
PostgreSQL互換な分散SQLデータベースのAmazon Aurora DSQLを公開情報から学んでみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
re:Invent 2024 の2日目火曜日のCEOキーノートで新しいAuroraデータベース 「Amazon Aurora DSQL」 が発表されました。会社のYouTubeチャンネルで Werner Vogels のキーノート前日にDSQLについて速報する機会がありました。
コメントのために調べた内容を、一次情報を中心に共有します。
re:Inventが終わった現時点でAmazon Aurora DSQLを知りたければ、4日目の CTO Werner Vogels のキーノートを見ておけば、ほとんどの人にとって十分でしょう。
AWS re:Invent 2024 - Dr. Werner Vogels Keynote DSQLは 1:22:40から
サーバーレス・コンピューティング視点から捉えたければ、Marc Brookerのブログやセッションがオススメです
-
Mark Brooker:DAT424 | Get started with Amazon Aurora DSQL
-
Mark Brooker:DAT427 | Deep dive into Amazon Aurora DSQL and its architecture
Auroraプロダクト群のDSQLのポジショニングを知りたければ、Grant McAlisterによる DAT405 "Deep dive into Amazon Aurora and its innovations" がオススメです
Amazon Aurora DSQLの特徴
DSQL(「ディー・シークウェル」と読みます)は"Distributed PostgreSQL"の略で(チョークトークDAT334のなかでそのような言及あり)、以下の特徴を持っています。
- 複数リージョンにまたがるactive-activeな書き込み
- 高可用
- strong snapshot isolation(PostgreSQLのrepeatable read isolation)
- 楽観的同時実行制御(OCC)
- PostgreSQL(16)互換
- サーバー管理不要(サーバーレス)
大規模複雑システムから小規模システムまでカバー
複数リージョンへのactive-activeな書き込みと言う特徴からは、複雑なシステムをメインターゲットとしているように感じてしまいますが、シングルリージョンでの運用や、日に数回しかリクエストがないような小規模システムでの導入も想定しています。
As we launch Aurora DSQL, we’re talking a lot about multi-region active-active, but that’s not the only thing its for. We built DSQL to be a great choice for single-region applications of all sizes - from a few requests per day to thousands a second and beyond.
