![[アップデート] Amazon ECS がコンテナのヘルスステータスを CloudWatch メトリクスで確認できるようになりました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-6d4fdf3578638cab4e6e4655b3d692aa/15a803840d72679e6593006354d5766b/amazon-elastic-container-service?w=3840&fm=webp)
[アップデート] Amazon ECS がコンテナのヘルスステータスを CloudWatch メトリクスで確認できるようになりました
いつ、どのコンテナでヘルスチェックが失敗したのか把握したい
こんにちは、のんピ(@non____97)です。
皆さんはいつ、どのコンテナでヘルスチェックが失敗したのか把握したいなと思ったことはありますか? 私はあります。
従来コンテナのヘルスチェックは現時点の状態しか分かりませんでした。必須コンテナであればタスク自体がUnhealthyになりタスク自体を再作成しようとしますが、そうではない場合は状態の後追いが難しいところでした。
今回アップデートにより Amazon ECS がコンテナのヘルスステータスを CloudWatch メトリクスで確認できるようになりました。
Container Insights with Enhanced Observability が有効なECSクラスターにおいて、タスク定義でコンテナヘルスチェックの設定を行なっていると、UnHealthyContainerHealthStatusメトリクスがPUTされるようになります。
これにより、いつ、どのコンテナでヘルスチェックが失敗したのか簡単に把握できるようになりました。
実際に確認してみます。
やってみた
検証環境
検証環境は以下のとおりです。
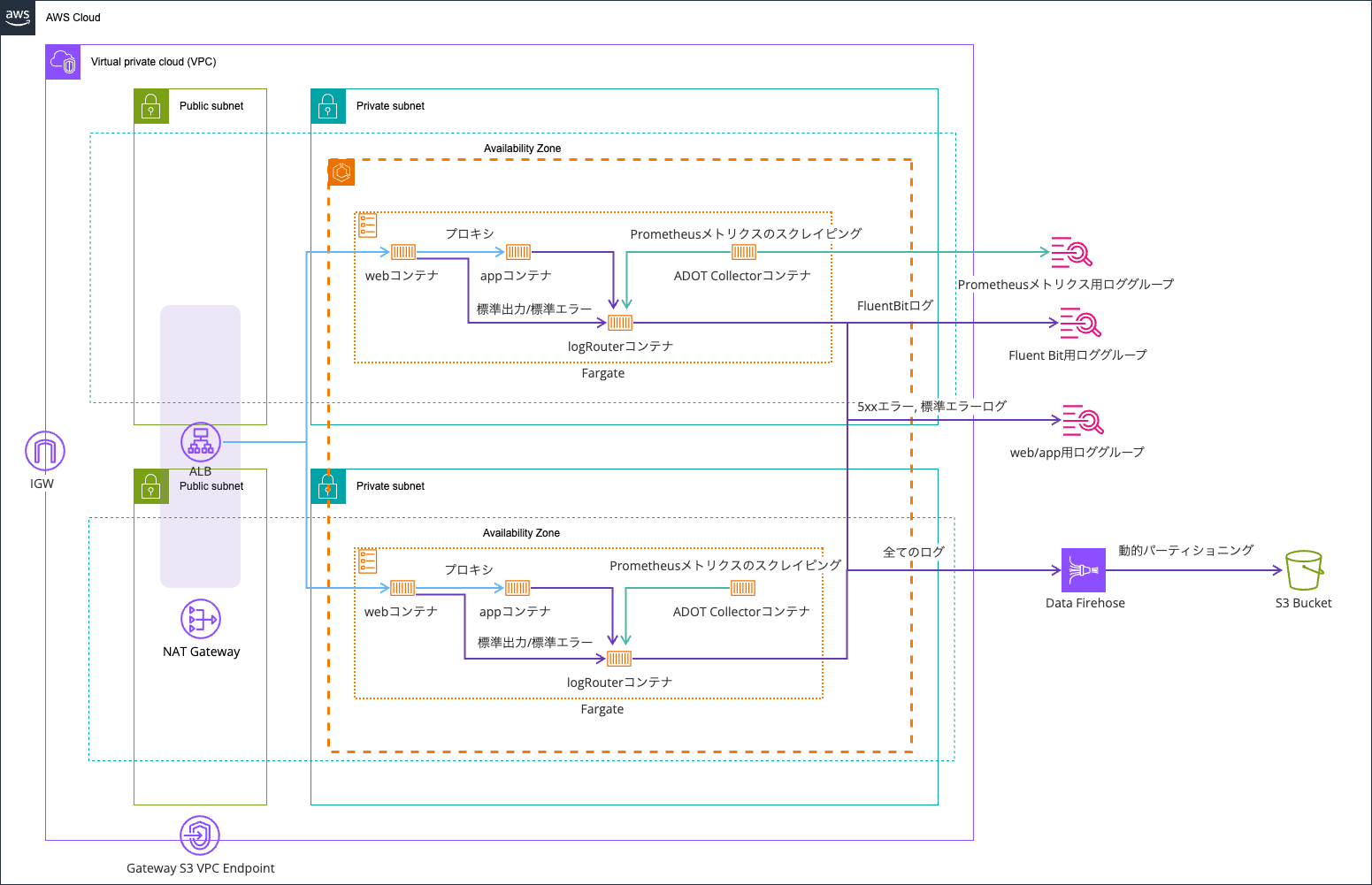
ベースは以下記事で使用したものを流用します。
コードは以下リポジトリに保存しています。
タスク定義のヘルスチェック周りは以下のようになっています。
{
.
