
Apache Parquet 入門 - 列指向フォーマットを簡易図とPythonで理解する
はじめに
今年もよろしくお願いします、コンサルティング部のぐっさんです。
現在 DEA の勉強をしているので、今回は「Apache Parquet」というデータフォーマットについて簡単な図解と Python でのデータ処理を交えながら解説します。
AWS の Athena や Glue を調べると「Parquet形式」という言葉をよく見かけますが、実際にどんな仕組みなのかよく分からない...という方も多いのではないでしょうか。私はそうでした。
この記事では、Parquet の仕組みを簡単な図解で理解した後、Python を使って実際にファイルの中身を確認していきます。
一言まとめ
Parquet を使うと 「必要な列だけ読むから速い」「圧縮効率が良い」「型情報があって扱いやすい」 というメリットがあります。
検証の流れ
- Parquet とは何か?(列指向フォーマットの仕組み)
- 列指向のメリットを理解する
- Parquet のファイル構造を知る
- AWS での活用方法を確認する
- Python で実際に Parquet ファイルを作成・中身を確認する
Parquet とは?
一言でいうと、「列指向」のデータフォーマット です。
列指向とは、データを列(カラム)単位でまとめて保存する方式のことです。従来の CSV や JSON は「行指向」でデータを保存しますが、Parquet は「列指向」で保存します。
読み方は「パーケ」「パルケ」「パーケット」等いろいろありそうです。
行指向 vs 列指向
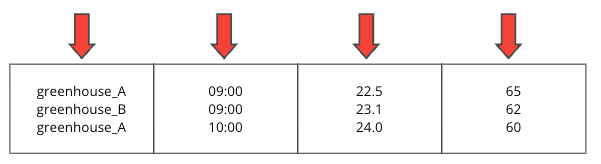
温室のセンサーデータを例に比較します。
元データ(温室センサー)
| greenhouse_id | timestamp | temperature | humidity |
|---|---|---|---|
| greenhouse_A | 2025-01-01 09:00:00 | 22.5 | 65 |
| greenhouse_B | 2025-01-01 09:00:00 | 23.1 | 62 |
| greenhouse_A | 2025-01-01 10:00:00 | 24.0 | 60 |
行指向(CSV, JSON など)の保存順
1行目のデータをすべて保存 → 2行目のデータをすべて保存 → ... という順番で保存します。
[greenhouse_A, 2025-01-01 09:00:00, 22.5, 65], [greenhouse_B, 2025-01-01 09:00:00, 23.1, 62], ...
─────────────── 1行目 ─────────────────── ─────────────── 2行目 ───────────────────
横軸のイメージです。

列指向(Parquet)の保存順
1列目のデータをすべて保存 → 2列目のデータをすべて保存 → ... という順番で保存します。
[greenhouse_A, greenhouse_B, greenhouse_A], [2025-01-01 09:00:00, ...], [22.5, 23.1, 24.0], [65, 62, 60]
────────── greenhouse_id 列 ────────── ──── timestamp 列 ──── ─ temperature 列 ─ ─ humidity 列 ─
縦軸のイメージです。
列指向のメリット
1. クエリが速い
例えば以下のようなクエリを実行する場合。データ抽出時に、読み込むデータ量が異なります。
SELECT AVG(temperature) FROM greenhouse_sensors;
| 形式 | 読み込むデータ |
|---|---|
| 行指向 | 全行(greenhouse_id, timestamp, temperature, humidity すべて) |
| 列指向 | temperature 列のみ |
よって 必要な列だけ読むのでデータが多ければ多いほど、圧倒的に速くなります。
2. 圧縮率が高い
データの圧縮率が高くなり、大量データの場合はファイルサイズを節約出来るといったメリットがあります。
temperature列: [22.5, 23.1, 24.0, 22.8, 23.5, ...]
↓
似た値が並ぶため、圧縮しやすい
注意 Parquet はスキーマや統計情報などのメタデータを持つため、小さいデータ(数百件程度)だと CSV より逆にサイズが大きくなることがあります。大量データで効果を発揮します。
3. 型情報を持つ
CSV: "22.5" ←文字列?数値?
