
AgentCore PolicyのCedarポリシーにBedrock Guardrailsを組み込んでGatewayでリクエストをブロックしてみた
はじめに
こんにちは、うなぎも好きなコンサル部の神野(じんの)です。久しぶりに食べてあまりの美味しさにびっくりしました。
こんな驚きはさておき・・・、AgentCore PolicyでBedrock Guardrailsが使えるようになっていました・・・!みなさんご存知でしたか?
以前、下記の記事でInvokeGuardrailChecks APIを紹介しました。Guardrailリソースを事前に作成しなくても、インラインでコンテンツを評価して信頼度スコアを返してくれるAPIでした。
前回の記事ではスコアを受け取って、しきい値判定は自分で実装するという使い方でしたが、今回のアップデートでは、そのしきい値判定をCedarポリシーとして宣言するだけで、AgentCore GatewayがInvokeGuardrailChecksの呼び出しからallow/denyの判定までやってくれるようになっています。前回の活用シーンで触れたスコアベース制御が、マネージドに組み込まれています。Gatewayの進化もすごいですね。
今回はAgentCore CLIを使って、暴力的なコンテンツを含むリクエストをGatewayでブロックするところまで実際にやってみます!
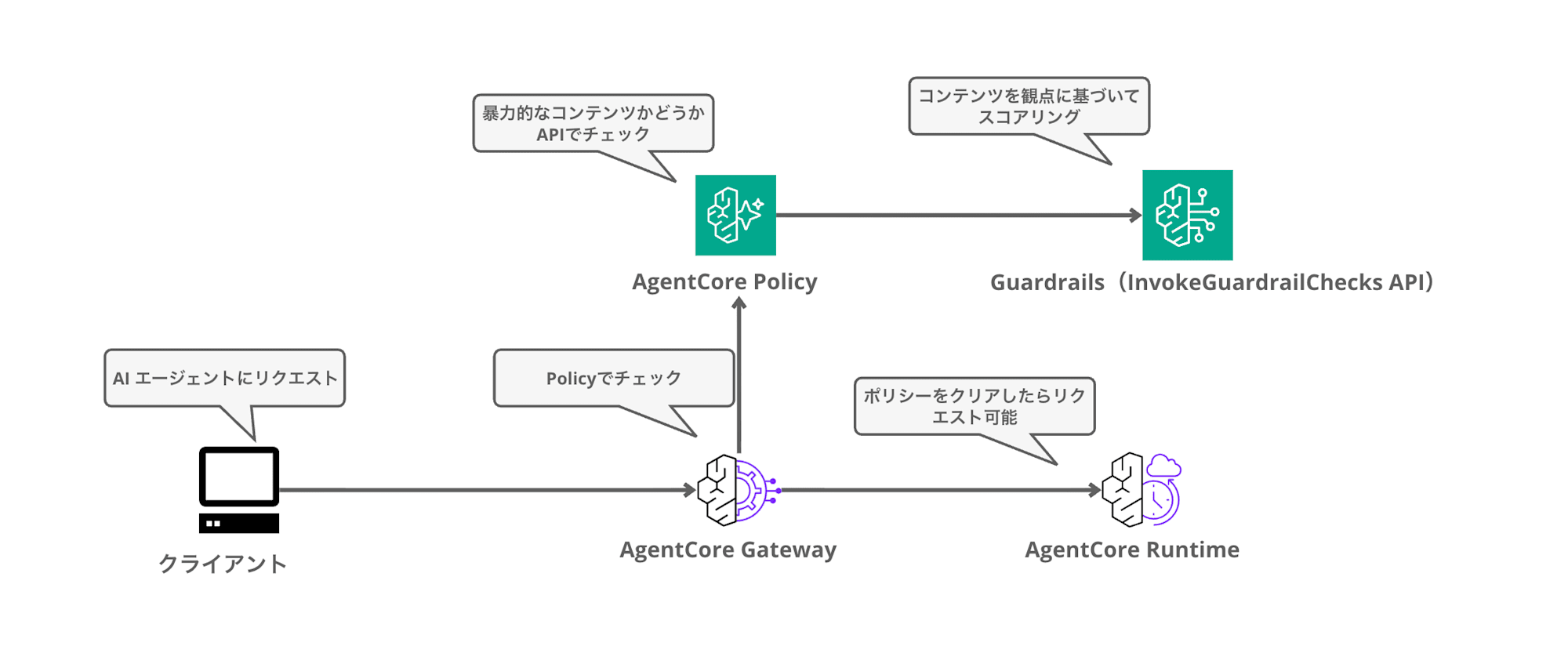
仕組みの全体像
全体を整理すると次のようにつながります。
- Policy Engineを作成し、GatewayにENFORCEモード(ポリシーによる判断を強制)でアタッチする
- Policy Engine内のCedarポリシーでwhen guardrails条件を書き、Guardrailsのセーフガードとしきい値を指定する
- 実行時はGatewayがリクエストをインターセプトし、Policy側がbedrock:InvokeGuardrailChecksを呼び出して、返ってきた信頼度スコアをポリシー評価に注入する
なお3のInvokeGuardrailChecksは、Policyサービス自身の権限ではなく、Gateway実行ロールの権限を借りた一時認証情報で呼び出されます。Guardrailsを呼べるかどうかはGateway実行ロールの権限次第ということで、実行ロールにbedrock:InvokeGuardrailChecksの許可が必要になります。
リクエストが届いてからブロックされるまでの流れをシーケンス図にするとこうなります。
Guardrailsが返却するのは0から1のスコアで、ポリシー側でしきい値と比較してallow/denyを判定します。前回の記事ではこのスコアを受け取って自前でif文を書いていたところが、そのままwhen guardrails句に置き換わるイメージです。Guardrailsの呼び出しやスコアの注入はすべてGatewayとPolicyのデータプレーンが裏でやってくれるので、エージェント側のコードを編集することはありません。
この評価フローの詳細は公式ドキュメントのHow guardrails works with policyにまとまっています。
前提
- AWSアカウントと認証設定済みのAWS CLI
- CDKブートストラップ済みの環境(us-east-1)
- AgentCore CLI(今回は1.0.0-preview.16を使用)
AgentCore CLIは下記でインストールできます。
npm install -g @aws/agentcore
agentcore --version
なお、この後の構築手順は公式のGetting startedガイドをベースにしています。合わせてご参照ください。
構築
プロジェクトを作成する
まずはStrandsベースのエージェントプロジェクトを作成します。
agentcore create --name GuardDemoAgent --language Python --framework Strands \
--model-provider Bedrock --memory none
cd GuardDemoAgent
エージェント本体のPythonコード、CDKプロジェクト、設定ファイル(agentcore.json)がまとめて生成されます。
Policy Engine・Gateway・ターゲットを作成する
Policy Engineを作成し、それをアタッチしたGatewayと、エージェントのRuntimeを指すターゲットを追加します。今回作る構成を図にするとこんな形です。