.
(中略)
.
.
"healthCheck": {
"command": [
"CMD-SHELL",
"wget -q -O - http://localhost:3000/health || exit 1"
],
"interval": 10,
"timeout": 3,
"retries": 3,
"startPeriod": 5
},
.
.
(中略)
.
.
}
メトリクスの確認
デプロイ完了後、メトリクスの状態を確認しましょう。
コンテナのヘルスステータスを確認すると、正常になっていました。

CloudWatchのコンソールでUnHealthyContainerHealthStatusでフィルタリングすると、ECS/ContainerInsights名前空間に以下ディメンションがあることが分かります。
- ClusterName
- ClusterName, ContainerName, ServiceName
- ClusterName, ContainerName, ServiceName, TaskId
- ClusterName, ContainerName, TaskDefinitionFamily
- ClusterName, ContainerName, TaskDefinitionFamily, TaskId
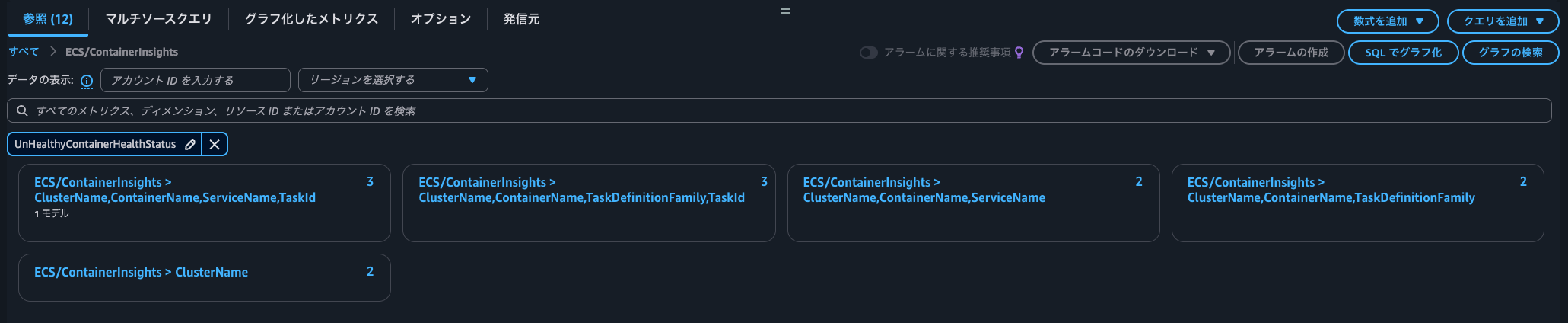
どのタスクのコンテナについてヘルスチェックが失敗しているのか簡単に確認できそうです。
実際にメトリクスを確認すると、現在は0となっていました。ただし、タスク起動時はアプリケーションが立ち上がっていなかったからか1とヘルスチェックに失敗していたようです。ヘルスチェックの猶予期間や再試行回数を見直すきっかけになりそうです。
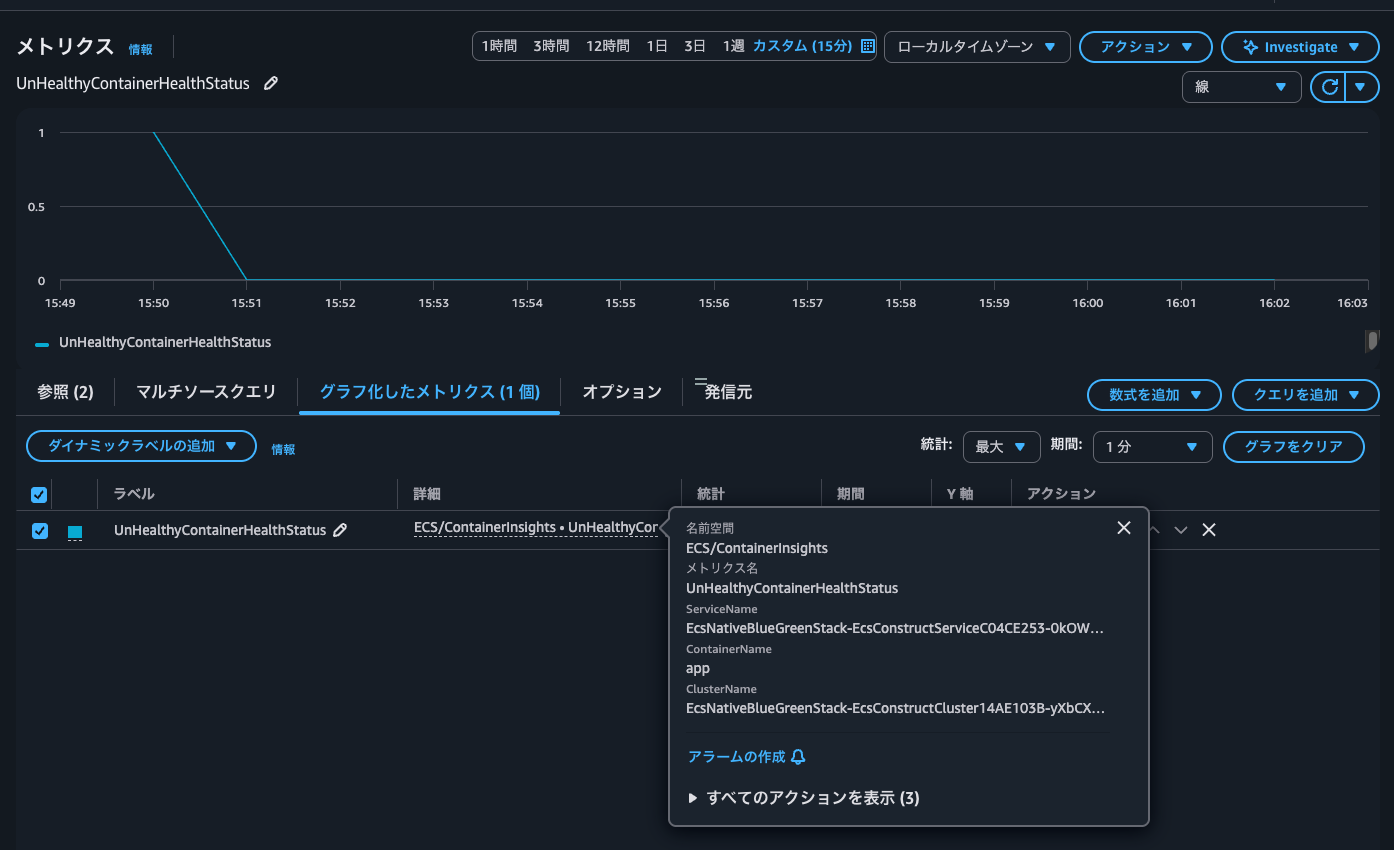
こちらのメトリクスはEMF形式のログによって表示されています。
/aws/ecs/containerinsights/EcsNativeBlueGreenStack-EcsConstructCluster14AE103B-yXbCXFNJC70r/performanceというロググループのログストリームFargateTelemetry-7742に以下EMF形式のログが出力されていました。
{
"Version": "0",
"Type": "Container",
"ContainerName": "app",
