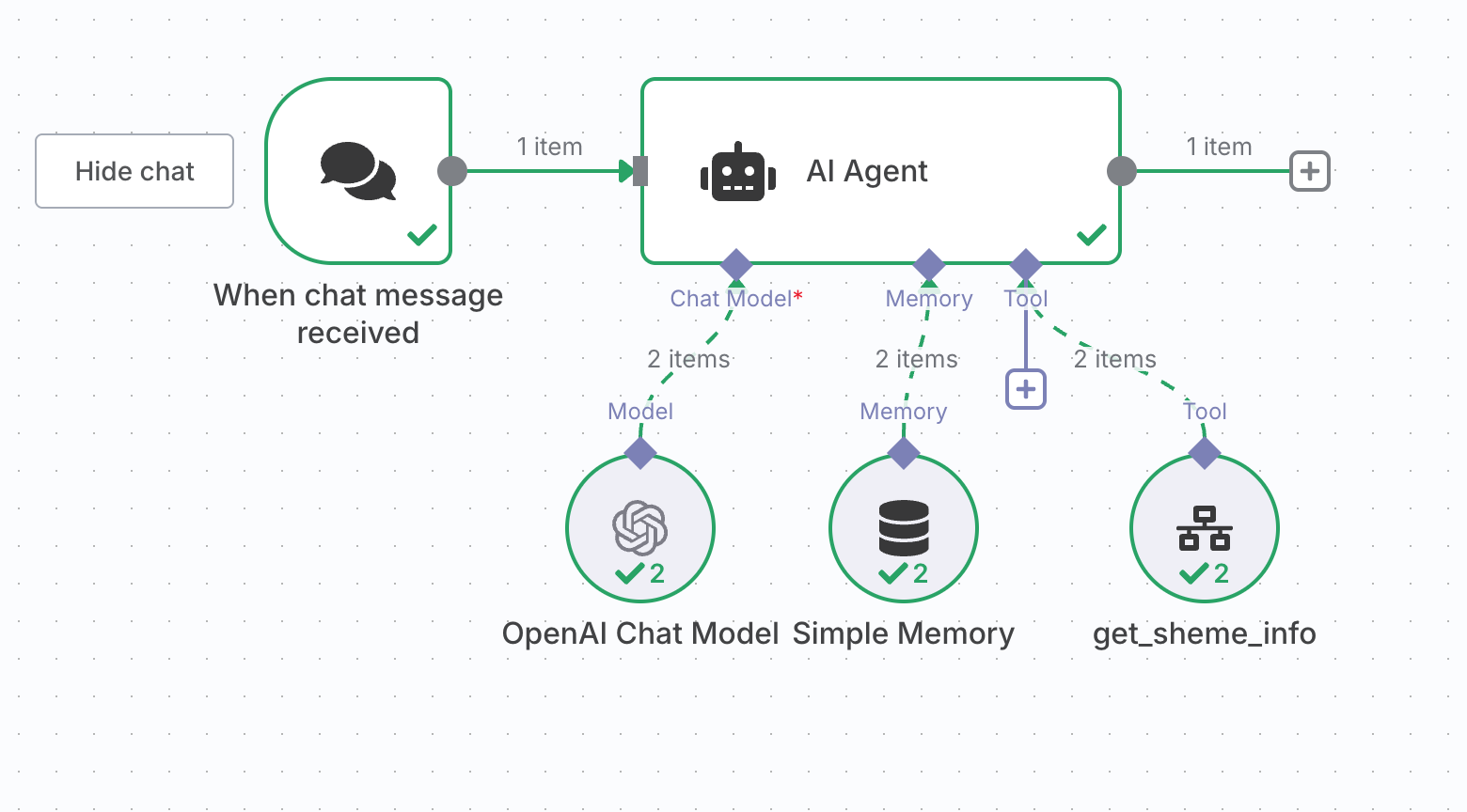
AIエージェント(OpenAI Chat Modelなど)の設定
AIエージェントノード内で、上記のワークフローをツールとして定義します。
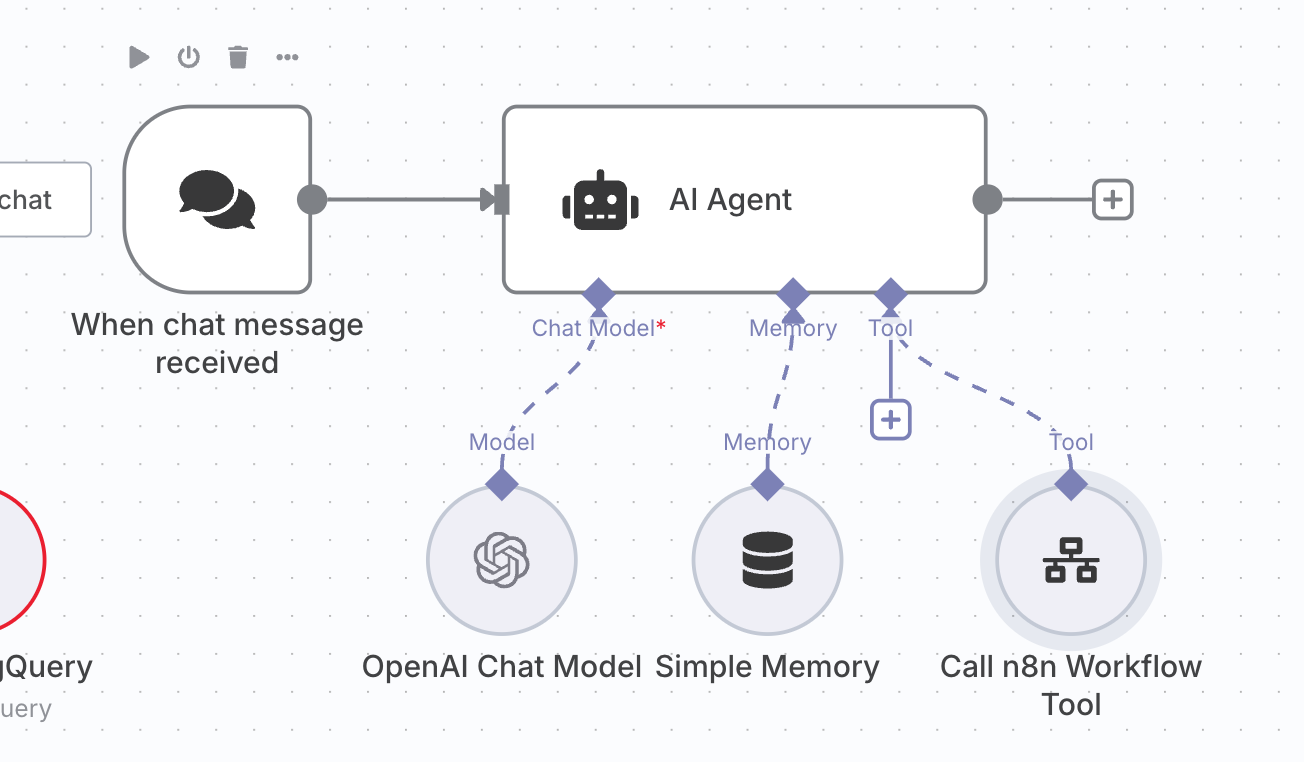
- AIエージェントノード
- Chat Modelの設定
- Model を gpt-3.5-turbo や gpt-4-turbo など、Function Callingをサポートするモデルに設定します。
- Memoryの設定
- コンテキストを永続化できるMemoryを設定します。なくても構いません。
- Toolの設定
- 上記で作成したワークフローを呼び出せる
