
【登壇レポート】 AI Builders Day Online (プレイベント)で「Amazon Bedrock AgentCore 本番導入への道 アーキテクチャ設計の実践」というタイトルで登壇しました!
はじめに
こんにちは、スーパーマーケット(ラ・ムー)が大好きなコンサルティング部の神野です。
2025年11月27日(木)に開催されたAI Builders Day Online (プレイベント)で登壇させていただきました!
何気にこういった社外の大きなコミュニティイベントでお話しするのは、初めてだったので緊張しましたね・・・! 他の登壇者の方も実践的なテーマばかりで実際にAIエージェント作成している方の話を聞けるのは面白くて、とても良いイベントでした!運営の皆様、改めてありがとうございました!
登壇資料
本登壇はAgentCoreの実践を見据えた話をしたく、少しでもAgentCoreを触ったことがある方を前提としています・・・!
申し訳ないですがAgentCoreの触り部分などを知りたい方は下記ブログを参考にしてください!
資料の解説
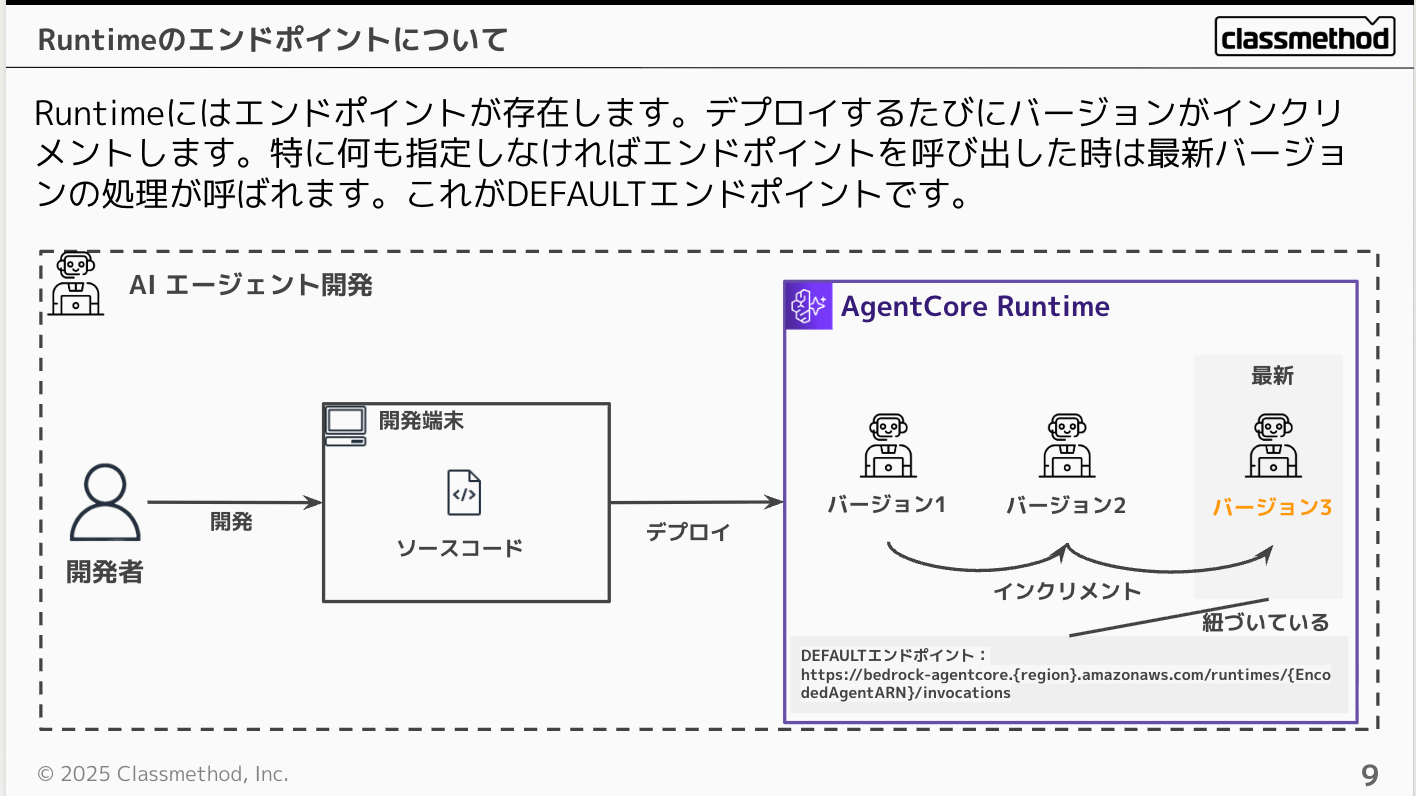
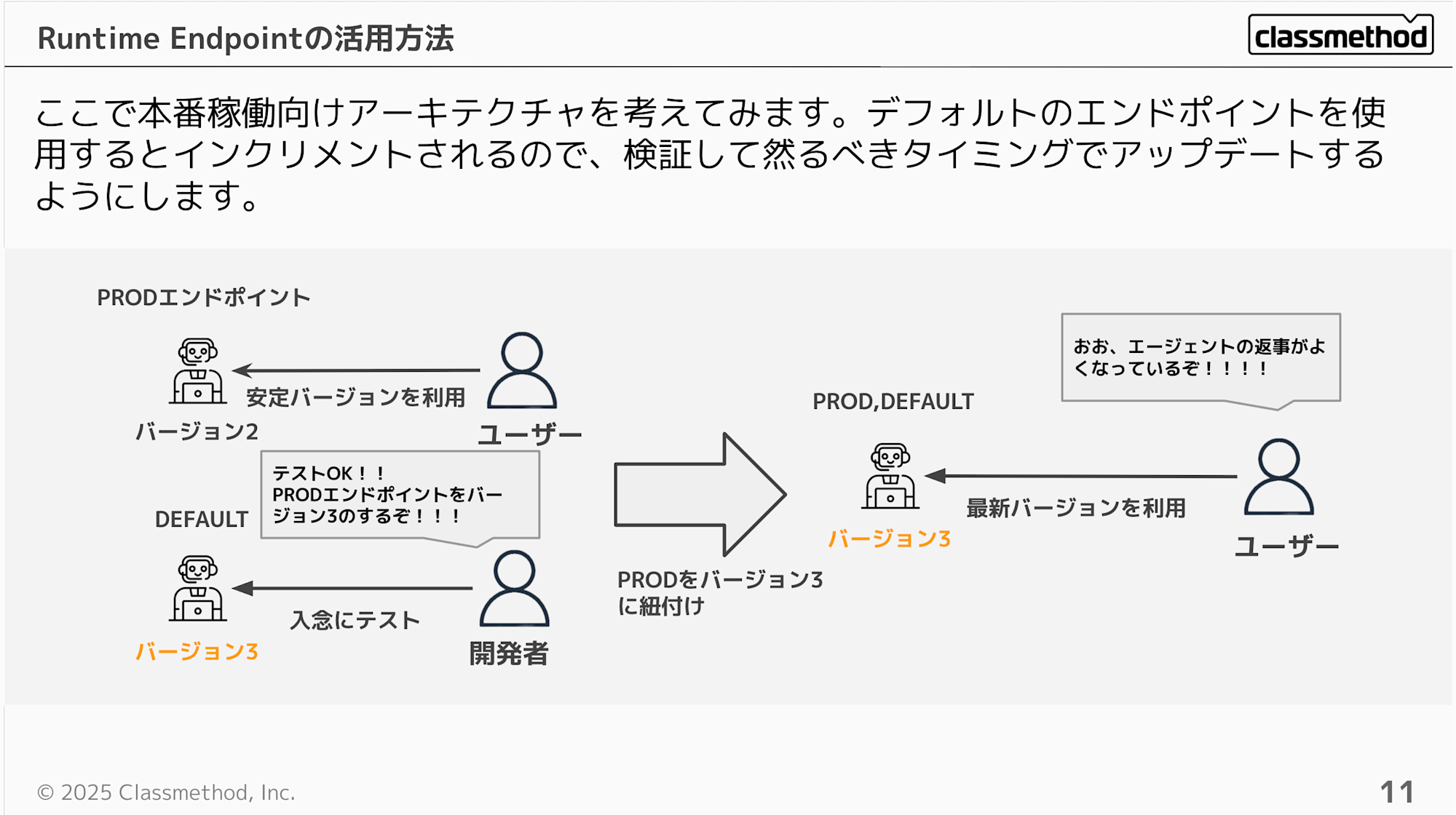
Runtime Endpointの活用方法
Runtimeにはエンドポイントが存在し、デプロイするたびにバージョンを保持していてインクリメントされて、常にDEFAULTエンドポイントと最新バージョンは紐付きます。なのでエンドポイントを呼び出すと最新のバージョンが実行される形となります。
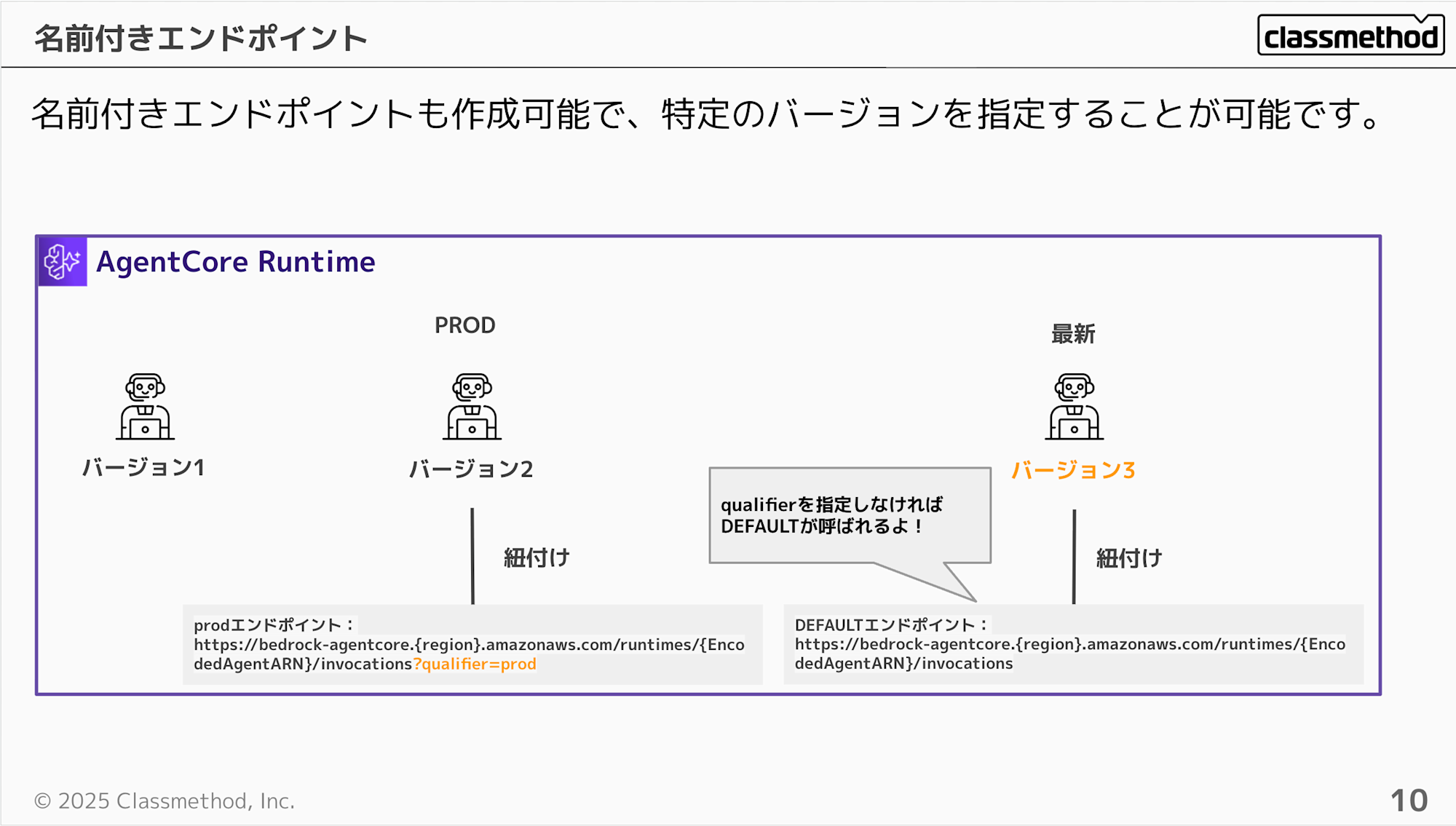
DEFAULT以外でも名前付きのエンドポイントを指定することが可能です。
例えば、本番用のエンドポイントをprodみたいな形で名前を付けることが可能で、名前付きのエンドポイントは下記のようにqualifierパラメータをエンドポイントの名前を指定すれば呼び出せます。
逆にqualifierを何も指定しなければDEFAULTのエンドポイントが実行されます。
https://bedrock-agentcore.{region}.amazonaws.com/runtimes/{EncodedAgentARN}/invocations?qualifier=prod
本番向けにRuntimeでホストするアプリケーションを考えた際に、最新バージョンを入念にテストして、問題なければ本番エンドポイントに紐づくバージョンをアップデートする形になると思います。
