
อัพเดทบริการ Amazon Personalize ในปี 2024
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
บทความนี้แปลมาจากบทความภาษาญี่ปุ่นที่ชื่อว่า AWS入門ブログリレー2024〜Amazon Personalize編〜 โดยเจ้าของบทความนี้คือ คุณ niino
Amazon Personalize คืออะไร
บริการ Machine Learning แบบ Fully Managed ที่ให้คำแนะนำแบบส่วนบุคคลสำหรับผู้ใช้ การนำระบบแนะนำนี้มาใช้จะช่วยเพิ่มอัตราการคลิกของสินค้า สามารถสร้างมาตรการส่งเสริมการขายที่มีประสิทธิภาพมากขึ้นสำหรับผู้ใช้แต่ละราย และสามารถสร้างเส้นทางที่นำไปสู่การซื้อได้
ยกตัวอย่างเช่น ในกรณีของเว็บไซต์ E-commerce สามารถใช้ Amazon Personalize เพื่อให้บริการระบบแนะนำในรูปแบบต่างๆ ดังต่อไปนี้
- คำแนะนำตามประวัติการซื้อสินค้า: แบบอิงสินค้า (Item-based)
- "สินค้าแนะนำสำหรับผู้ที่ซื้อสินค้านี้"
- คำแนะนำตามคุณลักษณะของผู้ใช้: แบบอิงผู้ใช้ (User-based)
- "สินค้าที่แนะนำสำหรับคุณ"
- การแสดงการจัดอันดับแบบส่วนบุคคล
- เช่น หากมีสินค้าแนะนำ 10 รายการ ลำดับการแสดงผลจะแตกต่างกันไปตามแต่ละผู้ใช้
การติดตั้งระบบแนะนำเหล่านี้ต้องใช้ความรู้และประสบการณ์ด้าน Machine Learning แต่คนที่มีทักษะในด้านนี้มีจำนวนจำกัด ด้วยเหตุนี้ การใช้ Amazon Personalize ซึ่งเป็นบริการแบบ Fully Managed จึงช่วยให้สามารถนำเข้าข้อมูลและสร้างโมเดลได้อย่างง่ายดายผ่าน Management Console โดยทำตามคำแนะนำที่ให้ไว้
คำศัพท์พื้นฐานของ Personalize
