
Amazon ECSのコンテナヘルスチェックを利用してEFSへの接続性をチェックし通知してみました
初めに
Amazon ECSではALB側のヘルスチェックとは別にコンテナヘルスチェックが用意されています。
コンテナヘルスチェックは指定した任意のコマンドを定期的に実行し終了コードが0であれば成功(OK)扱い、それ以外のコードもしくはタイムアウトが発生すると失敗(NG)扱いとなります。
ヘルスチェックNGとなった場合はALBのヘルスチェック同様にそのタスクの置き換えが行われます。
指定は任意なためWebサーバ目的で利用している場合はALB側のヘルスチェックを利用しており、こちらは未使用ということも多く普段の用途によっては忘れがちな機能だったりします。
最近ECSからEFSに接続できることをしっかり監視しておきたいなぁという話がありどうしようか、と考えていたところふとこちらの存在を思い出したので利用してチェックしてみます。
EFSのマウントポイントの名前解決はAZを超えない
Amazon EFSは複数のAZにマウントポイントを配置することができますがEFSのDNS名を名前解決した場合は所属するAZのマウントポイントのIPのみを返す仕様となっています。
そのため万が一マウントポイントに障害が発生した場合は別AZのマウントポイントへ自動的に切り替わるということはありません。
https://docs.aws.amazon.com/ja_jp/efs/latest/ug/disaster-recovery-resiliency.html
Amazon EFS ファイルシステムは、 AWS リージョン内の1つ以上のアベイラビリティーゾーンの障害に対して回復力があります。マウントターゲットは高い可用性を実現できるように設計されています。高可用性と他の AZ へのフェイルオーバーを設計する場合、各 AZ のマウントターゲットの IP アドレスと DNS は静的ですが、これらは複数のリソースによってバッキングされた冗長コンポーネントであることに注意してください。
