
【いまさら聞けない】Amazon Bedrock Knowledge BasesでRAG環境を構築する手順
はじめに
こんにちは!AI事業本部のこーすけです。10月から新規事業統括部からAI事業本部に箱が変わりました。
今回はBedrockのナレッジベースでRAGを使えるようになるまでの手順を改めて整理してみます。
前提
LLM(Large Language Model) は大量のテキストデータを学習した言語モデルのことです。一般的な事柄であれば私たちの質問に対して十分納得感のある回答を返してくれます。
しかし、LLMは学習したデータに含まれない事柄については正しく回答することができません。モデルは学習時点以降の世の中の出来事については知り得ませんから、今日の天気は教えてくれませんし、学習データ以外の情報は知り得ませんから、あなたが社内独自の手続きについて聞いたとしてもLLMにとっては「知らないこと」なので答えようがないのです。
この課題へのアプローチとして現在主流なのが、RAG(Retrieval Augmented Generation) という手法です。
これは、LLMに社内ドキュメントなどの外部知識を連携させる手法です。
イメージとしては、「テストに教科書を持ち込む」 ようなものです。
何も持たずに自分の記憶(学習データ)だけで答えるのではなく、手元の教科書(社内ドキュメント)から必要なページを探してカンニングしながら答えることで、LLMが本来「知らないこと」でも正確に回答できるようになります。
具体的には、以下のステップを踏むことでこれを実現します。
- 検索(Retrieve): ユーザーの質問に関連する情報を、ドキュメントの中から探し出す。
- 取得(Augment): 見つけた情報を取得し、プロンプトに参考情報として組み込む。
- 生成(Generate): LLMがその情報を元に回答を作成する。
これにより、ユーザーは事実に基づいた回答を得られるだけでなく、参照元(ソース)も確認できるため、情報の信頼性を容易に検証することができます。
AWS Bedrockで実現するRAG構成
RAGをゼロから構築しようとすると、ドキュメントのテキスト分割(チャンキング)、ベクトル化、ベクトルデータベースの構築・管理、そして検索ロジックの実装など、かなり多くの工数がかかります。
そこで今回は、これらの複雑なパイプラインをマネージドサービスとしてまるっと提供してくれる Amazon Bedrock Knowledge Bases を利用して、クイックにRAG環境を構築します。
今回使用するサービスと構成