ขอแนะนำแนวคิดที่ควรทราบในการใช้งานแบบคร่าวๆ ภาพรวมจะเป็นดังนี้ (ความแตกต่างระหว่างสองอย่างนี้จะอธิบายในภายหลัง)
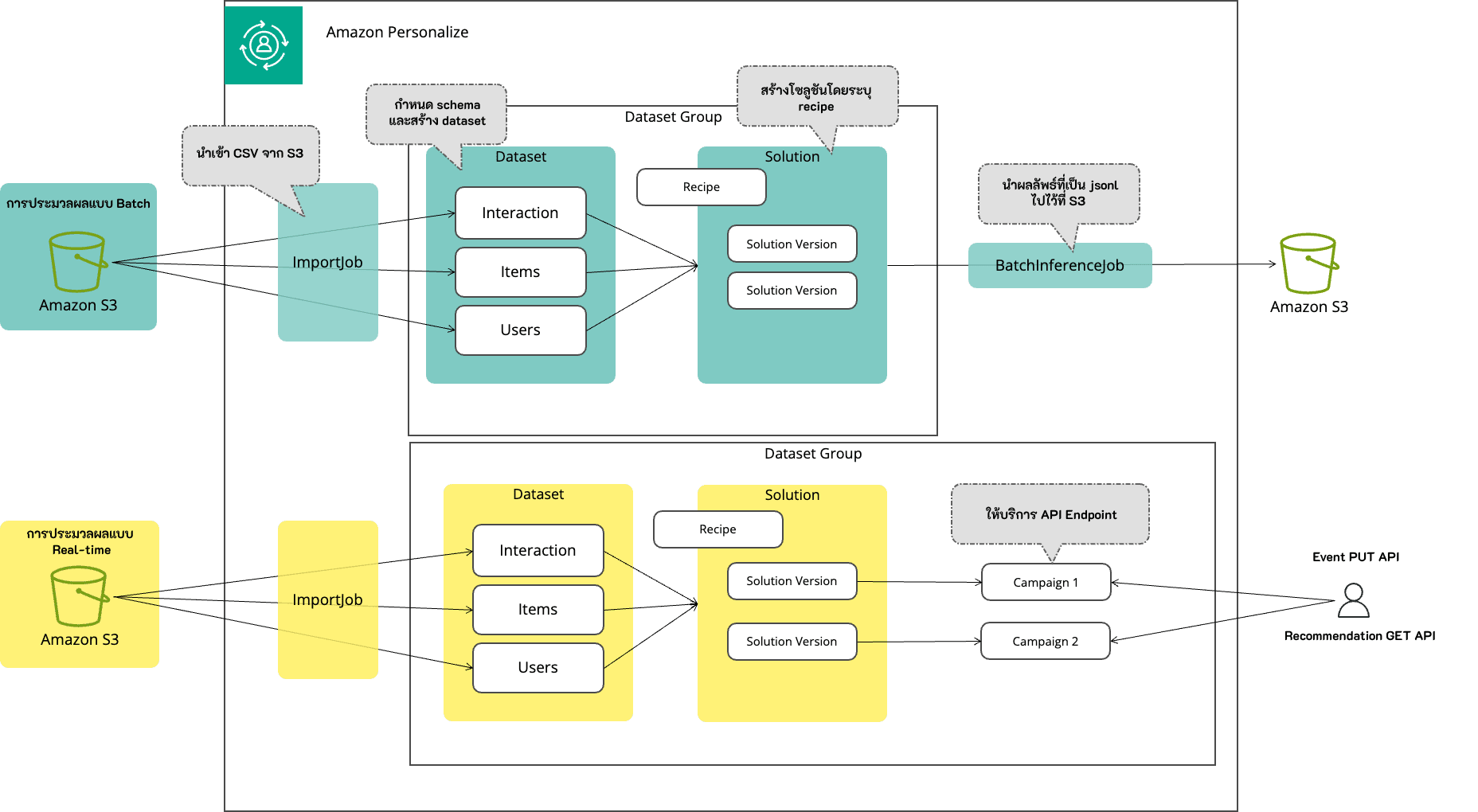
Custom Dataset Group:
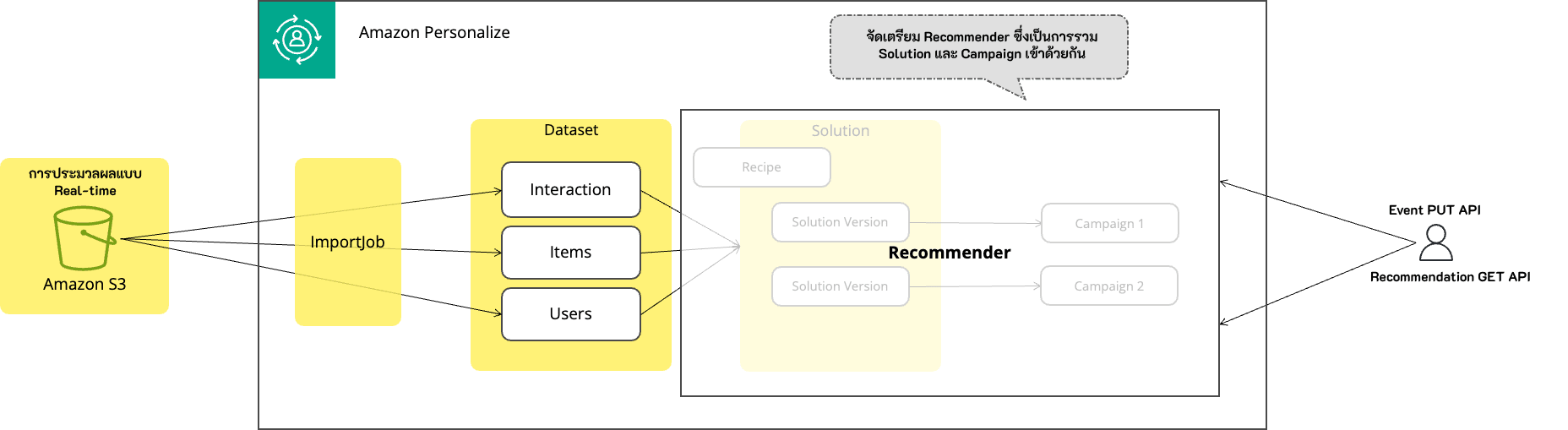
Domain Dataset Group:
Dataset Group
สิ่งแรกที่ต้องสร้างใน Personalize คือ Dataset Group โดย Dataset Group มีหน้าที่รวบรวมชุดข้อมูล (Dataset) เข้าด้วยกัน
Domain Dataset Group และ Custom Dataset Group
เมื่อสร้าง Dataset Group จะต้องระบุโดเมน
| ประเภท | คำอธิบาย |
|---|---|
| Domain Dataset Group | dataset group ที่เฉพาะเจาะจงสำหรับการแนะนำในโดเมนเฉพาะ สามารถใช้ได้กับ VIDEO_ON_DEMAND และ ECOMMERCE รองรับเฉพาะ Real-time job เท่านั้น |
| Custom Dataset Group | dataset group แบบกำหนดเองที่สามารถใช้สำหรับการแนะนำในวงกว้าง รองรับทั้ง Real-time job และ Batch job |
ตามที่แสดงในภาพข้างต้น Domain Dataset Group เป็นฟังก์ชันที่ห่อหุ้มส่วนของ Solution/Solution Version/Campaign ทำให้มีการตั้งค่าน้อยลงและสามารถทำการประมวลผลแบบ Real-time ได้
Dataset
หมายถึงข้อมูลที่ใช้ในการสร้างโมเดลการแนะนำ แต่ละชุดข้อมูลต้องมีจำนวนข้อมูลขั้นต่ำ โดยจะสามารถสร้างคำแนะนำที่มีคุณภาพสูงได้เมื่อมีการปฏิสัมพันธ์กับสินค้า (Item Interaction) อย่างน้อย 50,000 รายการ จากผู้ใช้ 1,000 คนที่มีการปฏิสัมพันธ์กับสินค้าอย่างน้อย 2 รายการ
