
Amazon Bedrock에서 Text-To-SQL을 활용해 데이터 분석하기
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
자연어로 SQL을 만들어 데이터를 습득할 수 있게 만드는 시스템을 PoC 해본 내용을 공유합니다.
데이터를 분석하려할 때 시간이 걸리는 일 중 하나는 SQL 작성입니다.
물론 잘 만들어진 UI 기반의 대시보드로 SQL을 알 필요 없이 데이터를 확인하는 것도 가능합니다.
하지만, 복잡하거나 시스템이 없거나, 로우한 데이터를 처리하고 보여주려면 사람이 직접 SQL을 작성하고 실행해서 확인하는 작업이 필요할 때도 있게 됩니다.
SQL을 잘 모르는 사람이 해당 작업을 하려면 SQL 작성법을 배워야 하거나 잘 아는 사람에게 도움을 받아야 합니다.
위와 같은 점들을 고려해서, SQL을 몰라도 사람의 언어로 데이터를 확인할 수 있으면 얼마나 좋을까요?
이러한 생각들이 모여서 생긴게 바로 Text-To-SQL이라는 개념입니다.
Text-To-SQL
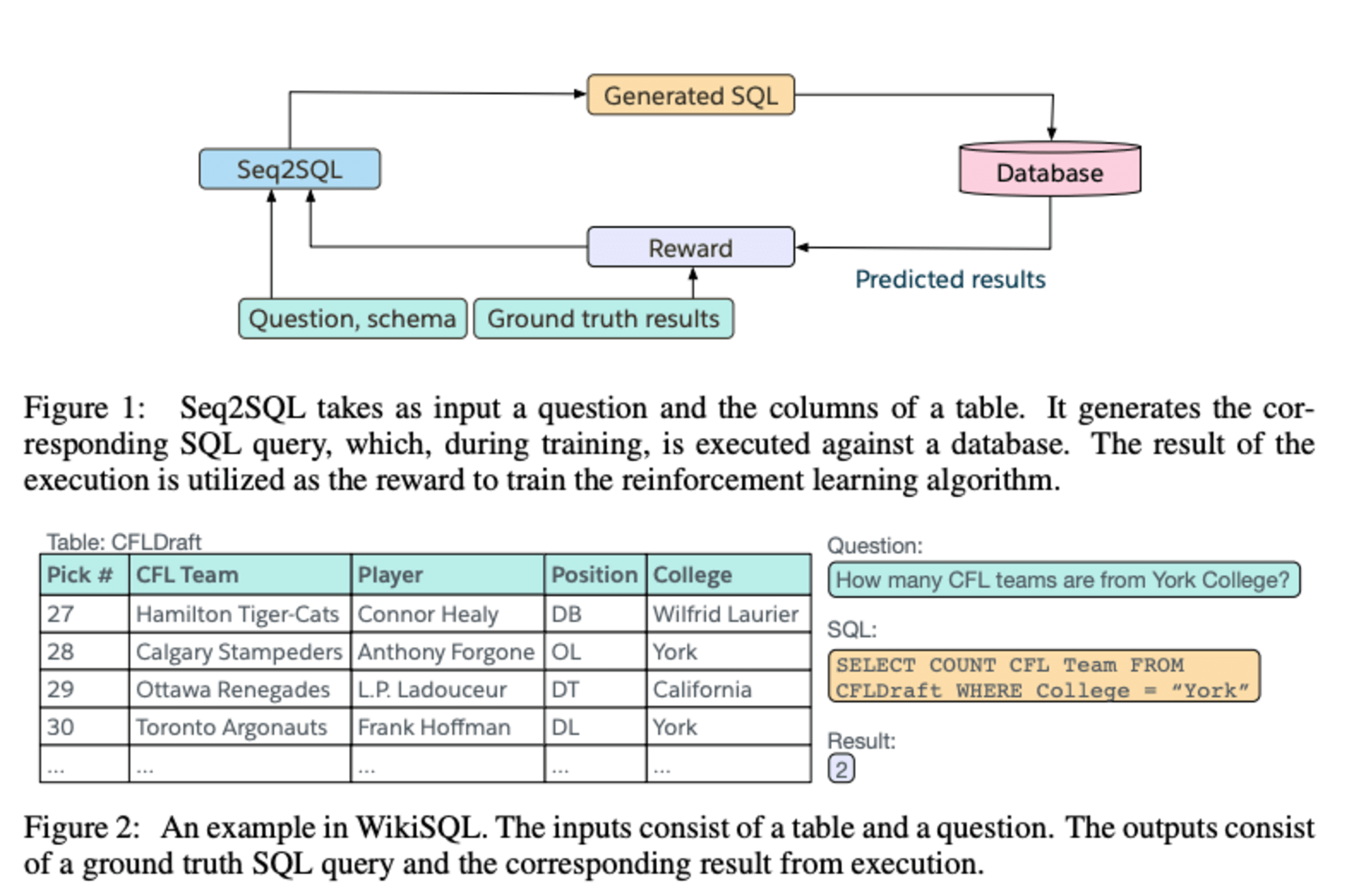
SEQ2SQL: GENERATING STRUCTURED QUERIES
FROM NATURAL LANGUAGE USING REINFORCEMENT
LEARNING
Salesforce에서 2017년에 SEQ2SQL 이라는 키워드를 가진 논문을 하나 내게 됩니다.
이 논문에서는 사람이 사용하는 자연어로 SQL을 만드는 방법을 제시하고, 실제 모델이 얼마나 그걸 수행해내는지 알아내게 됩니다.
하지만 우리는 GPT가 나온 이후, 범용적인 자연어 모델을 사용할 수 있게 되었습니다. 자연어로 SQL을 만드는 SEQ2SQL에서, 요즘은 Text-To-SQL이라고 불리우는, 개념을 통해 일반적인 LLM 모델에서도 자연어로 SQL을 만드는 것이 가능해졌습니다.
그럼 실제로 한번 자연어를 통해 SQL이 만들어지는 과정을 알아봅시다.