ただ、あくまでAZを超えた復旧がされないだけであり裏側の仕組みで冗長化されており必要に応じて復旧はされるためそこまで極端にこの仕様を気にする必要はない部分ではあります。
EFSへの接続がNGでもタスクを落としたくなかった
前述の通り自動復旧は行われるため一応切断を拾える仕組みにしておきたいけど、なんらかの事情でタスク自体は落としたくないなぁという時もあるかもしれません(今回そのケースでした)。
通常であればヘルスチェックは問題のあるコンポーネントを検知しそれを入れ替えて継続ということを目的として利用されますが、一応少し工夫するとチェックはしつつも落とさないということは実現可能です。
(結果としてNGが出ないだけで一応死活はチェックしているので間違いではないのですが...)
今回外形監視するほどでもないし、ALBのヘルスチェックに反応できるようにアプリ側に組み込むほどでもない...という形でしたのでこちらを使って少し無理やり実装してみます。
実装・検証
今回はnginxのコンテナにEFSをマウントし、そこに接続がNGとなった場合に通知を飛ばすということをしてみます。
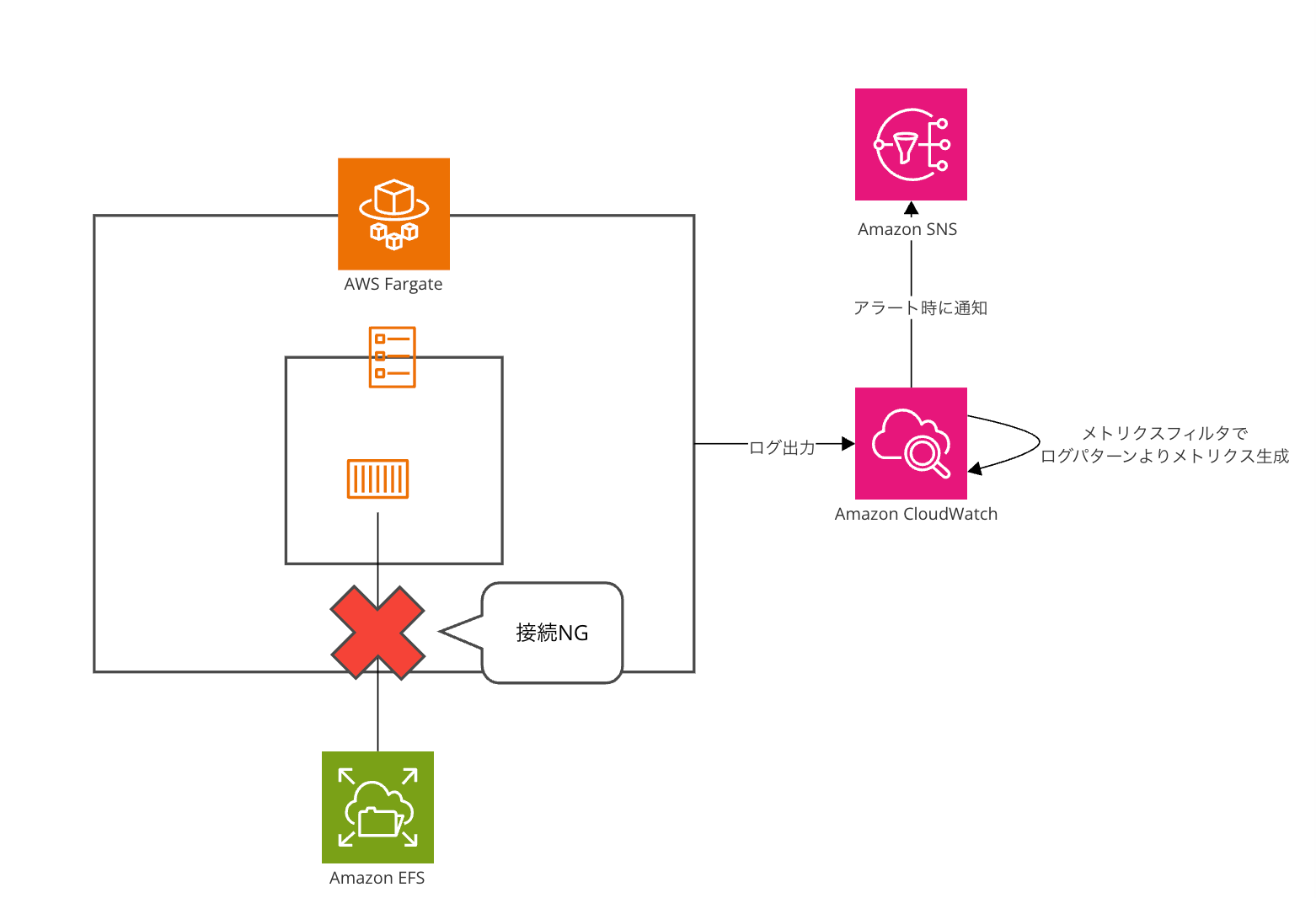
なお、ECSの仕様上タスクの起動処理時にタスクが立ち上がっていない場合ヘルスチェック以前の部分でタスクが立ち上がらずダウンするためこちらは対象外となります。
タスク定義
今回のポイントとなるのヘルスチェック部分は以下の通りです。
"command": [
"CMD-SHELL",
