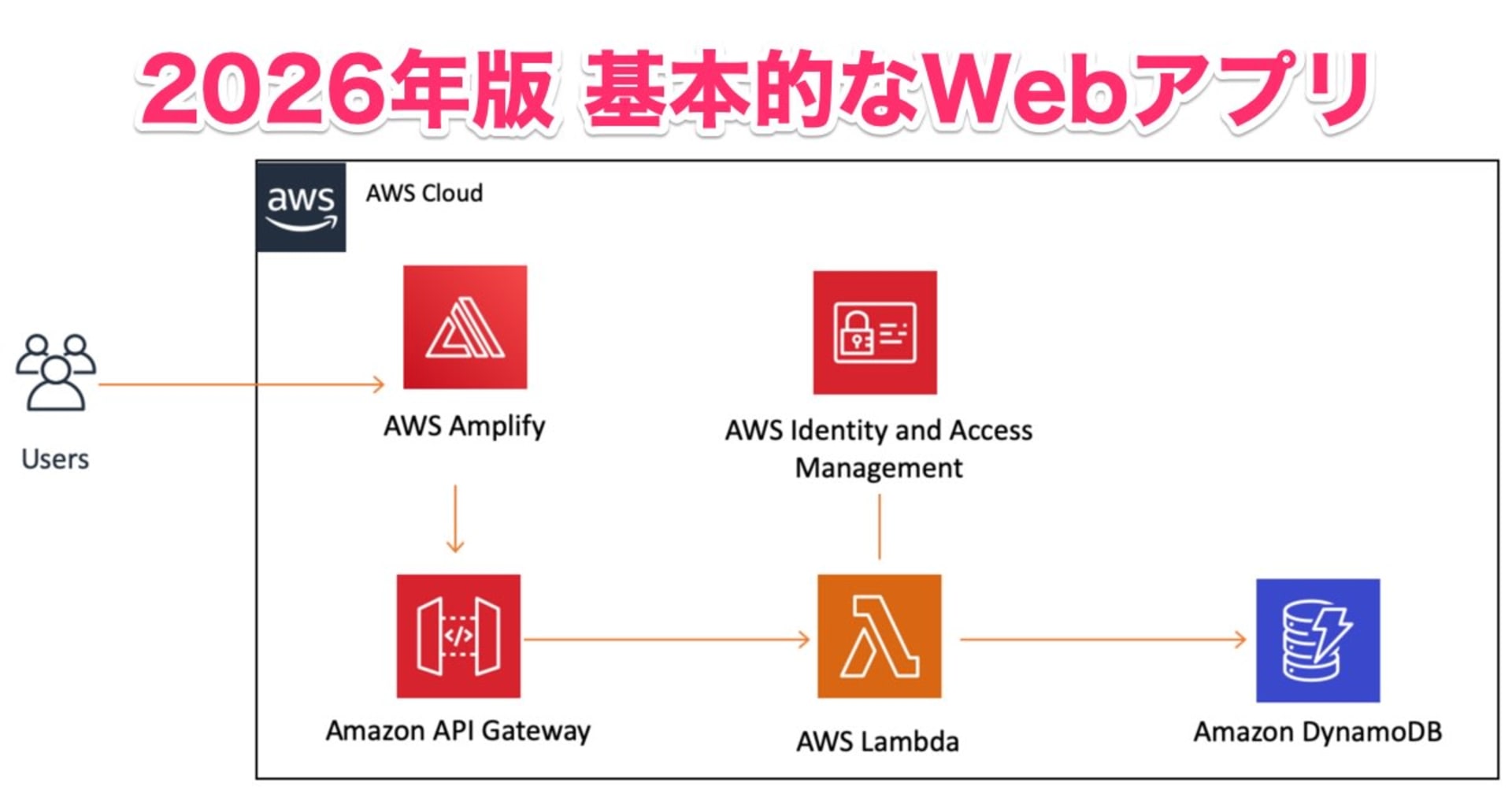
【AWS Amplify 노하우 시리즈】 7. Custom Resolver 도 적극적으로 활용합시다!
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
안녕하세요!ㅎㅎ Classmethod 컨설팅부 소속 김태우입니다.
Amplify 시리즈 일곱번째 글입니다! 이번 글에서는 Amplify API 를 사용할 때 기본적으로 생성해주는 resolver 가 아닌, 직접 커스터마이징한 resolver 를 만들어서 사용하고 싶을 때 어떻게하면 되는지에 대해 설명합니다.