Amazon Bedrock Knowledge Basesは柔軟性が高く、データソースにはWebサイト(クローラー)やConfluence、Salesforceなどを指定できたり、ベクトルストアにはAmazon Aurora PostgreSQLやPinecone、Redis Enterprise Cloudなどを選択できたりと、要件に合わせて様々な構成が組めるのが特徴です。
今回は標準的かつAWS環境だけで完結する以下の構成を採用しました。
- Amazon Bedrock Knowledge Bases
RAGのオーケストレーター的な役割です。データソースの同期から、ユーザーの質問に基づく検索、そしてLLMへの回答生成指示までを一元管理します。 - Amazon S3 (Data Source)
RAGで検索対象としたいドキュメント(PDFなど)を格納する場所です。 - Amazon OpenSearch Serverless (Vector Store)
ドキュメントの内容をベクトル化して保存しておくデータベースです。今回はナレッジベースのコンソールから作成することで、ユーザー側での複雑なセットアップを省略できる構成をとります。
ここで少しわき道にそれますが、RAGの構成を考える際、データの検索方法として 「ベクトル検索」 がよく使われます。
従来の「キーワード検索」は、単語が完全に一致しないとヒットしませんが、「ベクトル検索」は文章の意味を数値(ベクトル)に変換して計算するため、「言葉が違っても意味が近い情報」を探し出すことができます。
例えば、「PCが動かない」と検索した際、キーワード検索では「パソコン」「起動しない」といった言葉を含む文書は見つけにくいですが、ベクトル検索なら「意味が近い」としてこれらをヒットさせることができます。これを行うために必要なデータベースが 「ベクトルストア(Vector Store)」 です。
各サービス間の関係と、RAGを実施するまでに行われていることを以下に整理します。

【データの準備フェーズ(青線)】
① Data Sync: S3上のドキュメントをナレッジベースが読み込みます。
② Vectorize & Store: ナレッジベースがテキストを分割・ベクトル化(埋め込み)し、OpenSearch Serverlessに保存します。
【回答の生成フェーズ(赤線)】
③ Question: ユーザーが質問を投げます。
④ Vector Search: ナレッジベースが質問文をベクトル化し、OpenSearch Serverlessに対して類似検索を行います。
⑤ Relevant Info (Chunks): 検索の結果、関連性の高いドキュメントの断片(チャンク)がナレッジベースに返されます。
