
【登壇資料】「アラート調査の自動化にむけて」というタイトルでopsmethod #1に登壇しました #opsmethod
はじめに
こんにちは、カスタマーサクセス部の奥井大和/やまとです。
2026年2月13日(金)に開催されたクラスメソッド主催の勉強会「opsmethod #1」にて、「アラート調査の自動化にむけて」というテーマで登壇しました。
opsmethodはシステム運用に関する勉強会で、今回が第1回の開催です。テーマは「そのシステム運用、AIに任せよう」でした。私は登壇に加えて、運営と司会進行を担当しました。
本記事では、発表内容を振り返りながら、アラート調査の自動化における「どこからAIに任せるか」という起点の選び方と、Claude Code+AWS CLIで実装した仕組みについてお話しします。
opsmethod #1 「そのシステム運用、AIに任せよう」 - connpass
登壇資料
当日の発表スライドはこちらです。
伝えたかったこと
アラート調査の自動化とは
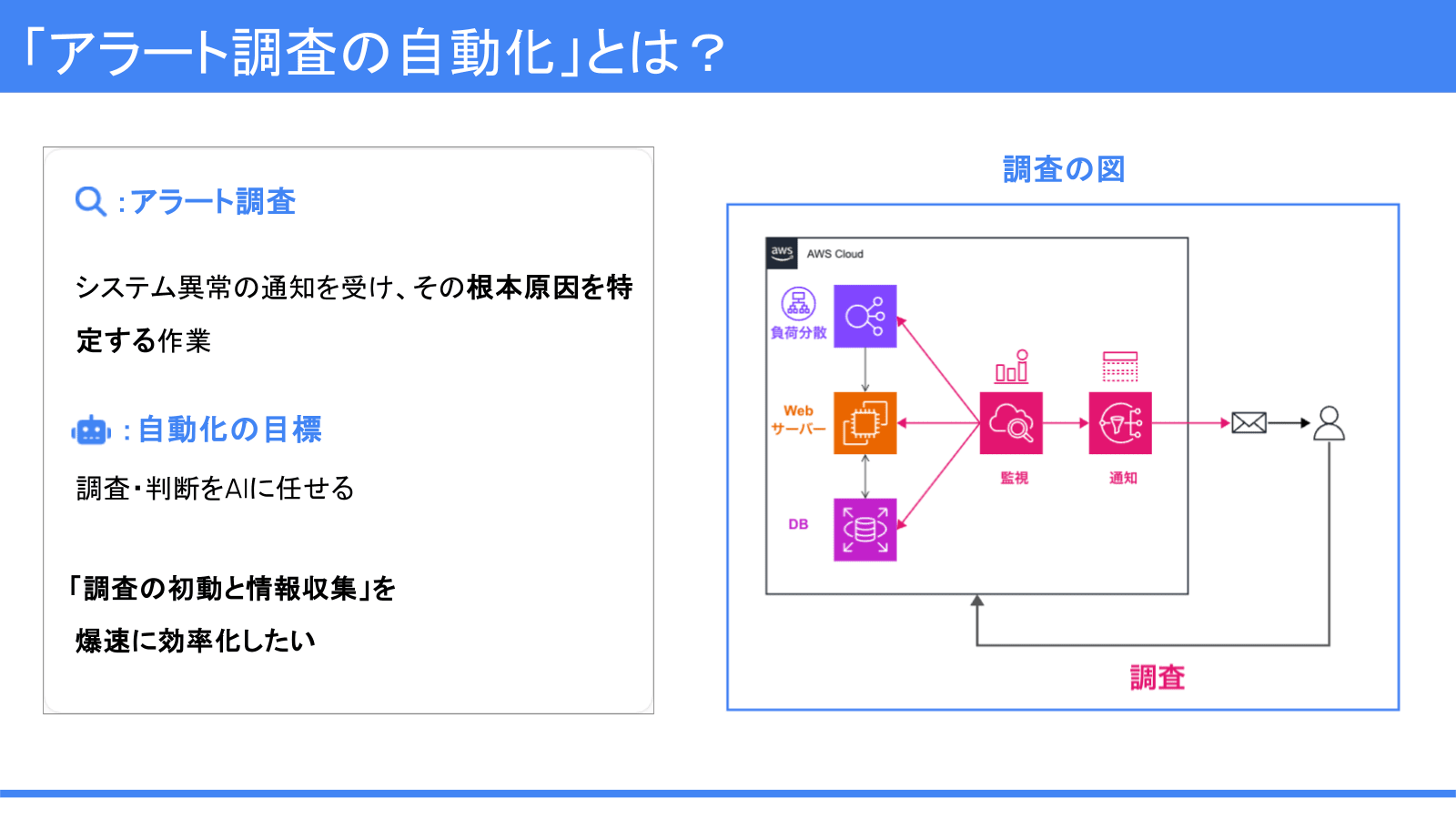
まず今回の発表における用語の定義です。
- アラート調査:システム異常の通知を受け、その根本原因を特定する作業
- 自動化のゴール:調査・判断をAIに任せ、「調査の初動と情報収集」を効率化すること
最終判断の可否は人間が行う前提です。AIに原因の目星をつけさせることで、調査のスピードを上げることを目指していきます。
調査プロセスの分解

日々のアラート対応で気づいたことがありました。それは調査対象の環境やリソースは毎回異なりますが、やっていること自体はほぼ同じということです。メトリクスを見て、ログを見て、CloudTrailで変更履歴を確認する。このプロセスを分解すると、以下の6段階になりました。
- 最初の状況確認と判断(サービス停止?影響範囲?)
- 対象の特定(ID確認、構成把握)
- 情報収集(メトリクス、ログ、CloudTrail)
- 分析・原因の切り分け(しきい値判定、相関分析)
- 関連する影響の確認(同システムの他サービスへの波及)
- 結果の記録・次のアクション
最初の状況確認は人間の判断が必要です。しかし、そこから先の大半のアクションはロジックに基づいた定型作業です。そこで私は対象さえ決まれば、AIに任せられる余地があると考えました。
自動化の起点をどこにするか

プロセスが分解できたところで、調査をどこからAIに任せるかが問題になります。自動化の起点には複数のパターンがあります。今回の発表では主要な3パターンをあげ、比較してみました。
| 項目 | A: 全自動 | B: トリアージ後 | C: 部分的 |
|---|---|---|---|
| 速度 | 最速 | 数分のロス | 遅い |
