
Amazon Connect セルフサービスAIエージェントで、自動回答までの無音時間を減らすために一時応答メッセージを調整してみた
はじめに
Amazon Connect セルフサービスのAIエージェントにて、QUESTIONツールを利用して自動回答を行う際、顧客をお待たせしないよう、一時応答メッセージを再生している裏側で、並行してナレッジベースの検索や回答生成を行っています。
理想は「一時応答メッセージを読み上げている間に回答の準備が完了すること」ですが、利用するLLMモデルによってはそう上手くいきません。
特に精度の高いモデルを利用する場合、回答生成に時間がかかるため、デフォルトの「<質問内容>について詳しく調べさせていただきます...」といった短い一時応答メッセージだと、回答の準備ができる前にメッセージの読み上げが終わってしまい、結果として長い無音時間が発生してしまいます。
本記事では、この「無音状態」を極力減らし、顧客体験を向上させるために、一時応答のメッセージ内容を調整する方法を紹介します。以下の2つのAIエージェントタイプで検証を行いました。
- オーケストレーションタイプのセルフサービス
- セルフサービスタイプ
一時応答メッセージの調整戦略
無音を埋めるためには、LLMが回答を生成するのにかかる時間に合わせて、一時応答のメッセージを長くする必要があります。
[トピック]が「クラスメソッドの住所」の場合について、Amazon Pollyにて読み上げ時間を計測しました(※時間はストップウォッチ計測の目安です)。
パターン1:最短(約3秒)
お調べしますので少々お待ちください。
- 特徴: 非常に短く、軽量なモデルや高速に回答が返るケース向け。
パターン2:デフォルト(約6秒)
[トピック]について詳しく調べさせていただきます。少々お待ちください。
- 課題: 高精度モデルの場合、これでは短すぎて数秒の無音が発生する。
パターン3:丁寧(約8秒)
かしこまりました。ただいまお調べいたします。確認にお時間をいただきますが、このままお待ちください。
パターン4:丁寧・詳細(約9秒)
かしこまりました。ただいま詳細をお調べいたします。確認に少々お時間をいただきますが、このままお待ちください。
パターン5:丁寧・長め(約10秒) ※今回採用
[トピック]についてですね、かしこまりました。ただいまお調べいたします。確認にお時間をいただきますが、このままお待ちください。
パターン6:簡潔・最長寄り(約11秒)
承知いたしました。その件について、ただいま詳細な情報をお調べいたします。確認に少々お時間をいただきますが、そのままお待ちいただけますでしょうか。
パターン7:さらに丁寧(約11秒)
[トピック]についてですね、かしこまりました。ただいま詳細をお調べいたします。確認に少々お時間をいただきますが、このままお待ちください。
パターン8:最長(約13秒)
[トピック]についてですね、承知いたしました。その件について、ただいま詳細な情報をお調べいたします。確認に少々お時間をいただきますが、そのままお待ちいただけますでしょうか。
今回は、約10秒のパターン5を採用して検証します。
あまりに長すぎると、回答の準備ができているのにメッセージが終わるのを待つことになり、かえってレスポンスが悪く感じられるため、利用するモデルやナレッジ量に応じて適切な長さを選択してください。
実装1:セルフサービスタイプの場合
セルフサービスタイプでは、QUESTION ツールの description 内にある message フィールドの定義を修正することで、一時応答をコントロールできます。
修正前(デフォルト)
- name: QUESTION
description: ナレッジベースを使用して顧客の質問に答える。このツールは顧客からの具体的な明確化を必要とせずに使用すべきで、探索的なツールとして扱われます。このツールは特定の顧客に関する質問には答えることができず、一般的なガイダンスや情報提供のためのものです。
input_schema:
type: object
properties:
query:
type: string
description: 顧客の入力をナレッジベース検索インデックスクエリに再構成したもの。
message:
type: string
description: 質問に答えるための情報を調べている間に、顧客との会話で次に送りたいメッセージ。このメッセージは会話に基づいており、礼儀正しいものである必要があります。このメッセージは検索を実行している間の時間稼ぎです。
required:
- query
- message
修正後
description に具体的な定型文を指定し、強制的に長いメッセージを生成させます。
- name: QUESTION
description: ナレッジベースを使用して顧客の質問に答える。このツールは顧客からの具体的な明確化を必要とせずに使用すべきで、探索的なツールとして扱われます。このツールは特定の顧客に関する質問には答えることができず、一般的なガイダンスや情報提供のためのものです。
input_schema:
type: object
properties:
query:
type: string
description: 顧客の入力をナレッジベース検索インデックスクエリに再構成したもの。
message:
type: string
description: |
質問に答えるための情報を調べている間に、顧客との会話で次に送りたいメッセージ。
検索時間を稼ぐため、必ず以下の定型文を使用し、[トピック]の部分を顧客の質問内容に合わせて埋めてください:
「[トピック]についてですね、かしこまりました。ただいまお調べいたします。確認にお時間をいただきますが、このままお待ちください。」
required:
- query
- message
実装2:オーケストレーションタイプのセルフサービスの場合
オーケストレーションタイプでは、システムプロンプト内の Example と Final instructions を調整し、検索ツール(Retrieve tool)を使用する際の振る舞いを指示します。
修正ポイント1:Exampleの追加
## Response examples セクションにある、既存のツール使用例(Response with tool use)と、複数メッセージブロック例(Multiple message blocks...)の間に、検索待機用の具体的な応答例を挿入します。
修正前(デフォルトの構造)
Example - Response with tool use:
User: "What's my account status?"