Parquet: 22.5 (DOUBLE) ←型が明確
型情報があると、ETL 処理などでデータ加工を行う際に便利です。
# CSV の場合:型変換が必要
df = pd.read_csv('data.csv')
df['temperature'] = df['temperature'].astype(float) # 手動で型変換
df['date'] = pd.to_datetime(df['date']) # 日付も変換
# Parquet の場合:そのまま使える
df = pd.read_parquet('data.parquet') # 型情報付きで読み込み
Parquet のファイル構造
Parquet ファイルは先頭と末尾に PAR1 というマジックナンバー(4バイト)が配置されており、これによって Parquet ファイルであることを識別できます。
全体の構造は以下のようなイメージです。
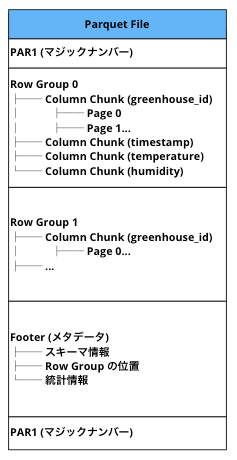
| 要素 | 説明 |
|---|---|
| Row Group | 一定サイズごとにまとめた行のグループ。クエリ時にスキップ判定の単位になる |
| Column Chunk | 1つの Row Group 内の 1列分のデータ |
| Page | Column Chunk 内のデータ単位。実際の値が格納される |
| Footer | メタデータ(スキーマ、統計情報、各要素の位置など) |
※ チャンク(chunk)= 「塊」の意味。大きなデータを扱いやすい単位に分割したもの。
補足 Parquet は HDFS(Hadoop Distributed File System) 上で使われることを前提に設計されました。AWS では HDFS の代わりに S3 を使いますが、この設計思想はそのまま活きています。
スキーマ情報とは
各列のデータ型や構造の定義です。
例:
- greenhouse_id: STRING (文字列)
- timestamp: STRING (文字列)
- temperature: DOUBLE (小数)
- humidity: INT32 (整数)
統計情報とは
各 Column Chunk の要約データです。クエリの高速化に使われます。
例(temperature 列の Column Chunk):
- min: 22.5(最小値)
- max: 24.0(最大値)
- null_count: 0(NULL の数)
補足 文字列型の列(名前など)にも min/max は記録されますが、Unicode のコードポイント順でソートされるため、日本語の場合は意味のある比較になりません。統計情報が活きるのは数値や日付などの値です。
Predicate Pushdown(述語プッシュダウン)
統計情報を使った高速化の仕組みを Predicate Pushdown と呼びます。
SELECT * FROM greenhouse_sensors WHERE temperature > 30;
例えば上記のクエリを実行するとき・・・
1. Footer の統計情報を見る
→ 「temperature 列の max は 24.0」
2. 条件と比較
→ 「24.0 < 30 なので該当データは絶対にない」
