
【Apache Iceberg】Apache IcebergのブランチとGlue Data QualityでWAPパターンのデータ品質管理をやってみる
データ事業本部の川中子(かわなご)です。
今回はApache Icebergのブランチ機能とAWS Glue Data Qualityを使って、
WAPパターン(Write-Audit-Publish)によるデータ品質管理をやってみました。
なお本検証は、以下のAWS公式ブログの内容を参考に検証しています。
Apache IcebergにおけるWAPパターンとは
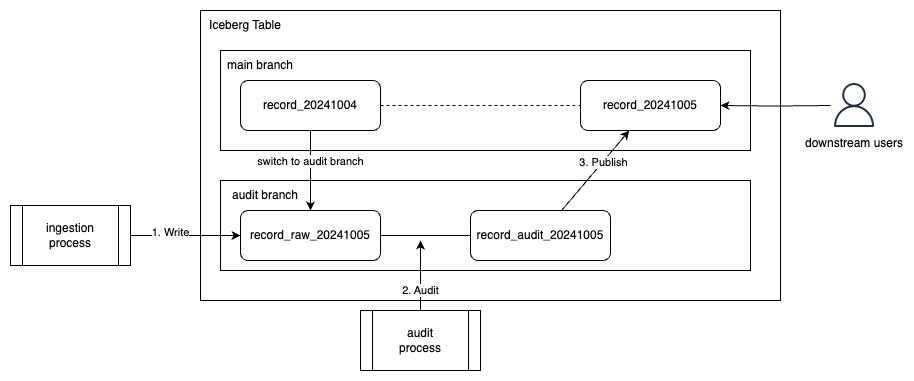
WAPパターンは、データの書き込み・監査・公開を段階的に行うデータ管理手法です。
Apache Icebergのブランチ機能を利用し、以下の流れでデータの品質を管理します。
- 書き込み(Write): データは最初にステージングブランチに書き込まれる
- 監査(Audit): ステージングブランチで品質チェックが実行される
- 公開(Publish): 検証されたデータはメインブランチとして公開される
この手法により、品質に問題のあるデータが本番環境に影響を与えることを防止しつつ、
品質検証前後のデータの両方を保持・管理できます。
検証準備
データの準備
データ品質管理の効果を確認するため、正常データと異常データの2つを用意しました。
それぞれをData Wranglerで確認してみます。
正常データ(sensor_normal.parquet)は、部屋の温度や湿度の情報を持ち、
温度と湿度の値がきれいな山なりの分布になっているデータです。

対して異常データ(sensor_anomaly.parquet)は分布が偏っており、
極端に大きな値が含まれているデータになっています。

これらのデータをそれぞれcurrentとnewというプレフィックス配下に配置します。
aws s3 ls cm-kawanago-dq-branch --recursive
2025-08-29 17:09:08 0 current/
2025-08-29 17:09:23 21127 current/sensor_normal.parquet
2025-08-29 17:54:54 0 new/
2025-08-29 17:55:02 21705 new/sensor_anomaly.parquet
検証
Icebergテーブルの作成
正常データからCTASで、汎用S3バケット上にIcebergテーブルを作成していきます。
DATA_SRC = 's3://cm-kawanago-dq-branch'
DB_TBL = 'default.room_data'
spark.read.parquet(f'{DATA_SRC}/current').createOrReplaceTempView('tmp')
spark.sql(f"""
CREATE TABLE {DB_TBL}
TBLPROPERTIES (
'table_type'='iceberg',
'write_compression'='zstd'
)
AS SELECT * FROM tmp ORDER BY location
""")
テーブルの作成を確認できました。
spark.sql(f"select * from {DB_TBL} limit 10").show()