| 精度 | 誤検知リスク | 人間が要否判断 | 都度判断 |
| 導入コスト | 高い(構築など) | 中程度 | 低い |
| 環境影響 | システム変更あり | 最小限 | なし |
求める場合によって、全自動が正解とは限りません。目的に合わせて選択することが重要です。
実装構成と調査フロー
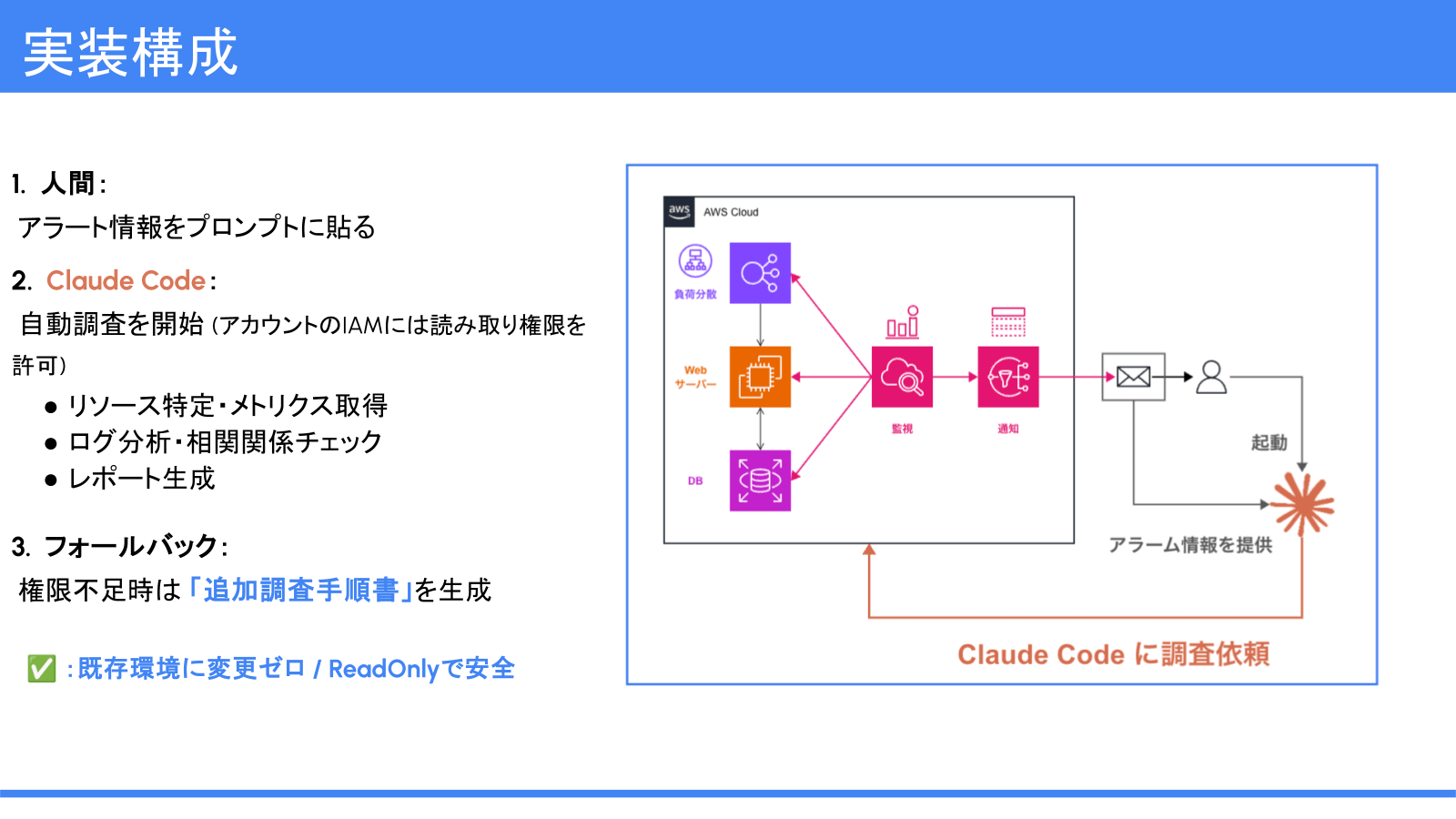
ここで私は、「B: トリアージ後から自動」を選択しました。理由は3つです。
- 「サービスが止まっているか」「ユーザー影響はあるか」の判断は人間が担う
- 対象さえ特定できれば、その後の情報収集や分析はロジックで回せる
- 既存のAWS環境にAIエージェント等の追加コンポーネントを導入せず、今ある権限内で完結できる
具体的にはClaude CodeとAWS CLIを組み合わせています。Claude Codeはターミナル上で動くAIツールなので、コマンド実行やファイル操作を自律的に行えます。
調査フロー:
- 人間がアラートを受けて最初の状況確認を行う
- アラーム情報をプロンプトに貼り付ける
- Claude Codeを起動する
- Claude CodeがAWS CLIでリソース特定・メトリクス取得・ログ分析・相関関係チェック・レポート生成を自動実行する
- 権限不足で確認できない項目は「追加調査手順書」を生成して人間に渡す
IAMにはReadOnly(読み取り専用)権限のみを付与しています。環境への意図しない変更を防ぐためです。またAWS公式のMCPサーバーを活用し、公式の情報に基づいたエビデンスの取得を可能にしています。
Claude CodeにはSkillsという機能があり、調査プロセスをカスタムスラッシュコマンドとして定義できます。以下は実際に使用しているSKILL.mdです。
SKILL.md
---
name: investigation-start
description: CloudWatch異常検知調査を自動開始するスキル
---
# 調査開始スキル
Survey.txtを読み込み、CloudWatch異常検知調査を自動実行します。
## 使用方法
```
/investigation-start YYYYMMDD
```
## 前提条件
- `~/Projects/aws-investigation/investigations/YYYYMMDD/Survey.txt` が存在すること
- AWS CLIが設定済みで、対象アカウントにアクセス可能なこと
- 読み取り専用権限(ReadOnlyAccess相当)があること
## 実行ステップ
### 1. ロギング開始
```bash
cd ~/Projects/aws-investigation/investigations/YYYYMMDD
