![[レポート] Build large-scale transactional data lakes with open table formatsに参加しました #AWSreInvent #ANT336](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート] Build large-scale transactional data lakes with open table formatsに参加しました #AWSreInvent #ANT336
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
データ事業本部のkobayashiです。ラスベガスで開催されていたre:Invent2024に現地参加しました。
本記事は AWS re:Invent 2024 のセッション「ANT336 | Build large-scale transactional data lakes with open table formats」のセッションレポートです。
このセッションでは、トランザクショナルデータレイクの概念と実装についての説明がありました。
はじめはデータ管理の変遷と現在のクラウドベースのレイクハウスアーキテクチャに至る流れが紹介され、Apache Iceberg、Hoodie、Delta Lakeなどのオープンテーブルフォーマット(OTF)の重要性を説明がありました。次にOTFレコードレベルの更新と削除、スキーマと分割の進化、データの整合性と一貫性、そしてパフォーマンスの向上の説明がありました。
またAWSでは、EMR、Glue、Athenaなどのサービスを通じてこれらのオープンテーブルフォーマットをサポートし、パフォーマンスの最適化ときめ細かなアクセス制御を提供しています。さらに、SageMaker LakeHouseの導入により、データの統合と活用がより容易になったという内容でした。
セッションの概要
タイトル
ANT336 | Build large-scale transactional data lakes with open table formats
概要
Transform your data landscape by building large-scale transactional data lakes using open table formats (OTFs) with AWS analytics services. The rise of generative AI and ML demands robust and scalable data infrastructure, and OTFs offer a cutting-edge solution for modern data architectures. Learn best practices for operating tables at scale, focusing on high performance, cost optimization, and operational excellence. This session also covers streaming data challenges, showcasing how OTFs enable seamless schema evolution and strong reliability for streaming workloads.
- Level: 300
- Session Type: Breakout session
スピーカー
- Radhika Ravirala, Principal Product Manager, Amazon
- Giovanni Matteo Fumarola, Sr. Manager, Amazon Web Services
内容
はじめにジェンダは次の通りです。
- トランザクショナルデータレイクの台頭
- オープンテーブルフォーマット(OTFs):入門
- OTFsを使用したトランザクショナルデータレイクの構築と最適化
- パフォーマンス
- きめ細かなアクセス制御
- AWSの分析サービスとの相互運用性