그럼 시작하겠습니다! :)
글을 읽기전에 주의점
2020.08.06 에 추가한 내용입니다.
현재는 @function 디렉티브를 통해 아래의 작업이 자동화됩니다. 자세한 내용은 공식 홈페이지를 참조해주세요 :)
어떤 상황에서 커스텀 리졸버가 필요한가요?
Amplify API 에서 자동으로 생성해주는 리졸버들도 상당히 유용하며, 대부분의 경우 이정도 수준에서 앱을 개발하는데 거의 문제가 없을거라 생각합니다. 하지만 거의 대다수의 애플리케이션에서는 커스텀 리졸버도 필요할거라 생각합니다. 먼저 가장 간단한 경우인 기존 resolver 를 복붙해서 커스터마이징 하는 경우에 대해 간략히 설명하겠습니다.
예를 들어, 유저별 권한에 따라 데이터소스로부터 전달받아오는 결과를 제한하고 싶을 경우에는 amplify/backend/api/${API명}/build/resolvers 폴더의 해당 resolver 를 amplify/backend/api/${API명}/resolvers 에 복사해놓고, response mapping template 에서 VTL 문법으로 결과값을 유저종류에 맞게 필터링해주면 됩니다. 이렇게 복붙해서 가져온 resolver 파일의 파일명이 기존 build 폴더 아래에 배치된 resolver 파일명과 같다면 amplify push 시에 해당 resolver 는 amplify/backend/api/${API명}/resolvers 폴더에 직접 복사한 resolver 파일을 사용하게 됩니다.
AwS Amplify: Overwriting Resolvers
이정도 수준의 커스터마이징은 사실상 파일 덮어쓰기로 매우 간단하게 할 수 있는 일이라서 커스터마이징이라고 말하기에도 거창한 수준일 것 같습니다 ^^;
하지만, 커머스 앱에서 주문 API 를 제공한다던가, 소셜앱 등에서 친구관계인 경우에만 좋아요를 누를 수 있고, 좋아요 수와 좋아요를 누른 사람을 동시에 저장해야하는 트랜잭션 처리 등을 한다던가(말이 복잡하네요...ㅋㅋ) 하는 복잡한 로직이 필요한 경우, VTL 기반의 리졸버를 작성하는 것보다 범용 프로그래밍 언어로 작성하는 것이 훨씬 효율적인 경우도 종종 있습니다. 즉, AWS Lambda 를 데이터소스로 둔 리졸버가 필요한 경우이죠!
이번 글에서는 이러한 케이스에 맞춰서 AWS Amplify 의 Lambda-backed 커스텀 리졸버를 어떻게 만들 수 있는지 알아보겠습니다! (사실 Amplify 공식문서를 보면 다 나와있지만, 한국어로도 한번 정리해두는 것이 좋을 것 같다는 생각으로 쓰고 있습니다ㅎㅎ)
AWS Amplify: Add a custom resolver that targets an AWS Lambda function
직접 만들어봅시다!
우선, amplify init 을 통해 Amplify 프로젝트를 생성합니다. 이 과정은 스킵하고 넘어가겠습니다!ㅎㅎ
1. amplify add function
기존 Lambda 리소스가 존재하는 경우에는 생략해도 괜찮지만, amplify push 와 함께 배포 사이클을 같이 설정해두고 싶은 경우에는 amplify add function 을 통해 Lambda 리소스를 만드는것이 좋습니다. amplify add function 과 관련한 공식 문서는 아래 링크를 참조해주세요 :)
AWS Amplify CLI: function Overview
다시 본론으로 돌아와서, Amplify CLI 를 통해 amplify add function 을 실행시키신 후에,
? Choose the function template that you want to use:
라고 나오는 선택지에서는 Hello world function 을 선택해서 진행해보겠습니다.
? Do you want to access other resources created in this project from your Lambda function? (Y/n)
라고 나오는 선택지에서는, Y 를 입력하면 Amplify 프로젝트에 등록해둔 카테고리 들을 선택하는 질문이 나옵니다. 이 과정은 IAM Policy 와 관련해서 권한설정을 자동화하기 위한 질문인데, 기존 프로젝트에서도 n 을 입력하고나서 추후에 간단하게 "직접" 입력할 수 있으므로 잘 모르겠으면 n 을 누르셔도 무방합니다!