시스템 구성
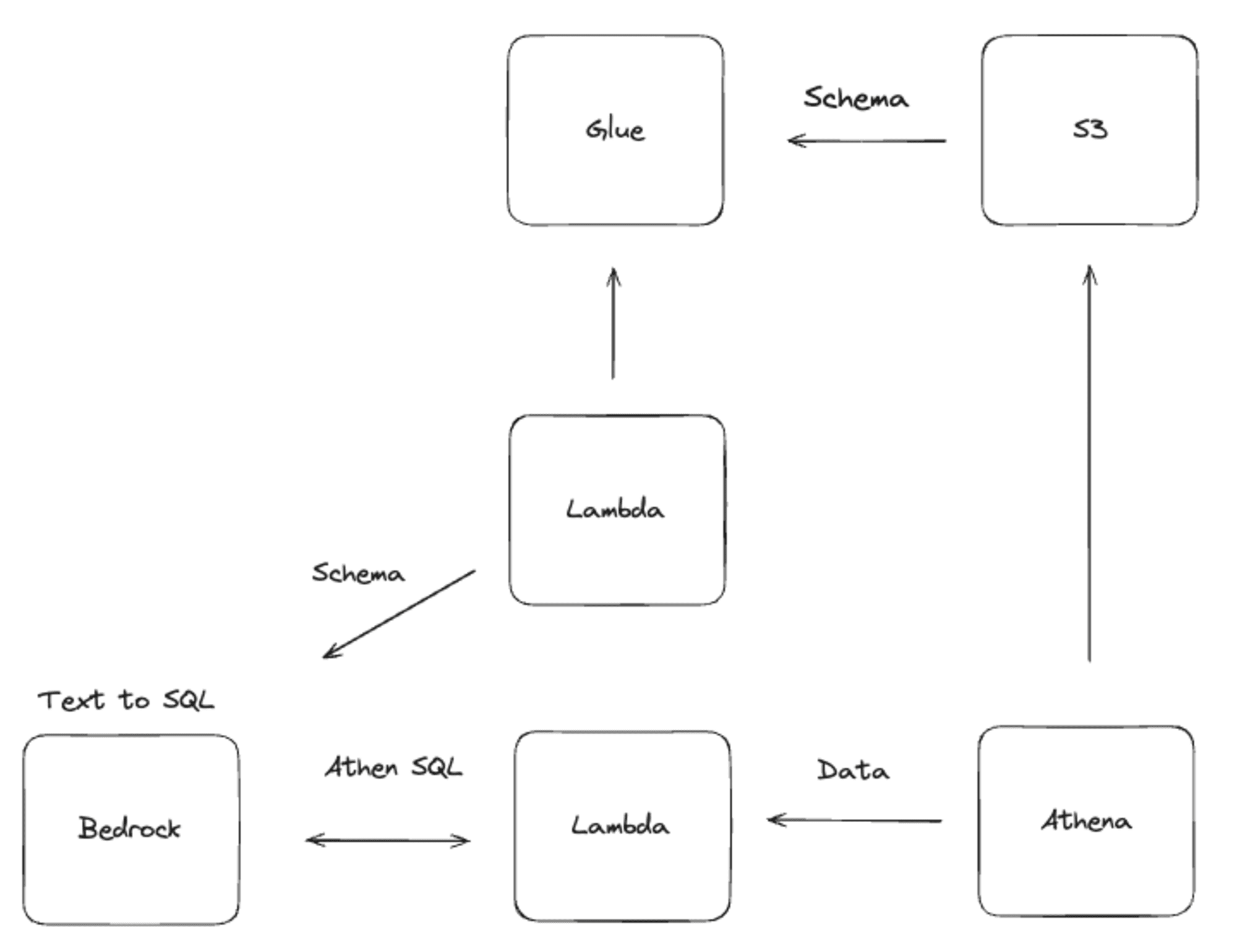
자연어를 통해 SQL을 만드는 것은 LLM에 SQL을 만들어달라고 하면 됩니다.
하지만, 사용중인 데이터를 가져오는 SQL을 만드려면 어떻게 해야할까요?
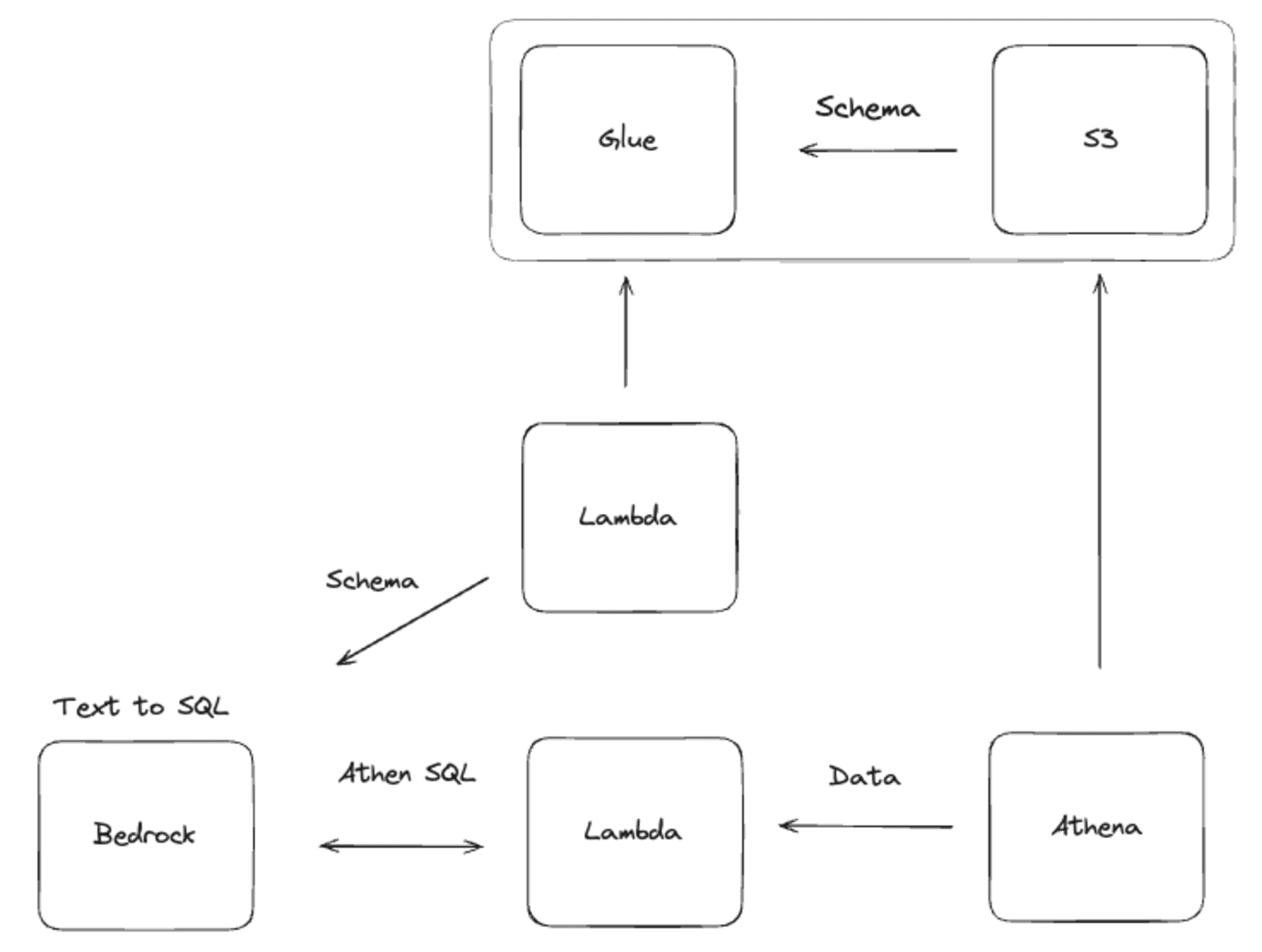
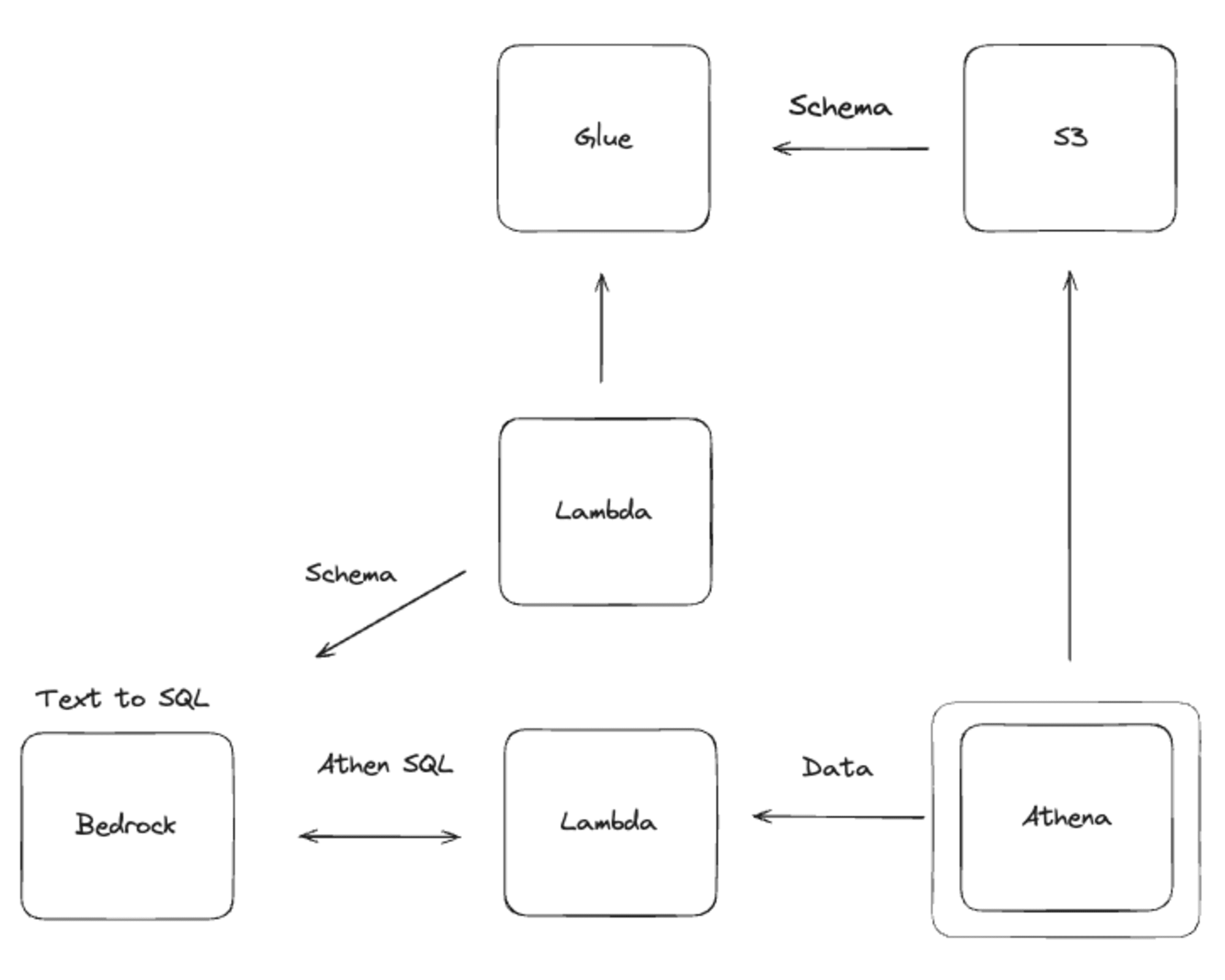
저는 Amazon S3에 데이터가 있다고 가정하고 자연어로 Amazon S3의 데이터를 확인하는 방법을 만들어봤습니다.
