![[Amazon Athena] OpenX JSON SerDeのオプションプロパティを試してみた](https://devio2023-media.developers.io/wp-content/uploads/2019/04/amazon-athena.png)
[Amazon Athena] OpenX JSON SerDeのオプションプロパティを試してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部 IoT事業部の若槻です。
Amazon AthenaのOpenX JSON SerDeでは、SerDeのオプションとして次のプロパティを設定することができます。(説明は後述)
| プロパティ名 | 既定値 |
|---|---|
| ignore.malformed.json | FALSE |
| dots.in.keys | FALSE |
| case.insensitive | FALSE |
| mapping | - |
今回は、上記オプションプロパティの設定の有無による動作の違いを確認してみました。
やってみた
OpenX JSON SerDeのオプションプロパティがデフォルトのテーブルと設定されたテーブルを作成し、それぞれの動作を見てみます。
まず既定のプロパティのテーブルcounts_defaultを作成します。
CREATE EXTERNAL TABLE counts_default(
id string,
a_b string,
count int
)
ROW FORMAT
SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS
INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://cm-test-220801/counts'
TBLPROPERTIES ('has_encrypted_data'='false')
次に、それぞれのオプションプロパティを既定値から変更したテーブルcounts_optionalを作成します。
CREATE EXTERNAL TABLE counts_optional(
id string,
a_b string,
count int