⑥ Prompt + Context: ナレッジベースが、「ユーザーの質問」と「検索された情報(Context)」を組み合わせてプロンプトを作成し、LLM(Claudeなど指定したモデル)に渡します。
⑦ Answer: LLMが生成した回答がユーザーに返されます。
データの準備フェーズ
1. ドキュメントデータの準備とS3バケットの作成
まずはRAGとして参照したいデータを準備します。せっかくなのでAWSの勉強もできたらと思い、AWSの公式ドキュメントのpdfをダウンロードして使いました。
今回はDynamoDBのデベロッパーガイドを使用することにします。3866ページとあまりに膨大だったため冒頭100ページを切り出して使用しました。
ここで注意ですが、pdfがスキャンされた画像ベースのものである場合、Bedrockがテキストを読み取ることができず、ベクトル化に失敗してしまいます。
PDFリーダーでファイルを開き、テキストを選択できるか確認すると確実かもしれません。
ファイルはs3に格納するだけで大丈夫ですが、バケットはナレッジベースと同じリージョンにある必要があります。後でナレッジベースのデータソースにこのs3バケットを指定するので、右上の「S3 URI をコピー」をクリックしてURIを控えておくと便利です。
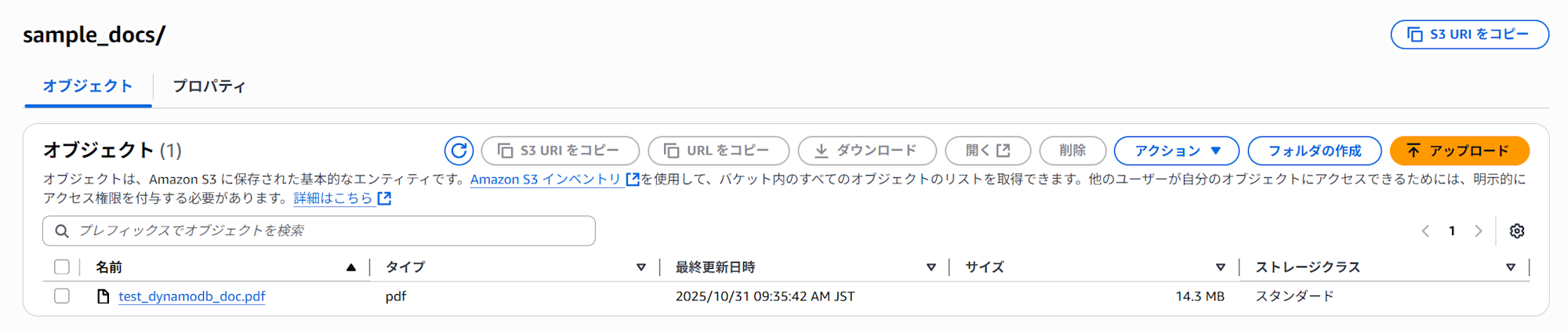