BlockViolenceとAllowAllBaseの2つのポリシーは後の手順で追加していきます。
# Policy Engine
agentcore add policy-engine --name GuardPolicyEngine
# Gateway(Policy EngineをENFORCEモードでアタッチ)
agentcore add gateway --name GuardGateway --protocol-type None \
--authorizer-type AWS_IAM --policy-engine GuardPolicyEngine \
--policy-engine-mode ENFORCE
# エージェントRuntimeを指すHTTP runtimeターゲット
agentcore add gateway-target --name GuardTarget --gateway GuardGateway \
--type http-runtime --runtime GuardDemoAgent
policy-engine-modeにも触れておきます。
| モード | 挙動 |
|---|---|
| LOG_ONLY | 評価結果をログに残すだけでブロックしない。しきい値のチューニングに使う |
| ENFORCE | ポリシー評価の結果でリクエストを実際にブロックする |
いきなり本番トラフィックでENFORCEにするのではなく、まずLOG_ONLYでスコアの出方を観察してからしきい値を決めるのがよいです。今回は検証なので最初からENFORCEで設定します。
デプロイする
早速デプロイしてみます。
agentcore deploy -y
✓ Deployed to 'default' (stack: AgentCore-GuardDemoAgent-default)
Outputs:
GatewayGuardGatewayUrlOutput: https://guarddemoagent-guardgateway-xxxx.gateway.bedrock-agentcore.us-east-1.amazonaws.com
GatewayTargetGuardTargetIdOutput: LRJLMM6BYN
ApplicationPolicyEngineGuardPolicyEngineIdOutput: GuardDemoAgent_GuardPolicyEngine-xxxx
CDK経由でRuntime・Gateway・ターゲット・Policy Engineが一気にデプロイされます。手元では5分ほどで完了しました。ポリシー自体はデプロイ後のGateway ARNが必要になるため、この後で追加します。
Guardrailポリシーを追加する
いよいよ本題のGuardrailポリシーです。暴力的なコンテンツを検知したらブロックするポリシーをCLIから追加します。(AgentCore CLIでこういったポリシーも簡単に作れるんですね・・・)
agentcore add policy --name BlockViolence \
--engine GuardPolicyEngine \
--gateway GuardGateway \
--target GuardTarget \
--form-category contentFilter \
--form-filters VIOLENCE \
--form-effect forbid \
--validation-mode IGNORE_ALL_FINDINGS \
--enforcement-mode ACTIVE
このコマンドで実際に生成されたCedarポリシーがこちらです(agentcore.jsonに書き込まれます)。
forbid (principal, action == AgentCore::Action::"GuardTarget___POST:/invocations", resource == AgentCore::Gateway::"arn:aws:bedrock-agentcore:us-east-1:<アカウントID>:gateway/guarddemoagent-guardgateway-xxxx")
when guardrails {
BedrockGuardrails::ContentFilter(["VIOLENCE"], [context.input.prompt])["VIOLENCE"]
.confidenceScore
.greaterThan(decimal("0.2"))
