
AgentCore Evaluations のバッチ評価(Preview)を試してみた
はじめに
こんにちは、スーパーマーケットが好きなコンサルティング部の神野(じんの)です。
以前、ブログでAgentCore Evaluations の概要や On-demand 評価について紹介しました。
継続的に本番環境の評価を行うならオンライン評価、特定のセッションを評価したいならオンデマンド評価を使うといった使い分けでした。そこに最近バッチ評価も追加されました!
名前の通り複数のセッションをまとめて一括で評価する機能です。リグレッションテストをしたい時のように一括で評価したい時に良さそうですね。
今回はこのバッチ評価を実際に試してみたので、セットアップから結果の確認までの流れを紹介していきます!
前提
今回は下記バージョンを使用しました。
-
AgentCore CLI 1.0.0-preview.8
-
Python 3.13
-
CloudWatch の Transaction検索が有効化済み
-
使用したリージョン
- us-east-1
-
使用したモデル
- us.anthropic.claude-haiku-4-5-20251001-v1:0
バッチ評価の位置づけ
AgentCore Evaluations の概要や組み込みエバリュエータについては前回の記事で紹介していますが、改めて全ての評価方法を整理します。
| 観点 | On-demand | Online | Batch |
|---|---|---|---|
| トリガー | 呼び出し側が開始(同期) | 継続的・イベント駆動 | 呼び出し側が開始(非同期) |
| セッションソース | 呼び出し側がセッションID、もしくは span をインライン提供 | ロググループを監視 | CloudWatch Logs からサービスが自動発見 |
| スコープ | 単一セッション | サンプリングルールに合致する全セッション | 複数セッション(時間範囲・セッションID指定可) |
| グランドトゥルース(正解データ) | evaluationReferenceInputs 経由 | サポートなし | sessionMetadata でインライン指定 |
| 結果 | 同期レスポンス | CloudWatch メトリクス / ダッシュボード | 集約サマリー + CloudWatch にセッション別詳細 |
| ユースケース | 開発時のスポットチェック、CI/CD | 本番モニタリング | ベースライン測定、変更前後の比較、リグレッションテスト |
補足ですが、グランドトゥルースは「期待される正解」のことで、期待される応答文・ツール呼び出し順序・満たすべき条件をあらかじめ定義しておき、エージェントの実際の振る舞いと突き合わせて評価します。オンライン評価は本番トラフィックを常時監視する仕組みのため、事前に正解を用意できずグランドトゥルースは使えません。
On-demand は前回の記事で試した方式で、呼び出し側が個別のセッションIDを指定していましたが、バッチ評価では複数のセッションに対して、セッションの発見・span の収集・スコアリングの全てをサービス側で処理してくれるので、ジョブを投入するだけになります。
また、バッチ評価では Trajectory 系エバリュエータも使えます。最近追加されたエバリュエータですね。これはエージェントが期待通りの順番でツールを呼んだかを評価するもので、3種類あります。
| エバリュエータ | 評価内容 | 例(期待: A → B → C) |
|---|---|---|
| TrajectoryExactOrderMatch | 期待通りの順番で、余分なツール呼び出しもない | A → B → C なら合格、A → B → X → C は不合格 |
| TrajectoryInOrderMatch | 期待通りの順番だが、間に別のツールが入ってもOK | A → B → X → C でも合格 |
| TrajectoryAnyOrderMatch | 順番は問わず、期待したツールが全て使われていればOK | B → C → A でも合格 |
どこまで厳密にツール呼び出し順序を評価したいかによって使い分ける形です。ちなみにオンライン評価では利用不可で、バッチ評価とオンデマンド評価のみ利用可能です。
サンプルエージェントの作成とデプロイ
公式ドキュメントの Getting Started では Acme Store のカスタマーサポートエージェントが使われていますが、今回は社内ITヘルプデスクエージェントに変えて試してみます。
社員からの問い合わせに対して、チケット照会・パスワードリセット・システム稼働状況確認・チケット作成・エンジニアへのエスカレーションの5つのツールで対応するエージェントです。
プロジェクト作成
まず AgentCore CLI でプロジェクトを作成します。
agentcore create --name HelpDesk --framework Strands --model-provider Bedrock --memory none
cd HelpDesk
エージェントコードの実装
app/HelpDesk/main.py を下記の内容で置き換えます。
コード全体
"""Corporate IT helpdesk agent."""
from strands import Agent, tool
from strands.models.bedrock import BedrockModel
from bedrock_agentcore.runtime import BedrockAgentCoreApp
app = BedrockAgentCoreApp()
MODEL_ID = "us.anthropic.claude-haiku-4-5-20251001-v1:0"
SYSTEM_PROMPT = (
"あなたは社内ITヘルプデスクのアシスタントです。"
"社員からのIT関連の問い合わせ、パスワードリセット、"
"システム稼働状況の確認、チケット管理をサポートしてください。"
)
@tool
def lookup_ticket(ticket_id: str) -> str:
"""Look up a support ticket by ID and return its status and details."""
tickets = {
"TKT-2001": {
"status": "open",
"category": "network",
"summary": "VPN connection drops during video calls",
"priority": "high",
"created": "2026-05-20",
"assignee": "network-team",
},
"TKT-2002": {
"status": "in_progress",
"category": "hardware",
"summary": "Laptop battery drains in 2 hours",
"priority": "medium",
"created": "2026-05-18",
"assignee": "hardware-team",
"note": "Replacement battery ordered, arriving May 25",
},
"TKT-2003": {
"status": "resolved",
"category": "software",
"summary": "Slack notifications not working on macOS",
"priority": "low",
"created": "2026-05-15",
"resolved": "2026-05-16",
"resolution": "Updated Slack to v4.41, re-enabled notification permissions",
},
"TKT-2004": {
"status": "open",
"category": "access",
"summary": "Cannot access AWS console after team transfer",
"priority": "high",
"created": "2026-05-22",
"assignee": "iam-team",
},
"TKT-2005": {
"status": "pending",
"category": "software",
"summary": "Need license for JetBrains IntelliJ IDEA",
"priority": "low",
"created": "2026-05-21",
"note": "Waiting for manager approval",
},
}
return str(tickets.get(ticket_id, {"error": f"Ticket {ticket_id} not found"}))
@tool
def reset_password(employee_id: str, system: str) -> str:
"""Reset password for an employee on a specified system."""
supported = {"active_directory", "aws_console", "jira", "confluence", "slack"}
if system.lower() not in supported:
return f"System '{system}' is not supported. Supported: {', '.join(sorted(supported))}"
return (
f"Password reset completed for {employee_id} on {system}. "
"Temporary password sent to registered email. "
"Please change it within 24 hours."