위의 그림에서 Bedrock(Amazon Bedrock)이 유저가 입력을 하는 부분입니다. 실제로는 streamlit으로 따로 채팅 페이지를 만들거나 슬랙같이 사용자가 기존에 사용하던 방법등으로 제공하는게 좋지만, PoC 적 관점에서 일단 Bedrock도 채팅을 사용할 수 있기 때문에 사용해보겠습니다.
Amazon Bedrock 에 대해 알고 싶으시다면 위의 글을 확인해주세요.
전체적인 흐름은 Amazon Bedrock의 Prompt Flows를 사용해보겠습니다. Prompt Flows는 LLM이 채팅을 넘어서 실제로 외부 세상에 동작을 수행시켜주는 일련의 과정을 만드는 기능입니다. Prompt Flows에 대해 알고 싶으시다면 위의 글을 확인해주세요.
Amazon S3의 데이터를 가져오기 위해 첫 번째로 할일은 사용자의 요청을 통해 SQL을 만들기 위해 스키마를 알아오는 것입니다.
사용자가 채팅을 입력하면 AWS Lambda에서 AWS Glue Crawler가 만들어둔 스키마와 DB, Table 정보를 가져올겁니다. 그리고 이 정보들과 사용자의 요청을 섞어서 LLM을 통해 SQL을 만들게 됩니다.
여기까지 자연어를 통해 SQL을 만들긴 했지만, 실제로 데이터를 가져오지는 못 했습니다. 그래서 우리는 만들어진 SQL로 데이터를 가져와서 사용자에게 보여줄 겁니다.
SQL이 만들어지면 우리는 다음 AWS Lambda에 SQL을 넘기고 이 SQL로 Amazon Athena를 통해 Amazon S3의 데이터를 습득합니다.
위의 일련의 과정을 통해 사용자는 사람의 언어로 SQL 없이 데이터를 확인할 수 있게 됩니다.
그러면 Prompt Flows 부터 살펴봅시다.
Prompt Flows 설정하기
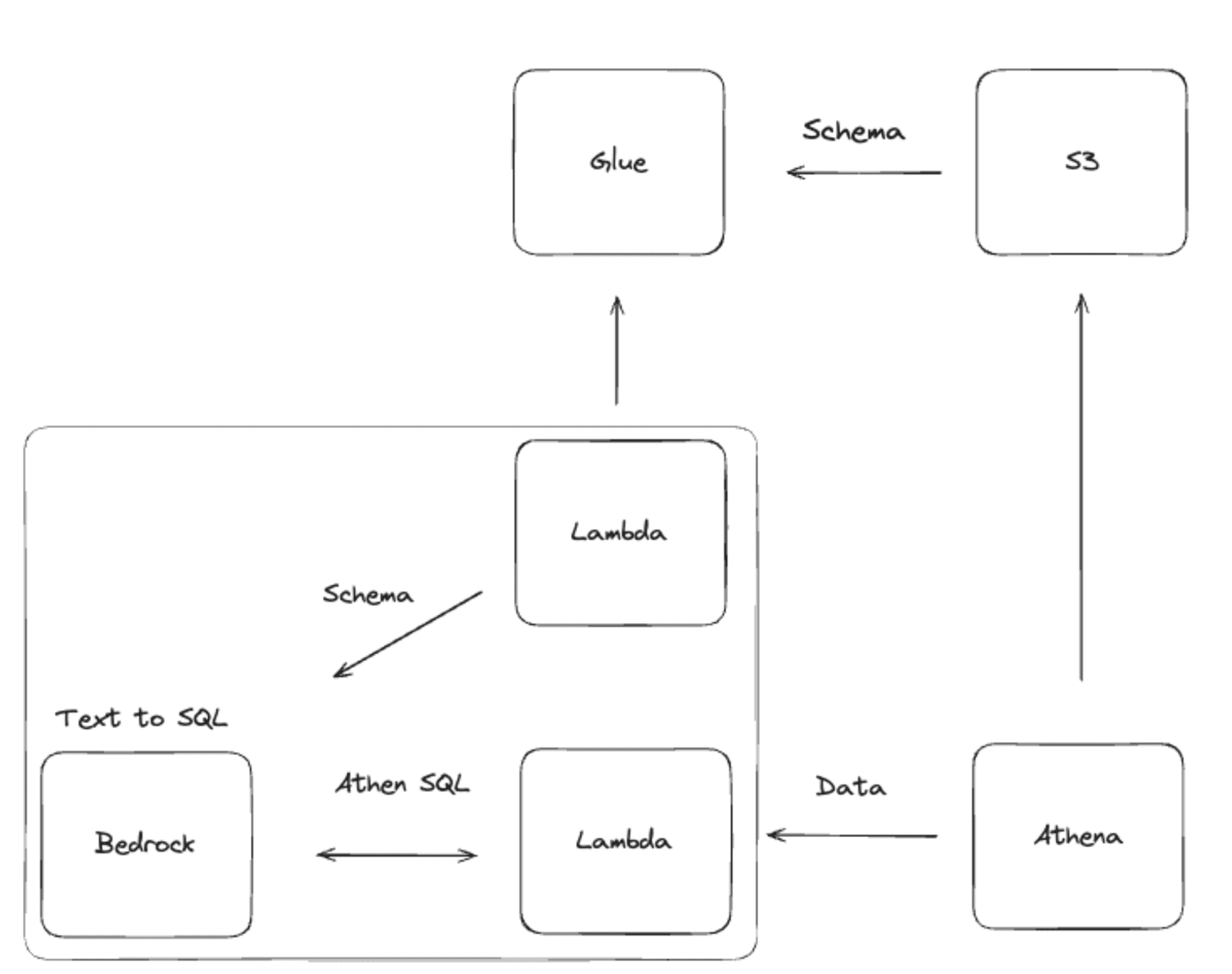
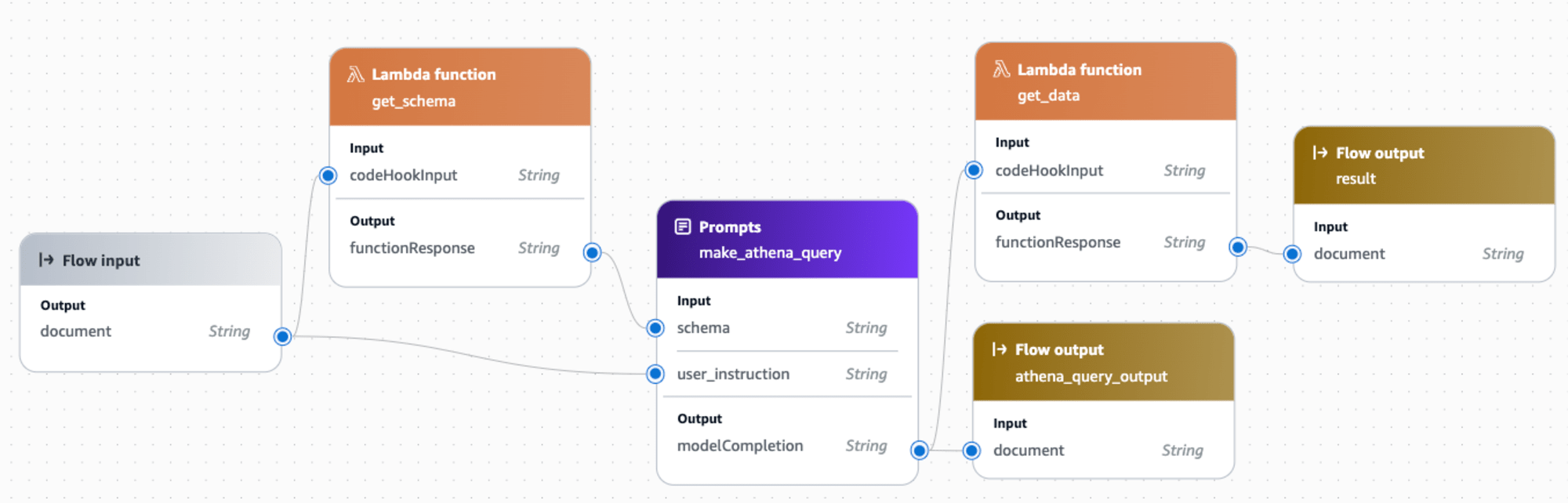
위에서 언급한 일련의 과정을 진행하기 위해 Amazon Bedrock의 Prompt Flow 라는 기능을 이용해서 만들어 보았습니다. 위의 알록달록한 UI 들이 사용자의 요청, AWS Lambda, 프롬프트, 아웃풋입니다.
왼쪽에서 부터 사용자의 요청이 들어오고 요청이 들어오면 스키마를 가져온 후, 다른 프롬프트를 통해 SQL을 작성합니다. 작성된 SQL은 사용자에게도 보여주기 위해 아웃풋이 달려 있습니다.
이후 SQL이 작성되면 실제로 SQL을 통해 데이터를 가져오고 마지막 아웃풋을 통해 사용자에게 보여집니다.
그럼 여기서 SQL을 만드는 프롬프트는 어떻게 구성했는지 알아보겠습니다.
SQL 작성 프롬프트