CloudFront / Lambda Proxyパターン
Runtimeをデプロイして使用できるエンドポイントのURLは下記のような形式で使用できます。
https://bedrock-agentcore.ap-northeast-1.amazonaws.com/runtimes/arn%3Aaws%3Abedrock-agentcore%3Aap-northeast-1%3A123456789012%3Aagent-runtime%2Fabcd1234/invocations
うーーん・・・、アカウントIDが含まれたり、ARNをエンコードする必要があるのは少し抵抗がありますよね。また、カスタムドメインなどを使いたいケースもあると思います。
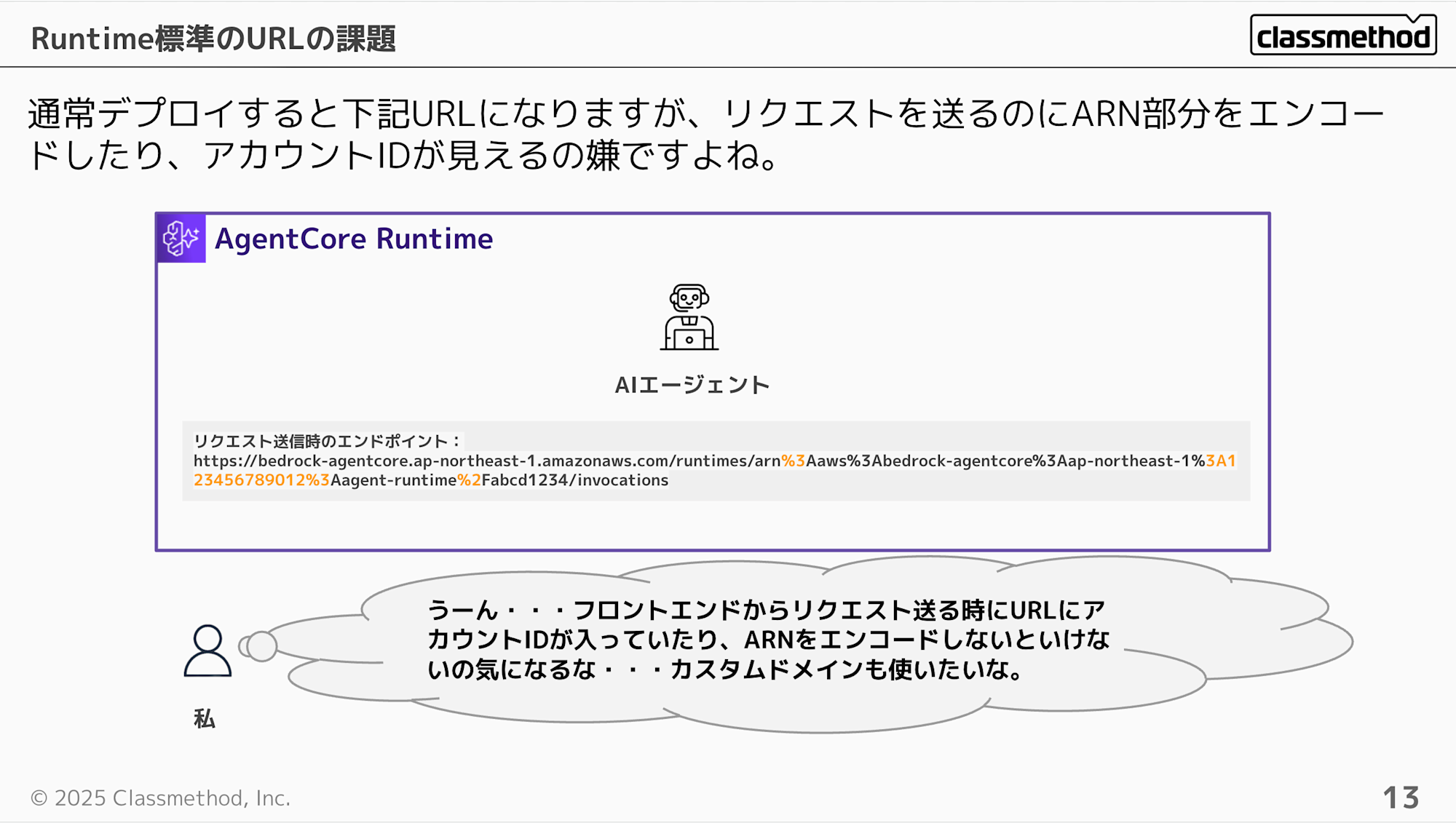
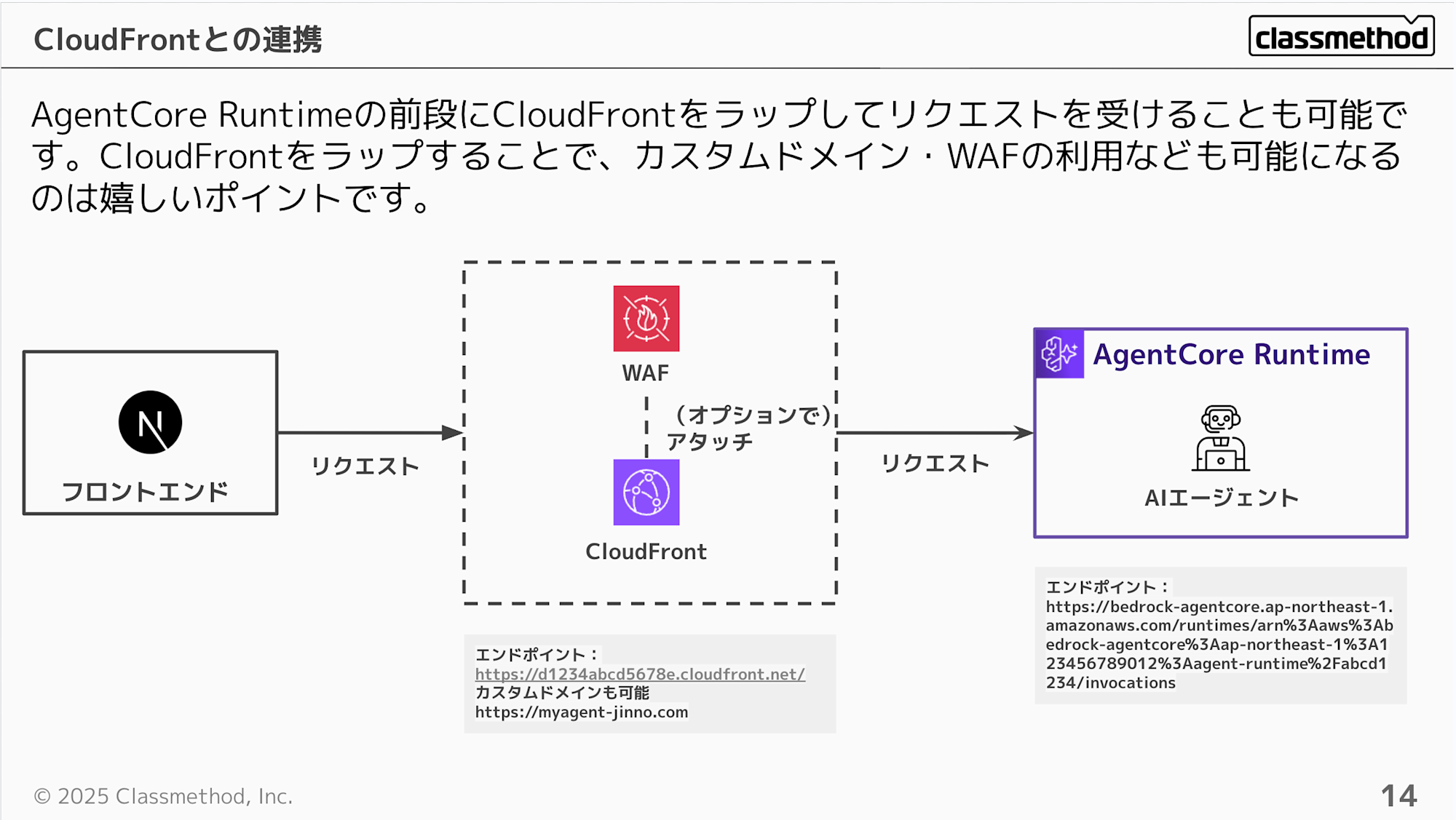
ここで上記問題に対応するためにCloudFrontをAgentCore Runtimeの前段で使用するケースを考えてみます。 カスタムドメインや場合によってはWAFも使用できるのは嬉しいポイントですよね。 これでARNをエンコードしたり、アカウントIDの露出を気にする必要はなくなります。
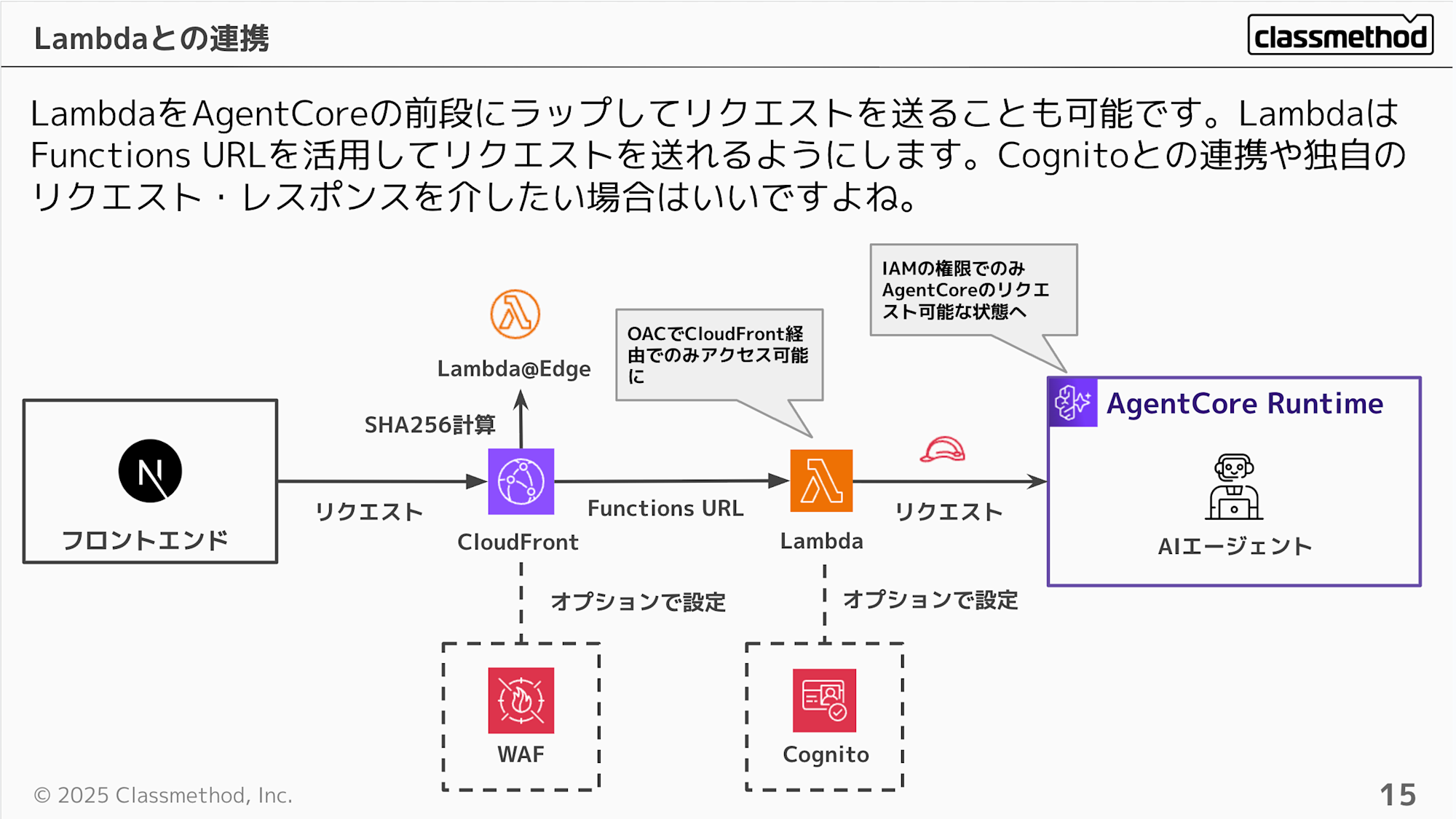
次はLambda + CloudFrontを前段に配置するケースを考えてみます。
こちらだと先ほどの構成に加えてLambdaで処理をインターセプトしたいユースケースや、Cognitoと連携して独自トークンの検証をしたいなども可能になるかと思います。
次にアクセス制御ですが、AgentCoreをIAM認証にすることで、基本的にLambda経由でしかアクセスできない構成が作れます。CloudFront単体だとトークンさえあれば元のURLでも実行可能でしたが、この構成なら元のURLはIAM権限がない限り叩けません。
とはいえ、現状AgentCoreにはリソースベースのポリシーが存在しないので、別途アクセス権限を持つIAMがあれば直接呼び出せてしまいます。「Lambda経由限定」を厳密に担保したい場合は、IAM権限の付与範囲を慎重に設計する必要がありますね。
リソースベースのポリシーに対応しました!「Lambda経由限定」を厳密に担保したい場合はリソースベースポリシーを活用しましょう!