3. この Row Group をスキップ!
→ データ本体を読まずに済む
つまり、統計情報だけを見て不要なデータを読み飛ばすことで、クエリが高速化されます。
AWS での活用
S3 + Athena(クエリ)
S3: s3://my-bucket/data/greenhouse_sensors.parquet
↓
Athena: SELECT AVG(temperature) FROM sensors WHERE humidity < 50;
↓
必要な列だけ読み込んで高速クエリ
Athena はスキャンしたデータ量に応じて課金されるため、列指向の Parquet を使うと必要な列だけ読み込む = コスト削減にもつながります。
Glue(ETL)
Glue を使うと CSV から Parquet への変換が簡単にできます。
またGlue Studio を使えば、ビジュアルエディタで ETL 処理を作成することもできます。
S3 (CSV) → Glue ETL → S3 (Parquet)
↓
Glue Studio でノーコード変換
実際に試してみる
今回は Python と Jupyter Notebook を使い、ローカル環境で Parquet ファイルの作成・確認を行います。
※各ツールやセッティングの詳細については今回割愛いたします。
検証環境
- OS macOS
- Python 3.13
- 仮想環境(venv)を使用
- 依存ライブラリは
requirements.txtで管理
補足 Jupyter Notebook: ブラウザ上でコードを実行しながら結果を確認できる対話型の開発環境です。データ分析や検証作業でよく使われます。
# requirements.txt
pandas>=2.0.0
pyarrow>=14.0.0
jupyter>=1.0.0
ipykernel>=6.0.0
matplotlib>=3.0.0
# 仮想環境の作成・有効化
python -m venv .venv
source .venv/bin/activate # Windows の場合: .venv\Scripts\activate
# ライブラリのインストール
pip install -r requirements.txt
# Jupyter Notebook の起動
jupyter notebook
Python で Parquet を作成・読み込み
pandasというPythonのライブラリを使えば、CSV と同じ感覚で Parquet ファイルを扱えます。
import pandas as pd
# Parquet 形式でデータを保存
df.to_parquet('data.parquet')
# 読み込み(特定の列だけ取得も可能)
df = pd.read_parquet('data.parquet', columns=['temperature'])
詳しい検証は次のセクションで行います。
より実践的なデータで試す
温室センサーデータは 3 件だけでしたが、より実践的な例として 100 件のデータを扱ってみましょう。
ここでは架空の神社「クラメソ神社」の初詣お祓い参加者データを作成し、最終的に「厄年の人とそうでない人でお守りの購入数に差があるか」を可視化してみます。

なお、データ内の年齢は(大変都合よく)数え年であるものとします。
