
DuckDBを使ってS3に格納されているParquetファイルを調査してみた
はじめに
データ事業本部ビッグデータチームのkasamaです。
今回はDuckDBを使ってS3に格納されているParquetファイルを調査したいと思います。
背景
秘匿性の高いデータのため、ファイルをローカルにダウンロードできない制約がある環境で、S3上のParquetファイルを効率的に分析したい場合に有効です。
DuckDBを使用することで、ファイルをダウンロードすることなく、S3上のParquetファイルを直接操作できます。
テストデータ準備
まず、テストデータを準備します。AWS CloudShell上でPythonスクリプトを実行し、任意のS3 BucketにParquetファイルを作成します。
まず、CloudShellにログインし、必要なライブラリをインストールします。
pip install --user pandas pyarrow boto3 numpy
続いて、作成した任意のBucketを環境変数に設定します。
export BUCKET_NAME="<sample-analytics-bucket>"
以下のコマンドを実行し、Parquetファイルを生成するスクリプトを作成します。
cat > create_sample_parquet.py << 'EOF'
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
import boto3
import pyarrow as pa
import pyarrow.parquet as pq
from io import BytesIO
import os
# 環境変数からバケット名を取得
bucket_name = os.environ.get('BUCKET_NAME', 'sample-analytics-bucket')
print(f"Using bucket: {bucket_name}")
# S3クライアントの初期化
s3_client = boto3.client('s3')
def create_sales_data(year_month, num_records=50):
"""売上データを生成"""
np.random.seed(42 + int(year_month.replace('_', '')))
data = {
'id': range(1, num_records + 1),
'product_name': np.random.choice(['Apple iPhone', 'Samsung Galaxy', 'Google Pixel'], num_records),
'category': np.random.choice(['Electronics', 'Mobile', 'Gadgets'], num_records),
'customer_name': [f'Customer_{i:03d}' for i in np.random.randint(1, 100, num_records)],
'amount': np.random.randint(100, 1000, num_records),
'date': pd.date_range(f'2024-{year_month.split("_")[1]}-01', periods=num_records, freq='D')
}
return pd.DataFrame(data)
def create_log_data(year_month, num_records=50):
"""ログデータを生成"""
np.random.seed(100 + int(year_month.replace('_', '')))
data = {
'id': range(1, num_records + 1),
'endpoint': np.random.choice(['/api/users', '/api/products', '/api/orders'], num_records),
'method': np.random.choice(['GET', 'POST', 'PUT'], num_records),
'status': np.random.choice(['SUCCESS', 'ERROR', 'WARNING'], num_records, p=[0.7, 0.2, 0.1]),
'message': [f'Request processed for user_{i}' for i in np.random.randint(1000, 9999, num_records)],
'count': np.random.randint(1, 100, num_records),
'timestamp': pd.date_range(f'2024-{year_month.split("_")[1]}-01', periods=num_records, freq='h')
}
return pd.DataFrame(data)
def upload_parquet_to_s3(df, bucket, key):
"""DataFrameをParquetとしてS3にアップロード"""
try:
buffer = BytesIO()
table = pa.Table.from_pandas(df)
pq.write_table(table, buffer)
buffer.seek(0)
file_size = len(buffer.getvalue())
s3_client.put_object(
Bucket=bucket,
Key=key,
Body=buffer.getvalue(),
ContentType='application/octet-stream'
)
print(f'✓ Uploaded: s3://{bucket}/{key} ({len(df)}行, {file_size:,}bytes)')
except Exception as e:
print(f'✗ Error uploading {key}: {str(e)}')
# メイン処理
try:
print("Parquetファイルの作成を開始します(各50行)...")
# 1. 売上データ(ルートレベル)- 2ファイル
print("売上データを作成中...")
sales_jan = create_sales_data('2024_01', 50)
sales_feb = create_sales_data('2024_02', 50)
upload_parquet_to_s3(sales_jan, bucket_name, 'sales_2024_01.parquet')
upload_parquet_to_s3(sales_feb, bucket_name, 'sales_2024_02.parquet')
# 2. ログデータ(サブディレクトリ)- 1ファイル
print("ログデータを作成中...")
logs = create_log_data('2024_01', 50)
upload_parquet_to_s3(logs, bucket_name, 'logs/access_2024_01.parquet')
print(f"\n🎉 Parquetファイルの作成が完了しました!")
except Exception as e:
print(f"エラーが発生しました: {str(e)}")
EOF
スクリプトを実行します。
python create_sample_parquet.py
以下のようなログになれば成功しています。
Using bucket: <sample-analytics-bucket>
Parquetファイルの作成を開始します(各50行)...
