![[レポート]AI Agents in Manufacturing: Building Intelligent Data Workflowsに参加してきました #IND305 ##AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[レポート]AI Agents in Manufacturing: Building Intelligent Data Workflowsに参加してきました #IND305 ##AWSreInvent
はじめに
こんにちは、おおはしりきたけです。3回目のre:Invent 2025に参加しております。
今回は、製造業でAI Agentをどのような構成で実現しているかが気になったので、本セッションを受けてきました。セッション概要は以下になります。
セッション概要
Manufacturing organizations often struggle with data silos and lengthy analysis cycles that delay decision-making. This session introduces Agentic Data Exploration using Amazon Bedrock Agents to automate analysis across various data sources. We'll explore how multi-agent workflows can seamlessly integrate structured databases, analytics exports, unstructured text, multimedia, and APIs for near real-time insights. Learn practical implementation patterns for orchestrating specialized AI agents in distributed problem solving scenarios. We will demonstrate how to reduce analysis timeframes from months to minutes while maintaining governance standards, ultimately accelerating operational decision-making in manufacturing environments.
日本語訳
製造業は、データサイロ化や長期にわたる分析サイクルに悩まされることが多く、意思決定の遅延につながっています。このセッションでは、Amazon Bedrock エージェントを用いた Agentic Data Exploration について紹介し、様々なデータソースにわたる分析を自動化します。