
エンジンもバージョンもバラバラなDBを横断するMCPを作ってみた
概要
こんにちは、クラスメソッド製造ビジネステクノロジー部の田中聖也です。
製造業の現場をまわっていると、設備の稼働実績はSCADA、在庫はWMS、部品表はE-BOM、購買は調達システム…というように、業務領域ごとにDBがバラバラに存在していて、しかもエンジンもバージョンもオンプレ/クラウドもバラバラ、という状況によく出会います。「このデータとあのデータを組み合わせて見たいだけなのに、データを集めるだけでも色んな部署の人達から集めないといけない」という問題があると思います。
そこで今回は、自然言語の問い合わせをLLMが解釈して、MCP経由で複数のDB(エンジン違い・バージョン違いを含む)を横断検索するデモアプリを作ってみました。実際に動かしてみると、MCPだけでは難しくて、RAGやオントロジーで意味や知識を連携させないとうまくいかない場面に気づいたので、その試行錯誤も含めて記録に残します。
この記事では以下のことに触れていきます。
- 作ったもの(複数DB横断MCPデモの全体像)
- MCPの動作原理(なぜ複数DBを1つのインターフェースで扱えるのか)
- 動かしてみた結果(うまくいったケース・微妙だったケース)
- MCPだけでは届かなかった「意味のつなぎ目」の話
- RAGとオントロジーが必要になる瞬間
なお、リポジトリはこちらに公開しています。
使い方
このデモアプリは以下のようなフローで動いています
ユーザーが質問入力 (Streamlit)
│
▼
build_agent(role) ← Agent を組み立て (agent.py)
├─ BedrockModel(model_id, region, max_tokens) ← どの LLM を使うかの宣言
├─ MCP 経由で DB ツール一覧を取得
└─ Agent(model=…, tools=…, system_prompt=…)
│
▼
result = agent(question) ← ★ここで初めて LLM にアクセス★
│
Strands が内部でループ:
┌──────────────────────────────────────────┐
│ ① Bedrock Converse API を呼ぶ (boto3 経由) │
│ ② LLM が「DBツールを使え」と返す │
│ ③ MCP サーバーで SQL 実行 │
│ ④ 結果を添えて再び Bedrock を呼ぶ ──┐ │
│ └──── 最終回答が出るまで ①〜④ を反復 ──┘ │
└──────────────────────────────────────────┘
│
▼
str(result) = 最終回答テキスト
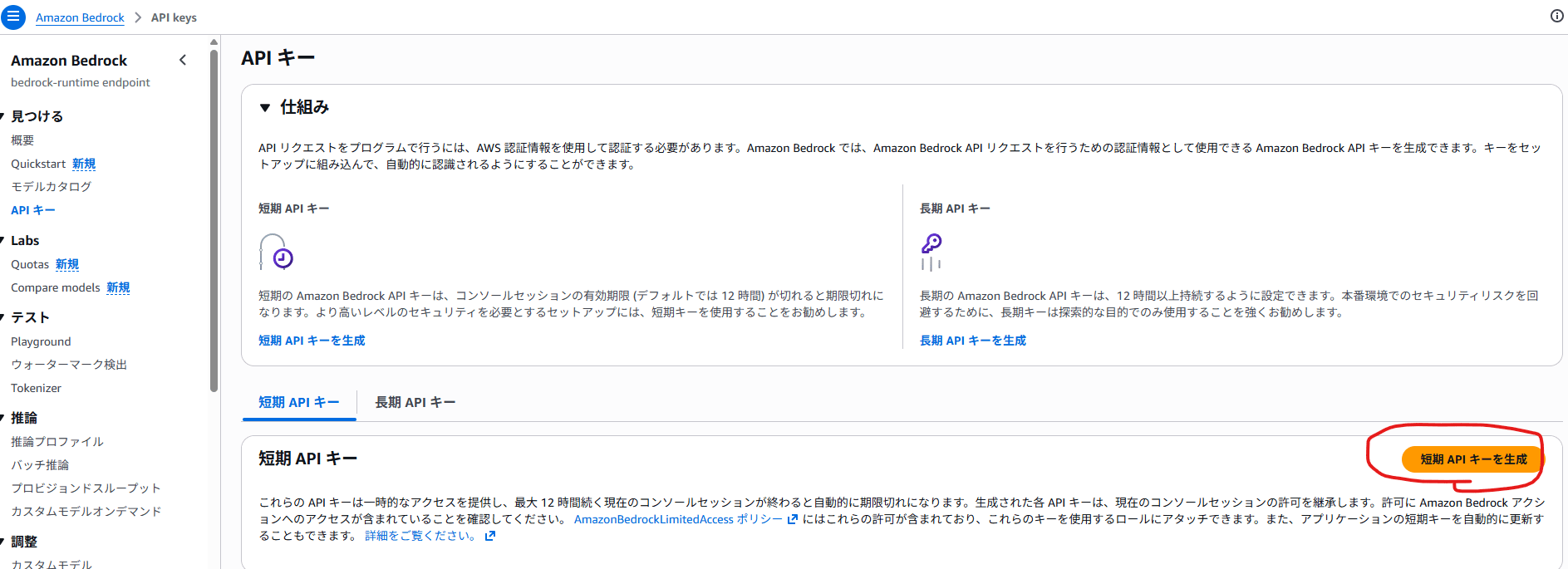