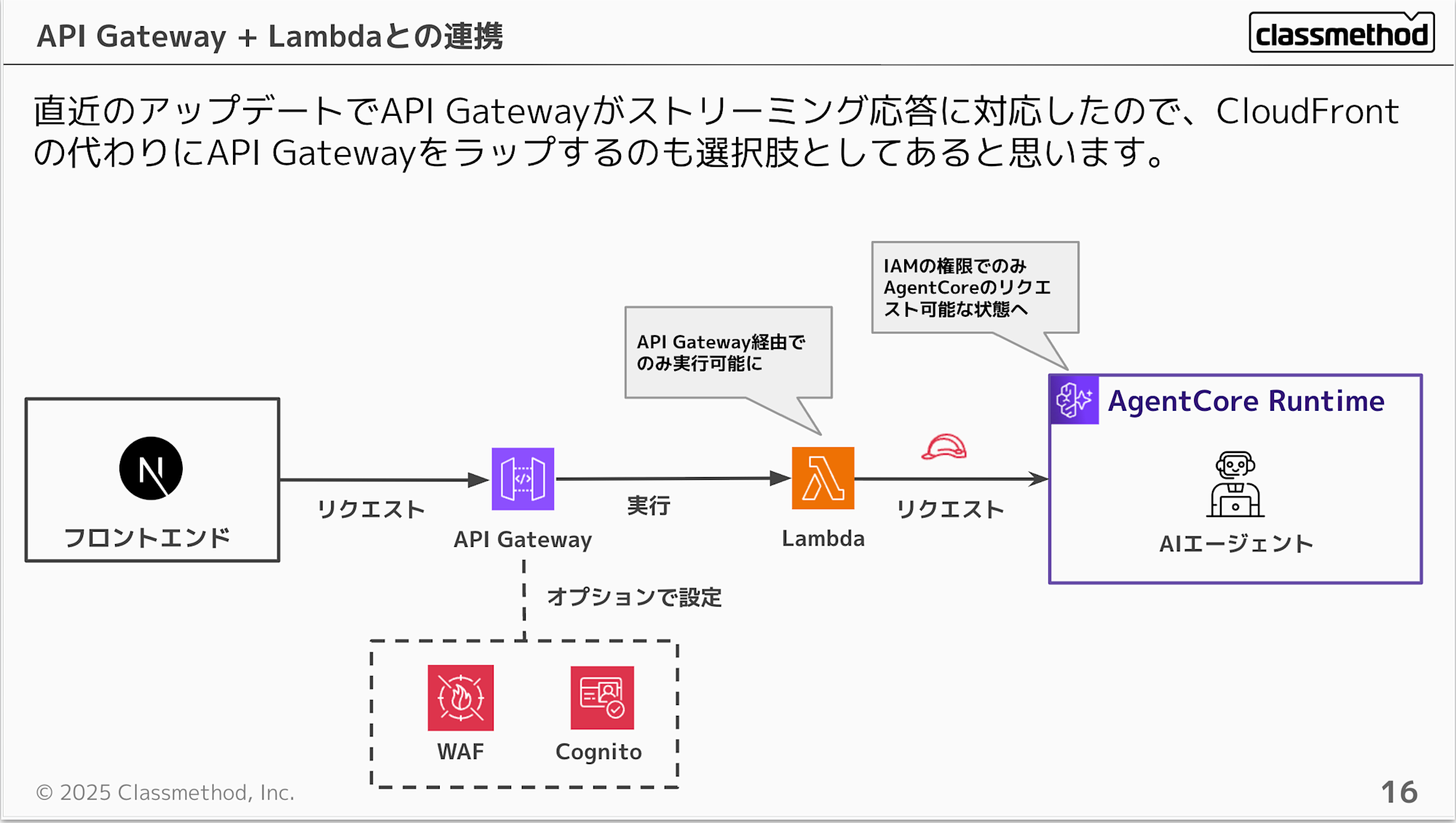
直近のAPI Gatewayのアップデートでストリーム応答も可能になりました。このアップデートによって、API Gateway + Lambdaを前段に配置することも実現できます。 基本は先ほどと変わりはないですが、API Gatewayを前段に配置することで、API Keyの利用や認証の設定が容易になるのは嬉しいですよね。
いくつか案をご紹介してきましたが、特に何かが正解と言ったわけではなく、要件に応じて最適なアーキテクチャを考えていく必要があるかと思います。その考える際に、上記構成を思い出して少しでも参考になったら嬉しく思います。
フロントエンドとの連携
AgentCoreはAIエージェントをホストする上で便利なマネージドサービスなので、フロントエンドと連携する際もできるだけ便利なマネージドサービスを組み合わせていきたいですよね。ざっと下記のような選択肢があると思います。
-
Lambda
-
Amplify
-
App Runner
-
ECS
AmplifyやApp Runnerはサクッとアプリを作るときに便利でよく使っているのですが、AIアプリケーションとは相性が悪い制約があるので注意したいです。悲しい。
-
Amplify
- Next.js API routesのストリーミングが動作しない(バッファリングされる) AI SDKなどをNext.js バックエンドで使用しようとすると使えなくて絶望します
-
AppRunner
-
120秒のリクエストタイムアウト
- エージェントとのやり取りが長時間に及ぶとタイムアウトになる可能性
-
WebSocketサポートなし(roadmapで最多要望)
- StreamlitはWebSocketを使用するためApp Runnerでホストするのは難しい
-

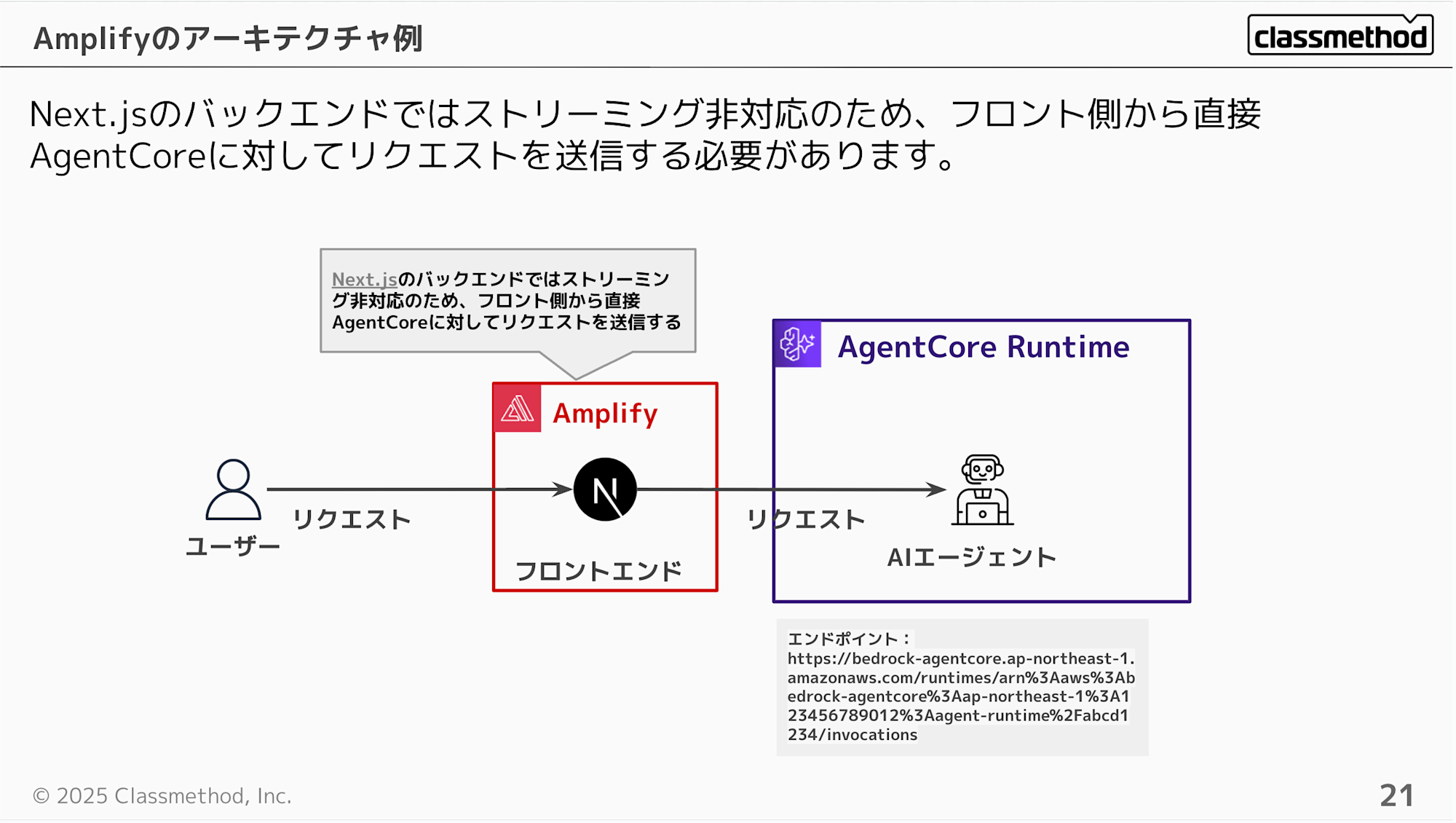
Amplifyでホストする場合は、クライアントから直接リクエストを送る形になります。
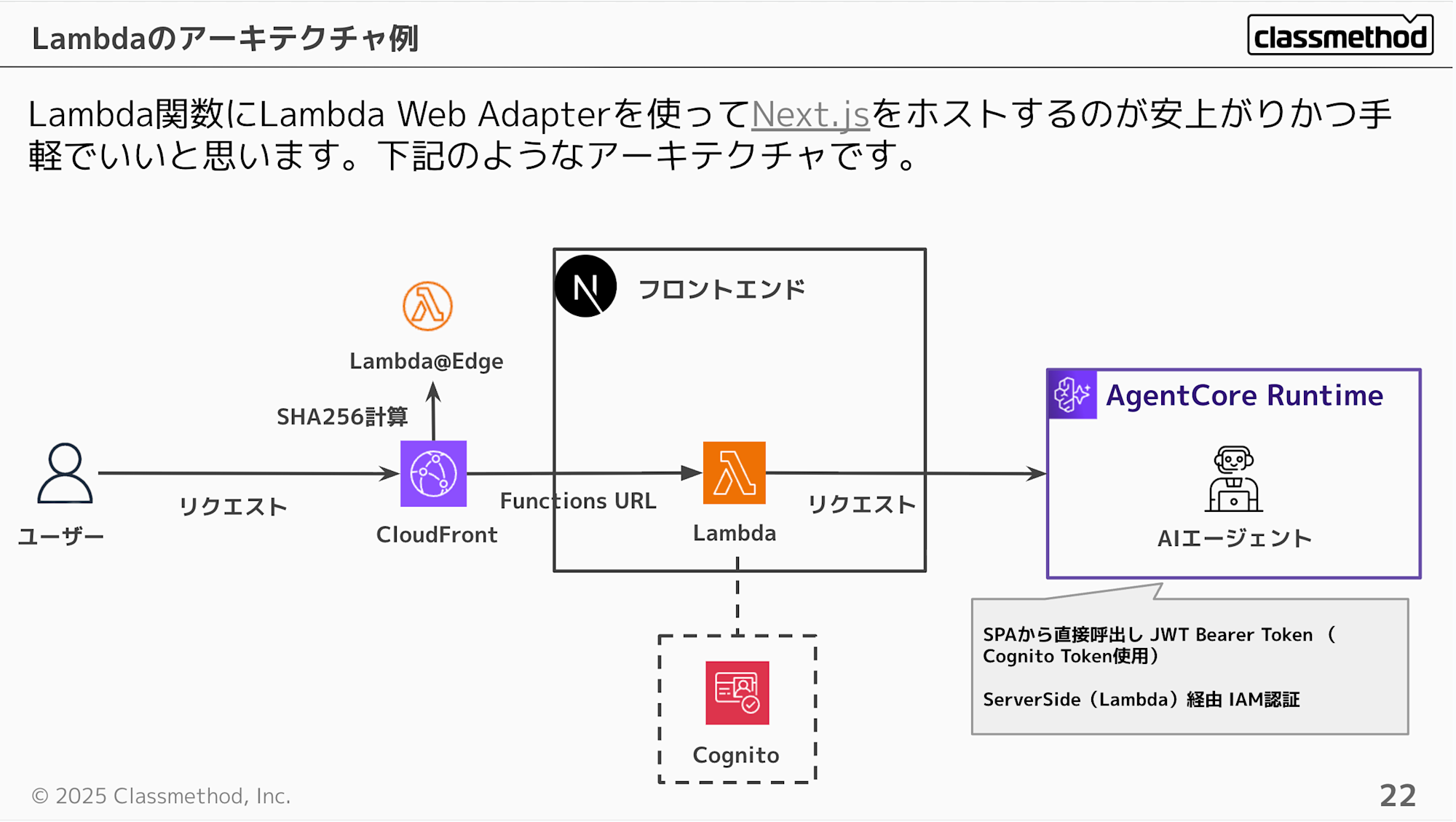
Lambda関数にLambda Web Adapterを使ってNext.jsをホストするのが、コスト的に安くかつ手軽で良いかと思います
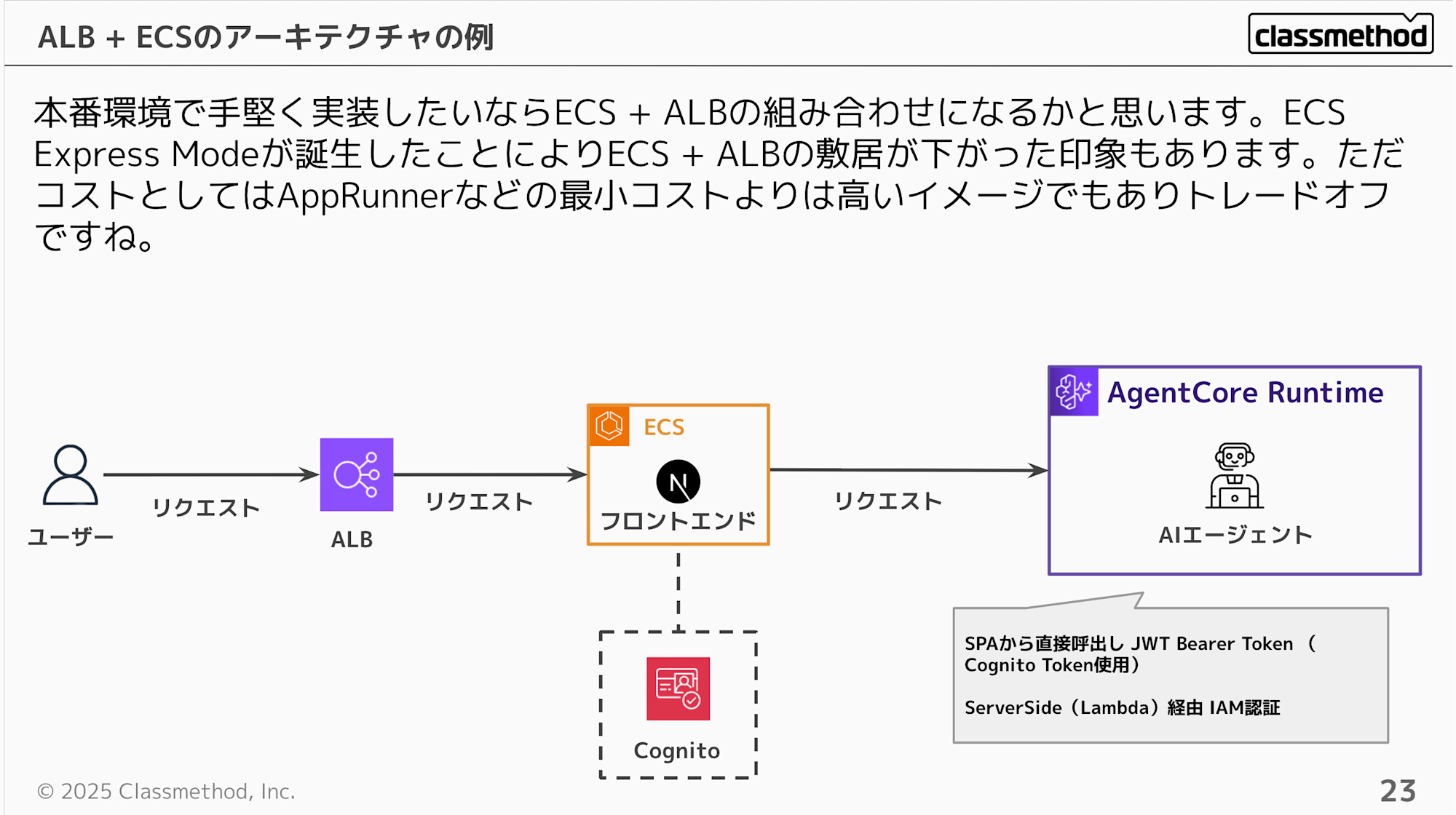
本番環境で手堅く実装したいならECS + ALB の組み合わせを選ぶことになると思います。直近のアップデートでECS Express Modeが誕生したことにより導入の敷居は下がった印象はあります。ただ、ECSでの最小コストはApp Runnerなどのマネージドサービスの最小コストよりは高くなる点に注意ですね。
GenU(Generative AI Use Cases JP)を使って手軽にAgentCoreを組みこむことも可能です。フロントエンドを作成するモチベーションがない場合はいい選択肢になるかと思います。ただ現時点では実験的な機能になるので注意が必要です。
GenUとの連携は試してみたブログもあるので、こちらも必要に応じてご参照ください。
