
AWS Agent RegistryからSkillsを動的に読み込んでStrands Agentに注入してみた
はじめに
こんにちは、スーパーマーケットが好きなコンサル部の神野(じんの)です。
以前書いたこちらの記事で、AWS Agent Registryがプレビューリリースされたことをご紹介しました。このサービスではSKillsやMCP Server、Agentを登録して管理することができます。
単純に登録したスキルを参照するだけでなく、エージェント自体にスキルを書き込まなくても、Registryで承認されたスキルだけを動的に取り出して注入できたら運用がかなり楽になりそうですよね。今回はその検証として、RegistryにAgent Skillsを登録して、Strandsから検索・注入するところまでをスキル有無の比較付きで試していきます!
イメージとしては下記のように実装します。シンプルです。
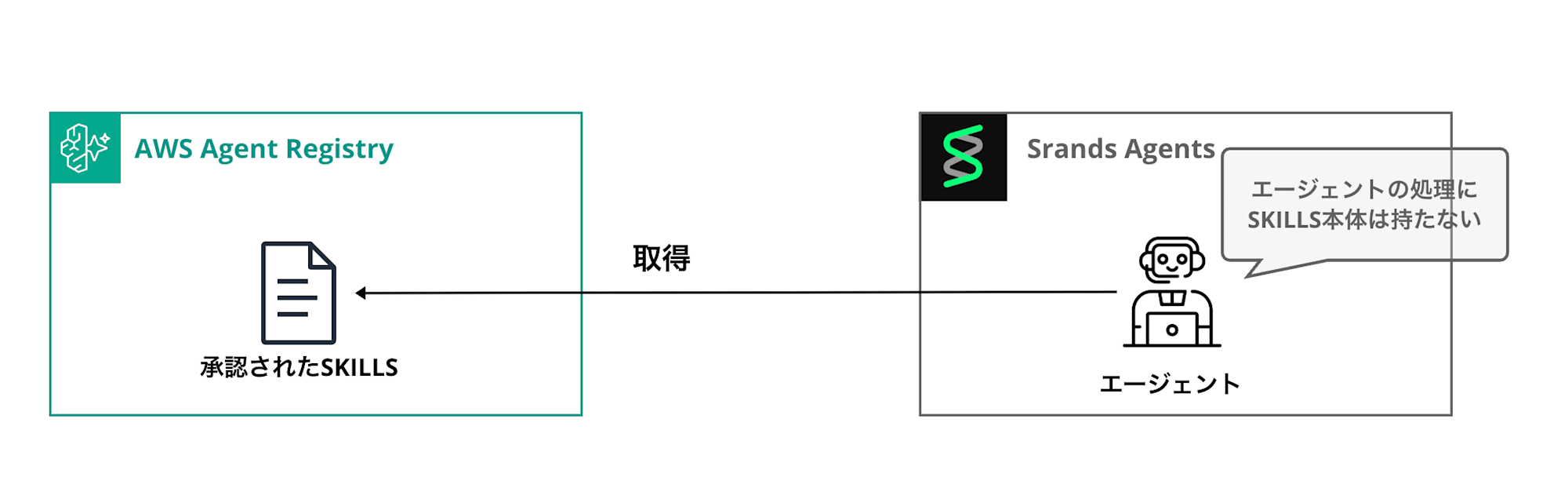
前提
今回使用したバージョンやモデルは下記となります。
| 項目 | バージョン・設定 |
|---|---|
| Python | 3.13 |
| パッケージ管理 | uv 0.9.26 |
| リージョン | us-east-1 |
| モデル | us.anthropic.claude-haiku-4-5-20251001-v1:0 |
実装
プロジェクト作成
uv でプロジェクトを初期化し、必要なパッケージを追加します。
uv init skills-dynamic-import-strands -p 3.13
cd skills-dynamic-import-strands
uv add "boto3>=1.42.87" "strands-agents>=1.36.0" "strands-agents-tools>=0.5.0" "pyyaml>=6.0"
今回の検証で実際にインストールされたバージョンは下記の通りです。
| パッケージ | インストールされたバージョン | 役割 |
|---|---|---|
| boto3 | 1.42.92 | Agent Registry の登録・検索 |
| botocore | 1.42.92 | boto3 のコア(自動追従) |
| strands-agents | 1.36.0 | Agent/Skill/AgentSkills プラグイン本体 |
| strands-agents-tools | 0.5.0 | file_read / shell 等の組み込みツール |
| pyyaml | 6.0.3 | SKILL.md フロントマターの解析 |
最終的なファイル構成はこちらです。
.
