
S3データソースでAmazon Bedrock Knowledge Baseの直接取り込み(Direct Ingestion)を試してみた
はじめに
こんにちは、スーパーマーケットが大好きなコンサルティング部の神野です。
Amazon Bedrock Knowledge Basesを使ったRAGアプリケーションを構築していると、Knowledge Basesにドキュメントを即座に反映したい、かつその頻度が高いケースに遭遇しませんか?少なくとも私は直近遭遇しました。
愚直にファイルが変更されたタイミング単位で同期をかければ良いのでしょうが、多数の人が大量に同期したいケースはどうでしょう。例えば自分がファイルアップロードしたタイミングでRAGに取り込んで欲しいですが、それが何百人が同時に1ファイルずつ更新する度に・・・となると同期ジョブの待ちが発生して体験が悪くなることが予想されます。
もちろんある程度の時間単位でバッチで動かすのも手だと思いますが、できれば個人がアップロードしたタイミングでそのファイルだけ同期されて欲しいって感じだと嬉しいです。
何かいい方法がないか調べてみると、Bedrockには直接取り込み(Direct Ingestion)機能がありました。
IngestKnowledgeBaseDocuments APIを使うことで、全件の同期ジョブを経由せずに、指定のドキュメントを直接Knowledge Basesに取り込めます。
これは今回やりたいことに近いし、なんだか良さそうな匂いがしますね。早速この直接取り込み機能について、作成・更新・削除の各操作を行なって理解を深めていきます!!
前提
使用環境
今回は下記環境を使用しました。
| 項目 | バージョン・値 |
|---|---|
| aws-cdk-lib | 2.235.1 |
| Node.js | 25.4.0 |
| リージョン | us-west-2 |
直接取り込み
通常のKnowledge Basesへのドキュメント取り込みは、S3バケットにドキュメントをアップロードし、StartIngestionJob APIで同期ジョブを実行、その後Knowledge Basesがドキュメントをスキャン・チャンキング・ベクトル化という流れで行われます。
一方、直接取り込みではIngestKnowledgeBaseDocuments APIでドキュメントを直接送信すると、Knowledge Basesが即座にチャンキング・ベクトル化を行います。つまり、同期ジョブのスキャン処理をバイパスできるため、より迅速にドキュメントを反映できるというわけです。
カスタムデータソースとS3データソースが直接取り込み可能ですが、今回はS3データソースを対象にします。
実装
CDKでKnowledge Bases環境を構築
まずは検証用のKnowledge Bases環境をCDKで構築します。
今回はS3 Vectorsをベクトルストアとして使用し、S3タイプのデータソースを作成します。
コード全量
import * as cdk from "aws-cdk-lib/core";
import { Construct } from "constructs";
import * as s3vectors from "aws-cdk-lib/aws-s3vectors";
import * as s3 from "aws-cdk-lib/aws-s3";
import * as bedrock from "aws-cdk-lib/aws-bedrock";
import * as iam from "aws-cdk-lib/aws-iam";
export interface CdkS3VectorsKbStackProps extends cdk.StackProps {
/**
* Vector dimension for embeddings (default: 1024 for Titan Embeddings V2)
*/
vectorDimension?: number;
/**
* Embedding model ID (default: amazon.titan-embed-text-v2:0)
*/
embeddingModelId?: string;
}
export class CdkIngestKbStack extends cdk.Stack {
public readonly vectorBucket: s3vectors.CfnVectorBucket;
public readonly vectorIndex: s3vectors.CfnIndex;
public readonly knowledgeBase: bedrock.CfnKnowledgeBase;
public readonly dataSourceBucket: s3.Bucket;
constructor(scope: Construct, id: string, props?: CdkS3VectorsKbStackProps) {
super(scope, id, props);
const vectorDimension = props?.vectorDimension ?? 1024;
const embeddingModelId =
props?.embeddingModelId ?? "amazon.titan-embed-text-v2:0";
const vectorBucketName = `vector-bucket-${cdk.Aws.ACCOUNT_ID}-${cdk.Aws.REGION}`;
// ===========================================
// S3 Vector Bucket
// ===========================================
this.vectorBucket = new s3vectors.CfnVectorBucket(this, "VectorBucket", {
vectorBucketName: vectorBucketName,
});
// ===========================================
// S3 Vector Index
// ===========================================
this.vectorIndex = new s3vectors.CfnIndex(this, "VectorIndex", {
vectorBucketName: vectorBucketName,
indexName: "kb-vector-index",
dimension: vectorDimension,
distanceMetric: "cosine",
dataType: "float32",
});
this.vectorIndex.addDependency(this.vectorBucket);
// ===========================================
// Data Source S3 Bucket (for documents)
// ===========================================
this.dataSourceBucket = new s3.Bucket(this, "DataSourceBucket", {
bucketName: `kb-datasource-${cdk.Aws.ACCOUNT_ID}-${cdk.Aws.REGION}`,
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
// ===========================================
// IAM Role for Knowledge Bases
// ===========================================
const knowledgeBaseRole = new iam.Role(this, "KnowledgeBaseRole", {
assumedBy: new iam.ServicePrincipal("bedrock.amazonaws.com"),
inlinePolicies: {
BedrockKnowledgeBasePolicy: new iam.PolicyDocument({
statements: [
// S3 Vectors permissions
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: [
"s3vectors:CreateIndex",
"s3vectors:DeleteIndex",
"s3vectors:GetIndex",
"s3vectors:ListIndexes",
"s3vectors:PutVectors",
"s3vectors:GetVectors",