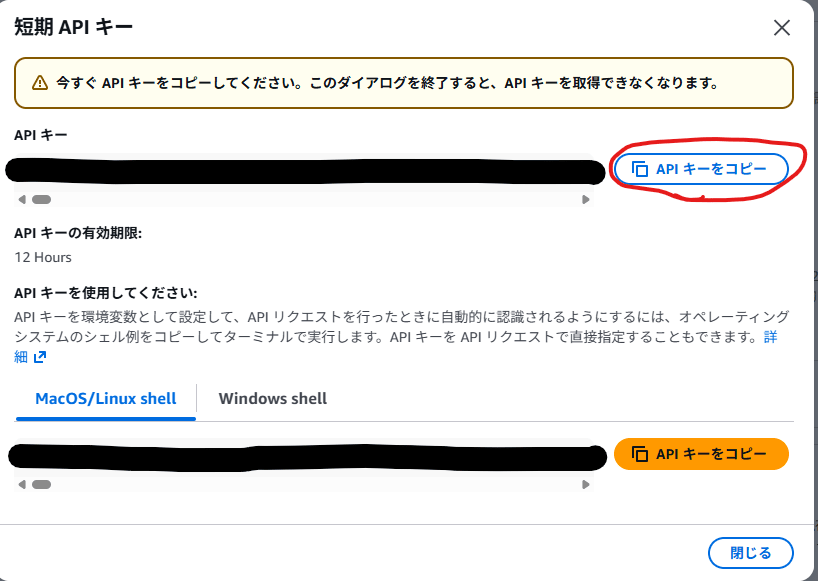
Bedrock Converse APIを呼ぶためにAPI Keyを払い出す必要があります。
以下の順で短期API Keyを洗い出してenvファイルのBEDROCK_API_KEYに値を入れてからコンテナを立ち上げてください。
記事の対象者
- オンプレ/クラウドに散らばった複数DBを横断して情報を取りたい人
- MCPで自社のDBをLLMにつなぎたいと考えている人
- MCPだけで完結すると思っていたけど、なんか思ったより難しいぞ…となっている人
- SSE / Streamable HTTP やツール名衝突など、MCP構築の沼で詰まった人
やろうとしたこと
最終的なゴールは、「東京工場の先週の稼働率ワースト3ラインと、その主力部品の在庫・発注状況・不良発生状況を一覧で出して」のような、複数の業務DBをまたぐ問いに自然言語1行で答えてもらうことです。
背景にあったニーズは、バージョンやエンジンが異なるオンプレ/クラウドのDBから、横断して情報を組み合わせて取得したい、というものでした。現場では「SCADAとWMSと購買を別々に開いて、Excelで突き合わせる」みたいな作業が日常的に発生していて、ここをLLM+MCPでまるっと吸収できないか、という発想です。
構成はざっくり以下の通りです。
Streamlit (Strands Agents + Bedrock Nova Lite)
│
├─ mcp-mysql ──→ MySQL 8.0 (E-BOM) / MySQL 5.7 (購買)
└─ mcp-postgres ──→ PostgreSQL 16 (SCADA) / 14 (QMS) / 13 (WMS)
「複数DBエンジン × 複数バージョン × 複数業務領域 × ロールベースのアクセス制御」を、Docker Composeで1ホストに再現しています。
環境
| 項目 | 内容 |
|---|---|
| OS | Windows 11 |
| LLM | Amazon Bedrock (Nova Lite) |
| エージェント | Strands Agents (Python) |
| UI | Streamlit |
| トランスポート | MCP over Streamable HTTP(ステートレス) |
| MCP SDK | mcp(Python SDK)の FastMCP |
| DBドライバ | mysql-connector-python / psycopg(v3) |
| DB | MySQL 8.0 / 5.7、PostgreSQL 16 / 14 / 13 |
| 実行基盤 | Docker Compose(DB 5 + MCP 2 + App 1 の8サービス) |
やってみた