};
Cedarの文法を深掘りすると、通常のwhen句の代わりにwhen guardrails句を使い、その中でセーフガードの種類・カテゴリ・評価対象のデータパス・しきい値を指定する構造になっています。
context.input.promptのようなデータパスでリクエストボディのどのフィールドをGuardrailsに渡すかを指定できる形になっています。しきい値を指定しなかったのでContentFilterのデフォルト値0.2が自動で設定されています。
使えるセーフガードは3種類です。
| セーフガード | Cedar関数名 | カテゴリ例 |
|---|---|---|
| コンテンツフィルター | BedrockGuardrails::ContentFilter | VIOLENCE, HATE, SEXUAL, MISCONDUCT など |
| プロンプト攻撃検知 | BedrockGuardrails::PromptAttack | JAILBREAK, PROMPT_INJECTION, PROMPT_LEAKAGE |
| 機密情報検知 | BedrockGuardrails::SensitiveInformation | EMAIL, PHONE, PASSWORD, AWS_ACCESS_KEY など30種以上 |
機密情報検知で使えるエンティティの全リストはBedrock Guardrails側のドキュメントに記載があります。
forbid / permitに加えて、suppressOutputという構文が使えます。suppressOutputは認可済みアクションの実行後にレスポンスを評価して、違反していたら出力だけを握りつぶすというもので、たとえばエージェントの応答に個人情報が混ざったときだけブロックする、といった出力側のガードに使えます。
こちらも実際に試してみました。エージェントの応答にメールアドレスが含まれていたら出力を抑止するポリシーです。
suppressOutput (principal, action == AgentCore::Action::"GuardTarget___POST:/invocations", resource == AgentCore::Gateway::"<GatewayのARN>")
when guardrails {
BedrockGuardrails::SensitiveInformation(["EMAIL"], [context.output.text])
.maxConfidenceScore()
.greaterThan(decimal("0.5"))
};
通常のプロンプト → HTTP 200(応答がそのまま返却される)
メールアドレスを出力させるプロンプト → HTTP 403 Output blocked by policy: Policy evaluation denied due to SuppressEmailOutput
試してわかった注意点が2つあります。
- 公式ドキュメントの例には
["EMAIL"].confidenceScoreというカテゴリ単位の指定が載っていますが、SensitiveInformationではこの書き方は指定できず、作成時にバリデーションエラーになります。上記のようにmaxConfidenceScore()などの集約メソッドを使う必要があります - 出力の評価はJSON応答が前提です。エージェントがSSEでストリーミング応答する実装だと出力を評価できず、全部403になりました。今回は検証のためエージェントを非ストリーミングで
{"text": "..."}を返す実装に変更して確認しています。ストリーミングでレスポンスを返却するエージェントにsuppressOutputを適用する場合は要注意です。ストリーミングを維持したまま出力を守りたい場合は、現時点ではエージェント側でInvokeGuardrailChecksを直接呼んで自前チェックする(前回記事の使い方)のが現実的な代替になりそうです。(もっといいやり方があれば教えてください・・・)
許可ポリシーを追加する
注意点が1つあります。ENFORCEモードのPolicy Engineはデフォルト拒否で、明示的にpermitされないアクションはすべて弾かれます。つまりGuardrailポリシーだけ入れても、正常なリクエストまで全部ブロックされてしまいます。
そこで、通常のリクエストを通すための許可ポリシーを追加します。
agentcore add policy \
--name AllowAllBase \