script ./survey_$(date +%Y%m%d_%H%M%S).log
```
### 2. Survey.txt読み取り
以下の情報を抽出:
- AlarmARN
- AlarmName
- StateChangeTime
- Region
- Namespace
- MetricName
- Threshold
- CurrentValue
- ResourceType
- ResourceId
- Tags
### 3. リソース特定(Phase 2)
```bash
# アラーム詳細取得
aws cloudwatch describe-alarms --alarm-names <AlarmName> --region <Region>
# リソース詳細取得(Namespaceに応じて)
# EC2の場合
aws ec2 describe-instances --instance-ids <InstanceId>
# RDSの場合
aws rds describe-db-instances --db-instance-identifier <DBInstanceId>
# Lambdaの場合
aws lambda get-function --function-name <FunctionName>
```
### 4. クイック診断(Phase 3)
```bash
# CloudTrail(過去24時間の設定変更)
aws cloudtrail lookup-events \
--lookup-attributes AttributeKey=ResourceName,AttributeValue=<ResourceId> \
--start-time $(date -u -d '24 hours ago' +%Y-%m-%dT%H:%M:%S)
# 同時刻の他アラーム
aws cloudwatch describe-alarms --state-value ALARM
# 前日同時刻比較
aws cloudwatch get-metric-statistics \
--namespace <Namespace> --metric-name <MetricName> \
--dimensions Name=<DimensionName>,Value=<DimensionValue> \
--start-time $(date -u -d '48 hours ago' +%Y-%m-%dT%H:%M:%S) \
--end-time $(date -u +%Y-%m-%dT%H:%M:%S) \
--period 3600 --statistics Average
```
### 5. 詳細調査(Phase 4)
```bash
