![[Amazon Bedrock] Claude Sonnet 4.5で圧力計の針を読み取る 〜YOLOセグメンテーションによる前処理で精度向上〜](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1764629855/user-gen-eyecatch/euj5htrlbpgqundj8ooc.jpg)
[Amazon Bedrock] Claude Sonnet 4.5で圧力計の針を読み取る 〜YOLOセグメンテーションによる前処理で精度向上〜
1. はじめに
製造ビジネステクノロジー部の平内(SIN)です。
クラスメソッド発 製造業 Advent Calendar 2025 3日目のエントリーです。
生成AIの進化により、画像認識技術も急速に発展しています。Amazon BedrockのClaude Sonnet 4.5を使用すれば、画像の内容を理解し、複雑な質問に答えることができます。
今回、製造現場で使用されている圧力計メーターの読み取りに挑戦してみました。しかし、単純にLLMに圧力計の画像を渡すだけでは、針の位置を正確に読み取ることができませんでした。
そこで、YOLOv8セグメンテーションモデルをファインチューニングし、圧力計の針を赤色で強調表示する前処理を実装することで、Claude Sonnet 4.5の認識精度を大幅に向上させることができました。
本記事では、プロンプトの工夫から画像前処理の実装まで、試行錯誤の過程と最終的なソリューションを紹介します。
以前に、画像処理だけで挑戦した圧力計の読み取りと比較してみて頂けると面白いかも知れません。
2. プロンプトによる試行
(1) 最初の試み(シンプルなプロンプト)
まず、以下のようなシンプルなプロンプトで圧力計の読み取りを試みました。
ユーザープロンプト:
この圧力計を読み取ってください。
システムプロンプト:
あなたは圧力計の画像から正確な数値を読み取る専門家です。画像を慎重に観察して、針の位置を正確に読み取ってください。
結果: 誤差平均 0.216 MPa
検証した結果は、以下のようなものです。
- Claude Sonnet 4.5は圧力計であることは認識できる
- しかし、針の位置を正確に特定できず、数値の読み取り精度は全く不十分でした
- 予測値が0.50 MPa付近に集中する傾向(8枚中5枚が0.50 MPaと判定)
- 特に低圧側(0〜0.2 MPa)で大きな誤差(+0.50〜+0.59 MPa)
- 針が細く、背景との区別が難しい画像では特に精度が低下

実は、Sonnet 4.5以外でも、いくつか試したのですが、良く似た結果(誤検知が多発)でした。

(2) プロンプトの改善(針の詳細説明を追加)
プロンプトを改善しようと、Few-shot や、Chain-of-Thought など、色々試行錯誤していて感じたのは、そもそも、「メーター針が認識できていないのでは?」という感覚でした。
ということで、メーター針の認識を詳細に説明するプロンプトを試してみました。
改善したシステムプロンプト:
あなたは圧力計の画像から正確な数値を読み取る専門家です。画像を慎重に観察して、針の位置を正確に読み取ってください。
## 【重要】針の特定方法と注意事項
### 針の物理的特徴
この圧力計には **ゲージの中心から放射状に伸びる細長い針** が1本あります。
- 針は **細く、直線的で、一端がゲージの中心に固定されています**
- 針は **中心から外側に向かって** 放射状に伸びています
- 針の長さは **ゲージの円の半径程度** です
- 針の色は **黒または濃い灰色** です
- 針は **1本だけ** 存在します
- 針には明確な **先端(外側の端)** があり、その先端が圧力値を示す目盛りを指しています
### 針ではないものに注意
画像内には針以外の要素があります。これらを針と間違えないでください。
- **JISロゴ**: ゲージ下部の円形のロゴマークは針ではありません
- **文字やブランド名**: "PRESSURE"、"JQA"などの文字は針ではありません
- **ネジやボルト**: ゲージ面にある固定用のネジは針ではありません
- **影**: 針の影は針ではありません
### 針を特定する手順
1. ゲージの **幾何学的な中心点**(円の中央)を見つけてください
2. その中心点から **放射状に伸びる細長い線** を探してください
3. その線が **目盛りの方向を向いている** ことを確認してください
4. その線の **外側の先端** が指している位置を読み取ってください
結果: 誤差平均 0.264 MPa(悪化)
色々な詳細説明を追加しても、飛躍的な精度改善はできず、むしろ悪化したイメージです。
- 誤差平均が 0.216 → 0.264 MPa に悪化(約22%悪化)
- 一部の画像で改善が見られたものの、全体的には精度が低下
- 針の向きを180度間違える事例が発生(0.00 MPa → 0.70 MPa と判定)
- 詳細な説明がLLMを混乱させている印象