)
@tool
def check_system_status(system_name: str) -> str:
"""Check the current operational status of a company system."""
statuses = {
"vpn": {
"status": "degraded",
"message": "Intermittent drops reported in Tokyo office. Engineering investigating.",
"since": "2026-05-24T08:30:00+09:00",
},
"email": {
"status": "operational",
"message": "All email services running normally.",
},
"aws_console": {
"status": "operational",
"message": "All AWS services accessible.",
},
"jira": {
"status": "maintenance",
"message": "Scheduled maintenance until 22:00 JST. Read-only access available.",
},
}
info = statuses.get(system_name.lower())
if not info:
return f"System '{system_name}' not found. Available: {', '.join(sorted(statuses.keys()))}"
return str(info)
@tool
def create_ticket(category: str, summary: str, priority: str) -> str:
"""Create a new support ticket for the employee."""
return (
"Ticket TKT-3001 created successfully. "
f"Category: {category}, Priority: {priority}. "
f"Summary: {summary}. "
"You will receive email updates on progress."
)
@tool
def escalate_to_engineer(ticket_id: str, reason: str) -> str:
"""Escalate a ticket to a senior engineer for immediate attention."""
return (
f"Ticket {ticket_id} escalated to senior engineering team. "
f"Reason: {reason}. "
"Expected response within 30 minutes during business hours."
)
agent = Agent(
model=BedrockModel(model_id=MODEL_ID),
tools=[lookup_ticket, reset_password, check_system_status,
create_ticket, escalate_to_engineer],
system_prompt=SYSTEM_PROMPT,
)
@app.entrypoint
def invoke(payload, context):
result = agent(payload.get("prompt", "Hello"))
return {"response": str(result)}
if __name__ == "__main__":
app.run()
チケット管理・パスワードリセット・システム状態確認、VPN の障害や Jira のメンテナンスなどイメージしてみました。
デプロイと動作確認
agentcore deploy
デプロイ後、動作を確認します。
agentcore invoke --prompt "チケット TKT-2001 の状況を教えてください"
チケット TKT-2001 の状況は以下の通りです:
| 項目 | 内容 |
|------|------|
| 状態 | オープン(対応中) |
| カテゴリ | ネットワーク |
| 概要 | ビデオ通話中のVPN接続切断 |
| 優先度 | 高 |
| 作成日 | 2026年5月20日 |
| 担当者 | ネットワークチーム |
このチケットは高優先度で、ネットワークチームが対応中です。
ビデオ通話中のVPN接続切断の問題については、高優先度で処理されています。
チケットの詳細が返ってきましたね! agentcore status --json から Runtime ARN を確認できます。
agentcore status --json
{
"resources": [
{
"name": "HelpDesk",
"deploymentState": "deployed",
"identifier": "arn:aws:bedrock-agentcore:us-east-1:123456789012:runtime/HelpDesk_HelpDesk-qTj1toGZS8",
"detail": "READY"
}
]
}
boto3 で操作する場合は、この Runtime ARN に加えてサービス名とログループ名が必要です。これらは Runtime ID から以下のルールで導出できます。
- Runtime ID:
HelpDesk_HelpDesk-qTj1toGZS8(ARN の末尾部分) - サービス名:
{Runtime ID}.DEFAULT - ログループ名:
/aws/bedrock-agentcore/runtimes/{Runtime ID}-DEFAULT
サンプルセッションの生成
バッチ評価を実行するには、まず評価対象のセッションが CloudWatch Logs に記録されている必要があります。さまざまなシナリオでエージェントを呼び出してセッションを生成していきます。
AgentCore CLI での実行
agentcore invoke --runtime HelpDesk --prompt "チケット TKT-2001 の状況を教えてください"
agentcore invoke --runtime HelpDesk --prompt "VPN が不安定なのですが、システムの状態を確認できますか?"
agentcore invoke --runtime HelpDesk --prompt "Active Directory のパスワードをリセットしてほしいです。社員IDは EMP-1234 です。"
agentcore invoke --runtime HelpDesk --prompt "TKT-2002 のノートPC バッテリーの件、進捗はどうなっていますか?"
agentcore invoke --runtime HelpDesk --prompt "Jira にログインできないのですが、メンテナンス中ですか?"
agentcore invoke --runtime HelpDesk --prompt "チーム異動で AWS コンソールにアクセスできなくなりました。TKT-2004 を確認してもらえますか?"
agentcore invoke --runtime HelpDesk --prompt "Slack の通知が来ないのですが、以前同じ問題のチケットがありませんでしたか? TKT-2003 を確認してください。"
agentcore invoke --runtime HelpDesk --prompt "IntelliJ のライセンス申請 TKT-2005 がまだ承認待ちです。エスカレーションできますか?"
agentcore invoke --runtime HelpDesk --prompt "メールが送れないのですが、システム障害でしょうか?チケットを作ってください。"
agentcore invoke --runtime HelpDesk --prompt "VPN が会議中に何度も切れます。TKT-2001 をエスカレーションしてください。"
チケット照会・パスワードリセット・システム状態確認・エスカレーションなど、さまざまなパターンを含めています。
いくつか実行結果を紹介します。
VPN のシステム状態確認
VPN の状態を確認しました。以下の結果です:
現在のシステム状態: 低下中(Degraded)
- 詳細: 東京オフィスで断続的な接続ドロップが報告されています
- 対応状況: エンジニアリングチームが現在調査中です
- 発生時刻: 2026年5月24日 08:30 から
VPN の不安定さはシステム側の問題が原因のようです。
エンジニアが対応中なので、状況の改善を待つようお願いします。
メール障害の確認 + チケット作成
確認結果をお知らせします:
メールシステムの状況: 正常に稼働しています
- 現在、すべてのメールサービスは正常に動作しており、システム障害は確認されません。
サポートチケットを作成しました:
- チケットID: TKT-3001
- カテゴリ: メール
- 優先度: 高
- 内容: メールが送信できない問題
システムは正常ですが、個別の環境での問題の可能性があります。
check_system_status でシステム状態を確認した上でチケットを作成するなど、複数ツールを組み合わせた対応もちゃんとできていますね!