"s3vectors:DeleteVectors",
"s3vectors:QueryVectors",
"s3vectors:ListVectors",
],
resources: [
// ARN format: arn:aws:s3vectors:REGION:ACCOUNT:bucket/BUCKET_NAME
`arn:aws:s3vectors:${cdk.Aws.REGION}:${cdk.Aws.ACCOUNT_ID}:bucket/${vectorBucketName}`,
`arn:aws:s3vectors:${cdk.Aws.REGION}:${cdk.Aws.ACCOUNT_ID}:bucket/${vectorBucketName}/index/*`,
],
}),
// S3 Data Source permissions
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: ["s3:GetObject", "s3:ListBucket"],
resources: [
this.dataSourceBucket.bucketArn,
`${this.dataSourceBucket.bucketArn}/*`,
],
}),
// Bedrock Foundation Model permissions
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: ["bedrock:InvokeModel"],
resources: [
`arn:aws:bedrock:${cdk.Aws.REGION}::foundation-model/${embeddingModelId}`,
],
}),
],
}),
},
});
// ===========================================
// Bedrock Knowledge Bases with S3 Vectors
// ===========================================
this.knowledgeBase = new bedrock.CfnKnowledgeBase(this, "KnowledgeBase", {
name: "S3VectorsKnowledgeBase",
description: "Knowledge Bases using S3 Vectors as vector store",
roleArn: knowledgeBaseRole.roleArn,
knowledgeBaseConfiguration: {
type: "VECTOR",
vectorKnowledgeBaseConfiguration: {
embeddingModelArn: `arn:aws:bedrock:${cdk.Aws.REGION}::foundation-model/${embeddingModelId}`,
},
},
storageConfiguration: {
type: "S3_VECTORS",
s3VectorsConfiguration: {
vectorBucketArn: this.vectorBucket.attrVectorBucketArn,
indexName: this.vectorIndex.indexName!,
},
},
});
this.knowledgeBase.addDependency(this.vectorIndex);
this.knowledgeBase.node.addDependency(knowledgeBaseRole);
// ===========================================
// Bedrock Data Source (S3 Type)
// ===========================================
const dataSource = new bedrock.CfnDataSource(this, "DataSource", {
name: "S3DataSource",
description: "S3 data source for knowledge base",
knowledgeBaseId: this.knowledgeBase.attrKnowledgeBaseId,
dataSourceConfiguration: {
type: "S3",
s3Configuration: {
bucketArn: this.dataSourceBucket.bucketArn,
},
},
});
dataSource.addDependency(this.knowledgeBase);
// ===========================================
// Outputs
// ===========================================
new cdk.CfnOutput(this, "VectorBucketArn", {
value: this.vectorBucket.attrVectorBucketArn,
description: "ARN of the S3 Vector Bucket",
});
new cdk.CfnOutput(this, "VectorIndexArn", {
value: this.vectorIndex.attrIndexArn,
description: "ARN of the Vector Index",
});
new cdk.CfnOutput(this, "KnowledgeBaseId", {
value: this.knowledgeBase.attrKnowledgeBaseId,
description: "ID of the Bedrock Knowledge Bases",
});
new cdk.CfnOutput(this, "DataSourceId", {
value: dataSource.attrDataSourceId,
description: "ID of the S3 Data Source",
});
new cdk.CfnOutput(this, "DataSourceBucketName", {
value: this.dataSourceBucket.bucketName,
description: "Name of the S3 bucket for data source documents",
});
}
}
ベクトルストアにはお値段がお安いS3 Vectorsを使用し、データソースタイプはS3に設定しています。
Embedding ModelはTitan Embeddings V2を使用しています。
デプロイと初回同期
デプロイします。
pnpm dlx cdk deploy
デプロイが完了すると、Knowledge Base ID、Data Source ID、バケット名が出力されます。
CdkIngestKbStack.DataSourceBucketName = kb-datasource-123456789012-us-west-2
CdkIngestKbStack.DataSourceId = YYYYYYYYYY
CdkIngestKbStack.KnowledgeBaseId = XXXXXXXXXX
CdkIngestKbStack.VectorBucketArn = arn:aws:s3vectors:us-west-2:123456789012:bucket/vector-bucket-123456789012-us-west-2
CdkIngestKbStack.VectorIndexArn = arn:aws:s3vectors:us-west-2:123456789012:bucket/vector-bucket-123456789012-us-west-2/index/kb-vector-index
以降のコマンドで使用するため、環境変数として設定しておくと便利です。
export KB_ID="XXXXXXXXXX" # KnowledgeBaseId の出力値
export DS_ID="YYYYYYYYYY" # DataSourceId の出力値
export BUCKET_NAME="kb-datasource-123456789012-us-east-1" # DataSourceBucketName の出力値
コンソールまたはCLIで初回同期を実行します。
aws bedrock-agent start-ingestion-job \
--knowledge-base-id "$KB_ID" \
--data-source-id "$DS_ID"
完了したら土台は整ったので、検証進めていきます!
検証
ドキュメントの作成・更新・削除などよくありそうなオペレーションと絡めて動作確認していきます!