ここまでの作業で、プロンプトだけでは問題解決が難しいという結論に達しました。
3. 画像前処理による試行
(1) 針を赤色で強調
メーター針の認識を向上させるため、画像の前処理をすることにしました。
前処理では、YOLOでセグメンテーションモデルをファインチューニングして、メーター針を検出し、赤色にペイントしてみました。

システムプロンプト(メーター針の色を指定)
あなたは圧力計の画像から正確な数値を読み取る専門家です。画像を慎重に観察して、針の位置を正確に読み取ってください。
圧力計の針は、赤色です。
結果: 誤差平均 0.286 MPa(さらに悪化)
前処理を追加したにもかかわらず、平均誤差は改善しませんでした。しかし、ピタリ正解のケースが出現し始めました。
そして、よく観察すると、メーター針を認識できているが、方向を180度間違えているものがあることに気が付きます。
この結果から、針を赤色にすることは有効だが、針の向き(先端の位置)を明示する必要があることが判明しました。

(2) 針を赤色で強調 + 針先にポインタ
針の先端に赤色の小さな三角形マーカーを追加し、向きを明確にする前処理を実装しました。

システムプロンプト(最終盤)
あなたは圧力計の画像から正確な数値を読み取る専門家です。画像を非常に慎重に観察して、針の位置を正確に読み取ってください。
## 圧力計の構造
この圧力計は円形のアナログゲージです。
- **測定範囲**: 0〜1.0 MPa
- **目盛りの配置**: 円周上に時計回りに配置
- 左下が 0 MPa(約7時の位置)
- 上部が 0.4〜0.6 MPa(11時〜1時の位置)
- 右下が 1.0 MPa(約5時の位置)
- **主目盛り**: 0, 0.2, 0.4, 0.6, 0.8, 1.0(0.2刻み、数字が表示されている)
- **小目盛り**: 各主目盛り間に10個の小目盛り(1小目盛り = 0.02 MPa)
## 針の特定方法
圧力計には **赤色の針** が1本あります。
- 針は **ゲージの中心から放射状に伸びる細長い線** です
- **針の先端には小さな赤色の三角形マーカー** が描画されています
- この三角形マーカーが指している方向が **針の先端** です
- 針の先端(三角形マーカーがある側)が圧力値を示しています
## 読み取り手順
1. ゲージの中心から放射状に伸びる **赤い針** を特定する
2. **針の先端にある小さな赤色の三角形マーカー** を見つける
3. 三角形マーカーが時計の何時の方向を指しているか確認する
4. その方向に対応する圧力値の範囲を特定する
5. 針の先端(三角形マーカーの位置)が指す目盛りを読み取る
結果: 誤差平均 0.023 MPa(劇的な改善!)
三角形マーカーの追加により、精度が劇的に向上しました。
- 誤差平均が 0.286 → 0.023 MPa に改善(約12倍の精度向上)
- 180度間違いが完全に解消
- 最大誤差も 0.05 MPa 以内に収まる