"timeout 10 ls /mnt/efs >> /dev/null 2>&1 && echo 'EFS health check: OK' >> /proc/1/fd/1 || echo 'EFS health check: NG' >> /proc/1/fd/2"
]
lsコマンドでefsをマウントしているディレクトリへの接続性をチェックしますが、lsコマンドにはタイムアウト時間がないため通常そのままではヘルスチェックのタイムアウトまで待機した上で失敗(=タスクダウン)となります。
そのためtimeoutコマンド経由で実行してヘルスチェックのタイムアウト前に早期終了させた上で、||演算子を使い終了コードを0で終わらせつつチェック用のログを出力させます。
厳密にはこの書き方lsが成功してもOK側のechoが失敗するとNG側のechoに派生する、NG側のecho自体が落ちると本当にヘルスチェックNGになるので注意してください。|| exit 0で吸収し必ず正常終了させるのも一つだと思います。
全体像は以下の通りです。
{
"family": "test-task",
"containerDefinitions": [
{
"name": "nginx",
"image": "public.ecr.aws/nginx/nginx:1.27-bookworm",
"cpu": 0,
"portMappings": [],
"essential": true,
"environment": [],
"mountPoints": [
{
"sourceVolume": "efs-volume",
"containerPath": "/mnt/efs",
"readOnly": false
}
],
"volumesFrom": [],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/test-task/test-task",