| ประเภทชุดข้อมูล | คำอธิบาย |
|---|---|
| Item interactions | ประวัติการปฏิสัมพันธ์ระหว่างผู้ใช้กับสินค้า ต้องมีข้อมูลอย่างน้อย 1,000 รายการ (เช่น ประวัติการกด "ถูกใจ" สินค้าของผู้ใช้) |
| Users | ข้อมูลเมตาดาต้าเกี่ยวกับผู้ใช้ ต้องมี userID ที่ไม่ซ้ำกันอย่างน้อย 25 รายการ (เช่น อายุ, เพศ, สมาชิกแบบมีคะแนนสะสม) |
| Items | ข้อมูลเมตาดาต้าเกี่ยวกับสินค้า (เช่น ราคา, ประเภท SKU, สถานะสินค้าคงคลัง) |
| Actions | ข้อมูลเมตาดาต้าเกี่ยวกับกิจกรรมที่ต้องการแนะนำให้ลูกค้าทำ (เช่น การติดตั้งแอพ, การกรอกโปรไฟล์, การสมัครรับอีเมลโปรโมชั่น) |
| Action interactions | ประวัติการปฏิสัมพันธ์ระหว่างผู้ใช้กับแอคชั่น (กิจกรรมที่ต้องการแนะนำให้ลูกค้าทำ) ต้องมีอย่างน้อย 2 รายการ (เช่น ประวัติว่าผู้ใช้รายนั้นกรอก/ไม่กรอกโปรไฟล์) |
Recipe
หมายถึงอัลกอริทึมที่ใช้ในการแนะนำ โดยมี Recipe ที่สามารถใช้งานได้ดังต่อไปนี้
| Recipe | คำอธิบาย |
|---|---|
| USER_PERSONALIZATION | รับรายการที่ปรับแต่งสำหรับผู้ใช้เฉพาะราย (เช่น "สินค้าที่แนะนำสำหรับคุณ") |
| PERSONALIZED_RANKING | จัดเรียงลำดับรายการสินค้าสำหรับผู้ใช้เฉพาะราย (เช่น "สินค้าที่คุณน่าจะชอบ") |
| RELATED_ITEMS | แนะนำสินค้าที่คล้ายกัน (เช่น "สินค้าที่แนะนำสำหรับผู้ที่ซื้อสินค้านี้") |
| POPULAR_ITEMS | แนะนำสินค้าที่กำลังเป็นที่นิยมหรือเทรนด์ |