Call n8n Workflow Toolノードを追加します。 - Sourceを
Databaseにし、Workflowを作成したものから選びましょう
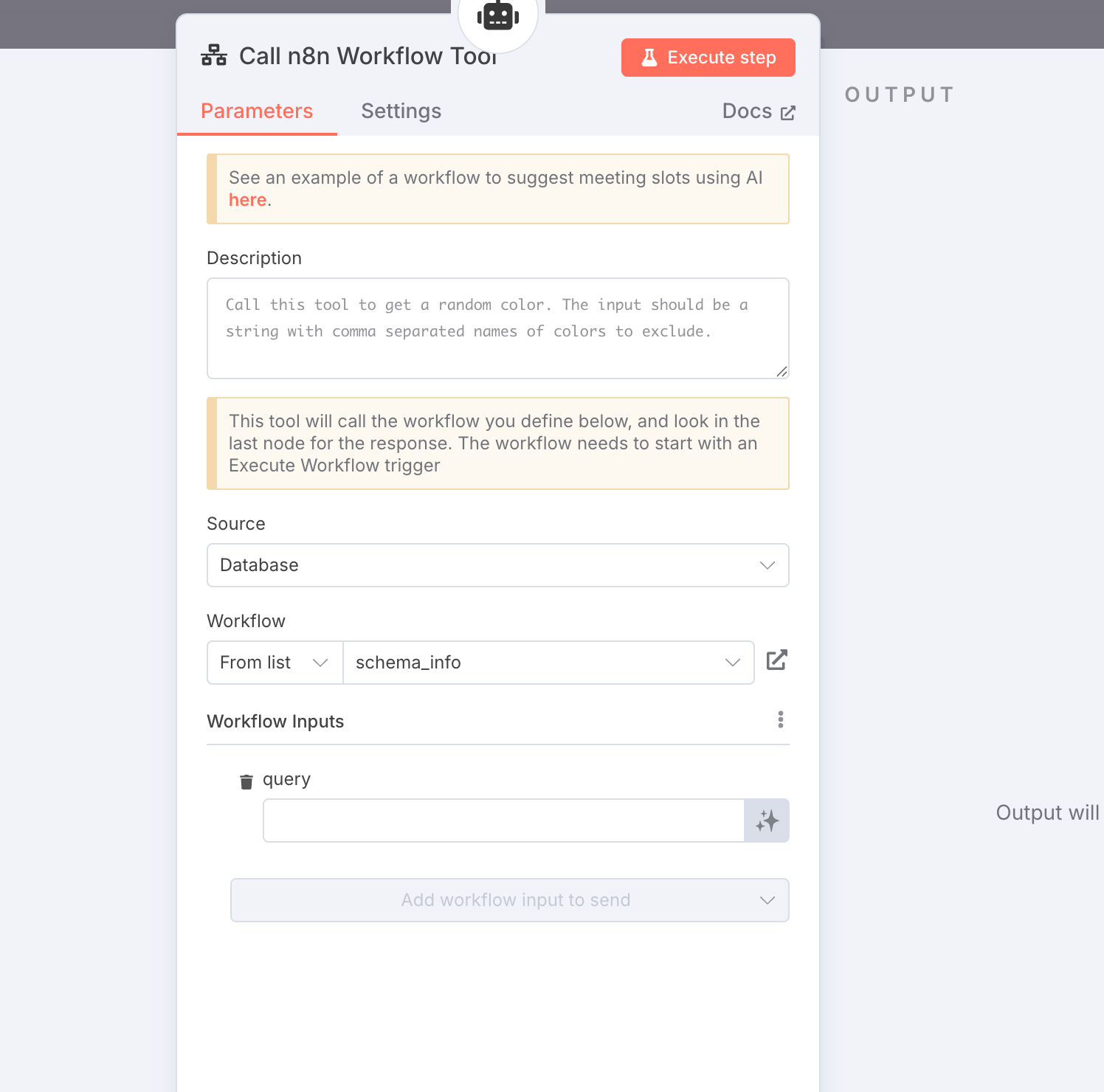
- 上記で作成したワークフローを呼び出せる
- Chat Modelの設定
AIエージェントノードのオプション設定で、システムメッセージを定義しておきます。
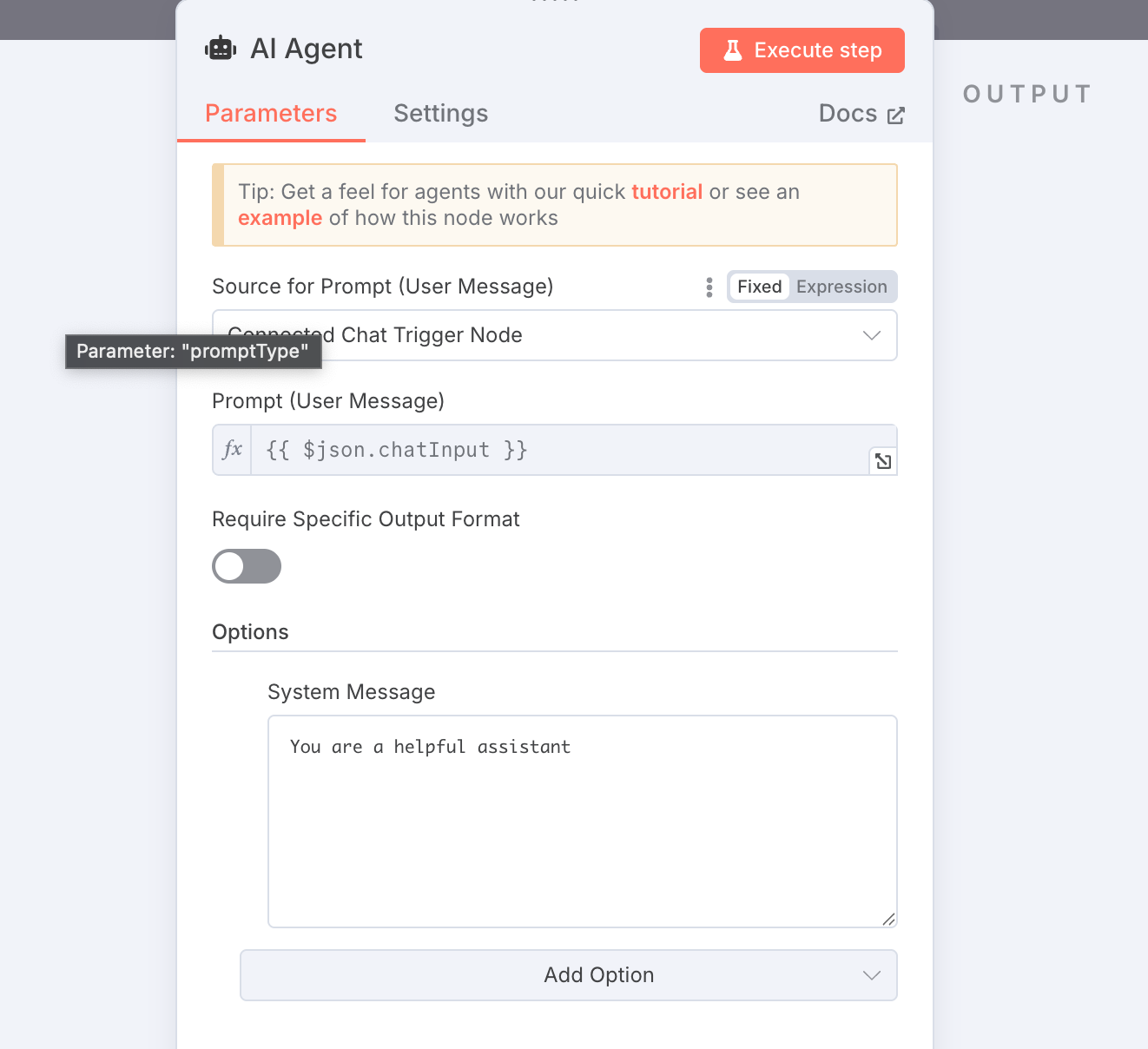
エージェントの振る舞いや回答の質を向上させるため、AIモデルがそのセッションでどのような役割を果たすべきか、どのような制約があるか、どのような情報を持っているかなどを事前に伝えておきます。
今回は以下の内容を定義しておきました。
