![[レポート] Data preparation authoring with AWS Glue Studioに参加しました #AWSreInvent #ANT320](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート] Data preparation authoring with AWS Glue Studioに参加しました #AWSreInvent #ANT320
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
データ事業本部のkobayashiです。ラスベガスで開催されていたre:Invent2024に現地参加しました。
本記事は AWS re:Invent 2024 のセッション「ANT320 | Data preparation authoring with AWS Glue Studio」のセッションレポートです。
このセッションは、AWS Glue StudioのノーコードビジュアルETL機能について、実践的なデモを交えながら解説が行われました。 注目すべき点として100以上のデータコネクタによる様々なデータソースとの連携、250以上の事前定義された変換機能、そしてSparkベースのサーバーレスアーキテクチャが紹介されました。
デモでは、Salesforceとの接続、データの変換・クリーニング、データ検証の3つの主要機能が紹介されました。
最近追加された機能として、Amazon Q統合によるETLスクリプト生成、アップグレードアシスタント、デバッグ支援機能なども紹介され、より使いやすくなった点も紹介されました。
またChalk Talkセッションなので後半では参加者からの質問を元に質疑応答が行われました。
セッションの概要
タイトル
ANT320 | Data preparation authoring with AWS Glue Studio
概要
This chalk talk covers the new no-code data preparation user experience for business users, data engineers, and data analysts with AWS Glue Studio Visual ETL. With the help of