| PERSONALIZED_ACTIONS | แนะนำการกระทำถัดไปที่เหมาะสมที่สุดสำหรับผู้ใช้เฉพาะราย (เช่น แนะนำให้เข้าร่วมโปรแกรมสมาชิก) |
| USER_SEGMENTATION | รับกลุ่มผู้ใช้ (เช่น ค้นหาผู้ใช้ที่เหมาะกับสินค้าที่ต้องการขาย) |
สำหรับข้อจำกัดอื่นๆ และรายละเอียดเพิ่มเติม กรุณาตรวจสอบจากเอกสารด้านล่าง
Choosing a recipe - Amazon Personalize
เมื่อวันที่ 2 พฤษภาคม 2024 ได้มีการอัพเดท v2 สำหรับ user-personalization และ personalized-ranking เมื่อเทียบกับเวอร์ชันก่อนหน้า:
- ความแม่นยำในการแนะนำเพิ่มขึ้นสูงสุด 9%
- ขอบเขตของการแนะนำขยายเพิ่มขึ้นสูงสุด 1.8 เท่า
Solution
เปรียบเสมือนกล่องที่สามารถบรรจุโมเดลหลายๆ โมเดลได้ โดยสร้างโซลูชันด้วยการระบุ Recipe และพารามิเตอร์ต่างๆ
Solution Version
เมื่อทำการเทรนนิ่งในโซลูชัน จะมีการสร้าง Solution Version ขึ้นมา ให้คิดว่าเป็นเหมือนโมเดลชนิดหนึ่ง
Campaign
สร้างแคมเปญจาก Solution Version เพื่อสร้างสภาพแวดล้อมที่สามารถเรียกดูผลการแนะนำผ่าน API ได้
Recommender
เปรียบเสมือนสิ่งที่ห่อหุ้ม Solution และ Campaign เข้าด้วยกัน เมื่อใช้ Domain Dataset Group จะต้องส่งคำขอไปยัง Recommender
อ้างอิง:
Amazon Personalize terms - Amazon Personalize
วิธีการใช้งาน
ภาพรวมขั้นตอนการทำงาน
ลำดับการใช้งาน Amazon Personalize มีดังนี้:
- การเตรียมและนำเข้าข้อมูล
- การสร้างและเทรนโมเดล
- การสร้างคำแนะนำ
ลองทดสอบการประมวลผลแบบ Batch