MCPの動作原理(なぜ複数DBを1つのインターフェースで扱えるのか)
まず前提として、MCP(Model Context Protocol) は、LLM(クライアント側)と外部ツール/データソース(サーバー側)の間を取り持つオープンな標準プロトコルです。LSP(Language Server Protocol、エディタと言語ツールの間を抽象化する仕組み)が「エディタ↔言語ツール」を抽象化したのと同じ発想で、「LLM↔ツール」を抽象化してくれます。
登場人物は3つです↓
| 役割 | 本デモでの実体 | 説明 |
|---|---|---|
| MCP Host / Client | Strands Agent(LLM側) | ツール呼び出しが必要になったとき、MCPサーバーへJSON-RPCリクエストを送る |
| MCP Server | mcp-mysql / mcp-postgres |
ツールの実体を持ち、リクエストを受けて実行・結果を返す |
| Transport | Streamable HTTP | ClientとServerをつなぐ通信路 |
今回のキモは、1つのMCPサーバーから複数バージョン・複数DBを alias で切り替えるようにしたことです。MySQL 8.0と5.7を1つの mcp-mysql で、PostgreSQL 16/14/13を1つの mcp-postgres で扱っています。mysql_query(database, sql, limit) のように引数で database(=alias)を受け取り、サーバー側で接続情報を引いて mysql.connector.connect() する、という素直な仕組みです。
MySQL/PostgreSQLとも公式・サードパーティのMCPサーバー実装を探したんですが、「1プロセスから複数バージョンのDBを alias で切り替える」「Streamable HTTPで動く」「読み取り専用ガードを入れる」という今回の要件と噛み合わず、結局自作することにしました。各MCPサーバーが約150行で、読み手が全コードを1ファイルで追えるのも、デモとしては結構ありがたいポイントでした。
段階的な探索(ReActループ)で動く
動かしてみて面白かったのは、LLMが一度に全部のSQLを書くわけではないことです。まず list_databases でどんなDBがあるか確認 → list_tables でテーブル名を見て → describe_table でカラムを把握 → 最後に query を発行、という段階的な探索をします。各ステップでMCP Clientが新しいJSON-RPCリクエストを投げ、結果をLLMのコンテキストに追記して再推論する、いわゆるReActループ(Reasoning + Acting、推論と行動を交互に繰り返す手法)ですね。
うまくいったケース:単発〜数ステップの横断検索