<message>
I'll look that up for you right away.
</message>
<thinking>
The customer is asking about their account status. Let me check what tools I have available - I have getUserStatus available for looking up account details. I'll use that to get their current information.
</thinking>
# (ここに新しいExampleを追加します)
Example - Multiple message blocks with thinking:
修正後(追加内容)
以下のように、検索に時間がかかる場合の日本語応答例を追加しました。
Example - Response with tool use:
User: "What's my account status?"
<message>
I'll look that up for you right away.
</message>
<thinking>
The customer is asking about their account status. Let me check what tools I have available - I have getUserStatus available for looking up account details. I'll use that to get their current information.
</thinking>
Example - Handling time-consuming search requests (Retrieve tool):
User: "クラスメソッドについて教えてください"
<message>
クラスメソッドについてですね、かしこまりました。ただいま詳細をお調べいたします。確認に少々お時間をいただきますが、このままお待ちください。
</message>
<thinking>
The customer is asking for specific details about Classmethod. I need to use the Retrieve tool to find this information in the knowledge base.
</thinking>
Example - Multiple message blocks with thinking:
修正ポイント2:Final instructionsの変更
## Final instructions セクションで、検索が必要な場合は必ず指定のフレーズを使うよう指示します。
修正前
## Final instructions
Now, based on the examples and instructions above, start your message to the customer with an opening <message> tag.