Create a Amazon Athena SQL query with the following requirements:
1. Follow proper SQL syntax.
2. Enclose table and column names in double quotes if they contain special characters or reserved words, add escape character for prevent to removing quote.
3. Use the syntax "OFFSET start LIMIT count" for pagination.
4. Ensure the query does not have any syntax errors and is fully compatible with standard SQL conventions.
5. Format as one line.
6. Add semicolon end of query.
7. NEVER ADD EXPLANATIONS COMMENTS IT'S DANGEROUS.
Schema: {{schema}}.
User Instruction: {{user_instruction}}.
몇 가지 지시 사항과 SQL을 만들기 위해 스키마와 사용자 요청을 변수로 받고 있습니다.
SQL 작성을 요구하기만 하면 되는데 왜 이렇게 이것저것 지시사항이 추가로 있을까요?
간단한게 SQL 작성을 요구하면 아래와 같은 문제가 생겼습니다.
- 특수문자, 예약어등이 SQL에 그냥 사용되어서 데이터 습득에 실패함
- Amazon Athena가 presto, trino 기반 SQL 쿼리 엔진이다 보니 SQL 문법이 일반적인 것과 약간의 다름이 있음
- 해당 SQL을 쉽게 사용하기 위해서는 한 문장으로 나와야 했음
- SQL 의외에 문장이 만들어지면 안되었음
이런 문제들을 해결하기 위해 하나 하나 지시사항을 추가하게됩니다. 마치 개발 과정에서 생기는 문제를 코드로 풀어내는 과정을 자연어로 풀게 되어서 좀 신기했습니다.
변수는 {{var}} 의 형태로 받게 됩니다. 전에 Prompt Flows에서 오는 값들을 변수형태로 받아서 최종적으로 SQL을 만들게 됩니다.
Amazon Bedrock에서 Prompt management이라는 기능이 있어서 실제로 테스트 해보면 이렇게 됩니다.
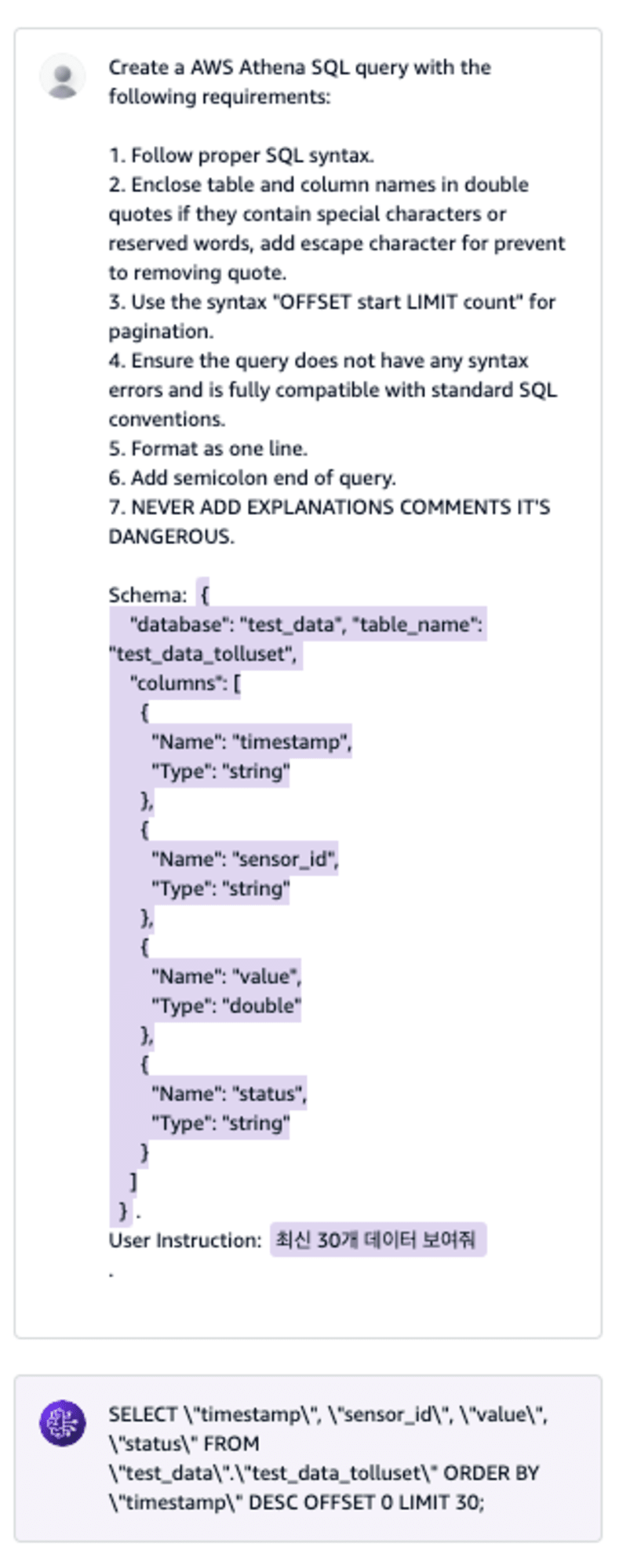
SQL에 이스케이프 문자가 들어 있어서 읽기 약간 불편한 감은 있지만 SQL이 잘 작성되고 있습니다. 실제 SQL 을 사용하기 전에 이스케이프 문자를 지우기 때문에 문제없지만, 사용자에게 보여주기 위한 용도를 위해서라면 추가적인 작업을 해도 좋을 것 같습니다.