Tips:Runtime lifecycle settings
Runtime には idleRuntimeSessionTimeout(アイドル時のタイムアウト)と maxLifetime(最大稼働時間)パラメータが存在し、セッションの自動終了タイミングを制御できます。
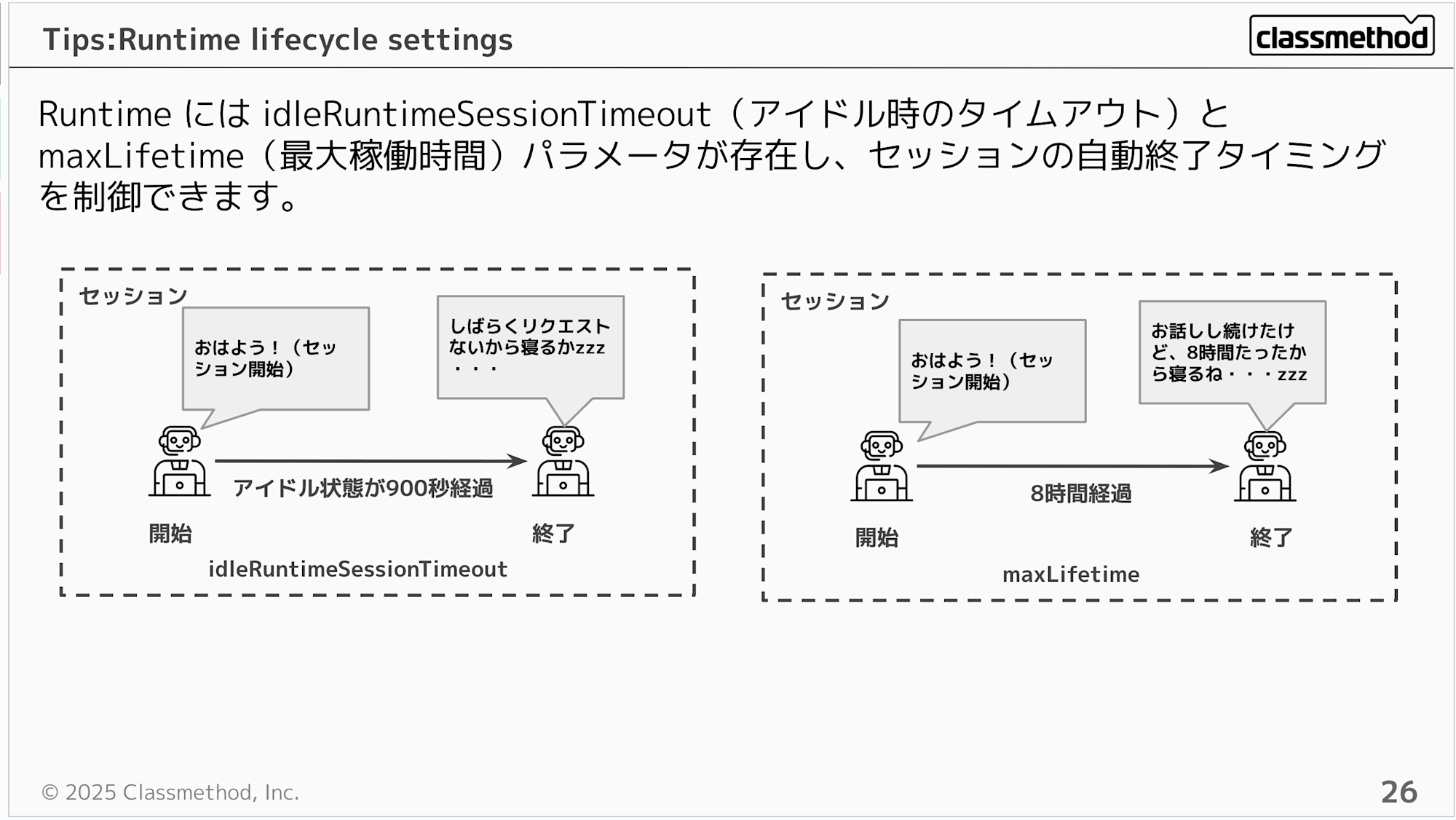
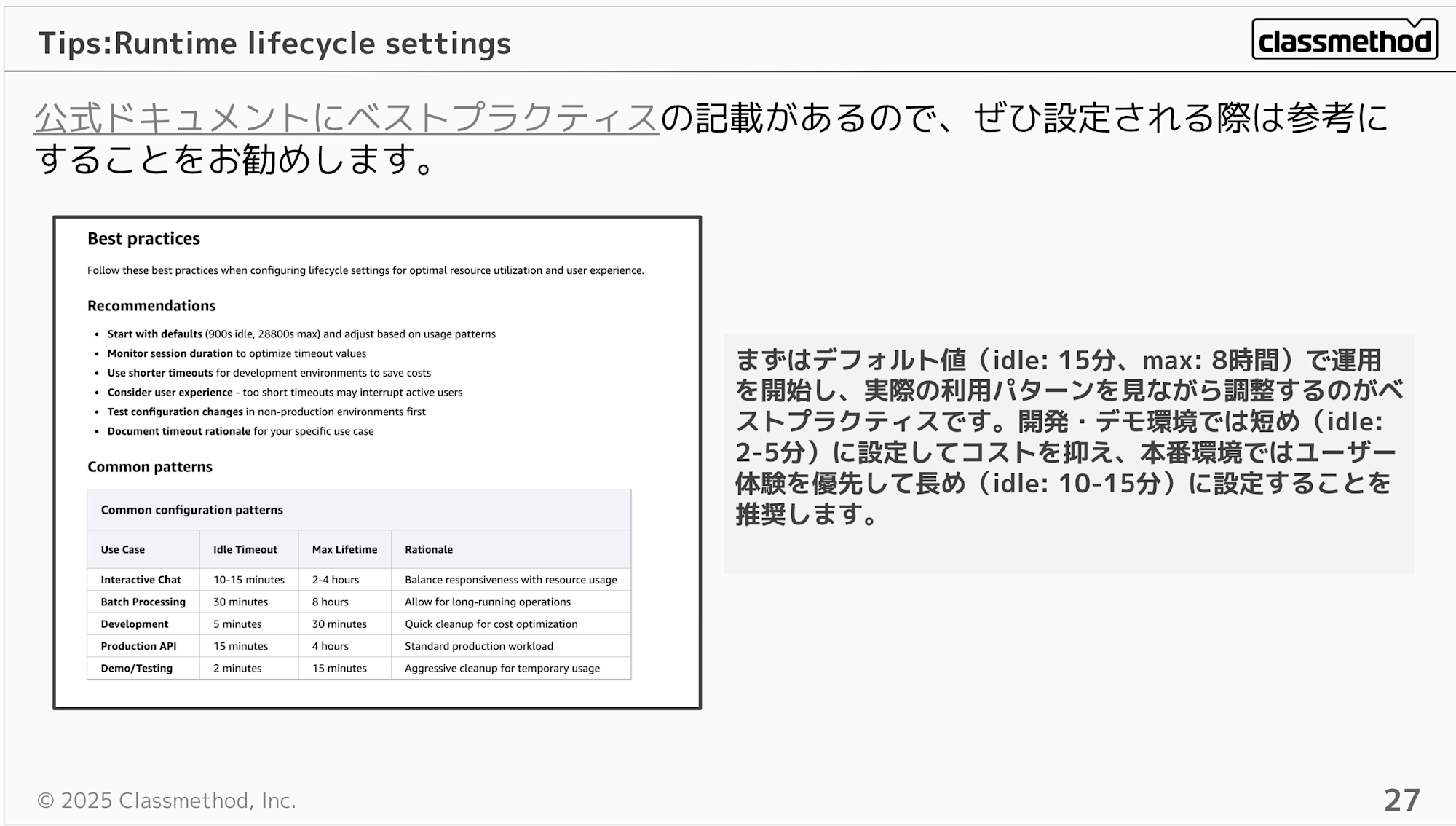
え、そんな値何を設定するの・・・?と思いますが公式ドキュメントに設定値のベストプラクティスが記載されているので、ベストプラクティスと同じく、まずはデフォルト値からユースケースに応じて調整して形になると思います。
まずはデフォルト値(idle: 15分、max: 8時間)で運用を開始し、実際の利用パターンを見ながら調整するのがベストプラクティスです。開発・デモ環境では短め(idle: 2-5分)に設定してコストを抑え、本番環境ではユーザー体験を優先して長め(idle: 10-15分)に設定することを推奨します。
Gatewayの利用イメージ / Semantic Searchを活用する
本登壇で一番熱く語りたかったポイントです。
Gatewayは既存のAPI、Lambda関数、各種サービスをMCP(Model Context Protocol)互換のツールに変換して、AIエージェントから簡単に呼び出せるようにしてくれるサービスです。また既存のMCP Serverとのハブにもなって中央集約的に管理もできます。
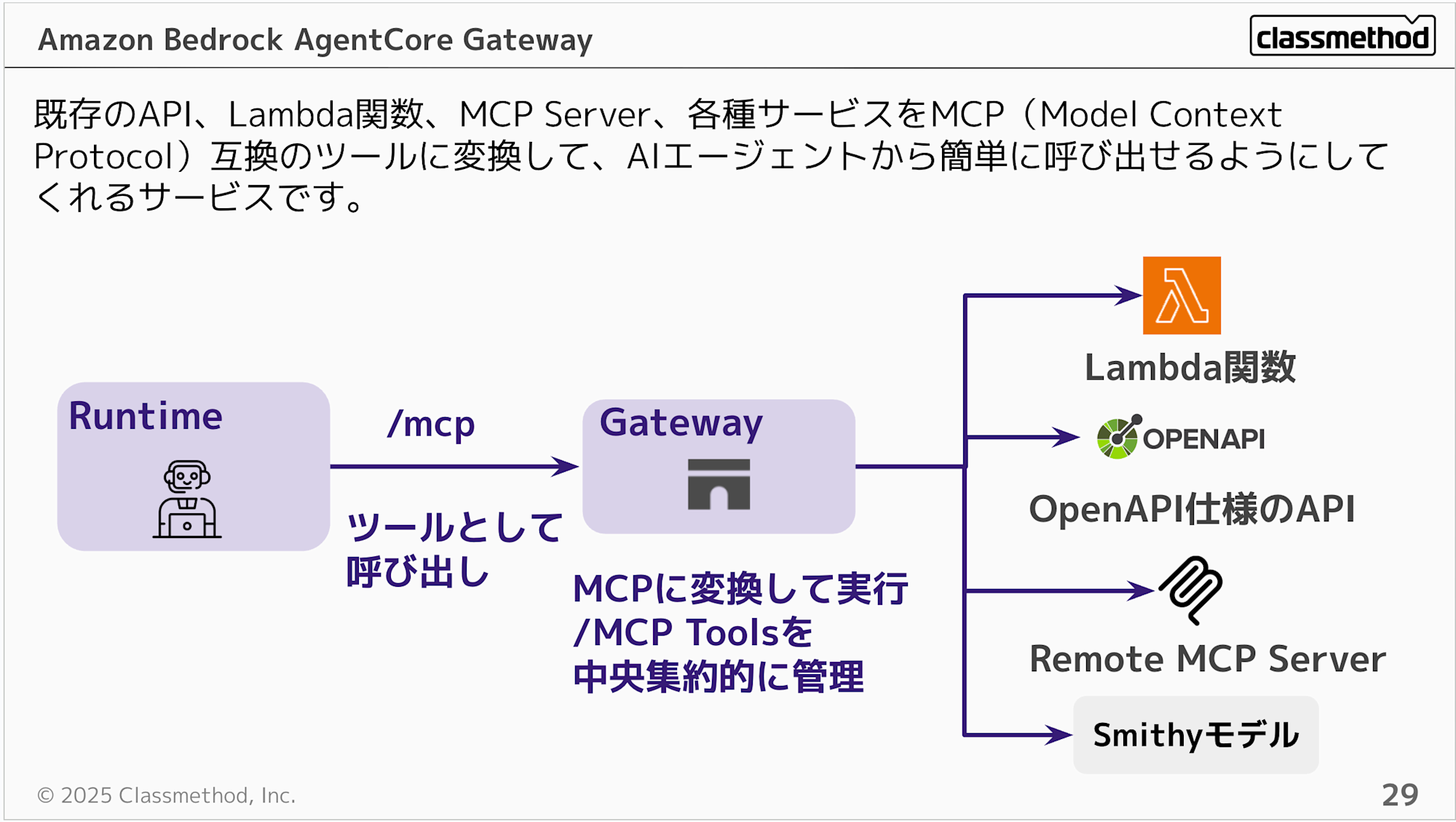
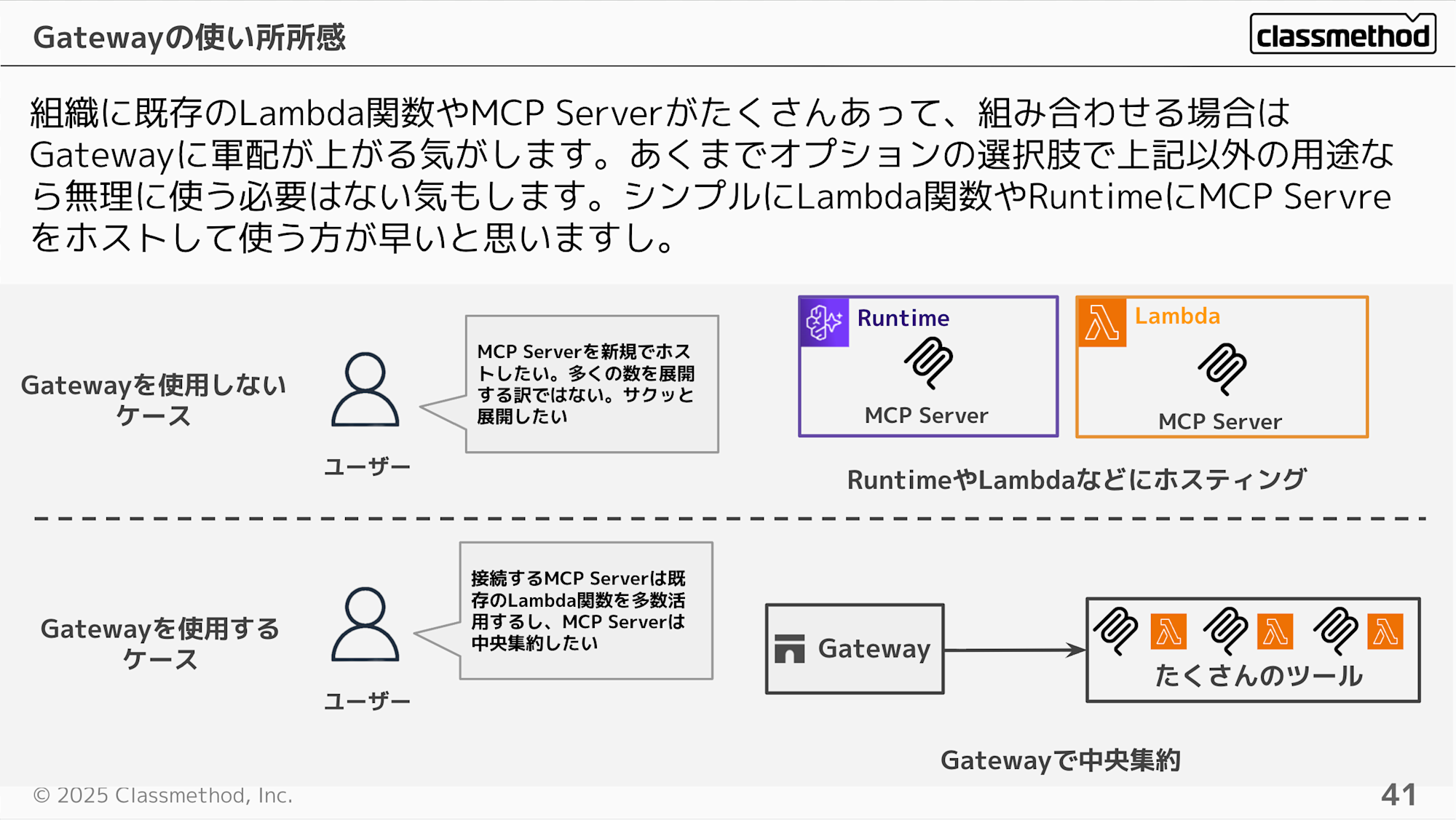
よく誤解されがちなのですが、GatewayはMCP Server自体をホストするものではないです。あくまで既存のLambda関数をツール化したり他のMCP Serverを中央集約的に管理するのが役目となります。MCP Server自体をホストしたいならRuntimeを使うことになるかと思います。
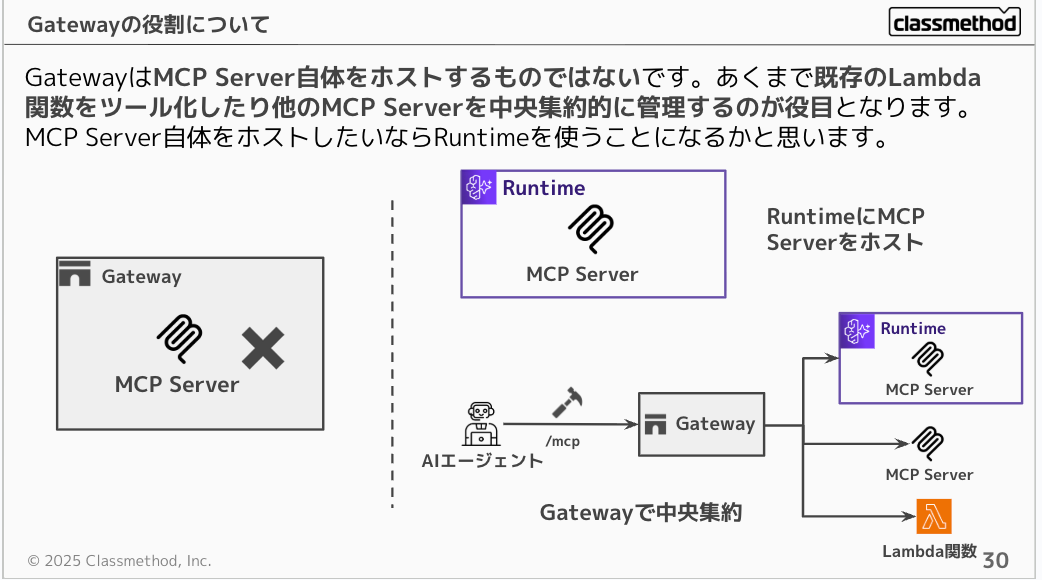
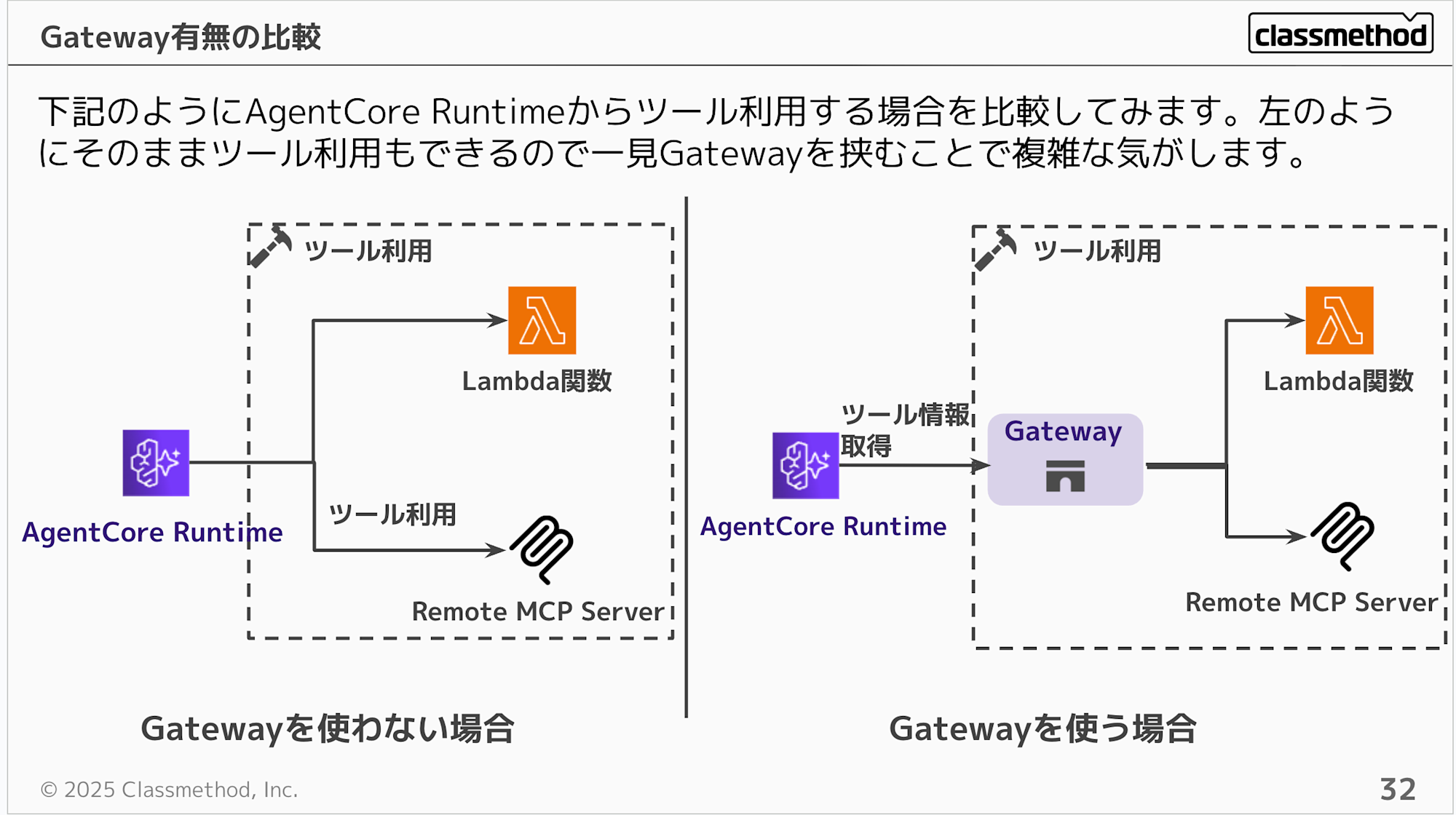
Gatewayはハブとわかりましたがメリットがわかりづらいですよね。Gatewayを使用しなくても、RuntimeからLambdaやMCP Serverを直接呼び出せるのに、Gatewayを挟むと一見複雑になるように見えます。
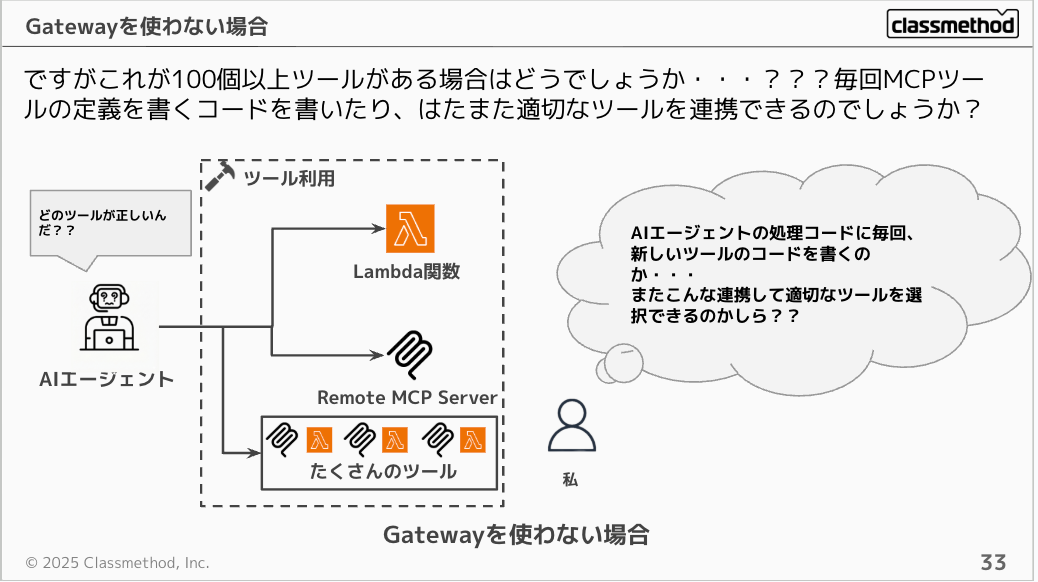
例えば、100個以上のツールがある場合を考えてみます。毎回MCPツールの定義を書くコードを書いたり、100個のツールをAIエージェントが適切に見つけられるのでしょうか。
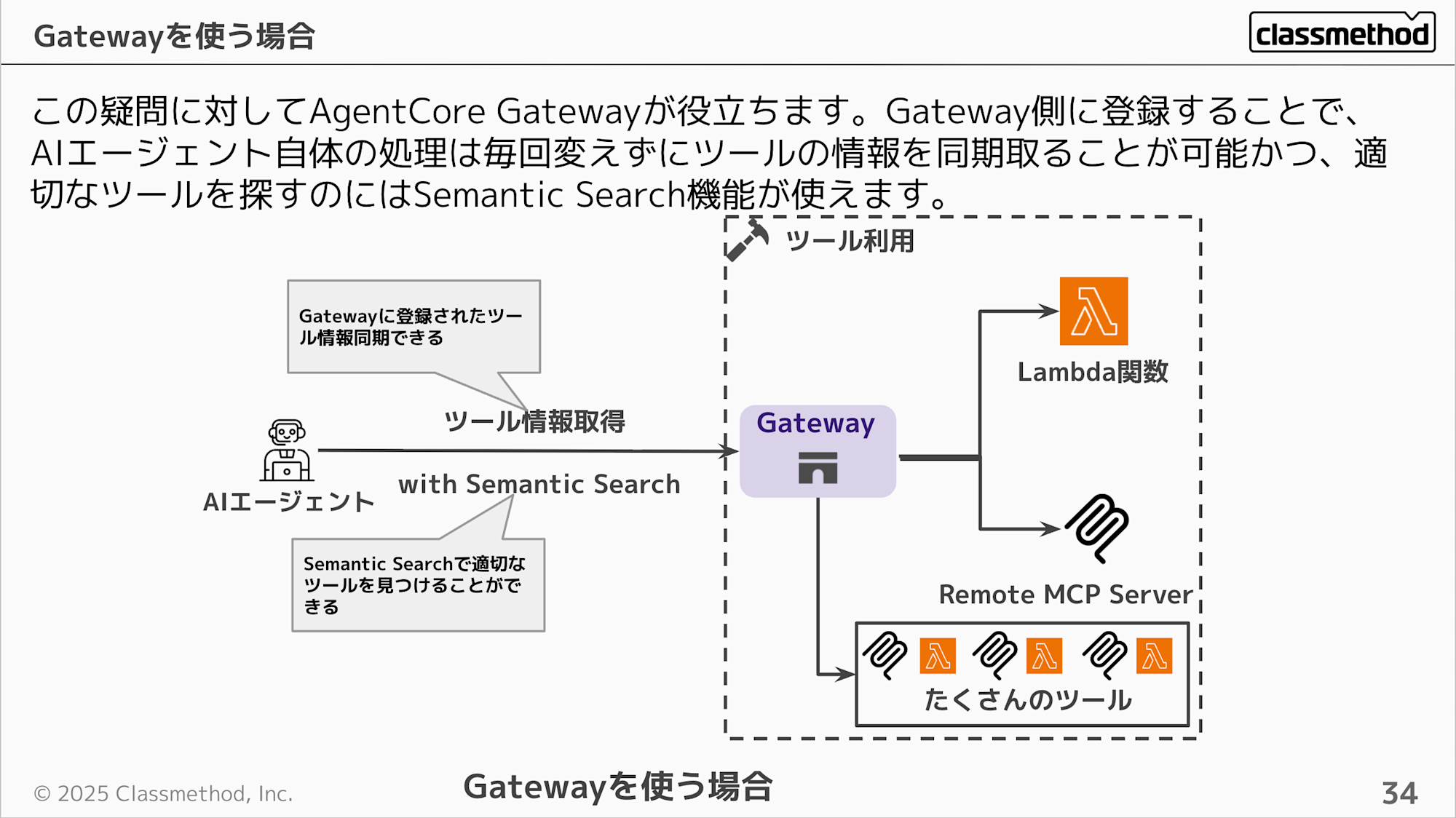
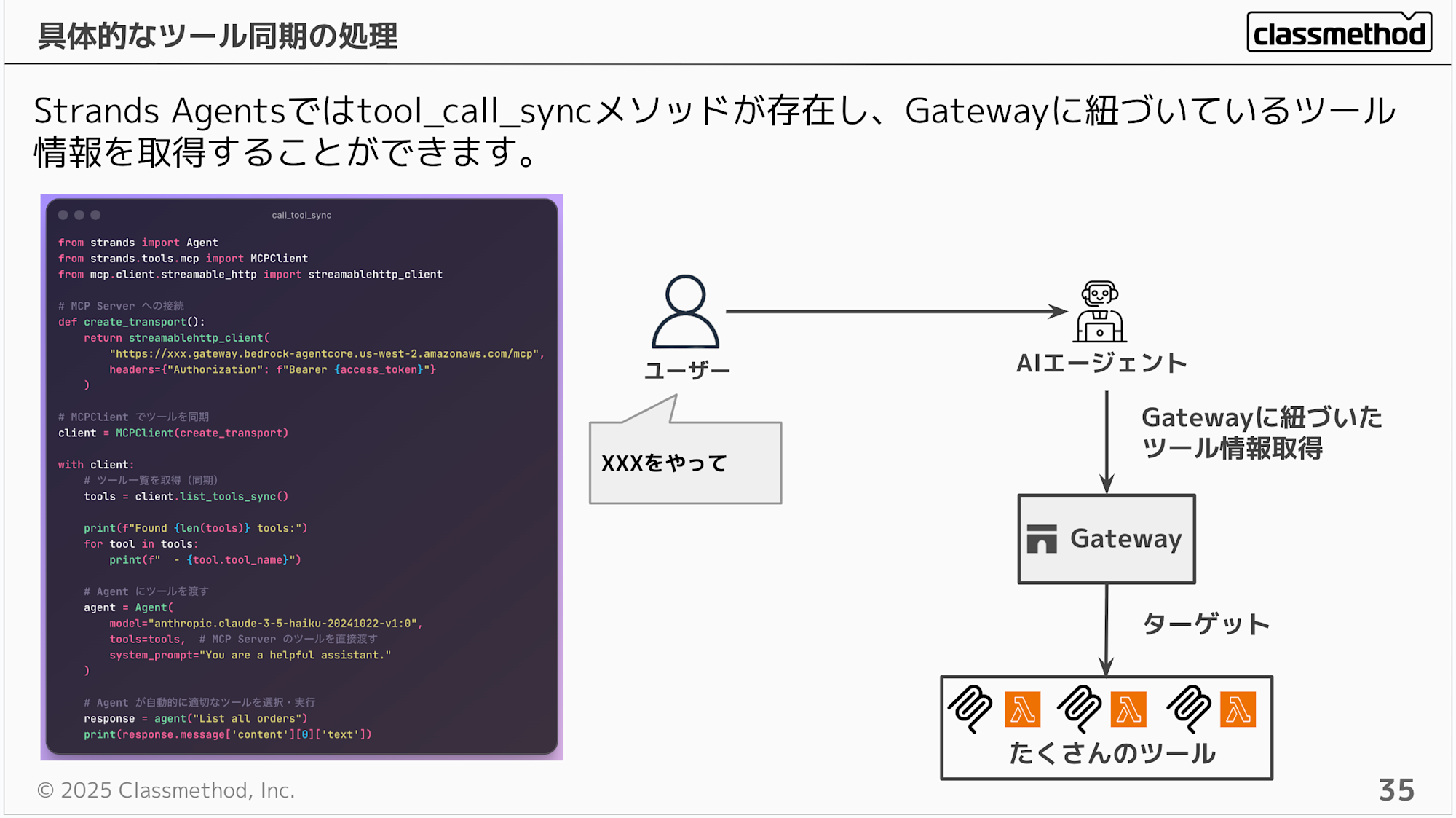
