
AgentCore Gateway にツールを束ねて Managed Harness から使ってみた
はじめに
こんにちは、恋愛リアリティーショーも大好きなコンサル部の神野です。
AgentCore の Managed Harness、コードを書かずにサクッとエージェントが作れるのはめちゃくちゃ便利ですよね。 みなさん使っていますか?
私も使ってみたのですが、ツール側の準備は自分でやる必要があります。特にRAGとか作りたいのに自前で毎度作るのは手間だな・・・と感じました。Bedrock Agentsみたくお手軽にできたらなと思う今日この頃です。
そこで今回は簡単にHarness 利用者が RAGなどを使えるように、AgentCore Gateway にナレッジベース検索・Web ページ取得・AWS ドキュメント検索の3つのツールを束ねて、CDK でデプロイしておけば誰でも Managed Harness から繋いで使える、というコンセプトのツールキットを作ってみました。
Gateway 1つ繋ぐだけで3つのツールが全部使えるようになるので、利用者側の手間がかなり少なくて済みますね。
今回のコードは下記リポジトリで公開しています。記事中ではポイントを抜粋して解説していますが、全体像はこちらを参照ください。
AgentCore Gateway
本題に入る前に、Gateway の役割を軽く整理しておきます。
Gateway は既存の API や Lambda 関数、MCP Server などを束ねて、エージェントから統一的に呼び出せるようにするハブです。
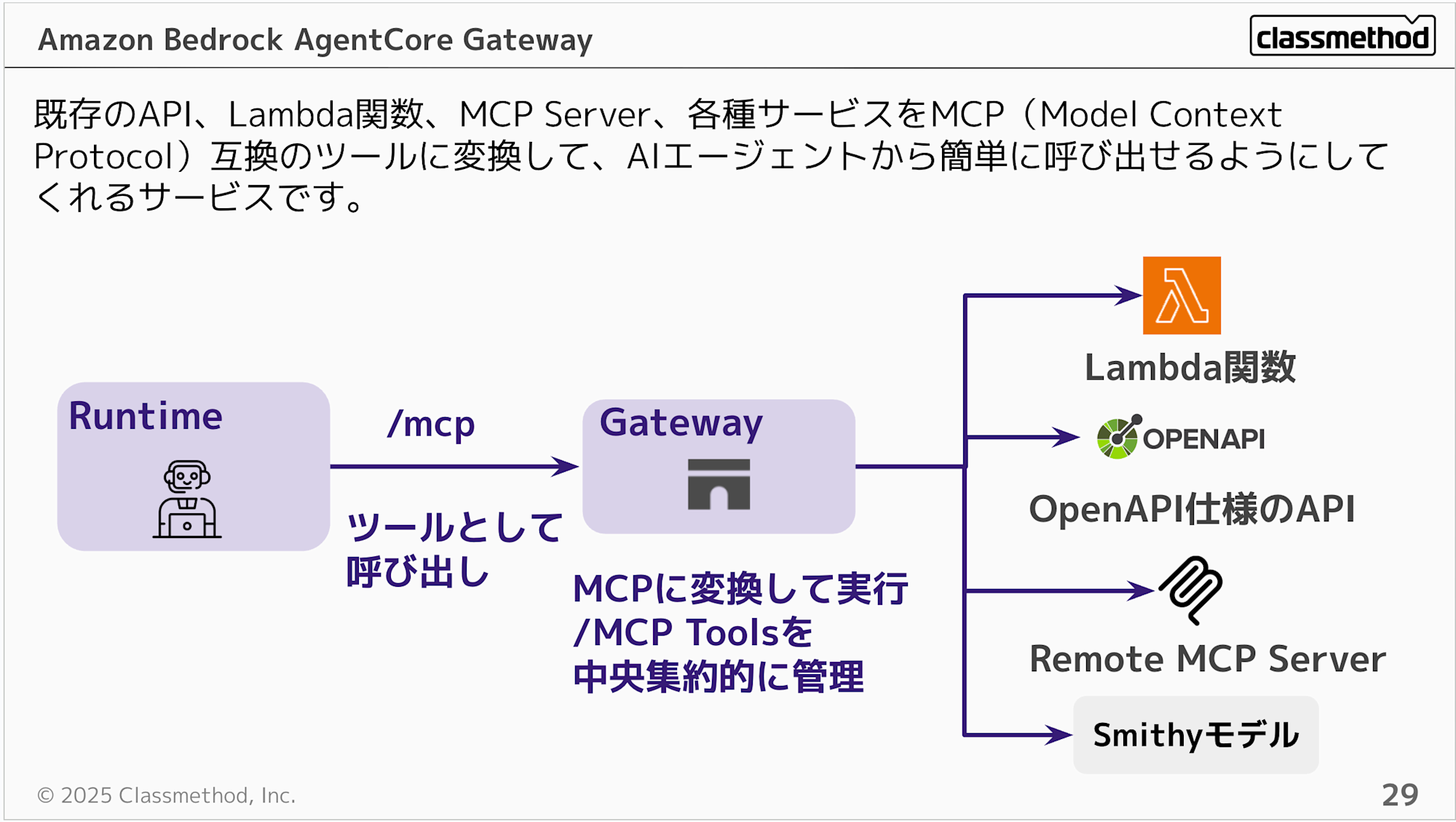
Gateway を使わなくても Runtime から Lambda や MCP Server を直接呼び出すことはできます。ただ、組織内に Lambda や MCP Server がたくさんある場合、個別にエージェントへ紐づけるのは管理が大変ですよね。
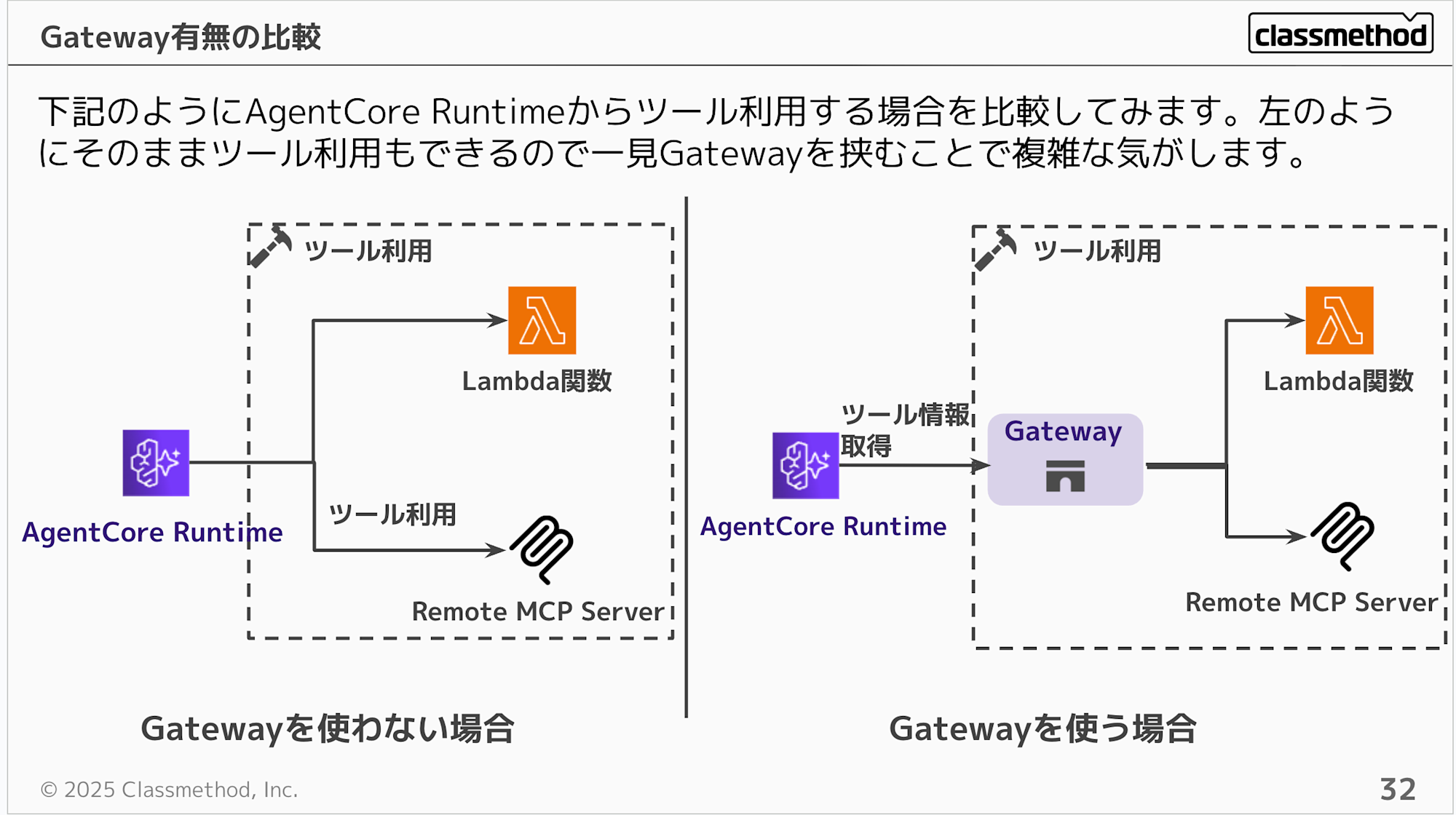
Gateway に集約しておけば、エージェント側は Gateway 1つを接続するだけで裏にある全ツールにアクセスできます。ツールの追加や変更があってもエージェント側のコードを変える必要がないのもメリットです。
今回のようにインフラ提供者が Gateway を CDK でデプロイしておけば、利用者は Managed Harness のコンソールから Gateway を追加するだけ。ツールの中身を意識する必要がないのがポイントです。
Gateway の詳細やプロダクション運用のTipsについては、下記記事で解説しています!
アーキテクチャ
全体像はこんな感じです。
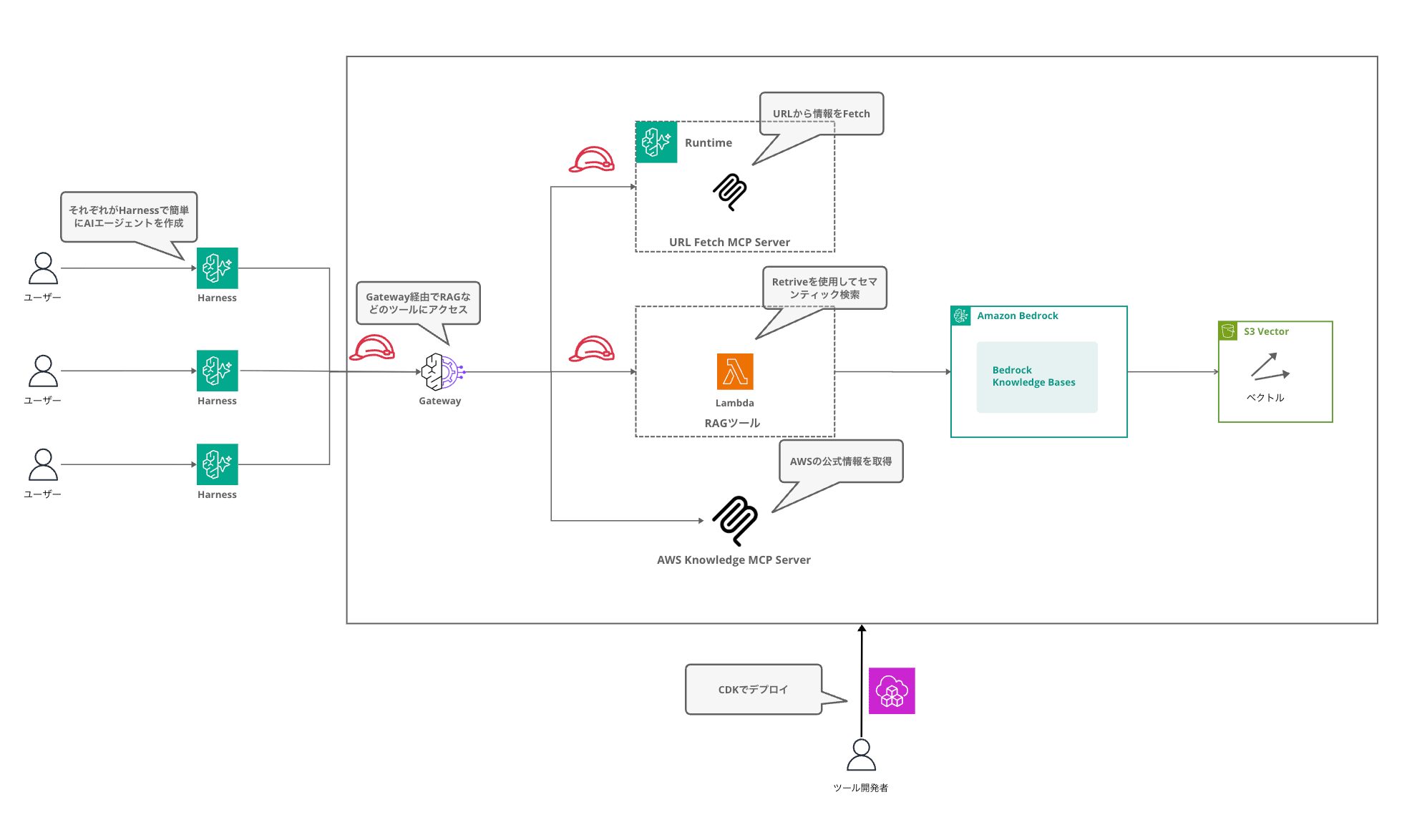
複数のユーザーがそれぞれ Managed Harness で AI エージェントを作成し、Gateway 経由で RAG などのツールにアクセスする構成です。ツール開発者は CDK で一度デプロイしておくだけで、利用者側は Gateway を繋ぐだけでツールが使えるようになります。
Gateway に3つの Target を登録しています。
| Target | ツール名 | 説明 | 実装方式 |
|---|---|---|---|
| kb-retrieve | retrieve_documents | ナレッジベースからドキュメント検索 | Lambda |
| web-tools | fetch_webpage | Web ページのテキスト取得 | FastMCP on AgentCore Runtime |
| aws-knowledge | search_documentation 他 | AWS 公式ドキュメント検索 | AWS ホスト済み MCP Server |
Target の実装方式をあえて3種類にしています。Lambda ターゲット / MCP Server on Runtime / 外部 MCP Server、それぞれ CDK でどう書くのかを一通り試したかったのが理由です。
前提
- AWS CDK v2.254.0
@aws-cdk/aws-bedrock-agentcore-alphav2.254.0-alpha.0- Node.js 22+(検証は v25.9.0)
- Docker(Runtime のコンテナビルドに必要)
- デプロイリージョン: us-east-1
プロジェクト構成