トランザクショナルデータレイクの歴史
以下が説明の要約になります。
トランザクショナルデータレイクの初期段階は、リレーショナルデータベースシステムの形で、顧客はリレーショナルデータベースシステムを使用していたが、その理由はそれらがトランザクションの実行を支援するように設計され、INSERT、UPDATE、DELETEなどのプリミティブを提供し、高ボリュームのトランザクション環境に適していた。
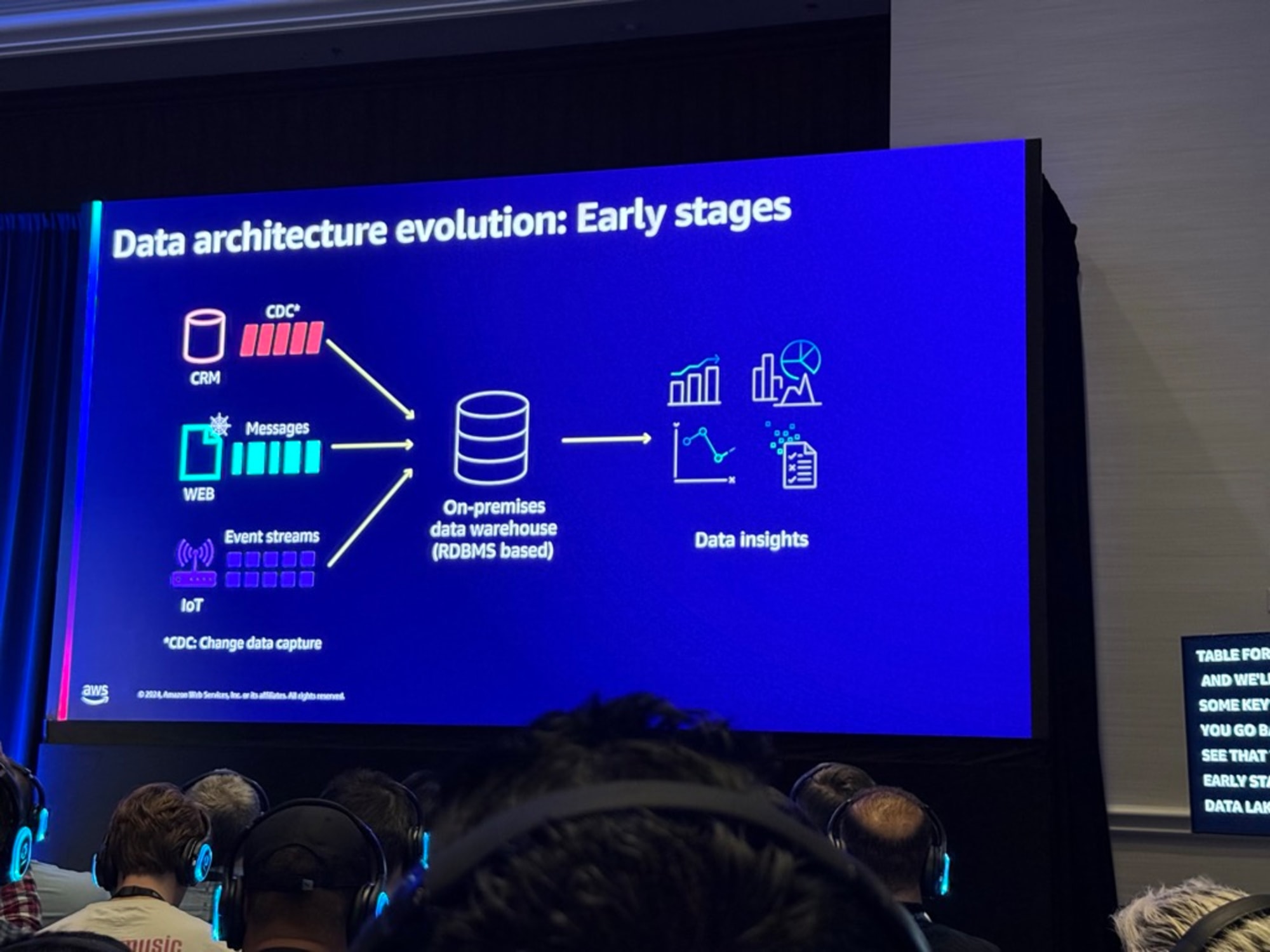
ただ前述のアーキテクチャでは集計データに対する大規模で複雑な分析クエリを実行する能力に限界があり、この問題に対処するため、OLAPシステムやオンプレミスのデータウェアハウスが登場した。データウェアハウスはこれらの問題に対処し、構造化データの管理に優れ、BIシステムを支える複雑なクエリと分析を実行する重要な機能を提供しました。
しかし、 データウェアハウスはRDBMSベースで構造化データの管理と複雑な分析に優れていたが、スケーリングが困難なため、この制限を解決するためにHadoopベースのデータレークが登場し、柔軟なスケーリングと多様なデータ形式の扱いを実現しました。
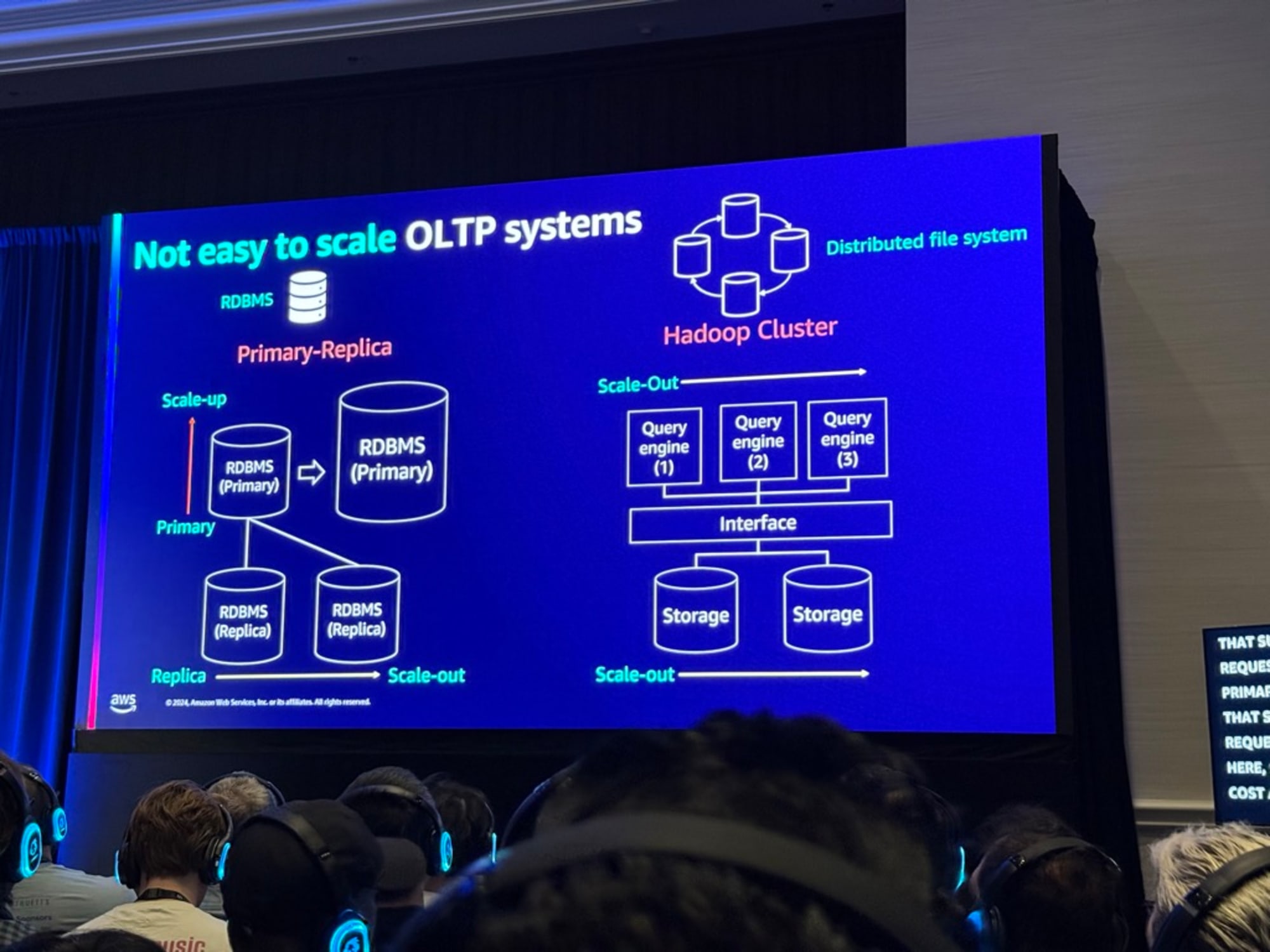
Hadoopとデータレークにも3つの主な制限があります。
- ACID特性の欠如による一貫性の問題
- 非効率なデータレイアウトによる性能低下
- 細かい権限管理の難しさ
これらの課題に対し、クラウドとオブジェクトストレージの発展により、Lakehouseアーキテクチャが登場しました。Lakehouseは以下の利点があります。
- データレークの柔軟性と低コスト
- データウェアハウスの一貫性と管理性 を組み合わせ、さらに機械学習やログ分析など現代のデータ処理要件にも対応する統合的なソリューションを提供
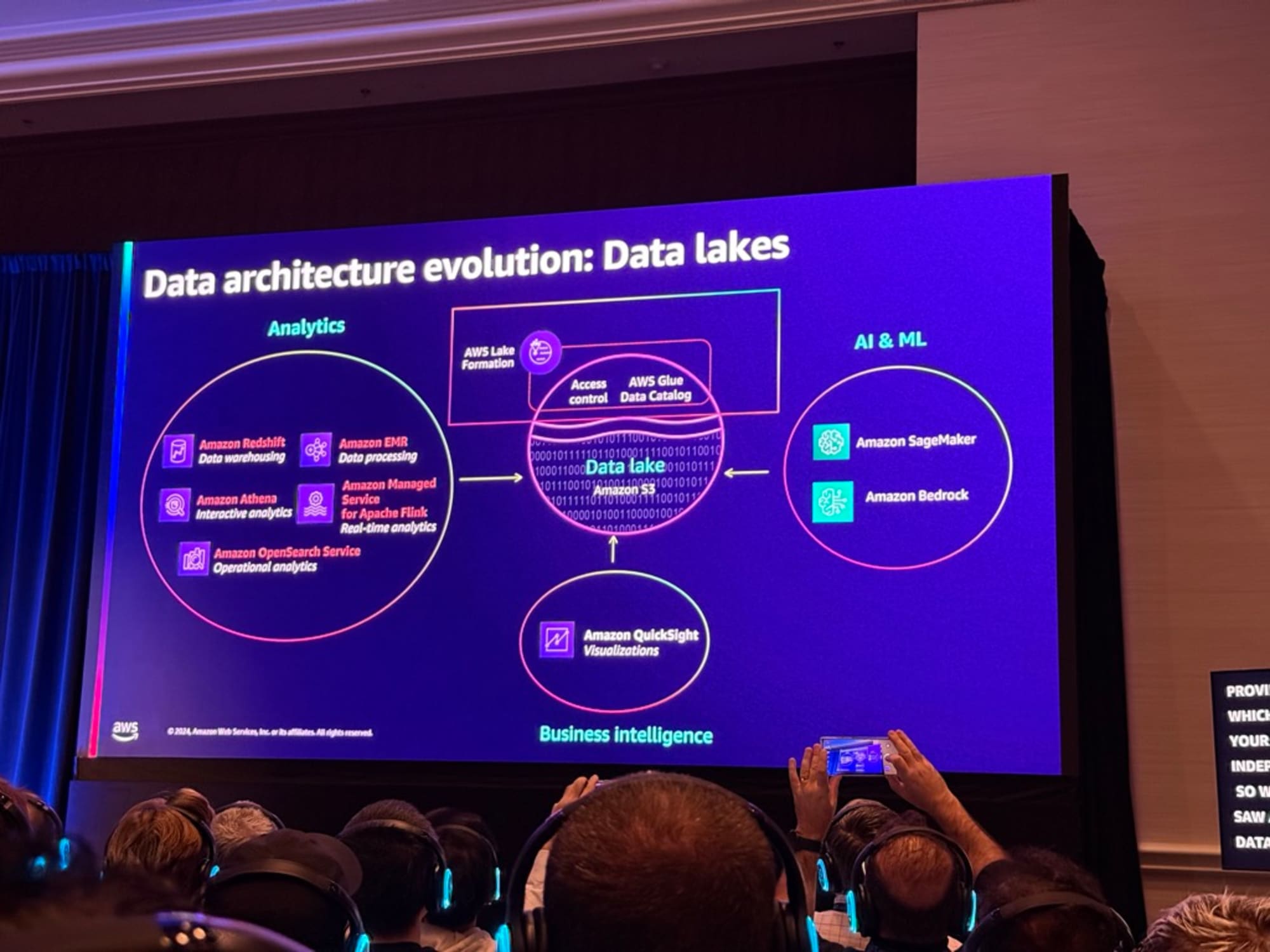
ただLakehouseにも課題はあり、継続的な更新を行う能力、一貫したパフォーマンス、そして規制に準拠する能力が課題となります。またトランザクションと分析ワークロードを実行できる単一のプラットフォームを持つことができるか、データウェアハウスがオープンソースの柔軟性をサポートできるか、同様に、データレイクがエンドツーエンドのガバナンスをサポートし、パフォーマンスとACID特性を追加できるかといった要求もありました。