ここからは実際の結果を見ていきます。まずうまくいったケースです。
ケース1
品質マネージャーのロールで「直近1週間で不良件数が最も多かったラインを特定し、その時間帯のセンサー異常と、原因と思われる部品の設計変更履歴を照合して」と投げると、QMS(品質)→ SCADA(設備稼働)→ E-BOM(部品表)を横断して、ちゃんと因果の仮説まで添えて返してくれました↓

第3ライン(東京工場)の不良7件に対して、同時間帯の振動異常(0.235mm/s)を引き当て、さらに該当部品の設計変更履歴(ねじ緩み防止改良が複数)まで照合しています。「振動異常は不良発生時刻と一致しており、原因の可能性が高い」という根拠の出し方は、製造現場でそのまま使えるレベルだなと感じました。
ケース2
購買担当のロールで「発注済みで14日以上経過した部品を抽出し、在庫消費ペースから欠品リスクが高い順にまとめて」と投げると、WMS(在庫)と購買を横断して、在庫日数を計算した一覧を返してくれました↓
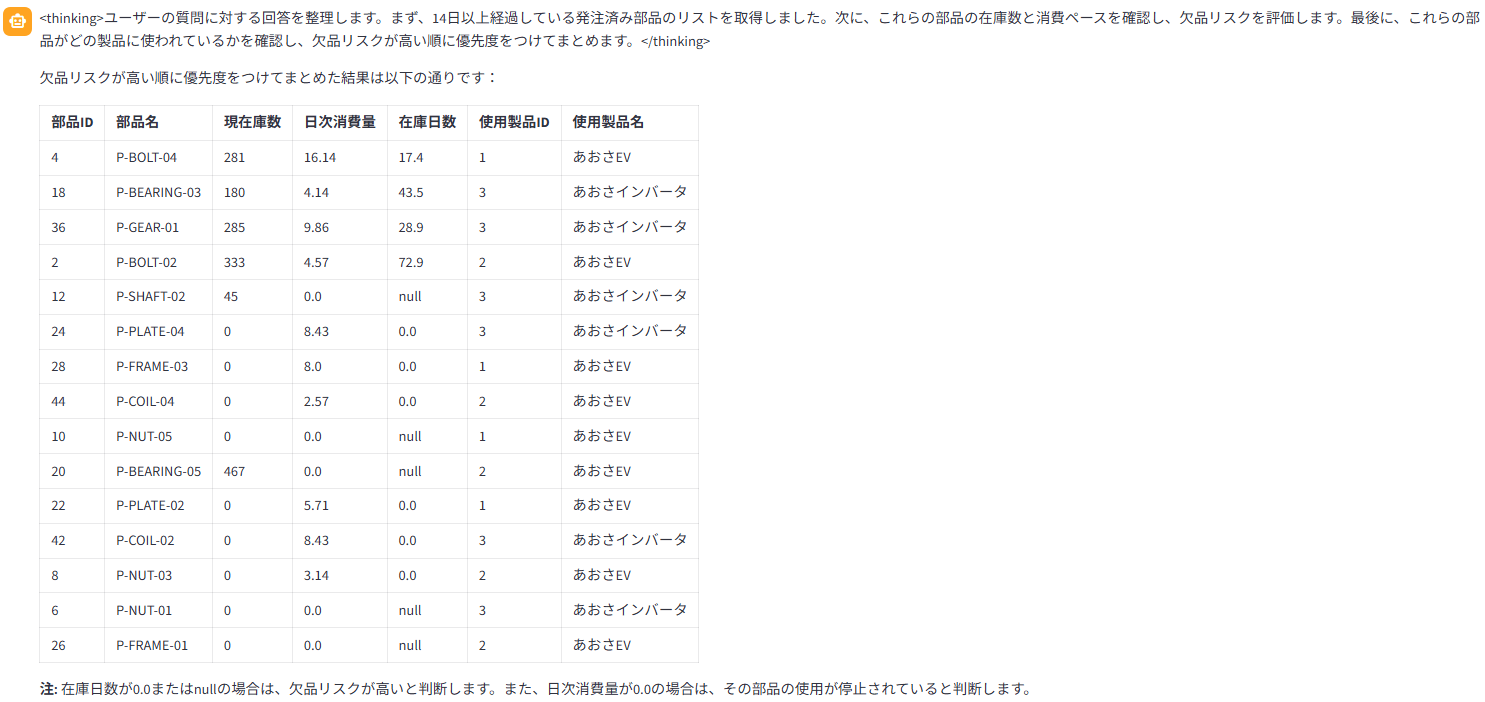
在庫日数が0.0またはnull(=消費に対して在庫が尽きている/消費が止まっている)を欠品リスクが高いと判断する、という注釈まで自分で付けてくれていて、ここは確かに賢いですね。
ロール制御もちゃんと効く
アクセス制御の境界テストもやってみました。大阪工場の現場オペレーターのロールで「東京工場の第1ラインの稼働率を教えて」と聞くと、拠点スコープ違反として拒否されます↓
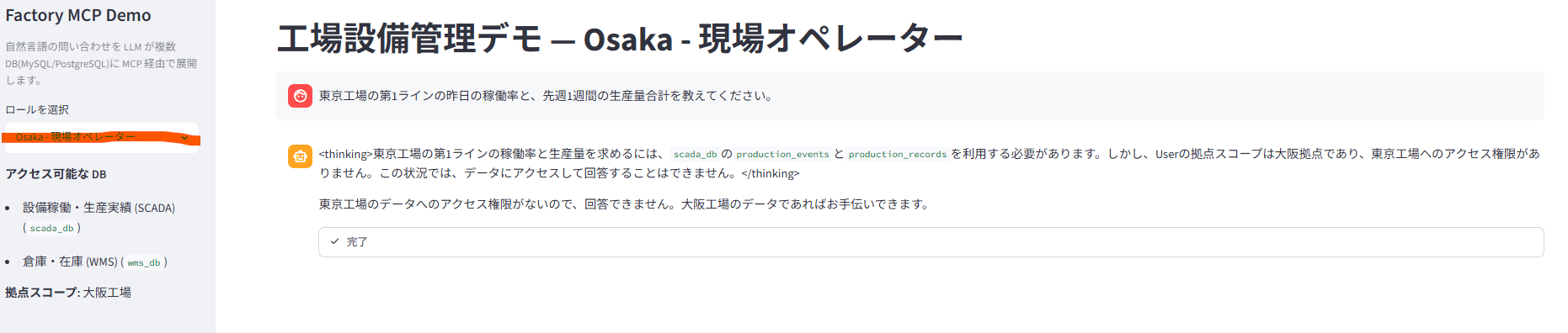
「東京工場のデータへのアクセス権限がないので、回答できません。大阪工場のデータであればお手伝いできます」と、きちんと拠点スコープで弾いてくれています。
東京工場の購買担当のロールで「SCADAのセンサー異常を見せて」と聞くと、購買ロールにはSCADAへのアクセスが含まれていないため、これも拒否されます↓

ロール制御は、アプリ層でシステムプロンプトに「使ってよいDB alias」「絞り込むべき拠点ID」を固定埋め込みする方式にしています。「LLMがプロンプトに従うこと」と「MCPサーバーの読み取り専用ガード」の二重防御で成り立っている形ですね。なお本番運用では、DB層でロール/VIEWのGRANTを併用することを推奨します。プロンプト依存のソフトな統制だけだと、どうしても突破リスクが残るためです。
微妙だったケース:MCPだけでは届かなかった「意味のつなぎ目」
一方で、ここからが本題です。
現場オペレーターのロールで「昨日の第2ラインで停止や保全が入っていた時間帯に、倉庫から部品が急に出庫されていたか確認して」と投げたときの結果がこちらです↓