agentcore-gateway-kit/
├── bin/
│ └── app.ts # CDK エントリーポイント
├── lib/
│ ├── knowledge-base-stack.ts # Stack 1: KB + S3 Vectors
│ └── rag-gateway-stack.ts # Stack 2: Gateway + Lambda + Runtime
├── lambda/
│ └── kb-retrieve/
│ └── index.py # KB Retrieve Lambda
├── mcp-server/
│ ├── server.py # FastMCP Web Tools
│ ├── requirements.txt
│ └── Dockerfile
├── sample-data/
│ └── sample.txt
├── cdk.json
├── package.json
└── tsconfig.json
2スタック構成にしています。Knowledge Base と Gateway を分けることで、Knowledge Base は残しつつ Gateway 側だけ差し替える、といった運用ができます。
実装のポイント
コード全体はリポジトリを参照いただくとして、ここでは CDK で Gateway + 各 Target を組む際のポイントに絞って解説していきます。
Knowledge Base スタック
ベクトルストアに S3 Vectors を使っています。OpenSearch Serverless と違って追加のインフラが不要で、検証用途ならお安くて扱いやすいです。
S3 Vectors は CDK の L1 構成(CfnVectorBucket / CfnIndex)で定義します。
const vectorBucket = new s3vectors.CfnVectorBucket(this, 'VectorBucket', {
vectorBucketName,
});
const vectorIndex = new s3vectors.CfnIndex(this, 'VectorIndex', {
vectorBucketName,
indexName: 'rag-gateway-index',
dimension: VECTOR_DIMENSION,
distanceMetric: 'cosine',
dataType: 'float32',
});
vectorIndex.addDependency(vectorBucket);
Knowledge Base の storageConfiguration で S3_VECTORS を指定して紐づけます。
const knowledgeBase = new bedrock.CfnKnowledgeBase(this, 'KnowledgeBase', {
name: 'RagGatewayKnowledgeBase',
roleArn: kbRole.roleArn,
knowledgeBaseConfiguration: {
type: 'VECTOR',
vectorKnowledgeBaseConfiguration: {
embeddingModelArn: `arn:aws:bedrock:${cdk.Aws.REGION}::foundation-model/${EMBEDDING_MODEL_ID}`,
},
},
storageConfiguration: {
type: 'S3_VECTORS',
s3VectorsConfiguration: {
vectorBucketArn: vectorBucket.attrVectorBucketArn,
indexName: vectorIndex.indexName!,
},
},
});
Embedding モデルは Amazon Titan Embed Text V2(1024次元)を使用しています。
Gateway の作成
const gateway = new agentcore.Gateway(this, 'RagGateway', {
gatewayName: 'rag-gateway-kit',
description: 'RAG Gateway Kit: KB Retrieve + Web Fetch + AWS Knowledge',
authorizerConfiguration: agentcore.GatewayAuthorizer.usingAwsIam(),