バッチ評価の実行
ここからが本題です!実際にバッチ評価を実行していきます。
AgentCore CLI での実行
AgentCore CLI を使うのが最もシンプルです。
agentcore run batch-evaluation \
--runtime HelpDesk \
--evaluator Builtin.GoalSuccessRate Builtin.Helpfulness Builtin.Faithfulness
CLI がプロジェクト設定から CloudWatch のログループとサービス名を自動解決し、ジョブを開始してポーリングしてくれます。完了すると以下のような出力が得られます。
Batch evaluation completed: HelpDesk_HelpDesk_1779590150637-d63979747f
Sessions: 13 completed, 0 failed, 13 total
Evaluator Avg Score
─────────────────────────────────────────────
Builtin.GoalSuccessRate 1.0000
Builtin.Helpfulness 0.8400
Builtin.Faithfulness 1.0000
Results saved to .cli/batch-eval-results/
出力されました!3つのエバリュエータの平均スコアがわかりますね! GoalSuccessRate と Faithfulness がどちらも満点の1.0、Helpfulness も0.84とスコアが出ました。ツール呼び出しの正確さと、ツール出力に基づいた回答の忠実性は完璧に評価されています。Helpfulness は全セッションで Very Helpful 以上の評価でした。
boto3 でより細かい制御が必要な場合
import boto3
import uuid
import time
import json
REGION = "us-east-1"
SERVICE_NAME = "HelpDesk-xyz789.DEFAULT"
LOG_GROUP = "/aws/bedrock-agentcore/runtimes/HelpDesk-xyz789-DEFAULT"
eval_client = boto3.client("bedrock-agentcore", region_name=REGION)
response = eval_client.start_batch_evaluation(
batchEvaluationName=f"helpdesk_baseline_{uuid.uuid4().hex[:8]}",
evaluators=[
{"evaluatorId": "Builtin.GoalSuccessRate"},
{"evaluatorId": "Builtin.Helpfulness"},
{"evaluatorId": "Builtin.Faithfulness"},
],
dataSourceConfig={
"cloudWatchLogs": {
"serviceNames": [SERVICE_NAME],
"logGroupNames": [LOG_GROUP],
}
},
clientToken=str(uuid.uuid4()),
)
batch_eval_id = response["batchEvaluationId"]
print(f"Started: {batch_eval_id}")
while True:
result = eval_client.get_batch_evaluation(batchEvaluationId=batch_eval_id)
status = result["status"]
print(f"Status: {status}")
if status in ("COMPLETED", "COMPLETED_WITH_ERRORS", "FAILED", "STOPPED"):
break
time.sleep(30)
print(json.dumps(result, indent=4, default=str))
start_batch_evaluation でジョブを開始し、get_batch_evaluation でポーリングしています。dataSourceConfig に CloudWatch Logs のサービス名とログループ名を指定するだけで、サービス側がセッションを自動的に発見してくれます。
filterConfig を使えば特定のセッションIDや時間範囲でフィルタリングすることも可能です。
結果の確認
集約結果
.cli/eval-job-results/ のレスポンスには集約されたサマリーが含まれます。
{
"batchEvaluationId": "HelpDesk_HelpDesk_1779590150637-d63979747f",
"status": "COMPLETED",
"evaluationResults": {
"numberOfSessionsCompleted": 13,
"numberOfSessionsFailed": 0,
"numberOfSessionsIgnored": 0,
"numberOfSessionsInProgress": 0,
"totalNumberOfSessions": 13,
"evaluatorSummaries": [
{
"evaluatorId": "Builtin.GoalSuccessRate",
"statistics": {
"averageScore": 1.0
},
"totalEvaluated": 13,
"totalFailed": 0
},
{
"evaluatorId": "Builtin.Faithfulness",