そこで登場したのがトランザクショナルデータレイクです。トランザクショナルデータレイクは、トランザクションサポートを提供し、データレイクの最適化と管理を簡素化するオープンテーブルフォーマット(OTF)によって支えられています。

トランザクショナルデータレイクの利用シーン
1つ目にストリーミング取り込みの例になります。データの整合性を保つため、読み取り操作を妨げることなく、アトミックな更新を即時に適用できる必要があります。これには、読み書きの分離とスナップショット管理が不可欠です。
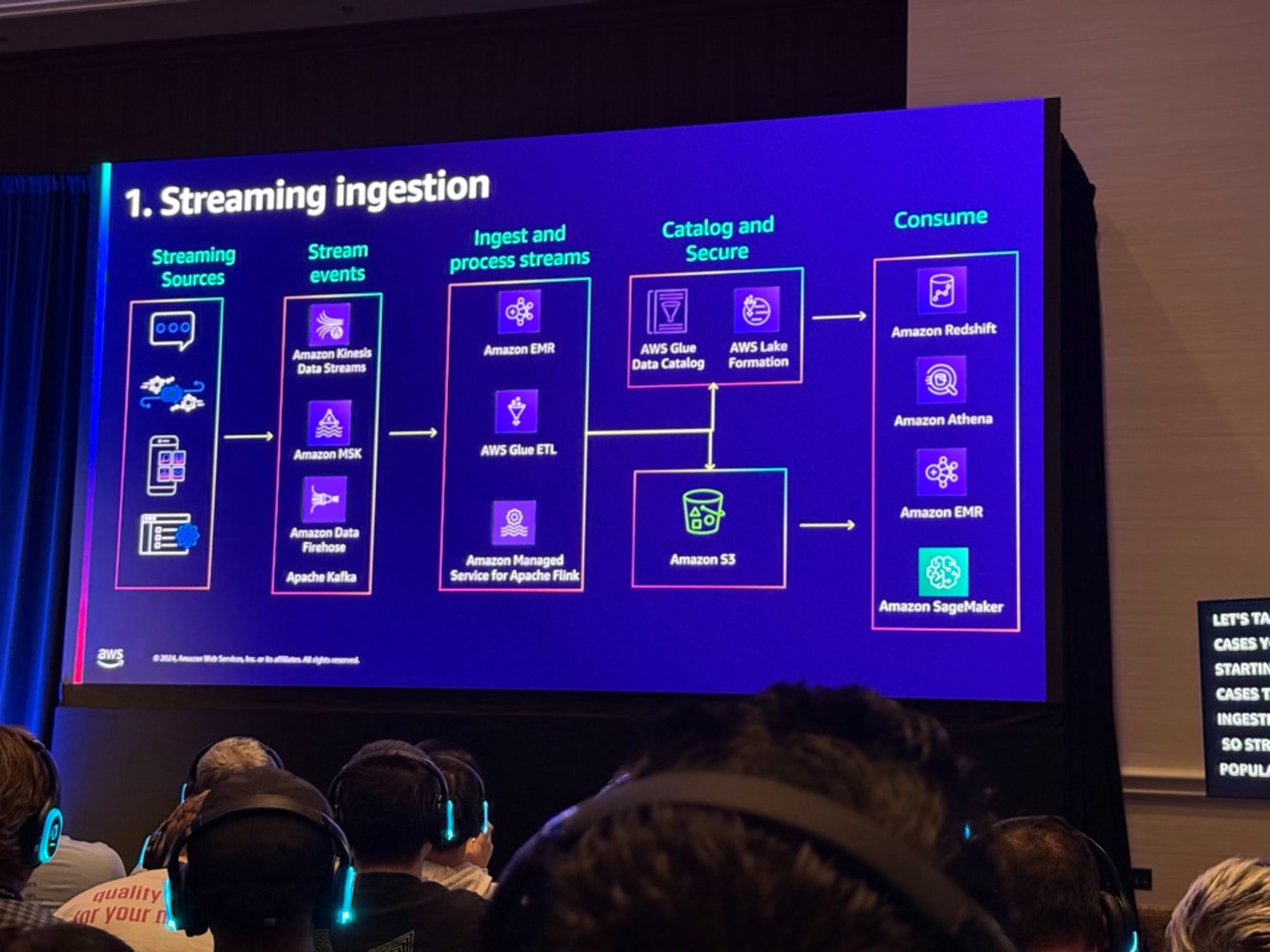
2つ目はデータプライバシー規制になります。
GDPRやCCPAに基づく個人データの削除要求に対応するには、大量のデータから特定レコードを効率的に特定・削除し、整合性を保ちながら更新する仕組みが必要になります。

