
Alteryx のユニークツールとSnowflake の SQL の出力が合わない時に確認したこと
はじめに
Alteryx のユニークツールの出力と SQL(Snowflake)の同様の処理の結果が合わない際に確認したことを記事としました。
前提条件
- DWH:Snowflake
- Alteryx Designer Desktop
- 2025.2.1.85 パッチ: 2
サンプルデータ
サンプルデータとして、ここでは Snowflake アカウントで使用できる「SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS」を使用します。
設定
ここでは既存の Alteryx ワークフローを Snowflake の SQL で置き換えることを考えます。特定のグループ(o_custkey)ごとにデータをまとめ、最新日付(o_orderdateの最大)のレコードを 1 件だけ取得する処理を、Alteryx(ソートツールとユニークツール)と Snowflake(ROW_NUMBER())で同じ結果になるように再現します。
ただしこのとき、最新日付のレコードが 1 件とは限らず、同一グループ・同一日付のレコードが複数存在するケースがあります。
サンプルデータもこのようになっています。例として、特定のレコード(o_custkey = 25)に絞って、同一日付が複数ある状況を確認してみます。
以下を実行すると、o_orderdate = '1998-06-15'に複数レコードが存在し、o_orderkeyが複数返ります。
-- 特定のレコードに絞って確認
>SELECT
o_orderdate, COUNT(*) AS cnt, ARRAY_AGG(o_orderkey) AS order_keys
FROM
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
WHERE
o_custkey = 25
GROUP BY
o_orderdate
HAVING
COUNT(*) > 1
ORDER BY
o_orderdate;