マルチエージェントワークフローが、構造化データベース、分析エクスポート、非構造化テキスト、マルチメディア、API をシームレスに統合し、ほぼリアルタイムのインサイトを実現する方法を探ります。分散型問題解決シナリオにおいて、専門の AI エージェントをオーケストレーションするための実践的な実装パターンを学びます。ガバナンス基準を維持しながら分析期間を数か月から数分に短縮し、製造環境における運用上の意思決定を加速する方法を紹介します。
登壇者
- Shawn Justice, Field CTO/Principal Solution Architect, AWS
- Rob Sable, Sr Solutions Architect, AWS
セッションレポート
1. 製造業が直面するデータの課題
製造業の現場では、データへのアクセス、コンテキストの欠如、リアルタイム性の確保、そして運用データの活用において多くの課題を抱えています。 スピーカーは、レガシーシステムやExcelによる管理、サイロ化されたデータ「デジタルカオス」が、意思決定を遅らせている現状を指摘しました。

2. 従来のアプローチの限界
従来のETLプロセスは非常に手間がかかり、硬直的です。 スピーカーは実体験として、ある製品の不具合の根本原因分析に「31日間」かかったエピソードを紹介しました。データの特定から正規化、スキーマ定義、スクリプト開発といった従来のプロセスを経ている間に、不良品がさらに25万個製造されてしまうという、ビジネス上の痛みを伴う例です。