従来の分析やBI用途に加え、生成AI(Bedrock等)の基盤モデル用のデータ供給源としても重要になっています。常に新鮮なデータを様々なアプリケーションをサポートするために、トランザクショナルデータレイクが中心的な役割を果たすようになっています。
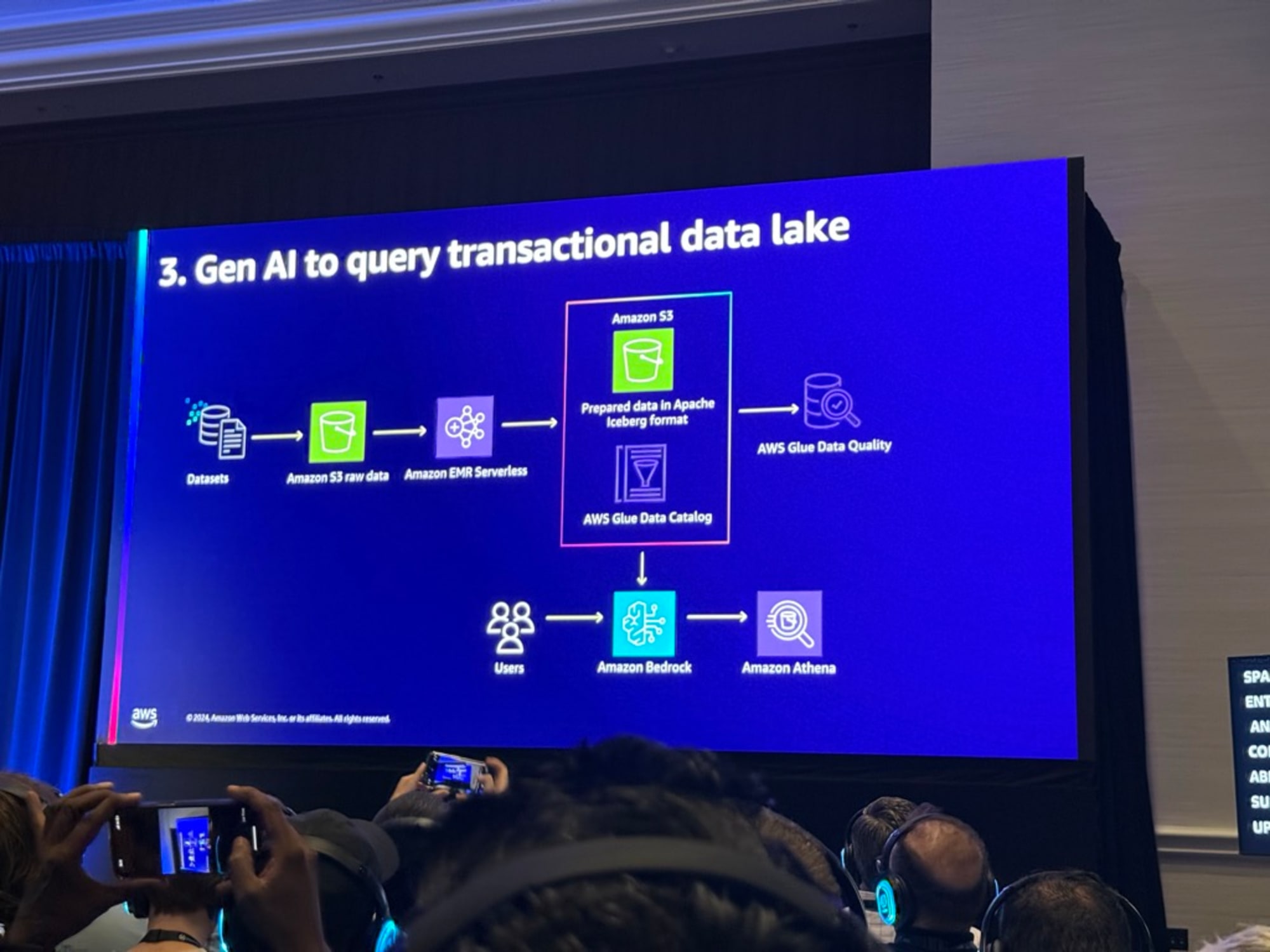
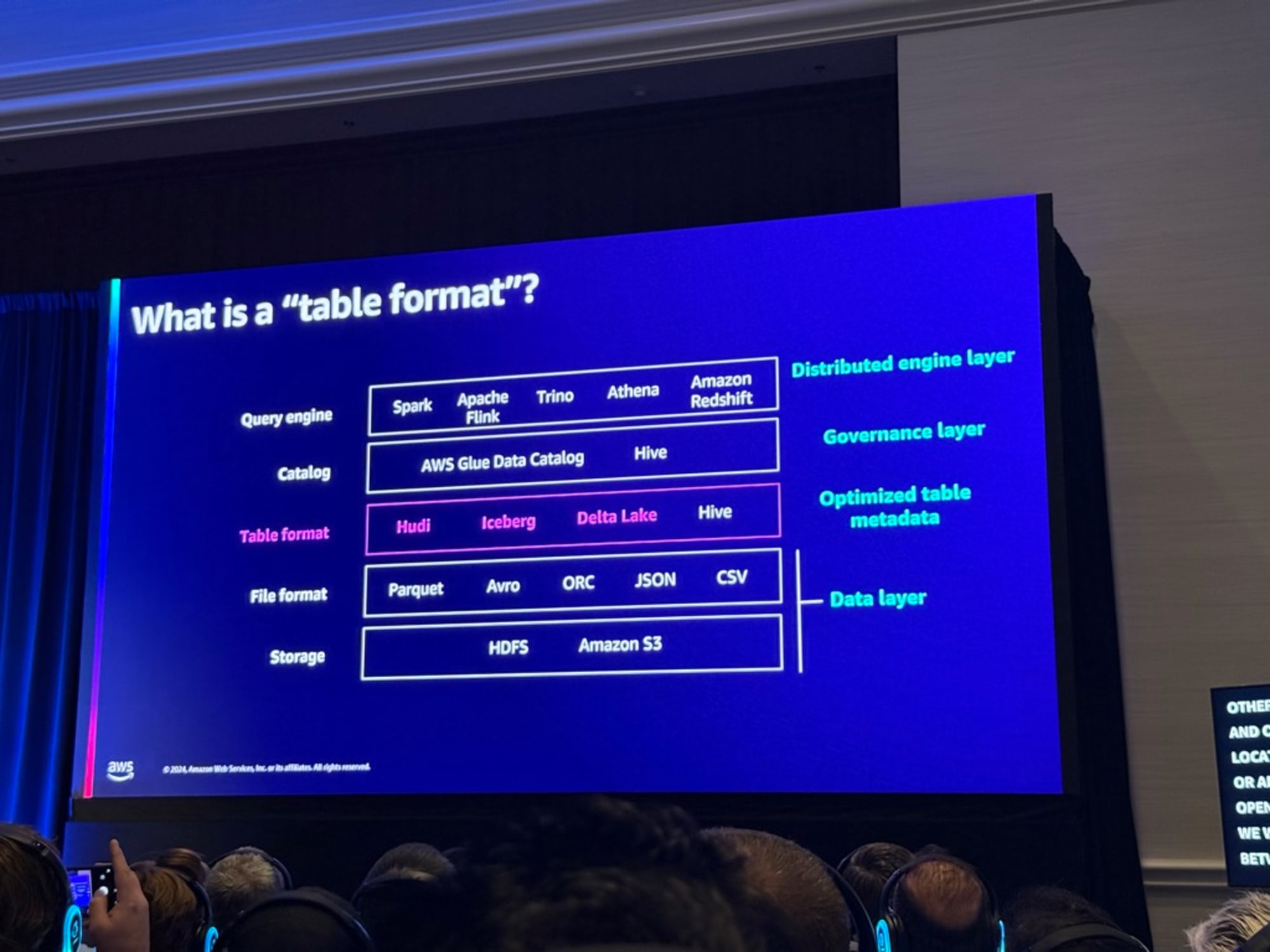
オープンテーブルフォーマット(OTFs):入門
分散クエリエンジンのアーキテクチャコンポーネントの表を元にテーブルフォーマットが何かを説明されました。
以下が説明の要約になります。
OTFはCatalogとFile formatの間に位置しています。OTFでもHudi、Iceberg、DeltaとHiveに分類され、Hiveは単純なフォルダ構造でデータを管理するが、 新しいHudi、Iceberg、Deltaは「マニフェスト」という仕組みでデータの追跡と管理を行い、より高度な操作が可能。
特定の時点でのテーブルはマニフェストを指しマニフェストはテーブルの状態を表すものである。
- OTFのマニュフェストの例
- テーブルには4つのオブジェクトしかない
- 挿入されるとストレージレイヤーに2つのオブジェクトを追加し、オープンテーブルフォーマットは新しいマニフェストを指すようにマニフェストを更新する
- 更新や削除などの操作が行われ、マニフェストは7つのオブジェクトを追跡する
- コンパクションの機能で既存のオブジェクトと新しいオブジェクトをコンパクトにし、必要に応じて新しいオブジェクトを作成する。この場合、元の白いオブジェクトと新しいオブジェクトをマニフェストから削除し、2つの青いオブジェクトが作成される
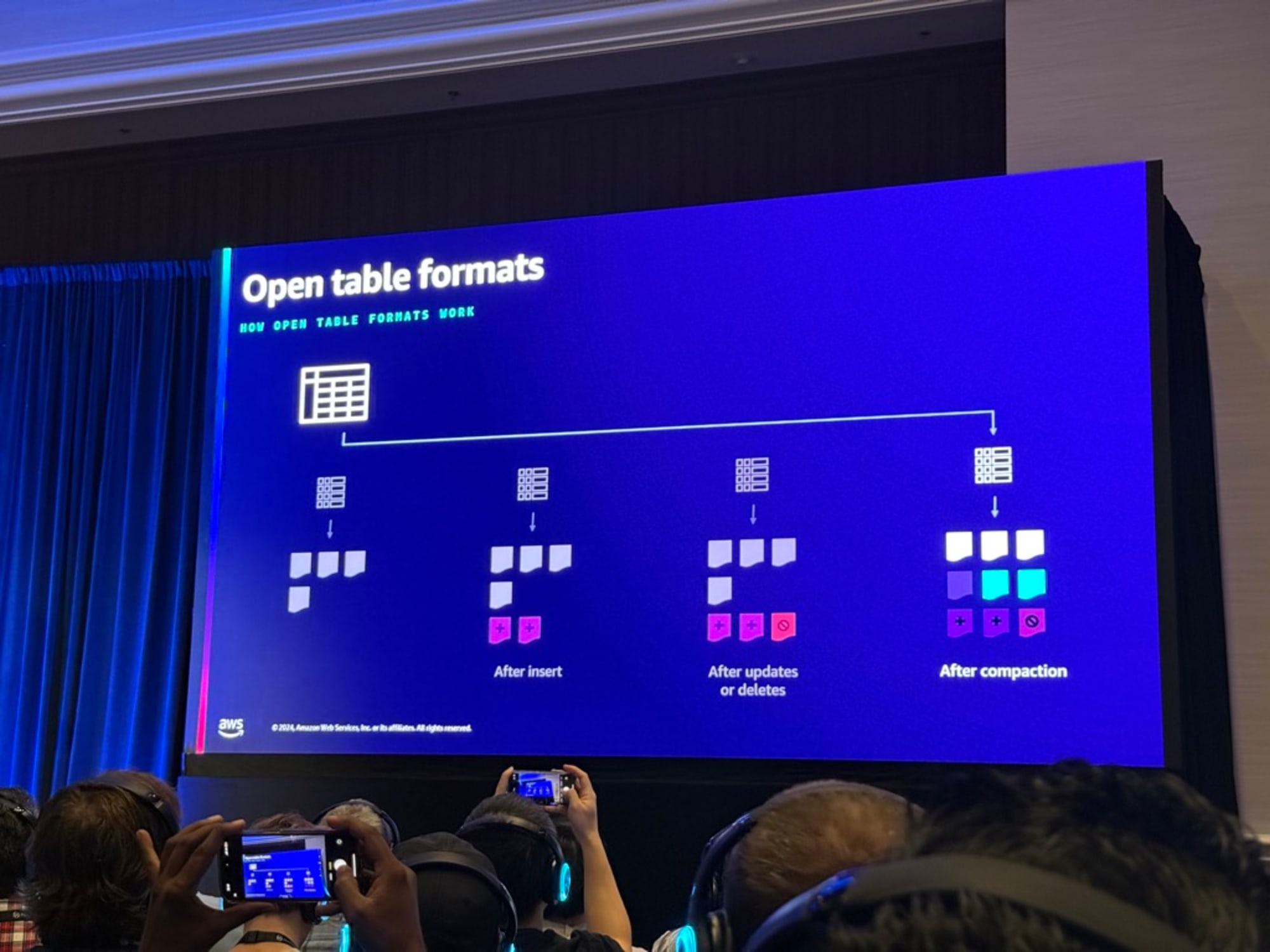
この時点では古いオブジェクトはまだストレージに保持されています。ただし、マニフェストでは、点線内の5つのオブジェクトのみが表示されます。しかし、OTFではタイムトラベルクエリを実行することができ、その際に最新データだけでなく過去のデータも保存されているので、「昔のデータがどうだったか」を以前のバージョンのマニフェストに対してクエリを実行することで確認できます。
タイムトラベルが必要なくストレージのコストを抑えたい場合はバキューミングをすることで不要なオブジェクトとマニフェストのストレージ全体をクリーンアップする機能もあります。