出庫レコード自体は引けています。ただ、停止時間帯(11:00〜22:00)と出庫(out)を突き合わせて「停止時間帯に急な出庫があったか」を判断する部分で、「停止時間帯に急な出庫は見当たらない」と結論づけてしまったんですね。実際には同じ時間帯に出庫レコードが並んでいるのに、です。
ここで効いてくるのが、データに意味の構造が無いことです。
理由カラムの「生産投入」「引当」「製造払出」「出荷確定」が、それぞれ「停止と関係するのか/しないのか」をLLMは知らない- 「停止」「保全」というイベントが、どのテーブルのどの状態を指すのかが暗黙知になっている
- そもそも「急な出庫」とは何を基準に急と判断するのか、定義がどこにも無い
つまり、SQLで物理的に行を引いてくることはできても、その行が業務的に何を意味するのかをLLMが正しく解釈できないと、横断分析は最後のひと押しで滑ってしまいます。
MCPだけでは難しい、と気づいた理由
整理すると、複数DB横断MCPには、データの取得そのものとは別に、以下のような壁があると感じました。
| 壁 | 何が起きるか |
|---|---|
| 文脈の断絶 | DBをまたぐと、テーブル間の関係性(外部キーが物理的に存在しない等)が分からず、つなぎ方を間違える |
| 用語のゆらぎ | 「停止」「保全」「払出」など、業務用語と実データの対応がLLMに渡っていない |
| 暗黙のルール | 「在庫日数0.0は欠品リスク」のような判断基準が、その場のLLMの推測に依存してしまう |
最初は「MCPで全DBにつなげば、あとはLLMがよしなにやってくれる」と思っていたんですが、実際には意味や知識を別レイヤーで補わないと、横断分析の精度が安定しないことに気づきました。
ここまでに直したこと(時系列)
ここまでサラッと書いてきましたが、最初から動いたわけではなく、何度かソースコードに手を入れています。「なぜ直したのか」を時系列で残しておきます。同じ構成を組む人の参考になればと思います。
修正1: SSEトランスポート → Streamable HTTP(ステートレス)に切り替えた
最初の実装ではMCPサーバーのトランスポートに**SSE(Server-Sent Events、サーバーからの一方向ストリーミング配信)**を使っていました。ただ、SSEは2エンドポイント方式で長時間のアイドル接続を前提にしているため、Streamlitの再実行や瞬断で MCPClient のコンテキストが壊れる場面がありました。将来ALBやAPI Gatewayの裏に置くことを考えても、SSEの長時間アイドル接続はLBのタイムアウト問題を踏みやすいです。