# CloudTrail詳細(過去7日)
aws cloudtrail lookup-events \
--lookup-attributes AttributeKey=ResourceName,AttributeValue=<ResourceId> \
--start-time $(date -u -d '7 days ago' +%Y-%m-%dT%H:%M:%S)
# CloudWatch Logs分析
aws logs filter-log-events \
--log-group-name <LogGroupName> \
--filter-pattern "ERROR" \
--start-time $(($(date -d '2 hours ago' +%s) * 1000))
```
### 6. 仮説立案と検証(Phase 5)
収集したデータから:
- 3つ以上の仮説を立案
- 確度順に並べる
- 検証方法を決定
- 検証を実行
- 採択/棄却を判定
### 7. 関連サービス洗い出し(Phase 6)
```bash
# IAMロールから
aws ec2 describe-instances --instance-ids <InstanceId> \
--query 'Reservations[0].Instances[0].IamInstanceProfile.Arn'
# VPC/Subnetから
aws ec2 describe-instances --filters "Name=vpc-id,Values=<VpcId>"
# タグベース
aws resourcegroupstaggingapi get-resources \
--tag-filters Key=Application,Values=<ApplicationName>
```
### 8. レポート生成(Phase 7)
`findings/investigation_report.md` を作成
テンプレート:`~/.claude/skills/investigation-start/templates/investigation_report.md`
### 9. 追加調査項目リスト化(Phase 8)
権限不足による未実施項目を `additional_procedures/` 配下に手順書生成
テンプレート:
- `~/.claude/skills/investigation-start/templates/ec2_procedure.md`
- `~/.claude/skills/investigation-start/templates/rds_procedure.md`
- `~/.claude/skills/investigation-start/templates/lambda_procedure.md`