4. サンプル実装
前処理を含むBedrockへのアクセスを構成してみました。
画像とプロンプトは、Lambdaに送信されます。Lambdaでは、受け取った画像をセグメンテーションモデルで前処理し、Bedrockにリクエストしています。
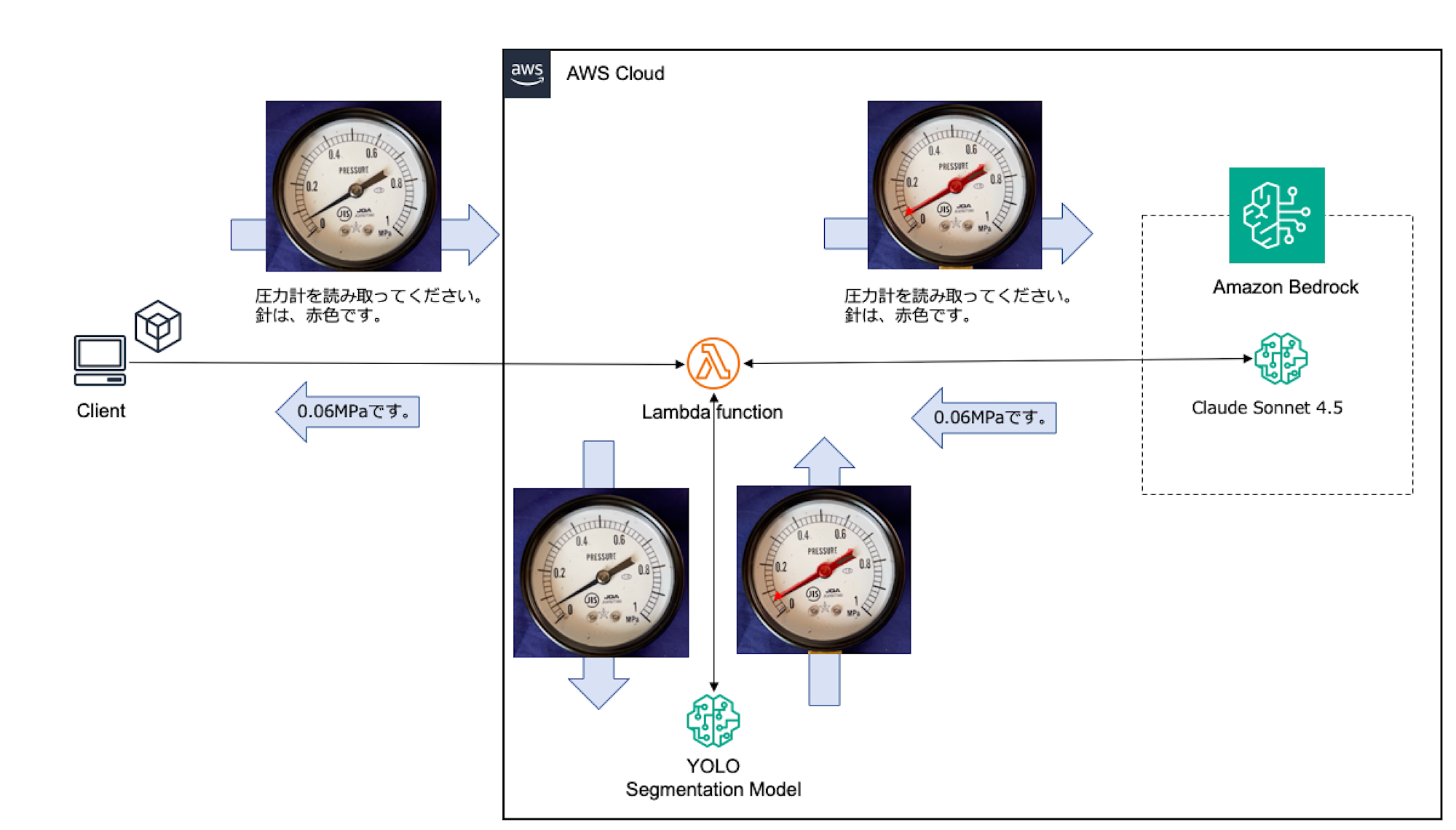
Github: https://github.com/furuya02/aws-pressure-gauge-reader
(1) デプロイ手順
サンプルは、以下の手順でデプロイできます。
ステップ1: Clone
git clone https://github.com/furuya02/aws-pressure-gauge-reader
cd aws-pressure-gauge-reader
ステップ2: CDK Deploy
cd cdk
npm install
npx cdk bootstrap # 初回のみ
npx cdk deploy
ステップ3: Bedrock Model Accessの有効化
- AWS Console → Amazon Bedrock → Model access
- Claude Sonnet 4.5 を有効化(us-east-1リージョン)
ステップ4: テスト実行
cd scripts
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
python test.py ../sample_images/0001.png
出力例:
[YOLO処理] 針検出成功: 1個の針を検出しました
[LLM解析結果]
--------------------------------------------------------------------------------
この圧力計の針は **約0.05 MPa** を指しています。
針は0と0.2の間の、0に近い位置を示しており、目盛りから判断すると
**0.05 MPa前後** の値を示していると読み取れます。
--------------------------------------------------------------------------------
[INFO] 前処理済み画像を保存中: output/0001_processed.png
[SUCCESS] テストが完了しました
(2) Lambda
YOLOv8 + PyTorch + OpenCVの依存関係は、Lambda Layerの250MB制限を超過するため、Dockerコンテナイメージ形式で実装されています。
参考: AWS Lambdaでの機械学習モデル実装ガイド docs/02_implementation/01_lambda-ml-implementation-guide.md
また、モデルのロードは、かなり時間がかかるため、キャッシュしています。
# グローバル変数でモデルとクライアントをキャッシュ
processor = None
bedrock_client = None
def initialize_processor():
global processor
if processor is None:
processor = YOLOProcessor(model_path='/opt/ml/model/best.pt')
processor.load_model()
return processor
def initialize_bedrock_client():
global bedrock_client
if bedrock_client is None:
bedrock_client = boto3.client('bedrock-runtime', region_name='us-east-1')
return bedrock_client
当初、Bedrock Agentを使用する予定でしたが、以下の理由により Lambda直接呼び出しに変更しました。
- 画像連携の制約:
sessionState.filesは Action Group に画像を渡せない - 非効率性: 単一アクションではAgentのオーバーヘッド(約1.3秒)が無駄
- シンプルさ: Lambda直接呼び出しの方が理解しやすく、デバッグも容易
参考:Bedrock Agentを利用しない理由 docs/01_architecture/01_why-not-bedrock-agent.md
(3) 実装
実装について簡単に紹介させてください。
Lambda関数ハンドラー
import json
import base64
import os
import boto3
from yolo_processor import YOLOProcessor
# グローバル変数(コールドスタート対策)
processor = None
bedrock_client = None
def lambda_handler(event, context):
"""
Lambda関数のエントリーポイント
"""
# 初期化
global processor, bedrock_client
if processor is None:
processor = YOLOProcessor(
model_path=os.environ.get('MODEL_PATH', '/opt/ml/model/best.pt'),
conf_threshold=float(os.environ.get('CONF_THRESHOLD', '0.65')),
iou_threshold=float(os.environ.get('IOU_THRESHOLD', '0.5'))
)
processor.load_model()
if bedrock_client is None:
bedrock_client = boto3.client(
'bedrock-runtime',
region_name=os.environ.get('BEDROCK_REGION', 'us-east-1')
)
# リクエストの解析
body = json.loads(event.get('body', '{}'))
image_base64 = body.get('image')
user_prompt = body.get('userPrompt', 'この圧力計を読み取ってください。')