そういった背景もあってか、クラスターの作成画面にはリージョンを指定する程度しか設定らしい設定しかなくても、いい感じに動きます。
メモリサイズやレプリカやフェイルオーバーといったデータベースサーバー管理から開放された、サーバーレスな作りです。
結果整合性ではなく強い一貫性が採用されているのも、トレードオフを承知の上で、ビルダー向けにこのような技術選定となっているようです。
Having observed teams at Amazon build systems for over twenty years, we’ve found that application programmers find dealing with eventual consistency difficult, and exposing eventual consistency by default leads to application bugs. Eventual consistency absolutely does have its place in distributed systems8, but strong consistency is a good default. We’ve designed DSQL for strongly consistent in-region (and in-AZ) reads, giving many applications strong consistency with few trade-offs.
AuroraであってAuroraでない、トランザクションデータベースを再設計
Amazon Aurora DSQLは名前にAuroraが含まれていますが、おなじみのAuroraとは中身が別物です。
参加したセッションの中で"Rethinking Transactional Databases" という標語がありました。

※DAT427 セッションから
Amazon Auroraといえば、コンピュートとストレージを分離した設計が有名ですが、Amazon Aurora DSQLはさらに分割が進み(disaggregate)
- SQLコンピュート
- Read
- Write
- ストレージ
がそれぞれ独立に動作・スケールします。
フロントエンド、クエリ実行はPostgreSQL由来ですが、そこから下はトランザクション管理とストレージは新規のものです。
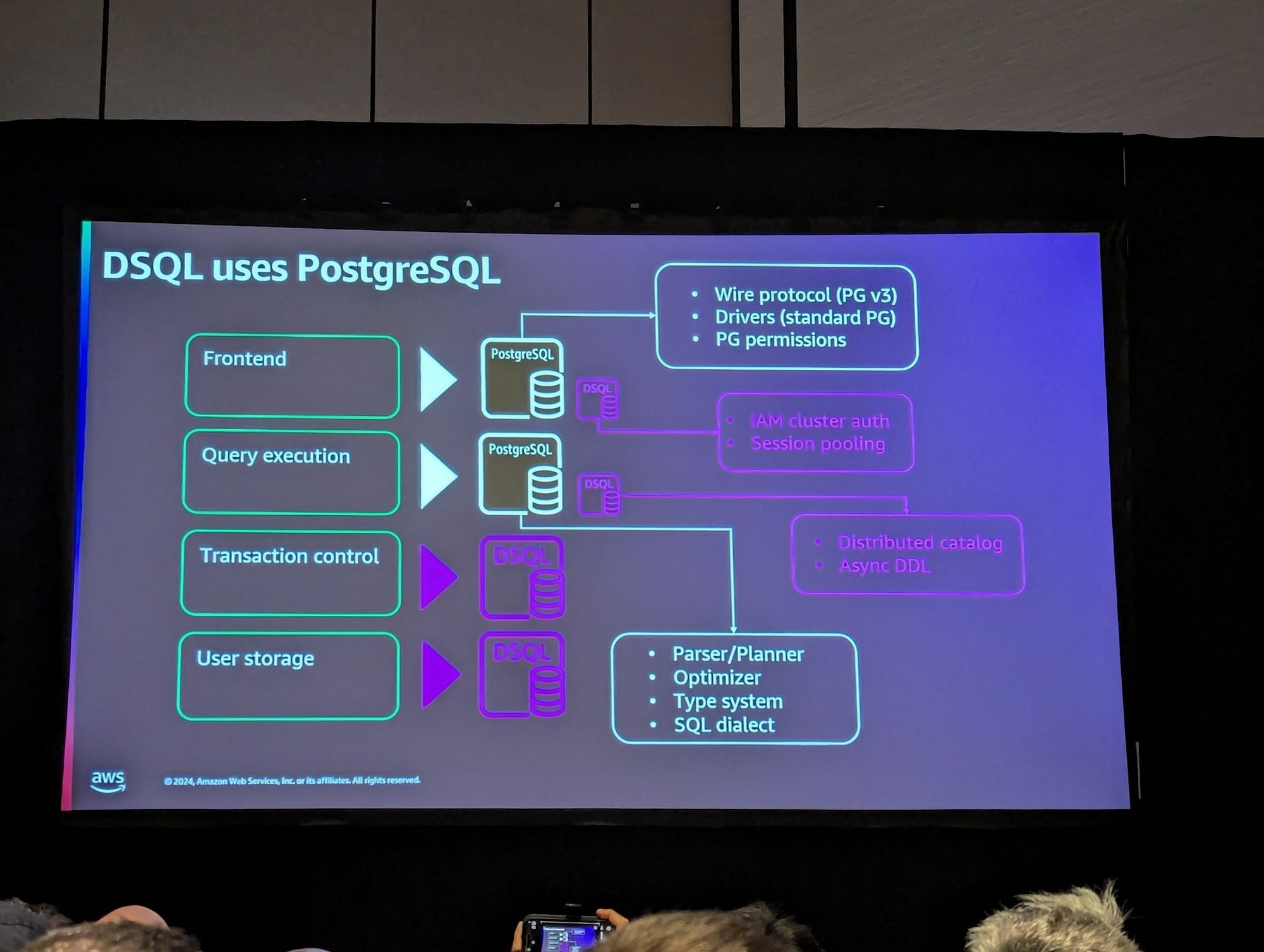
※Chalk Talk DAT334 セッションから
プログラミング言語でいうと、PostgreSQL系はCで書かれており、後者はRustで書かれています。
特に、"Log is the Database"なAuroraストレージは、ジャーナルとストレージに分かれています。
このコンポーネント分割から、PostgeSQL互換は何を指しているのか、イメージしやすいと思います。
リード処理について
DSQLはリージョンをまたいだ active-active に対応した分散データベースです。
読み書きはどうなっているのでしょうか?