今回はアプリケーションに組み込む前提でコンソールではなくAPIを活用して、検証していきます。
ドキュメントの作成
まずは IngestKnowledgeBaseDocuments APIを使ってドキュメントを取り込みます。
S3データソースの場合、S3上のファイルを指定して取り込みます。
まず、S3にドキュメントをアップロードします。
echo "Amazon Bedrockは、主要なAI企業が提供する高性能な基盤モデルを単一のAPIで利用できるフルマネージドサービスです。" > bedrock-intro.txt
aws s3 cp bedrock-intro.txt s3://${BUCKET_NAME}/documents/bedrock-intro.txt
次に、直接取り込みを実行するingest-knowledge-base-documentsAPIでKnowledge Basesに取り込みます。
aws bedrock-agent ingest-knowledge-base-documents \
--knowledge-base-id "$KB_ID" \
--data-source-id "$DS_ID" \
--documents '[
{
"content": {
"dataSourceType": "S3",
"s3": {
"s3Location": {
"uri": "s3://'"${BUCKET_NAME}"'/documents/bedrock-intro.txt"
}
}
}
}
]'
実行すると、非同期処理が開始され下記のようにレスポンスが返却されます。
statusがSTARTINGとなっていますね。
{
"documentDetails": [
{
"knowledgeBaseId": "XXXXXXXXXX",
"dataSourceId": "YYYYYYYYYY",
"status": "STARTING",
"identifier": {
"dataSourceType": "S3",
"s3": {
"uri": "s3://kb-datasource-123456789012-us-west-2/documents/bedrock-intro.txt"
}
},
"updatedAt": "2026-01-25T12:21:37.536031+00:00"
}
]
}
取り込みは非同期で処理されるため、ステータスが下記のように遷移していきます。
| ステータス | 説明 |
|---|---|
STARTING |
取り込み処理の開始 |
IN_PROGRESS |
チャンキング・ベクトル化処理中 |
INDEXED |
正常に取り込み完了 |
FAILED |
取り込み失敗 |
PARTIALLY_INDEXED |
一部のみ取り込み成功 |
今のままだとステータスが不明でどうやって完了を判断するんだ・・・?と不安になりますが、大丈夫です。
GetKnowledgeBaseDocuments APIでS3のパスをキーにしてステータスを確認できます。
取り込み開始して、少し経ってから実行してみます。
aws bedrock-agent get-knowledge-base-documents \
--knowledge-base-id "$KB_ID" \
--data-source-id "$DS_ID" \
--document-identifiers '[
{
"dataSourceType": "S3",
"s3": {
"uri": "s3://'"${BUCKET_NAME}"'/documents/bedrock-intro.txt"
}
}
]'
実行すると、直接取り込みを実施した時と同じ形式でレスポンスが返却されます。
{
"documentDetails": [
{
"knowledgeBaseId": "XXXXXXXXXX",
"dataSourceId": "YYYYYYYYYY",
"status": "INDEXED",
"identifier": {
"dataSourceType": "S3",
"s3": {