});
@aws-cdk/aws-bedrock-agentcore-alpha の L2 構成を使っています。L2 のデフォルトは Cognito 認証ですが、Managed Harness は IAM で接続するため Cognito だとエラーになります。GatewayAuthorizer.usingAwsIam() で明示的に IAM を指定しています。
Lambda ターゲット(Knowledge Base Retrieve)
Lambda ターゲットは L2 の addLambdaTarget で追加できます。
gateway.addLambdaTarget('KBRetrieveTarget', {
gatewayTargetName: 'kb-retrieve',
lambdaFunction: kbRetrieveFn,
toolSchema: agentcore.ToolSchema.fromInline([
{
name: 'retrieve_documents',
description: 'ナレッジベースからドキュメントを検索します。',
inputSchema: {
type: agentcore.SchemaDefinitionType.OBJECT,
properties: {
query: { type: agentcore.SchemaDefinitionType.STRING, description: '検索クエリ' },
maxResults: { type: agentcore.SchemaDefinitionType.INTEGER, description: '最大取得件数' },
},
required: ['query'],
},
},
]),
});
ToolSchema.fromInline でツールの入力スキーマを定義しています。型の指定には SchemaDefinitionType の enum を使う必要があり、文字列リテラル("object" など)だとコンパイルエラーになる点に注意です。
Lambda 側の処理はこんな感じです。
def handler(event, context):
query = event.get('query', '')
kb_id = event.get('knowledgeBaseId', KNOWLEDGE_BASE_ID)
max_results = min(event.get('maxResults', 5), 100)
response = client.retrieve(
knowledgeBaseId=kb_id,
retrievalQuery={'text': query},
retrievalConfiguration={
'vectorSearchConfiguration': { 'numberOfResults': max_results }
},
)
results = []
for r in response.get('retrievalResults', []):
results.append({
'content': r['content'].get('text', ''),
'score': r.get('score'),
'location': r.get('location', {}),
})
return { 'results': results, 'count': len(results) }
Bedrock の Retrieve API を呼んで検索結果を返すだけのシンプルな実装です。RetrieveAndGenerate ではなく Retrieve を使っているのは、Managed Harness 側のモデルに回答を生成させるためです。
MCP Server on Runtime(Web ページ取得)
AgentCore Runtime 上で動く FastMCP サーバーを Gateway Target として登録します。
MCP Server のコードです。
mcp = FastMCP("web-tools", host="0.0.0.0", stateless_http=True)
@mcp.tool()
def fetch_webpage(url: str, max_length: int = 5000) -> str:
"""Fetch a web page and return its text content."""