Query Processorはストレージに対してページ操作はせず、filtering, aggregation, projection等で行を直接要求します。
ローカルキャッシュを(ほぼ)排除することで、難しいスケール問題も回避しています。
DSQLの読み込みは強い一貫性のスナップショットアイソレーションです。
ハードウェアクロックではなく、Amazon Time Sync Serviceからクロックを取得し、同じAZにあるMVCCストレージからデータを取得します。
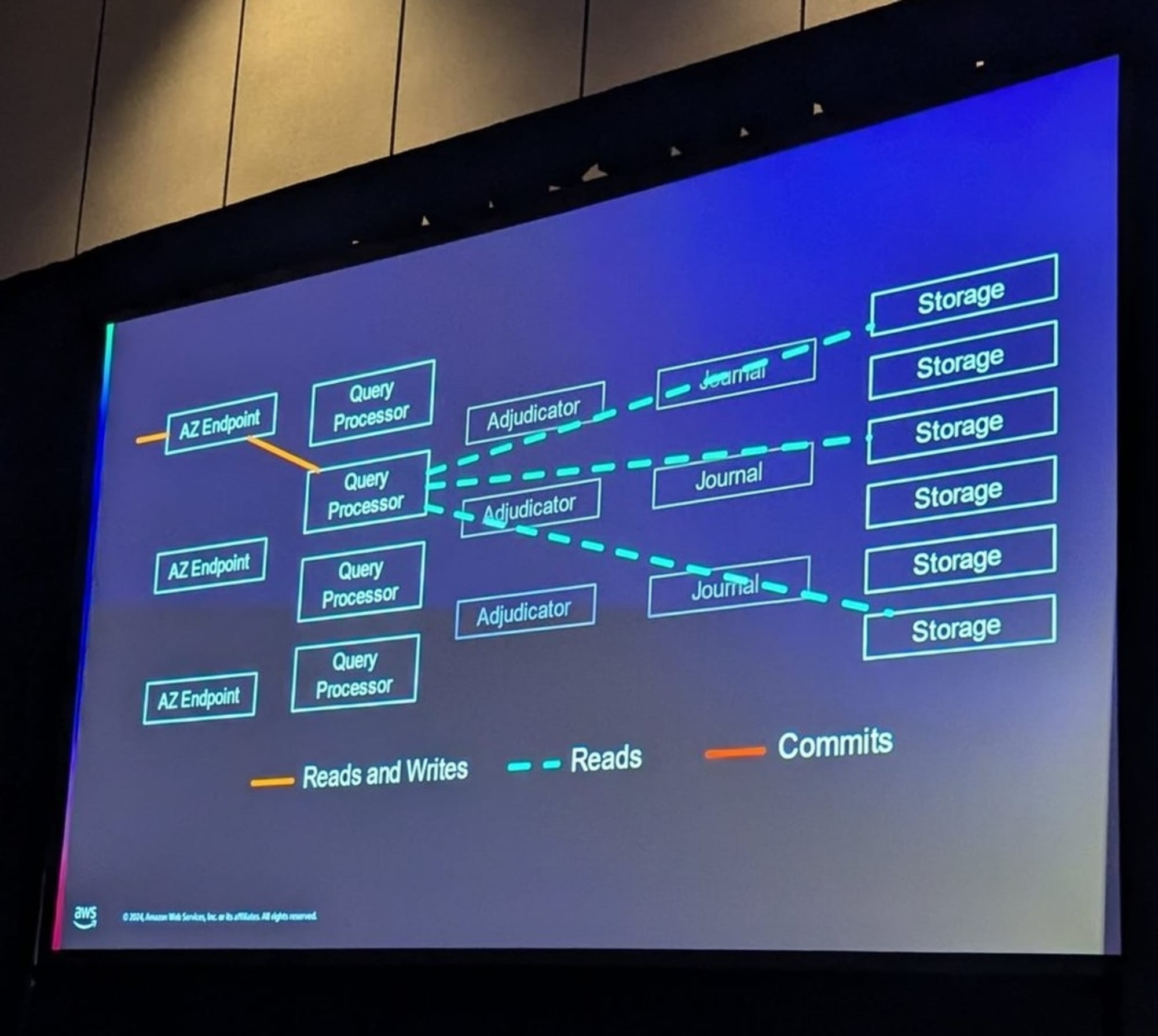
※Chalk Talk DAT334 セッションから

※キーノートから
Write 処理について
書き込み、特にマルチリージョン構成の場合、工夫が必要です。
トランザクションがそれぞれ分離されていて(isolated; ACIDのI)、正しく順序をつけるのが、coordinationとなる Adjudicator(「ァデューディケーター」とよみます)コンポーネントです。
Adjudicatorがトランザクション間のコンフリクトをチェックし、問題がなければ、Journalに書き込みし、その後、トランザクションログを別AZ・リージョンに同期的にレプリケートします。
更新ステートメントはQuerry Processor内で行われ、COMMITのタイミングでStorageに反映されます。
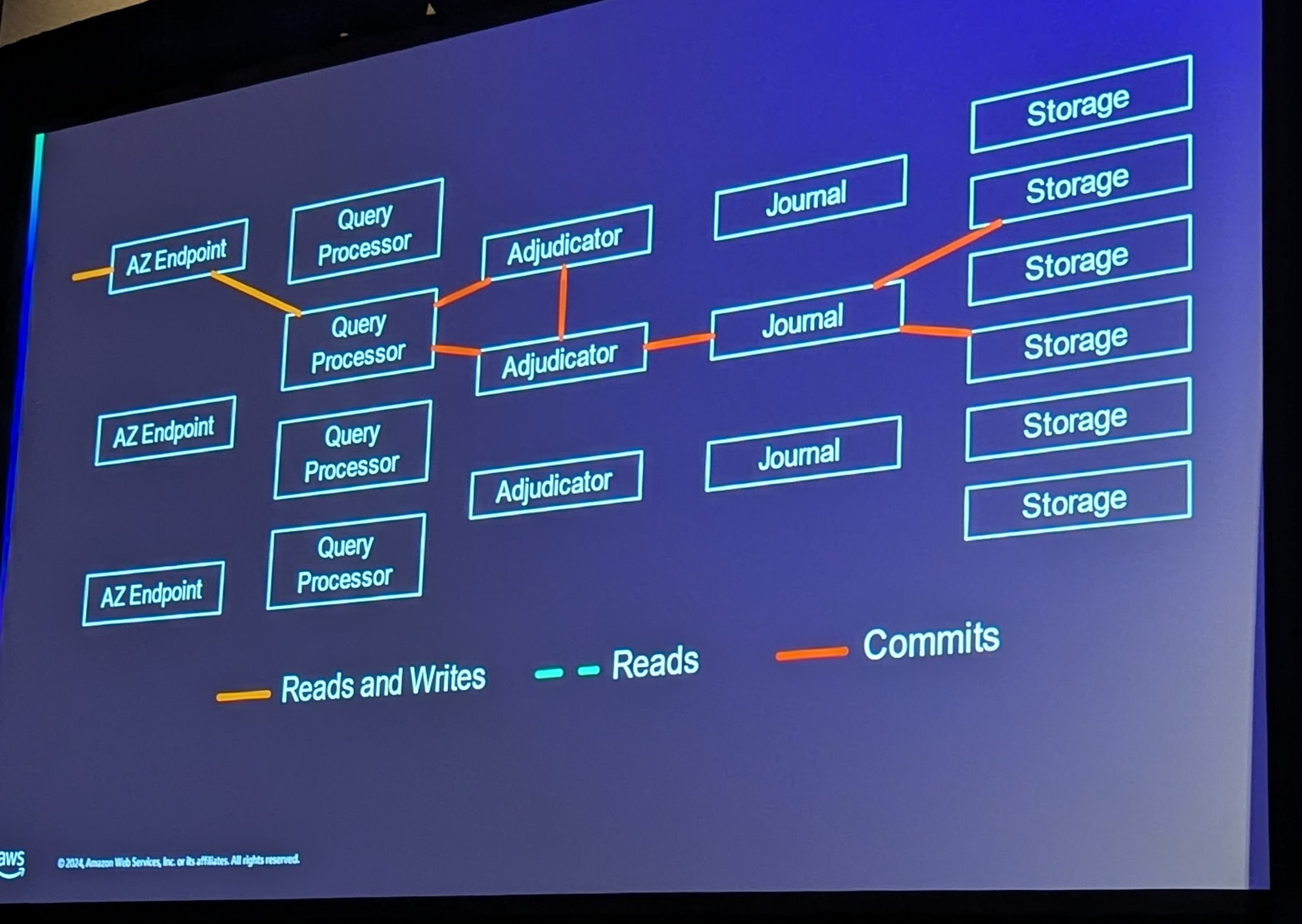
※Chalk Talk DAT334 セッションから
Optimistic Concurrency Control(OCC)とロックフリー
DSQLは類似製品に比べて書き込みが4倍はやい(レイテンシーが低い)と宣伝されています。ここで肝になるのがOCCとロックです。
悲観的(pessimistic)なアプローチでは、先にロックを取り、他の読み書きをブロックして、処理します。この場合、ロック中は他のトランザクション処理をブロックしてしまいます。
DSQLの楽観的(optimistic)なアプローチでは、コンフリクトが稀という想定のもと、COMMITのタイミングでコンフリクトを検知します。
書き込みキーが一様になるようにキー設計し、コンフリクト時のリトライが求められます。
- Concurrency control in Amazon Aurora DSQL | AWS Database Blog
- DSQL Vignette: Transactions and Durability - Marc's Blog
DSQLを支える技術
