![[新機能] Amazon SageMaker AIがサーバーレスなMLflow機能をサポートしました](https://images.ctfassets.net/ct0aopd36mqt/33a7q65plkoztFWVfWxPWl/a718447bea0d93a2d461000926d65428/reinvent2025_devio_update_w1200h630.png?w=3840&fm=webp)
[新機能] Amazon SageMaker AIがサーバーレスなMLflow機能をサポートしました
データ事業本部の鈴木です。
Amazon SageMaker AIがサーバーレスなMLflow機能をサポートしました!
MLflowは非常に多くのユーザーが利用している機械学習の実験管理ツールです。
実験の記録・モデルの登録・比較や性能の可視化などの機能を備えており、MLflowを使うことでユーザーは実行した機械学習の実験管理ができるようになります。
これまでもSageMaker AIではマネージドなMLflowを備えていましたが、利用する際はサイズに応じた起動時間分の課金が発生していました。
今回のアップデートのMLflow機能はリクエストに応じて動的にスケーリングし、アイドル時間にはスケールダウンするようになりました。起動時間の短縮・アカウント間の共有・他のSageMaker機能との統合などこれまでのMLflow機能に追加の機能も提供されます。
機能制限があるとのことですが、追加料金なしで使えます。東京リージョンでも使えます。
使ってみる
MLflowアプリの作成