response = httpx.get(url, follow_redirects=True, timeout=30, headers={
'User-Agent': 'AgentCore-WebTools/1.0',
})
response.raise_for_status()
html = response.text
text = re.sub(r'<script[^>]*>.*?</script>', '', html, flags=re.DOTALL)
text = re.sub(r'<style[^>]*>.*?</style>', '', text, flags=re.DOTALL)
text = re.sub(r'<[^>]+>', ' ', text)
text = re.sub(r'\s+', ' ', text).strip()
return text[:max_length]
FastMCP のデコレータでツールを定義しています。HTML タグを除去してテキストだけ返すシンプルな処理です。
CDK 側では、L2 の AgentRuntimeArtifact.fromAsset で Dockerfile のビルドから ECR プッシュまで自動でやってくれます。
const runtimeEndpointUrl = cdk.Fn.sub(
'https://bedrock-agentcore.${AWS::Region}.amazonaws.com/runtimes/arn%3Aaws%3Abedrock-agentcore%3A${AWS::Region}%3A${AWS::AccountId}%3Aruntime%2F${RuntimeId}/invocations',
{ RuntimeId: webToolsRuntime.agentRuntimeId },
);
const webToolsTarget = new bedrockagentcore.CfnGatewayTarget(this, 'WebToolsTarget', {
gatewayIdentifier: gateway.gatewayId,
name: 'web-tools',
targetConfiguration: {
mcp: {
mcpServer: { endpoint: runtimeEndpointUrl },
},
},
credentialProviderConfigurations: [{
credentialProviderType: 'GATEWAY_IAM_ROLE',
credentialProvider: {
iamCredentialProvider: { service: 'bedrock-agentcore' },
},
}],
});
エンドポイント URL は Runtime ARN を URL エンコードして埋め込む形式です。
