
Amazon Connect での会話内容を日本語で要約し、コンタクト詳細に表示する方法
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
本記事では、Amazon Connect Contact Lensで文字起こしした内容を日本語で要約し、コンタクト詳細画面に表示する方法を紹介します。
Contact Lensには、会話内容の文字起こしと要約機能が標準で搭載されています。
ただし、要約機能は日本語に対応していません。
そこで、Contact Lensが文字起こしデータをS3に保存した際のトリガーで、AWS LambdaからAmazon Bedrockを利用して日本語の要約を生成します。
生成した要約は、コンタクト詳細画面の属性として保存することで、以下のように表示できます。
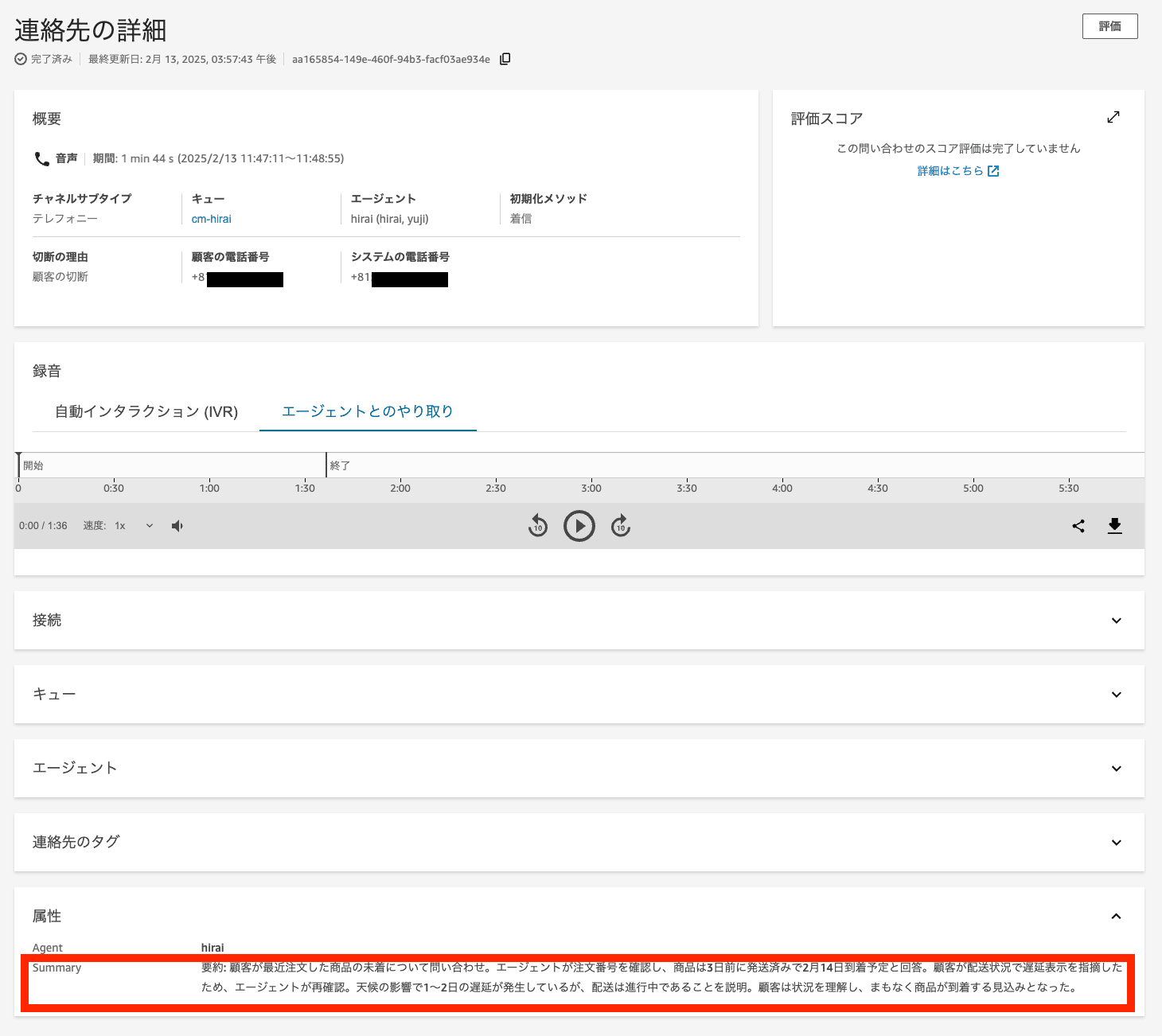
コンタクト詳細に要約文を表示
構成は以下の通りです。
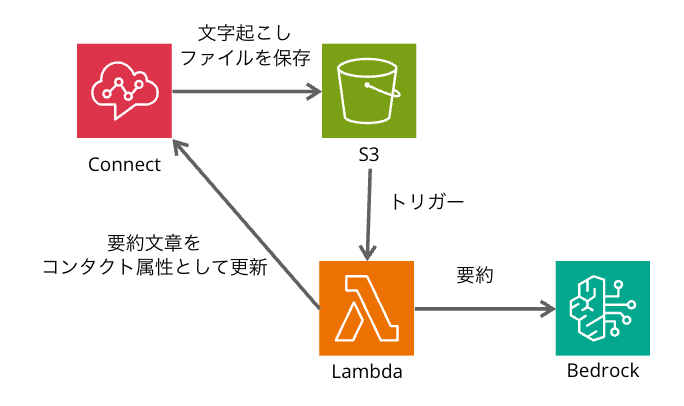
処理の流れは以下の通りです。
- Contact Lens が会話を文字起こしし、S3 に保存
- S3 の PUT イベントをトリガーに Lambda を実行
- Lambda が S3 から文字起こしデータを取得
- Bedrock で要約を生成
- Connect の update_contact_attributes API を使用し、コンタクト詳細に要約を保存
前提条件
- Connect インスタンスと S3 バケットを作成済み
- Contact Lens の会話分析を有効化
Lambda
Lambda関数の設定内容は以下の通りです。
- 名前:transcript-summarizer
- ランタイム: Python 3.13
- タイムアウト:20秒
- IAMロールに付与するポリシーは以下の通り(S3バケット名やConnect インスタンス名は環境に合わせて変更ください。)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::amazon-connect-xxxxxxxxxxx",
"arn:aws:s3:::amazon-connect-xxxxxxxxxxx/*"
]
},
{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "connect:UpdateContactAttributes",
"Resource": [
"arn:aws:connect:ap-northeast-1:111111111111:instance/3ff2093d-af96-43fd-b038-3c07cdd7609c",
"arn:aws:connect:ap-northeast-1:111111111111:instance/3ff2093d-af96-43fd-b038-3c07cdd7609c/contact/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
}
]
}
import json
import boto3
s3_client = boto3.client('s3')