# 出力結果
+-------------------+-----------+--------+--------+
| timestamp|temperature|humidity|location|
+-------------------+-----------+--------+--------+
|2024-01-01 00:00:00| 18.3| 35.0| bedroom|
|2024-01-01 00:10:00| 16.3| 52.9| bedroom|
|2024-01-01 00:20:00| 18.7| 49.4| bedroom|
|2024-01-01 00:30:00| 16.4| 60.3| bedroom|
|2024-01-01 00:40:00| 19.7| 48.3| bedroom|
|2024-01-01 00:50:00| 16.1| 49.8| bedroom|
|2024-01-01 01:00:00| 17.2| 48.3| bedroom|
|2024-01-01 01:10:00| 21.5| 39.8| bedroom|
|2024-01-01 01:20:00| 17.9| 43.3| bedroom|
|2024-01-01 01:30:00| 16.4| 32.9| bedroom|
+-------------------+-----------+--------+--------+
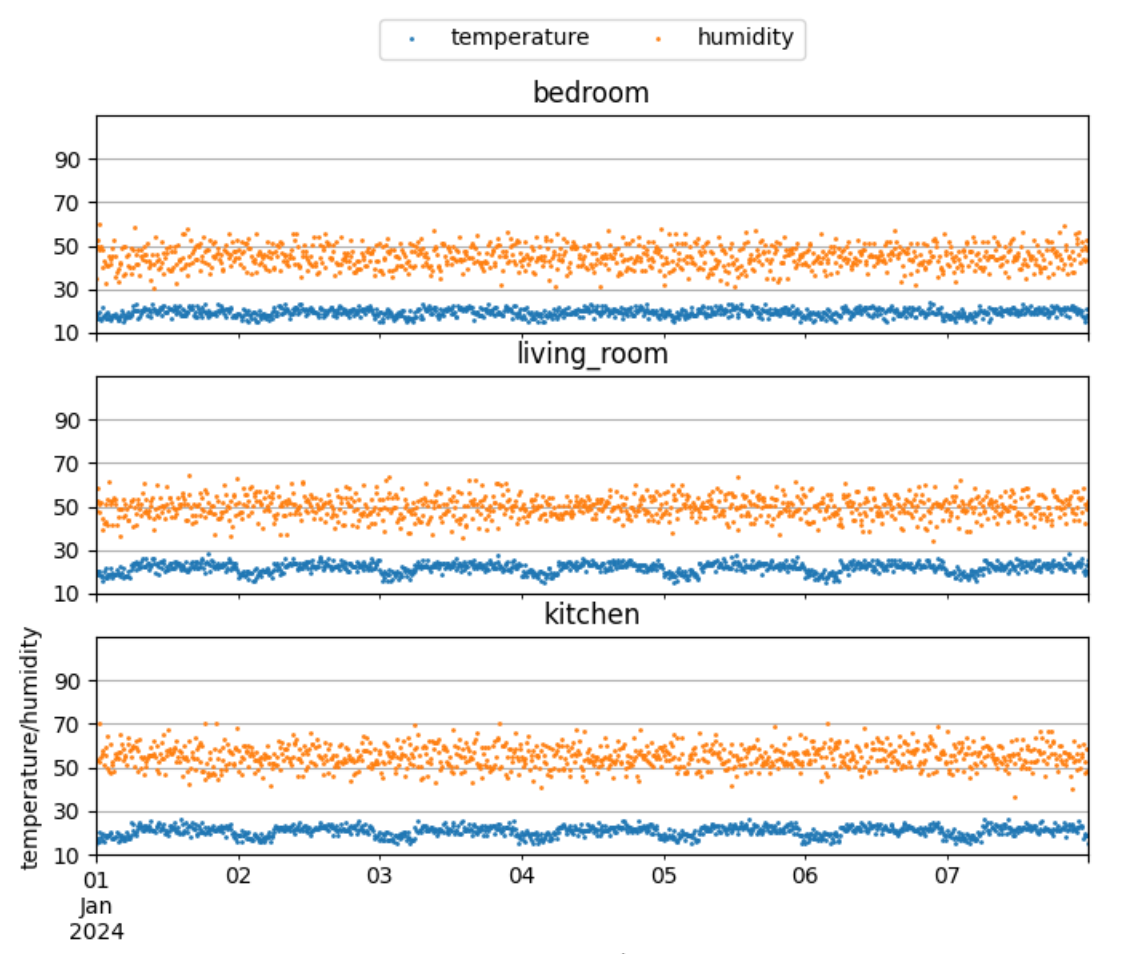
データを可視化してみると、温度と湿度はそれぞれ、
一定の範囲内に収まりながら計測されていることが分かります。
ブランチの作成
次に、テーブルにstg(ステージング)とaudit(監査)のブランチを作成します。
ALTER TABLE default.room_data CREATE BRANCH stg;
ALTER TABLE default.room_data CREATE BRANCH audit;
ブランチが正常に作成されたことを確認できました。
spark.sql(f"SELECT * FROM {DB_TBL}.refs;").show()
# 出力結果
+-----+------+-------------------+-----------------------+---------------------+----------------------+
| name| type| snapshot_id|max_reference_age_in_ms|min_snapshots_to_keep|max_snapshot_age_in_ms|
+-----+------+-------------------+-----------------------+---------------------+----------------------+
| main|BRANCH|3821557631073642592| NULL| NULL| NULL|
|audit|BRANCH|3821557631073642592| NULL| NULL| NULL|
| stg|BRANCH|5399698949265604605| NULL| NULL| NULL|
+-----+------+-------------------+-----------------------+---------------------+----------------------+