MCP Server ターゲットの credentialProviderConfigurations で iamCredentialProvider のサブプロパティ(service)を指定する必要があります。L2 の GatewayCredentialProvider.fromIamRole() はこのサブプロパティを出力しないため、MCP Server ターゲットでは L1(CfnGatewayTarget)を使用します。Lambda ターゲットの場合は L2 で問題ありません。
もう1つ重要なのが依存関係です。
webToolsTarget.addDependency(
webToolsRuntime.node.defaultChild as cdk.CfnResource,
);
const gatewayDefaultPolicy = gateway.role.node.findChild('DefaultPolicy').node.defaultChild as cdk.CfnResource;
webToolsTarget.addDependency(gatewayDefaultPolicy);
Gateway Target の作成時に、Gateway はエンドポイントに接続してツール一覧を取得しようとします。このとき Runtime が READY 状態でないと失敗しますし、Gateway ロールに InvokeAgentRuntime 権限がないと接続自体ができません。両方の依存を明示的に追加しています。
AWS Knowledge MCP Server
AWS が公式でホストしている MCP Server です。エンドポイント URL を指定するだけで使えます。
new bedrockagentcore.CfnGatewayTarget(this, 'AWSKnowledgeTarget', {
gatewayIdentifier: gateway.gatewayId,
name: 'aws-knowledge',
targetConfiguration: {
mcp: {
mcpServer: { endpoint: 'https://knowledge-mcp.global.api.aws' },
},
},
});
認証不要のパブリックエンドポイントなので、credentialProviderConfigurations は省略しています。search_documentation / read_documentation / recommend / list_regions / get_regional_availability / retrieve_skill の6つのツールが自動で Gateway に登録されます。
Gateway にツールを追加するには
Gateway の良いところは、ターゲットを追加するだけで新しいツールを足せることです。ここでは Lambda ターゲットと MCP Server ターゲットの追加例を紹介します。
Lambda ツールの追加
L2 の addLambdaTarget で追加できます。
