
Amazon Connect AIエージェントセルフサービスで方言が通じるかを仕組みから整理してみた
はじめに
Amazon Connect AIエージェントセルフサービスでは、自動回答やお問い合わせ内容のヒアリング、エージェントへの引き継ぎ、お問い合わせ内容の振り分けなど、AIエージェントが発信者の一次対応を行うケースがあります。
そのような場面において、「地域の方言に対応しているか?」という質問をいただくことがあります。
結論から言うと、「やってみないと断定的なことは言えない」というのが正直なところです。また、どの地域からの電話がメインになるか(特定の地域のみか、全国規模か)によっても対応の難易度や事前対策の打ちやすさが変わります。
実際の音声の聞こえ方やプロンプトの設定によってAIの挙動が変わるため、本記事ではAIエージェントの処理の仕組みを踏まえながら、方言が影響するポイントとその対策について整理してみます。
全国規模か、特定地域かで対策の考え方が変わる
方言への対策を検討する上で、まず「どの地域からの電話がメインになるか」を整理しておくことが重要です。対策の具体的な内容は後述しますが、設定タイミングの考え方が以下のように異なります。
特定地域に限定されるケース(例:東北エリア限定のサービス)
想定される方言がある程度絞られるため、事前に対策を講じやすい環境です(詳細は後述します)。
リリース前に想定される方言パターンで実際に試験発話を行い、音声認識やAIの挙動を事前確認しておくことも現実的です。
全国規模のケース
方言の種類が多岐にわたるため、事前に網羅的な対策を講じることは現実的ではありません。リリース後のログ分析をベースに、誤認識の傾向が見えてきたものから順次チューニングしていく運用が基本になります。
ただし、そのコンタクトセンターとして事前によく聞かれる方言や固有名詞のナレッジがある場合は、それらを事前に設定しておくことは有効です。
処理の流れと方言が影響するポイント
Amazon Connect AIエージェントセルフサービスは、発話から回答生成までに大きく以下の2つのステップで処理が行われます。
- 音声認識(Amazon Lex):お客様の音声をテキストに変換する
- AIエージェントによる理解と回答生成:テキスト化された内容をもとに意図を解釈し、検索クエリの生成や回答生成する
音声認識はAmazon Lexで行います。音声認識モデルの選択もできます。
回答生成はAIエージェントで行います。記事執筆時点では、モデルはClaude Sonnet 4.5など比較的新しいモデルも利用可能です。
方言の影響を考える上では、この2つのステップのそれぞれで課題が生じる可能性があります。
ステップ1:音声認識の壁(方言の音声が正しくテキスト化されるか)
まず、お客様の声をテキストに変換する段階の話です。
方言特有のイントネーションや単語によって、全く別の言葉に誤変換されてしまう可能性があります。
特に注意が必要なのは、AIがクエリを生成する際に使うキーワードとなる単語が誤変換されるケースです。
なかでも、誤変換後の文章が別の意味として自然に成立してしまう場合は、AIが誤変換に気づけないため、より注意が必要です。
例えば、一部の地域特有の発音として「し」と「ひ」が混同されるケースがあります。
「資料(しりょう)を送ってほしい」が「肥料(ひりょう)を送ってほしい」と誤変換された場合、「肥料を送ってほしい」は文章として自然に成立しているため、AIは誤変換に気づけず「資料のことだ」と判断できないまま、適切な回答ができない可能性があります。これが「別の意味として文章が成立してしまった」ケースの典型例です。