작성한 SQL의 내용을 보면 timestamp가 시간이라는 것을 알기 때문에 정렬도 잘 했네요.
지금은 스키마를 직접 넘겨주었지만 어떻게 하면 자동으로 스키마를 만들고 저장해둘 수 있을까요?
데이터 스키마 만들기
데이터 스키마를 아는 경우 손으로 작성하면 되지만, 복잡하거나 많으면 사람보다는 시스템이 해결해주면 편할 것 같습니다.
이런 케이스에서 Amazon S3의 데이터를 읽어 스키마를 추출하는 서비스가 있습니다.
AWS Glue Crawler는 자동으로 데이터의 스키마를 알아내는 기능이 있습니다. 구체적인 설정과 기능 보다는 어떤식으로 사용가능한지에 초점을 맞추겠습니다.
Crawler로 사용할 데이터의 소스와 AWS Glue의 database 지정하고 동작시키면 알아서 스키마를 가진 AWS Glue의 데이터 카탈로그 테이블을 만들게 됩니다.
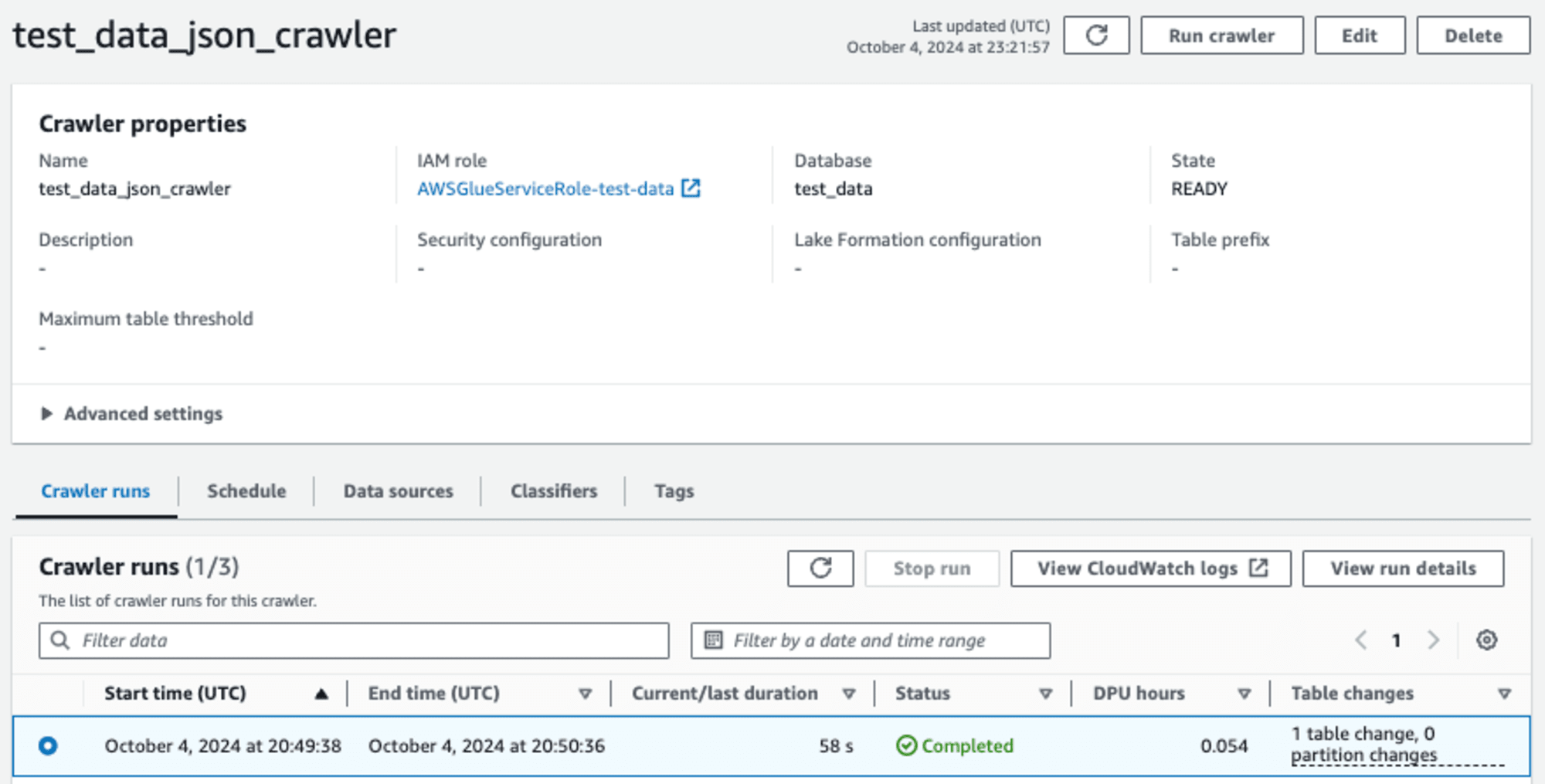
예를 들어 위처럼 Crawler를 동작시키면 아래처럼 스키마를 가진 테이블을 만들게 됩니다.
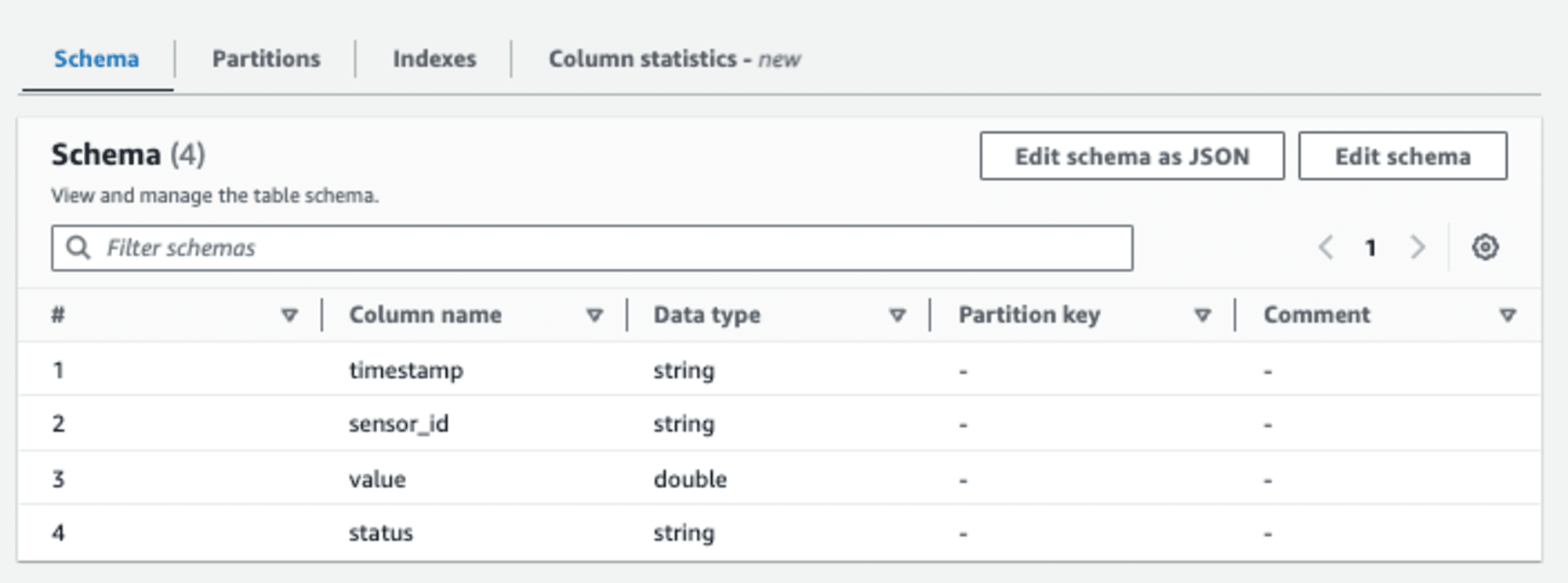
예시는 간단한 스키마를 확인하는 경우지만, 복잡하고 많은 스키마를 얻는데 유용하고 이외에도 많은 기능이 있으므로 필요한 경우 사용하면 매우 편합니다.