"statistics": {
"averageScore": 1.0
},
"totalEvaluated": 13,
"totalFailed": 0
},
{
"evaluatorId": "Builtin.Helpfulness",
"statistics": {
"averageScore": 0.84
},
"totalEvaluated": 13,
"totalFailed": 0
}
]
}
}
セッションの成功 / 失敗数と、各エバリュエータの平均スコアが一覧で確認できます。1ジョブあたり最大500セッションまで評価可能で、超過分は最新の500件が選択されます。
CLI で実行した場合、結果の JSON は .cli/batch-eval-results/ 配下にも保存されます。ただし中身を見てみると、こんな感じでセッション ID やプロンプトは含まれていません。
{
"results": [
{
"evaluatorId": "Builtin.Faithfulness",
"score": 1,
"label": "Completely Yes",
"explanation": "The assistant's response provides information about ticket TKT-2004..."
},
{
"evaluatorId": "Builtin.Helpfulness",
"score": 0.83,
"label": "Very Helpful",
"explanation": "The user's goal is to understand the status of their ticket (TKT-2004)..."
},
...
]
}
エバリュエータ ID・スコア・explanation がフラットに並んでいるだけなので、explanation の中身を読んで初めて「これは TKT-2004 の問い合わせの結果だな」とわかる構造です。13セッション × 3エバリュエータ = 39件の結果が並ぶので、個別セッションの確認にはちょっと厳しいですね。
コンソールでの確認
セッション別の結果を確認するなら、AgentCore コンソールから見るのが手軽です。
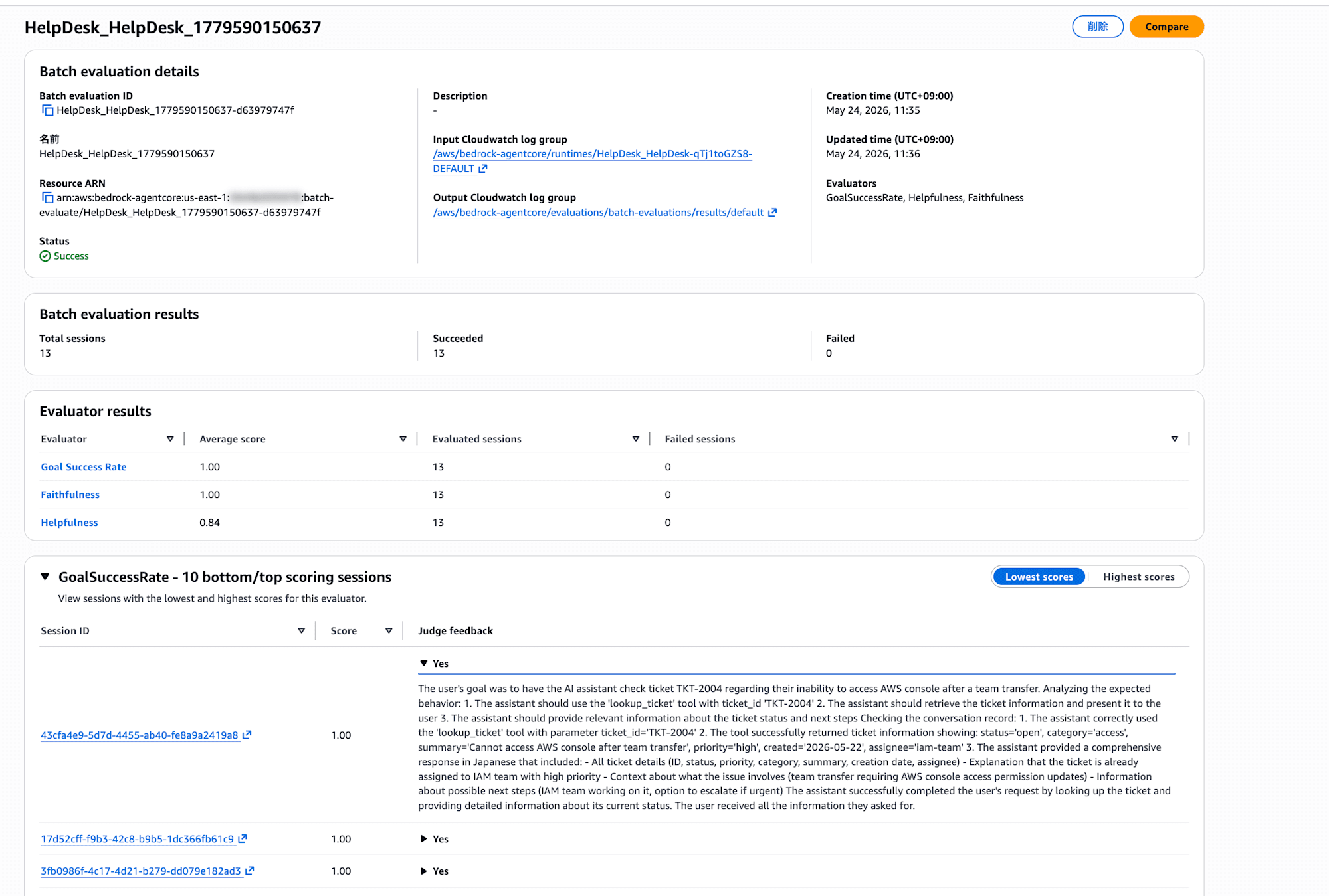
Batch evaluation details にはジョブの ID / ステータス / 入出力の CloudWatch ログループが表示されています。Batch evaluation results には全体のセッション数と成功・失敗の内訳、Evaluator results には各エバリュエータの平均スコアが一覧で確認できます。
さらに下部にはエバリュエータごとの上位・下位セッション一覧があり、セッション ID をクリックすると個別の Judge feedback(LLM がつけたスコアの根拠)も展開して読めます。JSON を眺めるよりも圧倒的にわかりやすいので、まずはコンソールで全体像を掴むのがおすすめです。
コードでセッション別詳細を取得する
コンソールで確認するのが楽ですが、CI/CD パイプラインに組み込んだり結果を加工したい場合はコードから取得することもできます。結果は CloudWatch Logs に OpenTelemetry イベントとして書き込まれています。
import boto3
import json
logs_client = boto3.client("logs", region_name="us-east-1")
output = result["outputConfig"]["cloudWatchConfig"]
response = logs_client.get_log_events(
logGroupName=output["logGroupName"],
logStreamName=output["logStreamName"],
)
for event in response["events"]:
attrs = json.loads(event["message"]).get("attributes", {})
print(f"Score: {attrs.get('gen_ai.evaluation.score.value')}")
print(f"Label: {attrs.get('gen_ai.evaluation.score.label')}")
print(f"Explanation: {attrs.get('gen_ai.evaluation.explanation', '')[:200]}")
print()
各セッション・各ターンごとに、スコアの数値(score.value)、カテゴリカルなラベル(score.label、例: Very Helpful / Not Helpful)、そしてスコアの根拠(explanation)が取得できます。
実際に取得した結果の一部を紹介します。
Faithfulness エバリュエータの explanation 例
Score: 1.0
Label: Completely Yes
Explanation: The assistant's response provides information about ticket TKT-2001
based on the tool output. Let me verify each piece of information:
1. Status: Tool shows 'open', Assistant says 'オープン(対応中)' - Matches ✓
2. Category: Tool shows 'network', Assistant says 'ネットワーク' - Matches ✓