system_prompt = body.get('systemPrompt', '圧力計の画像から正確な数値を読み取る専門家です。')
preprocess_image = body.get('preprocessImage', True)
# 画像をデコード
image_bytes = base64.b64decode(image_base64)
image = cv2.imdecode(np.frombuffer(image_bytes, np.uint8), cv2.IMREAD_COLOR)
# YOLO前処理(オプション)
yolo_message = "前処理スキップ"
if preprocess_image:
processed_image, needle_count = processor.process_image(image, mode='triangle')
yolo_message = f"針検出成功: {needle_count}個の針を検出しました"
# 前処理済み画像をBase64エンコード
_, buffer = cv2.imencode('.png', processed_image)
processed_image_base64 = base64.b64encode(buffer).decode('utf-8')
else:
processed_image_base64 = image_base64
# Bedrock LLM呼び出し
llm_response = invoke_bedrock_llm(
bedrock_client,
processed_image_base64,
user_prompt,
system_prompt
)
# レスポンス作成
return {
'statusCode': 200,
'body': json.dumps({
'llmResponse': llm_response,
'processedImage': processed_image_base64,
'yoloMessage': yolo_message
})
}
def invoke_bedrock_llm(client, image_base64, user_prompt, system_prompt):
"""
Bedrock LLMを呼び出す
"""
response = client.invoke_model(
modelId='us.anthropic.claude-sonnet-4-5-20250929-v1:0',
body=json.dumps({
'anthropic_version': 'bedrock-2023-05-31',
'max_tokens': 1024,
'system': system_prompt,
'messages': [
{
'role': 'user',
'content': [
{
'type': 'image',
'source': {
'type': 'base64',
'media_type': 'image/png',
'data': image_base64
}
},
{
'type': 'text',
'text': user_prompt
}
]
}
]
})
)
result = json.loads(response['body'].read())
return result['content'][0]['text']
CDKスタック
import * as cdk from 'aws-cdk-lib';
import * as lambda from 'aws-cdk-lib/aws-lambda';
import * as iam from 'aws-cdk-lib/aws-iam';
import { DockerImageCode, DockerImageFunction } from 'aws-cdk-lib/aws-lambda';
import * as path from 'path';
export class PressureGaugeStack extends cdk.Stack {
constructor(scope: cdk.App, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// Lambda関数の作成(コンテナイメージ)
const gaugeDetectionFunction = new DockerImageFunction(this, 'GaugeDetectionFunction', {
functionName: 'pressure-gauge-detection',
code: DockerImageCode.fromImageAsset(path.join(__dirname, '../lambda')),
memorySize: 3008, // 3GB
timeout: cdk.Duration.seconds(120),
environment: {
MODEL_PATH: '/opt/ml/model/best.pt',
BEDROCK_REGION: 'us-east-1',
CONF_THRESHOLD: '0.65',
IOU_THRESHOLD: '0.5',
},
});
// Bedrock呼び出し権限を追加
gaugeDetectionFunction.addToRolePolicy(new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: ['bedrock:InvokeModel'],
resources: ['arn:aws:bedrock:*::foundation-model/*anthropic.claude-sonnet-4-5-*'],
}));
}
}
5. 試行錯誤
ここまで、かなりスムーズに改善が進んだように書いてしまっていますが、当然というか、結構な試行錯誤があったことは想像できると思います。
ここで、少し、失敗例も供養させてください。
(1) OpenCVによる前処理
前処理としての画像処理は、当初、OpenCVによる処理を色々試しました。
- コントラスト強化
- シャープネス強化
- 中心マーカーの追加
- OpenCV色ベース検出
- OpenCV輪郭検出ベース