売上データを作成中...
✓ Uploaded: s3://<sample-analytics-bucket>/sales_2024_01.parquet (50行, 5,642bytes)
✓ Uploaded: s3://<sample-analytics-bucket>/sales_2024_02.parquet (50行, 5,620bytes)
ログデータを作成中...
✓ Uploaded: s3://<sample-analytics-bucket>/logs/access_2024_01.parquet (50行, 6,257bytes)
🎉 Parquetファイルの作成が完了しました!
Parquetファイルの調査
DuckDBに接続し、parquetファイルを調査したいと思います。
S3への設定方法は以下のブログを参考にさせていただきました。
私の環境では、IAM RoleでスイッチしてS3のあるAWSアカウントに接続しているため、その方法で試します。
前提としてDuckDBやAWS CLIコマンドの設定が完了していることとします。DuckDBのversionは1.3.0で実施しました。1.2.0だとエラーとなったのでUpdateしてください。
まず、以下のコマンドでAccessKeyId, SecretAccessKey, SessionTokenを取得します。
aws configure export-credentials --profile <your-profile>
次にDuckDB Local UIを立ち上げます。
duckdb --ui
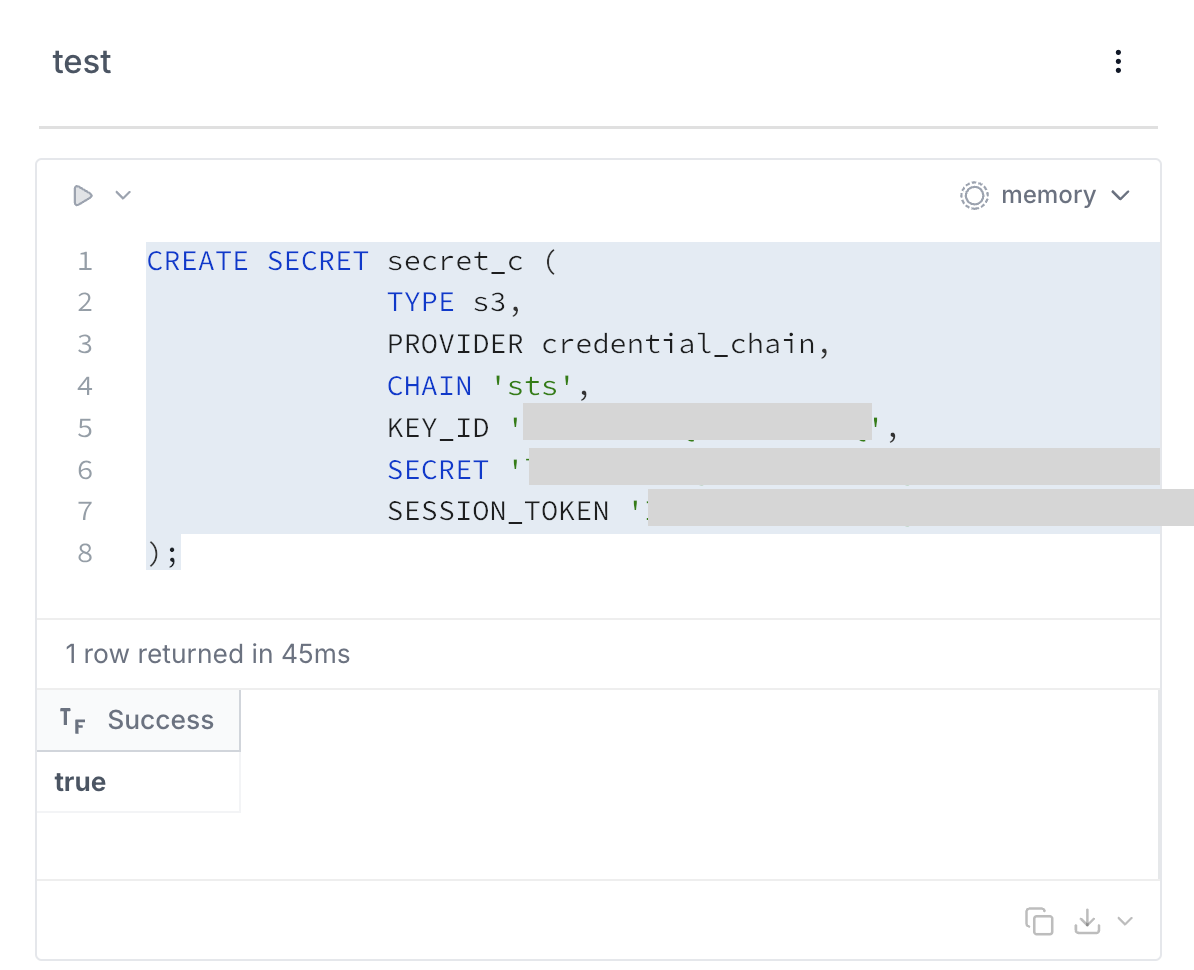
立ち上がったら、セル上で以下のコマンドを実行します。
CREATE OR REPLACE SECRET secret_c (
TYPE s3,
PROVIDER config,
KEY_ID '<取得したAccessKeyId>',
SECRET '<取得したSecretAccessKey>',
SESSION_TOKEN '<取得したSessionToken>'
REGION 'ap-northeast-1'
);
trueで返ってきたら接続成功です。
- ファイル一覧の確認
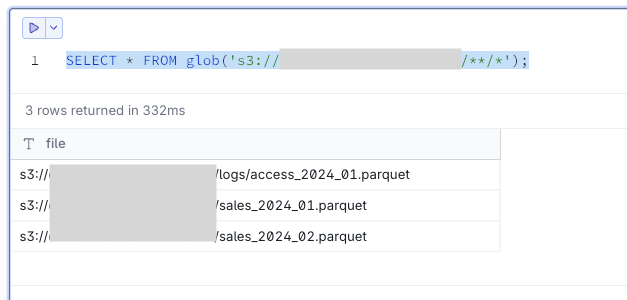
glob()関数を使用して、S3バケット内のParquetファイル一覧を確認します。
-- 基本的なファイル一覧取得
SELECT * FROM glob('s3://<sample-analytics-bucket>/**/*');
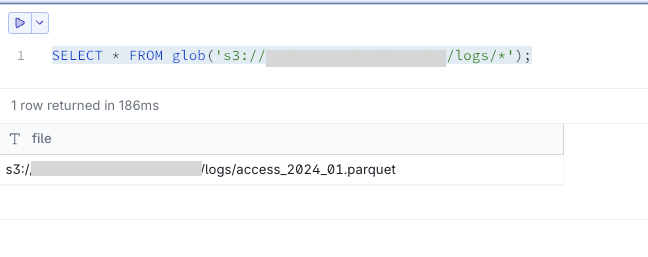
-- 特定pathのファイル一覧取得
SELECT * FROM glob('s3://<sample-analytics-bucket>/logs/*');
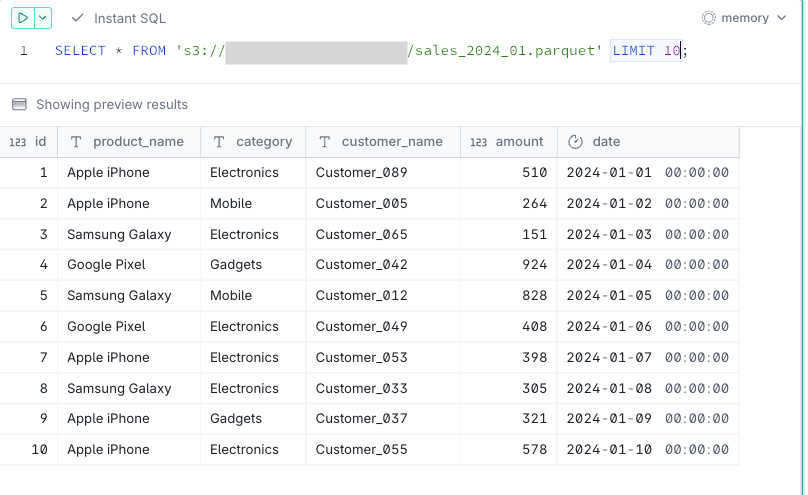
- データの参照・分析
ファイルをダウンロードすることなく、直接データを参照できます。
-- 単一ファイルの参照
SELECT * FROM 's3://<sample-analytics-bucket>/sales_2024_01.parquet' LIMIT 10;