connect_client = boto3.client('connect')
bedrock_client = boto3.client('bedrock-runtime')
CONNECT_INSTANCE_ID = "arn:aws:connect:ap-northeast-1:111111111111:instance/3ff2093d-af96-43fd-b038-3c07cdd7609c"
MODEL_ID = 'anthropic.claude-3-5-sonnet-20240620-v1:0'
def generate_summary(transcript):
prompt = f"""
以下の通話内容を、問い合わせの流れが分かりやすいように要約してください。
【要約のフォーマット】
1. 顧客の問い合わせ内容(何について問い合わせたか)
2. エージェントの対応(どのように対応したか)
3. 結論(最終的にどうなったか)
【通話内容】
{transcript}
【出力のルール】
- 箇条書きではなく、自然な文章で要約する
- できるだけ短く、簡潔にまとめる
- 重要な情報のみを含める
- 「まもなく到着予定」など、顧客が安心できる表現を含める
【出力例】
要約: 顧客が注文商品の配送遅延について問い合わせ。注文は3日前に発送され、2月14日到着予定だったが遅延中。天候の影響で一部地域に1~2日の遅延が発生。配送は進行中で、まもなく到着予定。
"""
response = bedrock_client.converse(
modelId=MODEL_ID,
messages=[{"role": "user", "content": [{"text": prompt}]}],
inferenceConfig={"maxTokens": 1000, "temperature": 0.5}
)
return response['output']['message']['content'][0]['text']
def extract_transcript_text(transcript_data):
return " ".join(
entry['Content']
for entry in transcript_data.get("Transcript", [])
if 'Content' in entry
)
def lambda_handler(event, context):
record = event['Records'][0]
bucket_name, object_key = record['s3']['bucket']['name'], record['s3']['object']['key']
response = s3_client.get_object(Bucket=bucket_name, Key=object_key)
transcript_data = json.loads(response['Body'].read().decode('utf-8'))
transcript_text = extract_transcript_text(transcript_data)
if not transcript_text:
print("No transcript found in the file.")