)
ROW FORMAT
SERDE
'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES ("ignore.malformed.json" = "TRUE", "dots.in.keys" = "TRUE", "case.insensitive" = "FALSE", "mapping.count"= "cnt")
STORED AS
INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://cm-test-220801/counts'
TBLPROPERTIES ('has_encrypted_data'='false')
ignore.malformed.json
不正なレコードを含むデータを作成します。
$ cat data
{"id":"u001","count":3,"a.b":"あああ"}
{いいい}
{"id":"u003","count":2,"a.b":"ううう"}
$ DATA_BUCKET_NAME="cm-test-220801"
$ aws s3 cp data s3://${DATA_BUCKET_NAME}/counts/data
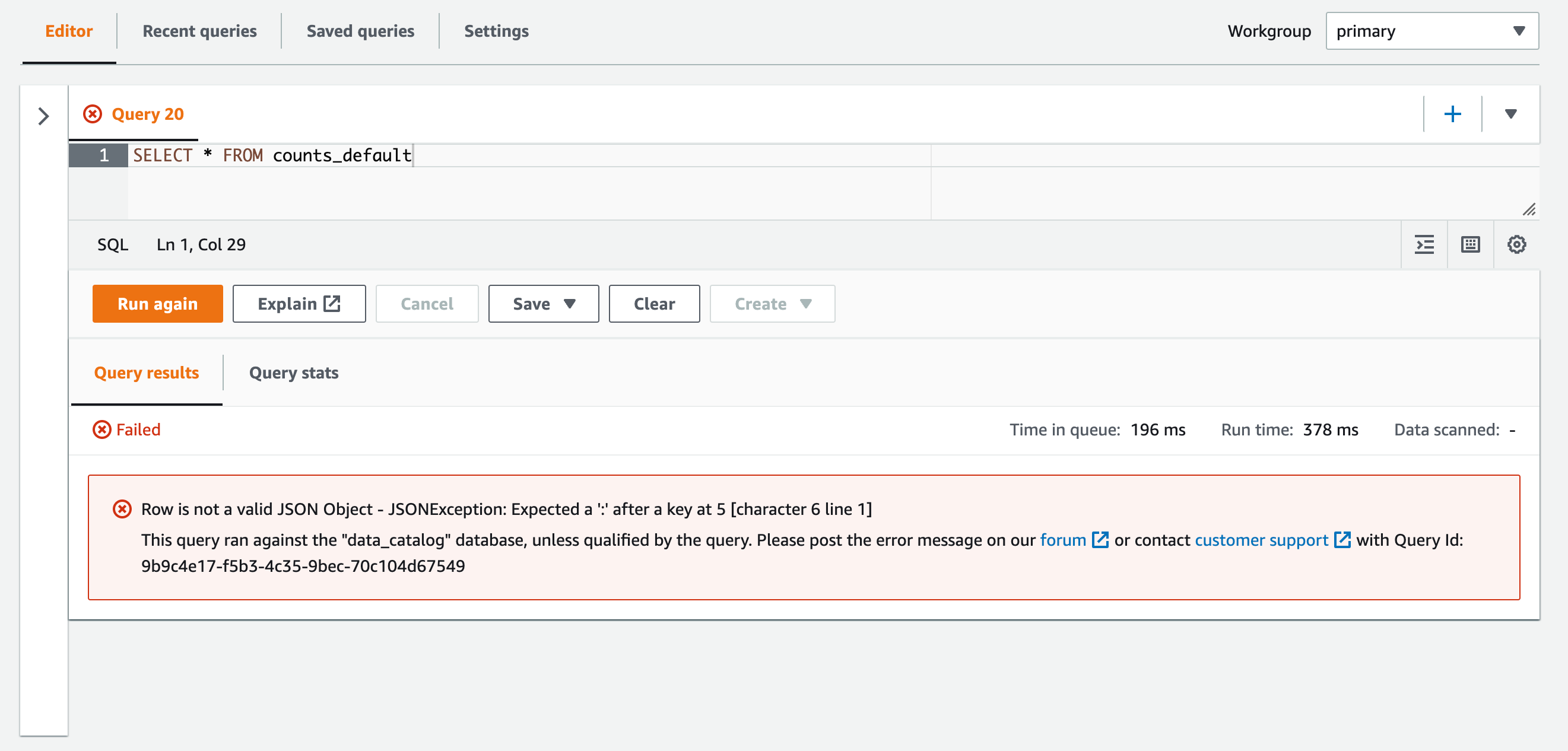
デフォルト設定のテーブル("ignore.malformed.json" = "FALSE")に対してSELECTクエリした場合。
SELECT * FROM counts_default
クエリがエラーとなりました。
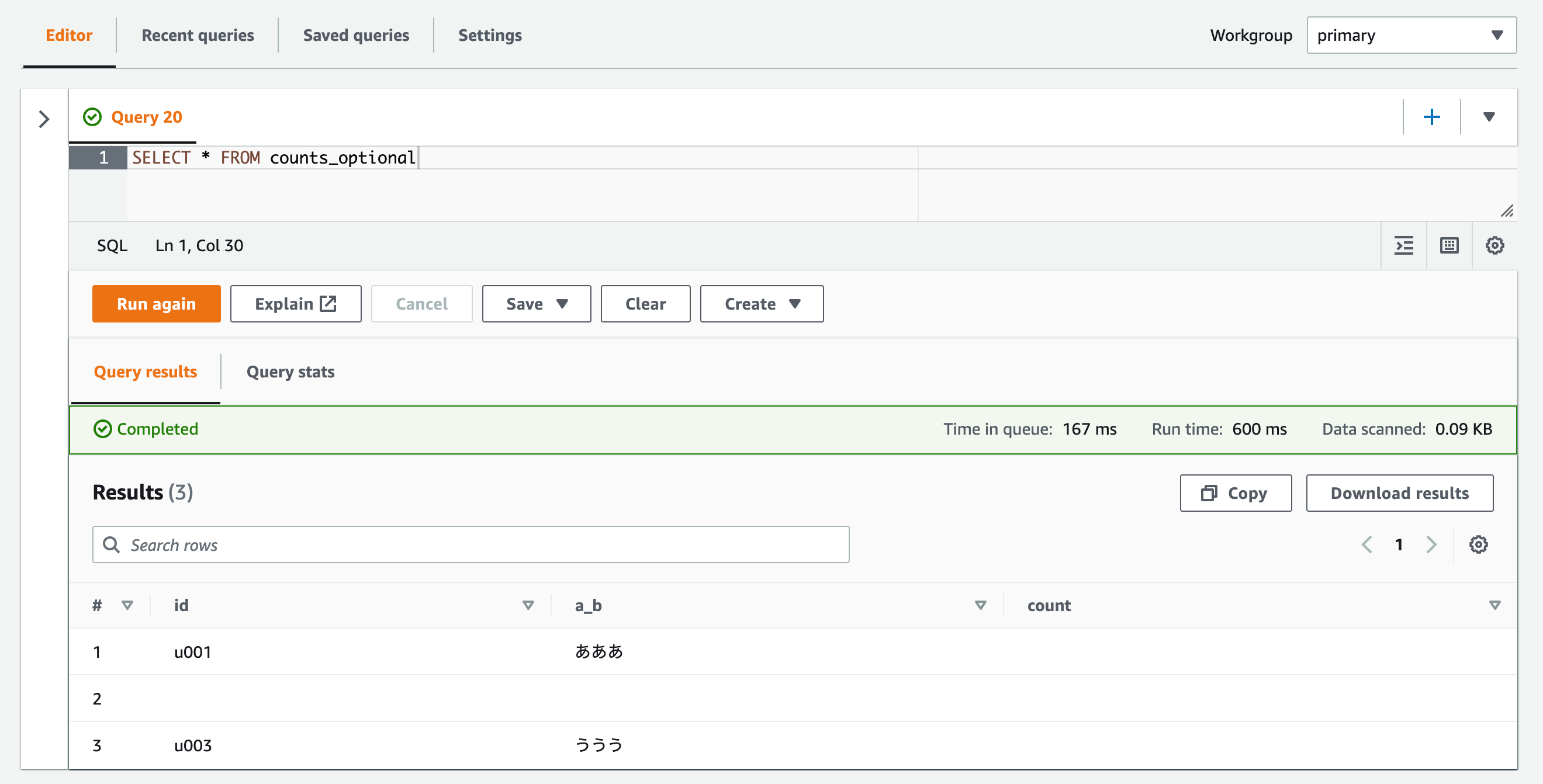
SerDeのオプションを設定したテーブル("ignore.malformed.json" = "FALSE")に対してSELECTクエリした場合。
SELECT * FROM counts_optional
不正なレコードを無視して、有効なレコードのみ取得できました。
dots.in.keys
JSON SerDeでは.を含むスキーマを定義することができませんが、SerDeでdots.in.keysがTRUEの場合、データのプロパティ中のドット.をアンダースコア_に置き換えてクエリすることができるようになります。