gateway.addLambdaTarget('MyNewTarget', {
gatewayTargetName: 'my-tool',
lambdaFunction: myFunction,
toolSchema: agentcore.ToolSchema.fromInline([{
name: 'my_tool',
description: 'ツールの説明',
inputSchema: {
type: agentcore.SchemaDefinitionType.OBJECT,
properties: { /* ... */ },
},
}]),
});
Lambda ターゲットは L2 だけで完結するのでシンプルですね。
MCP Server ターゲットの追加
前述の通り、MCP Server ターゲットは L1(CfnGatewayTarget)を使います。
new bedrockagentcore.CfnGatewayTarget(this, 'MyMcpTarget', {
gatewayIdentifier: gateway.gatewayId,
name: 'my-mcp-server',
targetConfiguration: {
mcp: {
mcpServer: {
endpoint: 'https://your-mcp-server.example.com',
},
},
},
credentialProviderConfigurations: [{
credentialProviderType: 'GATEWAY_IAM_ROLE',
credentialProvider: {
iamCredentialProvider: {
service: 'bedrock-agentcore',
},
},
}],
});
service の値は接続先によって変わります。AgentCore Runtime 上の MCP Server なら bedrock-agentcoreを指定します。
Target を追加して cdk deploy するだけで、既存の Managed Harness から新しいツールがすぐ使えるようになります。エージェント側を触る必要がないのは運用として嬉しいですね。
今回はシンプルにスタック内で直接書いていますが、Target の種類ごとにヘルパー関数や Construct を作っておくと、ツールが増えたときにもっと楽に管理できそうです。
デプロイ
npm install
npx cdk deploy --all
デプロイすると、sample-data 配下の AgentCore に関するサンプルドキュメントが S3 バケットに自動アップロードされます。ただし、S3 にファイルが置かれただけでは Knowledge Base には反映されません。コンソールまたは CLI から同期を実行する必要があります。
コンソールの場合は、Knowledge Base の画面から DataSource を選択して「Sync」ボタンを押します。