나머지는 적당히 선택해주고 amplify add function 과정을 마치고 나면
- amplify function build
- amplify function invoke ${function-name}
- amplify push
등을 적절하게 활용해서 개발하시면 됩니다! 이번 글에서는 function 보다는 커스텀 리졸버에 초점을 맞춰서 작성하려고 하기때문에 function 은 이쯤하고 스킵하도록 하겠습니다 :)
다음 스텝으로 넘어가기 전에, 저는 이번 포스팅을 위해 amplify 프로젝트를 새로 만들었으므로 amplify add api 도 해주고 넘어가도록 하겠습니다 :)
2. schema.graphql 에 커스텀 쿼리 선언
amplify/backend/api/${API명}/schema.graphql 폴더에 만드려고 하는 커스텀쿼리를 직접 작성해줍니다.
...
input MyCustomLambdaExecutionInput {
message: String!
}
type MyCustomLambdaExecutionResult {
data: String!
}
type Query {
myCustomLambdaExecution(input: MyCustomLambdaExecutionInput): MyCustomLambdaExecutionResult!
}
저는 input 타입과 result 타입도 직접 작성해주었습니다. 참고로, 이번에는 Query 에 대해서 진행하지만, Mutation 도 커스터마이징 할 수 있습니다!ㅎㅎ
3. 커스텀 리졸버용 CloudFormation 템플릿 작성
Amplify 공식 문서에서는 amplify/backend/api/${API명}/stacks/CustomResources.json 이라는 디폴트 템플릿에 리소스를 추가하는 것으로 설명하고 있는데, 실제 프로젝트에서는 이런식으로 커스텀 리소스를 추가하면, 마치 하나의 파일에 모든 백엔드 로직을 다 작성하는 것과 같은 수준의 복잡함을 떠안아야하는 문제가 생깁니다. amplify/backend/api/${API명}/stacks/ 아래의 모든 *.json 파일은 자동으로 함께 디플로이되므로 각 커스텀 리소스마다 CloudFormation 템플릿을 파일별로 분리시켜서 관리하시는 것을 개인적으로 추천합니다!
저의 경우 커스텀 쿼리의 이름이 myCustomLambdaExecution 이므로 myCustomLambdaExecution-stack.json 이라는 이름으로 새 파일을 만들어서 아래 코드를 입력해보겠습니다.
{
"AWSTemplateFormatVersion": "2010-09-09",
"Description": "An auto-generated nested stack.",
"Metadata": {},
"Parameters": {
"AppSyncApiId": {
"Type": "String",
"Description": "The id of the AppSync API associated with this project."
},
"AppSyncApiName": {
"Type": "String",
"Description": "The name of the AppSync API",
"Default": "AppSyncSimpleTransform"
},
"env": {
"Type": "String",
"Description": "The environment name. e.g. Dev, Test, or Production",
"Default": "NONE"
},
"S3DeploymentBucket": {
"Type": "String",
"Description": "The S3 bucket containing all deployment assets for the project."
},
"S3DeploymentRootKey": {
"Type": "String",
"Description": "An S3 key relative to the S3DeploymentBucket that points to the root\nof the deployment directory."
}
},
"Resources": {
"MyCustomLambdaExecutionLambdaResolverDataSource": {
"Type": "AWS::AppSync::DataSource",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"Name": "MyCustomLambdaExecutionLambdaResolverDataSource",
"Type": "AWS_LAMBDA",
"ServiceRoleArn": {
"Fn::GetAtt": [
"MyCustomLambdaExecutionLambdaResolverDataSourceRole",
"Arn"
]
},
"LambdaConfig": {
"LambdaFunctionArn": {
"Fn::Sub": [
"arn:aws:lambda:${AWS::Region}:${AWS::AccountId}:function:amplifycustomresolve86b2a0f6-${env}",
{ "env": { "Ref": "env" } }
]
}
}
}
},
"MyCustomLambdaExecutionLambdaResolverDataSourceRole": {
"Type": "AWS::IAM::Role",
"Properties": {
"RoleName": {
"Fn::Sub": [
"MyCustomLambdaExecutionLambdaResolverDataSourceRole-${env}",
{ "env": { "Ref": "env" } }
]
},
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "appsync.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
},
"Policies": [
{
"PolicyName": "InvokeLambdaFunction",
"PolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"lambda:invokeFunction"
],
"Resource": [
{
"Fn::Sub": [
"arn:aws:lambda:${AWS::Region}:${AWS::AccountId}:function:amplifycustomresolve86b2a0f6-${env}",
{ "env": { "Ref": "env" } }
]
}
]
}
]
}
}
]
}
},
"MyCustomLambdaExecutionLambdaResolver": {
"Type": "AWS::AppSync::Resolver",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"DataSourceName": {
"Fn::GetAtt": [
"MyCustomLambdaExecutionLambdaResolverDataSource",
"Name"
]
},
"TypeName": "Query",
"FieldName": "myCustomLambdaExecution",
"RequestMappingTemplateS3Location": {
"Fn::Sub": [
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Query.myCustomLambdaExecution.req.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
},
"ResponseMappingTemplateS3Location": {
"Fn::Sub": [
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Query.myCustomLambdaExecution.res.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
}
}
}
}
}
CloudFormation 에 익숙하신 분들은 살짝만 읽어보면 무엇을 하는지 바로 파악하실 수 있으시겠지만, CloudFormation 에 익숙하지 않으신 분들을 위해 위의 코드가 어떤 동작을 하는지 간략히 설명해보겠습니다
우선, 전체적으로 3가지 리소스를 생성합니다.