SageMaker StudioのMLflowに遷移すると、デフォルトのMLflowアプリを作成できます。
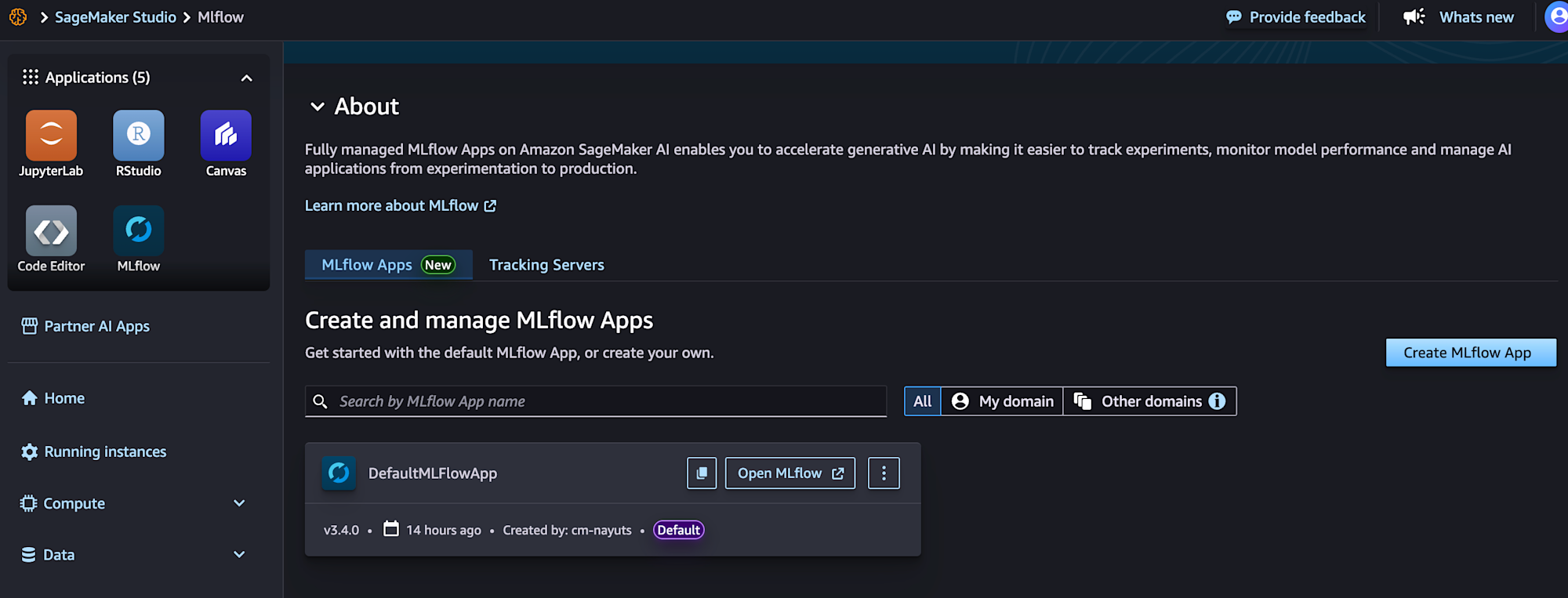
詳細画面を見ると確かにサイズの記載はありませんね。
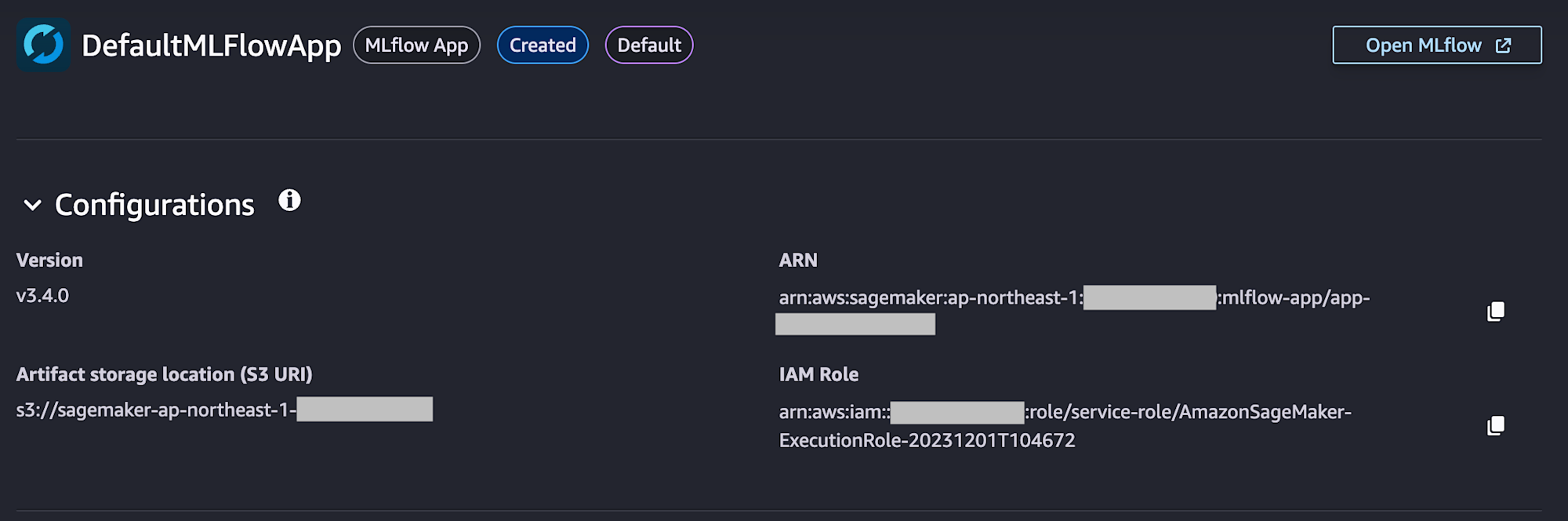
Open MLflowを押すとMLflowにアクセスできます。
なお、これまでのマネージドのMLflow機能はTracking Serversタブから利用でき、用途に応じて使い分ける形となりそうです。
MLflowアプリに実験を登録してみる
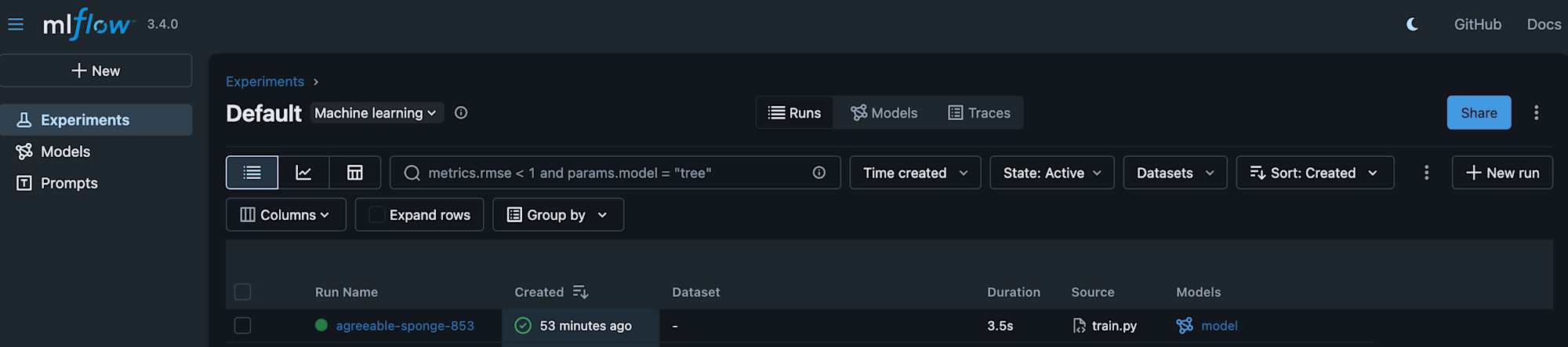
これまでのTracking Serversと同様にアプリのARNを取得し、機械学習コードで設定して実験を登録できました。
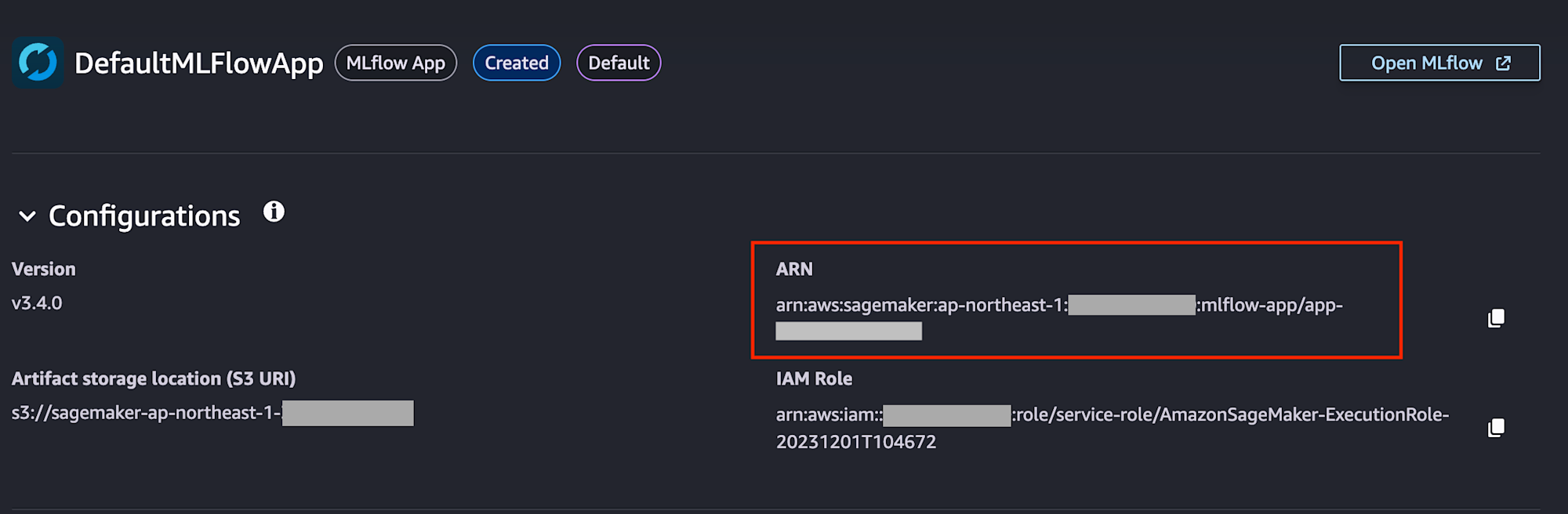
JupyterLab SpaceでNotebookを起動し、以下のトレーニングジョブを実行して登録しました。
import sagemaker
from sagemaker import get_execution_role
from sagemaker.sklearn.estimator import SKLearn
import pandas as pd
import os
sagemaker_session = sagemaker.Session()
role = get_execution_role()
region = sagemaker_session.boto_region_name
tracking_server_arn = f"{アプリのARN}"