3. 新しいアプローチ:Agentic Data Exploration
この課題に対し、AWSは「Agentic Data Exploration(エージェント型データ探索)」を提唱しています。これは以下の3つのステップで構成されます。
- ツールを用いてデータソースに統合する
- 専門化されたエージェントでデータにアクセスする
- エージェントに指示を与え、必要なインサイト(洞察)を生成させる

エージェントを用いたワークフローでは、LLM(大規模言語モデル)を中心に、「メモリ(記憶)」「ツール」「ゴール」、そして「アクション」と「観察」を組み合わせることで、自律的な問題解決を可能にします。
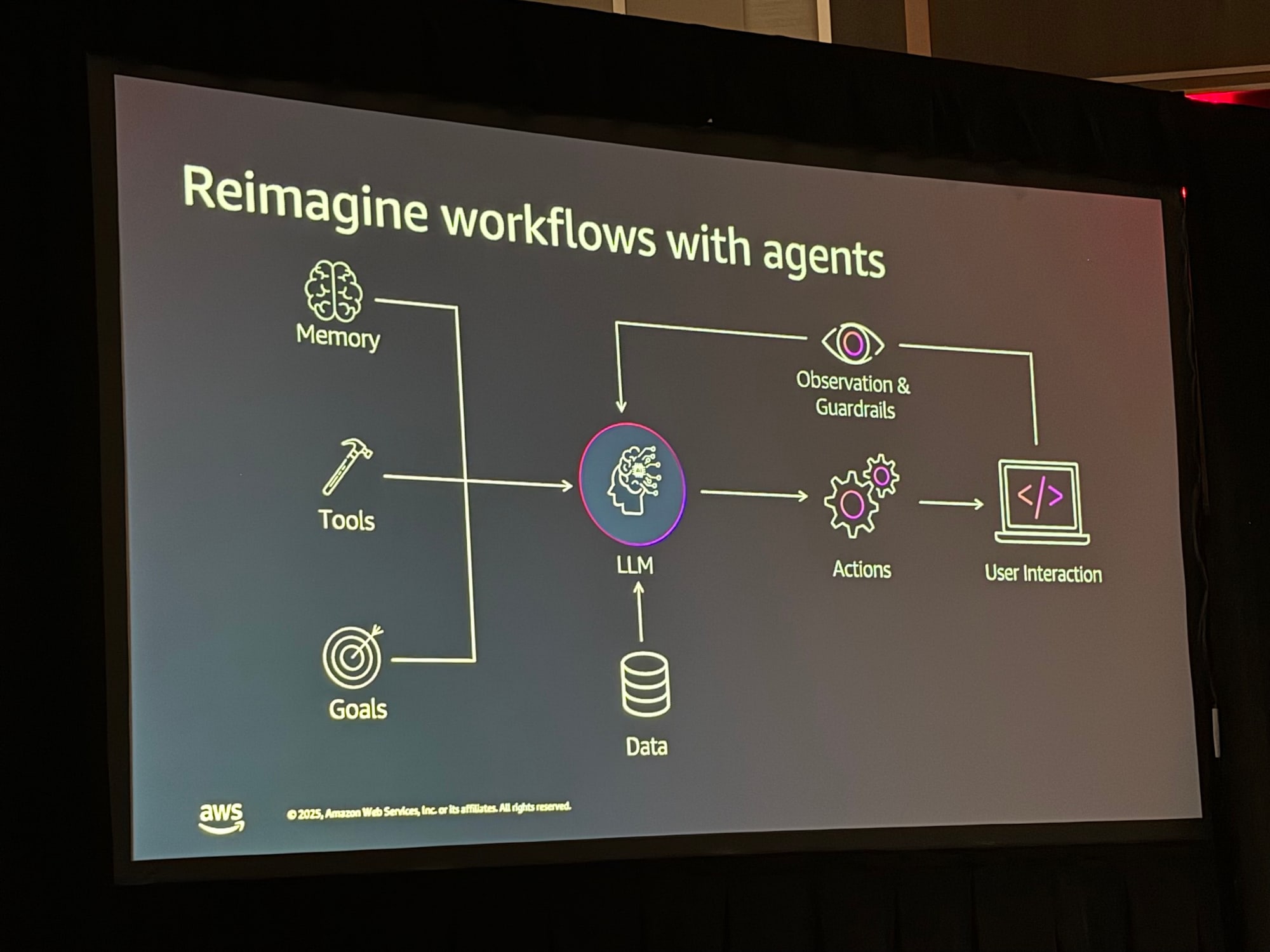
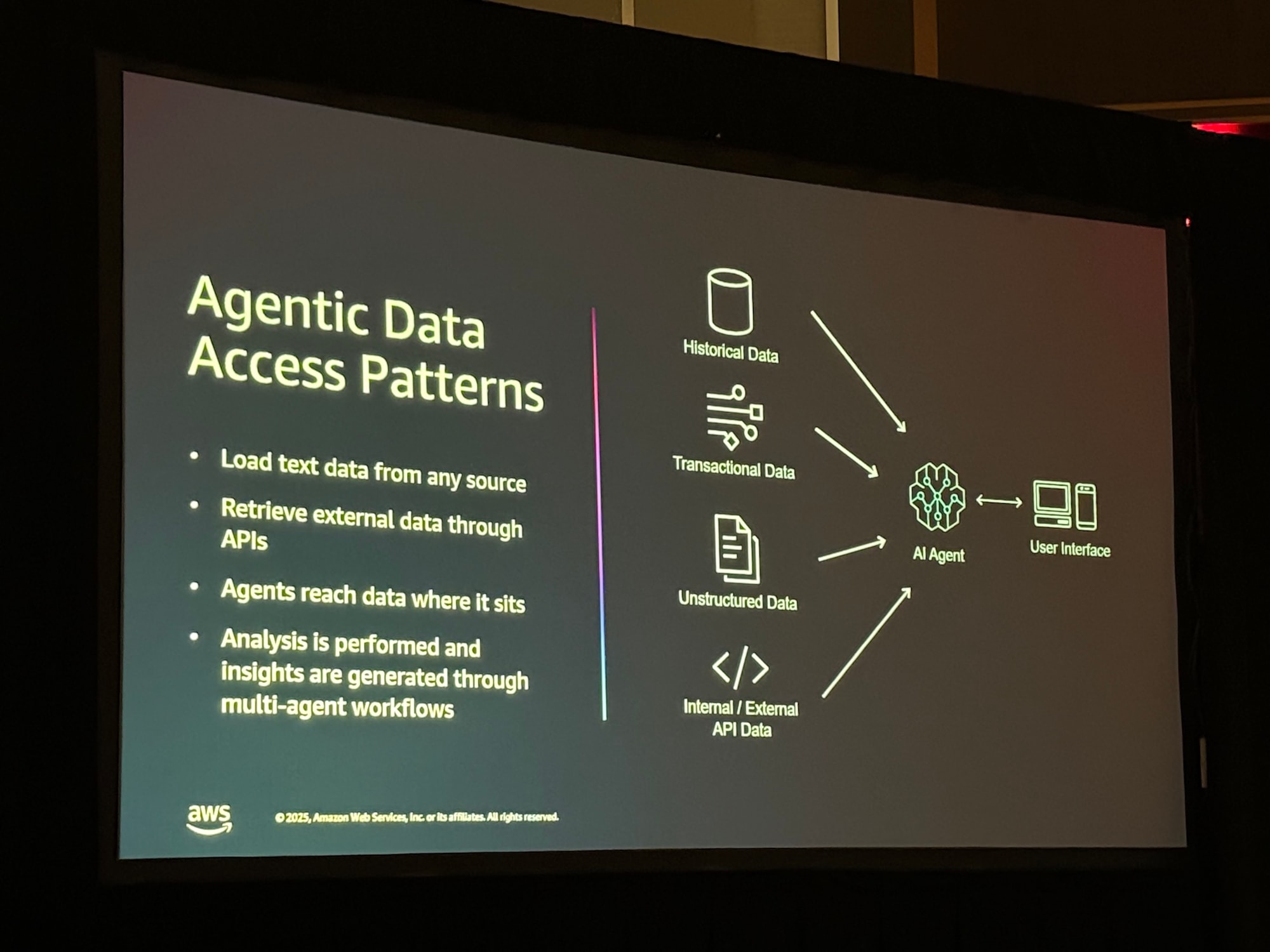
4. エージェントによるデータアクセスパターン
このアーキテクチャでは、データの所在や形式を問わず、エージェントが柔軟にアクセスします。 「過去のデータ」「トランザクションデータ」「非構造化データ」「APIデータ」を統合し、マルチエージェントワークフローを通じて分析を実行します。
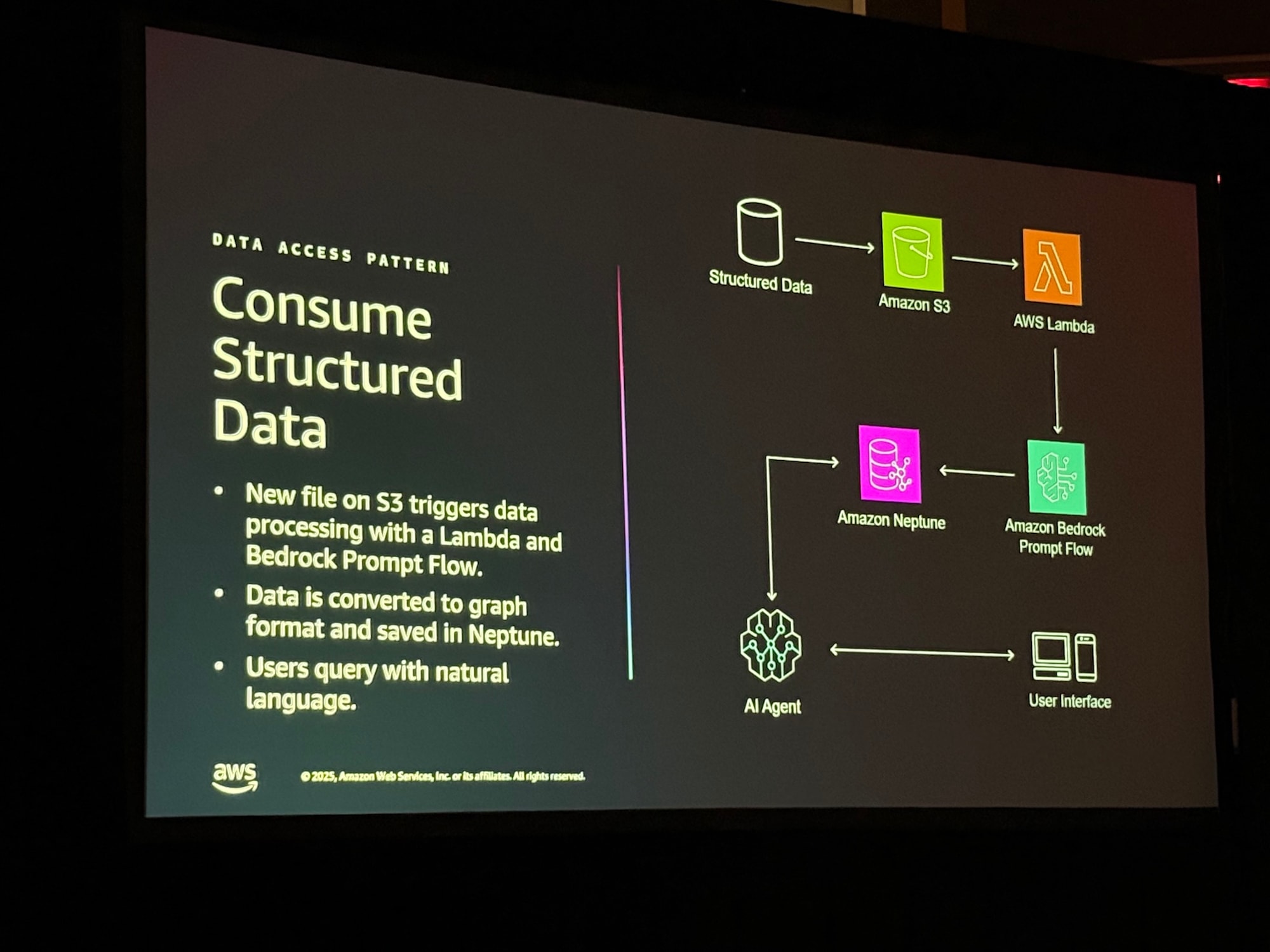
パターンA:構造化データの取り込み (Consume Structured Data)