テーブルが持つa_bスキーマのアンダースコア_をドット.に置き換えたa.bプロパティを持つデータを作成します。
$ cat data
{"id":"u001","count":3,"a.b":"あああ"}
{"id":"u002","count":1,"a.b":"いいい"}
{"id":"u003","count":2,"a.b":"ううう"}
$ DATA_BUCKET_NAME="cm-test-220801"
$ aws s3 cp data s3://${DATA_BUCKET_NAME}/counts/data
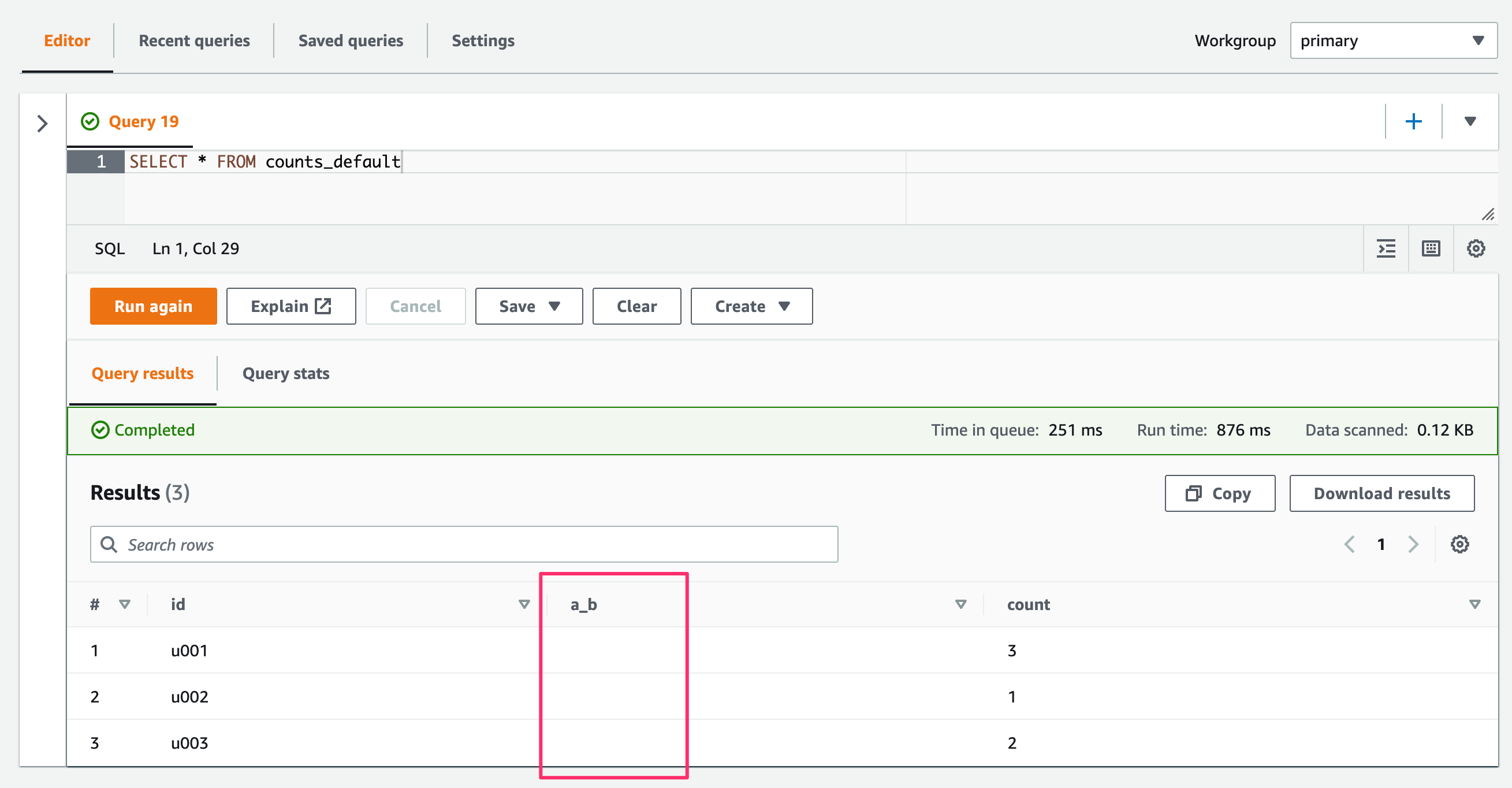
デフォルト設定のテーブル("dots.in.keys" = "FALSE")に対してSELECTクエリした場合。
SELECT * FROM counts_default
a_bプロパティの値は取得できていません。
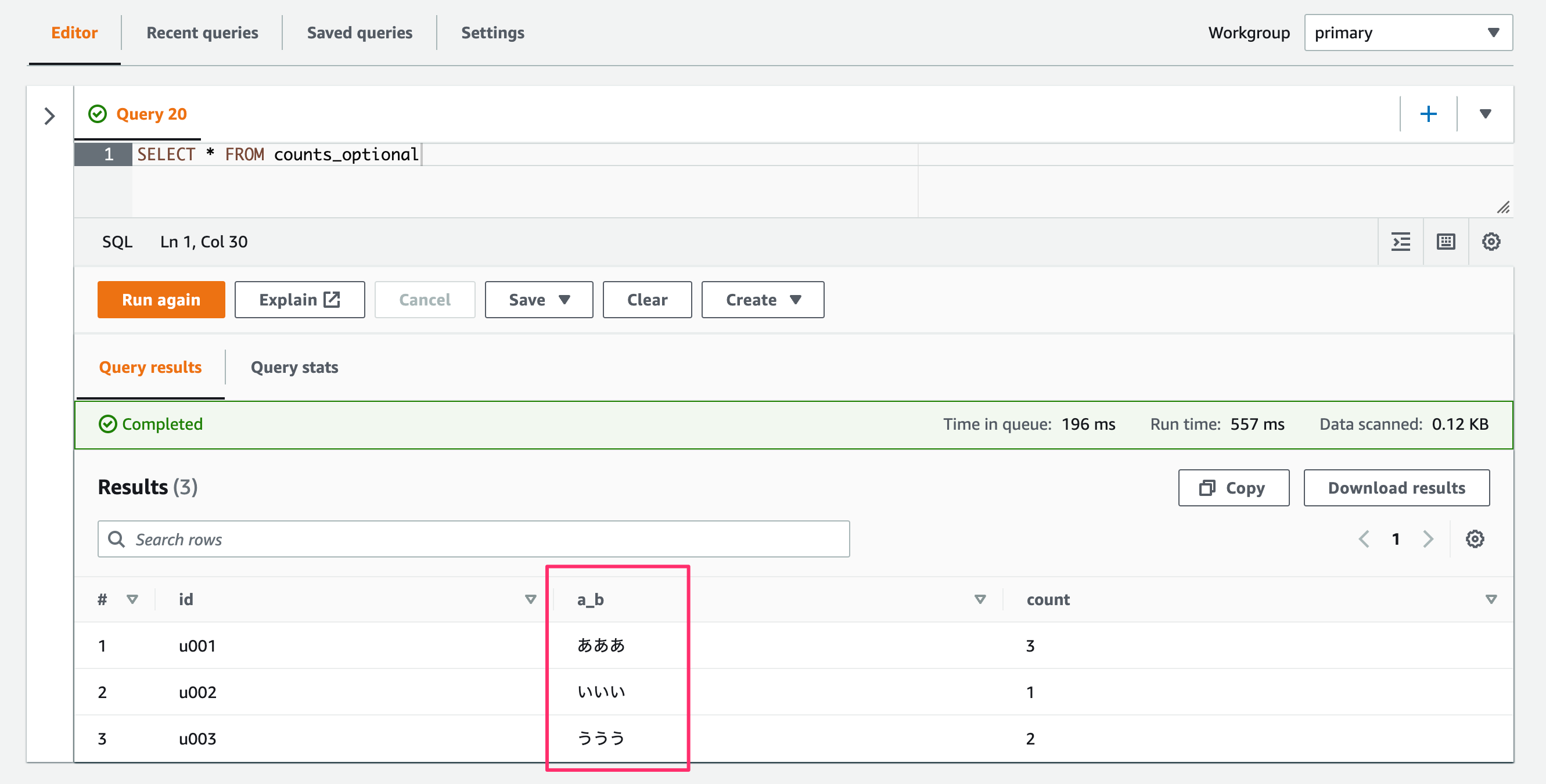
SerDeのオプションを設定したテーブル("dots.in.keys" = "TRUE")に対してSELECTクエリした場合。