"uri": "s3://kb-datasource-123456789012-us-west-2/documents/bedrock-intro.txt"
}
},
"statusReason": "",
"updatedAt": "2026-01-25T12:21:40.992274+00:00"
}
]
}
ステータスを見ると先ほどとは違ってINDEXEDになっていますね。無事に取り込み完了です。
アプリケーションに組み込む際は、非同期を意識して定期的にGetKnowledgeBaseDocumentsを実行してステータスをポーリングするような作りにする必要がありそうですね。完了判定やエラーハンドリングも意識したいですね。
試しにコンソール上でナレッジベースに対して動作確認してみます。
シンプルにBedrock について教えてと聞いてみます。
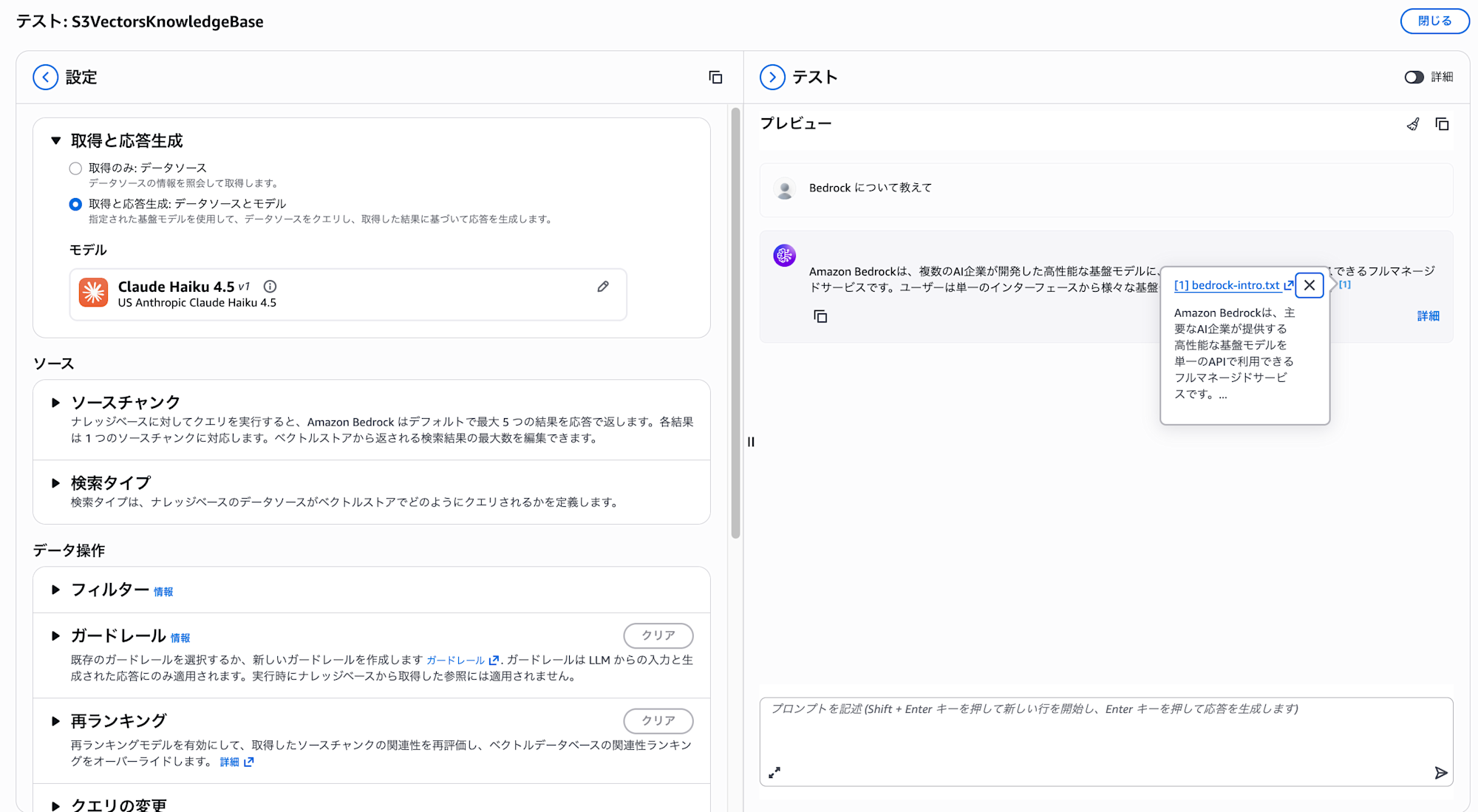
アップロードしたドキュメントを参照してレスポンスを返却してくれていますね!
ドキュメントの更新(Update)
次は先ほど作成したS3上のファイルを更新してみます。
echo "Amazon Bedrockは、主要なAI企業が提供する高性能な基盤モデルを単一のAPIで利用できるフルマネージドサービスです。Claude、Titan、Mistralなど多数のモデルに対応しています。" > bedrock-intro.txt
aws s3 cp bedrock-intro.txt s3://${BUCKET_NAME}/documents/bedrock-intro.txt
再度 IngestKnowledgeBaseDocuments を呼び出すと、ドキュメントが更新されます。
aws bedrock-agent ingest-knowledge-base-documents \
--knowledge-base-id "$KB_ID" \
--data-source-id "$DS_ID" \
--documents '[
{
"content": {
"dataSourceType": "S3",
"s3": {
"s3Location": {
"uri": "s3://'"${BUCKET_NAME}"'/documents/bedrock-intro.txt"
}
}
}
}
]'
実行するとレスポンスが返却されます。作成時と同じ形式ですね。タイムスタンプなどはもちろん更新されています。
{
"documentDetails": [
{
"knowledgeBaseId": "XXXXXXXXXX",
"dataSourceId": "YYYYYYYYYY",
"status": "STARTING",
"identifier": {
"dataSourceType": "S3",
"s3": {
"uri": "s3://kb-datasource-123456789012-us-west-2/documents/bedrock-intro.txt"
}
},
"updatedAt": "2026-01-25T12:40:40.567801+00:00"
}
]
}
同じS3 URIを指定することで既存ドキュメントが上書きされるので、S3上のファイルを更新してから直接取り込みを実行することで、Knowledge Bases側も更新されます。
同じようにコンソール上で動作確認してみます。
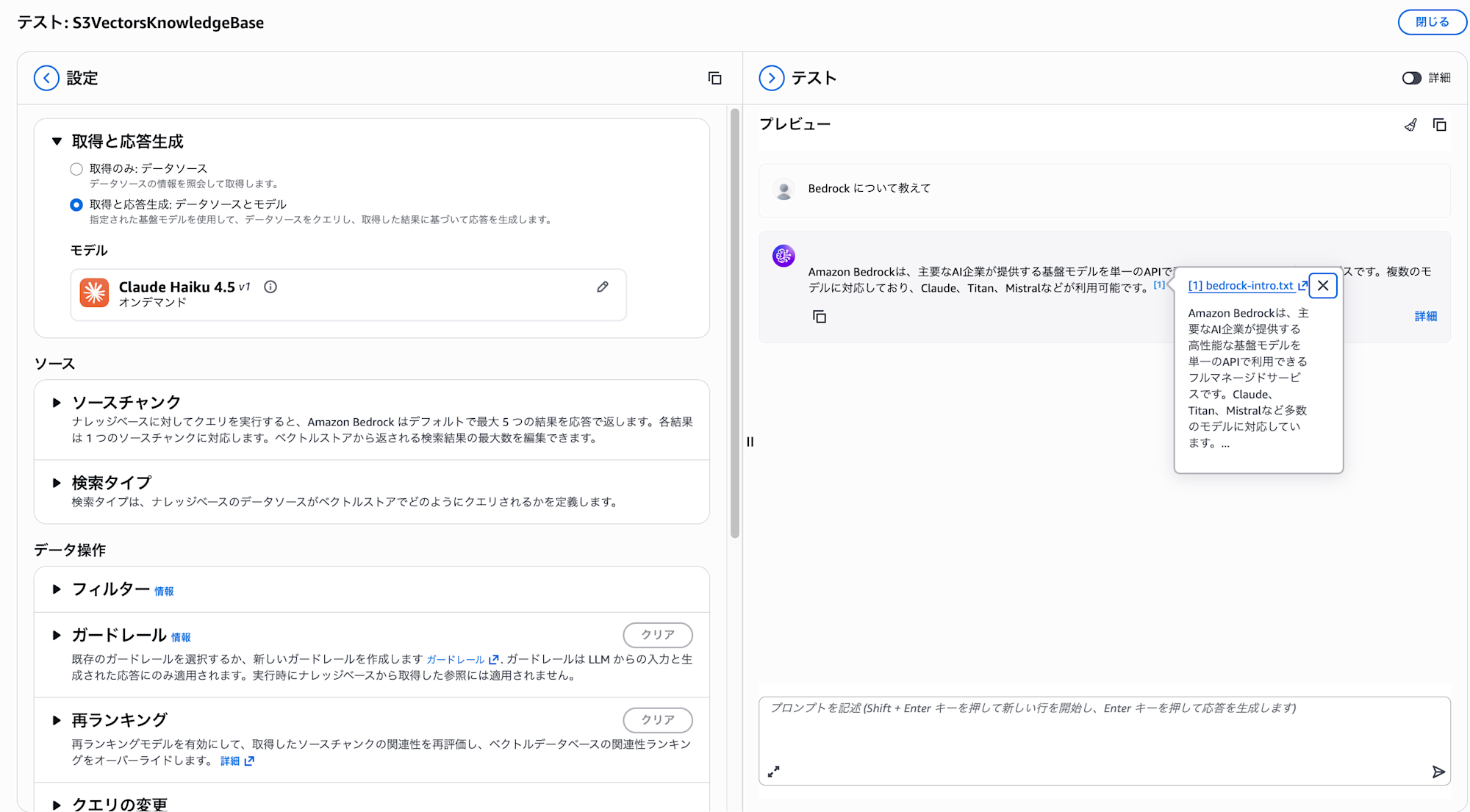
更新された内容が取得されていますね!
ドキュメントの削除(Delete)
次はドキュメントを削除する場合を確認してみます。
ドキュメントの削除には DeleteKnowledgeBaseDocuments APIを使用します。
aws bedrock-agent delete-knowledge-base-documents \
--knowledge-base-id "$KB_ID" \
--data-source-id "$DS_ID" \
--document-identifiers '[
{
"dataSourceType": "S3",