firecracker VMM、Cappian(スケールアップ)、Amazon Time Sync Servicなど、AWSの基盤システムを支える様々なサービスが活用されています。
例えば、クエリープロセッサー(PostgreSQL)は firecracker VMM 上で操作し、クエリー事にスケールアップ・アウトします。
re:Invent EXPOでのQ&A対応もあり
re:Invent 現地では、セッションやキーノートが主な情報源ですが、Expoを徘徊していると、何人ものDSQL開発陣がユーザーの質問を丁寧に対応してくれることに気づきました。
質問内容によってはよりシニアなエンジニアにエスカレーションするようで、質問の把握、説明のわかりやすさと、シニアなエンジニアはレベルが違いました。後でお名前を確認すると、対応してくださったのは、ローンチブログを書いたRaluca Constantinさんでした。
DSQL開発経緯
DSQLにはAWS Lambda のFirecrackerといった基盤技術に本質的に貢献したMarc Brookerが携わり、開発経緯が次のブログの "A Personal Story" にまとめられています
DSQL Vignette: Aurora DSQL, and A Personal Story - Marc's Blog
これによると、AWS Lambdaのようなサーバーレスコンピュート技術に携わる中で、以下のカスタマーペインを感じていたそうです
- サーバーレスコンピューティングシステムと古典的なRDBがスケーラビリティその他で相性が良くない(ギャップを埋める Amazon RDS Proxy というサービスがありますね)
- マルチリージョンでグローバルなサービスを妥協せずに運用するのが難しい
Auroraを現代風に再実装する周辺技術が揃ってきたことから、2021年からAuroraやQLDBといったAWSのデータベースチームと具体的な検討を進め、リリースにこぎつけたようです。
楽観的同時実行制御(OCC)、強い一貫性、選択肢を与えないシンプルでサーバーレスなクラスタ運用。
DSQLの出自がサーバーレスコンピュート部門ではなく、データベース部門だったら、分散Auroraはまた違った味付けになったのではないでしょうか?
2014年に発表されたAWS LambdaとAWS Auroraが10年の時を経てAmazon Aurora DSQLで合流したような印象を持ち、個人的には非常にムネアツな新サービス発表でした。
PR:2024/12/05(月)週はクラスメソッド全国拠点でAmazon Aurora DSQLの話が聞けるかも?