なお、音声認識で誤変換が起きてしまった場合でも、ステップ2のAIが文脈から正しく補正してくれるケースがあります。詳細は後述します。
構成の意図はわかりました。「まず限界を示してから、できるケースを説明する」という流れですね。書いてみます。
ステップ2:AIの理解の壁(テキスト化された方言から正しいクエリを生成できるか)
次に、テキスト化された文章からAIが検索クエリ(キーワード)を抽出する段階です。
ただし、ステップ1で触れたとおり、誤変換後の文章が別の意味として自然に成立してしまっているケースでは、プロンプトの前提条件があっても正しいクエリを生成できない場合があります。
一方で、AIの言語理解能力は非常に高く、音声認識がある程度正しく文字起こしされていれば、方言の意味を汲み取って適切な標準語のクエリに変換してくれる可能性があります。
また、プロンプトに「どのようなコールセンターの窓口か」「どのような内容の問い合わせが来るか」といった前提条件をしっかり記載しておけば、発話単体の文脈が乏しい場合でもAIが補正してくれる可能性が高まります。
例えば、東北地方などの訛りで「鍵(かぎ)」を「かげ」と発音されたケースで考えてみます。「影をなくしたがどうすればよい?」という文字起こしになった場合は、文脈から「鍵」を推測する手がかりがなく、AIが正しいクエリを生成できる可能性は低くなります。
一方、「影をなくして家に入れない」と文字起こしされた場合、AIは「家に入れないという文脈から、影ではなく鍵の誤変換だろう」と推測し、「鍵 紛失」といった正しいクエリに変換してくれる可能性があります。
また、「防犯カメラが動かへんようになってもたから、見てほしいんやけど」と文字起こしされた場合は、「動かへん」「なってもた」「見てほしい」といった方言表現が残っていても、AIは文脈全体から意味を読み取り、「防犯カメラ 故障 修理」といった標準語のクエリに変換してくれる可能性が高いです。
このように、音声認識の誤変換があってもAIが文脈から補正してくれるケースがある一方で、文脈が乏しかったり誤変換後の文章が別の意味として自然に成立してしまったりする場合は、AIも正しいクエリを生成できないケースが考えられます。
運用後の対策(チューニング)について
リリース後にAIで解決できずオペレーターへエスカレーションされたケースについては、文字起こし結果やAIが生成したクエリのログを確認することをおすすめします。
ログから以下の点を確認することで、「音声認識の段階で崩れているのか」「AIの理解の段階で崩れているのか」を切り分けることができ、どの対策が必要かを判断しやすくなります。
- 音声認識の結果(発話がどのようなテキストに変換されたか)
- AIが生成した検索クエリ(テキストからどのようなキーワードが抽出されたか)
- 最終的にAIが返した回答
特定の方言で誤認識の傾向が見られたり、AIがうまくクエリを作れなかったりした場合は、以下の2つの対策を組み合わせて精度を継続的に向上させることが可能です。
カスタム語彙とプロンプト補正ルールの使い分け
前述のとおり、AIエージェントセルフサービスは「音声認識(Amazon Lex)」と「AIエージェントによる理解と回答生成」の2つのステップで処理が行われます。2つの対策はそれぞれ対処するステップが異なります。
カスタム語彙(ステップ1:音声認識の対策)
音声認識の誤変換そのものを防ぎたい場合に有効です。
カスタム語彙は日本語(ひらがな・カタカナ・漢字)のみ対応しており、英字には対応していません。「Amazon Cognito」や英字を含む型式などは登録できないため、その場合はプロンプト補正ルールで対応するしかありません。