しかし、どれも、成果はありませんでした。
(2) メーター針のポインタ
結果的に、小さな三角形が最適だったのですが、ポインターは、色々試行錯誤しています。人間が見て「分かりやすい」という極端な表現は、逆にLLMを混乱させるかも知れないという印象です。


(3) 針先だけのセグメンテーション
180度誤認する問題に対応するため、針先の方だけのセグメンテーションモデルの作成も試みました。
しかし、これは、モデルの精度が非常に悪くなってしまって、前処理段階で針を見失うという結果となってしまいました。


6. まとめ
本記事では、LLMによる圧力計メーター読み取りを紹介させていただきました。
試行錯誤から得られた知見
-
プロンプトの工夫だけでは不十分
- シンプルなプロンプト: 誤差平均 0.216 MPa
- 針の詳細説明を追加: 誤差平均 0.264 MPa(悪化)
- プロンプトを複雑にしても、むしろ精度が低下する
-
画像前処理も段階的な改善が必要
- YOLO前処理(赤色のみ): 誤差平均 0.286 MPa(さらに悪化)
- 針を赤色にするだけでは、向きを180度間違える問題が発生
- 針の先端に三角形マーカーを追加: 誤差平均 0.023 MPa(劇的な改善!)
-
最終的なソリューション
- YOLOv8セグメンテーションで針を検出
- 針を赤色で強調 + 先端に三角形マーカーを追加
- 適切なプロンプトと組み合わせて実用レベルの精度を達成
- 誤差平均 0.023 MPa(初期の約10分の1)
-
AWS Lambdaでのサーバーレス実装
- Dockerコンテナイメージ形式でYOLO + Bedrockを統合
- コールドスタート対策により、2回目以降は2-5秒で応答
比較まとめ
| 試行 | 手法 | 誤差平均 | 主な問題点 |
|---|---|---|---|
| 1 | シンプルなプロンプト | 0.216 MPa | 針の位置が不明確 |
| 2 | 針の詳細説明追加 | 0.264 MPa | プロンプトが複雑すぎて混乱 |
| 3 | YOLO前処理(赤色のみ) | 0.286 MPa | 針の向き(先端)が不明確 |
| 4 | YOLO前処理 + 三角形マーカー | 0.023 MPa | 比較的高い精度 |