มาลองใช้ Personalize กัน โดยครั้งนี้จะทดลองทำการประมวลผลแบบ Batch
การเตรียมข้อมูล
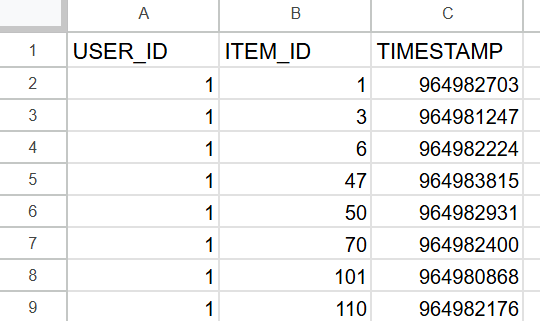
ดาวน์โหลดข้อมูลการให้คะแนนภาพยนตร์ (ml-latest-small.zip) จากเว็บไซต์ด้านล่าง จากนั้นนำข้อมูลมาประมวลผลเพื่อสร้างรายการที่แสดงว่า "ผู้ใช้คนไหนดูหนังเรื่องอะไรเมื่อไหร่" แล้วใช้ Personalize เพื่อแนะนำภาพยนตร์ที่ควรดูต่อไป
เปลี่ยนชื่อไฟล์ ratings.csv เป็น interactions.csv และลบคอลัมน์ rating ที่ไม่ได้ใช้ในการแนะนำออก จากนั้นเปลี่ยนชื่อคอลัมน์เป็น USER_ID, ITEM_ID, TIMESTAMP ซึ่งเป็นข้อมูลที่จำเป็นต้องมี เมื่อตั้งค่าเสร็จแล้วให้อัปโหลดไฟล์ interactions.csv ไปยัง S3 bucket
- USER_ID: ID ที่ระบุตัวผู้ใช้อย่างไม่ซ้ำกัน เช่น รหัสสมาชิก
- ITEM_ID: ID ที่ระบุสินค้าหรือไอเทมอย่างไม่ซ้ำกัน เช่น SKU (ในกรณีนี้คือ ID ของภาพยนตร์)
- TIMESTAMP: วันเวลาที่ทำรายการ เช่น วันเวลาที่ซื้อ (ในกรณีนี้คือวันเวลาที่ดูภาพยนตร์)
- สามารถใช้ได้เฉพาะรูปแบบ UNIX TIMESTAMP เท่านั้น
การนำเข้าข้อมูล
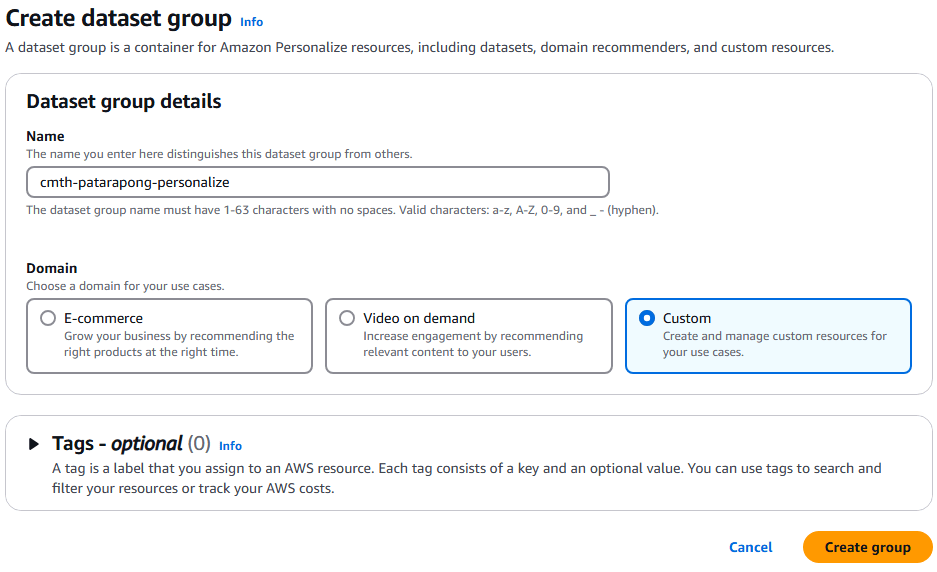
ขั้นแรกให้สร้างกลุ่มชุดข้อมูล (dataset group) จาก Create dataset group เนื่องจากไม่ได้เป็นการใช้งานสำหรับ E-commerce หรือ Video on demand จึงเลือกโดเมนเป็น Custom
จาก Create dataset ให้เลือก item interactions dataset