特にリレーショナルデータベースやCSVなどの構造化データに対するアプローチとして、Amazon Neptune の活用が紹介されました。 S3に新しいCSV等のファイルが配置されると、Lambdaと Amazon Bedrock Prompt Flow がトリガーされ、データをグラフ形式に変換してNeptuneに保存します。これにより、複雑な結合処理を事前に定義することなく、エージェントが関係性を理解して検索できるようになります。
パターンB:APIによるデータ参照 (Lookup Data Using APIs)
ERPやWMS(倉庫管理システム)など、APIを持つシステムに対しては、エージェント用の「ツール」を作成します。ユーザーは自然言語で問い合わせを行い、エージェントが裏側でAPIを叩いて必要なデータを取得します。

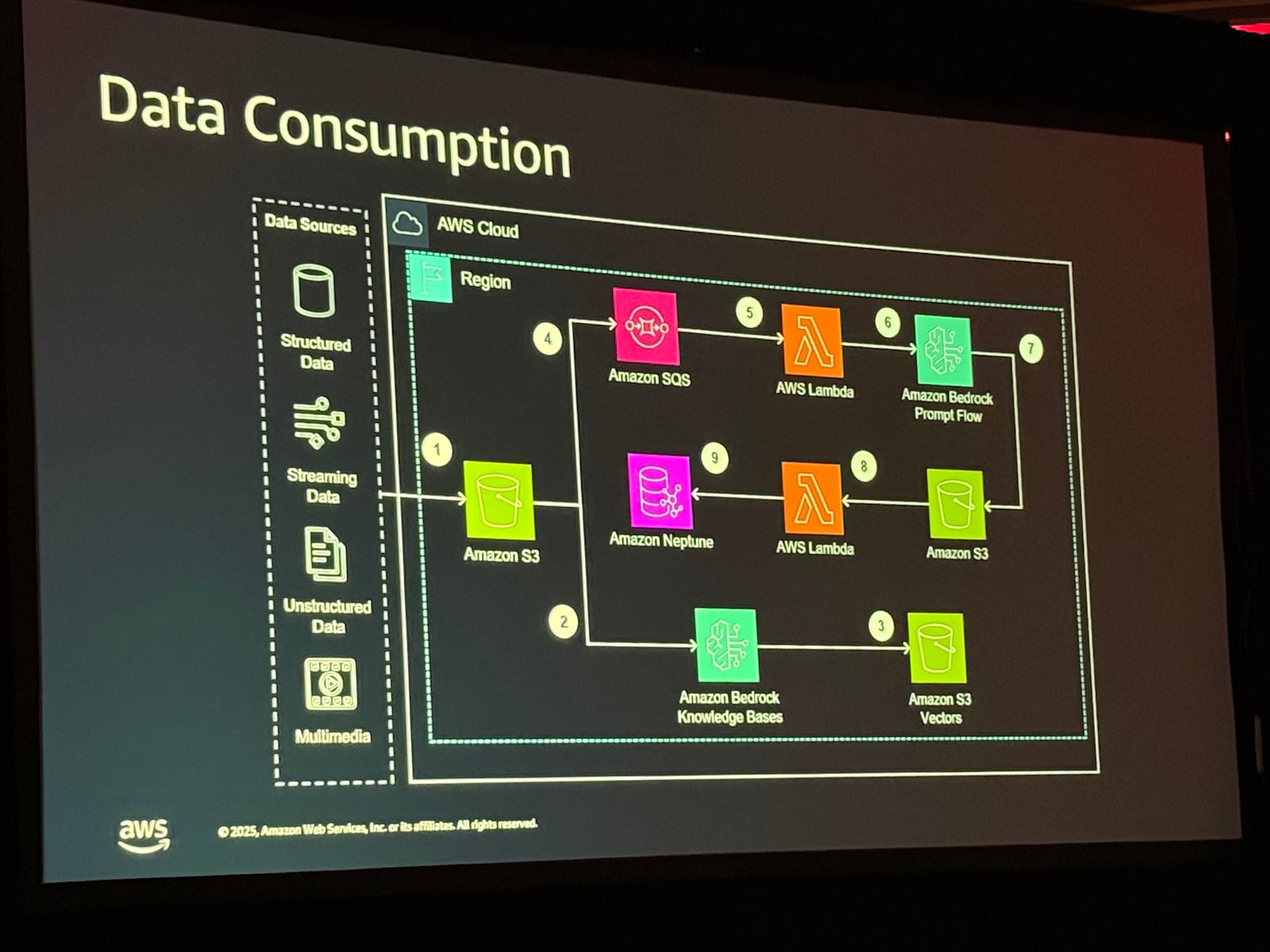
5. 全体アーキテクチャ
セッションの後半では、具体的なAWSアーキテクチャが「データの取り込み」と「データの探索」の2つに分けて解説されました。
データ取り込みアーキテクチャ
構造化データ、非構造化データ、ストリーミングデータなどをAWSクラウド内に取り込む部分です。 Amazon Bedrock Prompt Flowを用いてデータを処理し、関係性データはAmazon Neptuneへ、非構造化データはベクトル化してS3へ格納するフローが描かれています。
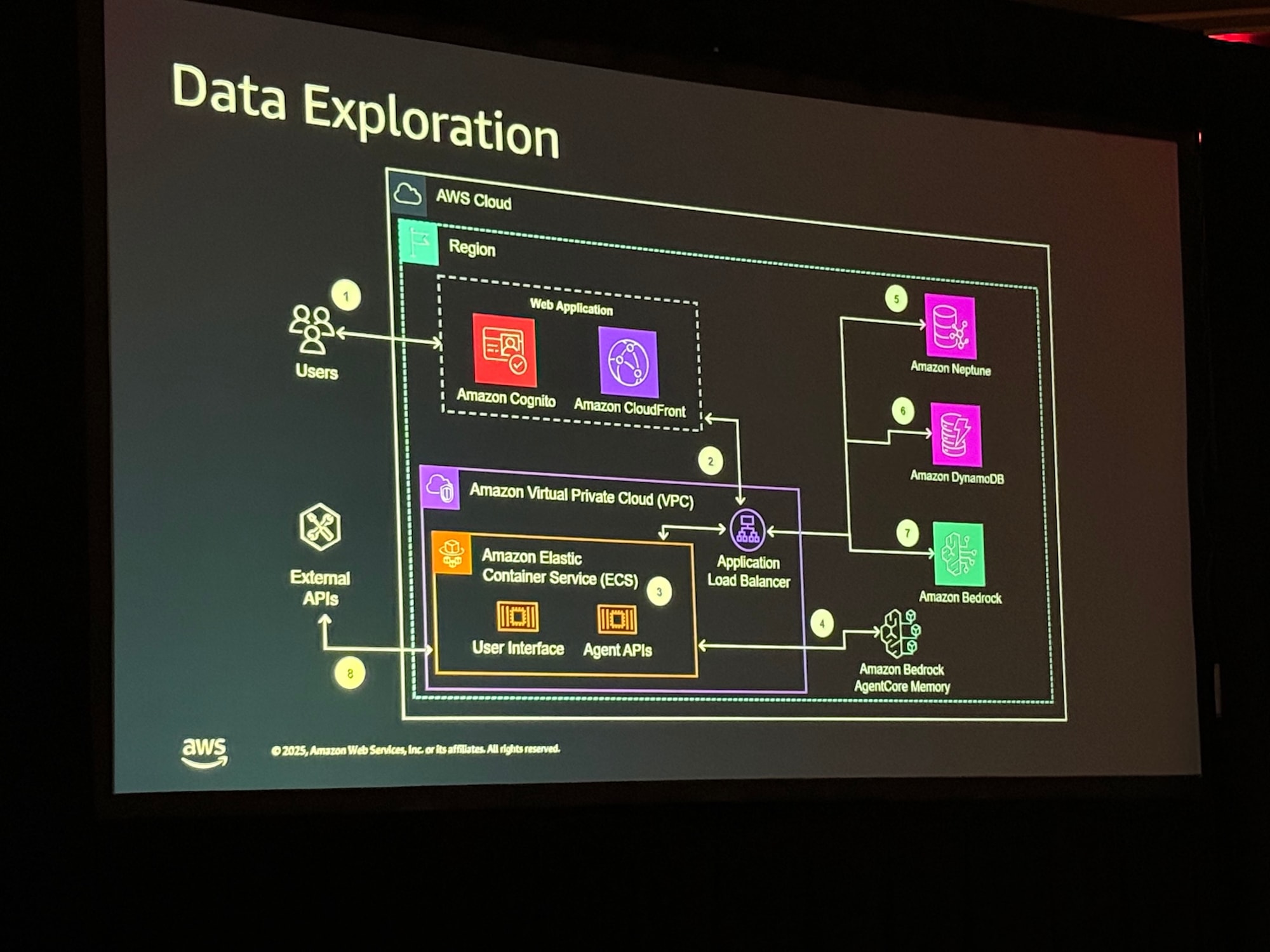
データ探索アーキテクチャ