!mkdir -p training_code
%%writefile training_code/requirements.txt
mlflow==3.1.4
sagemaker-mlflow==0.2.0
%%writefile training_code/train.py
from __future__ import print_function
import argparse
import joblib
import mlflow
import os
import pandas as pd
from sklearn import datasets
from sklearn import tree
from sklearn.metrics import f1_score, accuracy_score
from sklearn.model_selection import train_test_split
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--max_leaf_nodes', type=int, default=-1)
parser.add_argument('--output-data-dir', type=str, default=os.environ['SM_OUTPUT_DATA_DIR'])
parser.add_argument('--model-dir', type=str, default=os.environ['SM_MODEL_DIR'])
args = parser.parse_args()
iris = datasets.load_iris()
train_data = pd.DataFrame(iris.data, columns=iris.feature_names)
train_data.insert(0, 'target', iris.target)
mlflow.set_tracking_uri(os.environ['MLFLOW_TRACKING_ARN'])
mlflow.autolog()
# labels are in the first column
y = train_data.iloc[:, 0]
X = train_data.iloc[:, 1:]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=46, stratify=y
)
max_leaf_nodes = args.max_leaf_nodes
clf = tree.DecisionTreeClassifier(max_leaf_nodes=max_leaf_nodes)
clf = clf.fit(X_train, y_train)
test_pred = clf.predict(X_test)
test_f1 = f1_score(y_test, test_pred, average='weighted')
test_acc = accuracy_score(y_test, test_pred)
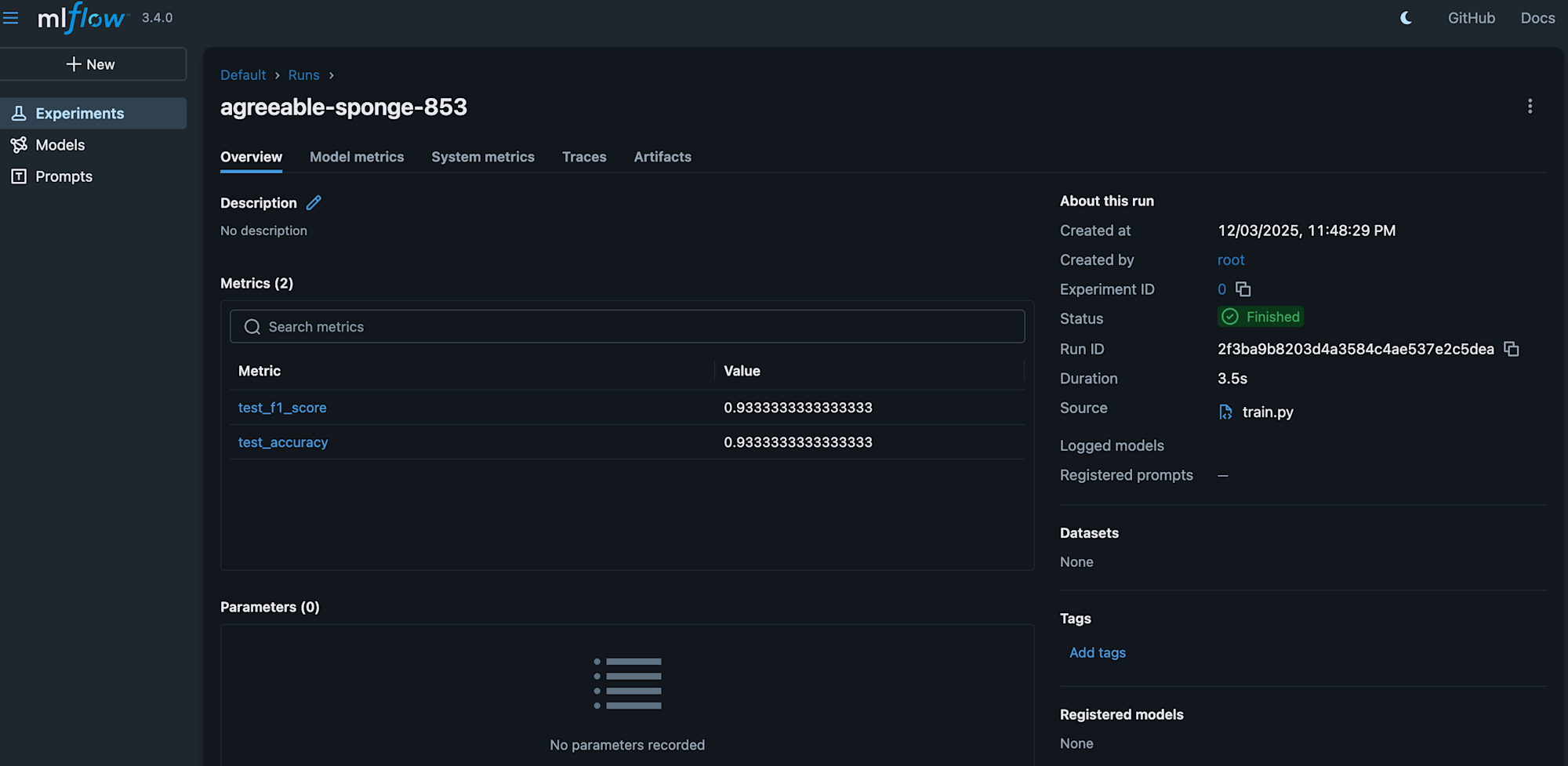
mlflow.log_metric("test_f1_score", test_f1)
