
ALB + EC2 Auto Scaling 環境下、"スケーリングプロセスの中断" と "Lambda 関数" を利用してヘルスチェックで失敗したインスタンスを保持しつつスケールアウトも実行させてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
テクニカルサポートの 片方 です。
ALB + EC2 Auto Scaling の環境下において、"スケーリングプロセスの中断" と "Lambda 関数" を利用してヘルスチェックに失敗したインスタンス(UnHealthy 状態)を削除しないで保持しつつ、ヘルスチェックに失敗したインスタンス(UnHealthy 状態)の台数分を追加でスケールアウトする仕組みを考えてみました。
それならば、スケールイン保護を利用すれば良いと考える方も多いと思いますが、こちらは仕様上 インスタンスがヘルスチェックに失敗した場合は置換えられます。
また、スケーリングプロセスの中断の場合では新規にスケールアウトが発生しません。
そのため、"スケーリングプロセスの中断" と "Lambda 関数" を利用して実現しました。
インスタンスのスケールイン保護は、次の状況から Auto Scaling インスタンスを保護することはできません。
スタンスがヘルスチェックに失敗した場合のヘルスチェックの置換。詳細については、「Auto Scaling グループでのインスタンスのヘルスチェック」を参照してください。
実装してみた
ALB と EC2 Auto Scaling の作成方法は省かせていただきます。
なお、対象 EC2 Auto Scaling グループと、対象 ALB ターゲットグループの arn は後ほど必要となるのでメモしてください。
EC2 Auto Scaling
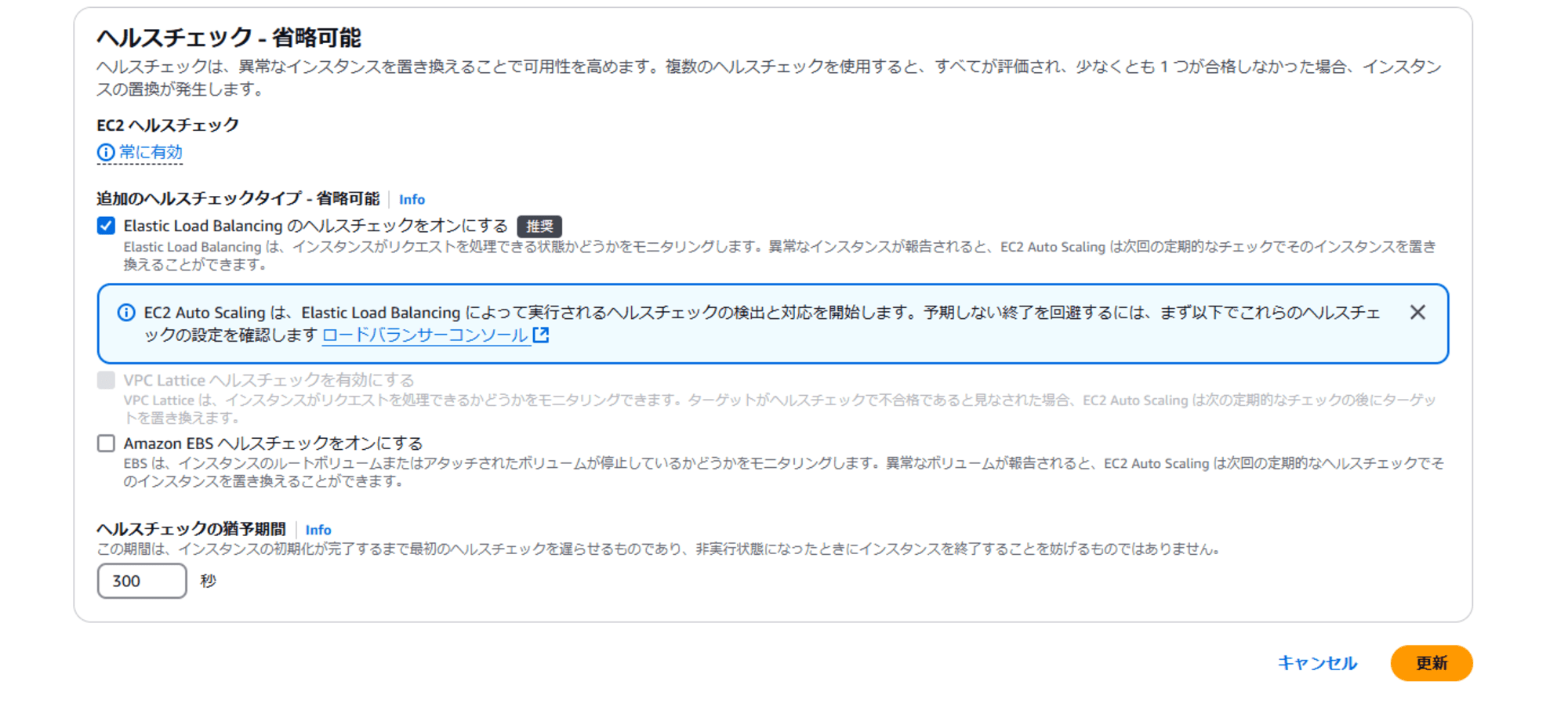
追加のヘルスチェックタイプで、Elastic Load Balancing のヘルスチェックをオンにしてください。
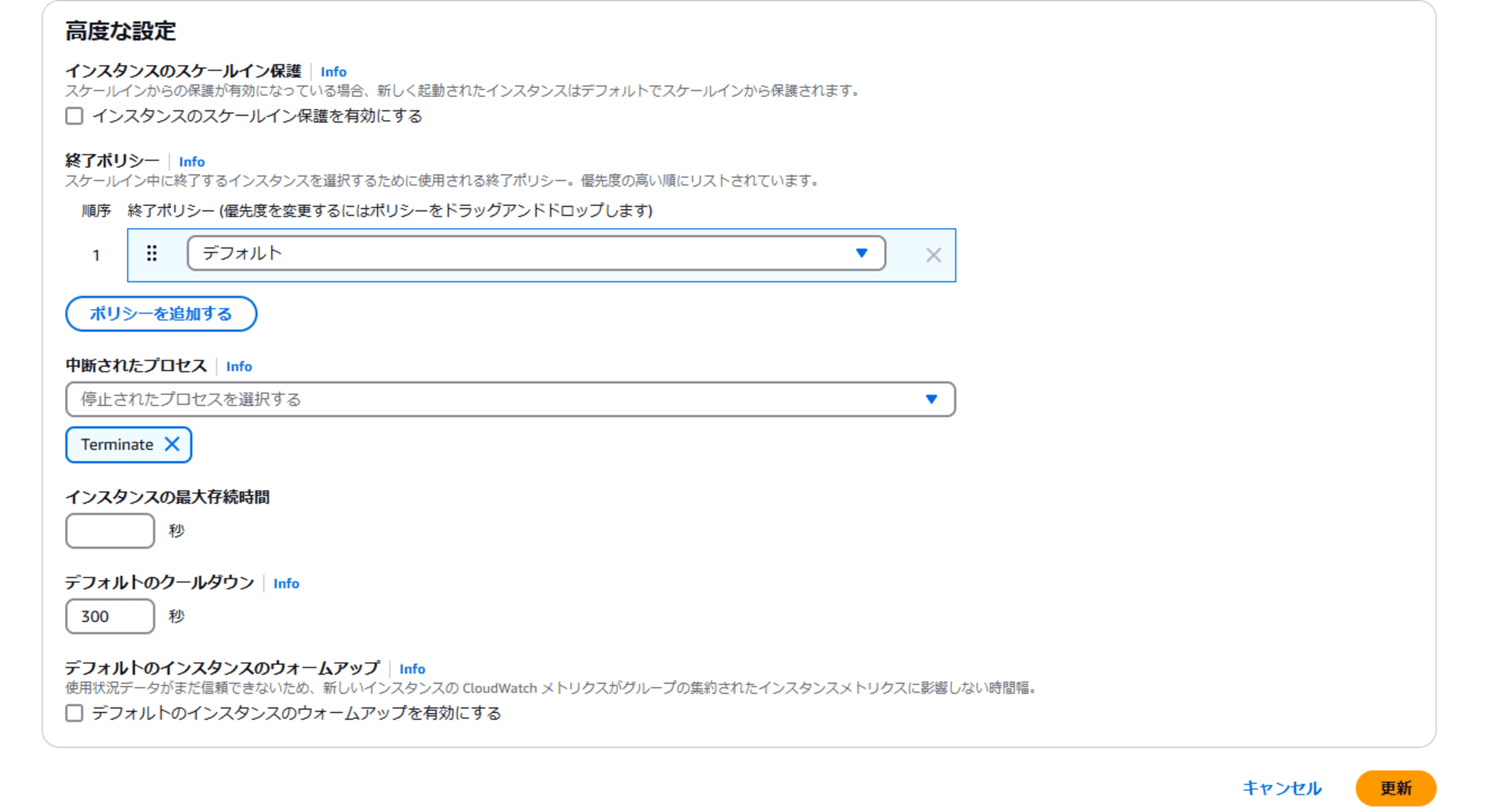
高度な設定から中断されたプロセスのセクションで、Terminate を選択します。

ロール
ロールを作成します。Lambada 関数で使用するためのロールです。
基本的な Lambda アクセス権限で新しいロールを作成した際に、以下のポリシーをアタッチしてください。
アタッチするポリシー例