+-------------+-----+------------+
| O_ORDERDATE | CNT | ORDER_KEYS |
|-------------+-----+------------|
| 1998-06-15 | 2 | [ |
| | | 3696386, |
| | | 345858 |
| | | ] |
+-------------+-----+------------+
Alteryx のワークフロー(処理内容)
今回置き換え対象となる Alteryx のワークフローは下図です。
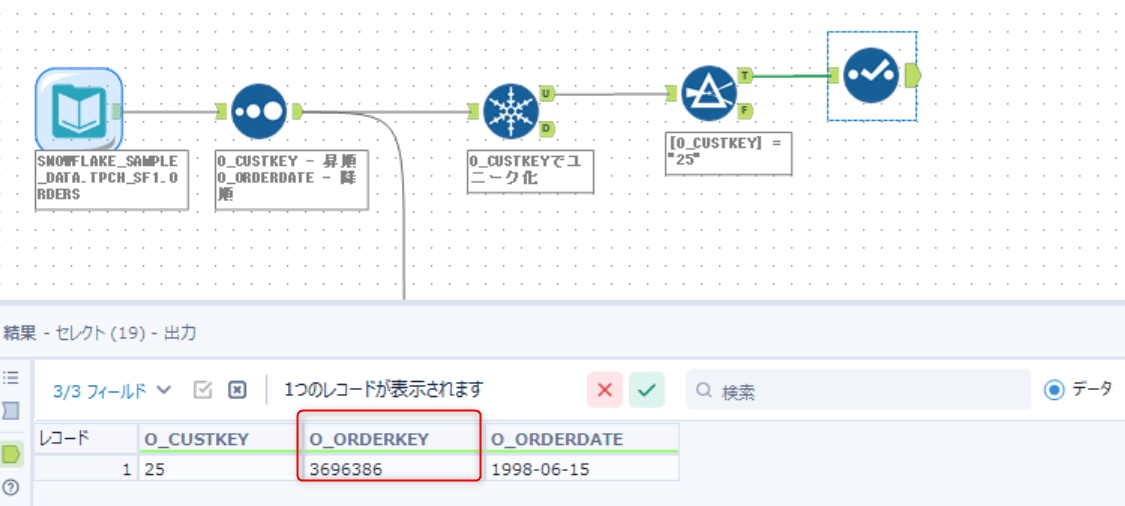
このワークフローでは、Snowflake のサンプルデータSNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERSを入力とし、以下の流れで処理しています。
- 入力:
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS - 並び替え(ソートツール)
O_CUSTKEYを 昇順、O_ORDERDATEを 降順でソートしています- これにより、同一
O_CUSTKEYの中では、より新しいO_ORDERDATEのレコードが先に並ぶ状態になります
- ユニーク化(ユニークツール)
O_CUSTKEYでユニーク化します- ユニークツールは 各グループの最初のレコードを残すため、直前のソート結果に従って「各
O_CUSTKEYの最新日付のレコード」が選ばれます
- フィルタ
- 条件
[O_CUSTKEY] = '25'により、対象をO_CUSTKEY = 25のみに絞り込みます
- 条件
最終的に O_CUSTKEY = 25 の 1 レコードが出力され、例として O_ORDERDATE = 1998-06-15 が選ばれていることが確認できます。
ポイントはユニークツールの仕様で、Alteryx 側ではソートで順序を作り、これをユニークツールのインプットとすることで、各グループの先頭が取得される仕組みとなっています。
このツール仕様はドキュメントは関連する以下の記事でも紹介されています。