return
summary = generate_summary(transcript_text)
contact_id = transcript_data.get("CustomerMetadata", {}).get("ContactId")
if not contact_id:
print("No contact ID found. Check JSON structure.")
return
connect_client.update_contact_attributes(
InstanceId=CONNECT_INSTANCE_ID,
InitialContactId=contact_id,
Attributes={'Summary': summary}
)
return {
'statusCode': 200,
'body': 'Successfully processed transcript and updated contact attributes.'
}
このLambdaは、S3に保存された通話の文字起こしデータを読み取り、Bedrockを使用して要約を生成します。生成された要約は、Connectのコンタクト属性として保存されます。
主な処理の流れは以下の通りです。
- S3から文字起こしデータを取得
- Bedrockで要約を生成
- Connectのコンタクト属性を更新
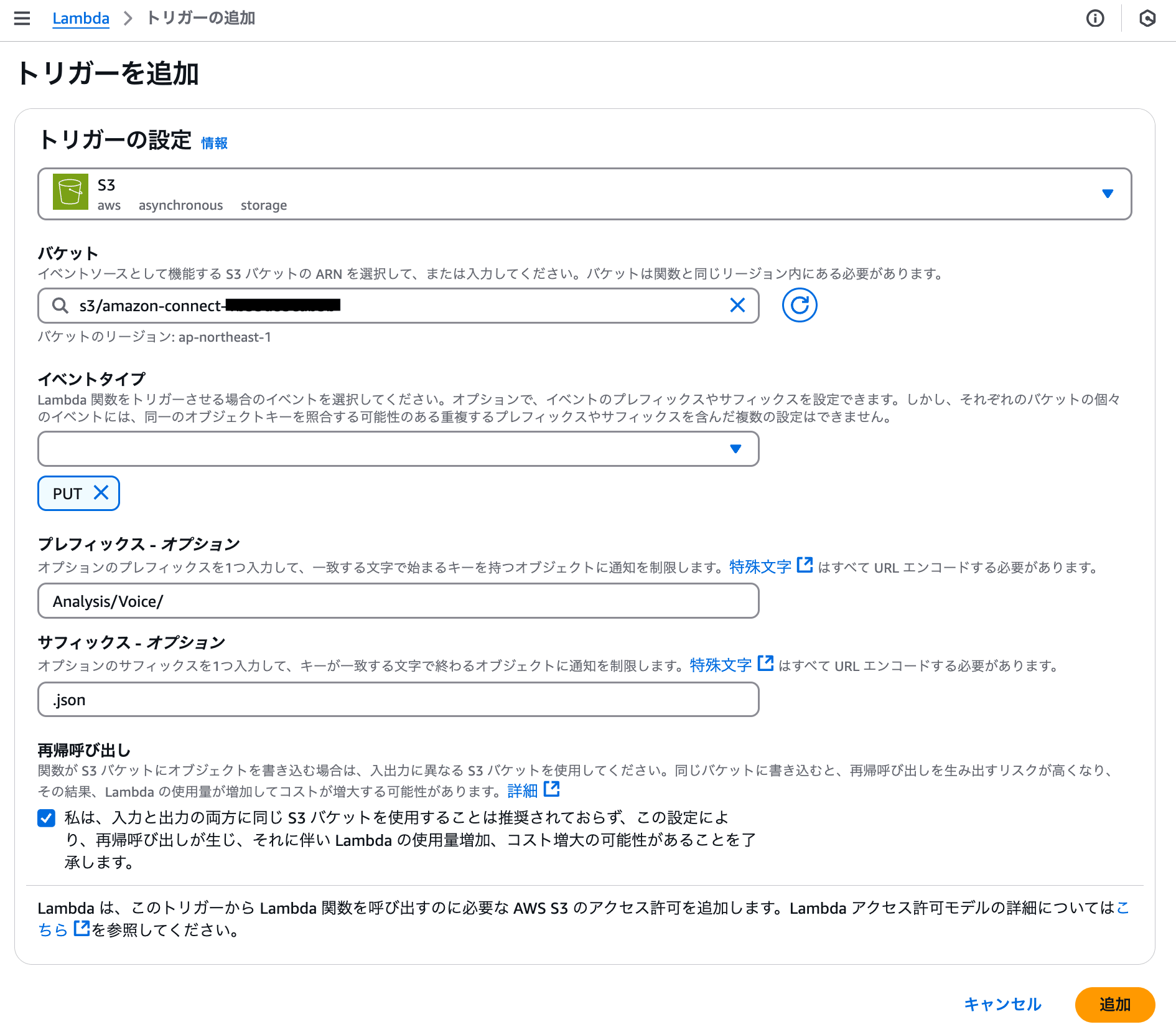
Lambdaのトリガー設定
Lambda関数のトリガー設定として、以下のようにS3バケットのイベントを指定します。
- バケット
- Contact Lensが保存するS3バケット
- イベントタイプ
- PUT
- プレフィックス
- Analysis/Voice/
- サフィックス
- .json
- .json
音声通話とチャットの文字起こしデータは、以下のプレフィックスパターンでS3に保存されます。
- 音声通話の分析結果(JSON)