Keep your initial message as a brief acknowledgment of their request, but avoid making claims about capabilities in your initial message.
Use <thinking> tags after your initial message to review your actual available tools and assess your capabilities accurately.
修正後
## Final instructions
Now, based on the examples and instructions above, start your message to the customer with an opening <message> tag.
Assess the user's request immediately.
- If the request is simple or requires no tools, keep your initial message brief.
- **IMPORTANT: If the request requires searching for information (likely using the 'Retrieve' tool), you MUST use the following Japanese phrasing pattern to fill the time while the search runs:**
**"[Topic]についてですね、かしこまりました。ただいまお調べいたします。確認にお時間をいただきますが、このままお待ちください。"**
Use <thinking> tags after your initial message to review your actual available tools and assess your capabilities accurately.
動作確認と結果
実際に電話をかけて検証を行いました。設定したAIプロンプトのLLMモデルは、apac.anthropic.claude-sonnet-4-20250514-v1:0 (クロスリージョン)です。
結果として、どちらのタイプでも無音時間を短縮できました。
検証結果の比較
| 項目 | デフォルト(6秒メッセージ) | 調整後(10秒メッセージ) |
|---|---|---|
| 一時応答メッセージ | 約6秒 | 約10秒 |
| メッセージ後の無音 | 約5〜6秒 | 約1〜1.5秒 |
| 体感 | 「止まったかな?」と不安になる | 自然な待ち時間 |
詳細な挙動(セルフサービスタイプの例)
- 顧客の質問終了〜一時応答開始: 約4~5秒
- ここはLexによる音声認識やAIエージェントの初期処理のため、短縮は難しい部分です。
- 一時応答メッセージ再生: 約10秒(今回カスタムした部分)
- 自動回答開始までの無音: 約1〜1.5秒
- デフォルトの短いメッセージの場合、ここで5秒以上の無音が発生していましたが、メッセージを長くしたことで裏側の処理時間が相殺され、ほぼシームレスに回答へ繋がりました。