เลือก Import method โดยในครั้งนี้เนื่องจากข้อมูลได้ถูกจัดรูปแบบและพร้อมใช้งานแล้ว จึงเลือก Import data directly into Amazon Personalize datasets เพื่อดำเนินการต่อ

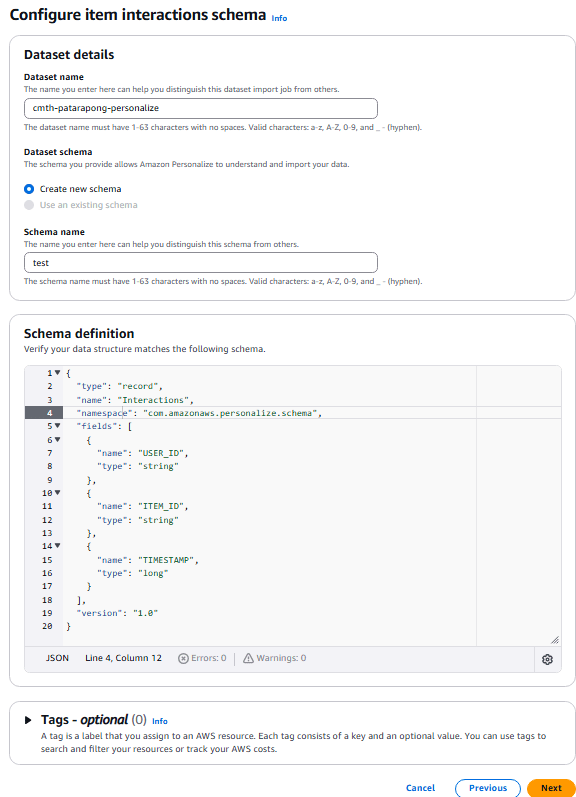
กำหนด schema ของชุดข้อมูล โดยต้องกำหนดสำหรับชุดข้อมูลแต่ละประเภท
ในครั้งนี้เราได้กำหนด schema สำหรับ Interactions
{
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "TIMESTAMP",
"type": "long"
}
],
"version": "1.0"
}
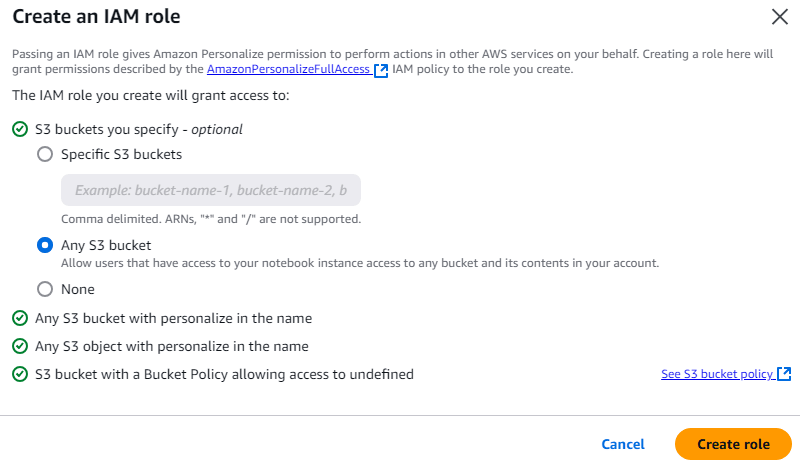
สร้าง IAM role สำหรับการใช้งาน Personalize
กำหนด bucket policy สำหรับ S3 bucket ที่เก็บข้อมูลดังต่อไปนี้
{
"Version": "2012-10-17",
"Id": "PersonalizeS3BucketAccessPolicy",
"Statement": [
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:ListBucket",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::<Bucket name>",
"arn:aws:s3:::<Bucket name>/*"
]
}
]
}
เมื่อตั้งค่าทั้งหมดเสร็จแล้ว ให้รันงาน import เพื่อนำเข้าข้อมูล
การสร้างและรันโมเดล
เมื่อการนำเข้าข้อมูลเสร็จสิ้นและชุดข้อมูลถูกสร้างขึ้น จะสามารถสร้าง solution ได้ โดยดำเนินการผ่าน Create solutions โดยกำหนด Solution Type เป็น Item recommendation และเลือก Recipe เป็น aws-user-personalization
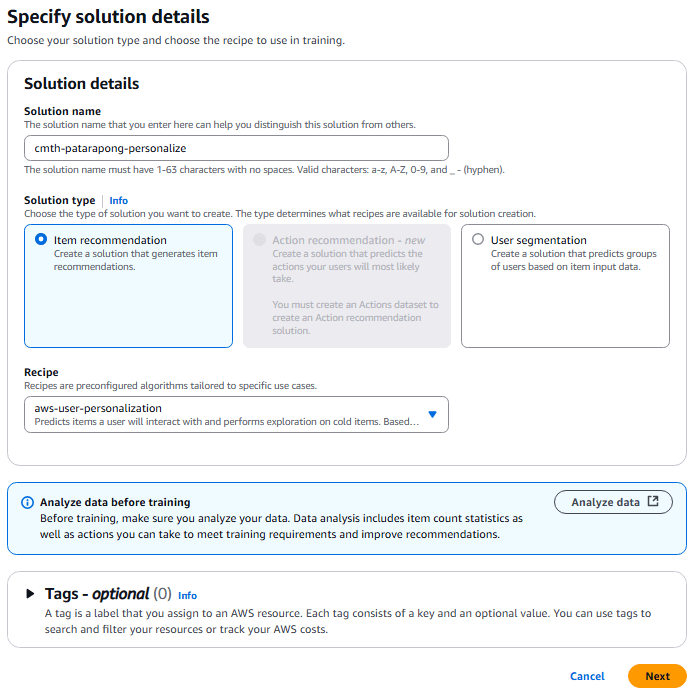
แม้จะสามารถเปลี่ยนแปลงไฮเปอร์พารามิเตอร์และระบุคอลัมน์ที่จะใช้ในการเทรนได้ แต่ในครั้งนี้จะใช้การตั้งค่าเริ่มต้นและดำเนินการสร้าง solution ต่อ