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:UpdateAutoScalingGroup"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "elasticloadbalancing:DescribeTargetHealth",
"Resource": "*"
}
]
}
※ 適宜修正してください。
Lambda 関数
Python 3.13 で作成しました。
実装する Lambda 関数例
import os
import boto3
from botocore.exceptions import ClientError
def lambda_handler(event, context):
# 環境変数から設定値を取得
target_asg_arn = os.getenv("TARGET_AUTO_SCALING_GROUP")
base_desired_capacity = int(os.getenv("BASE_DESIRED_CAPACITY", 2))
base_max_size = int(os.getenv("BASE_MAX_SIZE", 2))
target_group_arn = os.getenv("TARGET_GROUP_ARN")
if not target_asg_arn or not target_group_arn:
raise ValueError("環境変数 'TARGET_AUTO_SCALING_GROUP' と 'TARGET_GROUP_ARN' を設定してください。")
# クライアント初期化
elb_client = boto3.client("elbv2")
asg_client = boto3.client("autoscaling")
try:
# AutoScalingグループ名をARNから取得
response_asg = asg_client.describe_auto_scaling_groups()
target_asg_name = None
for asg in response_asg["AutoScalingGroups"]:
if asg["AutoScalingGroupARN"] == target_asg_arn:
target_asg_name = asg["AutoScalingGroupName"]
break
if not target_asg_name:
raise ValueError(f"指定されたARN '{target_asg_arn}' に一致するAutoScalingグループが見つかりませんでした。")