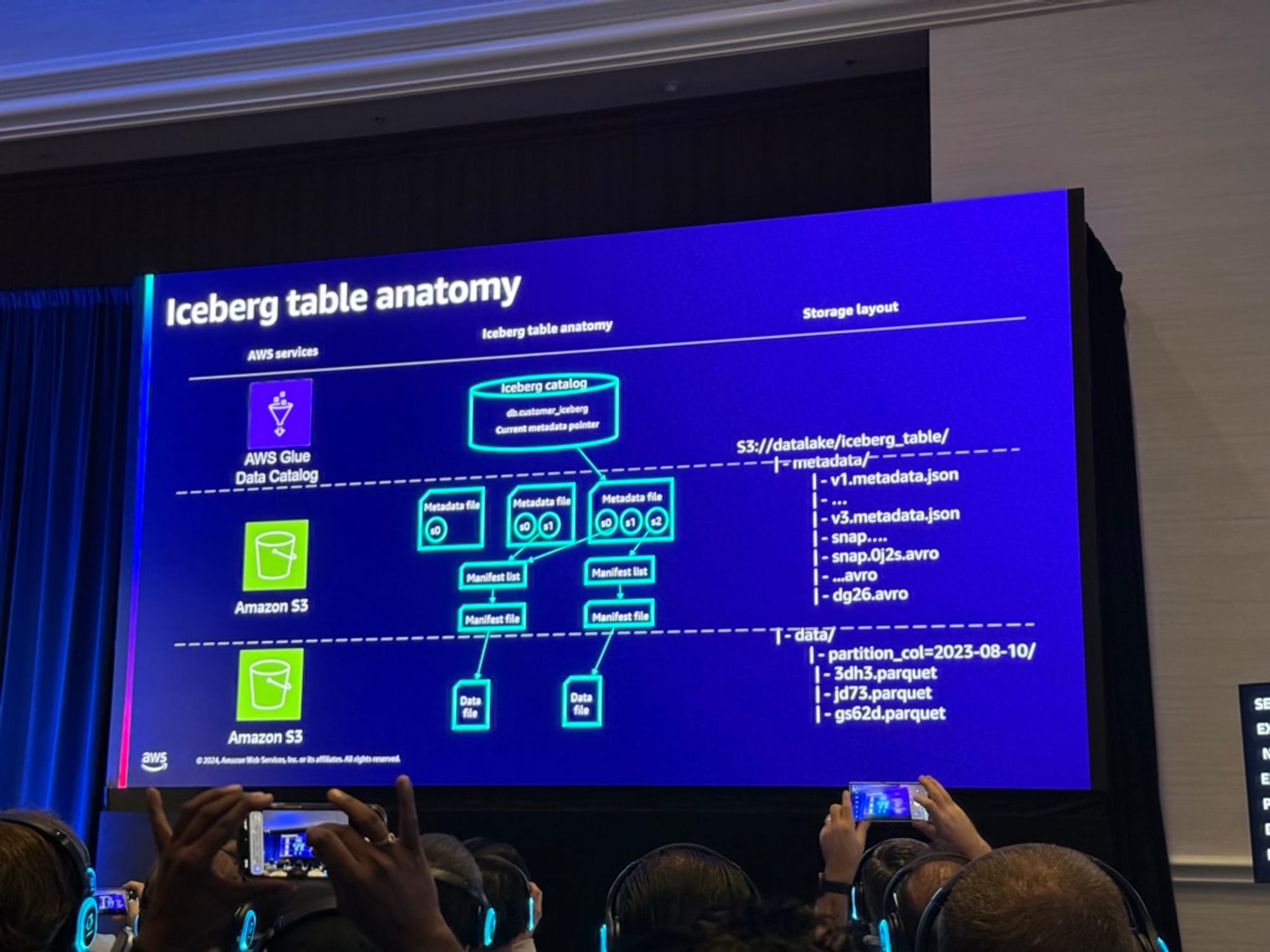
Apache Iceberg
顧客の関心、顧客のフィードバック、Iceberg自体のパフォーマンス向上、そしてオープンソースコミュニティであるためAWSではIcebergのリリースを優先しているようです。