3. Summary: Tool shows 'VPN connection drops during video calls',
Assistant says 'ビデオ通話中のVPN接続切断' - Matches ✓
4. Priority: Tool shows 'high', Assistant says '高' - Matches ✓
5. Created date: Tool shows '2026-05-20', Assistant says '2026年5月20日' - Matches ✓
6. Assignee: Tool shows 'network-team', Assistant says 'ネットワークチーム' - Matches ✓
All information in the assistant's response accurately reflects the data from
the tool output.
Helpfulness エバリュエータの explanation 例
Score: 1.0
Label: Above And Beyond
Explanation: The user had two clear goals: (1) determine if there's a system outage
preventing email sending, and (2) create a support ticket. The assistant successfully
accomplished both goals. The response clearly communicates that the email system is
operational (no outage), and confirms ticket TKT-3001 was created with appropriate
details (high priority, email category).
Beyond fulfilling the explicit requests, the assistant goes further by:
- Providing clear, well-structured information with visual formatting
- Explaining that while the system is operational, individual environment issues may exist
- Offering three concrete troubleshooting steps the user can try immediately
explanation には LLM がなぜそのスコアをつけたのかの理由が詳しく書かれています。Faithfulness ではツール出力の各フィールドと応答の対応を1つずつ検証し、Helpfulness ではユーザーのゴール達成度や追加の付加価値まで評価してくれています。詳細を見たい場合はこのように取り出すと分析できますね。
変更前後の比較
バッチ評価の結果は get_batch_evaluation で取得できるので、変更前後のスコアを比較することもできます。例えば以下のように2つのバッチ評価 ID を指定して差分を出すだけです。
比較スクリプト例
import boto3
eval_client = boto3.client("bedrock-agentcore", region_name="us-east-1")
baseline = eval_client.get_batch_evaluation(batchEvaluationId=baseline_id)
treatment = eval_client.get_batch_evaluation(batchEvaluationId=treatment_id)
baseline_summaries = {
s["evaluatorId"]: s["statistics"]["averageScore"]
for s in baseline["evaluationResults"]["evaluatorSummaries"]
}
treatment_summaries = {
s["evaluatorId"]: s["statistics"]["averageScore"]
for s in treatment["evaluationResults"]["evaluatorSummaries"]
}
print(f"{'Evaluator':<35} {'Baseline':>10} {'Treatment':>10} {'Delta':>10}")
print("=" * 67)
for eid in baseline_summaries:
b = baseline_summaries[eid]
t = treatment_summaries.get(eid, 0)
delta = t - b
print(f"{eid:<35} {b:>10.4f} {t:>10.4f} {delta:>+10.4f}")
プロンプト調整やモデル変更のたびにバッチ評価を実行しておけば、スコアの推移を追えるようになります。
コンソールからも比較できます。バッチ評価の詳細画面右上にある Compare ボタンを押すと、過去のバッチ評価を選択して並べて比較できます。
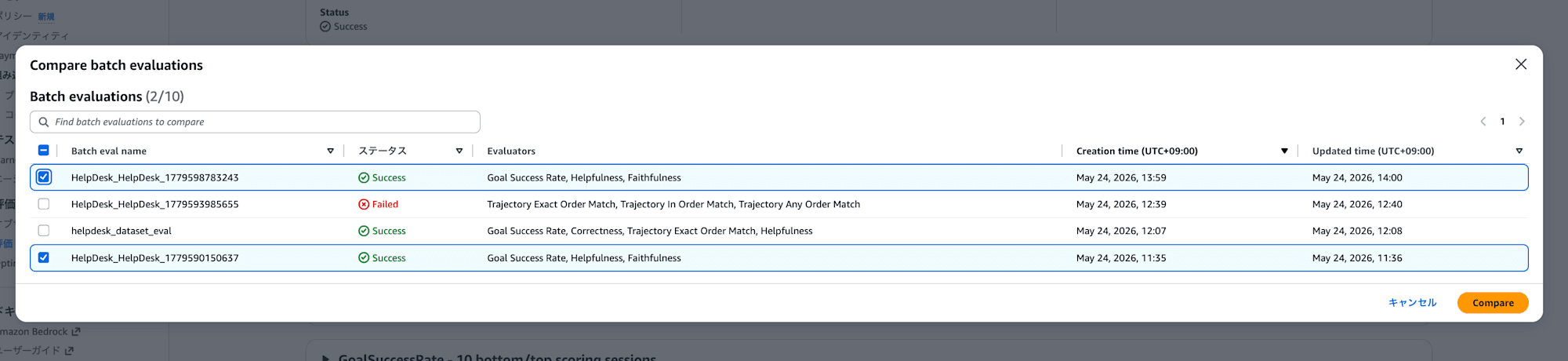
比較したいバッチ評価を2つ選択すると、エバリュエータごとの平均スコアを棒グラフで並べて表示してくれます。スコア分布の内訳も確認できるので、改善したのかデグレしていないかが視覚的にわかりますね。
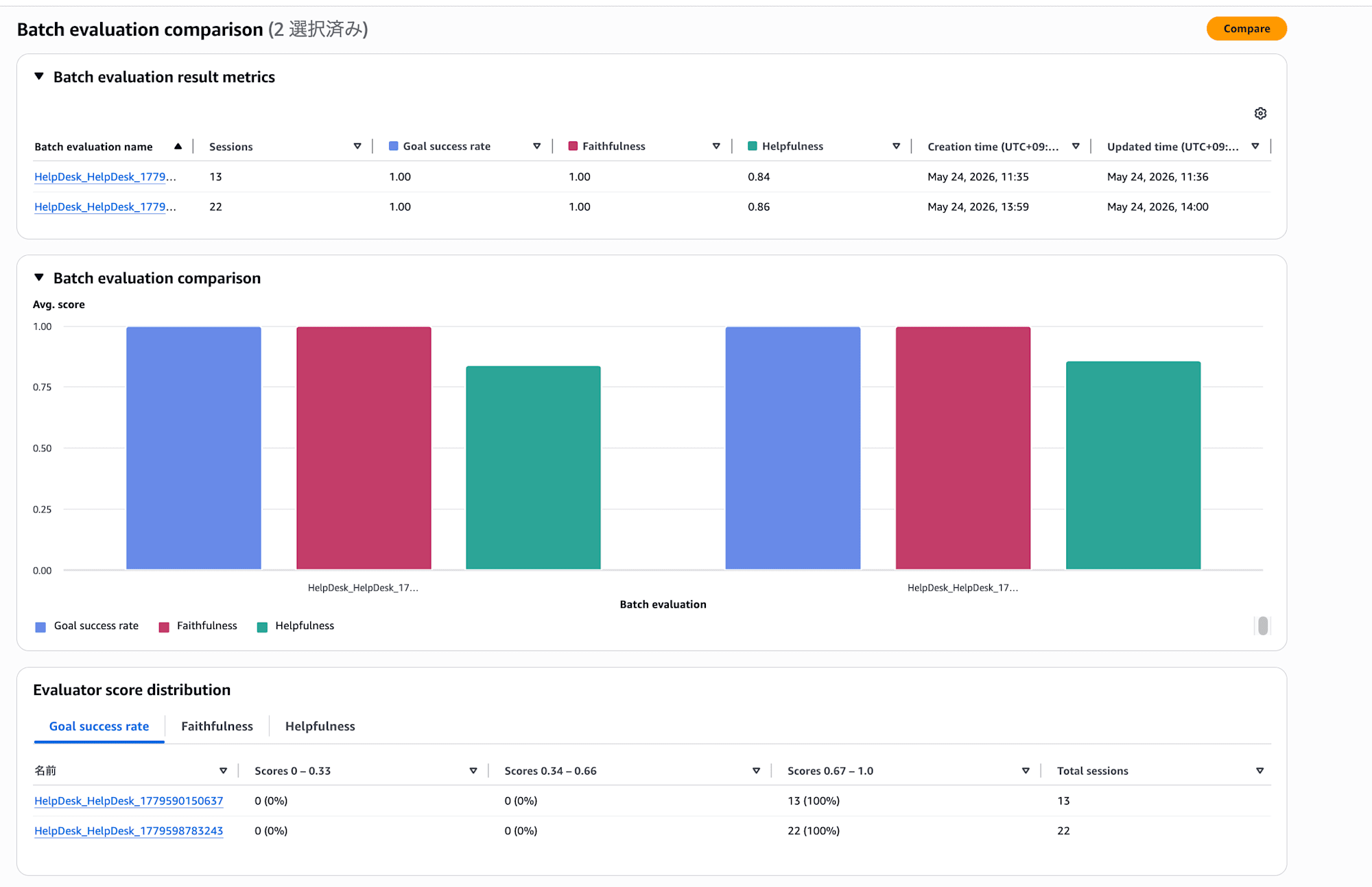
コードを書かなくてもサクッと比較できるのは便利です!