まずランダムなデータを生成しCSVを作ります。
補足 コード内で
random.seed(42)を設定しています。これは疑似乱数のシードを固定することで、誰がいつ実行しても同じデータが生成されるようにするためです。デバッグや検証で再現性を確保したい場合に便利です。
import pandas as pd
import random
# 再現性のためシード固定
random.seed(42)
# 名前リスト(姓と名を組み合わせ)
last_names = ['田中', '鈴木', '佐藤', '高橋', '伊藤', '渡辺', '山本', '中村', '小林', '加藤',
'吉田', '山田', '松本', '井上', '木村', '林', '斎藤', '清水', '山口', '森']
first_names_male = ['太郎', '一郎', '健太', '翔太', '大輔', '拓也', '健', '直樹', '誠', '亮']
first_names_female = ['花子', '幸子', '美咲', '陽子', '愛', '真由美', '恵子', '由美', '裕子', '明美']
# 厄年(数え年)
# 男性: 25歳、42歳(大厄)、61歳
# 女性: 19歳、33歳(大厄)、37歳、61歳
yakudoshi_male = [25, 42, 61]
yakudoshi_female = [19, 33, 37, 61]
# 100件のデータを生成
data = []
for i in range(1, 101):
gender = random.choice(['男性', '女性'])
if gender == "男性":
name = random.choice(last_names) + random.choice(first_names_male)
yakudoshi_ages = yakudoshi_male
else:
name = random.choice(last_names) + random.choice(first_names_female)
yakudoshi_ages = yakudoshi_female
age = random.randint(18, 70)
is_yakudoshi = age in yakudoshi_ages
omamori_count = random.randint(0, 2)
visit_date = f"2025-01-0{random.randint(1, 3)}"
data.append({
'id': i,
'name': name,
'gender': gender,
'age': age,
'is_yakudoshi': is_yakudoshi,
'omamori_count': omamori_count,
'visit_date': visit_date
})
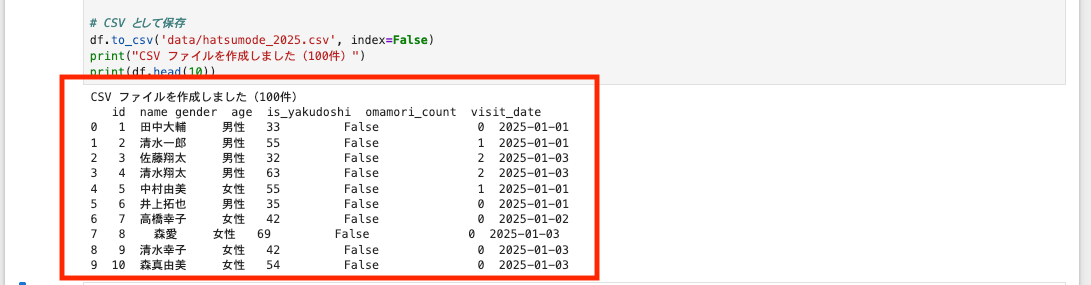
df = pd.DataFrame(data)
# CSV として保存
df.to_csv('data/hatsumode_2025.csv', index=False)
print("CSV ファイルを作成しました(100件)")
print(df.head(10))