SELECT * FROM counts_optional
データ中のa.bプロパティがa_bに置き換えられて取得できました。
case.insensitive
SerDeでcase.insensitiveプロパティがFALSEの場合、データのプロパティ名の大文字/小文字が厳密に扱われます。
countプロパティが大文字となったレコードを含むデータを作成します。
$ data
$ cat $DATA_FILE_NAME
{"id":"u001","COUNT":3}
{"id":"u002","count":1}
{"id":"u003","count":2}
$ DATA_BUCKET_NAME="cm-test-220801"
$ aws s3 cp data s3://${DATA_BUCKET_NAME}/counts/data
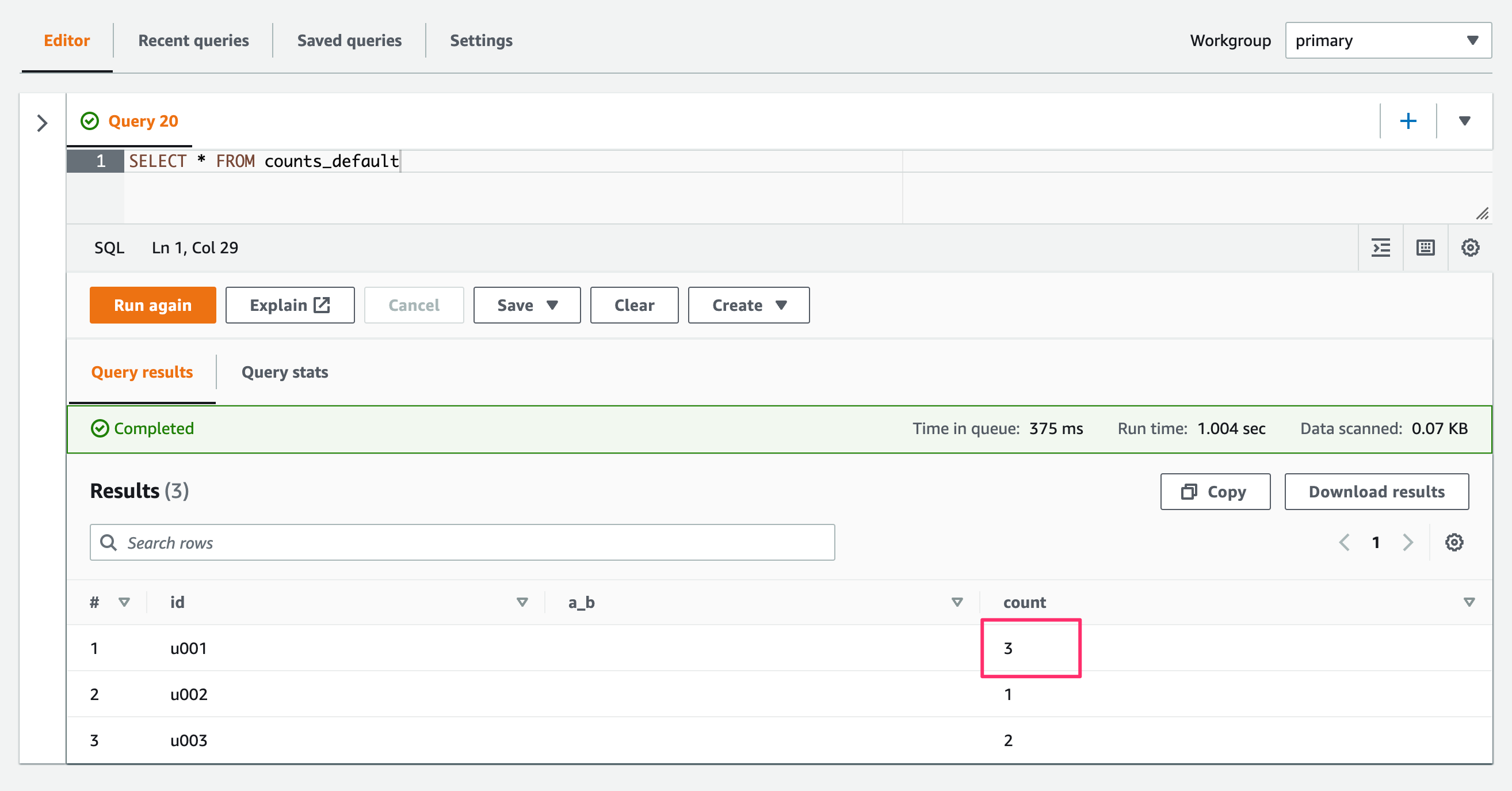
デフォルト設定のテーブル("case.insensitive" = "TRUE")に対してSELECTクエリした場合。