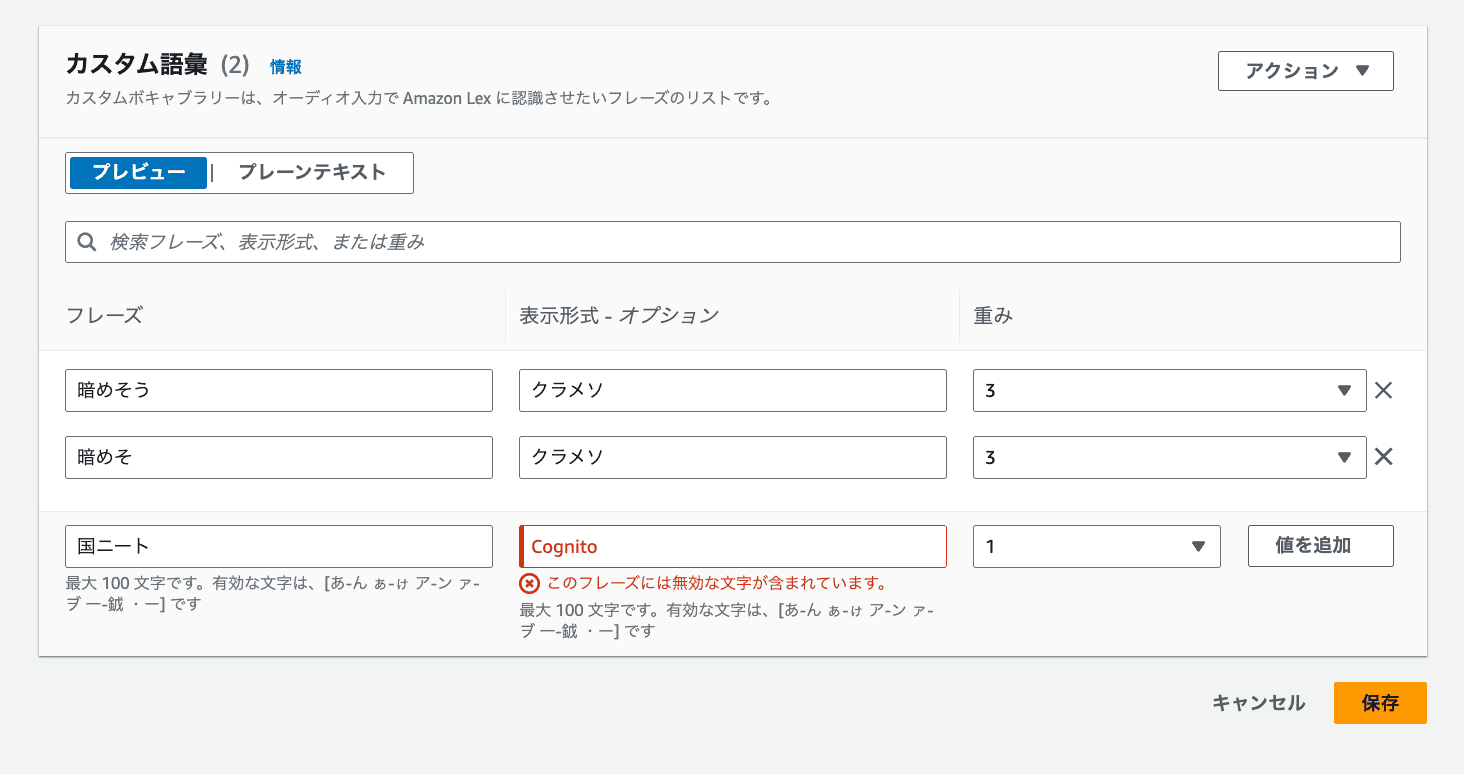
また、カスタム語彙は特定の単語を優先認識させる機能であり、「金額に関する文脈の場合のみ変換する」といった文脈に応じた条件付きの制御はできません。文脈を考慮した変換が必要な場合も、後述するプロンプト補正ルールで対応することになります。
設定タイミングの目安は以下のとおりです。
- 特定地域のサービス → 想定される方言をあらかじめ登録しておくことが可能
- 全国規模のサービス → 事前に網羅することは難しいため基本は運用後に追加。ただしコンタクトセンターとして事前にナレッジのある方言や固有名詞があれば、先に登録しておくことも有効
プロンプト補正ルール(ステップ2:AIの理解の対策)
音声認識で誤変換されてしまった後に、AIが正しく読み替えられるようにする対策です。
カスタム語彙で対応できない範囲、具体的には英字の固有名詞や英字を含む型式、あるいは文脈に応じた条件付きの変換が必要なケースをカバーする用途が主になります。
方言そのものへの対応という観点では、方言に英字が使われることはほぼないため、カスタム語彙を補完する形での利用が中心になります。
設定タイミングの目安は以下のとおりです。
- 特定地域のサービス → カスタム語彙で対応できなかった項目を事前に追記
- 全国規模のサービス → 事前に網羅することは難しいため基本は運用後に追加。ただしコンタクトセンターとして事前にナレッジのある方言や固有名詞があれば、先に登録しておくことも有効
AIエージェントのプロンプトへの追記例は以下のとおりです。
【方言・音声認識エラーの補正ルール】
方言や音声入力の文字起こしエラーにより、ユーザーの意図が正しくクエリに反映されない場合があります。
ユーザーの発話に以下のような方言や誤認識が含まれる場合は、リストに従って「標準語・正しい用語」に読み替えた上で、検索クエリ(query)を作成してください。
フォーマット: [方言・誤認識されやすいワード] → [標準語・正しい用語] (適用する文脈の条件)
<補正リスト>
- 「なんぼ」 → 「料金」「費用」 (金額や契約に関する文脈の場合)
- 「ほかす」 → 「捨てる」「廃棄」 (機器の処分に関する文脈の場合)
- 「いごかん」「いごかない」 → 「動かない」「故障」 (機器のトラブルに関する文脈の場合)
# 今後、特有の方言や誤認識が見つかった場合はここに追記してください
# - 「〇〇」 → 「△△」 (××に関する文脈の場合)
</補正リスト>
まとめ
Amazon Connect AIエージェントセルフサービスにおける方言対応について整理しました。
方言の影響度を判断する上で重要なのは、AIがクエリを生成する際に使うキーワードとなる単語が、方言の発音によって別の意味に誤変換されるかどうかです。語尾など回答に無関係な部分の方言や誤変換はAIが吸収してくれるケースが多い一方、クエリに影響するキーワード自体が誤変換されるケースは注意が必要です。
方言の影響が大きくなりやすいケースと小さくなりやすいケースは以下のとおりです。
| 影響度 | ケース |
|---|---|
| 大きい | クエリに影響するキーワードが方言の発音で別の意味に誤変換され、かつ文章として成立してしまう場合 |
| 小さい | 語尾など回答に無関係な部分が方言であったり、そこで誤変換が起きたりするだけの場合 |
方言対応に完璧な事前対策はありませんが、仕組みを理解した上で運用体制を整えることで、継続的に精度を向上させることができます。
特に全国規模のサービスでは、運用後のログ分析をもとにチューニングを続けることが現実的な方針です。