"s3": {
"uri": "s3://'"${BUCKET_NAME}"'/documents/bedrock-intro.txt"
}
}
]'
{
"documentDetails": [
{
"knowledgeBaseId": "XXXXXXXXXX",
"dataSourceId": "YYYYYYYYYY",
"status": "DELETING",
"identifier": {
"dataSourceType": "S3",
"s3": {
"uri": "s3://kb-datasource-123456789012-us-west-2/documents/bedrock-intro.txt"
}
},
"updatedAt": "2026-01-25T12:42:47.503248+00:00"
}
]
}
削除処理が開始されました。削除も非同期で処理されるため、DELETINGステータスを経て削除が完了します。
ただ、直接取り込みでKnowledge Basesから削除しても、S3バケット上のファイルは削除されません。
次回の同期ジョブ実行時に再度取り込まれてしまうため、S3バケット側のファイルも削除する必要があるので注意しましょう。整合性を保つことは意識したいポイントですね。
こちらも動作確認してみます。
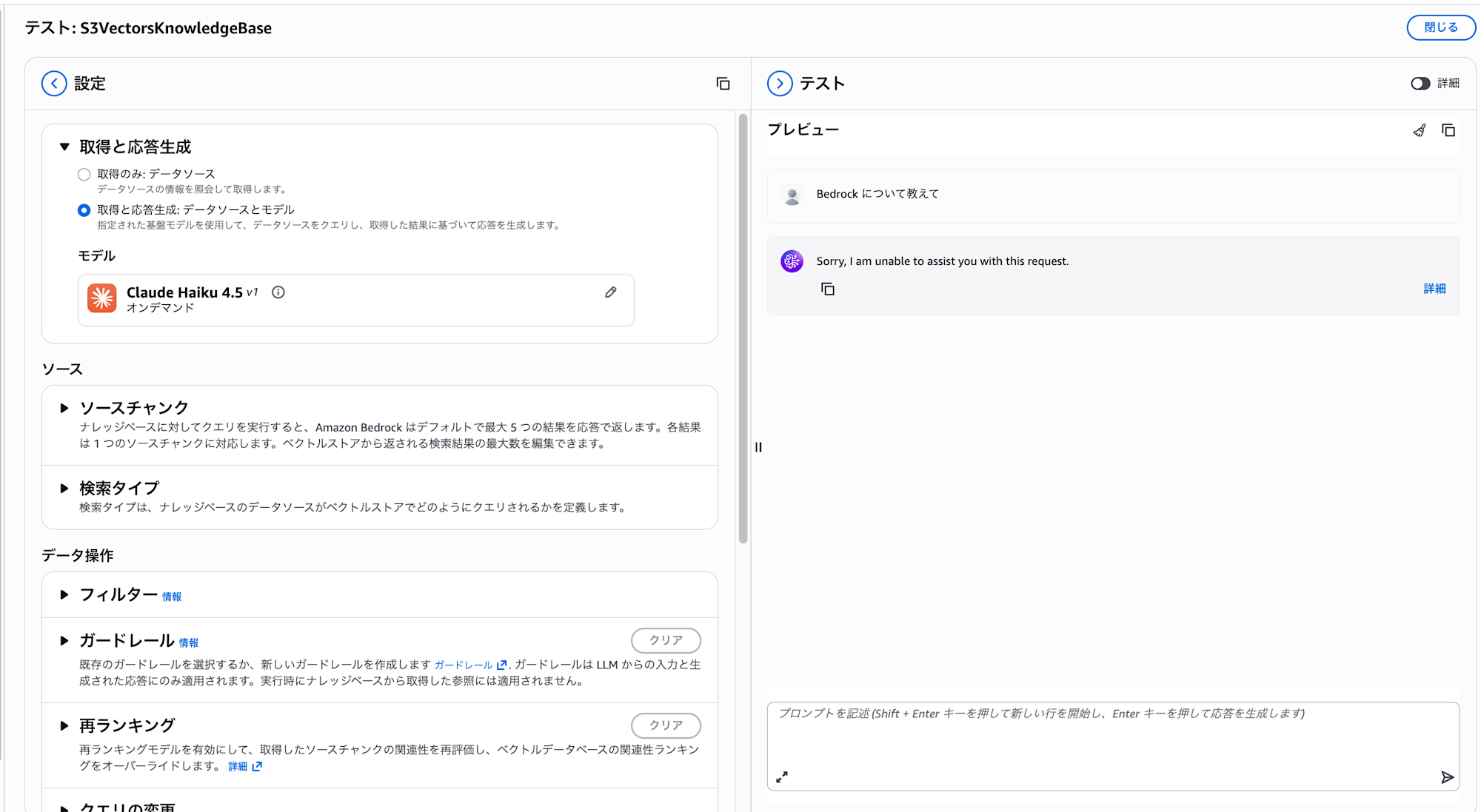
何も同期されているドキュメントがなくなったので回答できなくなりましたね。予想通りです。
複数ドキュメントの一括処理
1回のAPIコールでコンソールからは10件、APIからは25件のドキュメントを一括処理できます。
まずは複数のドキュメントをS3にアップロードします。
echo "AWS Lambdaはサーバーレスコンピューティングサービスです。" > lambda.txt
echo "Amazon S3はオブジェクトストレージサービスです。" > s3.txt
echo "Amazon DynamoDBはフルマネージドNoSQLデータベースです。" > dynamodb.txt
aws s3 cp lambda.txt s3://${BUCKET_NAME}/documents/
aws s3 cp s3.txt s3://${BUCKET_NAME}/documents/
aws s3 cp dynamodb.txt s3://${BUCKET_NAME}/documents/
アップロード後は単一ファイルをアップロードした時と同様にingest-knowledge-base-documentsを実行します。
配列内に複数ファイルを指定するだけなのでシンプルですね。
aws bedrock-agent ingest-knowledge-base-documents \
--knowledge-base-id "$KB_ID" \
--data-source-id "$DS_ID" \
--documents '[
{
"content": {
"dataSourceType": "S3",
"s3": {
"s3Location": {
"uri": "s3://'"${BUCKET_NAME}"'/documents/lambda.txt"
}
}
}
},
{
"content": {
"dataSourceType": "S3",
"s3": {
"s3Location": {
"uri": "s3://'"${BUCKET_NAME}"'/documents/s3.txt"
}
}
}
},
{
"content": {
"dataSourceType": "S3",
"s3": {
"s3Location": {
"uri": "s3://'"${BUCKET_NAME}"'/documents/dynamodb.txt"
}
}
}
}
]'
実行すると複数のステータスが返却されます。
{
"documentDetails": [
{
"knowledgeBaseId": "XXXXXXXXXX",
"dataSourceId": "YYYYYYYYYY",