그러면 실제로 데이터를 가져오는 부분을 확인해봅시다.
SQL 쿼리로 데이터 가져오기
Amazon S3의 데이터를 확인하려면 매번 데이터를 가져오는 작업이 필요하게 될 겁니다. 뿐만 아니라 데이터에 대해 쿼리를 하려면 SQL 기반으로 하기에는 추가작업이 필요하게 됩니다.
이런 경우 사용할 수 있는게 Amazon Athena 입니다. Amazon Athena는 SQL로 Amazon S3의 데이터를 쿼리할 수 있게 해줍니다. AWS Glue에서 만든 database와 table을 이용할 수 있습니다.
전에 만들어 본 SQL이 제대로 쿼리하는지 확인해 봅시다.
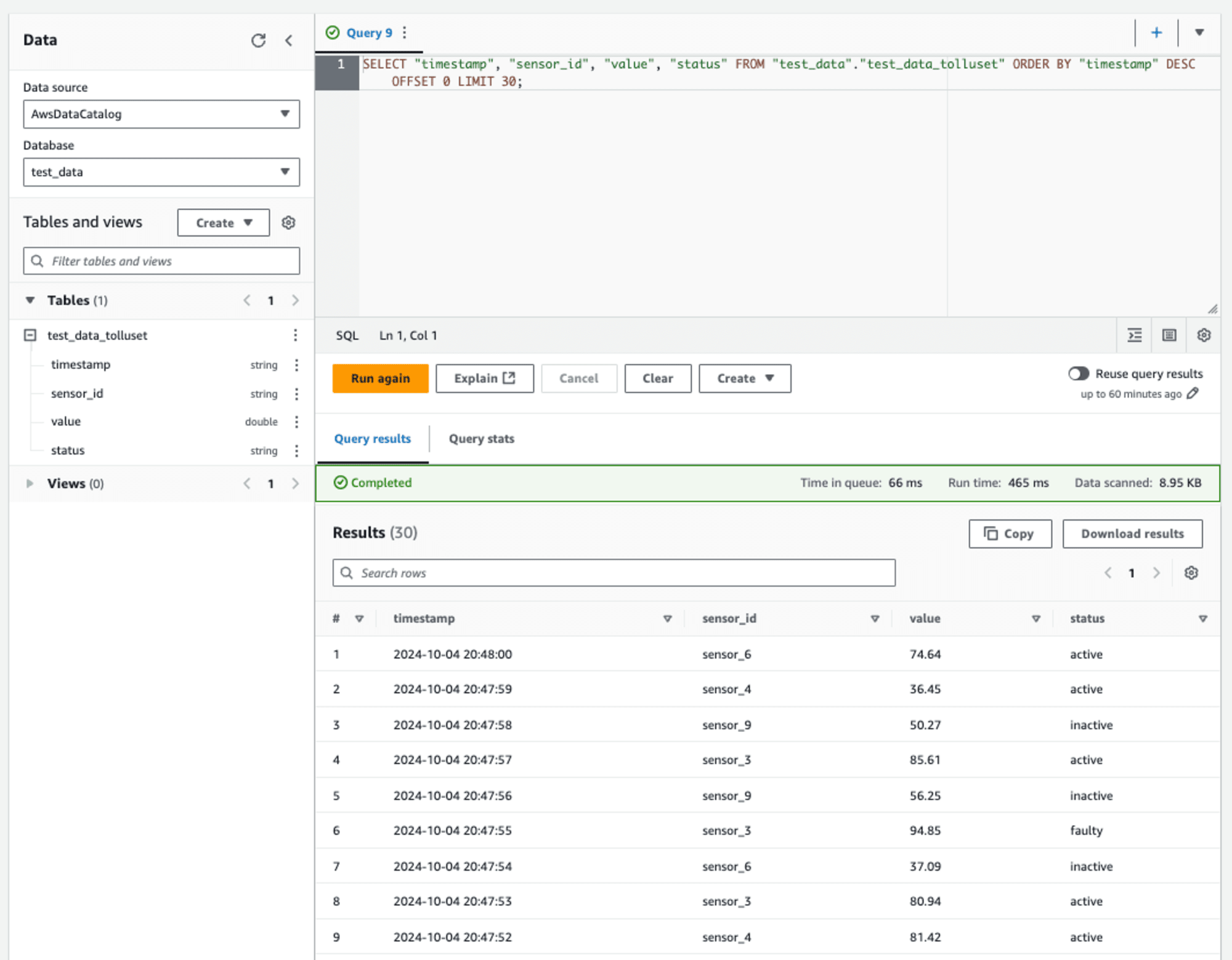
최신순대로 데이터를 잘 가져오고 Results (30) 이 부분을 보면 데이터도 30개를 가져온 것을 알 수 있습니다.
왼쪽에는 쿼리할 스키마도 보이고 있네요.
한가지 주의할 점은 JSON을 사용하는 경우 일반 JSON이 아니라 한줄에 하나의 JSON 아이템을 가지는 JSONL을 사용하셔야 합니다.
[{a: 1}, {b: 2}, {c: 3}]
->
{a: 1}
{b: 2}
{c: 3}
형태로 처리를 해줘야되기 때문에 JSON을 사용하는 경우 전처리를 해주어야 합니다.
실제로 데이터 가져와보기
Prompt Flows로 다시 돌아와봅시다. AWS Lambda 부분은 설명은 안해두었지만 AWS Glue에서 스키마 등의 정보를 가져오고, 두 번째 AWS Lambda 에서는 받은 SQL 으로 Amazon Athena 에 쿼리하면 됩니다.
아까 프롬프트에 했던 질문을 다시 해봅시다.