-- 単一ファイルの参照
SELECT * FROM 's3://<sample-analytics-bucket>/sales_2024_01.parquet';
DuckDBのUIであれば、SQL実行結果の右側でカラムごとの集計結果も確認できます。
INT型であればMAX/MINなど。
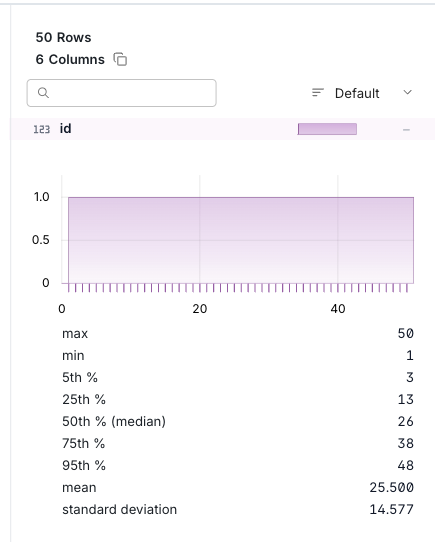
テキスト型であれば文字列ごとの集計。
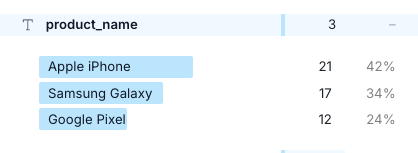
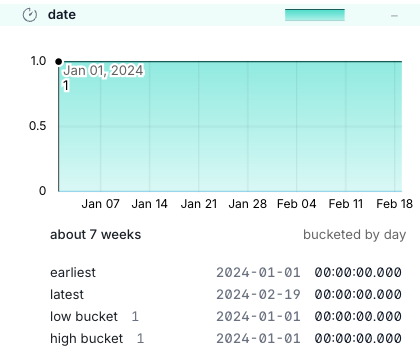
date型であればearliest、latestなど確認できます。
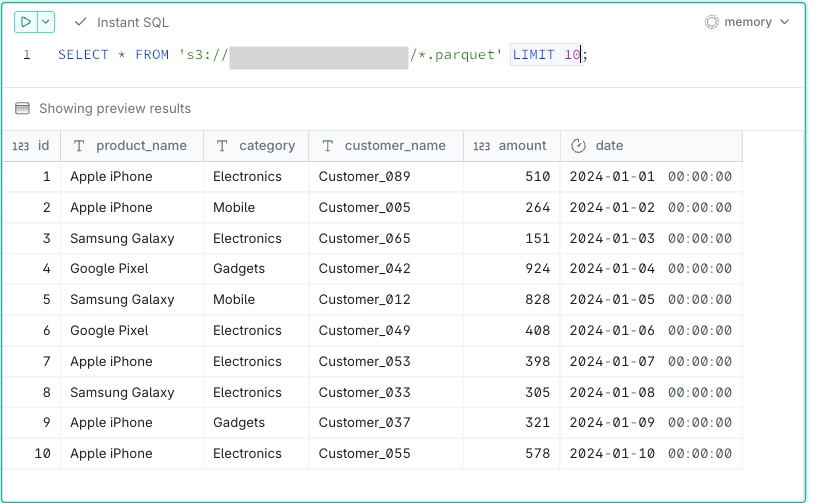
-- 複数ファイルの一括参照
SELECT * FROM 's3://<sample-analytics-bucket>/*.parquet';
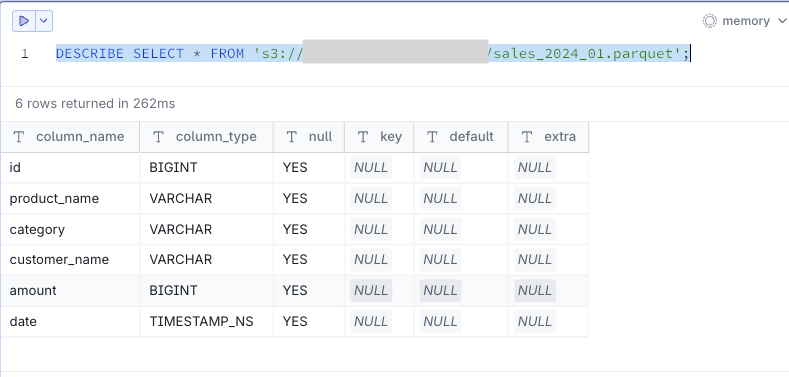
- スキーマ情報の確認
parquetファイルのスキーマ情報を確認できます。
DESCRIBE SELECT * FROM 's3://<sample-analytics-bucket>/sales_2024_01.parquet';
最後に
ローカルでアクセス権限を与えたくない場合は、CloudShell上でDuckDBをinstallしてデータ分析可能なので、役立つ場面は多いかと思いました。参考になれば幸いです。