"status": "STARTING",
"identifier": {
"dataSourceType": "S3",
"s3": {
"uri": "s3://kb-datasource-123456789012-us-west-2/documents/lambda.txt"
}
},
"updatedAt": "2026-01-25T12:46:42.231326+00:00"
},
{
"knowledgeBaseId": "XXXXXXXXXX",
"dataSourceId": "YYYYYYYYYY",
"status": "STARTING",
"identifier": {
"dataSourceType": "S3",
"s3": {
"uri": "s3://kb-datasource-123456789012-us-west-2/documents/s3.txt"
}
},
"updatedAt": "2026-01-25T12:46:42.252964+00:00"
},
{
"knowledgeBaseId": "XXXXXXXXXX",
"dataSourceId": "YYYYYYYYYY",
"status": "STARTING",
"identifier": {
"dataSourceType": "S3",
"s3": {
"uri": "s3://kb-datasource-123456789012-us-west-2/documents/dynamodb.txt"
}
},
"updatedAt": "2026-01-25T12:46:42.275428+00:00"
}
]
}
試しにLambda について教えてと聞いてみます。
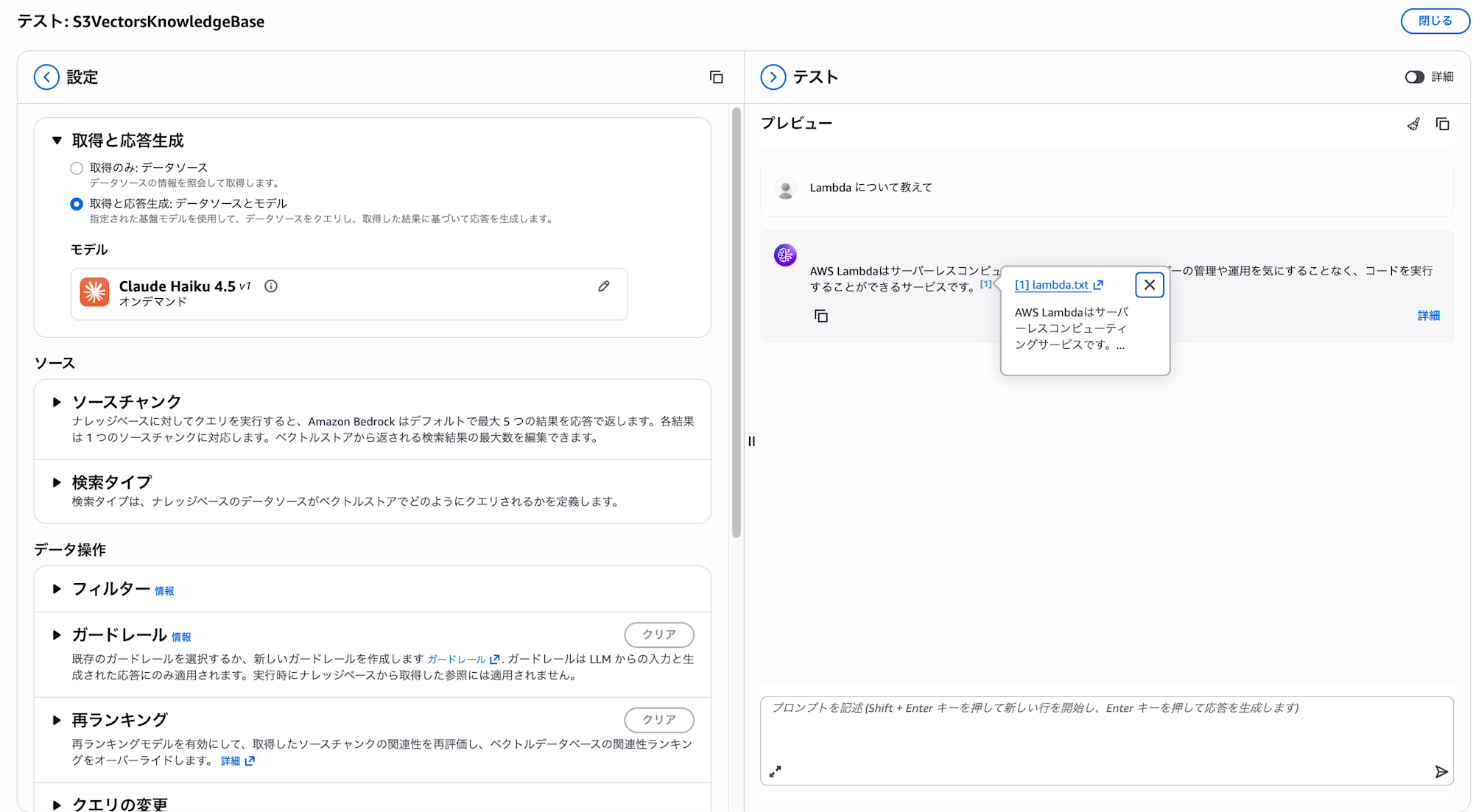
複数ファイルをアップロードした場合でも問題なく取り込まれていますね!
clientTokenによる冪等性の保証
アプリケーションに直接取り込み処理を組み込む際、ネットワークエラーやタイムアウトが発生したとき、リトライ処理を実装することが多いですよね。
しかし、リトライ時に実は最初のリクエストは成功していたというケースでは、同じドキュメントが重複して処理されてしまう可能性があります。
こういった問題を防ぐために、clientTokenパラメータが用意されています。
試しにファイルを作成してアップロードしてみます。
echo "Amazon CloudWatchはAWSリソースの監視サービスです。" > cloudwatch.txt
aws s3 cp cloudwatch.txt s3://${BUCKET_NAME}/documents/
clientTokenを指定して直接取り込みを実行します。
aws bedrock-agent ingest-knowledge-base-documents \
--knowledge-base-id "$KB_ID" \
--data-source-id "$DS_ID" \
--client-token "user123-cloudwatch-20260125124500" \
--documents '[
{
"content": {
"dataSourceType": "S3",
"s3": {
"s3Location": {
"uri": "s3://'"${BUCKET_NAME}"'/documents/cloudwatch.txt"
}
}
}
}
]'
連続でこのリクエストを送ると下記のようにレスポンスが返却されて、ステータスがSTARTINGではなくIN_PROGRESSとなっていますね。
{
"documentDetails": [
{
"knowledgeBaseId": "XXXXXXXXXX",
"dataSourceId": "YYYYYYYYYY",
"status": "IN_PROGRESS",
"identifier": {
"dataSourceType": "S3",
"s3": {
"uri": "s3://kb-datasource-123456789012-us-west-2/documents/cloudwatch.txt"