この疑問に対してGatewayが役立ちます。Gateway側にツールを登録し集約することで、AIエージェント自体の処理は追加や変更するごとに変えずに、Gatewayを介してツールの情報を同期することが可能かつ、求められている適切なツールを探すのにはSemantic Search機能が活用できます。
Strands Agentsを使っている場合ならtool_call_syncメソッドが存在し、Gateway紐づいているツール情報を取得することが可能です。
from strands import Agent
from strands.tools.mcp import MCPClient
from mcp.client.streamable_http import streamablehttp_client
# MCP Server への接続
def create_transport():
return streamablehttp_client(
"https://xxx.gateway.bedrock-agentcore.us-west-2.amazonaws.com/mcp",
headers={"Authorization": f"Bearer {access_token}"}
)
# MCPClient でツールを同期
client = MCPClient(create_transport)
with client:
# ツール一覧を取得(同期)
tools = client.list_tools_sync()
print(f"Found {len(tools)} tools:")
for tool in tools:
print(f" - {tool.tool_name}")
# Agent にツールを渡す
agent = Agent(
model="anthropic.claude-3-5-haiku-20241022-v1:0",
tools=tools, # MCP Server のツールを直接渡す
system_prompt="You are a helpful assistant."
)
# Agent が自動的に適切なツールを選択・実行
response = agent("List all orders")
print(response.message['content'][0]['text'])
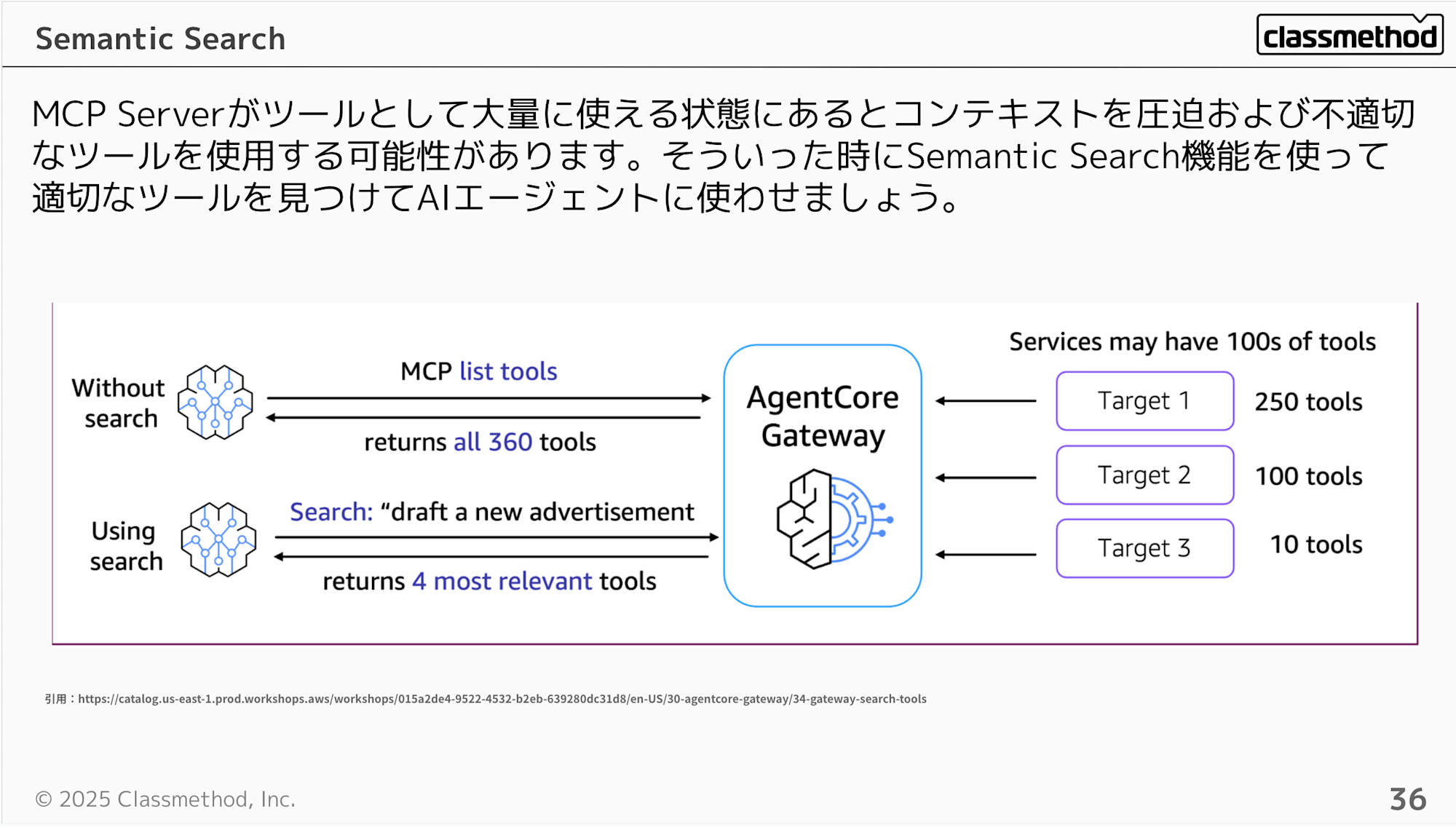
ツール同期する際にSemantic Search機能も活用できます。MCP Serverがツールとして大量に使える状態にあるとコンテキストを圧迫および不適切なツールを使用する可能性があります。そういった時にSemantic Search機能を使って適切なツールを見つけてAIエージェントに使わせましょう。
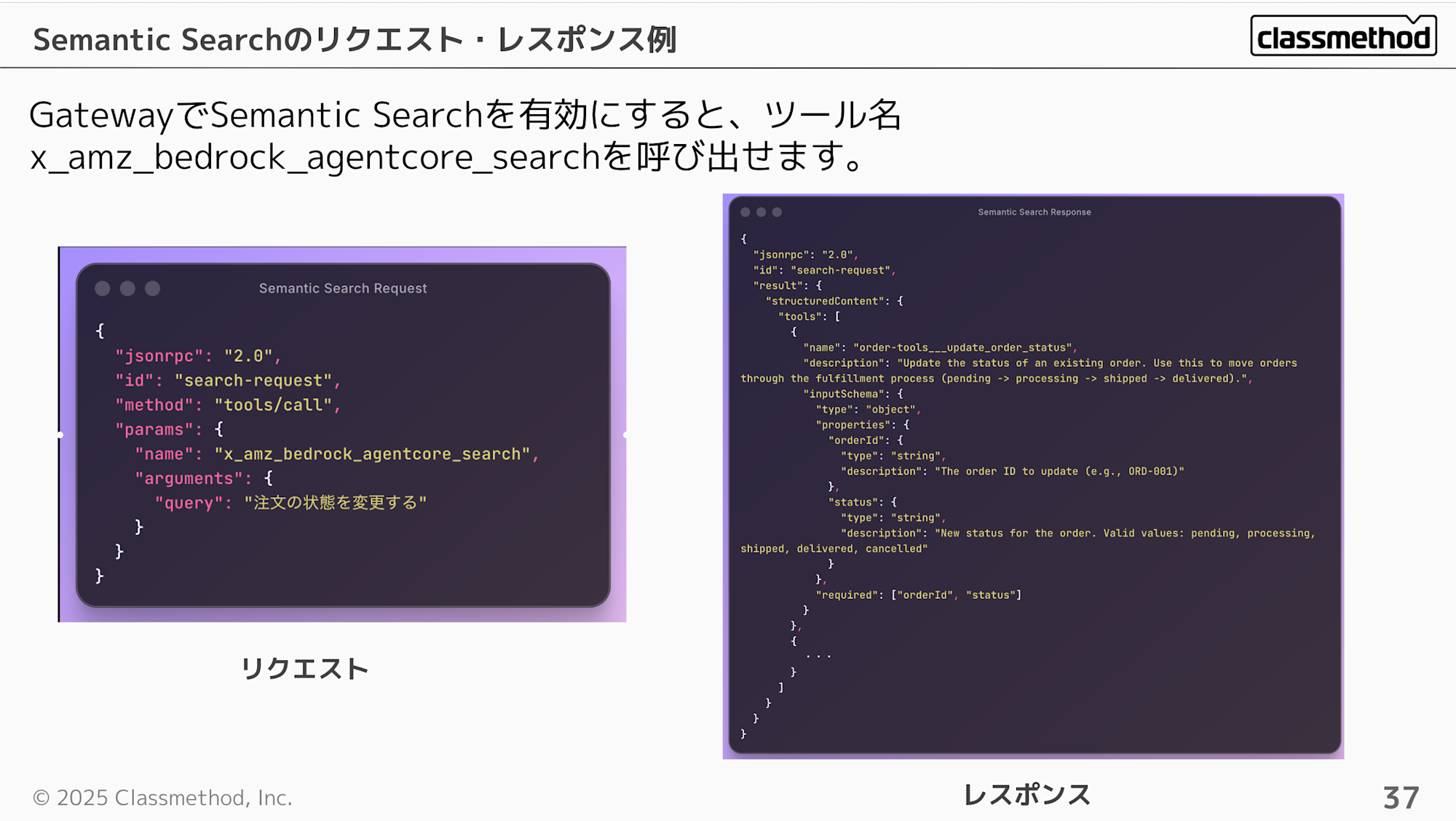
GatewayでSemantic Searchを有効にすると、ツール名x_amz_bedrock_agentcore_searchで検索を呼び出せます。 使用したところレスポンスは関連度順にツールが返却されるようにみえます。