"TaskId": "341e205ed4204d26b4184e08cf4d42f9",
"TaskDefinitionFamily": "EcsNativeBlueGreenStackEcsConstructTaskDefinitionF683F4B2",
"TaskDefinitionRevision": "75",
"ServiceName": "EcsNativeBlueGreenStack-EcsConstructServiceC04CE253-0kOWEJKBOsNT",
"ClusterName": "EcsNativeBlueGreenStack-EcsConstructCluster14AE103B-yXbCXFNJC70r",
"Image": "<AWSアカウントID>.dkr.ecr.us-east-1.amazonaws.com/cdk-hnb659fds-container-assets-<AWSアカウントID>-us-east-1:4c7ba85e7238bc3d718b237eb86f47a20d829dc483700d0c1def4c1480761ef1",
"ContainerKnownStatus": "PENDING",
"ContainerHealthStatus": "HEALTHY",
"Timestamp": 1769842260000,
"CpuUtilized": 3.7039804077148433,
"ContainerCpuUtilized": 3.7039804077148433,
"CpuReserved": 256,
"ContainerCpuReserved": 256,
"ContainerCpuUtilization": 1.4468673467636106,
"MemoryUtilized": 81,
"ContainerMemoryUtilized": 81,
"MemoryReserved": 512,
"ContainerMemoryReserved": 512,
"ContainerMemoryUtilization": 15.8203125,
"StorageReadBytes": 95830016,
"ContainerStorageReadBytes": 95830016,
"StorageWriteBytes": 0,
"ContainerStorageWriteBytes": 0,
"NetworkRxBytes": 91,