# ALBターゲットグループのヘルスチェック情報を取得
response = elb_client.describe_target_health(TargetGroupArn=target_group_arn)
targets = response.get("TargetHealthDescriptions", [])
# UnHealthy 状態のインスタンス数をカウント
unhealthy_count = sum(
1 for target in targets if target["TargetHealth"]["State"] != "healthy"
)
# 希望容量と最大数を計算
new_desired_capacity = base_desired_capacity + unhealthy_count
new_max_size = base_max_size + unhealthy_count
# AutoScalingグループの更新
asg_client.update_auto_scaling_group(
AutoScalingGroupName=target_asg_name,
DesiredCapacity=new_desired_capacity,
MaxSize=new_max_size
)
return {
"statusCode": 200,
"message": f"AutoScalingグループ '{target_asg_name}' を更新しました。",
"desired_capacity": new_desired_capacity,
"max_size": new_max_size
}
except ClientError as e:
return {
"statusCode": 500,
"message": f"エラーが発生しました: {e.response['Error']['Message']}"
}
環境変数設定
- BASE_DESIRED_CAPACITY: 基準となる希望するキャパシティーを設定
- BASE_MAX_SIZE: 基準となる最大キャパシティーを設定
- TARGET_AUTO_SCALING_GROUP: 対象 Auto Scaling グループの arn
- TARGET_GROUP_ARN: 対象 ALB ターゲットグループの arn
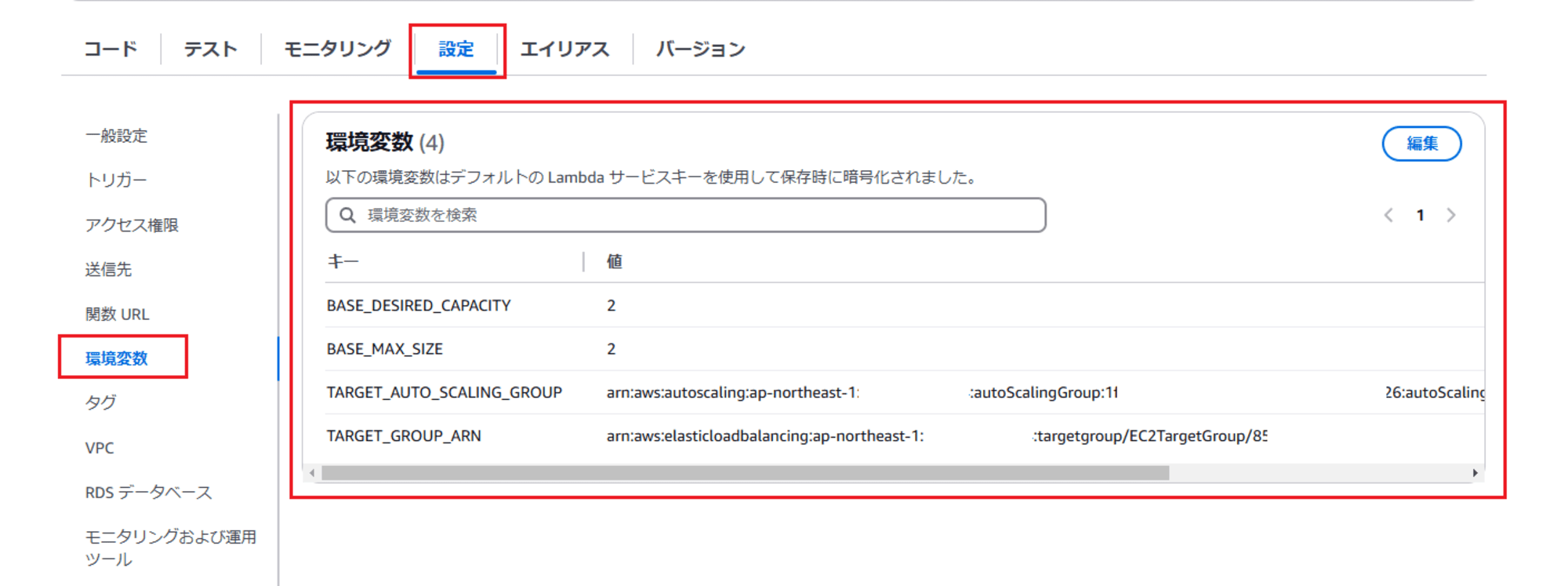

※ 適宜修正してください。
これで、実装は完了です。お疲れさまでした!
検証してみた