リクエスト例
{
"jsonrpc": "2.0",
"id": "search-request",
"method": "tools/call",
"params": {
"name": "x_amz_bedrock_agentcore_search",
"arguments": {
"query": "注文の状態を変更する"
}
}
}
レスポンス例
{
"jsonrpc": "2.0",
"id": "search-request",
"result": {
"structuredContent": {
"tools": [
{
"name": "order-tools___update_order_status",
"description": "Update the status of an existing order. Use this to move orders through the fulfillment process (pending -> processing -> shipped -> delivered).",
"inputSchema": {
"type": "object",
"properties": {
"orderId": {
"type": "string",
"description": "The order ID to update (e.g., ORD-001)"
},
"status": {
"type": "string",
"description": "New status for the order. Valid values: pending, processing, shipped, delivered, cancelled"
}
},
"required": ["orderId", "status"]
}
},
{
・・・
}
]
}
}
}
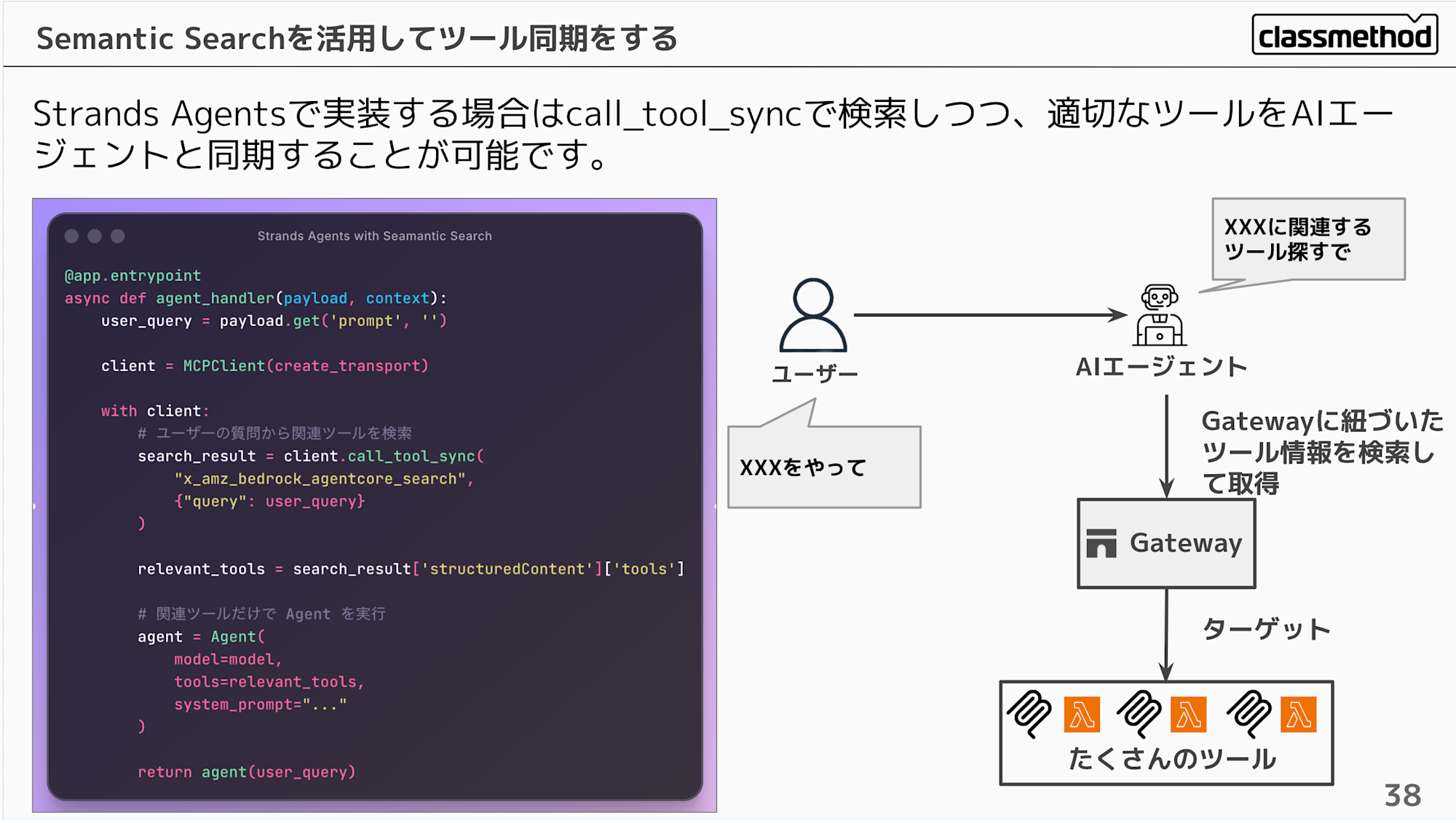
Strands Agentsで実装する場合はcall_tool_syncで検索しつつ、適切なツールをAIエージェントと同期することが可能です。
@app.entrypoint
async def agent_handler(payload, context):
user_query = payload.get('prompt', '')
client = MCPClient(create_transport)
with client:
# ユーザーの質問から関連ツールを検索
search_result = client.call_tool_sync(
"x_amz_bedrock_agentcore_search",
{"query": user_query}
)
relevant_tools = search_result['structuredContent']['tools']
# 関連ツールだけで Agent を実行
agent = Agent(
model=model,
tools=relevant_tools,
system_prompt="..."
)