データセット駆動のバッチ評価
ここまでは既存セッションに対するバッチ評価でしたが、事前に定義したシナリオでエージェントを呼び出してから評価まで一括実行する方法もあります。AgentCore SDK の BatchEvaluationRunner を使います。
実は AgentCore CLI のインタラクティブモードでもグランドトゥルース付きのバッチ評価が実行できます。agentcore run batch-evaluation を引数なしで実行すると、エバリュエータの選択からグランドトゥルースファイルの指定まで対話的に進められます。
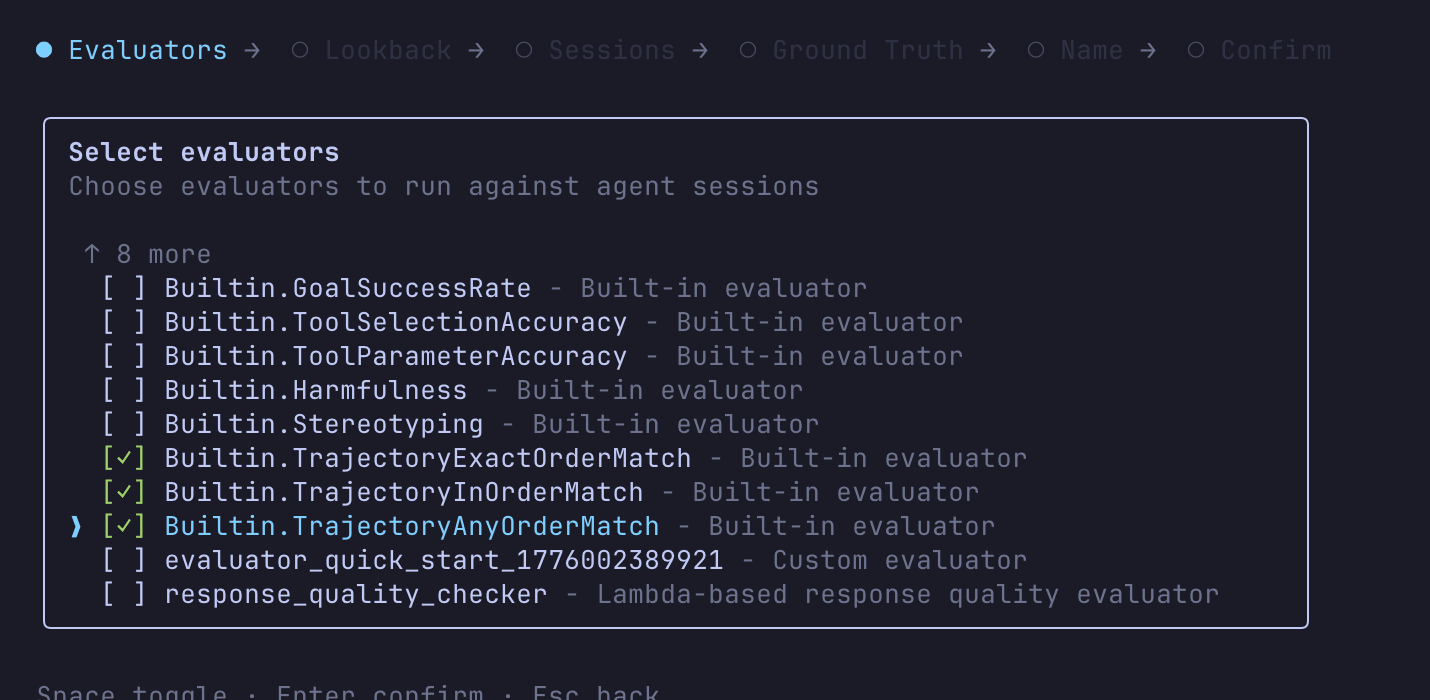
Trajectory 系エバリュエータもここから選択可能です。
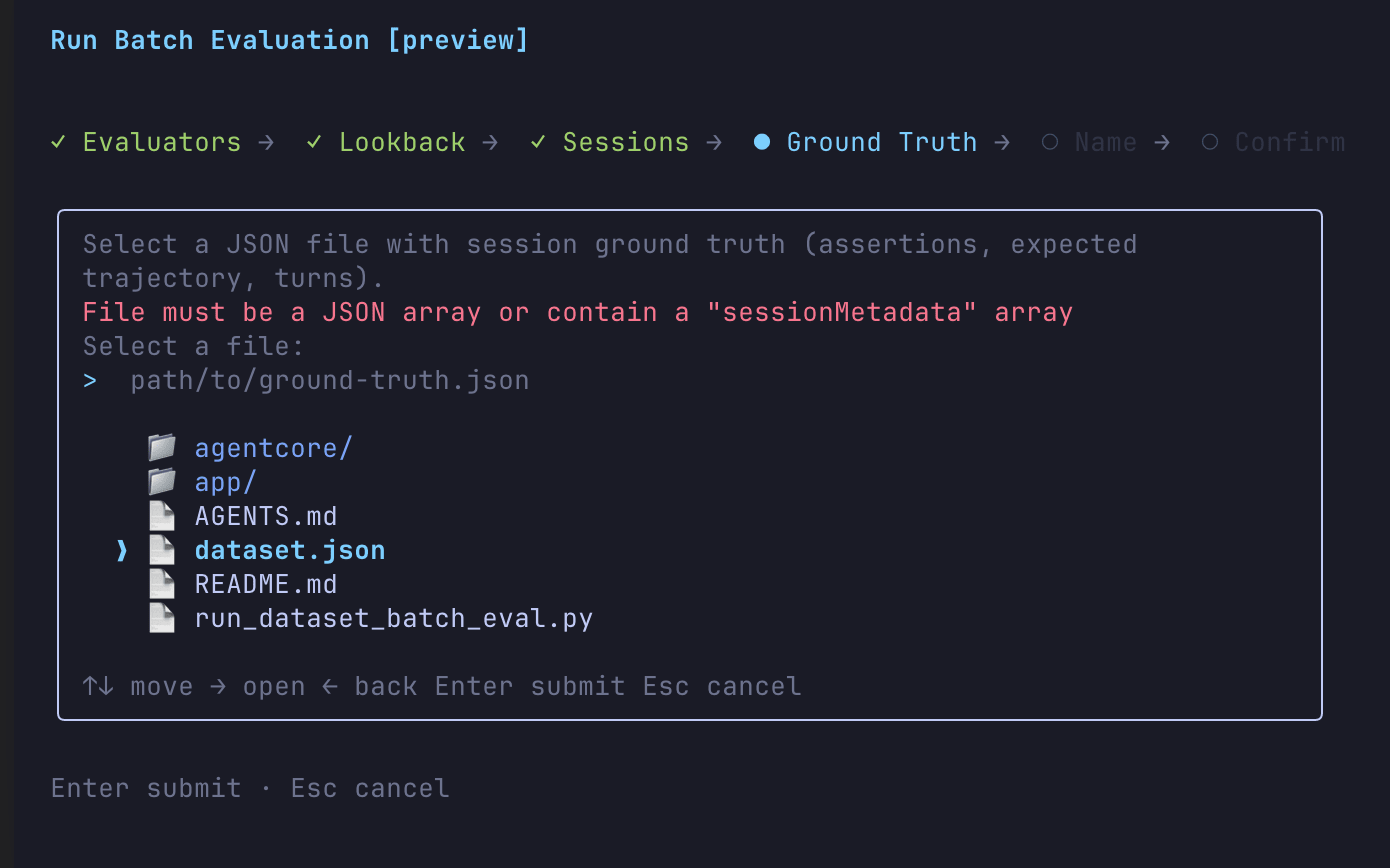
Ground Truth のステップではグランドトゥルースの JSON ファイルを指定できます。ただしファイル形式は sessionMetadata 配列を含む JSON で、セッション ID ごとにグランドトゥルースを紐づける形式です。
テストシナリオを定義して、エージェントを呼び出して、その結果をグランドトゥルース付きで評価するという流れをやりたいですが、 CLI だけでこれをやろうとすると、以下の手順を手動でつなげる必要があります。
- 各シナリオで
agentcore invokeを実行してセッションを生成 - CloudWatch にテレメトリが取り込まれるまで 2〜3分待つ
- 生成されたセッション ID を収集する
- セッション ID とグランドトゥルースを紐づけた sessionMetadata 形式の JSON を作成する
agentcore run batch-evaluation --ground-truthで評価を実行
特に4が辛いところで、invoke のたびに発行されるセッション ID を控えて「このセッション ID はパスワードリセットのシナリオだから期待するツール呼び出しは reset_password で・・・」と手動で JSON を組み立てるのは少し大変です。BatchEvaluationRunner を使えばこの一連の流れを1つのメソッド呼び出しで自動化してくれるので、データセット駆動の評価にはこちらを使っていきます。
環境構築
BatchEvaluationRunner は bedrock-agentcore パッケージの batch-eval extras に含まれています。agentcore create で作成したプロジェクトの仮想環境に追加インストールします。
cd app/HelpDesk
uv add --dev "bedrock-agentcore[batch-eval]"
データセットの作成
まず評価シナリオを JSON で定義します。
{
"scenarios": [
{
"scenario_id": "ticket-lookup",
"turns": [
{
"input": "チケット TKT-2001 の状況を教えてください",
"expected_response": "TKT-2001 はオープン状態です。ビデオ通話中にVPN接続が切断される問題が報告されています。"
}
],
"expected_trajectory": ["lookup_ticket"],
"assertions": ["エージェントが lookup_ticket ツールを使ってチケットの状態を確認した"]
},
{
"scenario_id": "password-reset",
"turns": [
{
"input": "Active Directory のパスワードをリセットしてほしいです。社員IDは EMP-1234 です。",
"expected_response": "パスワードをリセットしました。仮パスワードを登録メールに送信しました。"
}
],
"expected_trajectory": ["reset_password"],
"assertions": [
"エージェントが正しいシステム(Active Directory)のパスワードをリセットした",
"エージェントがユーザーに仮パスワードについて案内した"
]
},
{
"scenario_id": "vpn-escalation",
"turns": [
{
"input": "VPN が会議中に何度も切れます。チケット TKT-2001 をエスカレーションしてください。",
"expected_response": "TKT-2001 をシニアエンジニアチームにエスカレーションしました。"
}
],
"expected_trajectory": ["lookup_ticket", "check_system_status", "escalate_to_engineer"],
"assertions": [
"エージェントがエスカレーション前にチケットとシステムの状態を確認した",
"エージェントが適切な理由を添えてチケットをエスカレーションした"
]
}
]
}
各シナリオには turns(入力と期待される応答)、expected_trajectory(期待されるツール呼び出し順序)、assertions(自然言語での期待される振る舞いの記述)を定義しています。
3つ目の vpn-escalation シナリオでは、チケット確認 → システム状態確認 → エスカレーションという3ステップのツール呼び出し順序を期待しています。エージェントがいきなりエスカレーションするのではなく、まず状況を確認してから判断するという流れを評価できるのがポイントです。
グランドトゥルースと各エバリュエータの対応関係は下記の通りです。
| フィールド | 対応するエバリュエータ |
|---|---|
| turns[].expected_response | Builtin.Correctness |
| assertions | Builtin.GoalSuccessRate |