- /connect-instance-bucket/Analysis/Voice/YYYY/MM/DD/contact’s_ID_analysis_YYYY-MM-DDTHH:MM:SSZ.json
- チャットの分析結果(JSON)
- /connect-instance-bucket/Analysis/Chat/YYYY/MM/DD/contact’s_ID_analysis_YYYY-MM-DDTHH:MM:SSZ.json
動作確認
実際に電話での会話を行い、システムの動作を確認します。
電話での会話が終了すると、システムが自動的に会話を分析し、以下のようにコンタクト詳細画面に要約文が表示されました。会話2分程度した場合、S3バケットに保存されるのに、7分程度かかりました。そのため会話終了後、要約文が表示されるまでに7分程度かかりました。
コンタクト詳細に要約文を表示
要約: 顧客が最近注文した商品の未着について問い合わせ。エージェントが注文番号を確認し、商品は3日前に発送済みで2月14日到着予定と回答。顧客が配送状況で遅延表示を指摘したため、エージェントが再確認。天候の影響で1~2日の遅延が発生しているが、配送は進行中であることを説明。顧客は状況を理解し、まもなく商品が到着する見込みとなった。
なお、コンタクト属性では 32,768 byte までしか保存できませんので、長文を保存する場合、注意ください。
You can have up to 32,768 UTF-8 bytes across all attributes for a contact. Attribute keys can include only alphanumeric, dash, and underscore characters.
https://docs.aws.amazon.com/ja_jp/connect/latest/APIReference/API_UpdateContactAttributes.html