- AWS::AppSync::DataSource 타입의 Lambda 데이터소스 등록 (CloudFormation 에서는 등록도 리소스로 취급)
-
AWS::IAM::Role 타입의 Lambda 데이터소스가 의존관계를 가지는 IAM Role 을 생성
-
AWS::AppSync::Resolver 타입의 AppSync 리졸버 생성
각각에 대한 자세한 설명은 이번 글의 요지에서 벗어나므로 다른 글에서 CloudFormation 에 대해 좀 더 자세히 설명해보도록 하겠습니다. 이번 글에서는 CloudFormation 에 대한 전제지식이 어느정도 있으신 분들을 대상으로 포인트가 되는 부분들에 대해서만 언급하고 넘어가도록 하겠습니다.
포인트 설명
1. 네이밍 규칙을 확실하게 정하자
템플릿 코드를 보시면 이미 느끼시겠지만, 네이밍이 상당히 복잡한 것을 확인하실 수 있습니다. 저의 경우, Query 나 Mutation 의 이름을 적극적으로 사용하여
- 데이터소스 : Query/Mutation 이름 + LambdaResolver + DataSource
- IAM 롤 : Query/Mutation 이름 + LambdaResolver + DataSourceRole
- 리졸버 : Query/Mutation 이름 + LambdaResolver
의 규칙으로 Logical ID 를 정의했고, 실제 리소스명에 대해서도 위 규칙을 그대로 적용했습니다.
2. Lambda 의 arn 을 잘 확인하자
Lambda 의 arn 의 입력을 요구하는 리소스는 두가지 입니다.
- 데이터소스
- IAM Role
amplify add function 으로 등록한 Lambda 의 경우 amplify/backend/function/${function명}/${function명}-cloudformation-template.json 파일에서 Resources > LambdaFunction > Properties > FunctionName 에 선언되어 있으므로 기억이 안나시면 이쪽을 확인하시면 됩니다 :)
참고로, Lambda 함수에도 Query/Mutation 이름을 그대로 적용하는 룰을 지키면 더더욱 관리하기 용이할 것 같습니다!
추가적으로, amplify/backend/api/${API명}/parameters.json 에 해당 Lambda 의 arn 을 적어두고 CloudFormation 의 Parameters 로 받을수도 있지만 이번 글에서는 그냥 직접 입력하는 것으로 진행하겠습니다.
3. VTL 파일의 이름을 잘 적어주자
AppSync 리졸버 선언에서 Query/Mutation 타입과 필드명, 그리고 VTL 형식의 AppSync 리졸버 파일명을 실수없이 잘 적어주는 것이 중요합니다. 이번 글에서 "Lambda 리졸버" 라는 표현을 사용하고 있어서 개념이 헷갈리실 수 있으니 다시한번 용어를 정리하고 넘어가도록 하겠습니다.
AppSync 의 "리졸버" 는 오직 VTL 타입만 지원합니다. 따라서 모든 리졸버는 전부다 VTL 형식으로 적히는 것이 맞습니다.
그럼 Lambda 는 리졸버가 아닌가? 에 대한 대답은, 저희는 Lambda 를 리졸버 역할로 사용하고 있지만, 실제로 AppSync 에서 바라볼때 Lambda 는 리졸버가 아니라 "데이터소스" 로 인식하고 있으므로 정확한 용어는 Lambda 데이터소스 라고 말하는 것이 맞습니다.