| expected_trajectory | Builtin.TrajectoryExactOrderMatch / InOrderMatch / AnyOrderMatch |
これらのフィールドは全てオプションで、未指定のエバリュエータはグランドトゥルースなしモードで動作します。
BatchEvaluationRunner の実行
import json
import boto3
from bedrock_agentcore.evaluation import (
BatchEvaluationRunner,
BatchEvaluationRunConfig,
BatchEvaluatorConfig,
CloudWatchDataSourceConfig,
FileDatasetProvider,
AgentInvokerInput,
AgentInvokerOutput,
)
REGION = "us-east-1"
AGENT_ARN = "arn:aws:bedrock-agentcore:us-east-1:123456789012:runtime/HelpDesk-xyz789"
SERVICE_NAME = "HelpDesk-xyz789.DEFAULT"
LOG_GROUP = "/aws/bedrock-agentcore/runtimes/HelpDesk-xyz789-DEFAULT"
agentcore_client = boto3.client("bedrock-agentcore", region_name=REGION)
def agent_invoker(invoker_input: AgentInvokerInput) -> AgentInvokerOutput:
payload = invoker_input.payload
if isinstance(payload, str):
payload = json.dumps({"prompt": payload}).encode()
elif isinstance(payload, dict):
payload = json.dumps(payload).encode()
response = agentcore_client.invoke_agent_runtime(
agentRuntimeArn=AGENT_ARN,
runtimeSessionId=invoker_input.session_id,
payload=payload,
)
response_body = response["response"].read()
return AgentInvokerOutput(agent_output=json.loads(response_body))
dataset = FileDatasetProvider("dataset.json").get_dataset()
config = BatchEvaluationRunConfig(
batch_evaluation_name="helpdesk_dataset_eval",
evaluator_config=BatchEvaluatorConfig(
evaluator_ids=[
"Builtin.GoalSuccessRate",
"Builtin.Correctness",
"Builtin.TrajectoryExactOrderMatch",
"Builtin.Helpfulness",
],
),
data_source=CloudWatchDataSourceConfig(
service_names=[SERVICE_NAME],
log_group_names=[LOG_GROUP],
ingestion_delay_seconds=180,
),
polling_timeout_seconds=1800,
polling_interval_seconds=30,
)
runner = BatchEvaluationRunner(region=REGION)
result = runner.run_dataset_evaluation(
agent_invoker=agent_invoker,
dataset=dataset,
config=config,
)
print(f"Status: {result.status}")
print(f"Batch evaluation ID: {result.batch_evaluation_id}")
if result.evaluation_results:
er = result.evaluation_results
print(f"Sessions completed: {er.number_of_sessions_completed}")
print(f"Sessions failed: {er.number_of_sessions_failed}")
print(f"Total sessions: {er.total_number_of_sessions}")
for summary in er.evaluator_summaries or []:
avg = summary.statistics.average_score if summary.statistics else None
print(f" {summary.evaluator_id}: avg={avg}")
BatchEvaluationRunner は4つのフェーズを自動的に処理してくれます。
- データセットの各シナリオでエージェントを並行呼び出し
- CloudWatch へのテレメトリ取り込みを待機(デフォルト180秒)
StartBatchEvaluationAPI でバッチジョブを投入GetBatchEvaluationでポーリングして完了を待つ
エージェントの呼び出しからバッチ評価のポーリングまで、全て1つのメソッド呼び出しで完結するのは良いですね!