バケットは、Amazon Bedrock ナレッジベースと同じリージョンにある必要があります。
2. Bedrock Knowledge basesの作成
1.ナレッジベースを利用するにはBedrockから左メニューバーの「ナレッジベース」をクリックします。

2. 右下の「作成」から「ベクトルストアを含むナレッジベース」を選択します。
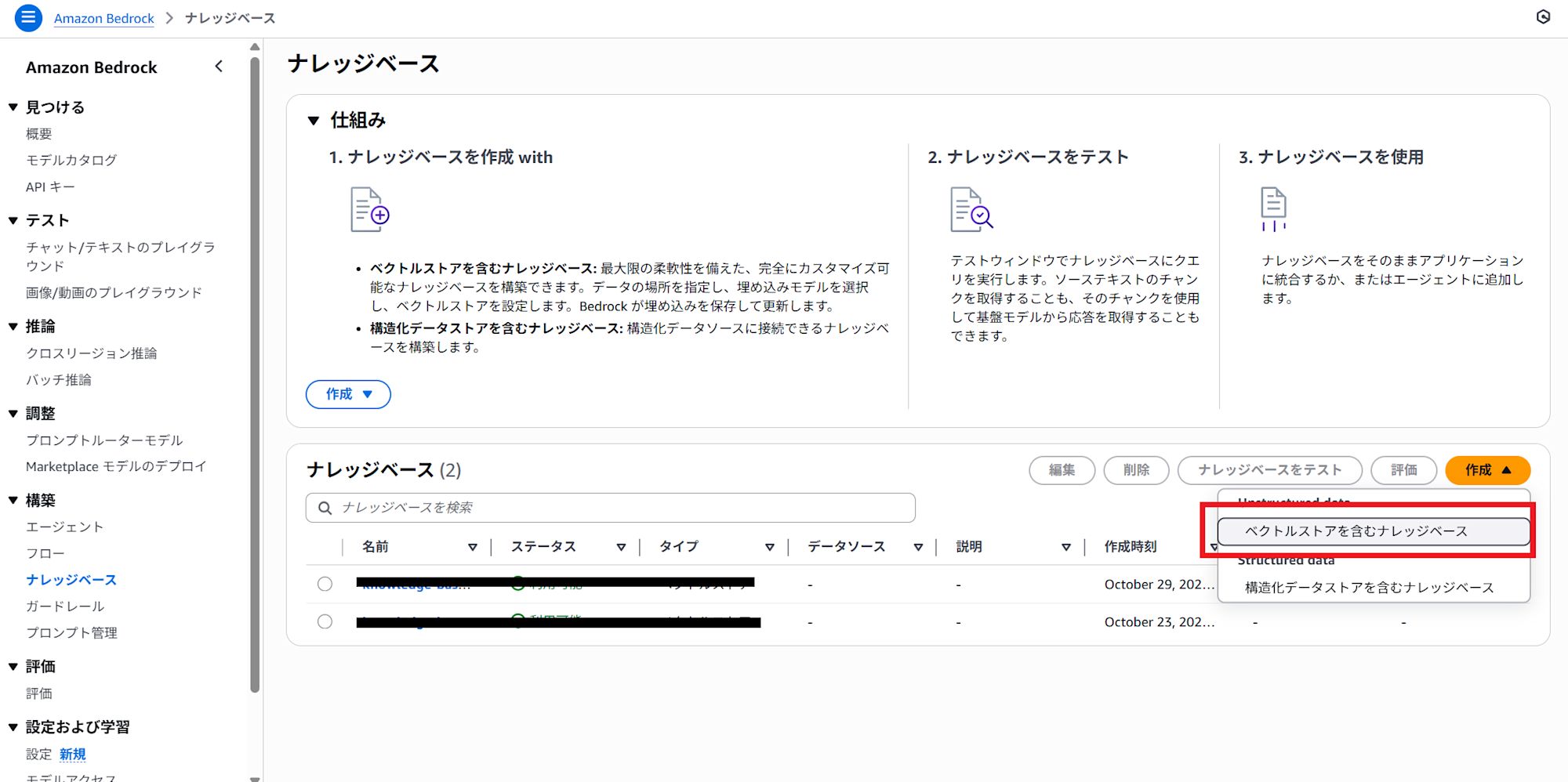
3. 遷移後の画面はこちらになります。
今回はデフォルト設定のまま、データソースはS3を指定します。
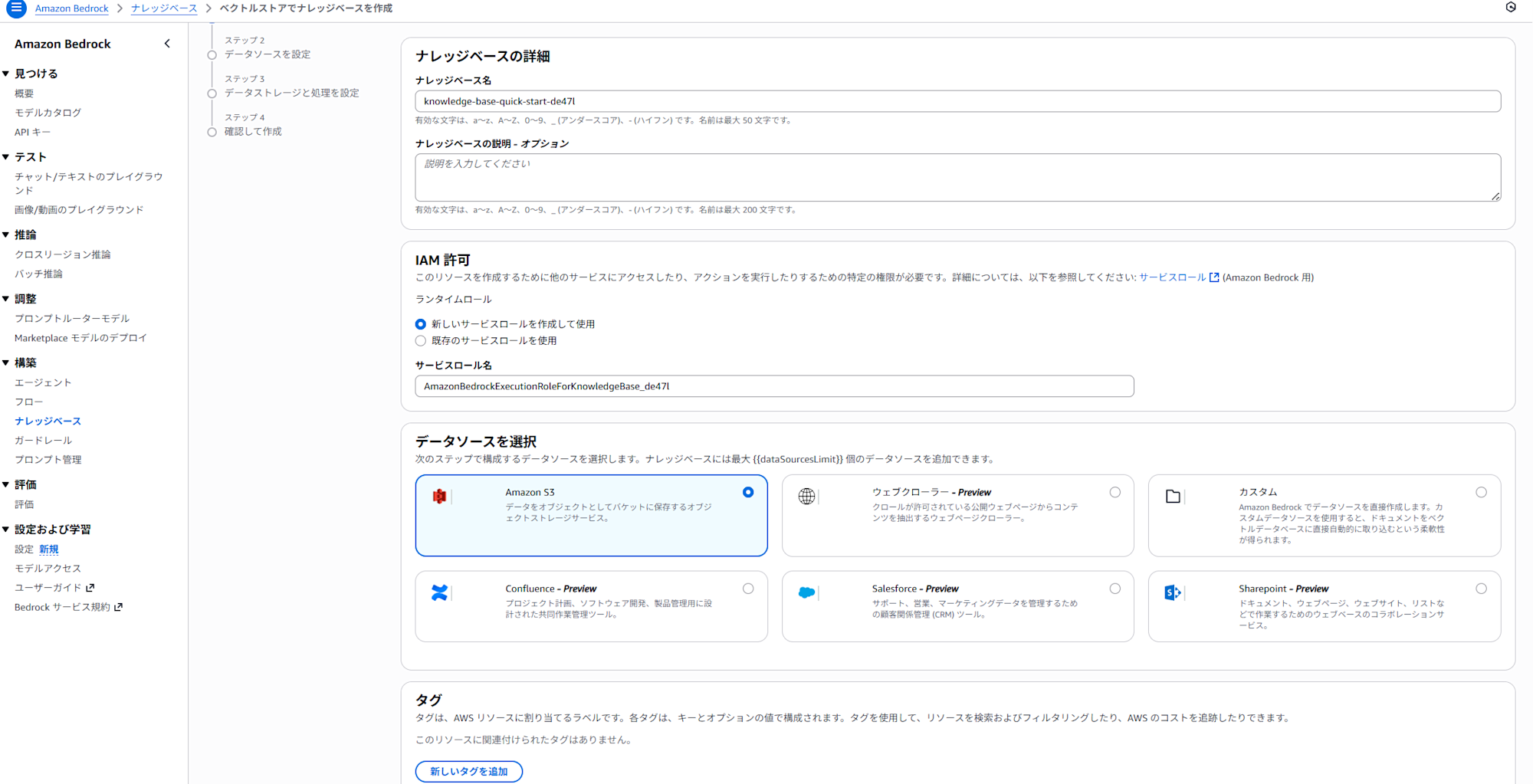
4. データソースの設定画面に遷移します。
S3のURLに先ほどコピーしたURLを指定するか、「S3を参照」をクリックし該当のリソースを指定します。その他はデフォルト設定のままにします。

5. ベクトルデータベースの設定画面に遷移します。
ベクトル化を行う埋め込みモデルと、ベクトルストアの選択を行います。今回はAmazon OpenSearch Serverlessを指定します。これにより、Amazon BedrockがバックエンドでOpenSearch Serverlessのベクトルエンジンを自動的に作成・設定します。自動で作成してくれるのでとても便利です。