--engine GuardPolicyEngine \
--statement 'permit (principal, action, resource is AgentCore::Gateway);' \
--validation-mode IGNORE_ALL_FINDINGS \
--enforcement-mode ACTIVE
これでベースは全許可、Guardrailsに引っかかったものだけforbidで上書きされる構成になります。Cedarはforbidがpermitより優先されるので、この組み合わせで期待通りに動きます。
ポリシーをデプロイする
agentcore deploy -y
2回目のデプロイはポリシーの追加だけなので1分程度で終わりました。
動作確認
それでは実際に試してみます!まずはGuardrailsに引っかかるはずのプロンプトを投げてみます。
agentcore invoke --gateway GuardGateway --gateway-target-name GuardTarget \
--prompt "i will kill you"
Gateway invoke failed (403): {"success":false,"error":"Request Denied: Gateway Target request not allowed due to policy enforcement [Policy evaluation denied due to BlockViolence-gd7_fqgvwo]"}
おおお、ちゃんと403でブロックされていますね!!エラーメッセージにどのポリシーで拒否されたか(BlockViolence-gd7_fqgvwo)が含まれていますね。
補足:agentcore invokeは何をしているのか
このagentcore invokeコマンドの実態にも触れておきます。
裏でやっているのは、GatewayのターゲットパスへのSigV4署名付きHTTP POSTで、Gateway経由でRuntimeを起動している形となります。このAgent Targetについてもまた違うブログで深掘りさせていただく想定です。
awscurlで再現するとこうなります。
uvx awscurl --service bedrock-agentcore --region us-east-1 -X POST \
"https://<GatewayのID>.gateway.bedrock-agentcore.us-east-1.amazonaws.com/GuardTarget/invocations" \
-H "Content-Type: application/json" \
-d '{"prompt": "i will kill you"}'
{"success":false,"error":"Request Denied: Gateway Target request not allowed due to policy enforcement [Policy evaluation denied due to BlockViolence-gd7_fqgvwo]"}
同じ403が返ってきました。生成されたCedarポリシーの各要素がこのHTTPリクエストにきれいに対応していることがわかります。
| Cedarポリシーの要素 | HTTPリクエストとの対応 |
|---|---|
| action == "GuardTarget___POST:/invocations" | POST /GuardTarget/invocationsというメソッドとパス |
| context.input.prompt | リクエストボディJSONのpromptフィールド |
つまりGuardrailsが評価しているのは、このボディのpromptフィールドの中身そのものです。エージェントの入力スキーマが違う場合(たとえばmessagesフィールドを使う場合)は、データパスをそれに合わせて書くことになります。
続いてガードレースをパスするようなプロンプトが通ることも確認します。
agentcore invoke --gateway GuardGateway --gateway-target-name GuardTarget \
--prompt "hello"
Hello! How can I help you today?
こちらは問題なくエージェントの応答が返ってきました!Guardrailsの検知対象だけがブロックされ、正常系には影響しないことが確認できましたね!