以下が説明の要約になります。
Icebergは3つのレイヤーで構成されています。
Icebergの最初の部分はメタデータファイルで、時間とともにテーブルの状態を指すスナップショットを保存します。
各スナップショットにはマニフェストリストがあり、これにはマニフェストのリストが含まれています。
各マニフェストは、その時点で追加されたファイルまたはファイルのリストを指します。
Copy-on-Write と Merge-on-Read
Icebergは以下の2つの概念がありこれらの違いの説明がありました。
- Copy-on-Write
- 更新や削除、挿入がある場合、Icebergはクエリエンジンに必要なすべてのデータファイルを文字通り書き直すように指示
- 書き込み操作中にデータを書き直すため、書き込みは高コスト
- 読み取り側には影響がない
- Merge-on-Read
- 更新、削除、マージ中に新しいオブジェクトが追加される。このオブジェクトはログファイルで、通常はテーブルに何が起こったかを追跡する
- 書き込みは非常に高速
- 読み取りはログファイルをすべてスキャンするので高コスト
これらの挙動の説明が次にありました。
Copy-on-Writeの挙動
以下が説明の要約になります。
- 新しいファイルが書き直される
- すべての書き直されたレコードを含む新しいデータファイルを指す新しいマニフェストファイルが作成される

- マニフェストファイルを指す新しいマニフェストリストが作成される
- 最後に3つのスナップショットを持つメタデータファイルが作成される。その際にS2は新しいマニフェストリストを指す

Merge-on-Readの挙動
以下が説明の要約になります。
- 新しいデルタファイルまたはログファイルが作成される(異なるドメインクラッターを持ち、ストレージレイヤー自体に作成され追加される)

- delete,insertの両方を指すマニフェストファイルと、古いマニフェストリストと新しいものを指すマニフェストリストを作成する

- 後に、新しいマニフェストリストを指すメタデータファイルが作成される

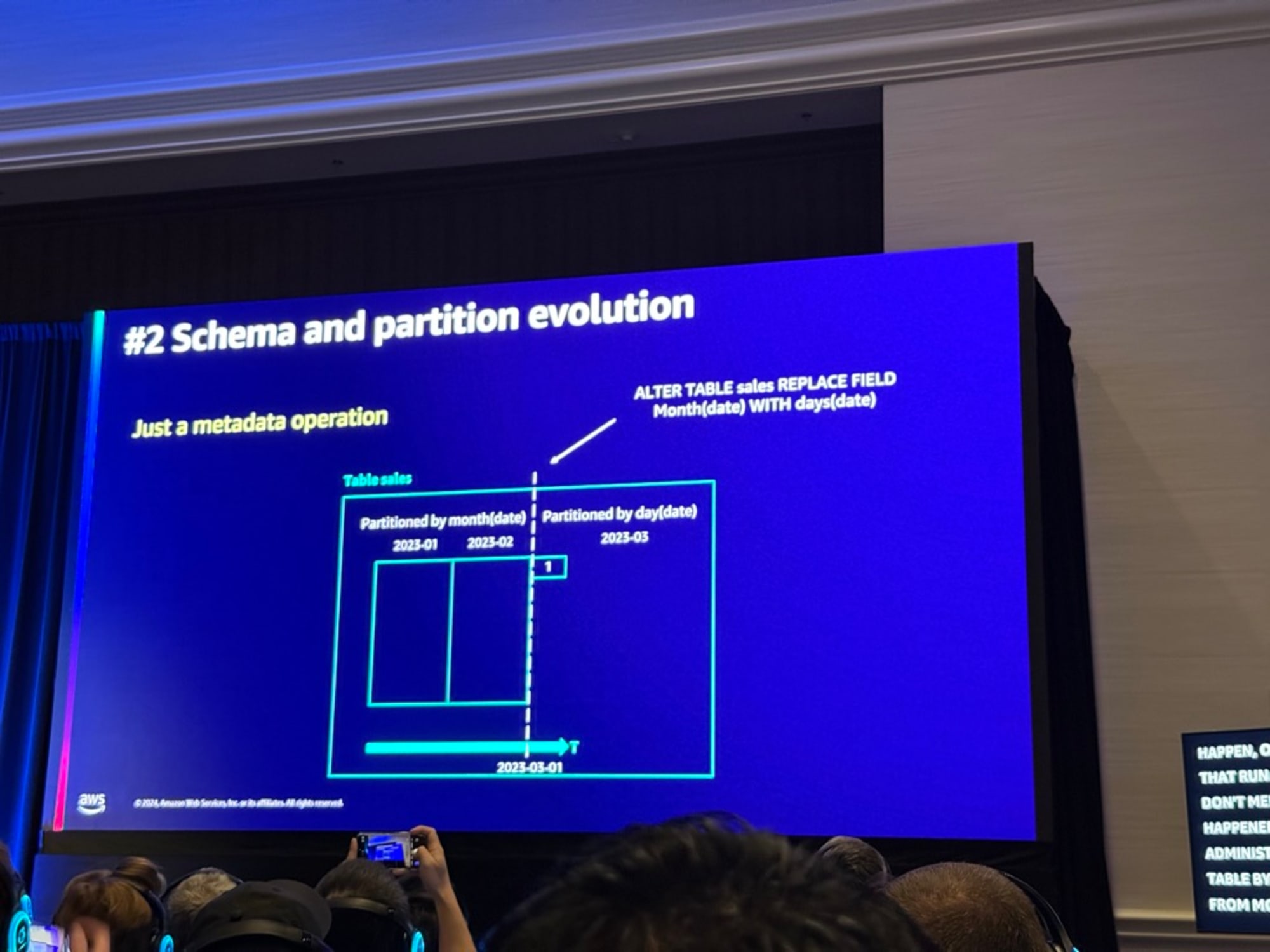
Schema and partition evolution
以下が説明の要約になります。
スキーマ変更はデータ操作やデータ移動を伴わない。
データ列の追加、削除、名前変更、順序変更ができるがこれは単なるメタデータ操作である。
管理者が列を更新し、列の追加や削除でスキーマを更新した特定の時点以降、Icebergはこれらの変更を記憶し、クエリエンジンが列の有無に関わらず適切な列を選択できるようにする

組織が時間とともに行ったすべての販売を含むテーブルがあり、このテーブルが月ごとにパーティション化されているケースシナリオについて考えてみる。
2023年1月と2023年2月がある。管理者はパーティションを月から日に変更してテーブルを変更することを決定しました。3月1日に新しいパーティションが作成され月末までに31の新しいパーティションが作成される。