これをJupyter Notebookで実行します。
通常はjupyter notebookを実行してブラウザが開いたあと、「New」から「Python3」を選んで新環境で実行します。
※今回私の環境では事前にipynb形式のファイルを用意しているため、画像上ではマークダウンのコメントが見えています。通常、コメント不要で直接コード実行のみですぐに試すことができます。
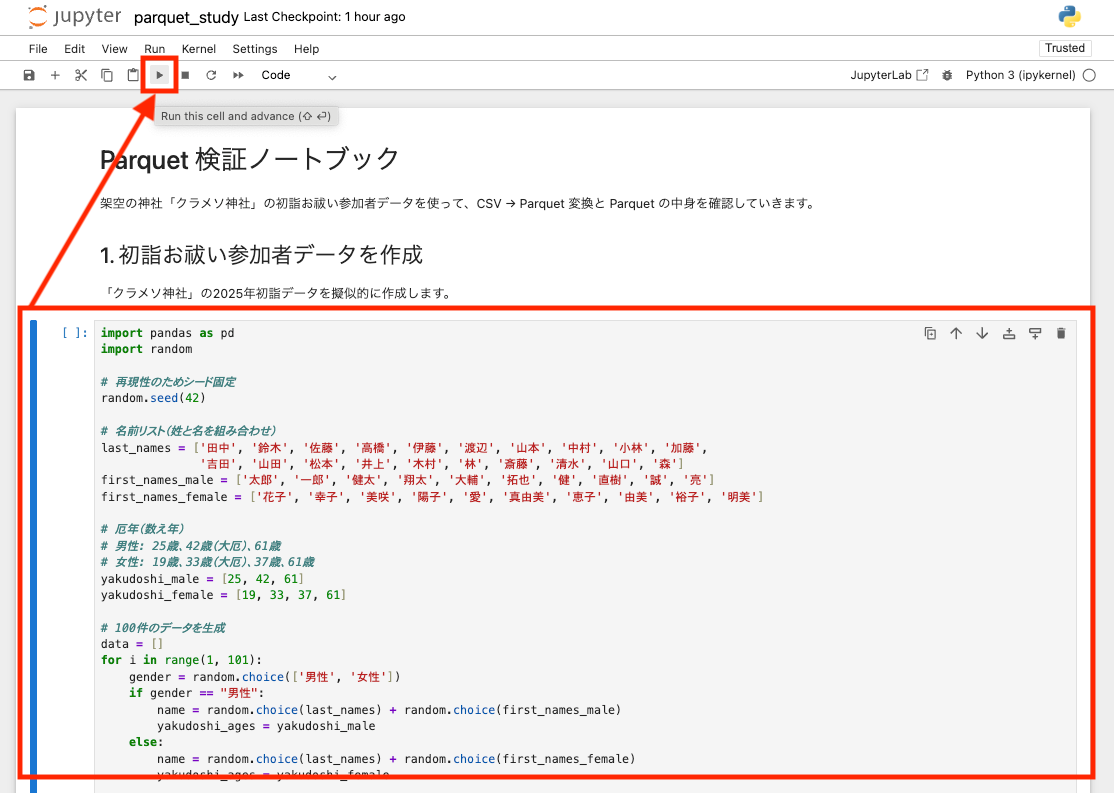
Notebookへの入力例
一つのセル内に上記のコードを格納します。(画像では途切れていますが、print(df.head(10))まで全て入れます)
コードが格納されたセルを押下し選択された状態(左ペインに青い棒線が出た状態)で画面上部の実行ボタンをクリックします。
これで対象のセルのコードのみ実行されます。
出力例
実行すると、コードのセルの直下に結果が出力されます。
データ形式を変換する
次に、pandasを使用して作ったCSVをParquet形式のデータに変換します。
コードはこれだけです。エラーがなければprintの結果のみ出力されます。
# CSV を読み込んで Parquet に変換
df = pd.read_csv('data/hatsumode_2025.csv')
df.to_parquet('data/hatsumode_2025.parquet')
print("Parquet ファイルに変換しました")
出力例

Parquet の Footer を確認
Parquet はバイナリ形式なので、テキストエディタで中身を見ることはできません。pyarrow を使ってスキーマやメタデータを確認してみましょう。
- スキーマ
import pyarrow.parquet as pq
# Parquet ファイルを開く
parquet_file = pq.ParquetFile('data/hatsumode_2025.parquet')
# スキーマ(型情報)を確認
print("=== スキーマ ===")
print(parquet_file.schema)
出力例
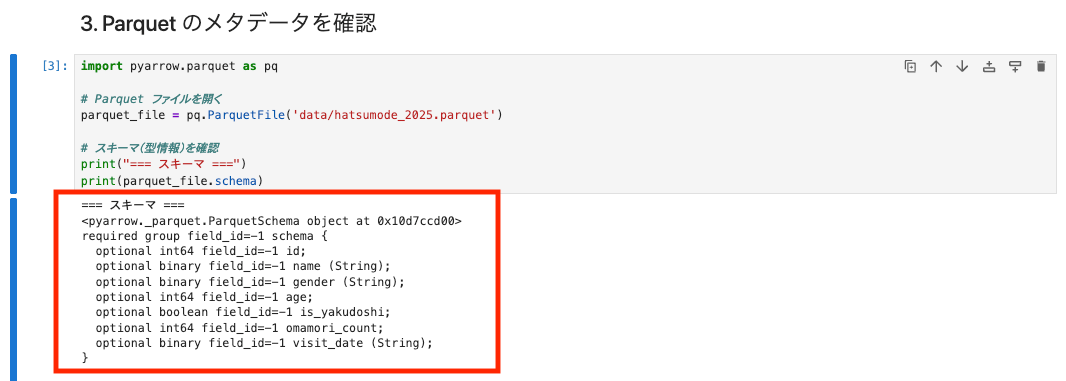
各要素の意味を確認してみましょう。カラムごとのデータ型等が出力されています。
| 要素 | 説明 |
|---|---|
optional / required |
NULL を許容するかどうか。pandas からの変換では基本的に optional になる |
int64, boolean, binary |
物理型(実際にファイルに保存される型)。文字列は binary として保存される |
(String) |
論理型の注釈。「このバイナリは文字列として解釈してね」という意味 |
field_id=-1 |
Apache Iceberg などのテーブルフォーマットで列を識別するための ID。-1 は未設定を意味する(今回は特に気にしなくて OK) |
- メタデータ
# ファイル全体のメタデータ
print("=== メタデータ ===")
print(parquet_file.metadata)
出力例

メタデータでは、全体のカラム数やRow Groupの数などの情報が確認できました。
| 項目 | 説明 |
|---|---|