"awslogs-create-group": "true",
"awslogs-region": "ap-northeast-1",
"awslogs-stream-prefix": "ecs"
},
"secretOptions": []
},
"healthCheck": {
"command": [
"CMD-SHELL",
"timeout 10 ls /mnt/efs >> /dev/null 2>&1 && echo 'EFS health check: OK' >> /proc/1/fd/1 || echo 'EFS health check: NG' >> /proc/1/fd/2"
],
"interval": 60,
"timeout": 60,
"retries": 10
},
"systemControls": []
}
],
"taskRoleArn": "arn:aws:iam::xxxxx:role/test-ecs-exec-role",
"executionRoleArn": "arn:aws:iam::xxxxx:role/ecsTaskExecutionRole",
"networkMode": "awsvpc",
"volumes": [
{
"name": "efs-volume",
"efsVolumeConfiguration": {
"fileSystemId": "fs-xxxxx",
"rootDirectory": "/",
"transitEncryption": "ENABLED",
"transitEncryptionPort": 2049
}
}
],
"placementConstraints": [],
"requiresCompatibilities": [
"FARGATE"
],
"cpu": "256",
"memory": "512",
"runtimePlatform": {
"cpuArchitecture": "X86_64",
"operatingSystemFamily": "LINUX"
}
}
この状態でEFSのマウントポイントのセキュリティグループをECSからアクセスできないものにすると以下のようにアクセスNGのログが出ます。
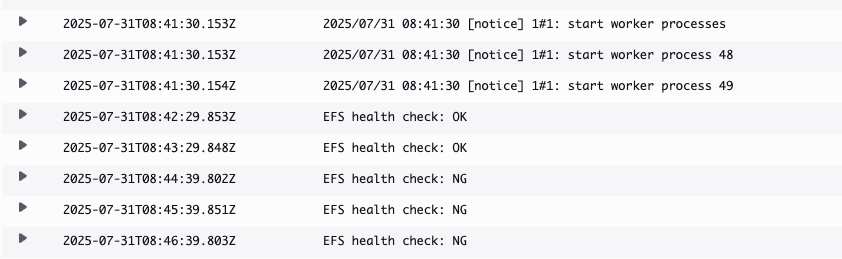
検知〜通知
上記のような設定をするとヘルスチェックが常に成功してしまう関係でコンテナのヘルスチェック結果では判別できないため先ほどのログをメトリクスフィルタを利用してメトリクス化してCloudWatch Alarmで通知させます。
以下のようにNGが出た場合に値が増えるようなメトリクスを作成します。
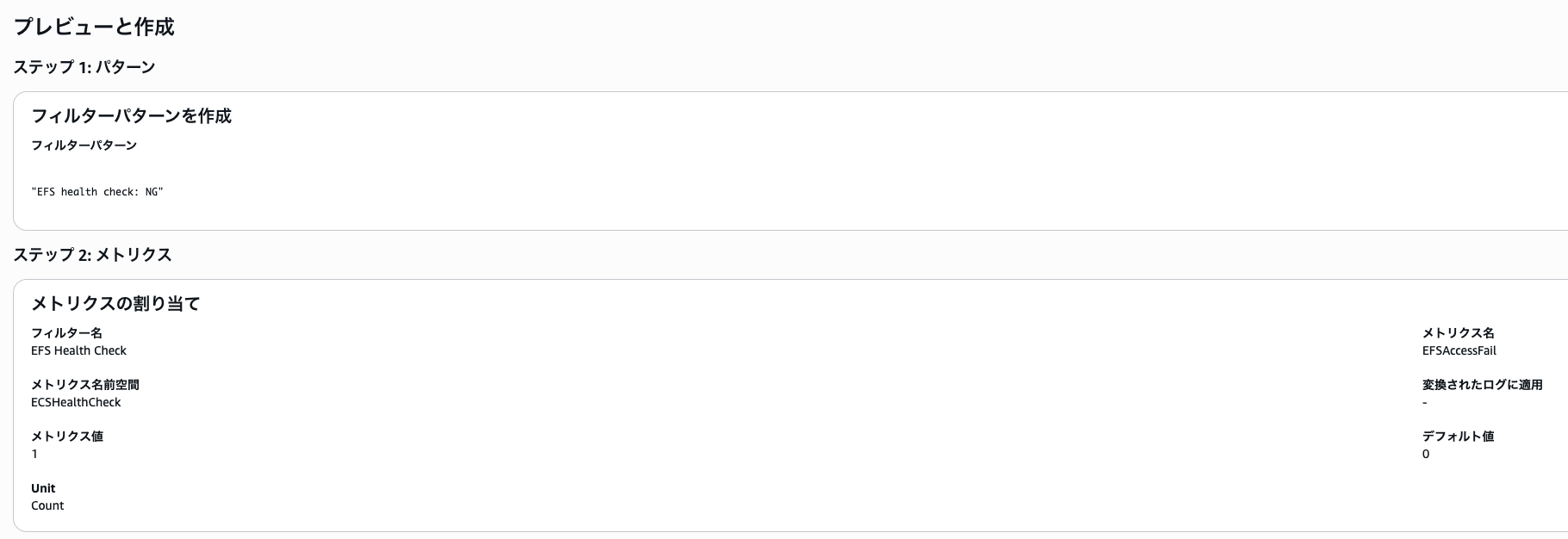
これに対して値が上がった時にNGが出るようにアラームを設定します。
時間あたりのデータポイント数はヘルスチェックの実行頻度に応じますのでそちらと合わせこの辺りは調整しましょう。
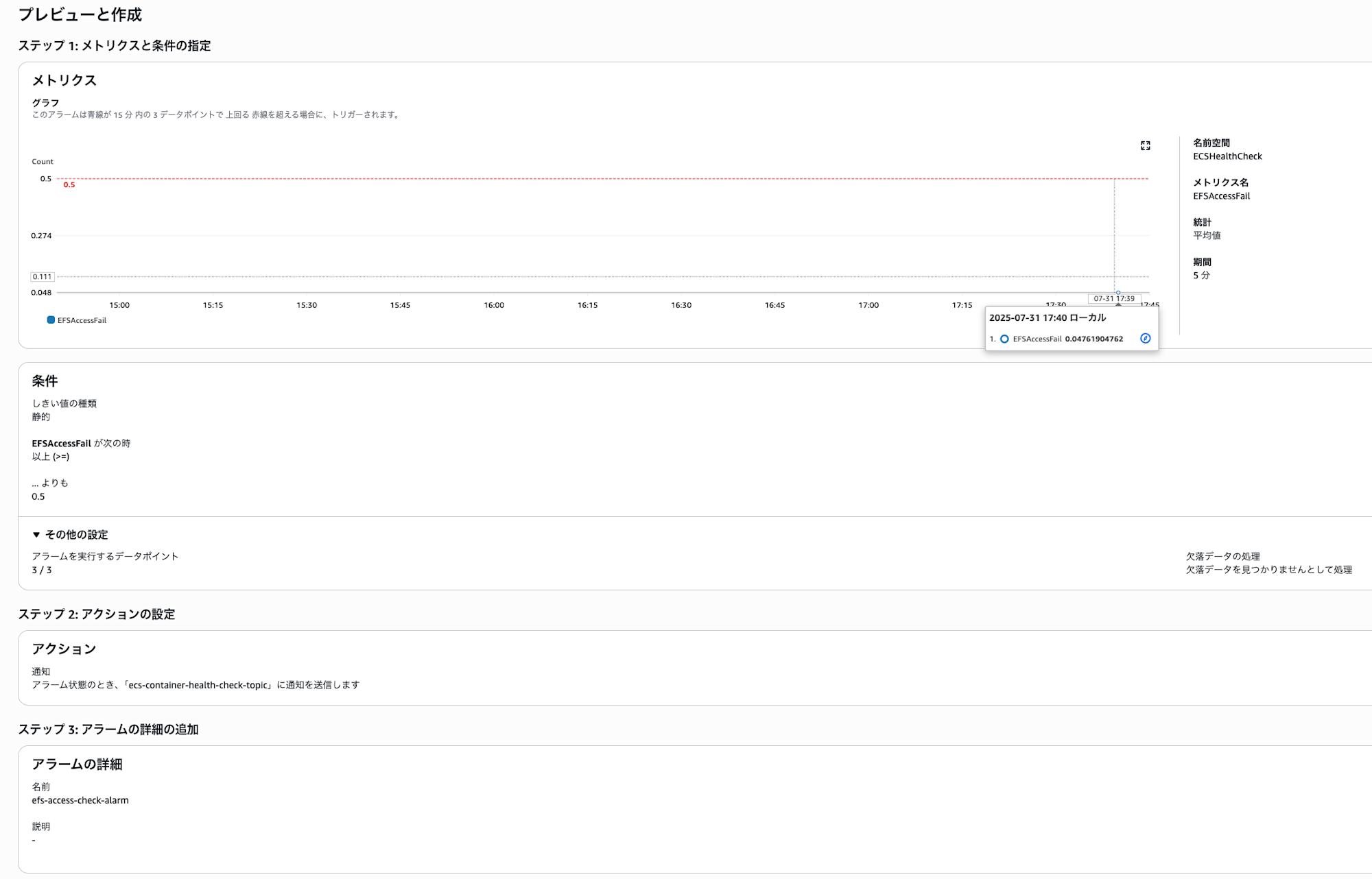
あとはNGが出続ければアラームが反応しメールが飛ぶのでこれでOKです
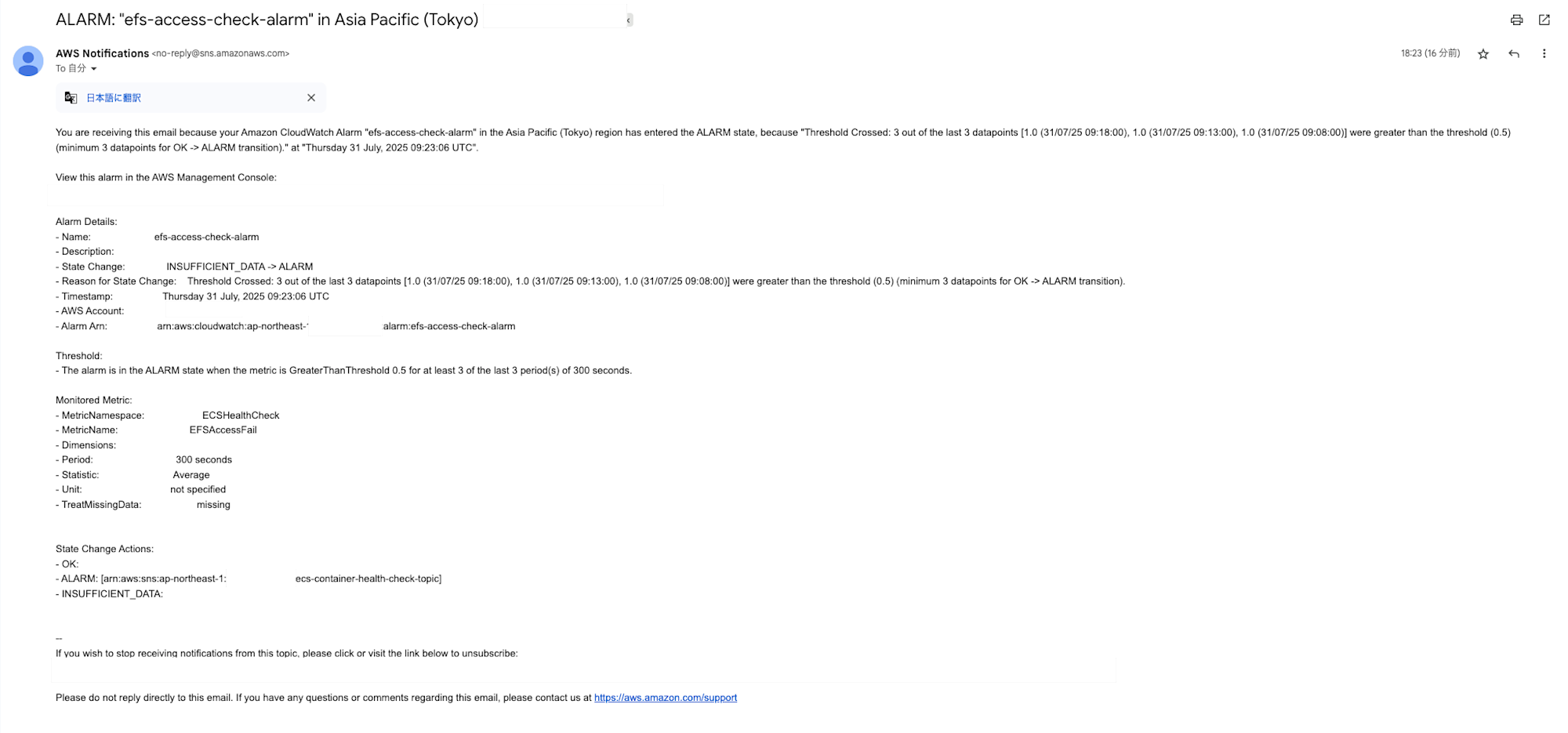
今回はタスクが単一の場合ですので複数タスクが立ち上がる場合は閾値なりタスクIDを含めて判別できるようにするなり調整するような形の方が良いかもしれません。
余談:ヘルスチェックのコマンドで出力したログはPID:1のファイルディスクリプタに出力する必要がある?
