![[新機能] Amazon Redshift データレイクテーブルのマテリアライズドビューの増分更新をサポートを試してみました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-63f1274931b942e9a92e601c1127ad73/cfe87ec6d62fa2fc3c474ed4cb2f6c2e/amazon-redshift?w=3840&fm=webp)
[新機能] Amazon Redshift データレイクテーブルのマテリアライズドビューの増分更新をサポートを試してみました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。データレイクテーブルのマテリアライズドビューに対する増分更新のサポートされました。これにより、大規模なデータレイクからマテリアライズドビューを短時間で増分更新が可能となり、マテリアライズドビューの利用用途を広げることができます。本日は、新機能の解説と実際のデータレイクテーブルのマテリアライズドビューの増分更新を試してみます。
マテリアライズドビューの増分更新の特長
マテリアライズドビューの増分更新は、Amazon Redshiftは最後の更新以降にベーステーブルで変更されたデータのみを更新します。ベーステーブルのデータが変更されるたびにマテリアライズドビュー全体を再計算する必要がなくなり、コスト効率が大幅に向上します。
インクリメンタル作成とリフレッシュ
執筆時点のマニュアルの内容をまとめますと、以下のとおりです。
少なくとも 1 つの外部テーブルでマテリアライズド ビューを使用する場合、マテリアライズド ビューの作成は増分的に行われます。
- 標準的なデータレイクテーブル(パーティション化されているかどうかに関わらず)
- Apache Icebergテーブル(コピーオンライトおよびマージオンリード)
- Amazon Redshift Spectrumテーブルと同じデータベース内の他のAmazon Redshiftテーブルとの結合
また、マテリアライズド ビューの更新は、次の場合に増分的に行われます。
- 標準的なデータレイクテーブルで
S3 DELETE(データファイルの削除)またはPUT(上書き)が行われた後(マテリアライズドビューが集計を行わない場合) - Apache IcebergテーブルでINSERT、DELETE、UPDATE、またはテーブルの圧縮が行われた後
筆者としては、Apache Icebergテーブルは、テーブルフォーマット内で時系列のスナップショットを持っているので、差分更新できることが理解できるのですが、変更検知するすべのない標準的なデータレイクテーブルでどのように差分更新ができるのか仕組みが解説がなくよくわかりませんでした。re:Inventの直前のアップデートということもあり、この疑問に対する情報がアップデートされたら反映したいと思います。
制限事項
マテリアライズドビューの使用には一般的な制限事項が適用されますが、外部データレイクテーブルに対するマテリアライズドビューには追加の制限事項があります。
- HudiやDelta Lakeテーブル、Spectrumネストデータアクセスではインクリメンタル作成はできません
- 特定の条件下では、リフレッシュが完全な再計算にフォールバックします
- Apache Icebergテーブルでは、単一のデータファイルで削除された位置を400万までしか処理できません
- Apache Icebergテーブルでは、マテリアライズドビューの作成とリフレッシュに同時スケーリングはサポートされていません