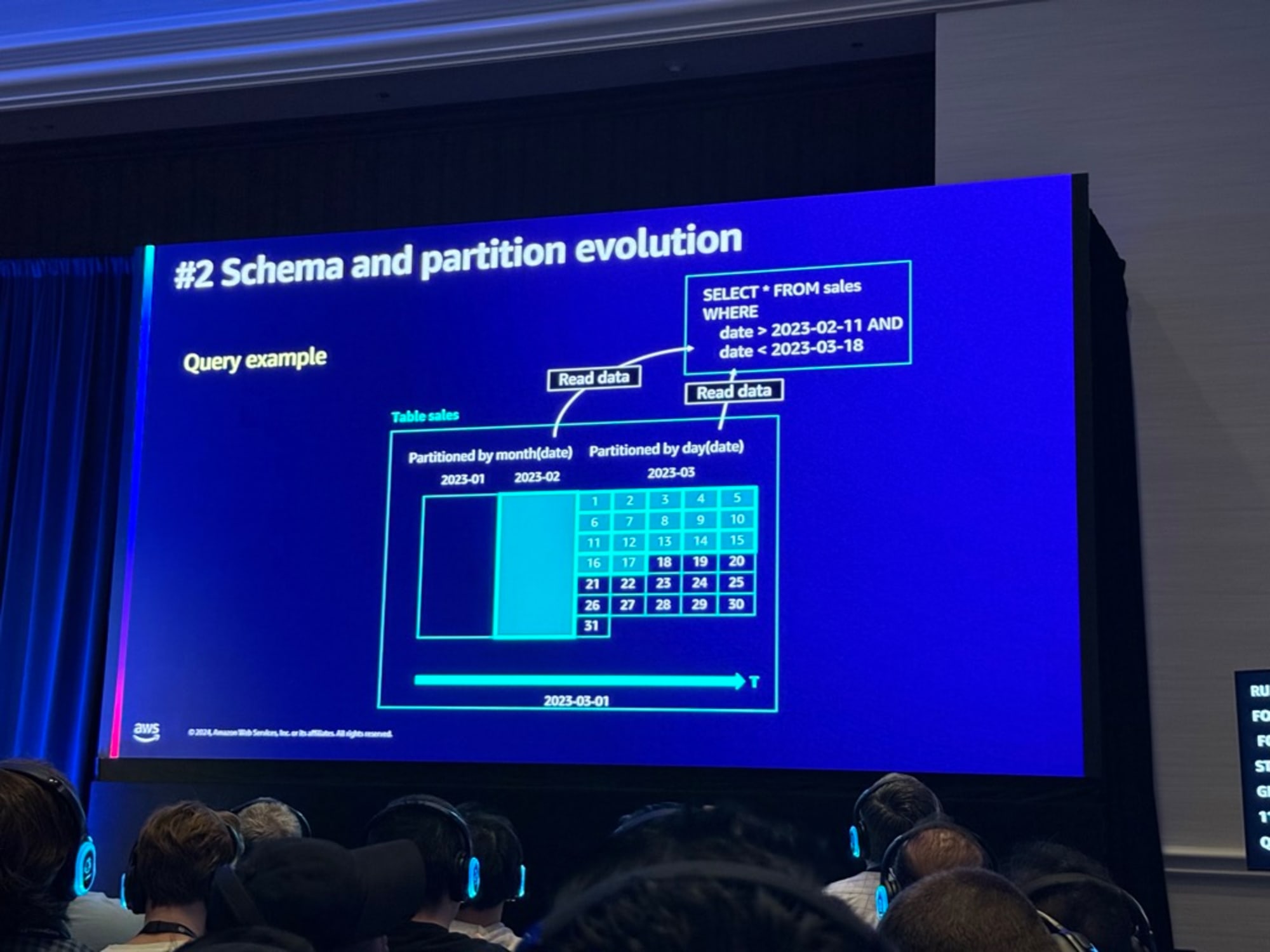
このテーブルに対して
Select * from sales where date > '2023-02-11' and date < '2023-03-18'
のクエリを実行するとIcebergはクエリを適切に分割しクエリエンジンにそのクエリを実行するための適切な知識と適切なオブジェクトを提供する
Tagging and branching for compliance
データトラッキングやロールバックの変更の説明もありました。
以下が説明の要約になります。
-
2月中に発生した他の2つのスナップショットがあり、S4は2月末に発生しS5は管理者が「月末」というラベルで特定のスナップショットにタグ付けする。
-
3月に別のスナップショットが来る。最後に3月の月末に別のスナップショットが来て、S7を「2024年月末」としてタグ付けする。
-
「スナップショットの有効期限切れ」という別の操作を行うとタグがなく、もはや必要とされていないスナップショットを削除する。
-
これらの操作によりタイムトラベルが可能になる

-
ブランチングとタグ付けはGitの動作と似ている
-
S7をスナップショットとして選び、それを分岐して新しいブランチを持つ新しいテーブルを作成する
-
T1と呼ばれるテーブルの異なるバージョンが作成できる
-
T2で別の操作を行い最後にコンパクション(圧縮)を行う
-
これを応用して、元のテーブルを新しいブランチに分岐させ、監査人がアクセスできないまたはアクセスすべきではないすべての列を削除することでデータを圧縮しこれで監査用のデータができる

Simplify queries with hidden partitions
パフォーマンス向上の手段として隠しパーティションの説明がありました。
以下が説明の要約になります。
-
テーブルにはいくつかの列があり、レベル、イベント時間、イベント日付がこのテーブルのパーティションとなる
-
イベント時間でフィルタリングするこのクエリを実行しようとすると、Hiveはクエリエンジンにすべてのデータをスキャンする必要があると伝える。
-
これを克服するために、新しいフィルター
イベント日付=2018-12-01を追加する。この場合クエリエンジンは部分的なスキャンのみを行う -
イベント日付とイベント時間の間には相関関係がありHiveでは2つの異なる列が必要

-
一方、Icebergでは隠しパーティションの概念があり、パーティショニングがイベント時間の日付関数によって行われる
-
前述のクエリを実行すると自動的に部分的なスキャンとなる

Randomized prefixes for S3
Icebergはパーティションにランダム化されたプリフィックスを追加している
以下が説明の要約になります。
-
Hiveの保存形式ではツリー構造ですべてのオブジェクトが同じプレフィックス(テーブル、データ、年)を保持
-
S3の場合、同じプレフィックスを共有しているため、すべてのリクエストが同じノードに着地し、その結果、503エラー、スロットリング、パフォーマンスの低下が発生する

-
Icebergの保存形式ではランダム化されたプレフィックスを各パーティションの前に追加
-
クエリエンジンはS3上でリクエストを分散させるためパフォーマンスが向上する

AWSでのOTF
- シャッフル削減、冗長スキャン排除、最適化されたデータ構造、最適化されたコード生成、適応的結合選択、ブルームフィルター、適応的ブルームフィルターの機能はデフォルトで有効
- すべてのEMRランタイムリリースはOSS Spark APIと100%互換性があり、EMRのすべてのデプロイメントとSparkを実行するGlue ETLエンジンでこれらの利点を得ることができる