created_by |
ファイルを作成したライブラリ(今回はpyarrow。※pandasがto_parquetメソッドで内部的に使用) |
num_columns |
列数 |
num_rows |
行数 |
num_row_groups |
Row Group の数(今回はデータが小さいため1つ) |
format_version |
Parquet フォーマットのバージョン |
serialized_size |
Footer のサイズ(バイト) |
- Row Group情報
# Row Group の情報
print("=== Row Group 情報 ===")
print(f"Row Group 数: {parquet_file.metadata.num_row_groups}")
for i in range(parquet_file.metadata.num_row_groups):
rg = parquet_file.metadata.row_group(i)
print(f"\nRow Group {i}:")
print(f" 行数: {rg.num_rows}")
出力例
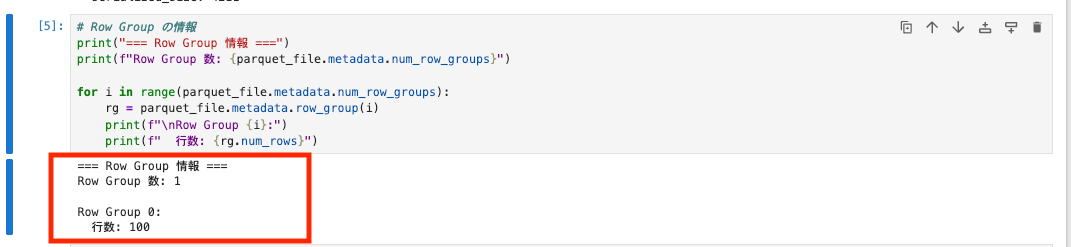
Row Groupごとの情報も確認できました。
今回は 100 件と少ないデータなので Row Group は 1 つだけですが、大量データの場合は複数の Row Group に分割されます。
- 統計情報
# 統計情報を確認(各カラムの min/max)
print("=== 統計情報 ===")
rg = parquet_file.metadata.row_group(0)
for i in range(rg.num_columns):
col = rg.column(i)
print(f"\n{col.path_in_schema}:")
if col.statistics:
print(f" min: {col.statistics.min}")
print(f" max: {col.statistics.max}")
print(f" null_count: {col.statistics.null_count}")
else:
print(" 統計情報なし")
出力例

このように、各列の最小値・最大値・NULL 数などの統計情報が保存されており、Predicate Pushdown に活用されます。
なおやはり漢字のデータは統計に向かないですね。
実際のデータを読み込む
では、肝心のデータを読み込んでみましょう。
parquetの中身をtableオブジェクトとして読み込んだのち、pandasの表の方が見やすいため
parquetからpandasのテーブルに変換したものをprintしています。
# 全データを読み込み
print("=== 全データ ===")
table = parquet_file.read()
print(table.to_pandas())
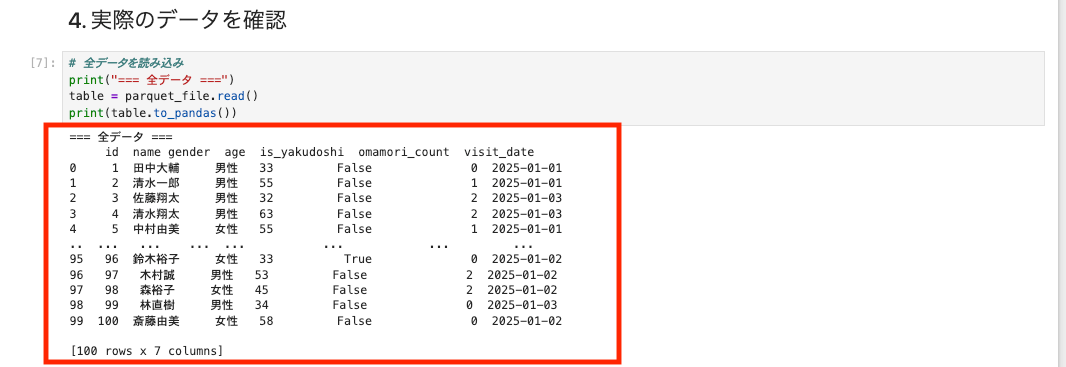
100件のデータが無事入っていそうですね。
ちなみに・・・気になったので見てみましたが、pandasのテーブル変換をせずにそのままprint(table)した結果は以下のようになります!