demonstrations, examples and interactive discussions, it dives into the intricacies of visually cleaning, transforming, and preparing data for analytics and machine learning. Additionally, it explores visual flow-based views to define connections to the data and set the ordering of the data flow process. Join this talk to learn how you can prepare data at scale without the need to write any code.
- Level: 300
- Session Type: Chalk talk
スピーカー
- Deen Prasad, Sr Solution Architect, AWS
- Julie Zhao, Sr Technical Product Manager, AWS
内容
はじめにアジェンダです。
- Data integration challenges
- AWS Glue overview
- AWS Glue Stuio demo
- Q&A

Data integration challenges
現代のデータ統合には主に6つの重要な課題があります。
- データが指数関数的に増加し続けていること(Growing exponentially)
- データエンジニア、データアナリスト、データサイエンティスト、ビジネスアナリストなど、多様なペルソナによってデータが消費されていること(Consumed by diverse persona)
- 従来のデータ統合ツールの限界(Traditional data integration tools)
- 新技術に関する技術的な複雑さ(Technical complexity of new technologies)
- 変革的なソリューションの提供(Deliver transformative solutions)
- データ品質の課題(Data quality challenges)
これらの課題に対して、インサイトを得るためにはデータの整理、処理、クリーニングが必要であり、下流の分析やAIアプリケーションに適したデータ準備が不可欠となっています。

AWS Glue overview
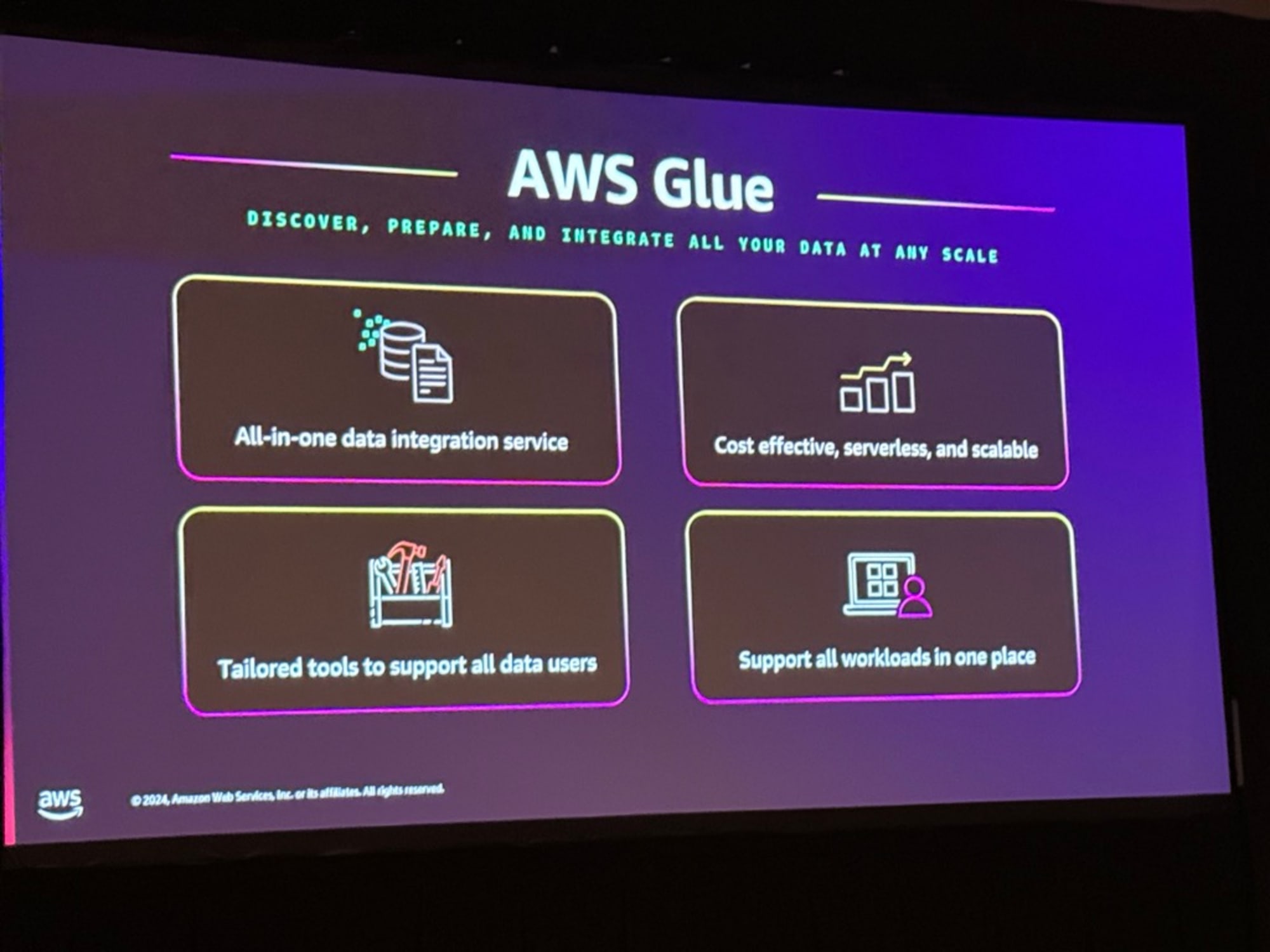
AWS Glueは「あらゆる規模でデータの発見、準備、統合を行う」ことをミッションとする統合サービスで、4つの主要な特徴を持っています。
- オールインワンのデータ統合サービス(All-in-one data integration service)として、100以上のデータコネクタやメタデータクローラー、データカタログなどの機能を提供しています。
- コスト効率の高いサーバーレスで拡張可能なアーキテクチャ(Cost effective, serverless, and scalable)を採用しており、使用時のみ課金されるため運用コストを削減できます。
- すべてのデータユーザーをサポートするためのツール(Tailored tools to support all data users)として、データエンジニア、アナリスト、サイエンティストなど、様々なユーザーに対応したインターフェースを提供します。
- すべてのワークロードを一箇所でサポート(Support all workloads in one place)し、バッチ処理やストリーミング処理などの多様なデータ処理に対応しています。
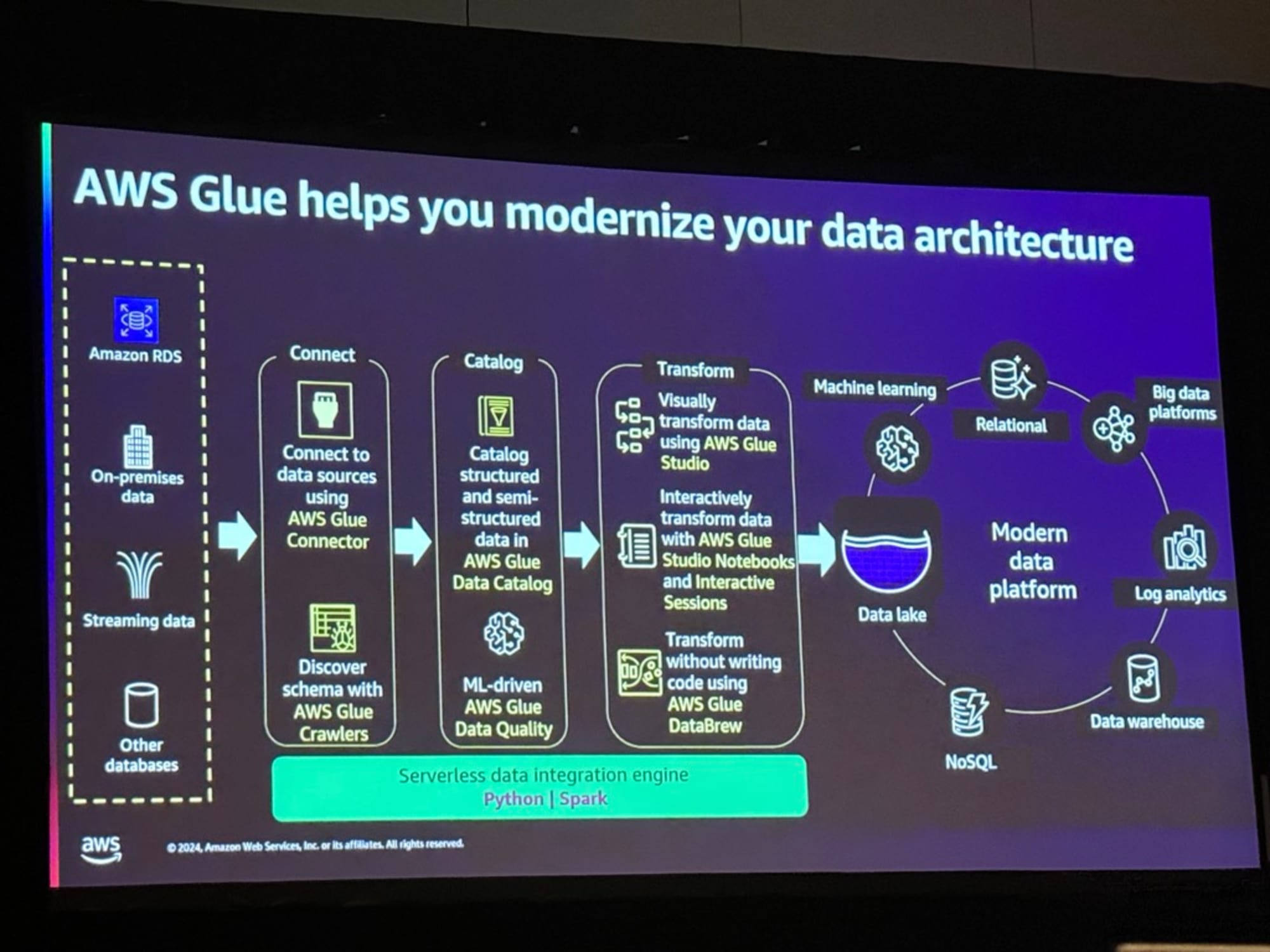
AWS Glueは、データの取り込みから活用までを一貫して管理できる近代的なデータアーキテクチャを提供します。このプロセスは主に3つのステップで構成されています。
- 接続(Connect)
- Amazon RDS、オンプレミス、ストリーミング、その他データベースからのデータソース接続
- AWS Glue Connectorを使用したデータソースへの接続
- AWS Glue Crawlersによるスキーマの自動検出
- カタログ化(Catalog)
- 構造化・半構造化データのAWS Glue Data Catalogへの登録
- ML駆動のAWS Glue Data Qualityによる品質管理
- 変換(Transform)
- AWS Glue Studioによるビジュアルデータ変換