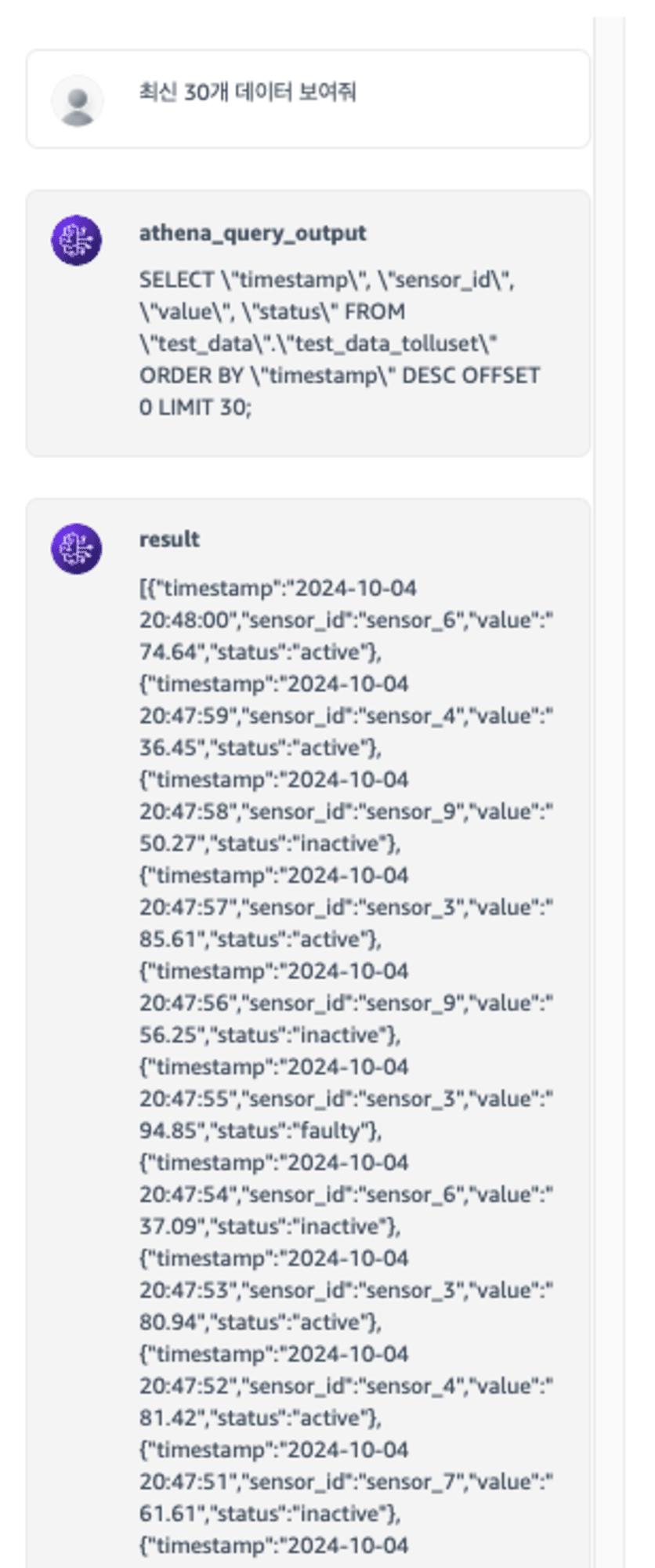
우리가 거쳐온 과정들을 그대로 보여주고 있는 것을 알 수 있습니다.
그러면 다른 질문도 해보죠.
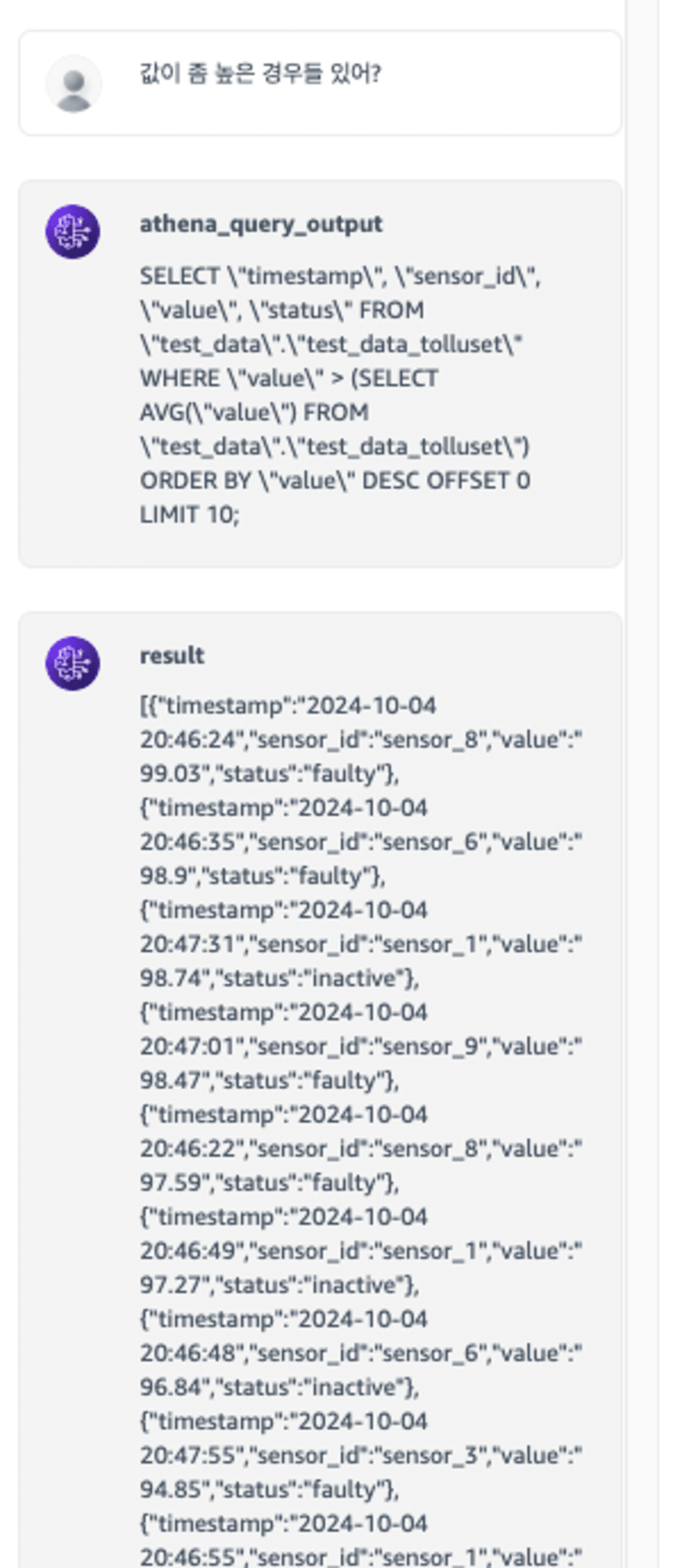
추상적인 질문을 던져보았습니다. 값이 좀 높은 경우들 있어?에서 좀 높은 이라는 요청을 평균보다 높은이라고 해석했네요. 좋은 해석인 것 같습니다.
더 추상적인 질문도 가능할까요?