return agent(user_query)
Semantic Searchを使用することでコンテキスト汚染を回避することにつながります。ANTHROPICの記事もMCP Serverをツールとして登録しすぎると、ツールの定義や結果に過剰なトークンが消費され、エージェントの効率が低下する可能性があるといっています。

これは人間でも同じようなことが言えると思います。いきなり、新しい職場に行って全ての情報を詰め込まれても適切な行動はできず自分がやりたいことに対してアドバイスしてくれる人が欲しいですよね。 AIエージェントも同じで、最適に実行できるようSemantic Searchで適切なツールを教えてあげるイメージを持つとわかりやすいです。
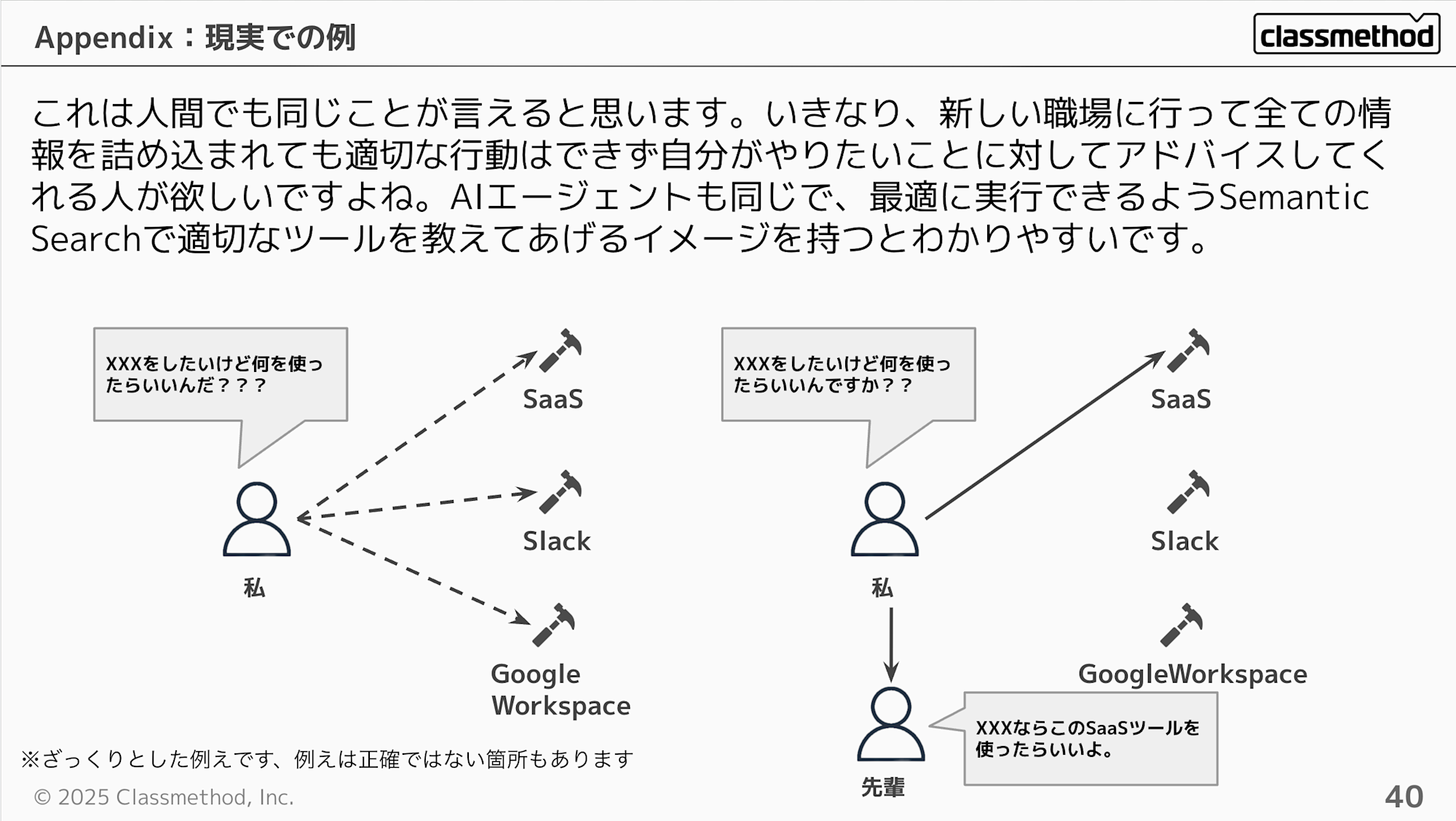
まとめるとGatewayの使い方としては、組織に既存のLambda関数やMCP Serverがたくさんあって、組み合わせる場合はGatewayに軍配が上がる気がします。あくまでオプションの選択肢で上記以外の用途なら無理に使う必要はない気もします。シンプルにLambda関数やRuntimeにMCP Serverをホストして使う方が早いと思います。
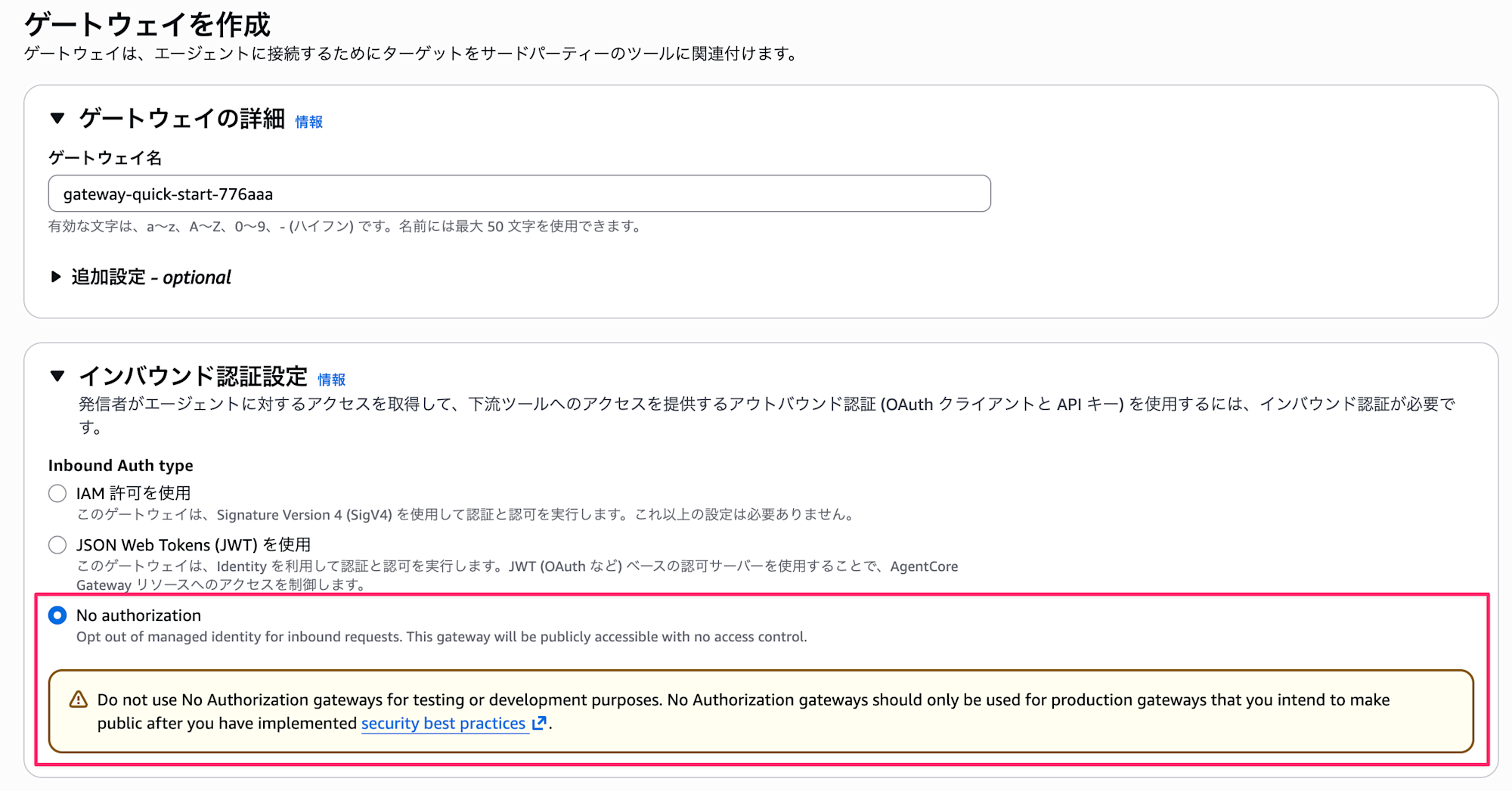
補足ですが、直近Gatewayでしれっと認証なしモードの設定が可能になりました。 現状、RuntimeでMCP ServerをホストするとIAMかJWT認証が必須なので、パブリックな環境にMCP Serverをホストしたい際にGatewayをハブとする選択肢も考えられますね。
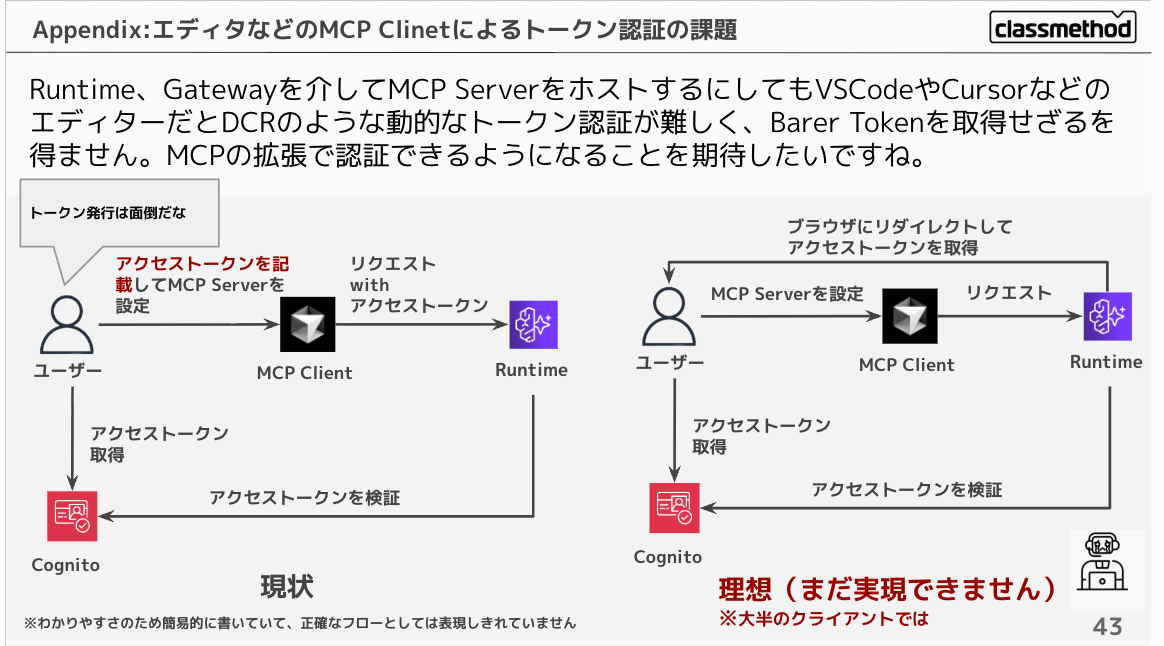
関連して、認証を設定してRuntime、Gatewayを介してMCP ServerをホストするにしてもVSCodeやCursorなどのエディターだとDCRのような動的なトークン認証が難しく、Bearer Tokenを取得せざるを得ません。MCPの拡張で認証できるようになることを期待したいですね。
ただIAM認証でRuntimeの認証を設定して、mcp-proxy-for-awsを活用すればIAMの権限を使って、MCPクライアントから独自のMCP Serverにアクセスする方法も考えられます。Claude CodeやCursorなどで実現できないか検証してみたいです。
Memoryの制御
前提としてMemoryのデータ構造をおさえます。ユーザー毎にactor_id、セッション毎にsession_idがビルトインの属性で存在するので簡単にユーザー毎の会話履歴を保持可能となります。
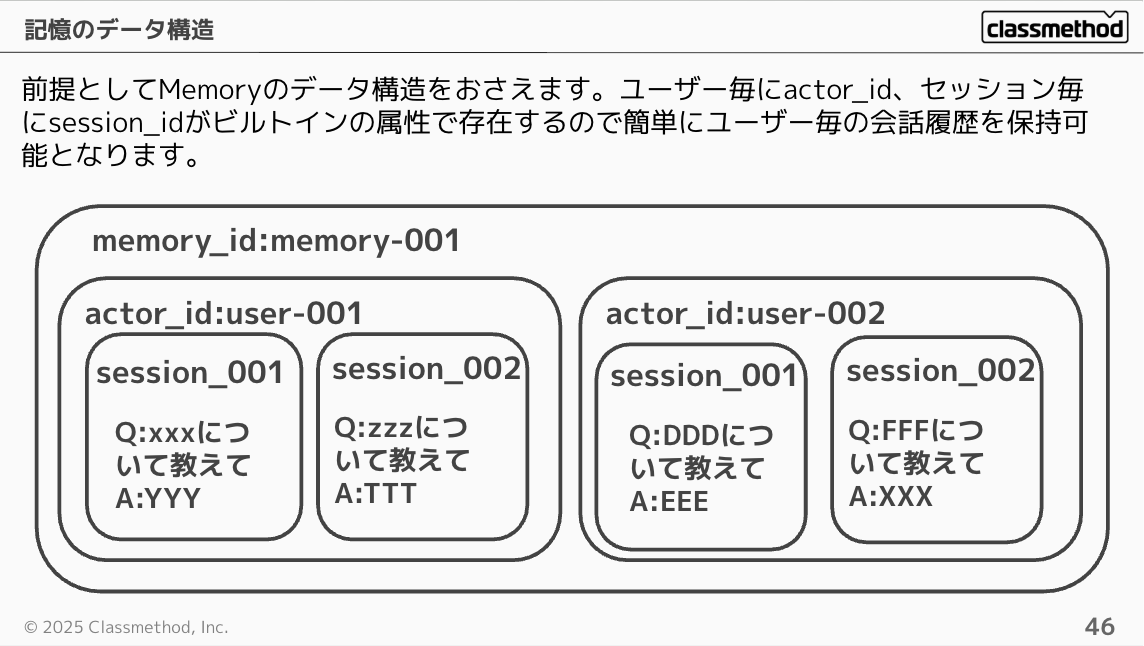
短期記憶の単位はChatGPTやClaudeなどの会話履歴タブがイメージしやすいです。

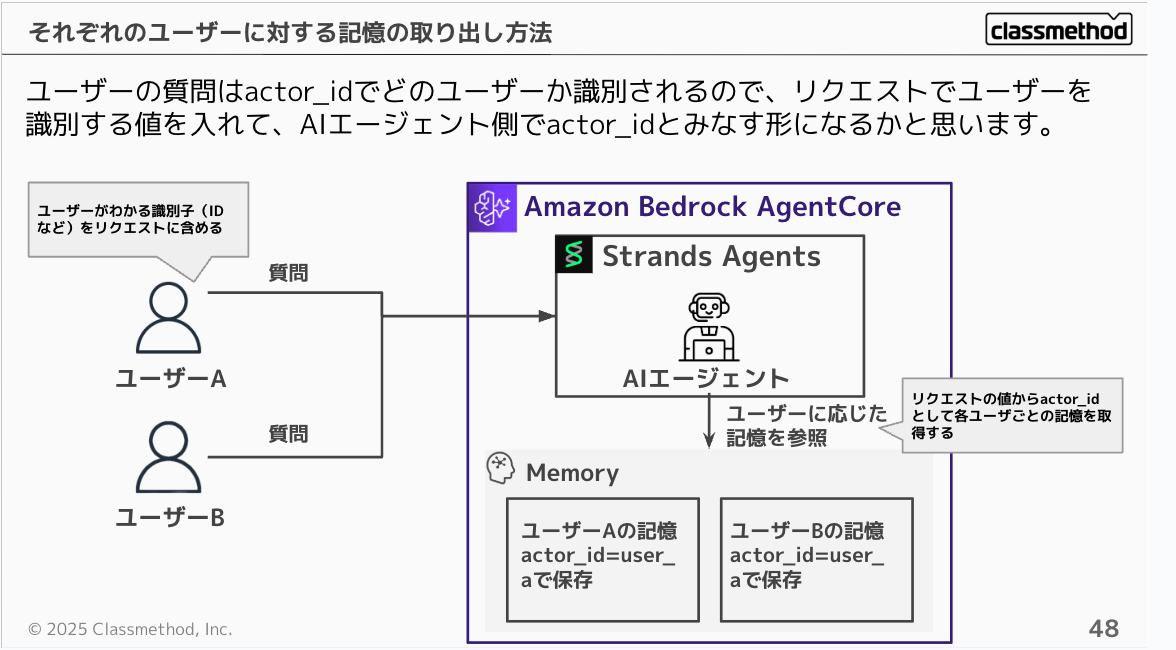
ユーザーの質問はactor_idでどのユーザーか識別されるので、リクエストでユーザーを識別する値を入れて、AIエージェント側でactor_idとみなす形になると思います。