だいぶ読みにくいですが、列ごとに管理されている様がよくわかりますね。
=== 全データ ===
pyarrow.Table
id: int64
name: string
gender: string
age: int64
is_yakudoshi: bool
omamori_count: int64
visit_date: string
----
id: [[1,2,3,4,5,...,96,97,98,99,100]]
name: [["田中大輔","清水一郎","佐藤翔太","清水翔太","中村由美",...,"鈴木裕子","木村誠","森裕子","林直樹","斎藤由美"]]
gender: [["男性","男性","男性","男性","女性",...,"女性","男性","女性","男性","女性"]]
age: [[33,55,32,63,55,...,33,53,45,34,58]]
is_yakudoshi: [[false,false,false,false,false,...,true,false,false,false,false]]
omamori_count: [[0,1,2,2,1,...,0,2,2,0,0]]
visit_date: [["2025-01-01","2025-01-01","2025-01-03","2025-01-03","2025-01-01",...,"2025-01-02","2025-01-02","2025-01-02","2025-01-03","2025-01-02"]]
特定の列だけ読み込む
次にParquet の列指向フォーマットを活かして、必要な列だけを読み込んでみましょう。
例えばここでは、「厄年の人とそうでない人のお守り購入数の平均」を比べてみることにしましょう。
pandasを使って、どのカラムを取得してくるか設定します。
# 特定の列だけ読み込み(列指向のメリット)
# 「厄年の人のお守り購入数の平均」を知りたい場合、必要な列だけ読めばOK
print("=== is_yakudoshi と omamori_count 列だけ読み込み ===")
df_filtered = pd.read_parquet('data/hatsumode_2025.parquet', columns=['is_yakudoshi', 'omamori_count'])
print(df_filtered.head(10))
# 厄年 vs 厄年でない人 のお守り購入数を比較
yakudoshi_avg = df_filtered[df_filtered['is_yakudoshi'] == True]['omamori_count'].mean()
not_yakudoshi_avg = df_filtered[df_filtered['is_yakudoshi'] == False]['omamori_count'].mean()
print(f"\n=== お守り購入数の平均 ===")
print(f"厄年の人: {yakudoshi_avg:.2f}個")