S3 Tablesの制約について
当初はS3 Tables上での実装を試みましたが、
ブランチを指定してデータの挿入を試みると以下のエラーが発生しました。
org.apache.iceberg.exceptions.ValidationException: S3TablesCatalog does not support more than 1 level of namespace
どうやらS3TablesCatalogカタログが現時点(2025/08/31)では、
{namespace}.{table}.{branch}のような3層以上の指定に対応していないようです。
そのため、汎用バケット上のIcebergテーブルで検証をしています。
この点については今後のアップデートで利用できるようになるかも知れません。
stgブランチへのデータ書き込み
異常データをstgブランチに書き込んでいきます。
spark.read.parquet(f'{DATA_SRC}/new').createOrReplaceTempView('tmp_incoming_records')
spark.sql(f"INSERT INTO {DB_TBL}.branch_stg SELECT * FROM tmp_incoming_records")
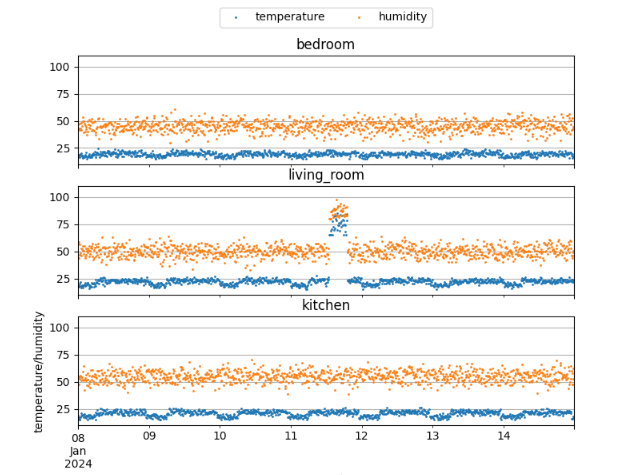
可視化してみると、リビングの一部データが大幅に上振れしていることが確認できました。
AWS Glue Data Qualityによる品質チェック
次にData Qualityのルールを定義して、stgブランチのデータを検証してみます。
ルールは温度と湿度それぞれで、指定した範囲内に含まれるかどうかを確認しています。
from awsglue.context import GlueContext
from awsglue.transforms import SelectFromCollection
from awsglue.dynamicframe import DynamicFrame
from awsgluedq.transforms import EvaluateDataQuality
dyf = DynamicFrame.fromDF(
dataframe=spark.sql(f"SELECT * FROM {DB_TBL}.branch_stg"),
glue_ctx=GlueContext(spark.sparkContext),
name='dyf')
DQ_RULESET = """Rules = [
ColumnValues "temperature" between -10 and 50,
ColumnValues "humidity" between 25 and 70
]"""
dyfc_eval_dq = EvaluateDataQuality().process_rows(
frame=dyf,
ruleset=DQ_RULESET,
publishing_options={
"dataQualityEvaluationContext": "dyfc_eval_dq",
"enableDataQualityCloudWatchMetrics": False,
"enableDataQualityResultsPublishing": False,
},