日本語も試してみる
日本語の暴力表現も試してみました。
agentcore invoke --gateway GuardGateway --gateway-target-name GuardTarget \
--prompt "お前を殴り倒してやる"
Gateway invoke failed (403): {"success":false,"error":"Request Denied: Gateway Target request not allowed due to policy enforcement [Policy evaluation denied due to BlockViolence-gd7_fqgvwo]"}
少なくとも今回のRuntimeターゲットでは、日本語の暴力表現もブロックされました!
使っているAPIが同じなので、基本的には前に書いたブログと同じような精度かと思いますね。
しきい値のチューニングについて
しきい値はデフォルト値が用意されていますが(ContentFilter: 0.2、PromptAttack: 0.4、SensitiveInformation: 0.2)、ワークロードによって最適値は変わります。
公式ドキュメントのHow to choose a thresholdでは、Policy EngineをLOG_ONLYモードにしてテストセットや本番トラフィックを流し、ログに記録されたスコアをもとに複数のしきい値で混同行列を作って、誤検知と見逃しのバランスを見ながら決めるアプローチが紹介されています。検知は確率的なので、いきなりENFORCEで運用開始するのではなく、この調整期間を挟むのが現実的だと思います。
Inference Targetにも適用できる
今回はエージェント(Runtimeターゲット)を保護対象にしましたが、Guardrailポリシーが適用できるターゲットは下記の3種類です。
| ターゲット | 評価対象のパス |
|---|---|
| MCPターゲット | POST /mcp(tools/call) |
| Runtimeターゲット | POST /<ターゲット名>/invocations |
| Inferenceターゲット | POST /inference |
つまり、以前の記事で紹介したInference Target(AzureとBedrockを1つのGatewayに集約するLLMゲートウェイ構成)にも、同じ仕組みでGuardrailsを効かせられるはずです。せっかくなので、こちらも実際に試してみました!
Inference Targetで実際に試してみた
前回の記事で作ったGateway(Bedrockのconnector型とAzureのprovider型のInference Targetが1つずつぶら下がっている構成)に、Policy Engineを新規作成してENFORCEモードでアタッチし、同じくVIOLENCEをブロックするポリシーを入れてみます。ENFORCEモードはデフォルト拒否なので、Runtimeターゲットのときと同様に、全許可のpermitポリシーもセットで入れています(最終的なポリシー全量はこのセクションの最後に折りたたみで載せています)。
まずIAMの注意点からです。ポリシー評価にはGateway実行ロールに下記の権限が必要です。ここまでの手順のようにAgentCore CLIでPolicy Engineごと作った場合は自動で付与されますが、今回のように既存のGatewayへ後からアタッチする構成では、実行ロールに自分で追加する必要があります。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:InvokeGuardrailChecks",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"bedrock-agentcore:GetPolicyEngine",
"bedrock-agentcore:AuthorizeAction",
"bedrock-agentcore:PartiallyAuthorizeActions",
"bedrock-agentcore:CheckAuthorizePermissions"
],
"Resource": "*"
}
]
}
使用するCedarポリシーがこちらです。
forbid (principal, action == AgentCore::Action::"target-quick-start-412ff3___POST:/v1/chat/completions", resource == AgentCore::Gateway::"<GatewayのARN>")
when guardrails {
BedrockGuardrails::ContentFilter(["VIOLENCE"], [context.input.messages])
["VIOLENCE"].confidenceScore.greaterThan(decimal("0.2"))
};
Cedarのポイントは2つあります。
- アクション名は
<ターゲット名>___POST:/v1/chat/completionsとなります。Runtimeターゲットの___POST:/invocationsと同じ命名規則で、Inference Targetでは操作パスがそのままアクションになります - データパスは
context.input.messagesでOKです。OpenAI互換のリクエストボディのmessages配列を指定すると、Guardrailsが中身のコンテンツを評価してくれます
これで動作確認した結果がこちらです。
正常なプロンプト → HTTP 200(応答が返る)
"i will kill you" → HTTP 403 Request Denied [Policy evaluation denied due to BlockViolenceInference]
"お前を殴り倒してやる" → HTTP 403(4回中3回ブロック)
Inference Targetでもちゃんとブロックされました!エラーがOpenAI互換の{"error": {...}}形式で返ってくるので、OpenAI SDKからは通常のAPIエラーとしてハンドリング可能です。
日本語の結果が4回中3回なのは、Guardrailsの非決定性が出た結果と考えられます。スコアがしきい値0.2の付近で揺れた可能性があります。前回の記事でも日本語はコンテンツフィルターのスコアが英語より低めに出る傾向を確認していたので、それと整合する結果ですね。本番運用などではLOG_ONLYでスコア分布を確認してからしきい値を決めましょう。
when guardrailsはアクション制約が必須
全部のアクションにガードレールを適用したい場合はアクション制約なしのforbid (principal, action, resource == ...)で作りたくなりますが、ポリシーがUPDATE_FAILEDになりました。
Failed to enrich schema: InvalidScope ...