ユーザーが実際に利用するアプリケーション側のアーキテクチャです。 ユーザーはCognito認証を経てWebアプリ(ECS上のコンテナ)にアクセスします。そこからAmazon Bedrockのエージェントを呼び出し、NeptuneやDynamoDB(エージェントの記憶/ログ用)と連携して回答を生成します。
6. Q&A セッション
チョークトークなので、セッションの最後に、会場からの質問に対してスピーカー陣が回答しました。主な質疑応答は以下の通りです。
Q1: ユーザー間のデータ分離とメモリ機能について
- Q データ探索の結果が他のユーザーに漏れることはないか? また、メモリ機能はどう働くのか?
- A ユーザーセッションごとにメモリは独立して生成されるため、データが混在することはありません。メモリには「短期(チャット履歴)」と「長期(事実や好みの学習)」の2種類があります。エージェントは長期メモリを通じて、ユーザーの役割(工場長か財務担当かなど)やデータの好みを学習し、同じ質問に対してもユーザーの文脈に合った回答を返すようになる。
Q2: 精度保証とハルシネーション対策について
- Q AIの回答が正しいことをどう保証するのか?
- A
- 評価機能: 自動化された評価テストを実行し、スコアリングを行うことで精度を測ります。
- スキーマによる制御: データを全量読み込ませるのではなく、エンティティとリレーションシップ(関係性)を定義し、それを「正解」としてエージェントに与えることで、勝手な推測を防ぎます。