"ContainerNetworkRxBytes": 91,
"NetworkRxDropped": 0,
"NetworkRxErrors": 0,
"NetworkRxPackets": 42729,
"NetworkTxBytes": 250,
"ContainerNetworkTxBytes": 250,
"NetworkTxDropped": 0,
"NetworkTxErrors": 0,
"NetworkTxPackets": 1771,
"UnHealthyContainerHealthStatus": 0,
"CloudWatchMetrics": [
{
"Namespace": "ECS/ContainerInsights",
"Metrics": [
{
"Name": "ContainerCpuUtilized",
"Unit": "None"
},
{
"Name": "ContainerCpuReserved",
"Unit": "None"
},
{
"Name": "ContainerCpuUtilization",
"Unit": "Percent"
},
{
"Name": "ContainerMemoryUtilized",
"Unit": "Megabytes"
},
{
"Name": "ContainerMemoryReserved",
"Unit": "Megabytes"
},
{
"Name": "ContainerMemoryUtilization",
"Unit": "Percent"
},
{
"Name": "ContainerStorageReadBytes",
"Unit": "Bytes/Second"
},
{
"Name": "ContainerStorageWriteBytes",
"Unit": "Bytes/Second"
},
{
"Name": "ContainerNetworkRxBytes",
"Unit": "Bytes/Second"
},
{
"Name": "ContainerNetworkTxBytes",
"Unit": "Bytes/Second"
},
{
"Name": "UnHealthyContainerHealthStatus",
"Unit": "None"
}
],
"Dimensions": [
[
"ClusterName"
],
[
"ServiceName",