print(f"厄年でない人: {not_yakudoshi_avg:.2f}個")
出力例
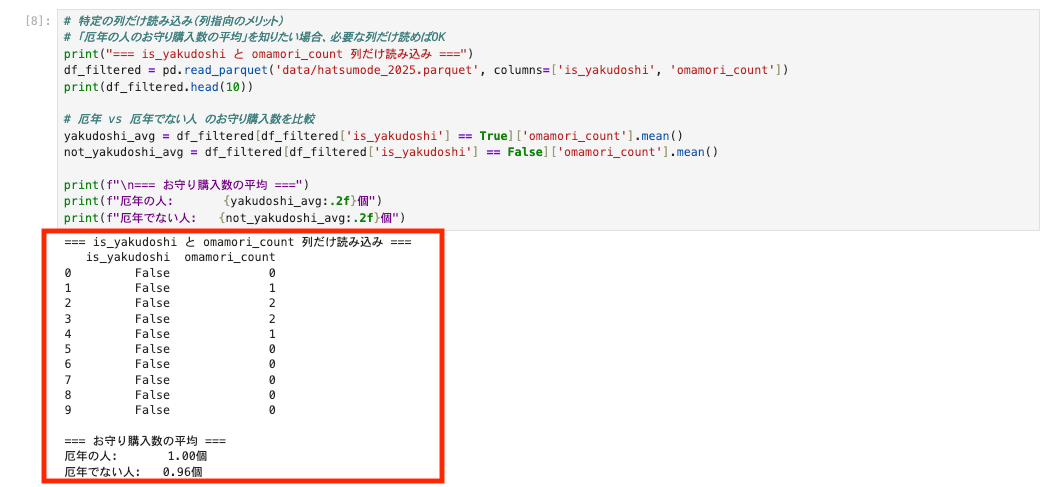
このように、計算に必要な列のみを取得してdf_filteredに格納し、その結果からお守りの購入数の平均を算出するといったことが出来ます。
CSVでも列指定はできますが、全行をスキャンします。反対に、Parquetは物理的に必要な列だけ読むので効率的に抽出が可能です。
データの可視化
最後に、せっかくなので読み込んだデータを matplotlib というライブラリでグラフにして可視化してみましょう。
import matplotlib.pyplot as plt
# 日本語フォント設定(macOS)
plt.rcParams['font.family'] = 'Hiragino Sans'
# 厄年 vs 非厄年のお守り購入数の平均
avg_by_yakudoshi = df.groupby('is_yakudoshi')['omamori_count'].mean()
# グラフ作成
fig, ax = plt.subplots(figsize=(8, 5))
avg_by_yakudoshi.plot(kind='bar', ax=ax, color=['#4CAF50', '#FF5722'])
ax.set_title('厄年 vs 非厄年:お守り購入数の平均', fontsize=14)
ax.set_xlabel('厄年かどうか', fontsize=12)
ax.set_ylabel('お守り購入数(平均)', fontsize=12)
ax.set_xticklabels(['厄年でない', '厄年'], rotation=0)
plt.tight_layout()
plt.show()
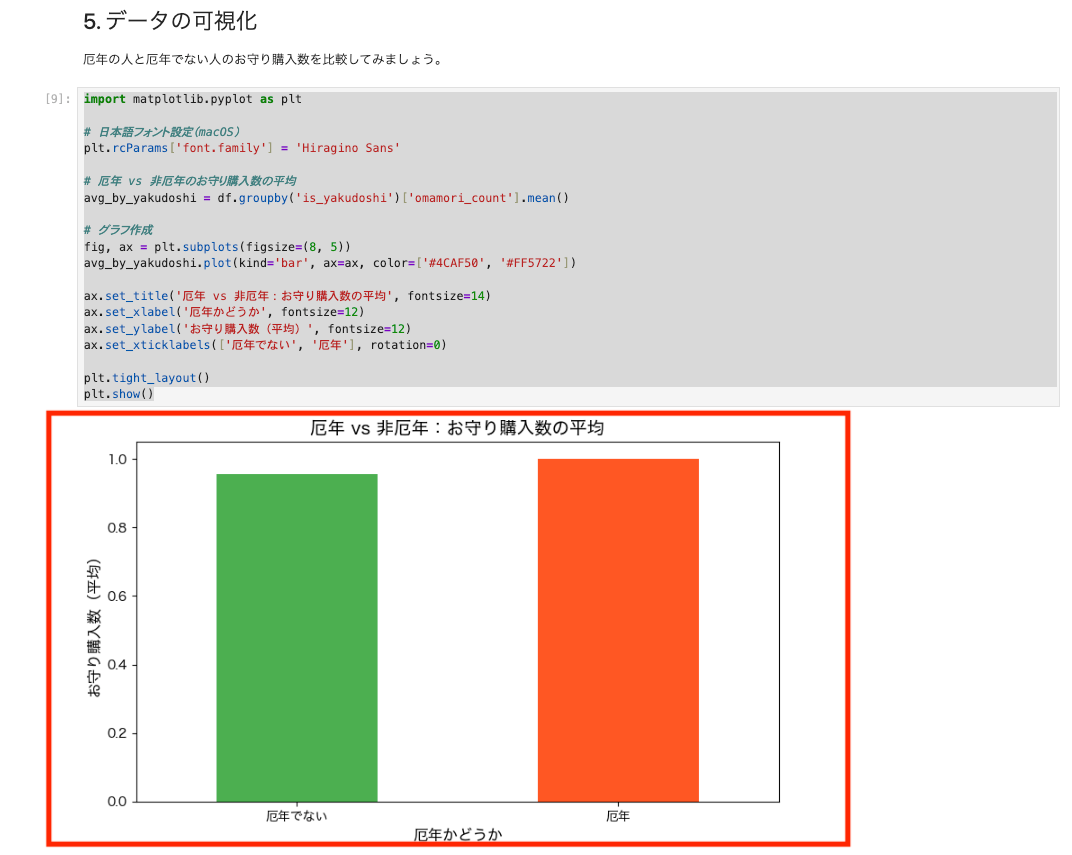
今回はランダムデータなので大きな差は出ていませんが、Parquet から読み込んだデータをそのまま pandas で加工しグラフとして可視化までできることが分かります。
若干ですが、厄年の人の方がお守りを買っていますね。私も去年が厄年だったのでしっかり買いました。涙
まとめ
| 特徴 | 説明 |
|---|---|
| 列指向 | 必要な列だけ読み込める |
| 高圧縮 | 似たデータが並ぶので圧縮しやすい |
| 型情報 | スキーマを持つので型安全 |
| AWS連携 | Athena, Glue, Redshift 等で活用 |
「大量データを効率よく保存・クエリしたい」ときに最適なフォーマットです。
ログ解析やデータ分析で威力を発揮しそうですね。今後実際のサービスやSQLでのクエリも試してみたいと思います。
最後までお読みいただきありがとうございました。この記事が誰かのお役に立てますと幸いです。
余談ですが、最後の見直しで各テストデータの西暦が「2025」になっていることに気がつきました・・・。道理で厄年に引っ張られているわけですね?ご容赦ください。
2026年もみなさま良い1年になりますように。