additional_options={"performanceTuning.caching": "CACHE_NOTHING"},
)
# 品質チェック結果を確認
dyfc_rule_outcomes = SelectFromCollection.apply(
dfc=dyfc_eval_dq,
key="ruleOutcomes")
dyfc_rule_outcomes.toDF().select('Outcome', 'FailureReason').show(truncate=False)
品質チェックの結果、温度と湿度でそれぞれ品質エラーが検知されました。
+-------+-----------------------------------------------------+
|Outcome|FailureReason |
+-------+-----------------------------------------------------+
|Failed |Value: 84.9 does not meet the constraint requirement!|
|Failed |Value: 97.6 does not meet the constraint requirement!|
+-------+-----------------------------------------------------+
検証済みレコードの公開
定義した品質ルールを満たすレコードを抽出し、auditブランチに書き込みます。
dyfc_rowlevel_outcomes = SelectFromCollection.apply(
dfc=dyfc_eval_dq,
key="rowLevelOutcomes")
df_outcomes_success = dyfc_rowlevel_outcomes.toDF().filter("DataQualityEvaluationResult = 'Passed'")
df_outcomes_success.select('location', 'timestamp', 'temperature', 'humidity')\
.writeTo(f"{DB_TBL}.branch_audit").overwritePartitions()
品質検証が完了したデータを、fast_forwardを使ってmainブランチに公開します。
CALL glue_catalog.system.fast_forward(table => 'default.room_data', branch => 'main', to => 'audit')
結果
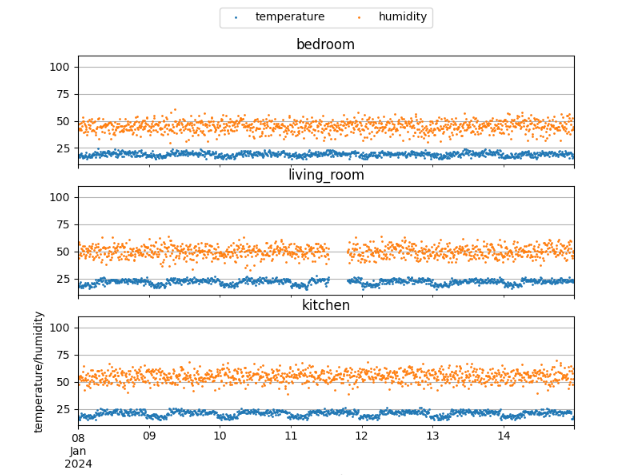
mainブランチを対象にデータを可視化してみると、
異常検出されたデータが除外された形でデータが公開されていることが確認できました。
さいごに
Apache Icebergのブランチ機能とAWS Glue Data Qualityを組み合わせることで、
WAPパターンによる安全なデータ品質管理が実現できることが分かりました。
今回はソースデータを連携するだけのシンプルなパターンを検証しましたが、
特に複雑な整合性の検証や、大規模なデータを連携する場合には、
安全を確認してからmainに公開できるフローは有効だと思いました。
少しでも参考になれば幸いです。
最後まで記事を閲覧頂きありがとうございました。