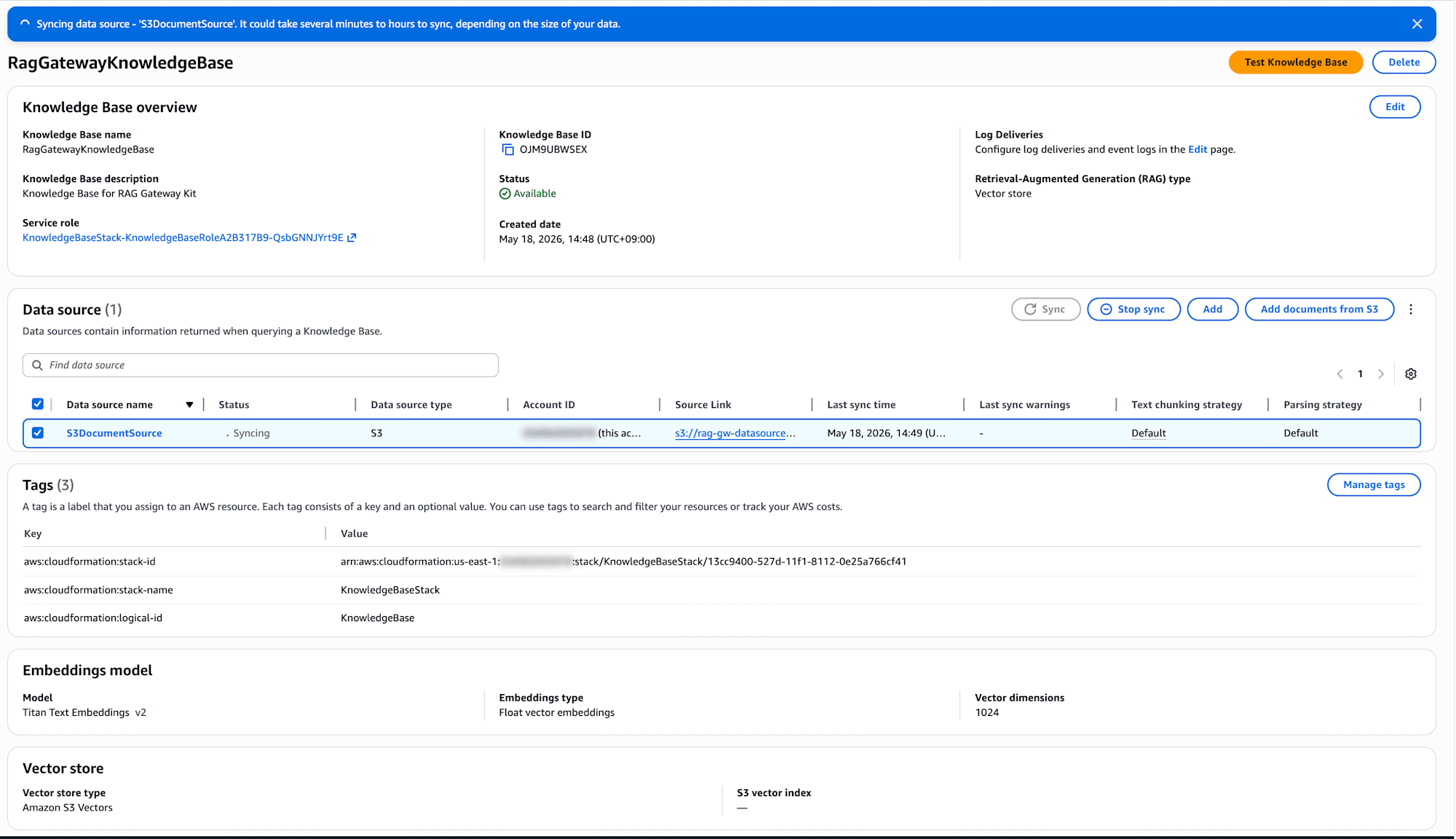
CLI の場合は下記コマンドです。KnowledgeBaseId と DataSourceId は CDK の Output から取得できます。
aws bedrock-agent start-ingestion-job \
--knowledge-base-id <KnowledgeBaseId> \
--data-source-id <DataSourceId>
自分のドキュメントを検索対象にしたい場合は、sample-data 配下にドキュメントを追加してcdk deployを実施するか、S3 バケットにアップロードしてから同期を実行してください。
aws s3 cp my-document.txt s3://<DataSourceBucketName>/
aws bedrock-agent start-ingestion-job \
--knowledge-base-id <KnowledgeBaseId> \
--data-source-id <DataSourceId>
動作確認
デプロイが完了したら、コンソールから Managed Harness を作成して動作確認してみます!
Managed Harness の作成
AWS コンソール → Bedrock → AgentCore → Managed Harness を開きます。
Advanced create harness から新規作成します。
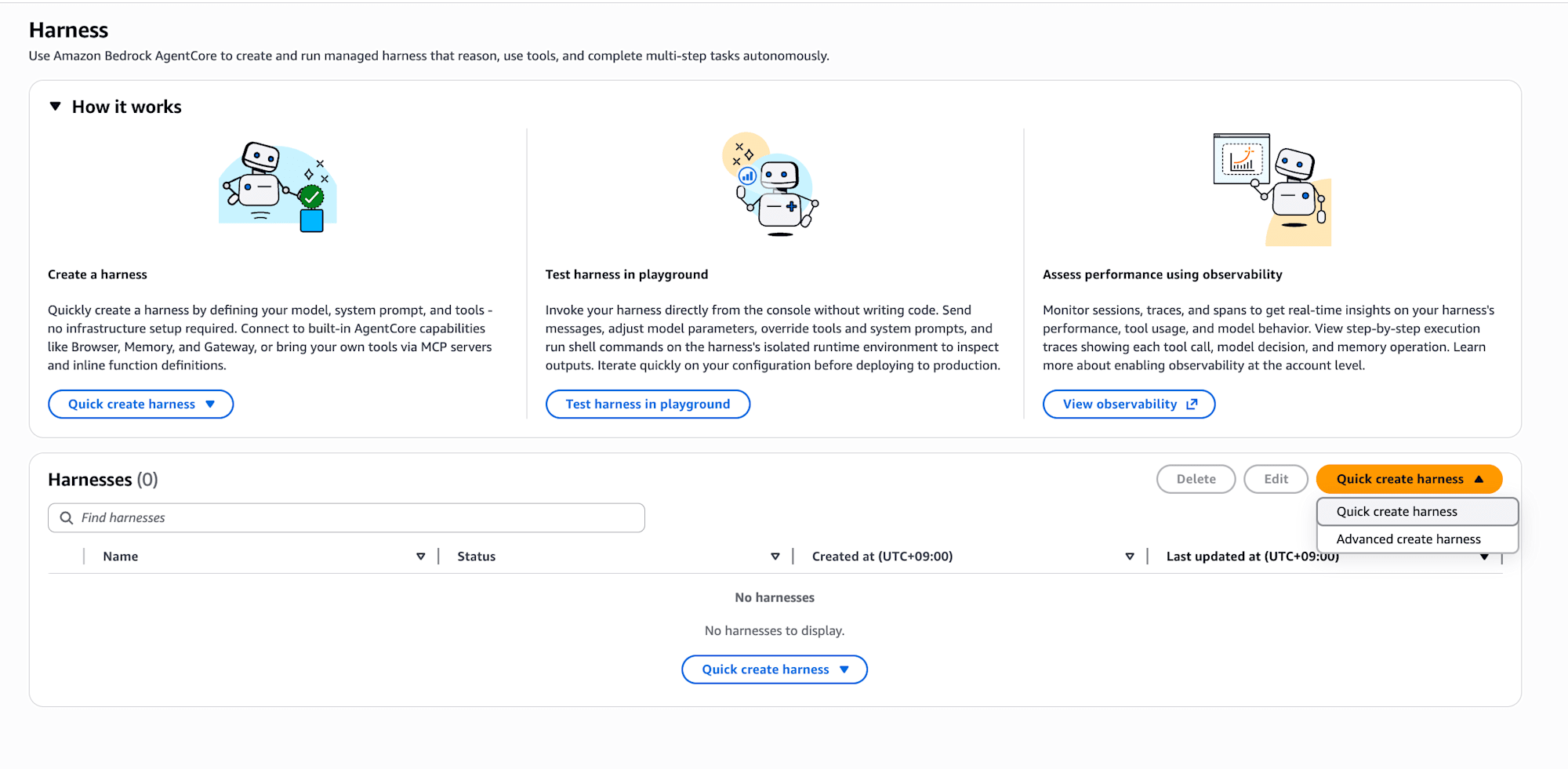
Tools セクションで Gateway を有効にし、デプロイした rag-gateway-kit を選択します。Gateway を1つ追加するだけで、3つの Target に含まれる全ツールが利用可能になります。
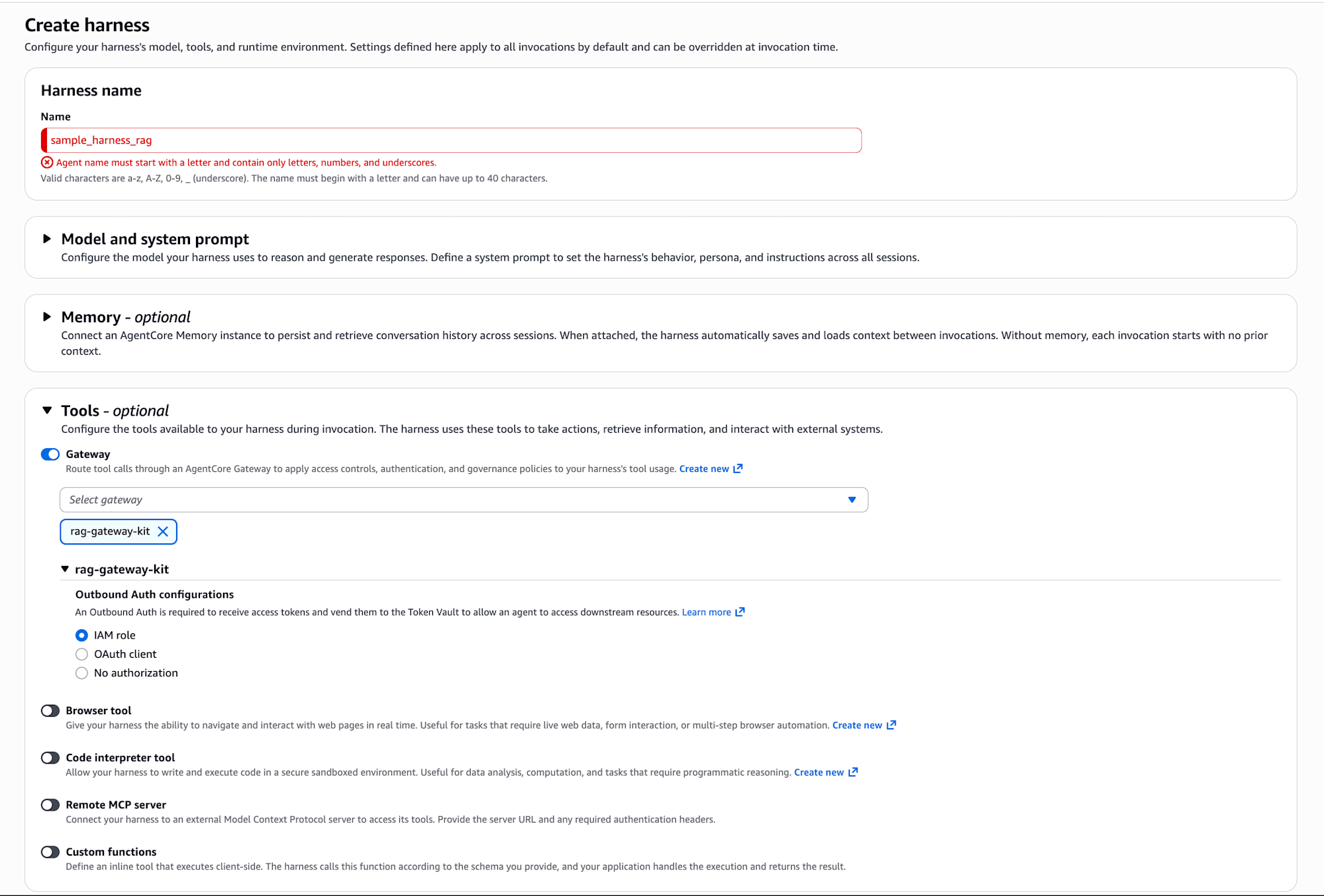
簡単に作れましたね。
作成が完了すると Status が Ready になります。「Test harness」から動作確認していきましょう。
Knowledge Base 検索(retrieve_documents)の確認
まずはナレッジベースの検索から試してみます。「AgentCore について RAG で検索して」と投げてみました。
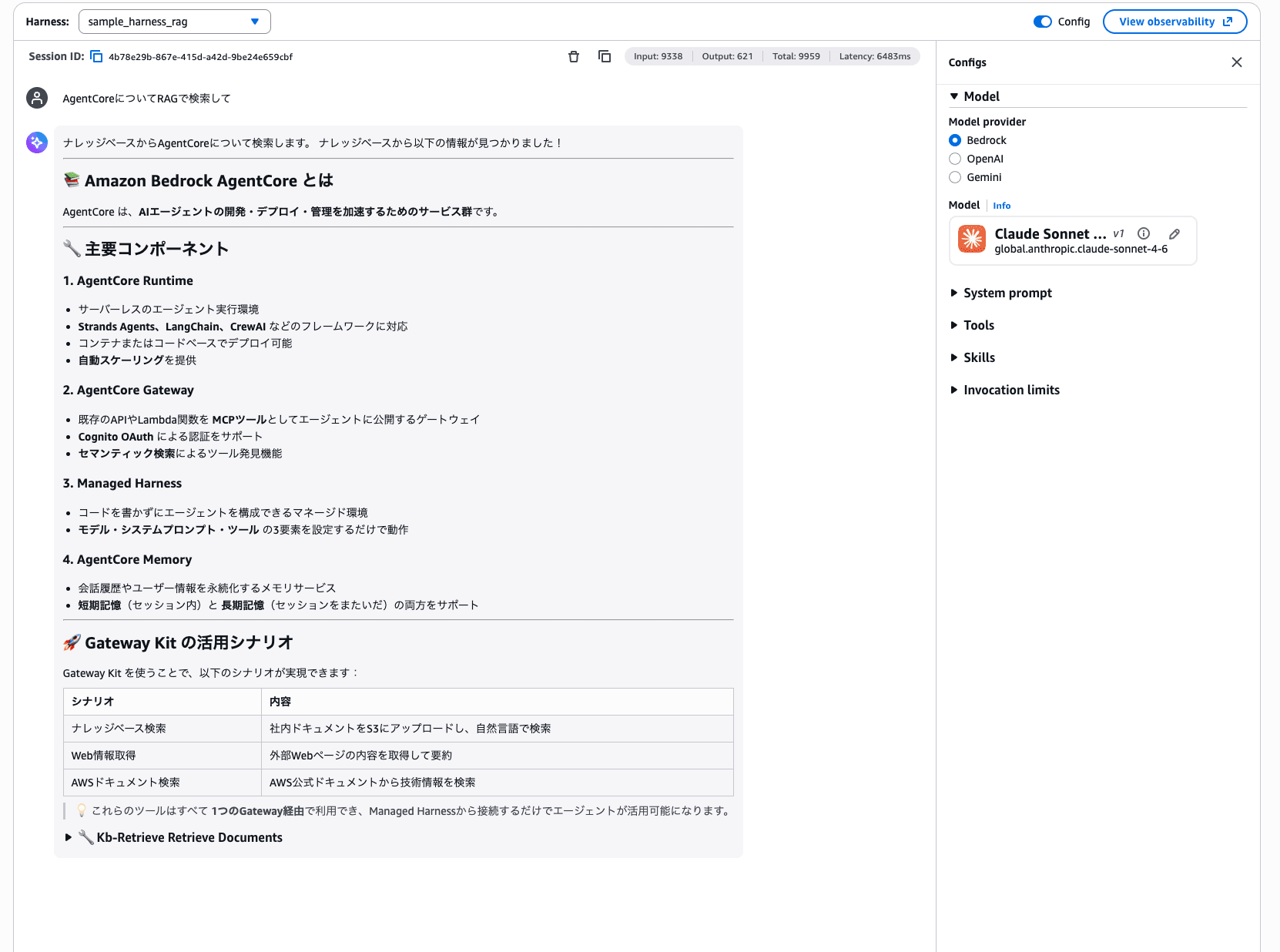
ナレッジベースから情報を取得して回答が生成されていますね!Gateway Kit の活用シナリオまで表にまとめてくれています。
Web ページ取得(fetch_webpage)の確認
次に Web ページの取得です。DevelopersIO の記事 URL を渡して内容を聞いてみます。
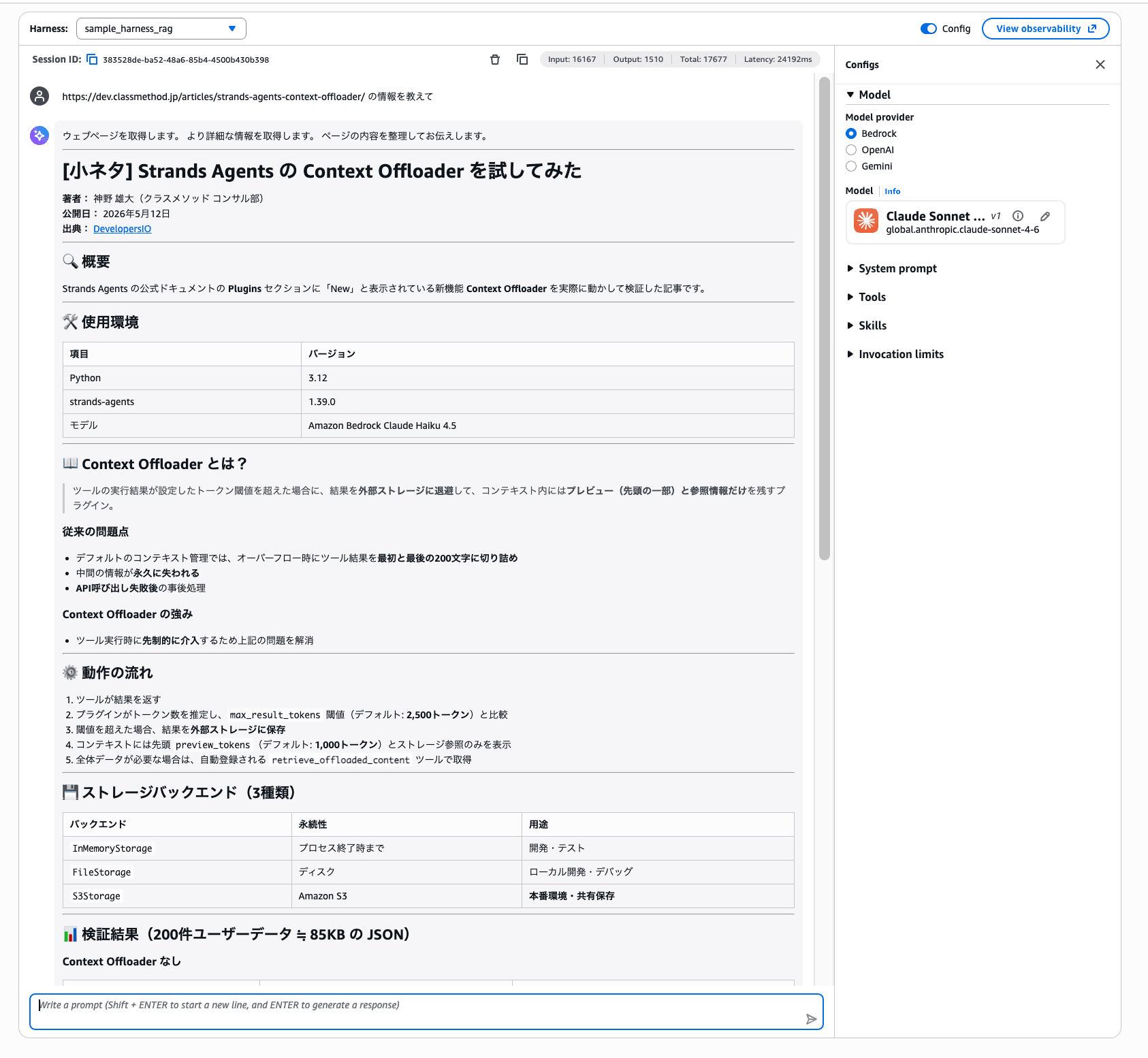
URL の内容を取得して、記事の概要・使用環境・検証結果まで構造化して返してくれていますね!