Snowflake(SQL)で同様の処理を行う
次に、この処理を Snowflake の SQL で再現します。
Alteryx のグループごとに並べて先頭を取るは、SQL では ROW_NUMBER() を使って表現できます。
WITH ranked AS (
SELECT
o_custkey,
o_orderkey,
o_orderdate,
ROW_NUMBER() OVER (
PARTITION BY o_custkey
ORDER BY o_orderdate DESC
) AS rn
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
)
SELECT o_custkey, o_orderkey, o_orderdate, rn
FROM ranked
WHERE rn = 1
AND o_custkey = 25;
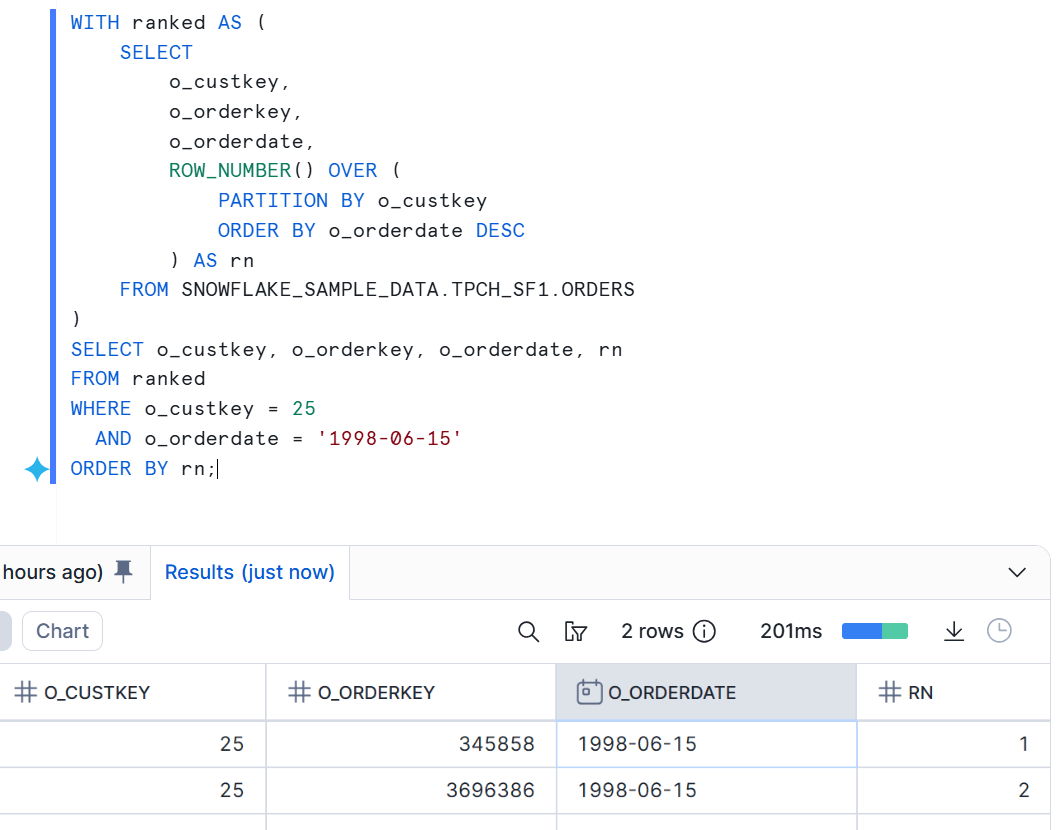
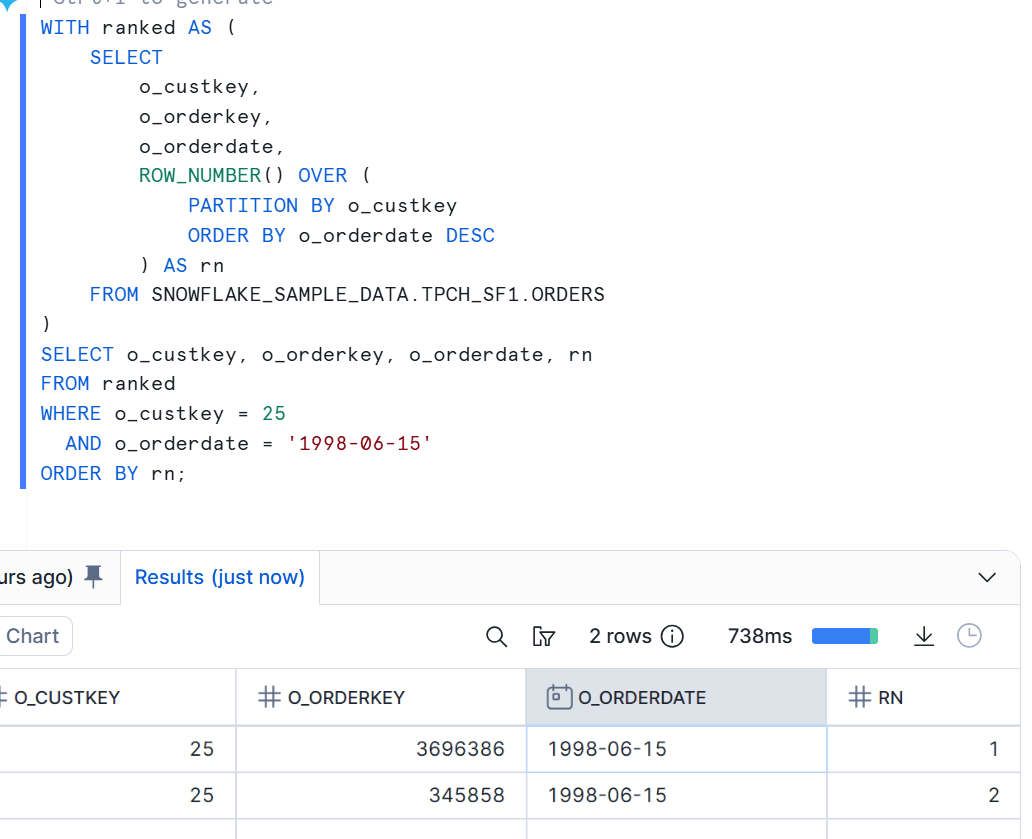
上記もo_custkeyごとに最新日付を 1 行取る処理となっていますが、もし 同一o_custkeyの中に同一のo_orderdateの行が複数存在すると、ORDER BY o_orderdate DESC だけでは同順位(同一日付)の行の順序が確定しません。
その結果、rn = 1 に選ばれる行が 実行のタイミングや実行計画等により変わり得るため、Alteryx と同じつもりで置き換えると、期待と異なる結果になる可能性があります。
下図は上記と同様のロジックで、わかりやすいように特定レコードのみ絞り込みを行った結果です。結果キャッシュを無効化(ALTER SESSION SET USE_CACHED_RESULT = FALSE;)し、何度か実行すると、結果は毎回同じにはなりません。
各製品の仕様
上述の差は、どこまで順序が保証されるかの違いにより起こります。それぞれ以下の通りです。
- Alteryx のユニークツール