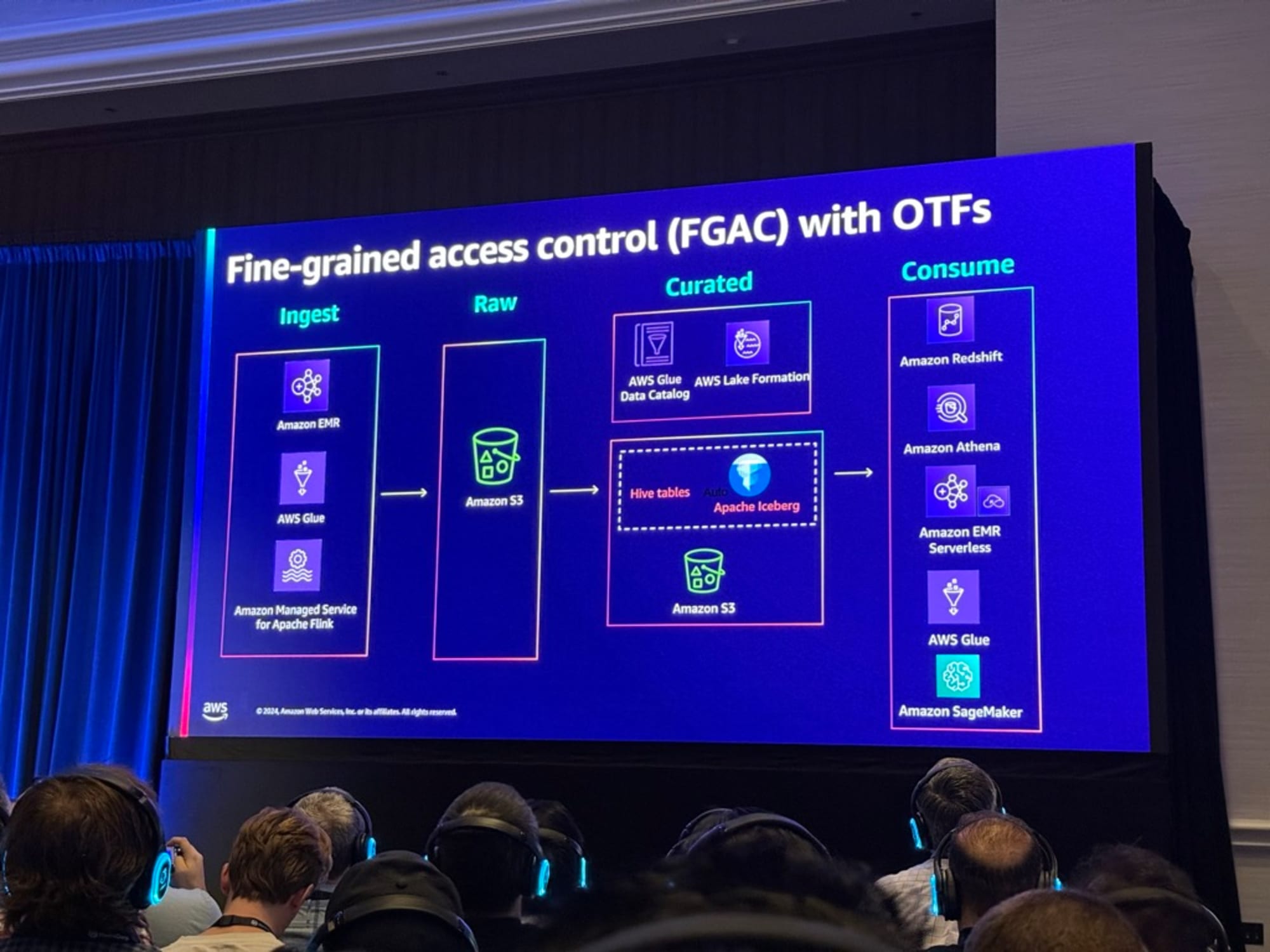
AWSでのOTFのCoarse-Grained permissionのアーキテクチャの説明がありました。

AWSでのOTFのFine-Grained access control(FGAC)のアーキテクチャの説明がありました。
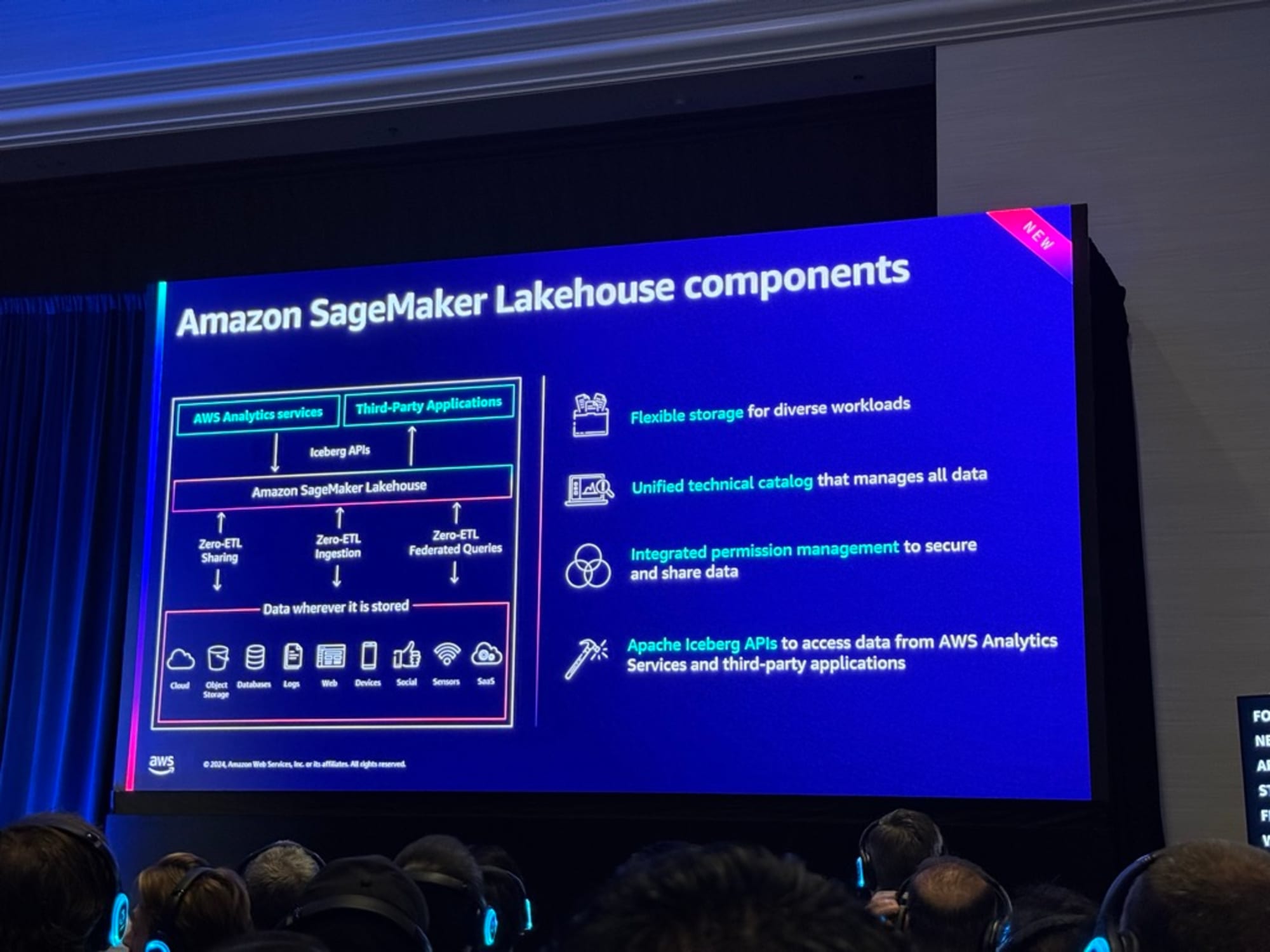
SageMaker Lakehouseでの活用も説明がありました。
- SageMaker Lakehouseはデータ分析とAIの統合基盤として注目されているが、S3やRedshiftなど異なるストレージのデータに一元的にアクセスでき、ParquetやIcebergといったオープンフォーマットもサポートしている。
- 使い方は簡単でJupyter NotebooksやBedrock APIを通じてアクセス可能。FGACにより、セキュアなデータ管理も実現可能。
- Apache Iceberg APIを通じてサードパーティツールとの連携も容易で、既存のデータ基盤を変更することなく導入できる
- これらにより、分散していたデータ資産を統合し、より効率的な分析とAI活用が可能

Firehoseを使用したIceberg tablesへのストリーミングも説明がありました。
- ストリーミングサービスを使用している場合、Firehoseを通じてIcebergサポートが追加された
- ターゲットのS3バケットに直接新しいテーブルと列を作成できる
- schema evolutionを、PIIデータをフィルタリングのサポートしている
- 現在プレビュー中の他のデータベースもGAになる予定で、これらすべてがIcebergフォーマットでトランザクショナルデータレイクに書き込む機能を提供する予定

まとめ
「ANT336 | Build large-scale transactional data lakes with open table formats」のセッションレポートをお届けしました。
今までIcebergにあまり触れることがなかったのですが、本セッションを聴講することでかなり理解と興味が深まりました。またIcebergの技術的な説明もあり非常に良いセッションでした。
S3 Tablesでも利用される技術なので今後もキャッチアップを行ってきたいです。
最後まで読んで頂いてありがとうございました。