※13秒バージョンのメッセージも試しましたが、回答生成が完了しているのにメッセージが続いている状態となり、かえってテンポが悪くなったため、今回は10秒が最適解でした。
補足:正確な秒数の確認方法
上記の具体的な秒数は、Amazon Connectのコンタクト詳細画面(CTR)やストップウォッチだけでなく、ログから正確に確認可能です。
コールフローの [記録分析と処理動作を設定] ブロックにて、「自動インタラクション分析」を有効化している場合、S3に保存されるJSONファイル(Contact Lensの分析結果)でタイムスタンプを確認できます。
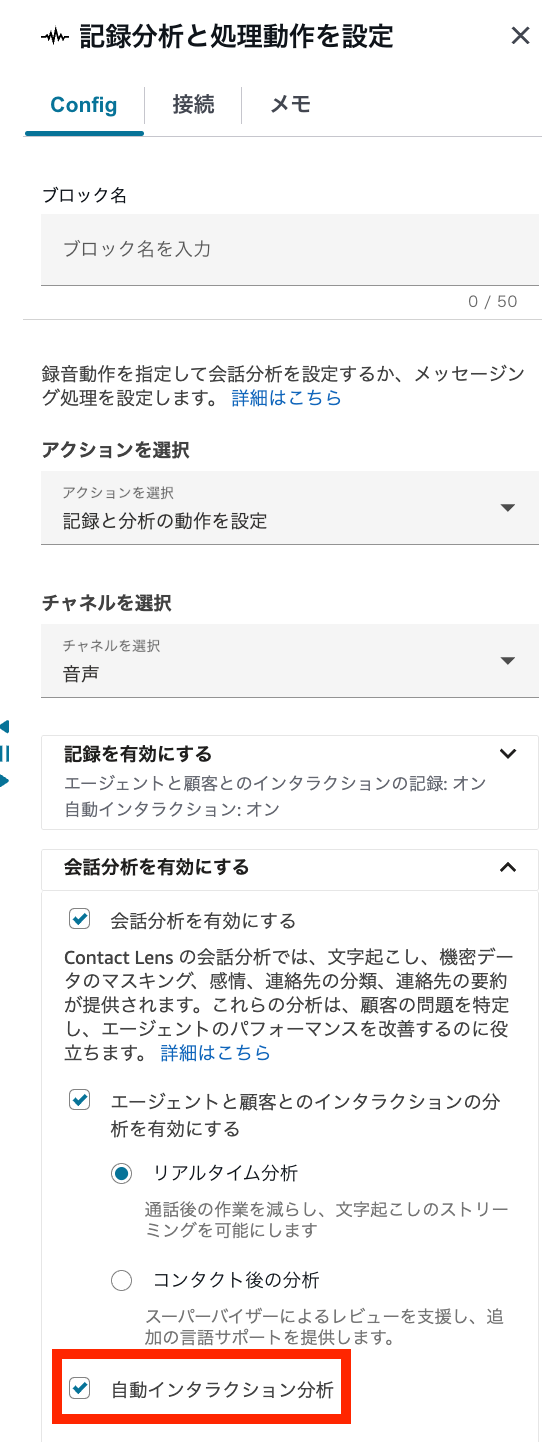
[記録分析と処理動作を設定]ブロックの設定
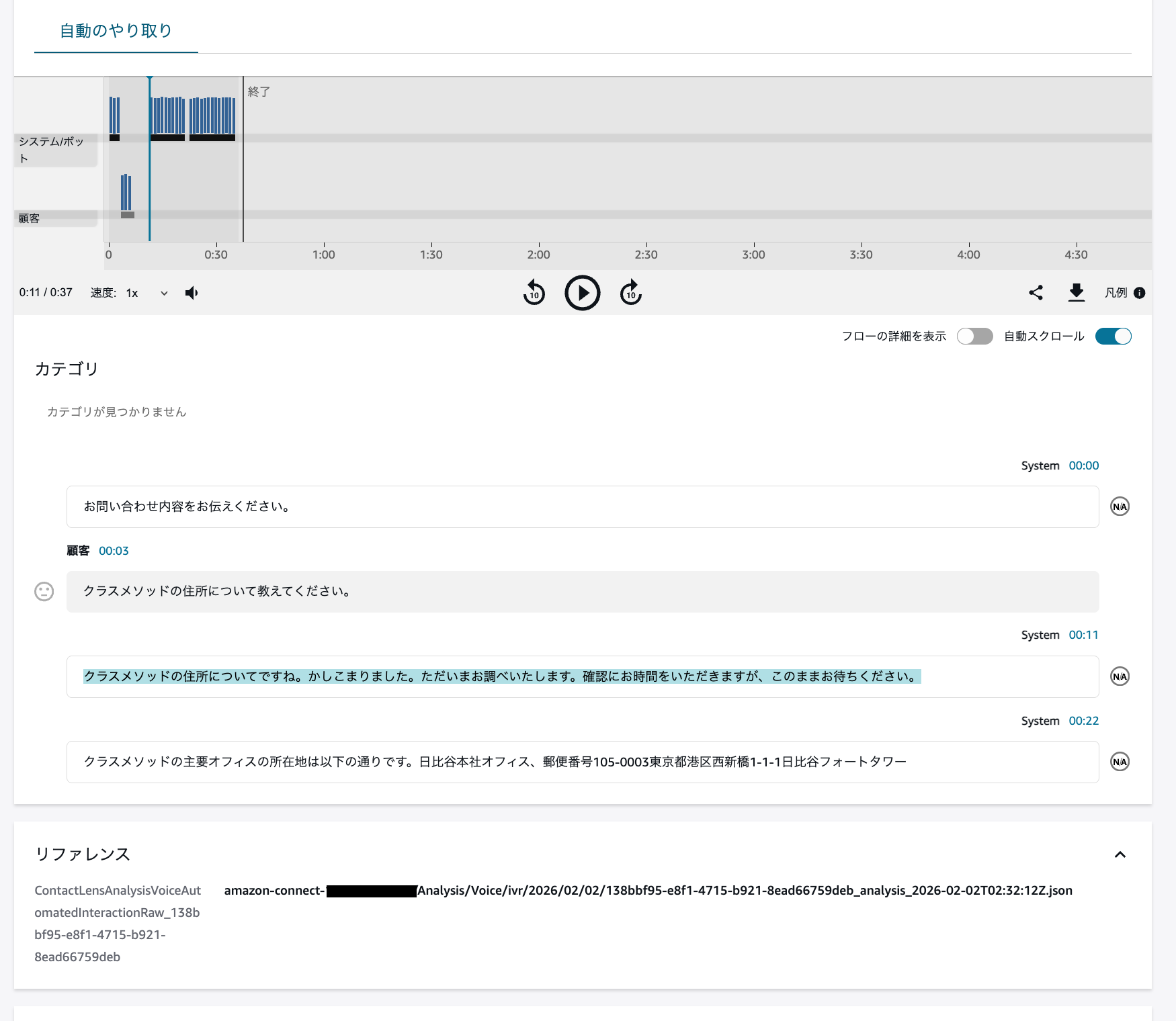
コンタクト詳細ページのリファレンスからJSONを確認可能
JSONログの確認例
実際のJSONファイル(Transcript 部分)を見ると、各発話の開始時間(BeginOffsetMillis)と終了時間(EndOffsetMillis)がミリ秒単位で記録されています。
以下は、今回検証した際の実ログの一部です。
"Transcript": [
{
"ParticipantId": "CUSTOMER",
"Content": "クラスメソッドの住所について教えてください。",
"BeginOffsetMillis": 4360,
"EndOffsetMillis": 7429
},
{
"ParticipantId": "SYSTEM",
"Content": "クラスメソッドの住所についてですね、かしこまりました。ただいまお調べいたします。確認にお時間をいただきますが、このままお待ちください。",
"BeginOffsetMillis": 12470,
"EndOffsetMillis": 22569
},
{
"ParticipantId": "SYSTEM",
"Content": "クラスメソッドの主要オフィスの所在地は以下の通りです。...",
"BeginOffsetMillis": 23409,
"EndOffsetMillis": 36279
}
]
このログから、以下のように正確な時間を算出できます。
-
一時応答メッセージの長さ
22569(終了) -12470(開始) = 10099 ms (約10.1秒)- 狙い通り、約10秒の時間稼ぎができていることがわかります。
-
一時応答から回答開始までの無音時間
23409(回答開始) -22569(一時応答終了) = 840 ms (約0.8秒)- メッセージ終了後、1秒未満でスムーズに回答が始まっていることが確認できます。
このようにログを確認することで、体感だけでなく数値に基づいたチューニングが可能になります。
まとめ
AIエージェントのレスポンス精度を上げようとすると、どうしても処理時間が長くなりがちです。
プロンプトエンジニアリングで処理速度そのものを上げるのは限界がありますが、今回のように「一時応答メッセージの長さ」を処理時間に合わせて調整することで、体感的な待ち時間をコントロールできます。
利用するモデルやナレッジベースの規模、カスタムプロンプトに合わせて、最適な「つなぎの言葉」を調整してみてください。