### 10. ロギング終了
```bash
exit
```
## 出力ファイル
| ファイル | 説明 |
|---------|------|
| `survey_YYYYMMDD_HHMMSS.log` | 全コマンド実行ログ |
| `findings/investigation_report.md` | 調査レポート |
| `findings/metrics_analysis.json` | メトリクス分析結果 |
| `findings/timeline.md` | イベント時系列 |
| `findings/references.md` | 参考リンク集 |
| `artifacts/cloudwatch_metrics.json` | 取得したメトリクスデータ |
| `artifacts/cloudtrail_events.json` | CloudTrailイベント |
| `additional_procedures/*.md` | 追加手順書(必要時) |
## 注意事項
- AWS MCP Serverの最新ドキュメントを参照し、正確なCLIコマンドを使用
- エラー発生時は代替手段を検討
- 全ての実行コマンドをログに記録
- 機密情報(認証情報、個人情報)は記録しない
## 時刻表記について
- **入力(Survey.txt等)**: CloudWatch アラームの形式に従い UTC で記載
- **内部処理**: UTC で統一
- **出力(レポート・ログ)**: UTC と JST(UTC+09:00)を併記
- 形式: `YYYY-MM-DD HH:MM:SS UTC (YYYY-MM-DD HH:MM:SS JST)`
- 例: `2024-01-15 10:30:00 UTC (2024-01-15 19:30:00 JST)`
- JST = UTC + 9時間
## 制約
- Systems Manager Run Commandは使用不可
- RDSへの直接クエリ実行は不可
- 書き込み・実行系の操作は全て不可
- 読み取り専用操作のみ
SKILL.mdに調査プロセスの各ステップとAWS CLIコマンド、制約事項を記載してみました。/investigation-start YYYYMMDD を実行するだけで、Claude Codeが調査プロセスを自動実行します。
導入成果と課題
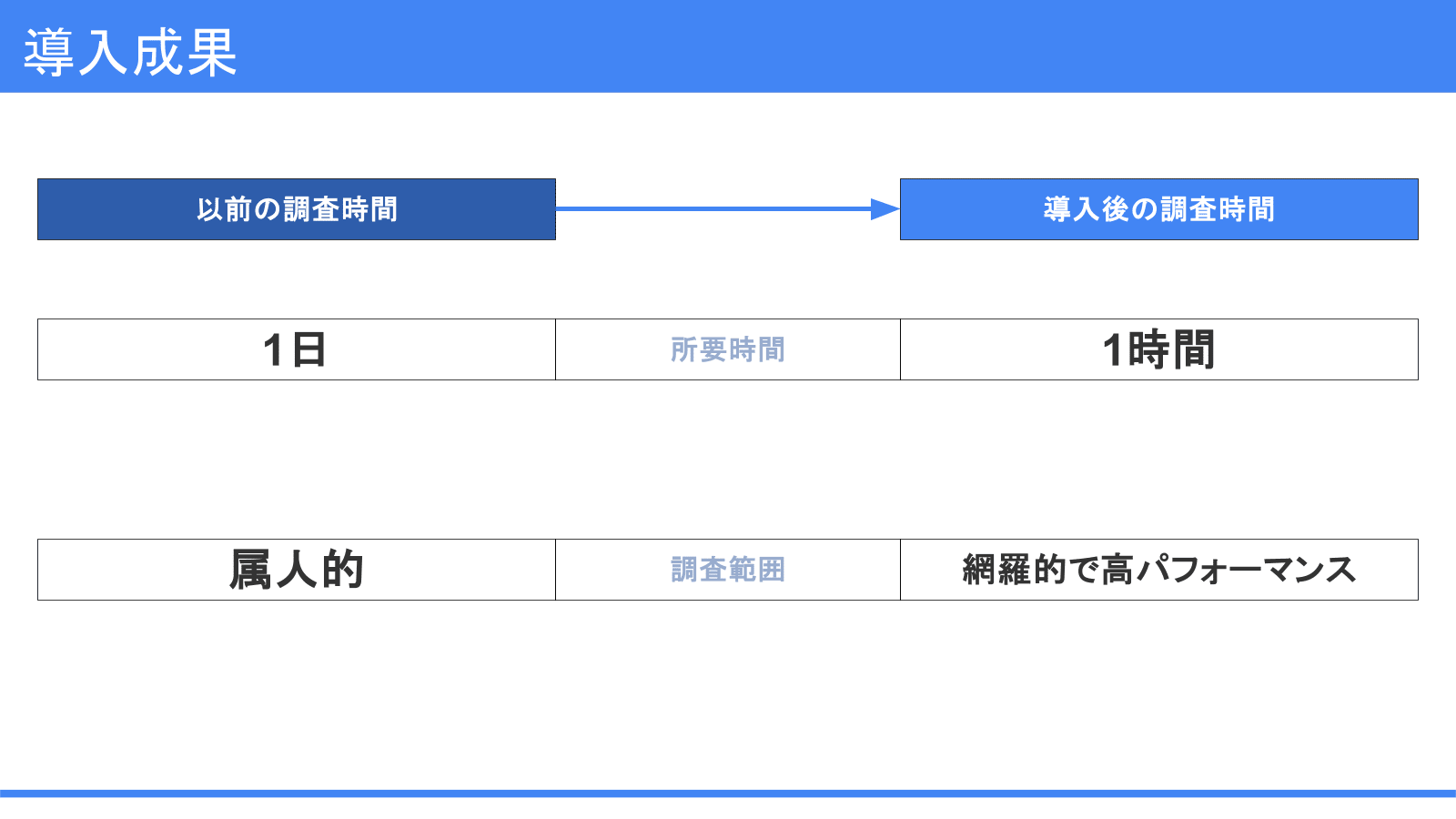
導入検証成果:
| 項目 | 以前 | 導入後 |
|---|---|---|
| 所要時間 | 1日 | 1時間 |
| 調査範囲 | 属人的 | 網羅的 |
時間が短縮された理由は3つあります。
- AIが網羅的に調べるため、抜け漏れが減った