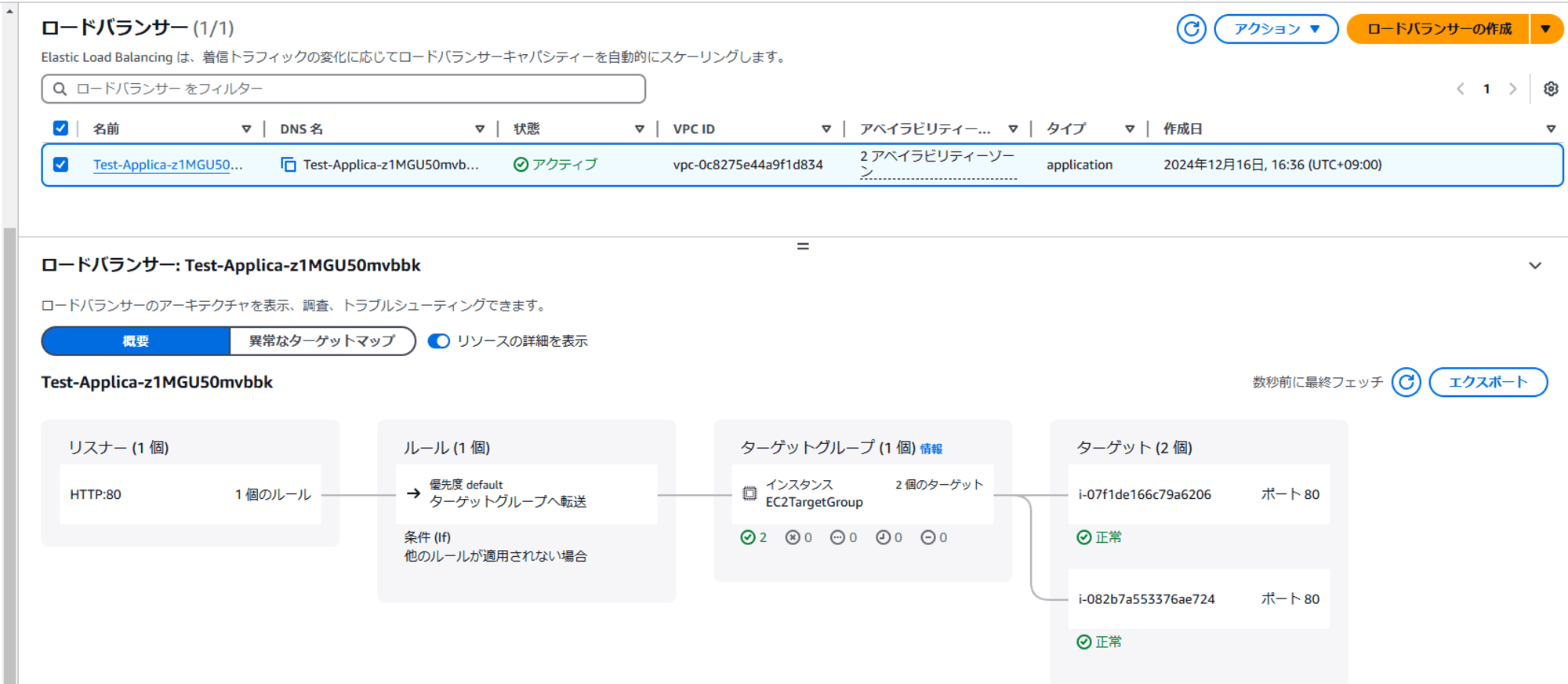
ALB + EC2 Auto Scaling は正常の状態です。

それでは ALB でヘルスチェックに失敗して UnHealthy 状態になるように EC2 インスタンスを操作します。
今回は Amazon Linux 2 のためインスタンスへ SSH 接続を行い "sudo ifdown eth0" コマンドを実行しました。
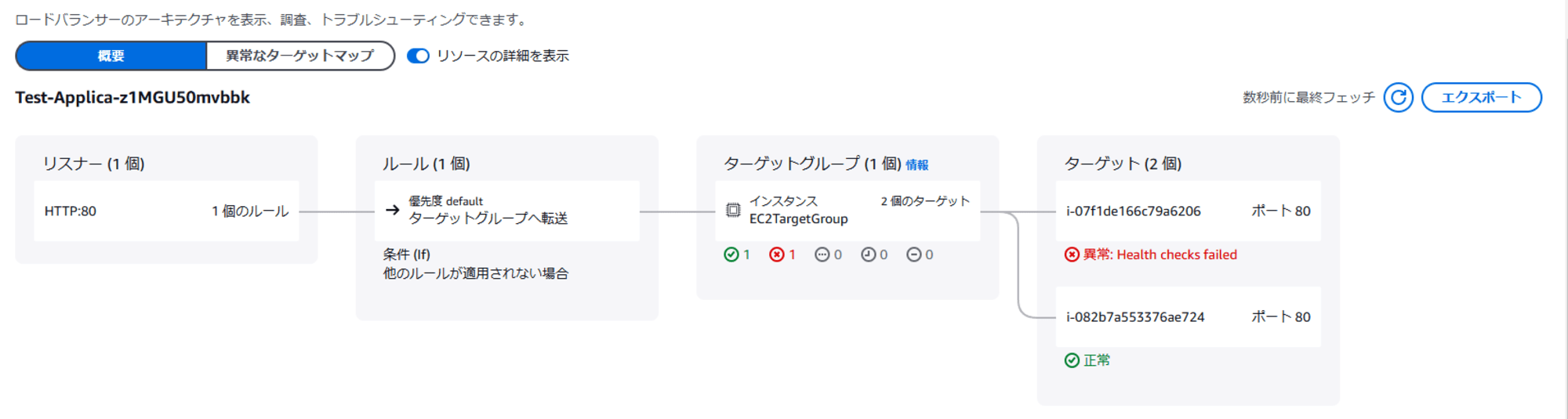
暫くするとステータスチェックに失敗したので、ALB 側を確認します。

UnHealthy 状態になってます。
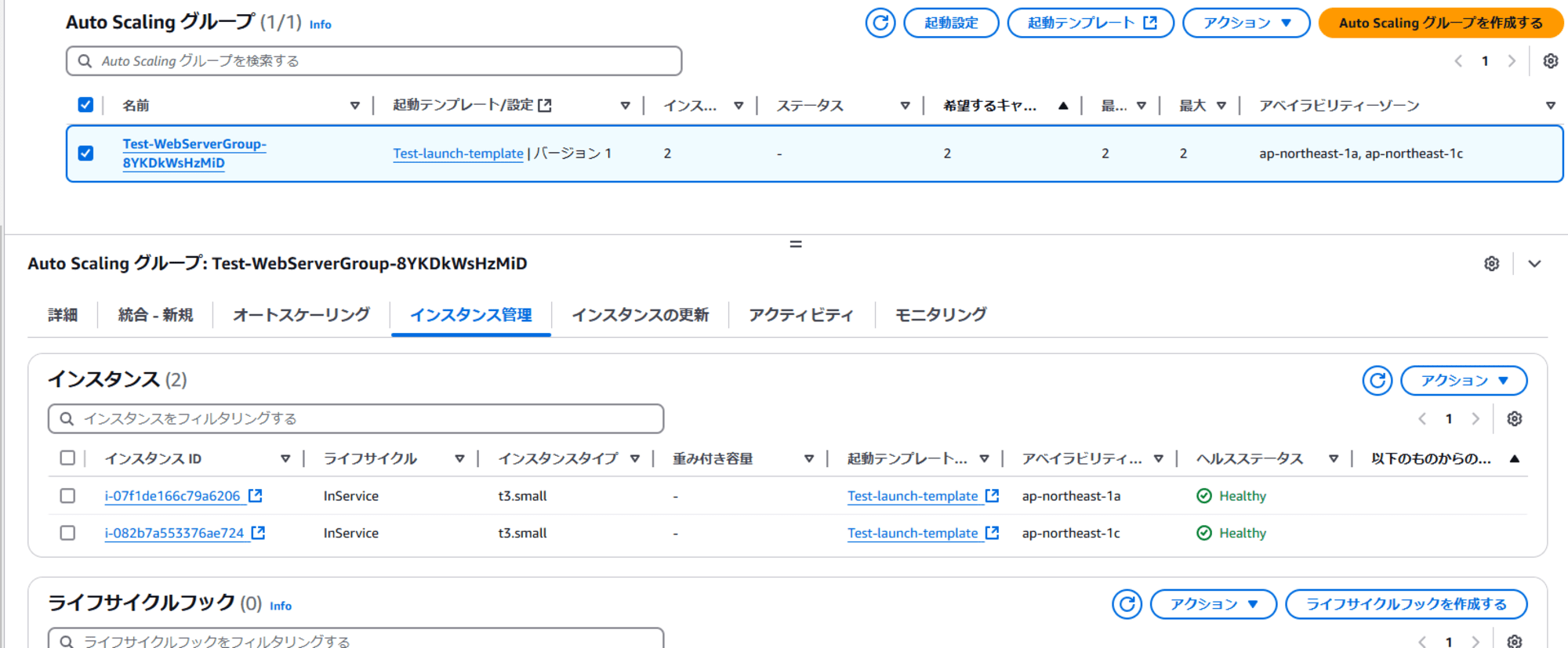
EC2 Auto Scaling 側でも UnHealthy 状態であること確認してます。また、プロセスの中断で "Terminate" を選択しているので、削除されていません。また新規に起動もないので想定通りです。

それでは、Lambada 関数をテストします。
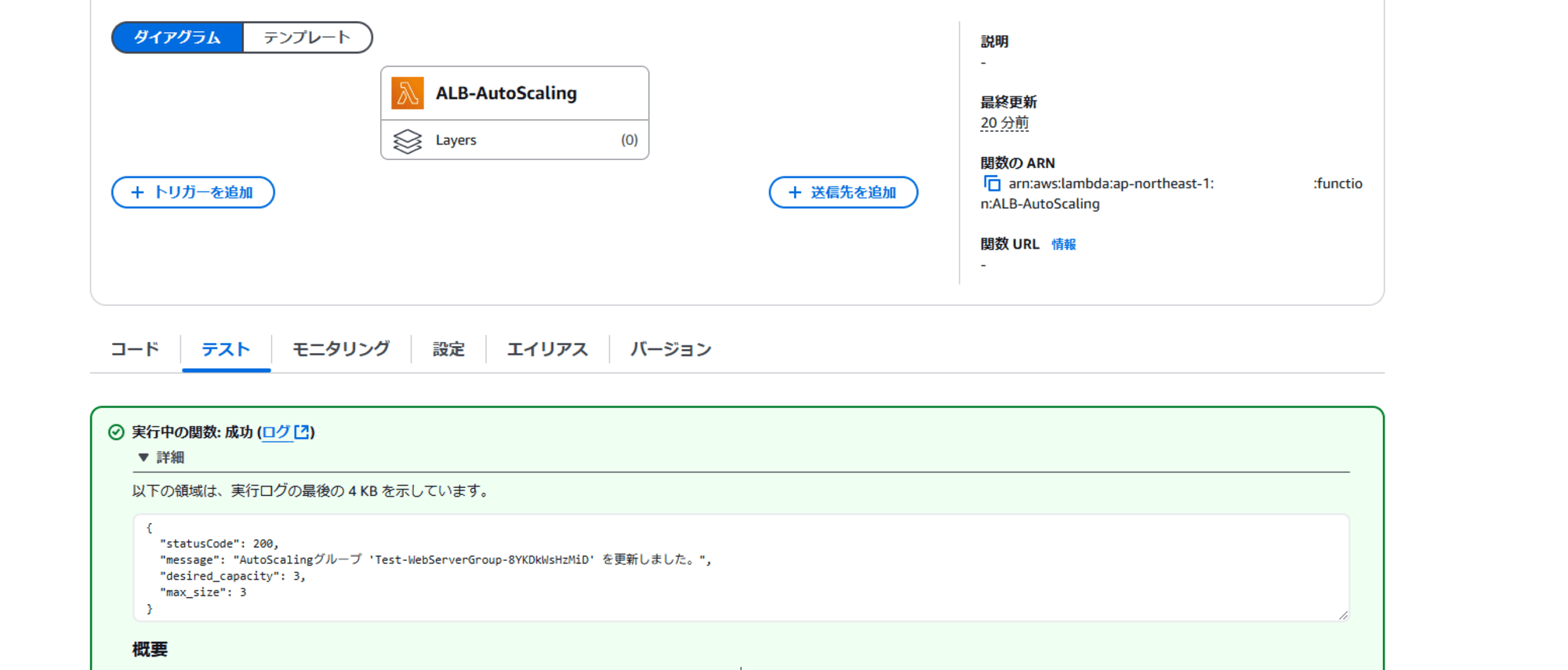
成功したので、ALB と EC2 Auto Scaling を確認します。