}
},
"statusReason": "",
"updatedAt": "2026-01-25T13:01:11.857718+00:00"
}
]
}
同じclientTokenでリクエストを送信すると、最初の1回だけが処理され、2回目以降は重複実行されません。
例えば、ユーザーがドキュメントをアップロードするAPIを実装する場合、ユーザーID + ファイル名 + タイムスタンプのような組み合わせでユニークなトークンを生成しておくと、リトライ時も安心ですね。
| パラメータ | 説明 |
|---|---|
clientToken |
33〜256文字のユニークな文字列。同じトークンでのリクエストは冪等になる |
メタデータの付与について
S3データソースでは、メタデータの指定方法に制限があります。
リクエストのボディにインラインでメタデータを指定はできません。
| データソースタイプ | インライン指定 | S3 location指定 |
|---|---|---|
| CUSTOM | ○ | ○ |
| S3 | × | ○ |
直接取り込みでもS3データソースでメタデータを付与したい場合は、メタデータファイル(.metadata.json)をS3にアップロードし、metadata.typeをS3_LOCATIONに設定およびURIを指定します。
試しに実行してみます。まずはメタデータを作成して、S3にアップロードします。
cat << 'EOF' > bedrock-intro.txt.metadata.json
{
"metadataAttributes": {
"category": "aws-service",
"year": 2023
}
}
EOF
aws s3 cp bedrock-intro.txt.metadata.json s3://${BUCKET_NAME}/documents/
アップロードが完了したら、メタデータも取り込むようにパラメータを指定します。
aws bedrock-agent ingest-knowledge-base-documents \
--knowledge-base-id "$KB_ID" \
--data-source-id "$DS_ID" \
--documents '[
{
"content": {
"dataSourceType": "S3",
"s3": {
"s3Location": {
"uri": "s3://'"${BUCKET_NAME}"'/documents/bedrock-intro.txt"
}
}
},
"metadata": {
"type": "S3_LOCATION",
"s3Location": {
"uri": "s3://'"${BUCKET_NAME}"'/documents/bedrock-intro.txt.metadata.json"
}
}
}
]'
レスポンスも確認します。
{
"documentDetails": [
{
"knowledgeBaseId": "XXXXXXXXXX",
"dataSourceId": "YYYYYYYYYY",
"status": "STARTING",
"identifier": {
"dataSourceType": "S3",
"s3": {
"uri": "s3://kb-datasource-123456789012-us-west-2/documents/bedrock-intro.txt"
}
},
"updatedAt": "2026-01-25T13:14:29.316549+00:00"
}
]
}
レスポンス上は特にメタデータが付与されたかどうかはわかりませんね。
試しにメタデータでフィルタリングして検索してみます。
retrieveコマンドの--retrieval-configurationでフィルタ条件を指定できます。
categoryがaws-serviceのドキュメントだけに絞って検索してみます。
aws bedrock-agent-runtime retrieve \
