
LangGraphで AIエージェントをまなんでいく - その5 エージェントのメモリ-
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
エージェントのメモリは、以下のような目的で利用されます:
- 文脈の保持:エージェントが連続するタスクや会話の流れを理解し、適切に応答するため。
- 学習と進化:過去の経験や対話を記憶して、それに基づいて将来の応答や行動を改善する。
以前作成したエージェント※1ですが、
※1 参考

最初の入力では内容を理解してツールを呼び出し、返答してくれますが、
その結果をさらに使用したいとなった場合はきちんと返答できていません。
これをやりたい場合、エージェントにメモリを追加してあげないといけません。
メモリの種類
エージェントのメモリには主に以下の2種類があります:
1. 短期メモリ (Short-term memory)
- 目的:
現在の対話やタスクの中で発生した情報を保持します。 - 特徴:
シーケンス内の前のステップで得た情報にアクセス可能。 - 例:
現在の会話中に出てきた情報を記憶する。 - ユースケース:
1つの会話中で、直前のユーザー入力に応じて適切に応答する。
2. 長期メモリ (Long-term memory)
- 目的:
以前の対話やタスクから得た情報を保持します。 - 特徴:
エージェントが長期間にわたって情報を記憶する。 - 例:
ユーザーの名前や過去の質問の履歴を覚える。 - ユースケース:
リピーター顧客とのやり取りで、過去の購入履歴や問い合わせ内容に基づいて対応する。
LangGraphにおけるメモリ管理
LangGraphでは、エージェントのメモリ管理を柔軟に設計できる仕組みが提供されています。
1. State(状態)
メモリに保持する情報の構造をユーザーが定義します。
ポイント:
必要な情報だけを保持するための「スキーマ」を作成。
エージェントのニーズに合わせて、記憶の内容や形式をカスタマイズ可能。
例:ユーザーの名前、過去の会話の要約、タスクの進行状況など。
ドキュメントに載っているサンプルを実行して確認してみます。
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict
class InputState(TypedDict):
user_input: str
class OutputState(TypedDict):
graph_output: str
class OverallState(TypedDict):
foo: str
user_input: str
graph_output: str
class PrivateState(TypedDict):
bar: str
def node_1(state: InputState) -> OverallState:
# Write to OverallState
return {"foo": state["user_input"] + " name"}
def node_2(state: OverallState) -> PrivateState:
# Read from OverallState, write to PrivateState
return {"bar": state["foo"] + " is"}
def node_3(state: PrivateState) -> OutputState:
# Read from PrivateState, write to OutputState
return {"graph_output": state["bar"] + " Lance"}
builder = StateGraph(OverallState,input=InputState,output=OutputState)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_2", "node_3")
builder.add_edge("node_3", END)
graph = builder.compile()
graph.invoke({"user_input":"My"})
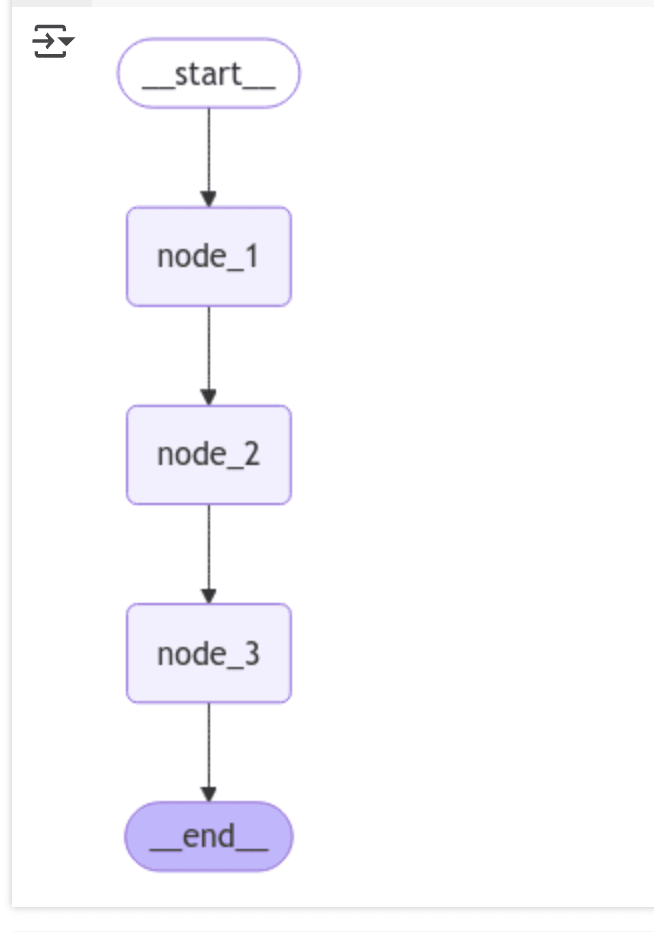