"ContainerName",
"ClusterName"
],
[
"ContainerName",
"ClusterName",
"TaskDefinitionFamily"
],
[
"TaskId",
"ServiceName",
"ContainerName",
"ClusterName"
],
[
"TaskId",
"ContainerName",
"ClusterName",
"TaskDefinitionFamily"
]
]
}
]
}
試しに異常時の状態も確認します。
ヘルスチェックに失敗するように変更してしばらく待つと異常となりました。

UnHealthyContainerHealthStatusは1となっていますね。
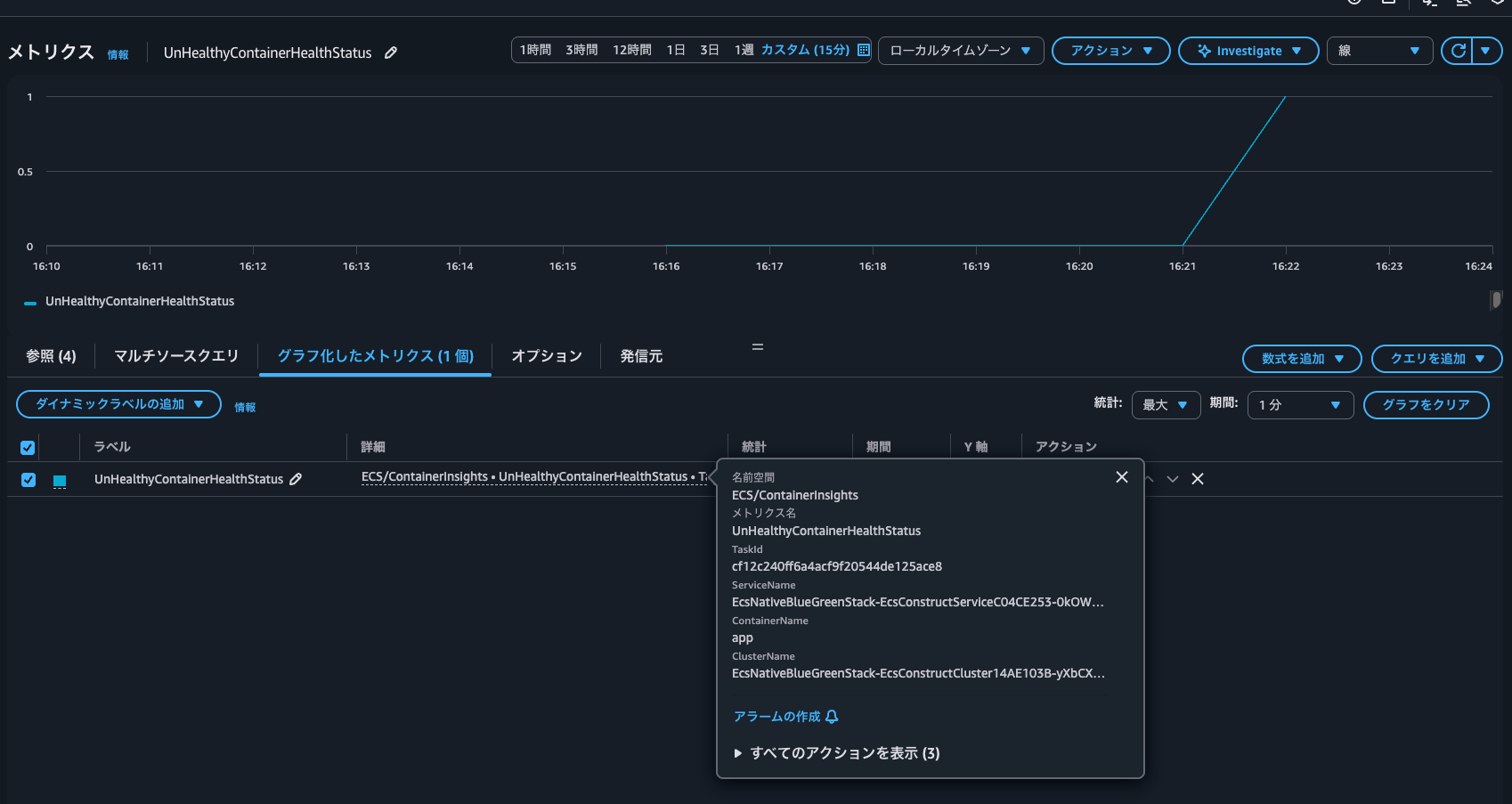
ECSサービスのイベントを確認すると、service EcsNativeBlueGreenStack-EcsConstructServiceC04CE253-0kOWEJKBOsNT has started 1 tasks: task 4dfa5dc2f76348f2ae9d9c22a48d7dca. Amazon ECS replaced 1 tasks due to an unhealthy status.と、このコンテナは必須コンテナであったため、新規タスクを作成し入れ替えようとしていることが分かります。ただし、具体的にどのコンテナなのかをここから判断することは難しいです。そういったときにはぜひUnHealthyContainerHealthStatusを使うと良いでしょう。

コンテナ停止に素早く気づいたり、タスク停止時のトラブルシューティングをするときに
Amazon ECS がコンテナのヘルスステータスを CloudWatch メトリクスで確認できるようになりました。
コンテナ停止に素早く気づいたり、タスク停止時のトラブルシューティングをするときに活躍しそうです。
何かしらのコンテナが停止したことに通知をしたい場合は、CloudWatch Metrics Insights Alarmを使ってGROUP BYで1つのアラームにコンテナごとの複数コントリビューターを用意すると、通知の内容からで素早く状況を整理することができると考えます。 (料金は要注意)
この記事が誰かの助けになれば幸いです。
以上、クラウド事業本部 コンサルティング部の のんピ(@non____97)でした!