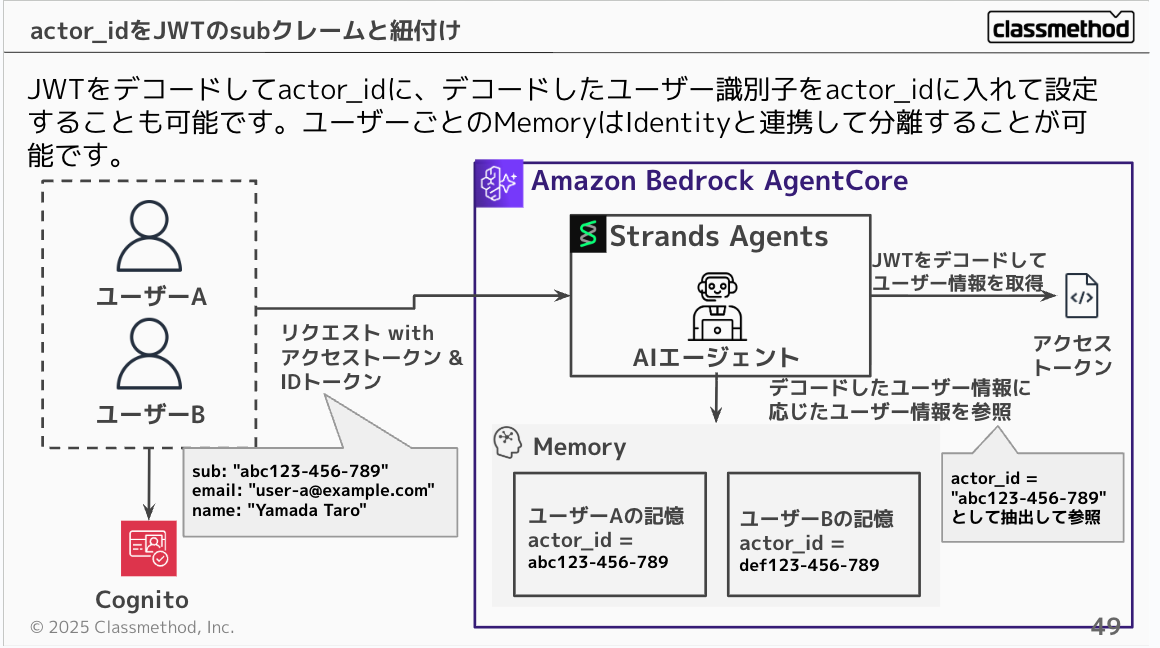
AgentCoreの認証をJWT認証としている場合、JWTをデコードしてactor_idに、デコードしたユーザー識別子を入れてactor_idに設定することも可能です。ユーザー毎の質問はIdentityと連携して簡単にMemoryと分離することが可能です。
Memoryの権限制御ですがアプリケーションだけではなく、インフラ側でも制御可能です。アプリケーションの設定ミスなどによる他者の記憶アクセスを回避することが可能です。JWTのIDTokenを活用して、Strands Agentsの処理で動的にIAMの権限を取得して権限分離を実現できます。
例えば下記のように記載して設定可能です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock-agentcore:CreateEvent",
"bedrock-agentcore:GetMemory",
"bedrock-agentcore:ListMemoryRecords",
"bedrock-agentcore:UpdateMemory",
"bedrock-agentcore:DeleteMemory"
],
"Resource": "arn:aws:bedrock-agentcore:us-west-2:123456789012:memory/*",
"Condition": {
"StringEquals": {
"bedrock-agentcore:actorId": "${cognito-identity.amazonaws.com:sub}"
}
}
}
]
}

上記の設定を行うことで、ユーザーAさんが保持している権限ではユーザーBさんの記憶にアクセスできません。アプリケーション側で誤ってユーザーBの記憶にアクセスしようとしてもIAMの権限で拒否されます。

デプロイ手法について
直接アップロードかコンテナイメージをアップロードするか選択可能です。Zipアップロードは250MB以下のパッケージをZIP形式で素早くデプロイでき、更新も高速です。 一方、コンテナベースは1GBまでの大規模パッケージや特殊な依存関係に対応し、既存のCI/CDパイプラインも活用できます。開発フェーズでは直接コードで素早くプロトタイピングし、本番環境ではコンテナへ移行するハイブリッドアプローチも有効です。

公式ドキュメントに直接アップロードかコンテナイメージのどちらを採用するかの比較情報も記載があるので、選択する際は参考になると思います。

おわりに
本登壇ではAgentCoreを本番利用する際に注意するポイントをいくつかご紹介させていただきました。何か1つでも皆様にとって新しい発見であったり、「AgentCoreをもっと使いこなしてみよう!」、「もっとAgentCoreを知りたい!」と思うきっかけになれば幸いです。次はIdentityをじっくり解説したいですね!
本記事が少しでも参考になりましたら幸いです!最後までご覧いただきありがとうございましたー!