LangGraphを使った状態管理型のグラフで、3つのノード(node_1, node_2, node_3)がデータを順次処理していくワークフローを構築しています。
それぞれのノードが異なるスコープの状態 (InputState, OverallState, PrivateState, OutputState) を読み書きするようになっています。
処理の流れ
- 入力:
- ユーザーからの入力:{"user_input": "My"}
- ノードの処理:
- node_1: "My" → "My name"(OverallStateのfooに保存)。
- node_2: "My name" → "My name is"(PrivateStateのbarに保存)。
- node_3: "My name is" → "My name is Lance"(OutputStateのgraph_outputに保存)。
- 出力:
- 最終的な出力:{"graph_output": "My name is Lance"}
ノード間で異なるStateに保存し、保存された結果を返しています。
2. Checkpointers(チェックポイント機能)
各ステップで状態を保存する仕組み。
- ポイント:
- 対話やタスクが進むごとにメモリを保存し、後で参照可能。
エージェントが複数の対話やステップ間の文脈を維持するのに役立つ。
Stateが1回のグラフ実行に対して一時的なものに対して、Checkpointersは各ステップの後にグラフの状態を永続化して保存できます。
では、実際に実装して試していきたいと思います。
最も簡単に使えるCheckpointersの一つはMemorySaverで、これはグラフの状態のためのメモリ内キー・バリュー・ストアです。
[langchain-academy]{https://github.com/langchain-ai/langchain-academy/blob/main/module-1/agent-memory.ipynb} のコードを使います。
メモリを使用しなかった場合は、前述で示していたとおりグラフの実行でメッセージの内容は消えていました。
MemorySaverは以下のコードで有効にできます。
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
react_graph_memory = builder.compile(checkpointer=memory)
メモリを使うときは、スレッドIDというのを指定します。
# Specify a thread
config = {"configurable": {"thread_id": "1"}}
# Specify an input
messages = [HumanMessage(content="Add 3 and 4.")]
# Run
messages = react_graph_memory.invoke({"messages": messages},config)
for m in messages['messages']:
m.pretty_print()

ここで使用したスレッドIDを使ってグラフを実行することで、以前の状態から処理を継続できるようになります。
messages = [HumanMessage(content="Multiply that by 2.")]
messages = react_graph_memory.invoke({"messages": messages}, config)
for m in messages['messages']:
m.pretty_print()

この通り、最初のグラフ実行時の結果を使用して、2回目の実行の答えを返してくれました(14が返ってくることを期待している)
メモリへの保存は、プロセスが終了したときに保存したものが消えてしましますので、開発中のテストやデバッグ、状態を一時的に保存するキャッシュに利用することに向いているとされています。
プロセス終了後も残したいと言った場合は、SQLite(ローカルでの永続化が必要な場合)やPostgreSQL(本番環境や大規模なデータ管理)をバックエンドに使用したチェックポイント機能のライブラリがあるので、それを使うことが適しています。