app/HelpDesk ディレクトリに run_dataset_batch_eval.py と dataset.json を配置し、uv run で実行します。
uv run run_dataset_batch_eval.py
実行すると、3シナリオの invoke → CloudWatch 取り込み待ち → バッチ評価投入 → ポーリングが自動的に行われ、以下のような結果が得られました。
Status: COMPLETED
Batch evaluation ID: helpdesk_dataset_eval-f879e432bd
Sessions completed: 3
Sessions failed: 0
Total sessions: 3
Builtin.GoalSuccessRate: avg=0.67
Builtin.TrajectoryExactOrderMatch: avg=0.33
Builtin.Helpfulness: avg=0.89
Builtin.Correctness: avg=1.0
Correctness は全シナリオで満点ですが、TrajectoryExactOrderMatch は 0.33 とかなり低い結果になりました。セッション別の内訳を見てみます。
| シナリオ | GoalSuccessRate | TrajectoryExactOrderMatch | Correctness | Helpfulness |
|---|---|---|---|---|
| ticket-lookup | 1.0 (Yes) | 1.0 (Yes) | 1.0 (Correct) | 0.83 (Very Helpful) |
| password-reset | 1.0 (Yes) | 0.0 (No) | 1.0 (Correct) | 0.83 (Very Helpful) |
| vpn-escalation | 0.0 (No) | 0.0 (No) | 1.0 (Correct) | 1.0 (Above And Beyond) |
ticket-lookup は期待通り lookup_ticket だけを呼んで合格。一方、password-reset では reset_password のみを期待していましたが、エージェントが最初に "Active Directory" というシステム名でツールを呼んでエラーになり、"active_directory" にリトライしたため、余分なツール呼び出しが発生して ExactOrderMatch が不合格になっています。
vpn-escalation は lookup_ticket → check_system_status → escalate_to_engineer の3ステップによるツール呼び出しを期待していましたが、エージェントが独自の判断で escalate_to_engineer だけを呼んだため、TrajectoryExactOrderMatch と GoalSuccessRate の両方が不合格に。ただし Helpfulness は Above And Beyond(1.0)で、ユーザーにとっては役立つ応答となっていたのでそういった評価になりました。詳細を見てみるのは面白いですね。
コンソールからも各エバリュエータの詳細を確認できます。
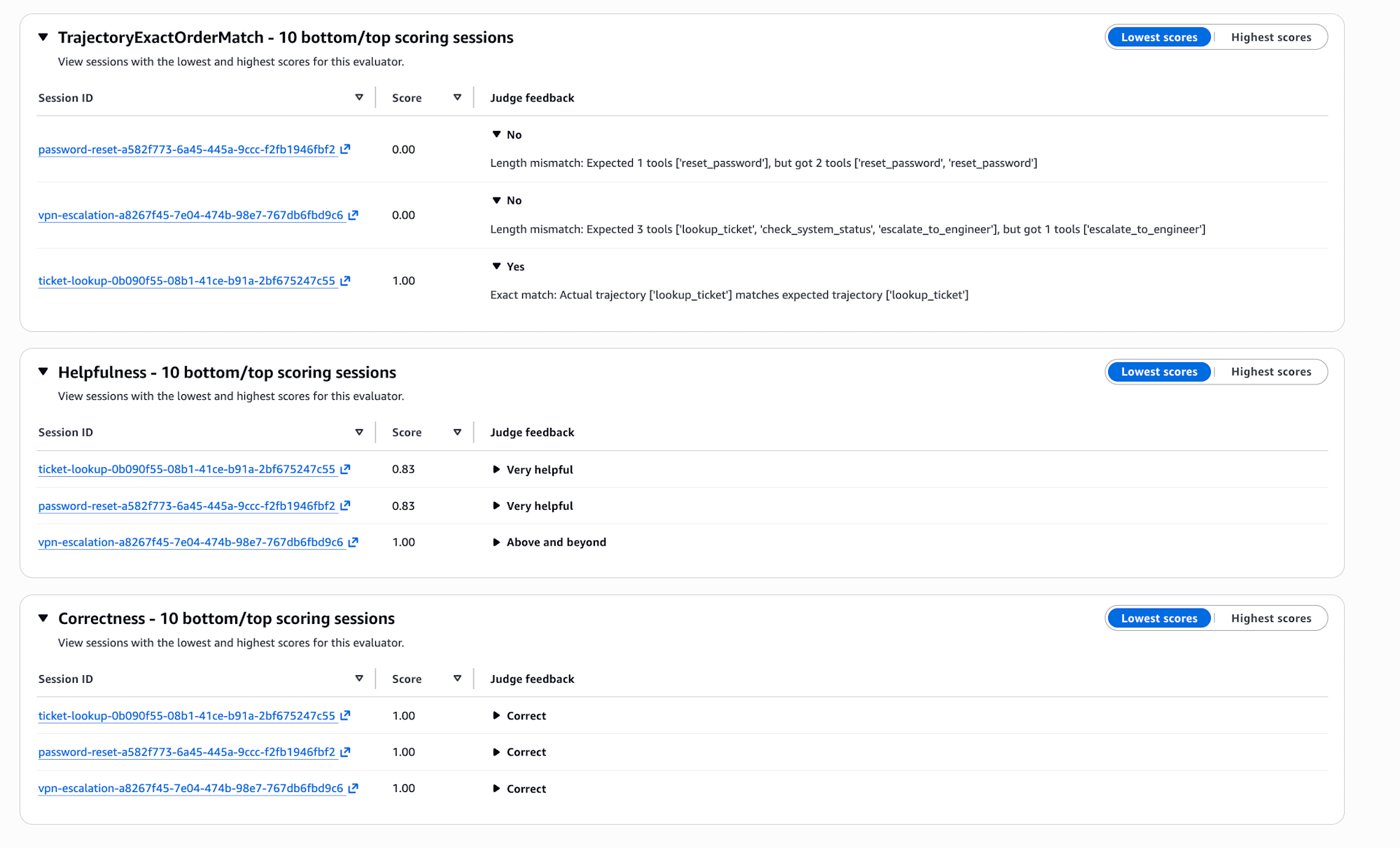
TrajectoryExactOrderMatch の Judge feedback には不合格の理由が具体的に表示されています。password-reset は「Expected 1 tools ['reset_password'], but got 2 tools ['reset_password', 'reset_password']」、vpn-escalation は「Expected 3 tools [...], but got 1 tools ['escalate_to_engineer']」とあり、期待と実際のツール呼び出しの差分が一目でわかります。
このように、応答の品質は高くてもツール呼び出しの順序が期待と異なるケースがあるため、ExactOrderMatch が厳しすぎる場合は InOrderMatch や AnyOrderMatch を使うのが良いかもしれませんね。結果だけ良ければ良い場合など。
おわりに
一括で評価できるのはよいですね。また、評価した結果がコンソールから確認できるのもありがたいですし、前回との比較などもやりやすそうです。Previewですが、バッチ的にリグレッションしていないかなど確認するのに良さそうです。私も積極的に使っていきたいと思いました。
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございました!