การสร้างคำแนะนำ
ในครั้งนี้ตามที่ได้กล่าวไว้ตอนต้น เราจะทำการประมวลผลแบบ Batch ในการทำ batch inference จำเป็นต้องเตรียมไฟล์ JSON สำหรับข้อมูลนำเข้าแบบ batch
ในครั้งนี้เราได้เตรียมไฟล์ JSONL ที่มี userId ตามด้านล่างและตั้งชื่อเป็น input.jsonl แล้วอัปโหลดไปยัง S3 bucket เราจะสามารถรับผลการแนะนำตาม userId เหล่านี้ได้
ทั้งนี้ การระบุ userId ต้องคำนึงถึงตัวพิมพ์ใหญ่และตัวพิมพ์เล็กด้วย
Preparing input data for batch recommendations - Amazon Personalize
{"userId": 1}
{"userId": 2}
{"userId": 3}
{"userId": 4}
{"userId": 5}
{"userId": 6}
{"userId": 7}
{"userId": 8}
{"userId": 9}
{"userId": 10}
จาก Get recommendations ให้เลือก Create batch inference job
หากเลือก Create campaign จะเป็นการสร้างคำแนะนำแบบ real-time inference
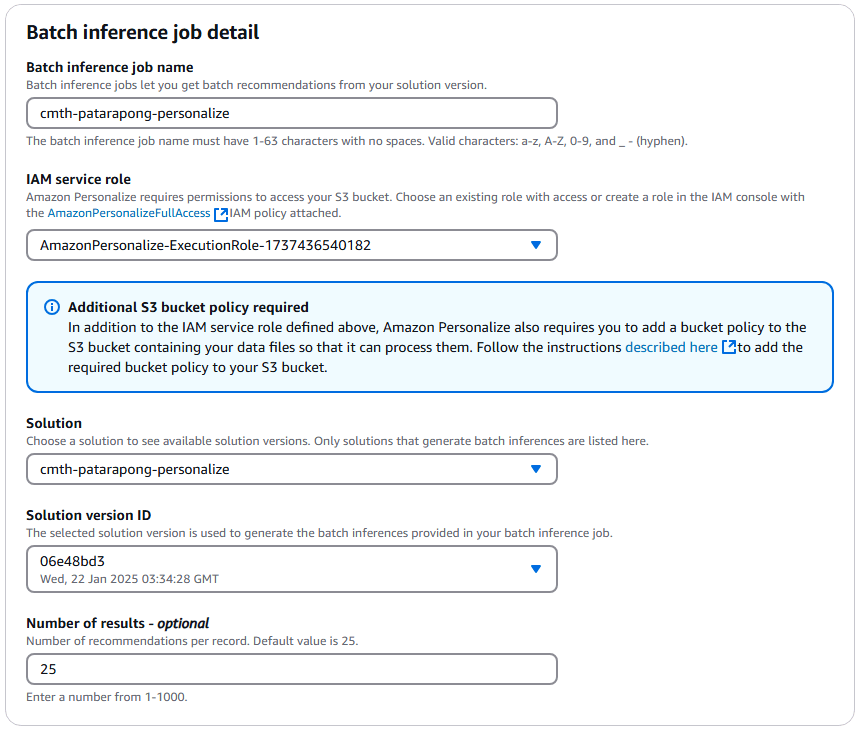
ดำเนินการ create batch inference job โดยระบุ solution และ solution version ที่สร้างไว้ก่อนหน้า พร้อมทั้งระบุ input data และ S3 bucket ปลายทางสำหรับผลลัพธ์


เมื่อการทำงานเสร็จสิ้น ไฟล์ชื่อ out ต่อท้าย จะถูกสร้างขึ้นใน S3 bucket ที่ระบุเป็นปลายทาง เมื่อดูเนื้อหาภายในไฟล์จะพบว่ามีการแนะนำรายการ (ในกรณีนี้คือภาพยนตร์) เรียงลำดับตามคะแนนจากมากไปน้อย
{
"input": {
"userId": 1
},
"output": {
"recommendedItems": [
"2081",
"1380",
"3793",
"1035",
.