クラスメソッドでは、来週から東京、大阪、札幌、福岡と全国各地の拠点でre:Invent 2024の振り返りイベントを実施します。
- 東京12/10(火)
- 大阪12/11(水)
- 札幌12/12(木)
- 福岡12/12(木) ※ 登壇します
スピーカー陣からやんわりヒアリングする限り、各拠点では何らかの形で Amazon Aurora DSQL のトピックが登場しそうです(知らんけど)。
楽観的同時実行制御(OCC)のAmazon Aurora DSQLらしく、スピーカーはネタ被り上等で話す所存ですので、是非ご参加ください。
リソース
Vogelのキーノートセッション
AWS re:Invent 2024 - Dr. Werner Vogels Keynote. DSQL は 1:22:40 から
ドキュメント系
- Distributed SQL Databases - Amazon Aurora DSQL - AWS
- Press Center AWS-Announces-New-Database-Capabilities-Including-Amazon-Aurora-DSQL-the-Fastest-Distributed-SQL-Database - US Press Center
- AWS Databa blog Introducing Amazon Aurora DSQL | AWS Database Blog
- AWS Database blog Concurrency control in Amazon Aurora DSQL | AWS Database Blog
- AWS Document What is Amazon Aurora DSQL? - Amazon Aurora DSQL
- AWS API ReferenceWelcome - Amazon Aurora DSQL
re:Invent セッション系
- Mark Brooker:DAT424 | Get started with Amazon Aurora DSQL
- Mark Brooker:DAT427 | Deep dive into Amazon Aurora DSQL and its architecture
- Grant McAlister : DAT405 | Deep dive into Amazon Aurora and its innovations
- DAT334 | Build resilient, high-performance applications with Amazon Aurora DSQL