SELECT * FROM counts_default
実際のデータがCOUNTまたはcountのいずれかに関わらず、いずれもcountプロパティとして取得されました。
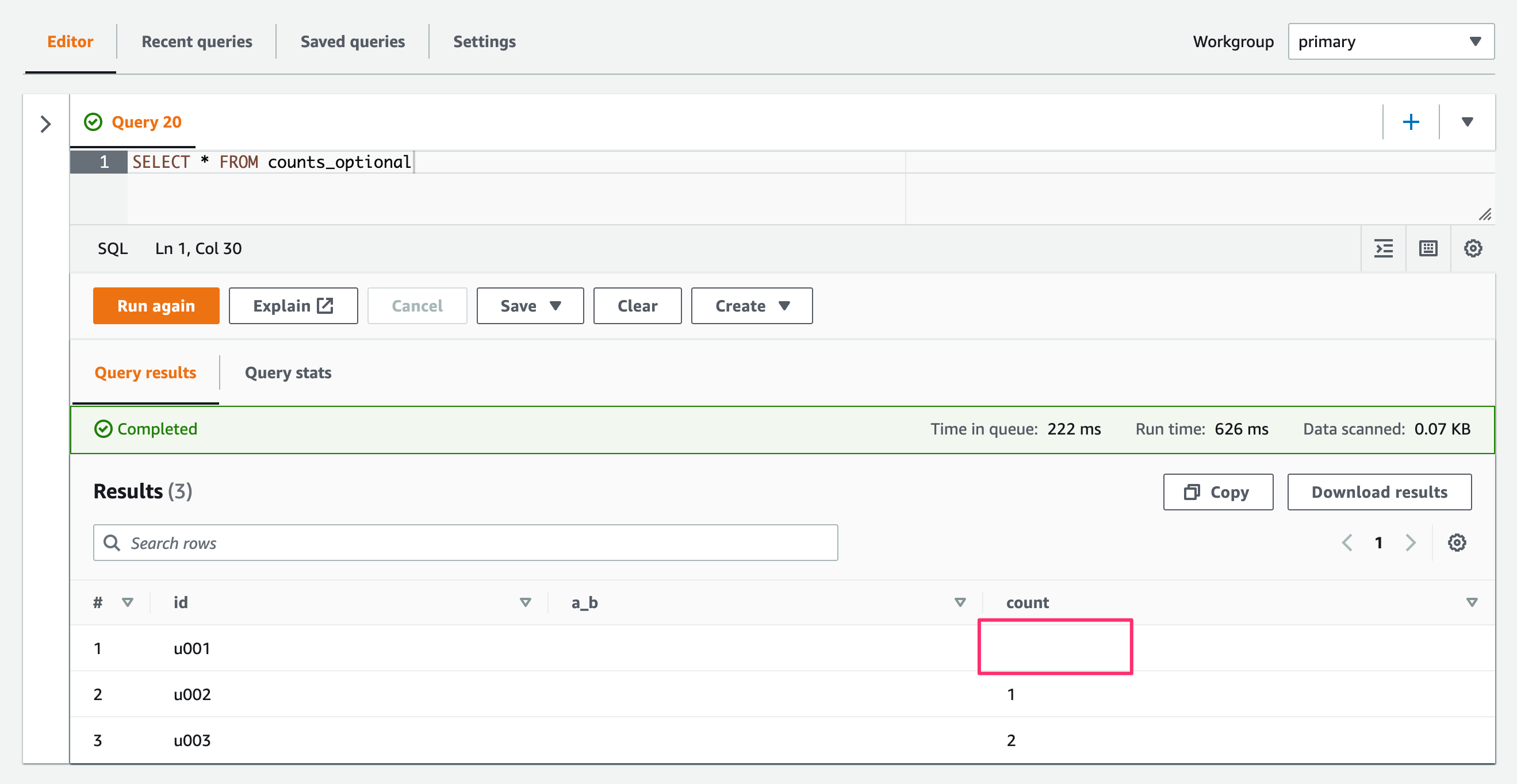
SerDeのオプションを設定したテーブル("case.insensitive" = "FALSE")に対してSELECTクエリした場合。
SELECT * FROM counts_optional
実際のデータがcountの場合のみ取得されました。
mapping
SerDeでmappingプロパティを使用すると、実際のデータとテーブルのスキーマの間でプロパティ名をマッピングすることができます。
マッピング対象のプロパティcntを含むデータを作成します。
$ cat data
{"id":"u001","a_b":"あああ","cnt":3}
{"id":"u002","a_b":"いいい","cnt":1}
{"id":"u003","a_b":"ううう","cnt":2}
$ DATA_BUCKET_NAME="cm-test-220801"