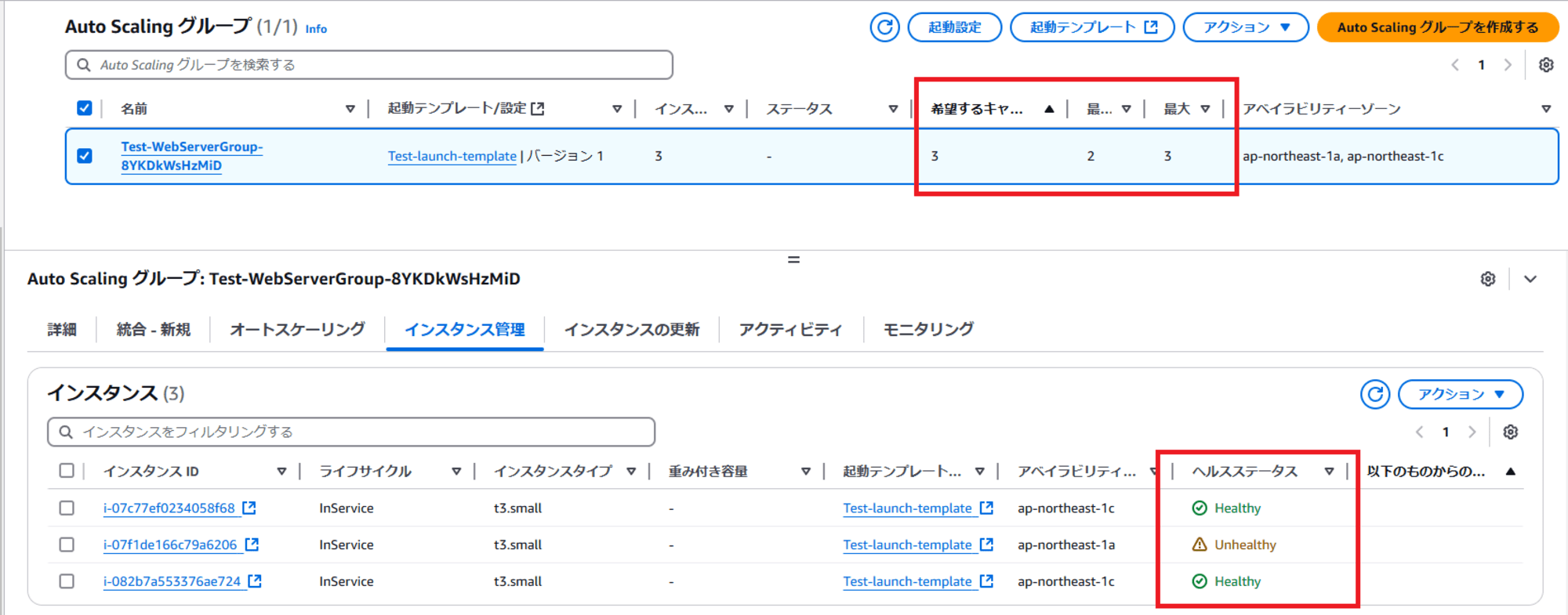
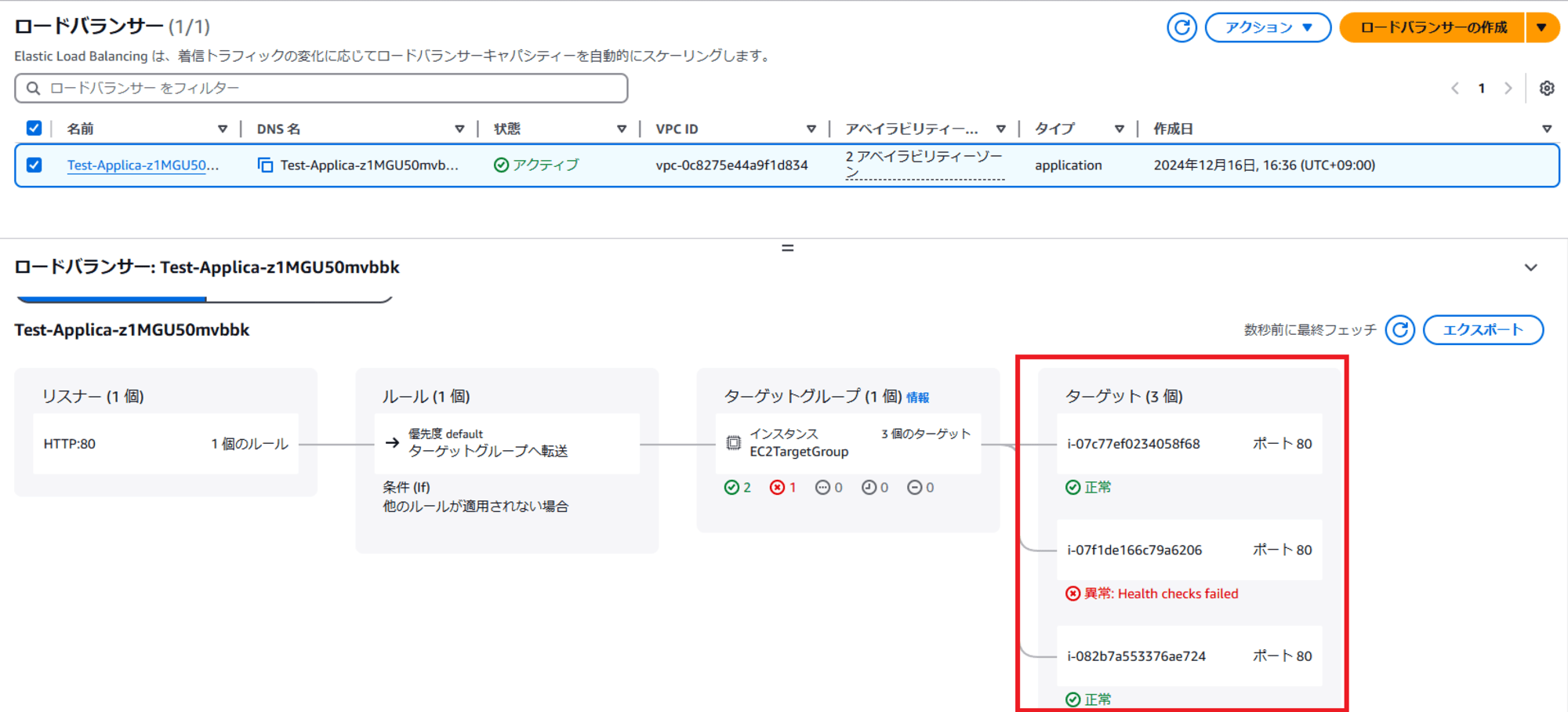

保持しつつ、新規に起動も完了しました、成功です!
まとめ
EventBridge のスケジュール機能を利用して、当該 Lambda 関数を定期実行させると有用です。
調査目的などにご検討ください。本ブログが誰かの参考になれば幸いです。
参考資料
- インスタンスのスケールイン保護を使用してインスタンスの終了を制御する - Amazon EC2 Auto Scaling
- Amazon でスケジュールに従って実行されるルールの作成 EventBridge - Amazon EventBridge
アノテーション株式会社について
アノテーション株式会社は、クラスメソッド社のグループ企業として「オペレーション・エクセレンス」を担える企業を目指してチャレンジを続けています。「らしく働く、らしく生きる」のスローガンを掲げ、様々な背景をもつ多様なメンバーが自由度の高い働き方を通してお客様へサービスを提供し続けてきました。現在当社では一緒に会社を盛り上げていただけるメンバーを募集中です。少しでもご興味あれば、アノテーション株式会社WEBサイトをご覧ください。