--knowledge-base-id "$KB_ID" \
--retrieval-query '{"text": "AWSサービスについて教えて"}' \
--retrieval-configuration '{
"vectorSearchConfiguration": {
"filter": {
"equals": {
"key": "category",
"value": "aws-service"
}
}
}
}'
実行結果を確認してみます。
{
"retrievalResults": [
{
"content": {
"text": "Amazon Bedrockは、主要なAI企業が提供する高性能な基盤モデルを単一のAPIで利用できるフルマネージドサービスです。Claude、Titan、Mistralなど多数のモデルに対応しています。",
"type": "TEXT"
},
"location": {
"s3Location": {
"uri": "s3://kb-datasource-123456789012-us-west-2/documents/bedrock-intro.txt"
},
"type": "S3"
},
"metadata": {
"x-amz-bedrock-kb-source-file-modality": "TEXT",
"category": "aws-service",
"year": 2023.0,
"x-amz-bedrock-kb-chunk-id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"x-amz-bedrock-kb-data-source-id": "YYYYYYYYYY"
},
"score": 0.592372715473175
}
],
"guardrailAction": null
}
先ほど付与したメタデータが反映されて取得できていますね!
yearが2024だと検索に引っかからないかも確認してみます。
aws bedrock-agent-runtime retrieve \
--knowledge-base-id "$KB_ID" \
--retrieval-query '{"text": "AWSサービスについて教えて"}' \
--retrieval-configuration '{
"vectorSearchConfiguration": {
"filter": {
"equals": {
"key": "year",
"value": "2024"
}
}
}
}'
実行結果を確認してみます。
{
"retrievalResults": [],
"guardrailAction": null
}
何も取得されていませんね!メタデータフィルタリングがされているのを確認できました。
S3データソースで直接取り込みを使う際の注意点
S3データソースで直接取り込みを使用する場合、Knowledge Basesからドキュメントを削除しても、S3上のファイルは自動削除されず、次回の同期ジョブ実行時にS3バケットの状態で上書きされる点にも注意が必要です。
S3とKnowledge Basesは自動同期しないため、両者の整合性を保つにはS3バケット上のファイルを追加・更新・削除した後、直接取り込みAPIで即座にKnowledge Basesに反映するというワークフローを意識する必要があります。エラーなどが起きたらロールバックして整合性を担保するような仕組みも考えておいた方が良いですね。
おわりに
S3データソースを使った直接取り込みは、S3とKnowledge Basesの整合性を意識する必要がありますが、同期ジョブを待つことなく即座にドキュメントを反映できるのは良いですね。
特にリアルタイム性が求められるRAGアプリケーションや、頻繁にドキュメントが更新されるユースケースで活躍しそうです。私も直近で使いたいケースがあったのでアプリケーションに組み込んでみようと思います。
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございましたー!!