今回コンテナヘルスチェックでechoを最初流した際に、あれ...ログがでない...となってました。
timeout 10 ls /mnt/efs >> /dev/null 2>&1 && echo 'EFS health check: OK' || echo 'EFS health check: NG'
これに関して色々試してみたりドキュメントを確認した結果、テキストとして明確には書かれているわけではないのですが以下に記載があるコマンドにあるようにPID1のプロセスの標準出力(fd/1)に対して出力する必要があります(おそらく2(標準エラー)でも良いはず)。
厳密に言えばその子プロセスにも継承されるものもあるためそちらでも良いとは思われるのですが、通常ENTRYPOINTで指定されたコマンド以外はPIDが動的になるためあえてそちらを選択する意味はないとは思います。
見える範囲で少し追跡してみる
そういうものとしか言いようがない、という部分はあるのですがとは見えるところまで見ておきたいというのはあったので少し確認しておきました。
ヘルスチェックコマンドでsleepを実行し滞留しているそのコマンドのプロセスを調査します。調査のために不足しているコマンドは必要に応じて追加してます。
結論としてはコンテナ内でパイプが片側しか見えなかったのであまり収穫はなく...というところです。
プロセスの状態
psコマンドの実行以下の通りになっていました。
sleepが一つだけ/bin/sh経由で実行されてますがSTARTの時刻関係を見る限りタイムアウト前のヘルスチェックコマンドと推定しています。おそらくタイムアウト時に/bin/sh経由で実行され流もののタイムアウトの際に親となるそのプロセスが残るものの子プロセスが孤立して残り複数のsleepコマンドが単独で残ってるのではないかなと思います。
root@ip-192-168-4-197:/# ps aufx
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 280 0.0 0.0 2580 908 ? Ss 05:14 0:00 /bin/sh -c sleep 10000
root 286 0.0 0.0 2488 876 ? S 05:14 0:00 \_ sleep 10000
root 19 0.0 1.5 1770516 14284 ? Ssl 05:11 0:00 /managed-agents/execute-command/amazon-ssm-agent
root 53 0.0 3.1 2010036 30272 ? Sl 05:11 0:00 \_ /managed-agents/execute-command/ssm-agent-worker
root 64 0.2 2.6 1852244 25392 ? Sl 05:11 0:00 \_ /managed-agents/execute-command/ssm-session-worker ecs-execute-command-ivi634q6788bqjn3szy7eyt2z8
root 75 0.0 0.3 4612 3668 pts/0 Ss 05:11 0:00 \_ /bin/bash
root 288 0.0 0.4 8540 4304 pts/0 R+ 05:14 0:00 \_ ps aufx
root 1 0.0 0.7 11464 7292 ? Ss 05:11 0:00 nginx: master process nginx -g daemon off;
root 27 0.0 0.0 2488 888 ? S 05:11 0:00 sleep 10000
nginx 48 0.0 0.2 11928 2744 ? S 05:11 0:00 nginx: worker process
nginx 49 0.0 0.2 11928 2744 ? S 05:11 0:00 nginx: worker process
root 275 0.0 0.0 2488 880 ? S 05:13 0:00 sleep 10000
ヘルスチェックコマンドのファイルディスクリプタ(FD)の先
$ ls -l /proc/27/fd/
total 0
lr-x------ 1 root root 64 Jul 14 05:31 0 -> /dev/null
l-wx------ 1 root root 64 Jul 14 05:31 1 -> 'pipe:[32401]'
l-wx------ 1 root root 64 Jul 14 05:31 2 -> 'pipe:[32402]'
$ ls -l /proc/275/fd/
total 0
lr-x------ 1 root root 64 Jul 14 05:31 0 -> /dev/null
l-wx------ 1 root root 64 Jul 14 05:31 1 -> 'pipe:[45954]'