.
.
"2692",
"4308",
"2797",
"2671",
"2712"
],
"scores": [
0.0088618,
0.0065327,
0.0053816,
0.0053691,
0.0050853,
0.0048317,
.
.
.
0.002566
]
},
"error": null
}
ค่าใช้จ่าย
แบ่งออกเป็นสามส่วนหลักๆ ได้แก่:
- การนำเข้าข้อมูล
- การเทรนนิ่ง
- การแนะนำ (แบบ Batch/Real-time)
การนำเข้าข้อมูล
คิดค่าใช้จ่าย 0.05 USD ต่อ 1GB ของข้อมูลที่อัปโหลดเข้า Personalize
การเทรนนิ่ง
คิดค่าใช้จ่าย 0.24 USD ต่อชั่วโมงสำหรับเวลาที่ใช้ในการเทรนนิ่ง
การแนะนำ
อ้างอิงจากตารางด้านล่าง
ค่าใช้จ่าย - Amazon Personalize | AWS (https://aws.amazon.com/th/personalize/pricing/?nc1=f_ls)
การประมวลผลแบบ Real-time
เนื่องจากมีการคิดค่าใช้จ่ายแบบ real-time จึงมักมีค่าใช้จ่ายสูงกว่าการประมวลผลแบบ batch โดยใช้แนวคิดที่เรียกว่า Transaction per second (TPS) ซึ่งหมายถึงจำนวนคำขอต่อวินาที และสามารถกำหนดค่าขั้นต่ำของปริมาณงานที่สามารถประมวลผลได้ต่อวินาทีผ่านการตั้งค่า Minimum provisioned transaction per second แต่เนื่องจากค่าต่ำสุดคือ 1 ดังนั้นแม้จะไม่มีคำขอเลย ก็จะถูกเรียกเก็บเงินอย่างน้อย 4 ดอลลาร์ต่อวัน
| การแนะนำแบบ Real-time | ค่าใช้จ่ายต่อ 1,000 คำขอ |
|---|---|
| 72 ล้านคำขอแรกต่อเดือน | 0.0556 USD |
| 648 ล้านคำขอถัดไปต่อเดือน | 0.0278 USD |
| มากกว่า 720 ล้านคำขอต่อเดือน | 0.0139 USD |
การประมวลผลแบบ Batch
การประมวลผลแบบ batch จะมีค่าใช้จ่ายตามจำนวนคำแนะนำที่ร้องขอ
| การแนะนำแบบ Batch | ค่าใช้จ่ายต่อ 1,000 คำแนะนำ |
|---|---|
| 20 ล้านคำแนะนำแรกต่อเดือนในแต่ละ Region | 0.067 USD |
| 180 ล้านคำแนะนำถัดไปต่อเดือนในแต่ละ Region | 0.058 USD |
| มากกว่า 200 ล้านคำแนะนำต่อเดือนในแต่ละ Region | 0.050 USD |
สรุป
Amazon Personalize ถือว่าเป็นบริการ Machine Learning ตัวหนึ่ง ซึ่งเราสามารถนำข้อมูลมาทำการ train ได้
จากนั้นตัวบริการก็จะให้ผลลัพธ์เป็นคำแนะนำ แต่ Amazon Personalize ก็มีค่าบริการที่ไม่ถูกเมื่อเทียบกับบริการอื่นๆ ดังนั้นจึงต้องคิดให้ดีว่าจะนำข้อมูลผลลัพธ์ที่ได้(คำแนะนำ) ไปต่อยอดยังไง