AWS ドキュメント検索(search_documentation 他)の確認
最後に AWS の公式ドキュメント検索です。「S3 について教えて」と投げてみます。
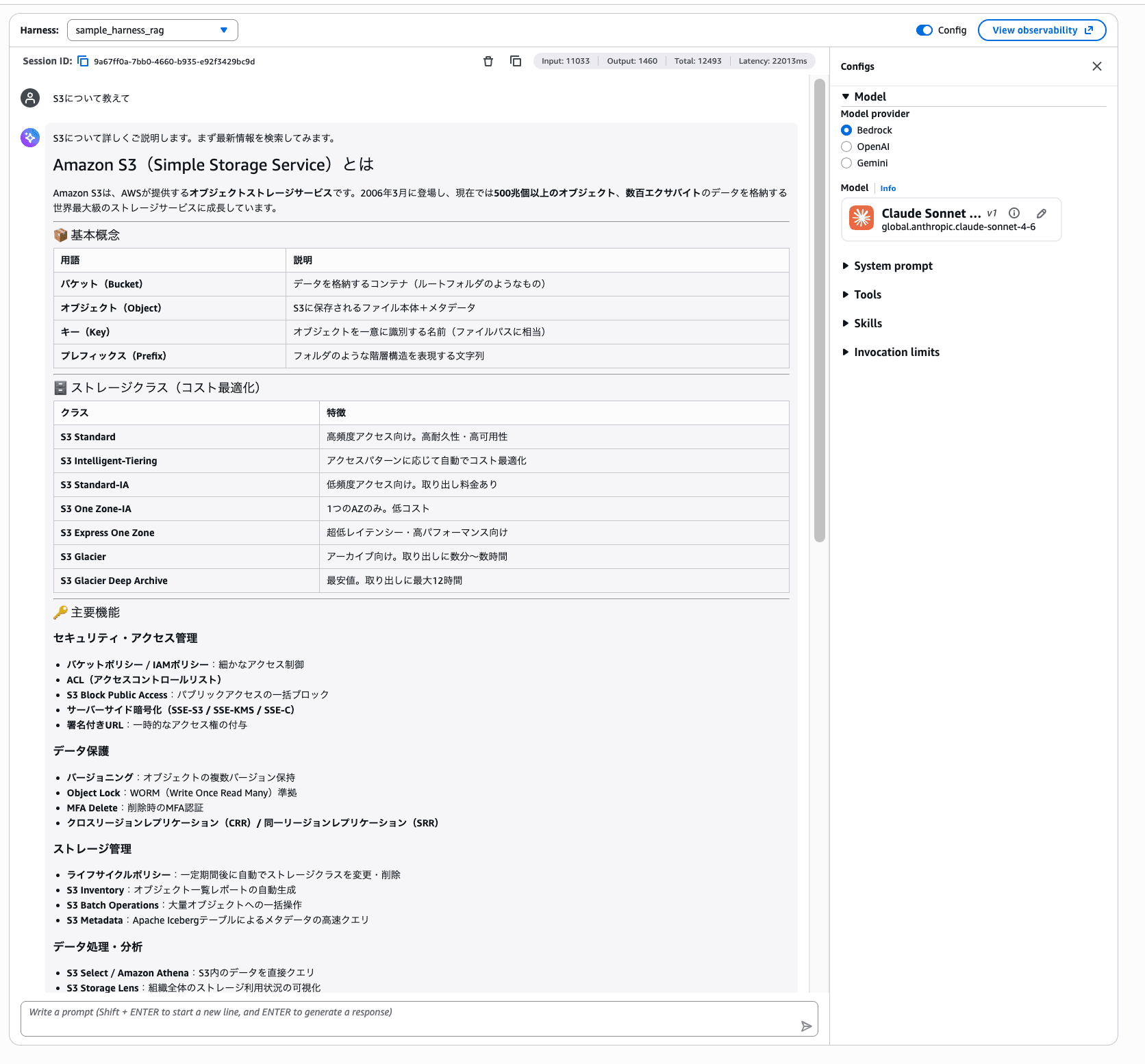
AWS Knowledge MCP Server 経由で公式ドキュメントの情報を取得して、S3 の基本概念からストレージクラス、最新アップデートまでまとめてくれました。ツール呼び出しの詳細を開くと、search_documentation が実行されているのが確認できます。
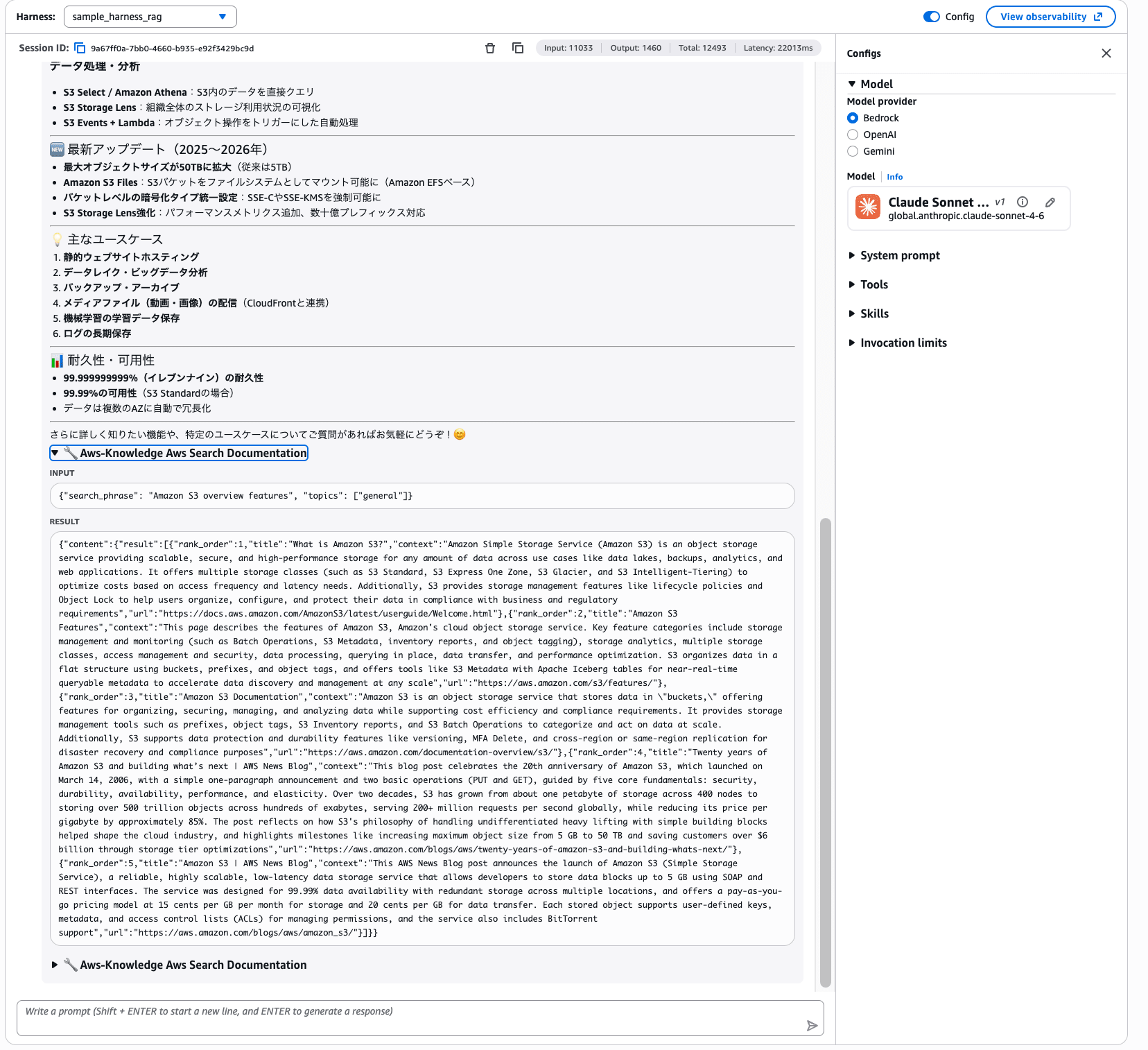
3つのツールすべてが Gateway 経由で問題なく動作していることが確認できました!
おわりに
Gateway に複数のツールを束ねて Managed Harness から使えるようにする、という構成を CDK で作成してみました。Lambda ターゲット / MCP Server on Runtime / 外部 MCP Server の3パターンを1つの Gateway に集約して多数のHarnessから手軽に利用できるのは良いですね。
Gateway に Target を追加するだけで新しいツールを足せるのも嬉しいポイントです。Harness利用者から多くニーズがあった機能はGatewayに追加するなども考えられそうです!(例えば、Braveを使ったWeb検索機能とか)
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございました!