あなたはBigQueryのデータに関する質問に答えるAIアシスタントです。
ユーザーのデータ分析を支援するために、BigQueryのスキーマ情報を提供したり、クエリのヒントを提案したりします。
## ツールの説明
- あなたは get_scheme_info というツールを使用できます。このツールは、Cloud Storageに保存されたBigQueryのテーブルスキーマJSONファイルの内容を取得します。
- ツールを呼び出す際は、ユーザーの質問に関連するスキーマファイルを特定し、そのファイルパスを正確に指定してください。
## BigQueryスキーマ情報
- ツールで取得したスキーマ情報は、BigQueryテーブルのカラム名、データ型、および説明を含んでいます。ユーザーの質問に対して、これらの情報をもとに正確な回答を提供してください
- 特に指定がない限り、BigQueryの標準SQL構文に則った説明やクエリのヒントを提供してください
- スキーマ情報がないテーブルやカラムについては、『情報が見つかりませんでした』などと明確に伝えてください
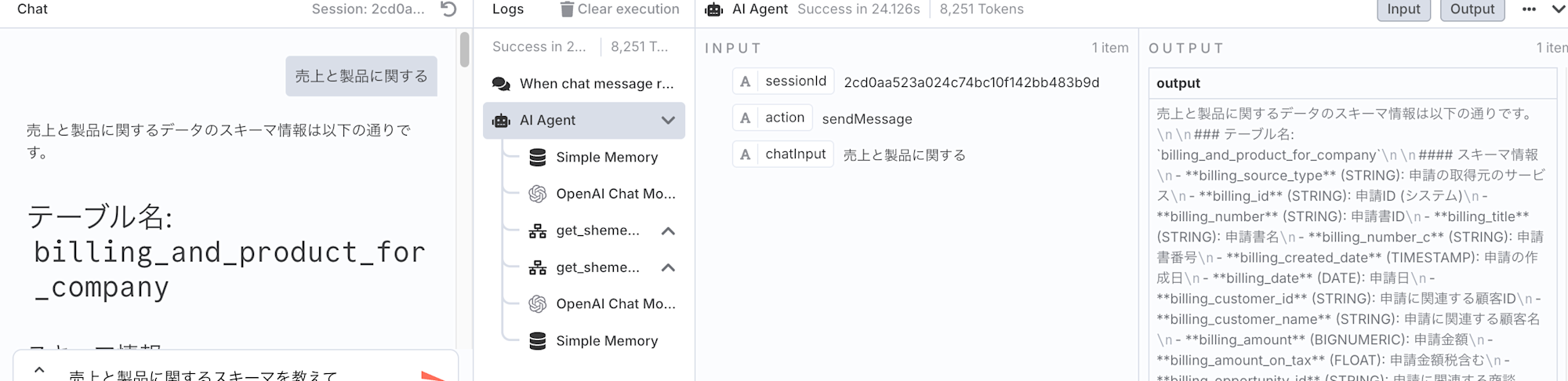
実行してみる
n8nのワークフロー設定画面で実行してみます。
仕組み
- ユーザーが「売上と製品に関するデータのスキーマを教えて」とプロンプトを与えます。
- AIエージェント(OpenAIモデル)は、その情報がCloud Storageにあることを理解し、get_scheme_info を呼び出すべきだと判断します。
- AIエージェントは、get_scheme_info ツールを呼び出します。
- n8nのTrigger Executed by the AI Toolノードがその呼び出しを受け取ります。
- Trigger Executed by the AI Toolノード以降のワークフローが実行され、Cloud StorageからJSONファイルの内容を読み込み、テキストに変換し、JSONとしてパースします。
- AIエージェントはこのレスポンス(テキスト形式のJSONオブジェクト)をツールの結果として受け取り、その情報に基づいてユーザーに応答を生成します。
この構成にすることで、「Tool attempted to return binary data」のエラーを回避し、AIエージェントがCloud StorageのJSONスキーマ情報を適切に利用できるようになりました。