そこで、MCP仕様(2025-03-26以降)で標準・推奨に格上げされたStreamable HTTPのステートレスモードに切り替えました。FastMCP(..., stateless_http=True, json_response=True) として、各ツール呼び出しを独立したHTTPリクエスト/レスポンスで完結させる形です。1リクエスト=1接続で完結するので、Streamlit再実行や瞬断に強くなり、水平スケールもしやすくなりました。今回のワークロード(短時間SELECTを都度実行)とも完全に整合していて、これは確実に効きました。
修正2: ツール名の衝突を mysql_ / postgres_ プレフィックスで回避した
2つのMCPサーバー(mcp-mysql / mcp-postgres)から取得したツールを1つのエージェントに合流させたところ、list_tables や query といった同名ツールが衝突しました。LLMがどちらのDBエンジンのツールを呼んでいるのか曖昧になってしまうんですね。
対処として、ツール名に mysql_ / postgres_ のプレフィックスを付けて名前空間を分けました。mysql_query / postgres_query のように区別することで、合流させても衝突しなくなりました。あわせて、LLMがどんなSQLを発行したのかをチャット出力に表示するようにして、デバッグしやすくしています。
修正3: ロールのアクセス制御を X-Allowed-Databases ヘッダで効かせた
当初、ロール制御はアプリ層のシステムプロンプトに「使ってよいDB alias」を固定埋め込みするだけのソフトな統制でした。ただ、プロンプト依存だけだと、LLMの解釈次第でアクセス可能範囲を越えてDBを参照しに行くリスクが残ります。
そこで、MCPサーバー側に X-Allowed-Databases ヘッダによるDBアクセス制御を実装しました。リクエストヘッダで許可DBを渡し、サーバー側でも弾けるようにした形です。「LLMがプロンプトに従うこと」だけに頼らず、MCPサーバー層でも境界を効かせる二重防御になりました。この記事の境界テスト(case4)がきれいに拒否されるのは、この修正のおかげです。
修正4: ツール呼び出しの暴走を _ToolCallLimiter で止めた
複数DBを横断する重い問いを投げると、LLMが list_databases → list_tables → describe_table → query の探索を延々と繰り返して止まらなくなることがありました。段階的探索(ReActループ)は便利な反面、止め時を自分で判断できないと暴走します。
対処として、agent.py に _ToolCallLimiter フックを追加し、AGENT_MAX_TOOL_CALLS でツール呼び出し回数の上限を設けました。あわせて BedrockModel に max_tokens を明示して、応答が途中で切れる事象も抑えています。
整理すると、修正の理由は以下です↓
| 修正 | 直した理由 |
|---|---|