- 自動化機能(自動マテリアライズドビュー、自動リフレッシュ、自動クエリ書き換え)はサポートされていません
検証環境の構築
検証の方針
以上を踏まえて、以下の条件で検証します。
- 1 つの外部テーブルでマテリアライズド ビューを使用する
- Apache Icebergテーブル(コピーオンライトおよびマージオンリード)
データレイクのテーブル作成
執筆時点(2024/11/01)では、Amazon Redshift Spactrumは、Icebergテーブルフォーマットに対する書き込みサポートをしていないので、Icebergのテーブルの作成や更新は、Amazon Athena を用います。
Amazon Athenaを使用してIcebergテーブルを作成するSQLは、以下のとおりです。
-- DROP TABLE lineorder;
CREATE TABLE lineorder
(
lo_orderkey int,
lo_linenumber int,
lo_custkey int,
lo_partkey int,
lo_suppkey int,
lo_orderdate date,
lo_orderpriority string,
lo_shippriority string,
lo_quantity int,
lo_extendedprice int,
lo_ordertotalprice int,
lo_discount int,
lo_revenue int,
lo_supplycost int,
lo_tax int,
lo_commitdate date,
lo_shipmode string
)
PARTITIONED BY (lo_orderdate)
LOCATION 's3://cm-datalake-20241101/redbergdb/lineorder/'
TBLPROPERTIES (
'table_type' = 'ICEBERG'
);
このテーブル(redbergdb.lineorder)に1993年分のデータをロードします。(4回に分けてロードしています。)
INSERT INTO redbergdb.lineorder (
SELECT
lo_orderkey,
lo_linenumber,
lo_custkey,
lo_partkey,
lo_suppkey,
lo_orderdate,
lo_orderpriority,
lo_shippriority,
lo_quantity,
lo_extendedprice,
lo_ordertotalprice,
lo_discount,
lo_revenue,
lo_supplycost,
lo_tax,
lo_commitdate,
lo_shipmode
FROM ssbgz_tsv.lineorder
WHERE lo_orderdate >= CAST('1993-01-01' AS date) AND lo_orderdate < CAST('1993-04-01' AS date)
-- WHERE lo_orderdate >= CAST('1993-04-01' AS date) AND lo_orderdate < CAST('1993-07-01' AS date)
-- WHERE lo_orderdate >= CAST('1993-07-01' AS date) AND lo_orderdate < CAST('1993-10-01' AS date)