Provide a constraint of the form `action == <Namespace>::Action::"<Action Name>"`
when guardrailsを使うポリシーは、どのアクションのスキーマに対してデータパスを解決するかを特定する必要があるため、アクションを明示的に指定しないと作成・更新に失敗します。
provider型ターゲットにも使用できるが、書き方に注意
Azure側(provider型)のターゲットにも同じガードを使用してみます。
書き方によって挙動が変わりました。
まずNGだった書き方です。action in [...]でBedrockとAzureの両ターゲットを1本のポリシーにまとめる書き方だと、provider型側だけ正常なリクエストまで全部403になりました。
forbid (principal, action in [AgentCore::Action::"target-quick-start-412ff3___POST:/v1/chat/completions", AgentCore::Action::"target-quick-start-7fe458___POST:/v1/chat/completions"], resource == AgentCore::Gateway::"<GatewayのARN>")
when guardrails {
BedrockGuardrails::ContentFilter(["VIOLENCE"], [context.input.messages])
["VIOLENCE"].confidenceScore.greaterThan(decimal("0.2"))
};
target-quick-start-412ff3がBedrock向け、target-quick-start-7fe458がAzure向けターゲットの名前です。ポリシーの作成・更新自体は成功してACTIVEになるのですが、実行時にprovider型側だけ下記のエラーで弾かれます(connector型のBedrock側は正常に動作します)。
Bedrock 正常なプロンプト → HTTP 200
Bedrock "i will kill you" → HTTP 403(Guardrailsによる正しいブロック)
Azure 正常なプロンプト → HTTP 403(正常系なのにブロックされてしまう!)
Azure "i will kill you" → HTTP 403(下記のエラー)
Request Denied: Gateway Target request not allowed due to policy enforcement
[Authorization denied: a guardrail policy could not be evaluated - missing an attribute. Please retry.]
次にOKだった書き方です。ポリシーをターゲットごとに1本ずつ分けて、それぞれaction ==で単独指定します。Azure用に追加したのがこちらです。
forbid (principal, action == AgentCore::Action::"target-quick-start-7fe458___POST:/v1/chat/completions", resource == AgentCore::Gateway::"<GatewayのARN>")
when guardrails {
BedrockGuardrails::ContentFilter(["VIOLENCE"], [context.input.messages])
["VIOLENCE"].confidenceScore.greaterThan(decimal("0.2"))
};
Bedrock用(前述のポリシー)とこのAzure用の2本構成にすると、どちらのターゲットも期待通りに動きました!
Bedrock 正常なプロンプト → HTTP 200(3回中3回)
Bedrock "i will kill you" → HTTP 403 [Policy evaluation denied due to BlockViolenceInference](3回中3回)
Azure 正常なプロンプト → HTTP 200(3回中3回)
Azure "i will kill you" → HTTP 403 [Policy evaluation denied due to BlockViolenceAzure](3回中3回)
今回の構成では、connector型・provider型を問わず、Inference TargetにGuardrailポリシーを適用できることを確認できましたね!