mlflow.log_metric("test_accuracy", test_acc)
mlflow.sklearn.log_model(clf, "model")
joblib.dump(clf, os.path.join(args.model_dir, 'model.joblib'))
sklearn = SKLearn(
entry_point="train.py",
source_dir="training_code",
framework_version="1.2-1",
instance_type="ml.c4.xlarge",
role=role,
sagemaker_session=sagemaker_session,
hyperparameters={"max_leaf_nodes": 30},
keep_alive_period_in_seconds=3600,
environment={"MLFLOW_TRACKING_ARN": tracking_server_arn},
)
sklearn.fit()
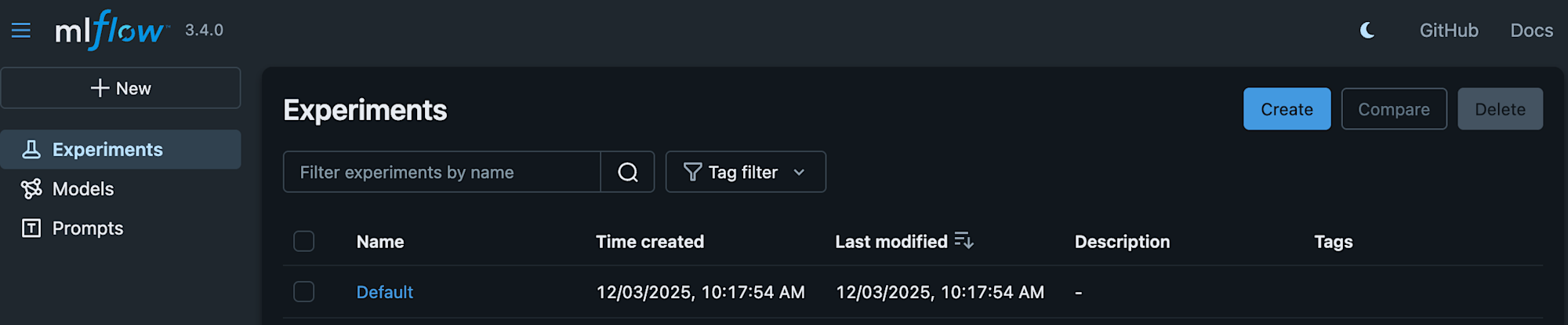
実行後、MLflowアプリを確認すると、たしかに実験が記録されていました。
最後に
Amazon SageMaker AIがサーバーレスなMLflow機能をサポートしたのでご紹介でした。
サーバレス版は機能制限があるとのことなので、使用したい用途に合うか確認の上導入するのがよいように思いました。
SageMaker AIでMLflowが使いたい方は非常に嬉しいアップデートだと思います。ぜひ使ってみましょう!