- ドキュメントにも明記されているようにキーごとに「最初のレコード」が採用されます。そのため、特定の結果にしたい場合は事前のソートが前提となります
- Snowflake(ROW_NUMBER)
ROW_NUMBER()はORDER BYで指定された順序に従って番号を振りますが、ORDER BYが同順位を許す場合、同順位内の順序まで保証されません。そのため、rn=1がどの行になるかが固定されないケースがあり得ます- ウィンドウ関数の利用上の注意として、順序指定が結果に影響する点がドキュメントにも記載されています
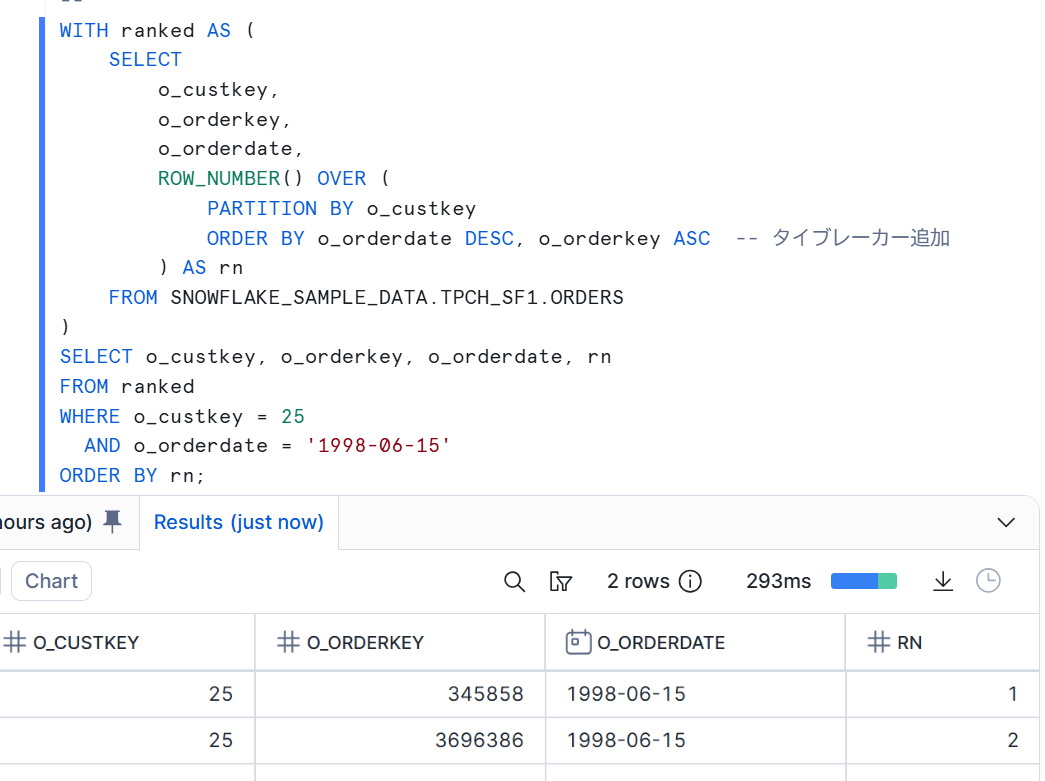
タイブレーカーの追加
対応方法として、ウィンドウ関数では ORDER BY で順序を定義する必要があるため、同順位が発生する可能性がある場合は、SQL 側でタイブレーカー(並び替えで同順位が発生したときに、どちらを先にするかを決める追加の並び替えキー)を追加して順序を明示します。
具体的には以下のようにタイブレーカーを追加します。一意に決まるまでキーを追加することで、Alteryx と SQL の結果を一致しやすくできます。
WITH ranked AS (
SELECT
o_custkey,
o_orderkey,
o_orderdate,
ROW_NUMBER() OVER (
PARTITION BY o_custkey
ORDER BY o_orderdate DESC, o_orderkey ASC -- タイブレーカーを追加
) AS rn
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
)
SELECT o_custkey, o_orderkey, o_orderdate, rn
FROM ranked
WHERE rn = 1
AND o_custkey = 25;
さいごに
Alteryx のユニークツールの出力と SQL(Snowflake)の同様の処理の結果が合わない際に確認した内容を記事としました。ツールごとの仕様に違いや特徴がある場合もあるので、注意できればと思います。こちらの内容がどなたかの参考になれば幸いです。