| SSE → Streamable HTTP | SSEの長時間アイドル接続でコンテキストが壊れ、LB親和性も低かった |
| ツール名プレフィックス | 2サーバー合流時に同名ツールが衝突し、LLMが呼び分けられなかった |
X-Allowed-Databases ヘッダ |
プロンプト依存のソフト統制だけでは境界突破のリスクが残った |
_ToolCallLimiter / max_tokens |
段階的探索が止まらず暴走、応答も途中で切れた |
ここまでは「配管としてのMCPを安定させる」ための修正でした。ですが、case3で滑ったような「意味のつなぎ目」は、これらをいくら直しても埋まりませんでした。ここからが本題です。
RAGとオントロジーが必要になる瞬間
ここで効いてくるのが、RAGとオントロジーです。
- RAG(Retrieval-Augmented Generation、検索で取得した情報をLLMの回答に注入する手法): 業務用語の定義、判断基準、過去の分析事例などを外部知識として検索・注入し、LLMが「その行が何を意味するか」を理解した上で推論できるようにする
- オントロジー(エンティティの種類・階層関係・許容プロパティを厳密に定義した意味モデル): 「停止イベントは設備状態の一種」「出庫理由には生産系と物流系がある」といった意味の地図を与え、DBをまたぐ関係性を明示する
特に製造業のDBは、少数のクラス分類(テーブル種別)に対して、膨大なインスタンスデータ(個々のレコード)がぶら下がる平坦な構造になりがちです。この場合、ただチャンク分割するだけでは大量の事実が行き場を失って1つの巨大なチャンクに押し込まれる「Orphan Axiom Problem(孤児公理問題)」という現象が起きることが、実証研究でも報告されています。つまり、横断検索を意味レベルで成立させたいなら、ベクトル検索だけでなく、グラフ構造(ノード=エンティティ、エッジ=関係性)を辿るGraphRAGや、意味の凝集度を保つチャンキング戦略まで踏み込む必要がある、ということですね。
MCPは「LLMとDBをつなぐ配管」としては圧倒的に便利です。ただ、その配管の先で意味と知識をどう構造化して渡すか——ここがRAGとオントロジーの出番なんだなと、手を動かしてみて確実に理解できました。次はこのデモにGraphRAGとオントロジーを足して、ケース3のような「意味のつなぎ目」をどこまで埋められるか検証してみたいと思います。
まとめ
複数のDB(エンジン違い・バージョン違い)を横断するMCPを作ってみました。
単発の問い合わせはかなりうまくいく一方で、業務の意味や知識をまたぐ問いになるとMCPだけでは届かず、RAGやオントロジーで意味を補う必要があると気づけたのが今回の収穫でした。
手を動かすとMCP・RAG・オントロジーの役割分担が腹落ちしますね!