- Notebooksやインタラクティブセッションでのデータ変換
- AWS Glue DataBrewによるコードレス変換
これらの処理は、Python/Sparkベースのサーバーレスデータ統合エンジン上で実行され、データレイク、データウェアハウス、機械学習など、様々な現代のデータプラットフォームに接続できます。
AWS Glue Stuio demo
AWS Glueの機能を説明するために、以下の3つのデモが実施されました。
- データ接続(Data Connection)
- データ準備(Data Preparation)
- データ検証(Data Validation)
これらのデモを通じて、コードを書かずにデータの接続から検証までを実施できる機能が紹介されました。

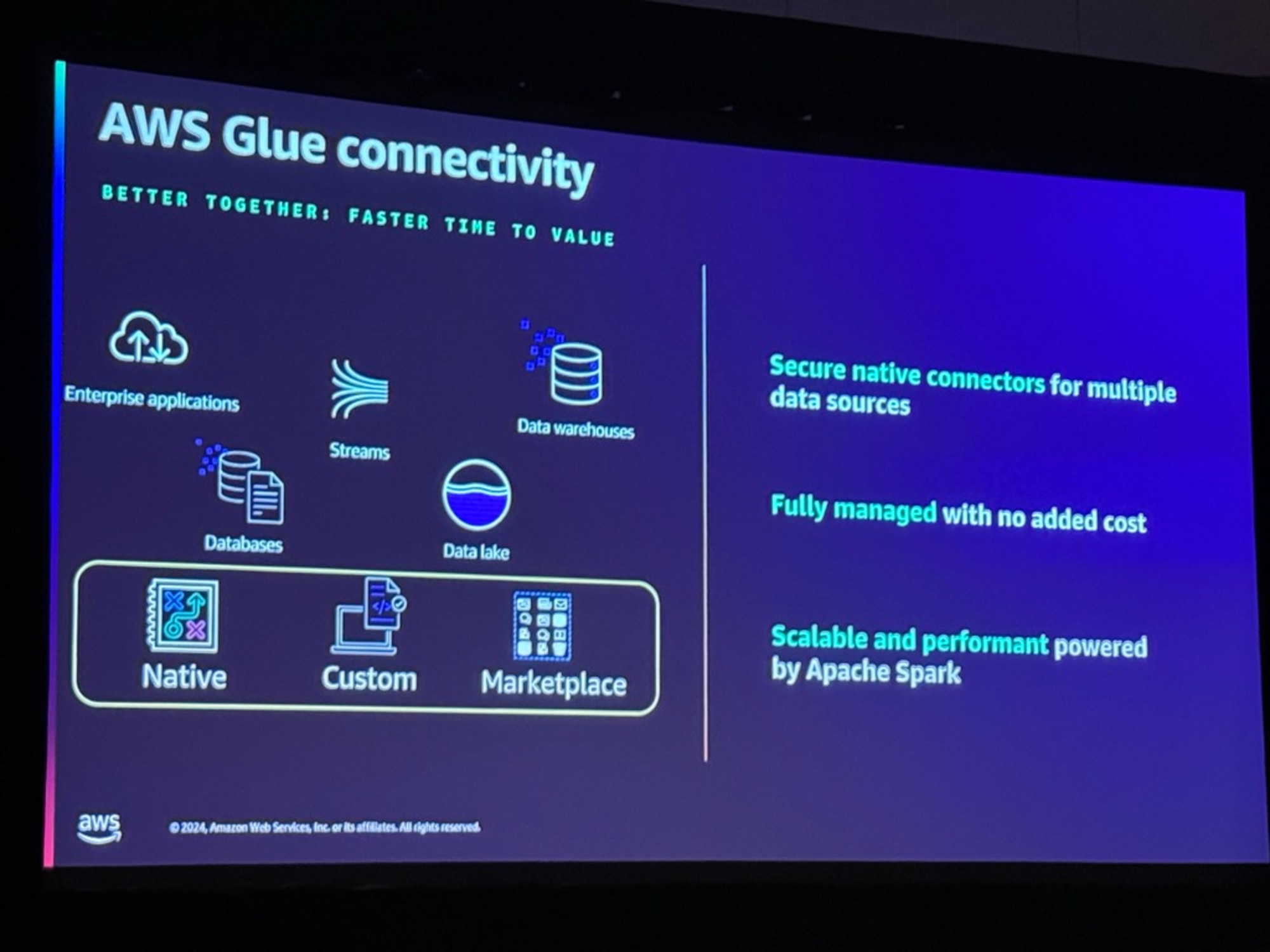
AWS Glueは「より良く、より速く価値を生み出す」をモットーに、包括的なデータ接続機能を提供しています。
- 接続可能なデータソース
- エンタープライズアプリケーション
- データベース
- ストリーミングデータ
- データレイク
- データウェアハウス
- 接続方式は3つのタイプから選択可能
- ネイティブコネクタ(Native)
- カスタムコネクタ(Custom)
- マーケットプレイスコネクタ(Marketplace)
- 主な特徴
- 複数のデータソースに対する安全なネイティブコネクタの提供
- 追加コストなしでフルマネージド
- Apache Sparkを活用した拡張性の高いパフォーマンス
これらの機能により、様々なデータソースへの接続を効率的に管理することが可能です。
AWS Glue Studioの「Data preparation authoring(データ準備オーサリング)」は、一般提供が開始された新機能で、ビジュアルETLとデータ準備のための統合オーサリング環境を提供します。
- データエンジニアとアナリストの生産性向上
- データ統合ジョブをより迅速に構築可能
- ビジュアルな操作による直感的な開発
- トラブルシューティングの簡素化
- データ統合における問題解決の複雑さを軽減
- 視覚的なデバッグ機能の提供
- コスト削減効果
- データ準備のオーサリングにかかるコストを削減
- 効率的な開発環境の提供
この機能により、コードを書かずにデータ準備作業を実行でき、開発効率の向上とコスト削減を同時に実現できます。