- AWS公式MCPの活用により、エビデンスの取得がスムーズになった
- AIが目星をつけてくれることで調査の進め方が明確になり、着手しやすくなった
課題と向き合い方:
| 課題 | 向き合い方 |
|---|---|
| 権限のトレードオフ | IAMは読み取り権限に絞っているためAIだけで完結しない。セキュリティとのバランスとして割り切る |
| 精度の限界 | 仮説が的外れなこともある。手放しにせず、人間がコンソールで裏取り確認を行う |
| 設定コスト | プロンプトや機能の定義に工数がかかる。しかしプロセス言語化の投資対効果は高い |
今回私は一貫してAIを「優秀な相方」として扱っています。調査メンバーが1人増えたくらいの認識で、手放しにはせず、最後は自分でもコンソールにアクセスして確認します。
登壇の感想
opsmethod第1回を無事に開催できました。「運用 × AI」というテーマに対して、参加者の関心が高いことを実感しました。懇親会では登壇者と参加者の間で具体的な技術の話が交わされていました。
今後もopsmethodは開催予定です。次回の開催情報はconnpassやSNSでお知らせしますので、ご関心のある方は、第2回もよろしくお願いします!
AWS運用エンジニア(24×365)募集
クラウド運用チームで AWS エンジニアを募集中!クラウドに関する Web システムや基幹システムの運用保守経験をお持ちの方を歓迎します。先輩エンジニアによる丁寧な OJT 研修、AWS 資格取得支援など充実のサポート体制で、AWS未経験からでも安心してAWS運用エンジニアとしてのキャリアをスタートできます。
▼ 詳細・応募はこちら
※ カジュアル面談も実施中!まずは話を聞いてみたいという方も大歓迎です。
AWS運用代行・サーバー監視のご案内
クラスメソッド マネージドサービスは、AWS国内支援実績No.1のクラスメソッドが提供する、クラウド特有の対応やクラウド技術者の不足に課題をお持ちのお客様向けのAWS運用トータル支援サービスです。
監視や運用支援にとどまらず、お客様のクラウド利用を最適化し日々の負担を最小化することで、お客様のビジネス効果の最大化を支援します。
クラスメソッドオペレーションズ株式会社について
クラスメソッドグループのオペレーション企業です。
運用・保守開発・サポート・情シス・バックオフィスの専門チームが、IT・AIをフル活用した「しくみ」を通じて、お客様の業務代行から課題解決や高付加価値サービスまでを提供するエキスパート集団です。
当社は様々な職種でメンバーを募集しています。
「オペレーション・エクセレンス」と「らしく働く、らしく生きる」を共に実現するカルチャー・しくみ・働き方にご興味がある方は、クラスメソッドオペレーションズ株式会社 コーポレートサイト をぜひご覧ください。