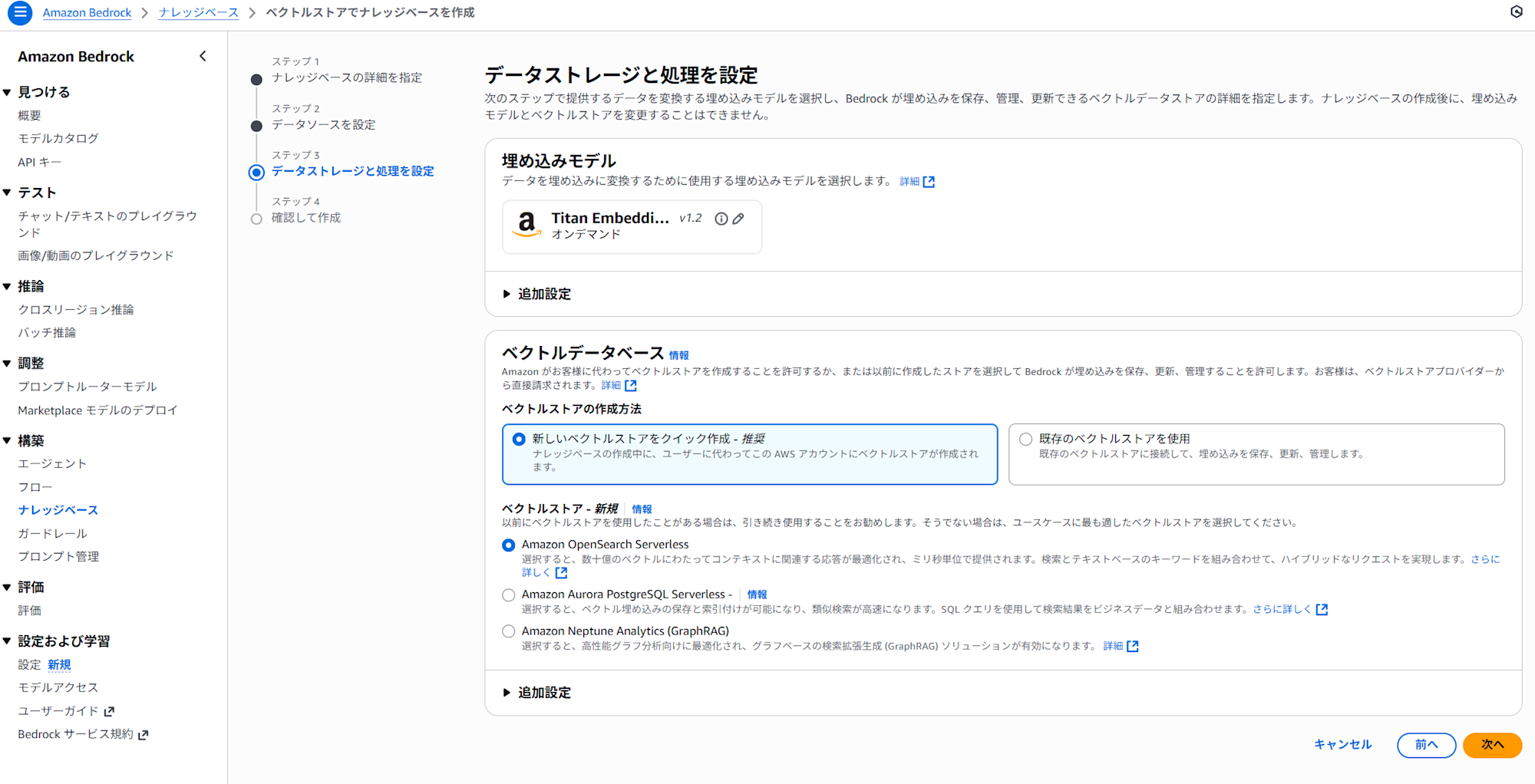
埋め込みモデルには「Titan Embeddings G1 - Text」を指定しました。
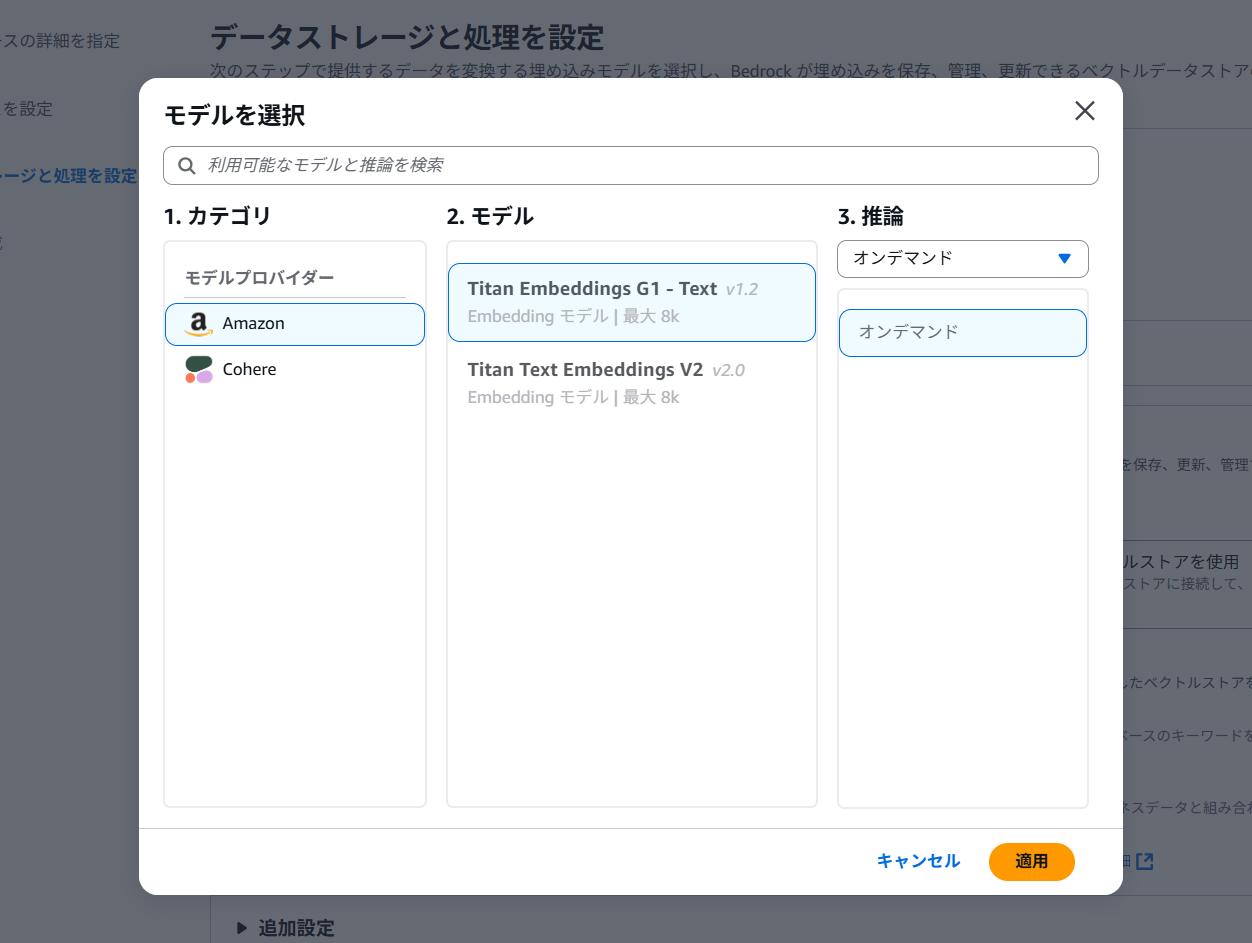
確認画面が表示されるので「ナレッジベースを作成」をクリックし、作成を行います。
6.作成されたナレッジベースを選択し、「同期」を押すことで、埋め込みが生成され、ベクトルがOpenSearch Serverlessに格納されます。S3バケットに入れているドキュメント量によっては数分から数時間待つ必要があります。

回答の生成フェーズ
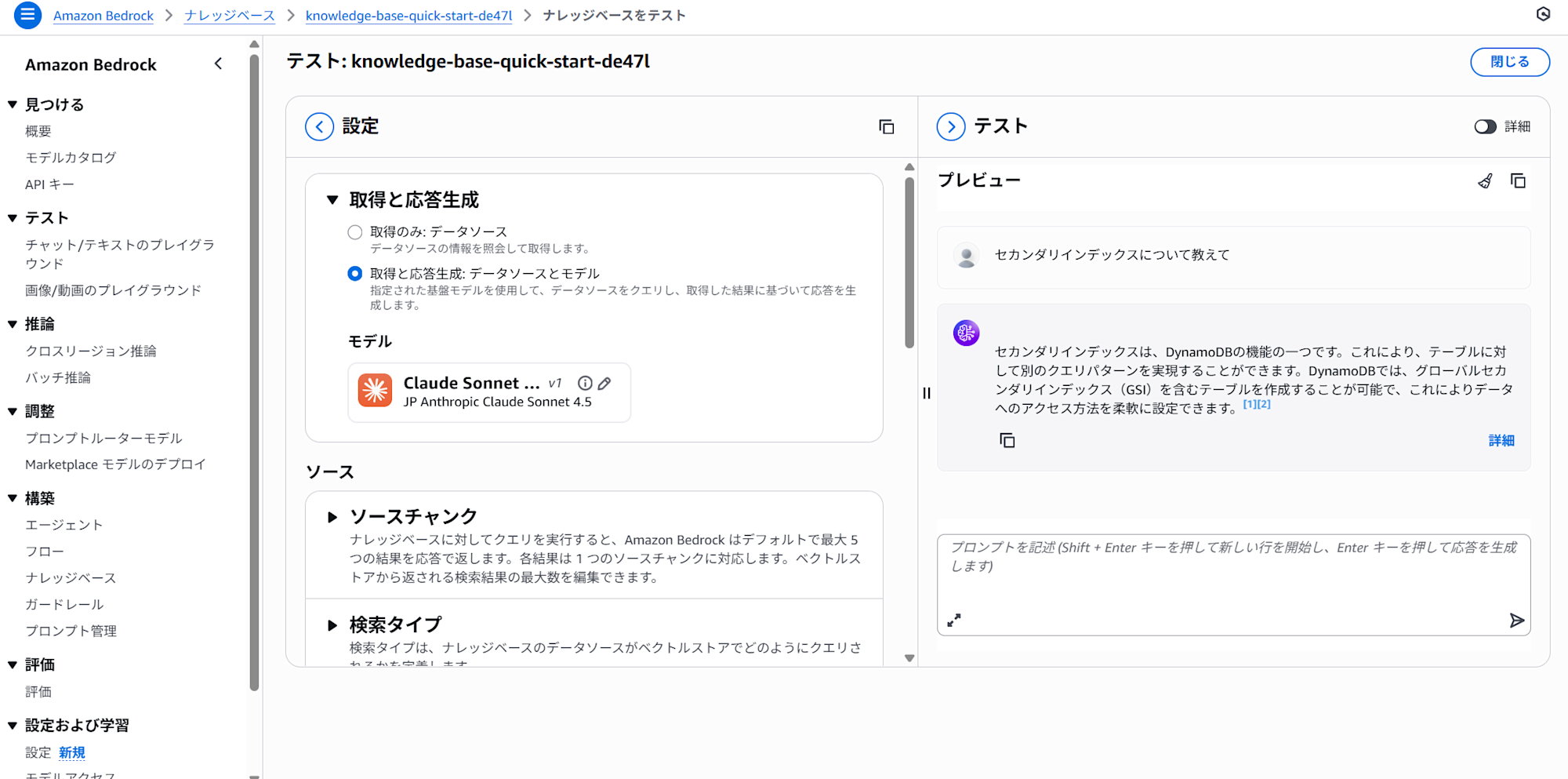
さっそくコンソールから触ってみます。右上の「ナレッジベースをテスト」をクリックし、画面中央の「取得と応答生成」 > 「モデル」の欄から使用するLLMを選択します。今回は「Claude Sonnet 4.5」を選択しました。

ご覧の通り、データソースを取得し回答生成まで行えることを確認しました。
おわりに
今回は、Amazon Bedrock Knowledge Basesを使って、RAG環境を構築する手順を整理しました。
最後まで読んでいただきありがとうございました!