하지만, 이 경우, VTL 형식의 리졸버는 단순히 Lambda 에 넘겨줄 데이터를 그대로 넘겨주기만하는 프록시 역할만 하게 되므로 편의상 이글에서는 계속해서 LambdaResolver 라는 표현을 쓰고 있습니다. 이 개념이 헷갈리신다면 먼저 용어에 대한 정의를 확실하게 해두고 넘어가도록 합시다! :)
다시 본론으로 돌아와서, 커스텀 리졸버는 Query 타입과 Mutation 타입을 둘 다 지원하므로, Query 타입 리졸버를 만들때는 Query 를, Mutation 타입 리졸버를 만들때는 Mutation 을 반드시 CloudFormation 과 VTL 파일명에도 같이 통일 시켜줘야합니다.
이번 글에서는 Query 타입이므로 Query 로 적고, VTL 파일명도 Query 로 시작하는 파일명을 입력하였습니다. 이 내용은 VTL 파일 안에도 같이 적용되어야하는 포인트이므로 실수해서 시간을 낭비하지 않도록 한번에 집중해서 잘 수정하도록 합니다!
4. VTL 리졸버 작성
이번에는 다시 amplify/backend/api/${API명}/resolvers/` 폴더로 가서 위 CloudFormation 에 선언해둔 resolver 파일 두개를 생성합니다.
제 경우에는
- Query.myCustomLambdaExecution.req.vtl
- Query.myCustomLambdaExecution.res.vtl
였습니다. 각각의 내용은 거의 복붙이지만, 위에서 언급한대로 Query/Mutation 타입과 이름 (필드명) 정도를 반드시 수정해줍니다!
Query.myCustomLambdaExecution.req.vtl 파일의 경우 아래와 같이 입력하고,
{
"version": "2017-02-28",
"operation": "Invoke",
"payload": {
"type": "Query",
"field": "myCustomLambdaExecution",
"arguments": $utils.toJson($context.arguments),
"identity": $utils.toJson($context.identity),
"source": $utils.toJson($context.source)
}
}
Query.myCustomLambdaExecution.res.vtl 파일의 경우 아래와 같이 입력합니다.
$util.toJson($ctx.result)
5. Lambda 함수 작성 (실제 커스텀 리졸버 역할)
이번에는 정의한 Query 의 인풋과 아웃풋 타입에 맞춰서 Lambda 함수를 수정해보겠습니다.
Node.js 타입으로 Lambda 환경을 구성한 경우에는 아래와 같이 코드를 입력해주세요.
exports.handler = async (event) => {
const response = {
data: "input message was: " + event.arguments.input.message
};
return response;
};
6. amplify push
드디어 모든 설정이 완료되었으므로 amplify push 를 통해 모든 리소스를 배포합니다. 참고로, 개발할 때는 amplify push -y 옵션을 주면 중간에 기다렸다가 y 를 눌러주지 않아도 되어서 편리합니다 :)
7. 결과 확인
amplify console api 를 입력하고 GraphQL 을 선택하면 AppSync 쿼리창이 열립니다. 아래와 같이 입력해서 지금까지 작성한 커스텀 쿼리가 정상작동하는 것을 확인해봅시다!
query customQuery {
myCustomLambdaExecution(input: {
message: "Hello"
}) {
data
}
}

마치며
이번 글에서는 Amplify 로 개발하다가 필연적으로 마주치는 커스텀 리졸버를 작성하는 방법에 대해 설명하였습니다.
CloudFormation 을 잘 아시는 분이나 모르시는 분들이나 둘 다, 함수하나 추가하는건데 뭐가 이리 복잡해?! 라고 생각하실 수도 있을 것 같습니다. 저도 그렇게 생각하니까요ㅠㅠㅋㅋㅋ
네, 제 생각에도 커스텀 리졸버를 몇개 정도가 아니라 수십개 이상 작성해야하는 경우에는, Amplify 가 아닌 직접 백엔드를 구축해서 개발하는 것이 더 효율적일 것 같습니다. 하지만 그렇지 않은 경우, MVP 를 목적으로 빠르고 효율적인 개발을 목적으로 하시는 경우에는 커스텀 리졸버 몇개 정도 직접 설정하는 것 정도는 전체 백엔드를 직접 하나하나 개발하는 것보다 훨씬 더 편리하게 개발하실 수 있지 않을까 생각합니다. 그리고 어느정도 비즈니스가 성장하면 특정 시점에 Amplify 에서 벗어나서 직접 백엔드를 구축해서 마이그레이션을 진행하는 것이 빠르게 변화하는 시장의 니즈를 만족시킬 수 있는 앱을 적시적소에 출시할 수 있는 전략이 되지 않을까 생각합니다.
이상, 컨설팅부의 김태우였습니다! :D