$ aws s3 cp data s3://${DATA_BUCKET_NAME}/counts/data
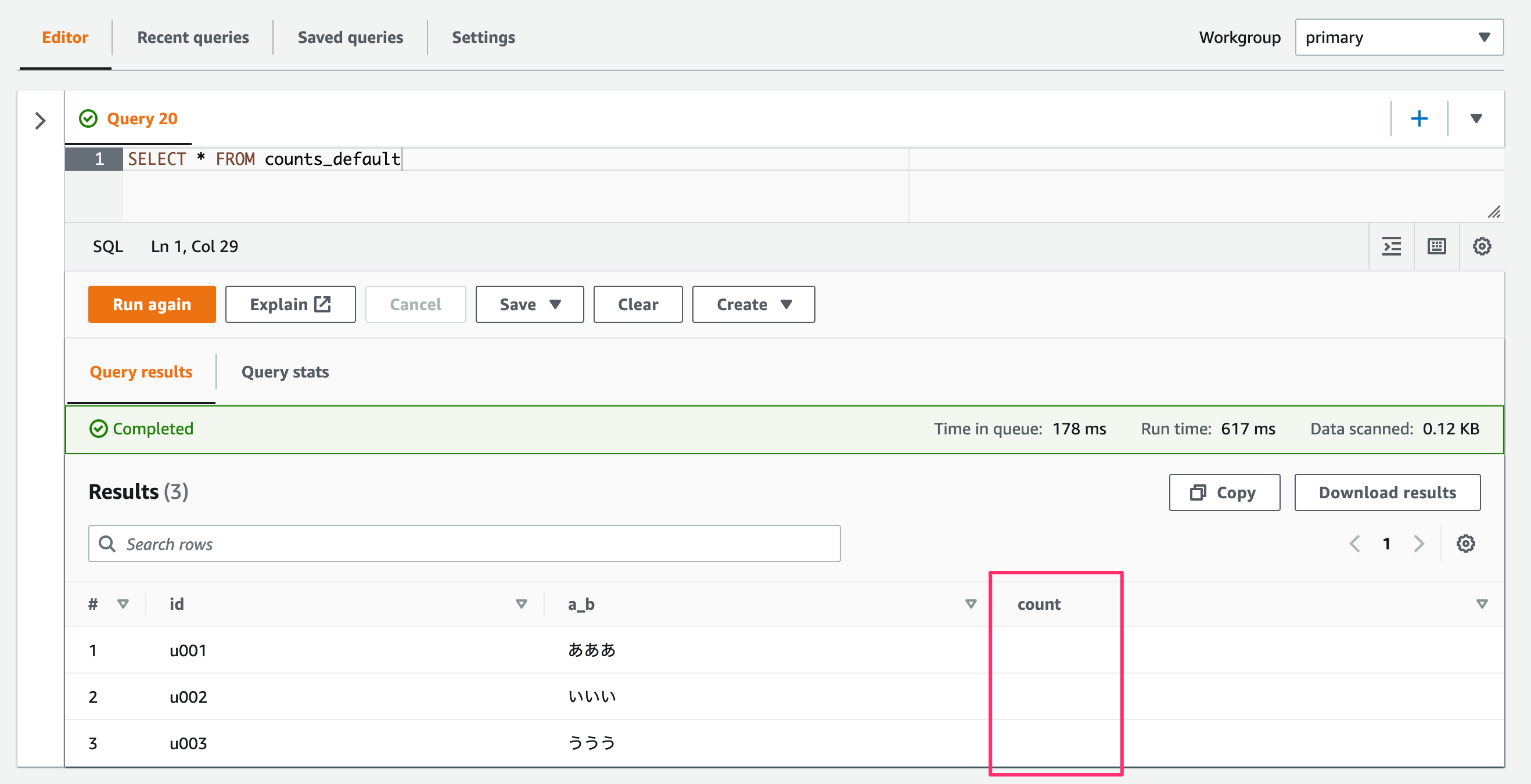
デフォルト設定のテーブルに対してSELECTクエリした場合。
SELECT * FROM counts_default
データのcountプロパティは取得できません。
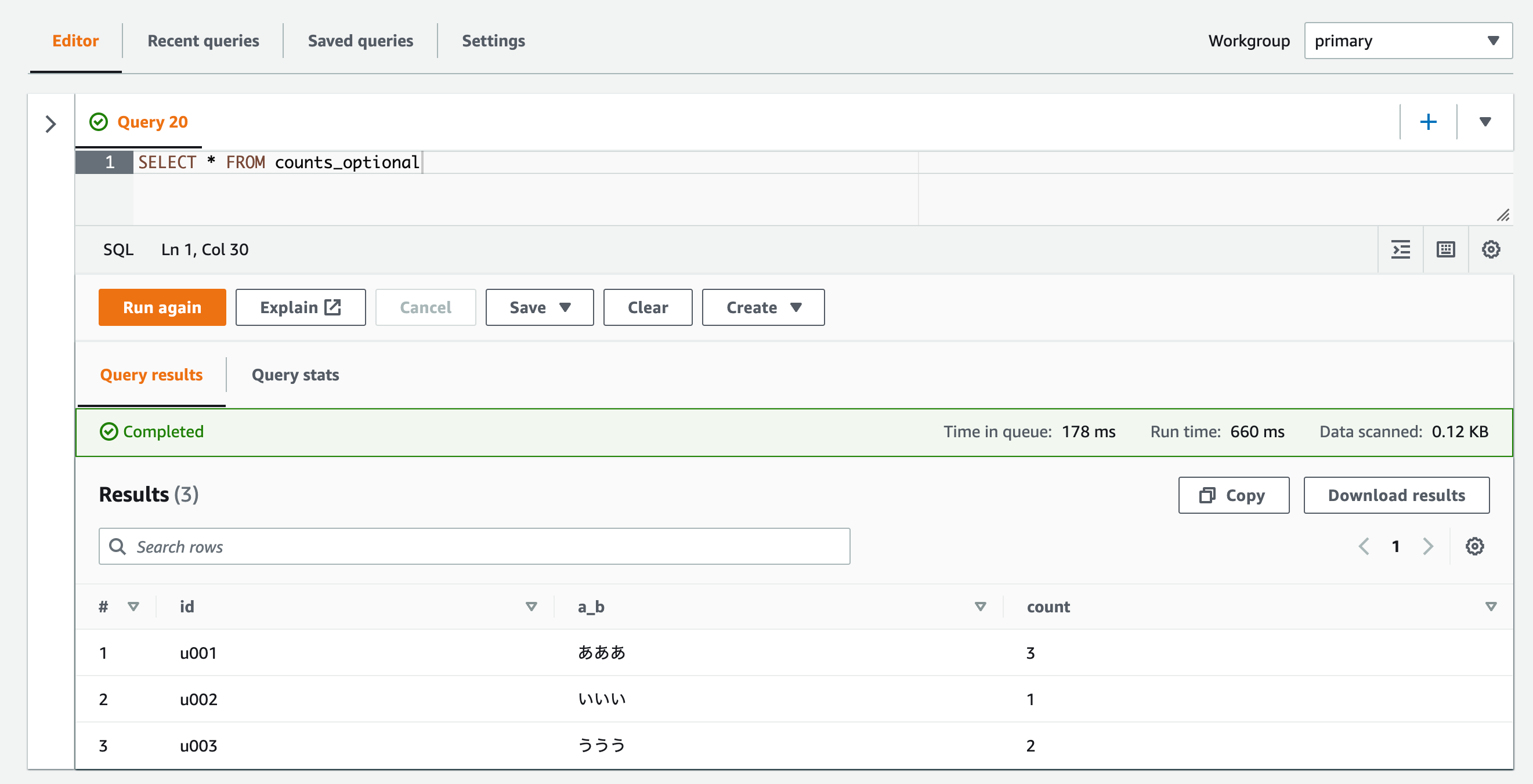
SerDeのオプションを設定したテーブル("mapping.count"= "cnt")に対してSELECTクエリした場合。
SELECT * FROM counts_optional
データのcntプロパティがcountとして取得できました。
おわりに
Amazon AthenaのOpenX JSON SerDeのオプションプロパティを試してみました。
このようにOpenX JSON SerDeは便利ですが、Hive JSON SerDeで利用可能なINSERT INTOが使えないという制限もあります。両者をうまく使い分けたいですね。
以上