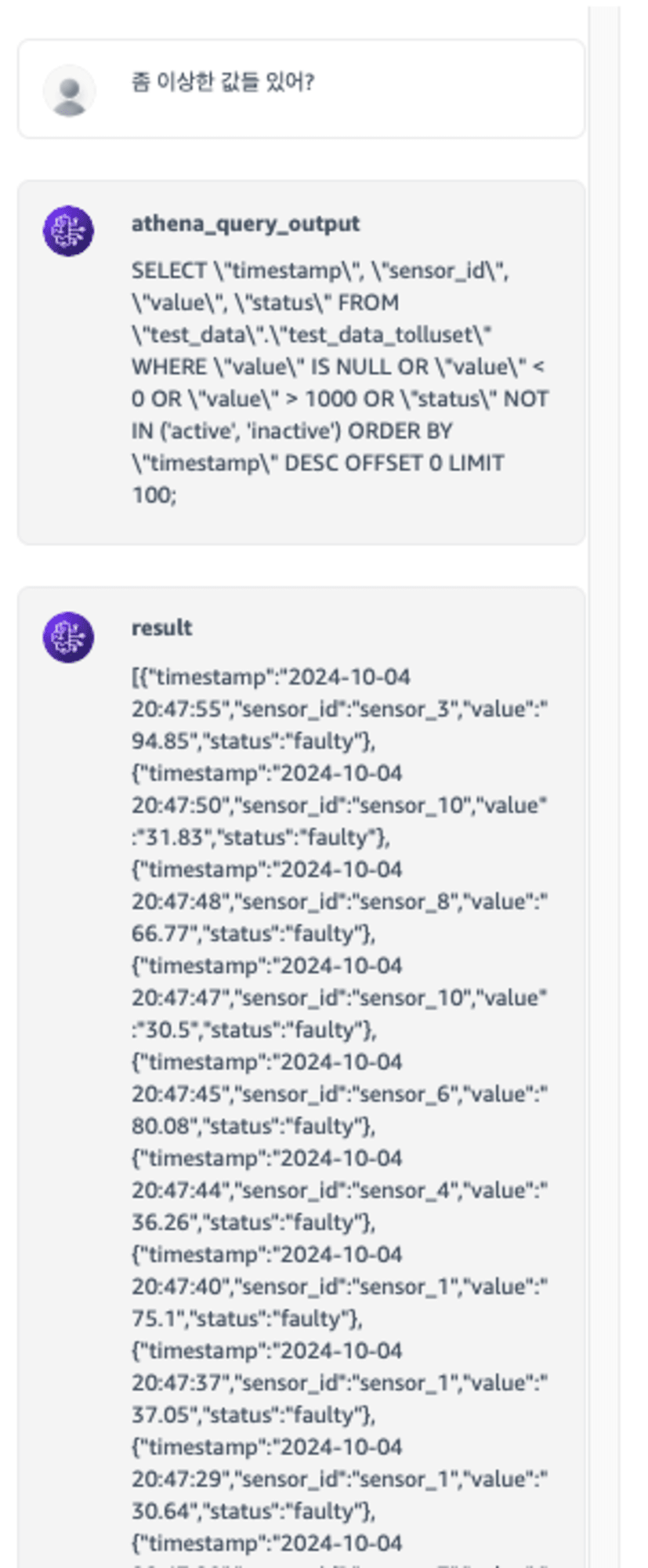
좀 이상한 값들 있어? 에서 이상한 값 을 추출한 부분이 흥미롭네요. 값이 비어있거나, 0과 1000 이라는 극단치, 스키마에서 status를 인식하고 작동중이 아닌 값을 얻어내려 했네요. 그리고 센스있게 최신순으로 100개만 추출하는 것까지 해주었습니다.
만약 SQL을 모르는 상태로 위의 질문을 접근했다면, 어떤식으로 데이터를 처리할지 그리고 SQL 문법등에 대해서 고민하는 과정이 필요했겠지만, 우리는 LLM에게 맡겨서 쉽게 해결하게 되었습니다.
마무리
사실, 위의 과정은 PoC 단계에서는 잘 동작하는 것처럼 보이지만 여러가지 해결해야할 과제들이 있습니다.
지금은 질문이 통하는 것 같지만 방향이 다르면 LLM이 당황하게 됩니다.
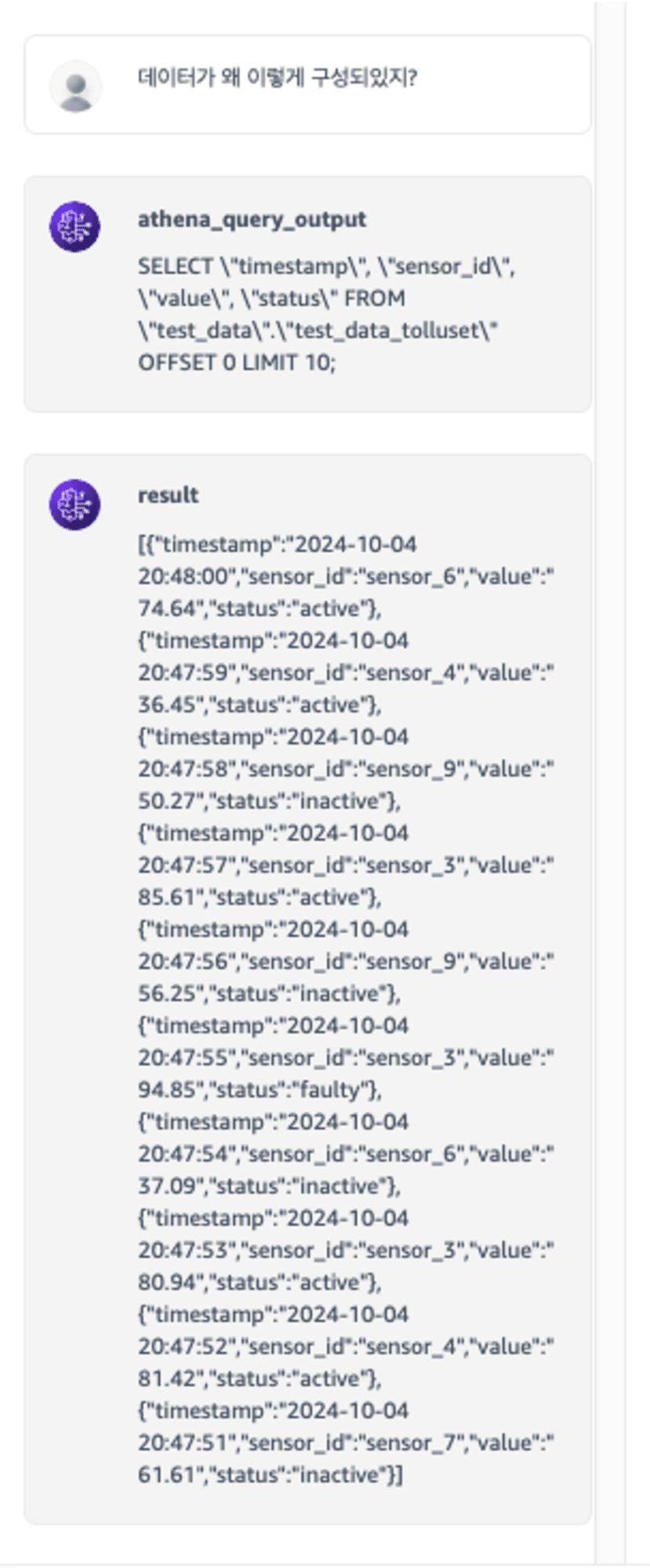
데이터가 왜 이렇게 구성되있지? 라는 다른 컨텍스트의 질문에 대답할 수 없으니 일반적인 쿼리를 만들어버렸습니다.
현재 동작은 데이터를 습득하는 과정, 즉 데이터 습득 이외의 질문에 대해서 다른 요청을 한다는 것을 인식하지 못합니다.
따라서, 사용자의 요청이 어떤 요청인지 파악하는 과정이 필요합니다.
그리고 확인 가능한 데이터의 종류, 스키마, 데이터의 양 등등 전체적인 메타 데이터 또한 알고 싶을 것 입니다.
또한, 만들어진 결과도 제대로 나왔는지 평가도 필요합니다. 지금은 SQL이 제대로 데이터를 가져오는지 알 수 있는 상황이었지만, 정확하게 알 수 없는 경우에 대해 파악해야합니다. 이런 경우 에러가 아니라 퀄리티가 낮은 것이기 때문에 퀄리티를 평가하는 시스템도 필요하게 됩니다.
여러 개선 및 추가해야하는 부분들이 있지만 핵심적인 Text-To-SQL은 위의 방식처럼 만드는게 가능합니다.
일을 프론트엔드 개발을 하고 DB도 NoSQL로 하다보니 SQL을 볼일이 적어서 막상 적어야 되면 힘들었습니다. 이런 방식의 시스템이 많이 생기면 하는 마음으로 만들어보았습니다. 이런 시스템이 많아진 세상이 되면 참 편해질 것 같네요 🤗
문의 사항은 클래스메소드 코리아로!
클래스메소드 코리아에서는 다양한 세미나 및 이벤트를 진행하고 있습니다.
진행중인 이벤트는 아래 페이지를 참고해주세요.
AWS에 대한 상담 및 클래스 메소드 멤버스에 관한 문의사항은 아래 메일로 연락주시면 감사드립니다!
Info@classmethod.kr