l-wx------ 1 root root 64 Jul 14 05:31 2 -> 'pipe:[45955]'
$ ls -l /proc/1/fd
total 0
lrwx------ 1 root root 64 Jul 14 05:32 0 -> /dev/null
l-wx------ 1 root root 64 Jul 14 05:32 1 -> 'pipe:[35067]'
lrwx------ 1 root root 64 Jul 14 05:32 10 -> 'socket:[32531]'
l-wx------ 1 root root 64 Jul 14 05:32 2 -> 'pipe:[35068]'
lrwx------ 1 root root 64 Jul 14 05:32 3 -> 'socket:[32528]'
l-wx------ 1 root root 64 Jul 14 05:32 4 -> 'pipe:[35068]'
l-wx------ 1 root root 64 Jul 14 05:32 5 -> 'pipe:[35067]'
lrwx------ 1 root root 64 Jul 14 05:32 6 -> 'socket:[32526]'
lrwx------ 1 root root 64 Jul 14 05:32 7 -> 'socket:[32527]'
lrwx------ 1 root root 64 Jul 14 05:32 8 -> 'socket:[32529]'
lrwx------ 1 root root 64 Jul 14 05:32 9 -> 'socket:[32530]'
pipeの先となるinodeを確認してみましたが入力側となるヘルスチェック側のコマンドは確認できましたが、取得(読み取り)側はなさそうです。基盤側でとってるのでしょうか?
$ lsof | grep -e 32401 -e 32402
sleep 27 root 1w FIFO 0,11 0t0 32401 pipe
sleep 27 root 2w FIFO 0,11 0t0 32402 pipe
そもそもヘルスチェック側のechoがうまく走っていない可能性もあるので念のためECS Exec上で直接ヘルスチェックコマンドの標準出力にデータを流し込んでみましたが、なぜかECS Execのセッション自体が落ちます。その後同じタスクIDで再接続すると問題なく繋がるのでコンテナ自体がクラッシュしているわけではなさそうです。
## PID1プロセス側も特に何か出るわけではない
$ echo "Hello World" >> /proc/1/fd/1
$
## ヘルスチェック側のプロセスに流し込むとECS exec自体が落ちるこれは一体...
$ echo "Hello World" >> /proc/27/fd/1
Exiting session with sessionId: ecs-execute-command-4it23rvigjxz3uc5h2valjb2vu.
PID 1の標準出力に流し込んでもECS Execの接続が落ちるわけではないので少なくともヘルスチェックとENTRYPOINTで実行されたプロセスのパイプの裏側の処理は別物になっていそうです。
この辺りはFargate基盤ではなくEC2基盤にすると何か見えたりするんでしょうか?どこかで試す機会があれば確認してみようかなと思います。
終わりに
ECSのヘルスチェックを通してタスクダウンをさせない形でEFSのチェックを実現してみました。
本来の使い方とは少し違う形にはなるのであまり好ましくないような気もするのですが、使う予定がなく浮いてるのであれば外形監視用のサーバを建てる必要もないため一つ選択肢になるのではないでしょうか。
今回は||演算子でエラーを吸収する形でダウンを回避しましたが、そのまま終了コード0以外で終わらせる形にすることで復旧を期待可能です。
ただなんらかタスク側の異常でマウントがうまくできないと言う場合でこれで解消可能な余地があるものの、マウントポイント側の長期的な問題の場合、設定や状況によっては落ちたタスクまた同一のAZで立ち上がるがエラーとなり別AZで起動するまで繰り返し続けてしまうリスクもあります。
タイムアウト周りの処理やキャッシュ周りに問題がある場合はそれを利用した復旧が有効な場合もあるかもしれませんが、EFSのマウントポイントは高可用性が確保されているとされているためそれに期待して復旧というのが無難とは思います。
どうしてもそういった場合の復旧も準備しておかないとダメな事情がある場合、IP直アクセスであれば別AZのマウントポイントに繋ぐことはできるのでその辺りを駆使しタスクは維持しつつ別AZ側に繋ぎに行くような形にする等どうしても自前でなんとかする形になるかなぁと思います。