-- WHERE lo_orderdate >= CAST('1993-10-01' AS date) AND lo_orderdate < CAST('1994-01-01' AS date)
);
-- SELECT count(lo_orderdate) FROM redbergdb.lineorder;
-- 91007488 records
-- SELECT count(distinct(lo_orderdate)) FROM redbergdb.lineorder;
-- 365
Amazon Redshift Spectrumで外部テーブルを作成
Amazon Redshiftで外部スキーマを作成します。
CREATE EXTERNAL SCHEMA redbergdb
FROM DATA CATALOG
DATABASE 'redbergdb'
IAM_ROLE 'arn:aws:iam::0123456789012:role/dev-nxgn-redshift-ap-northeast-1-0123456789012';
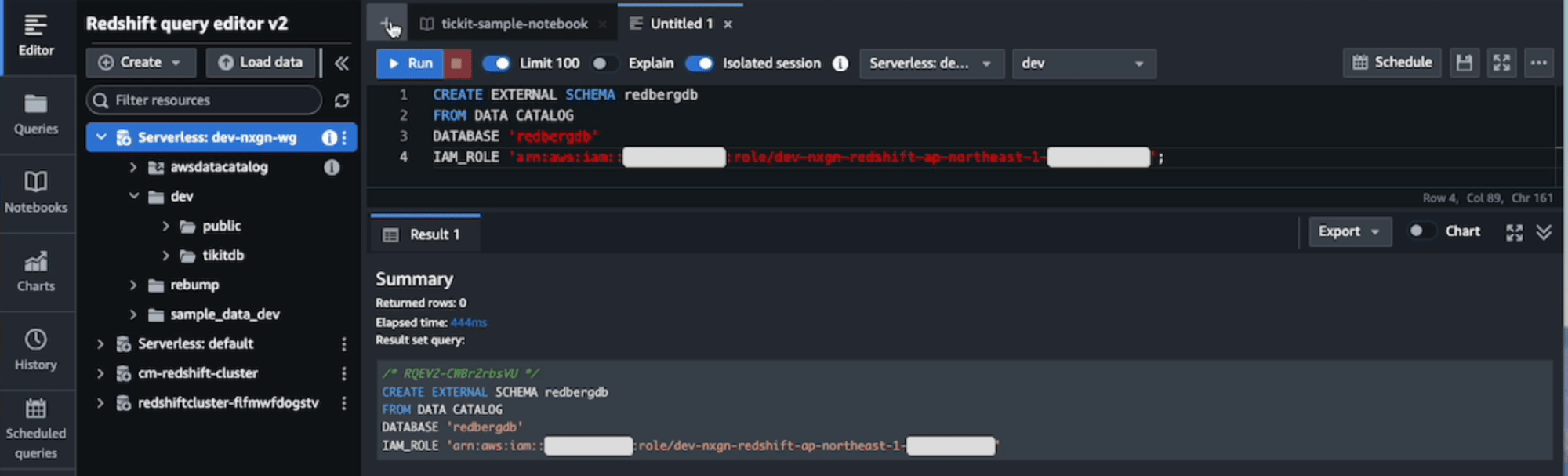
Amazon Athenaで作成したテーブルとそのデータが、Amazon Redshiftから参照できるようになります。
SELECT * FROM redbergdb.lineorder
WHERE lo_orderdate = CAST('1993-01-01' AS date)
LIMIT 10;
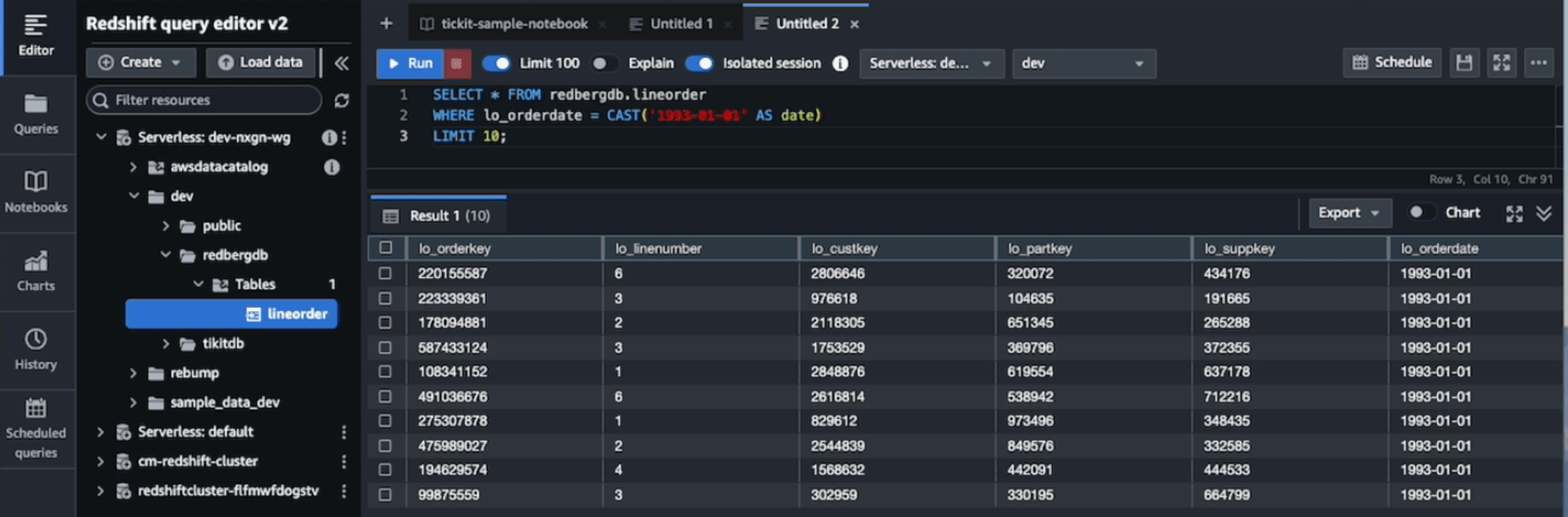
データレイクテーブルのマテリアライズドビューの増分更新を試す
マテリアライズドビューのベーステーブル(redbergdb.lineorder)の準備ができました。引き続き、Amazon Redshiftでマテリアライズドビューの作成と初期状態のの差分更新を実行して、それぞれの時間を計測します。なお、この検証では、Redshiftの結果キャッシュを無効化しています。そのため、ここからは、psqlコマンドを用いて、SQLを実行して計測しました。
dev=# SET enable_result_cache_for_session TO off;
SET
dev=# \timing
タイミングは on です。
マテリアライズドビューの作成
マテリアライズドビューを作成します。以下のSQLで顧客別の注文数を事前集計のマテリアライズドビュー(custorder_summary)を作成します。作成に要した時間は、約23.8秒でした。
dev=# -- 顧客別の注文数を事前集計
CREATE MATERIALIZED VIEW public.custorder_summary
AUTO REFRESH NO
AS
SELECT l.lo_custkey, COUNT(*) as order_count
FROM redbergdb.lineorder l
GROUP BY l.lo_custkey;
CREATE MATERIALIZED VIEW
CREATE MATERIALIZED VIEW
時間: 23755.496 ミリ秒(00:23.755)
続いて、初期状態(ベーステーブルに全く更新しない状態)で、マテリアライズドビューを更新します。更新に要した時間は、約2.3秒でした。
dev=# REFRESH MATERIALIZED VIEW public.custorder_summary;
INFO: Materialized view custorder_summary was incrementally updated successfully.