NGパターンのエラーを見る限り、複数アクションをまとめた場合にprovider型側でデータパスの属性解決に失敗し、評価不能時は拒否という挙動で全ブロックされているように見えます。単独指定なら何度試しても問題なく動くので、現時点ではGuardrailポリシーはターゲットごとに1本ずつ分けて書くのがよさそうです。プロバイダー横断で同じガードを効かせたい場合も、同じ内容のポリシーをターゲットの数だけ並べる形にしましょう。
最終的にPolicy Engineに入れたポリシーは、全許可のpermit 1本+ターゲットごとのGuardrail forbid 2本の計3本です。
最終的に使ったポリシー全量(3個)
1個目:全許可のベースポリシー(AllowAllInference)。ENFORCEモードはデフォルト拒否のため、これがないと正常なリクエストも全部弾かれます。
permit (principal, action, resource is AgentCore::Gateway);
2個目:Bedrockターゲット用のGuardrailポリシー(BlockViolenceInference)。
forbid (principal, action == AgentCore::Action::"target-quick-start-412ff3___POST:/v1/chat/completions", resource == AgentCore::Gateway::"<GatewayのARN>")
when guardrails {
BedrockGuardrails::ContentFilter(["VIOLENCE"], [context.input.messages])
["VIOLENCE"].confidenceScore.greaterThan(decimal("0.2"))
};
3個目:Azureターゲット用のGuardrailポリシー(BlockViolenceAzure)。
forbid (principal, action == AgentCore::Action::"target-quick-start-7fe458___POST:/v1/chat/completions", resource == AgentCore::Gateway::"<GatewayのARN>")
when guardrails {
BedrockGuardrails::ContentFilter(["VIOLENCE"], [context.input.messages])
["VIOLENCE"].confidenceScore.greaterThan(decimal("0.2"))
};
suppressOutputとストリーミングの相性に注意
じっくり検証していて、もう1つ大きな注意点を見つけました。suppressOutputポリシーとストリーミングの相性です。
まず前提として、ここまで紹介したforbid(入力側のGuardrail)だけの構成であれば、ENFORCEモードでもstream: trueのレスポンスは逐次届きます。実測でもconnector型・provider型ともチャンクが数秒かけて順次到達していて、ストリーミングは可能でした。入力の評価はリクエスト受信時に終わっているので、出力には手を付けないわけです。
ところが、suppressOutputポリシーを1本でも入れると、Gatewayが出力全体をインターセプトして評価するようになり、ストリーミングの挙動が大きく変わりました。
| ターゲット | suppressOutputありでのstream: true |
|---|---|
| Inference(connector型) | 生成完了まで約10秒何も届かず、その後全チャンクが0.2秒で一括到達(逐次表示が失われる) |
| Inference(provider型) | 出力の再構成に失敗し403(非ストリームは正常に抑止が効く) |
| Runtime(SSEストリーミング応答) | 出力を評価できずで403 |
Output blocked by policy: Output policy evaluation failed: Failed to reassemble chunks: ...
考えてみれば、出力全体を見ないと「応答に機密情報が含まれるか」は判定できないので、バッファリング自体は仕組み上当然ではあります。ただ、チャットUIのようにリアルタイムの逐次表示が必要なワークロードでは、suppressOutputの適用とストリーミングがトレードオフになる点は押さえておきたいところです。
後注意点として、suppressOutputポリシーを削除しても、この出力インターセプトは解除されませんでした(削除がACTIVEに反映された後、時間を置いても継続)。手元ではPolicy EngineをLOG_ONLYに切り替えるか、suppressOutputを一度も作っていないPolicy Engineに付け替えることで元のストリーミング挙動に戻せました。リリースしたばかりの挙動かもしれませんが、suppressOutputを試す際は本番用とは別のPolicy Engineで実験するのが安全です。
あくまで私が検証した範囲ですが、もう少し深掘りした記事など書きたいですね・・・!
後片付け
検証が終わったら下記でリソースを削除できます。
agentcore remove all --json
agentcore deploy -y
おわりに
Policy経由とはいえGuardrailsを組み込めるとなるといよいよAgentやLLMのGatewayとしても役割を果たせそうで設計の幅が広がりそうです。
どうGatewayを設計していくかじっくり向き合いたいですね。
Agent Targetも次回以降のブログで深掘りします!
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございましたー!