AWS Glue Data Qualityに新しく追加された機械学習(ML)機能は、MLベースの異常検知アルゴリズムを活用して、データ品質の監視と管理を強化します。
- 異常検知機能
- データ統計を分析してMLアルゴリズムにより異常を検出
- データパターンの変化を自動的に識別
- 隠れた品質問題の発見
- 通常では見つけにくいデータ品質の問題を特定
- 異常なデータパターンに関する洞察を生成
- 継続的モニタリング
- 動的なルールを自動生成
- データ品質の継続的な監視を実現
この新機能により、データ品質の問題をより早期に、より正確に発見できるようになり、データの信頼性が向上します。

Q&A
主な質疑応答
Q: カスタム変換が必要な場合はどうすればよいか?
A: Glue Studioでカスタム変換を作成し、アカウント内で共有することができる。詳細なリソースも用意されている。
Q: 異なる環境で異なる認証情報を使用する場合は?
A: Secret Managerを使用して認証情報を管理できる。実際の値はSecrets Managerで安全に保管される。
Q: Salesforceからのデータ抽出をフィルタリングできるか?
A: Where句を使用してデータをフィルタリングでき、特定の条件に基づいて必要なデータのみを抽出できる。
Q: Glue 5.0でのデータフレームとオープンリネージモデルの対応は?
A: 現在はダイナミックフレームを使用しているが、将来のバージョンでデータフレームのサポートを計画している。
増分更新について
Q: データの増分更新はどのように処理さるか?
A: 現在は定期的なジョブスケジューリングで対応。新しいZero ETL機能で15分ごとの変更キャプチャが可能。
Q: Salesforce側でのトリガーは可能ですか?
A: 現時点ではプッシュベースのトリガーはサポートしていなくポーリングベースの方式を使用している。
Q: 大量のデータを処理する際のパフォーマンスは?
A: Sparkの並列処理機能を活用し、パーティション分割によって効率的なデータ処理が可能。
まとめ
「ANT320 | Data preparation authoring with AWS Glue Studio」のセッションレポートをお届けしました。
最後まで読んで頂いてありがとうございました。