REFRESH
時間: 2308.681 ミリ秒(00:02.309)
後で注文数を比較するため、order_countの総数を取得します。order_countの総数は、91007488件です。
dev=# SELECT SUM(order_count) FROM public.custorder_summary;
sum
----------
91007488
(1 行)
時間: 2557.636 ミリ秒(00:02.558)
マテリアライズドビューの増分更新
次には、ベーステーブルに更新をかけた後、マテリアライズドビューを更新して増分更新になり、マテリアライズドビューの更新時間が短縮されるかを確認します。
Amazon Athenaからベーステーブルに更新します。1994年1月1日のデータをredbergdb.lineorderにロードします。
このテーブル(redbergdb.lineorder)に1994年1月1日分のデータをロードします。
INSERT INTO redbergdb.lineorder (
SELECT
lo_orderkey,
lo_linenumber,
lo_custkey,
lo_partkey,
lo_suppkey,
lo_orderdate,
lo_orderpriority,
lo_shippriority,
lo_quantity,
lo_extendedprice,
lo_ordertotalprice,
lo_discount,
lo_revenue,
lo_supplycost,
lo_tax,
lo_commitdate,
lo_shipmode
FROM ssbgz_tsv.lineorder
WHERE lo_orderdate = CAST('1994-01-01' AS date)
);
-- SELECT count(lo_orderdate) FROM redbergdb.lineorder;
-- 91256724 records
-- SELECT count(distinct(lo_orderdate)) FROM redbergdb.lineorder;
-- 366
では、Amazon Redshiftに戻り、ベーステーブル更新した状態で、マテリアライズドビューを更新します。更新に要した時間は、約3.2秒でした。
dev=# REFRESH MATERIALIZED VIEW public.custorder_summary;
INFO: Materialized view custorder_summary was incrementally updated successfully.
REFRESH
時間: 3237.601 ミリ秒(00:03.238)
ベーステーブル更新したマテリアライズドビューで、order_countの総数を取得します。order_countの総数は、初期状態よりも増加して91256724件です。
dev=# SELECT SUM(order_count) FROM public.custorder_summary;
sum
----------
91256724
(1 行)
時間: 159.535 ミリ秒
検証結果
- マテリアライズドビューの作成
- 新規作成: 約23.8秒
- 初期状態のリフレッシュ: 約2.3秒
- マテリアライズドビューの増分更新
- ベーステーブル追加後のリフレッシュ: 約3.2秒
ベーステーブル追加後のリフレッシュは、ベーステーブルに1994年1月1日分のデータが追加され、その増分データに対して集計・追加したため、初期状態のリフレッシュよりも1秒程度ですが増加しました。マテリアライズドビューを新規で作成する場合と比較して圧倒的に速くなったことがおわかりでしょう。
最後に
執筆時点(2024年11月1日)では、Amazon Redshift Spectrumは、Icebergテーブルフォーマットに対する書き込みをサポートしていないため、Icebergテーブルの作成や更新にはAmazon Athenaを使用します。今年のre:Inventで、Icebergテーブルの更新もサポートされることを期待しています。
筆者としては、Apache Icebergテーブルがテーブルフォーマット内で時系列のスナップショットを保持しているため、差分更新が可能であることは理解できます。しかし、変更を検知する手段のない標準的なデータレイクテーブルでどのように差分更新ができるのか、その仕組みについての解説がなく、よく理解できませんでした。そのため、今回の検証では、ベーステーブルにApache Icebergテーブルを採用しました。
今後、Icebergテーブルフォーマットは様々なクエリエンジンで積極的に利用されることが予想されます。今回のアップデートで、ベーステーブルがIcebergの場合に増分更新ができるようになったことは喜ばしいことです。この新機能は、データレイククエリのパフォーマンスを向上させ、コスト効率の良い方法でデータの鮮度を維持することでしょう。