- 透明性の確保:エージェントが回答に至るまでに「どのデータソースにアクセスしたか」をUI上で提示し、人間が検証できるようにしている。
- A
Q3: レガシーデータやERPとの連携について
- Q: 巨大なERPデータや古いCSVファイルはどう扱うべきか?
- A すべてのデータをグラフDBに入れる必要はありません。エージェントにはスキーマ情報を与え、必要に応じてAPI経由でERPを参照させたり、Text-to-SQLで古いDBを検索させたりします。重要なのは、どのツールを使えばどのデータにアクセスできるかをエージェントに正しく指示する。
Q4: エージェント開発の進め方について
- Q: 開発で驚いたことはあるか?
- A 最初は手探りでしたが、最近はAWSのエージェント機能が成熟し、開発サイクルが劇的に短縮されました。以前は5〜6ヶ月かかっていたものが、今は1ヶ月程度で次バージョンへ移行できるスピード感でイノベーションが進んでいる。
まとめ
本セッションでは、製造業のデータ分析を「数ヶ月」から「数分」に短縮するための具体的な解として、Amazon BedrockとAmazon Neptuneを組み合わせたエージェント型ワークフローが提示されました。 厳格なスキーマ定義に縛られず、LLMとエージェントの柔軟性を活かしてデータ統合を行う点が、従来のETLアプローチとの大きな違いであり、最大のメリットであると結論付けられました。