├── pyproject.toml
├── register_skill.py # SKILL.mdをRegistryへ登録する
├── registry_skill_loader.py # Registryから検索してSkillに変換する
├── agent.py # スキル有/無でAgentを組み立てて比較する
└── skills/
└── doc-reviewer/
└── SKILL.md
Registryの作成
まず自動承認をオンにしたRegistryをAPIで作成します。
uv run python3 -c "
import boto3, json
c = boto3.client('bedrock-agentcore-control', region_name='us-east-1')
resp = c.create_registry(
name='skills-auto-approve',
description='Agent Skills registry with auto-approval enabled',
approvalConfiguration={'autoApproval': True},
)
print(json.dumps(resp, indent=2, default=str))
"
自動承認をオンにしておくと、スキル登録時に承認まで自動で進みます。レスポンスの registryArn 末尾がRegistry IDになるので、この後のスキル登録や検索で使うため控えておきます。
登録するSKILL.md
ドキュメントを固定フォーマットでレビューするスキルを登録します。スキルの差がわかりやすいよう、見出し・絵文字・優先度タグを指定します。
---
name: doc-reviewer
description: 仕様書やドキュメントを日本語で構造化レビューし、要点・リスク・改善提案を優先度付きで返す
---
あなたはドキュメントレビュー担当の日本語アシスタントです。
入力として渡された文書を、必ず以下のMarkdown見出し構成で出力してください。
順序・見出し名・絵文字は変えないこと。
## 🎯 要点 (TL;DR)
- 箇条書きで最大3項目、1項目あたり40文字以内で端的にまとめる
## ⚠️ リスク
- 箇条書きで最大5項目。各項目は「リスク内容 — 想定される影響」の形式で書く
## 🛠 改善提案
- 箇条書きで最大5項目。必ず冒頭に `[P1]`/`[P2]`/`[P3]` の優先度タグを付ける
- `[P1]` は即時対応が必要なもの、`[P2]` は次スプリント相当、`[P3]` はいつかやれば良いもの
上記以外のセクションは追加しないこと。冗長な前置きや結論段落は書かないこと。
スキルをRegistryに登録する
SKILL.mdをRegistryに登録するスクリプトです。
"""Register a local SKILL.md to AWS Agent Registry and approve it immediately."""
from __future__ import annotations
import argparse
import logging
import os
import re
import time
from pathlib import Path
import boto3
import yaml
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
FRONTMATTER_RE = re.compile(r"^---\s*\n(.*?)\n---\s*\n(.*)$", re.DOTALL)
def _wait_until_not(control, registry_id: str, record_id: str, transient: str, *, timeout: float = 30.0) -> str:
deadline = time.monotonic() + timeout
while True:
status = control.get_registry_record(
registryId=registry_id,
recordId=record_id,
)["status"]
if status != transient:
return status
if time.monotonic() > deadline:
raise TimeoutError(f"record {record_id} stuck in {transient}")
time.sleep(1.0)
def parse_skill_md(path: Path) -> tuple[str, str, str]:
text = path.read_text(encoding="utf-8")
match = FRONTMATTER_RE.match(text)
if not match:
raise ValueError(f"{path} must start with YAML frontmatter")
meta = yaml.safe_load(match.group(1)) or {}
name = meta.get("name")
if not name:
raise ValueError(f"{path} frontmatter must define 'name'")
return name, meta.get("description", ""), text
def register_skill(registry_id: str, skill_md_path: Path, record_version: str = "1.0", region_name: str = "us-east-1") -> str:
name, description, inline_content = parse_skill_md(skill_md_path)
control = boto3.client("bedrock-agentcore-control", region_name=region_name)
created = control.create_registry_record(
registryId=registry_id,
name=name,
description=description,
recordVersion=record_version,
descriptorType="AGENT_SKILLS",
descriptors={"agentSkills": {"skillMd": {"inlineContent": inline_content}}},
)
record_id = created["recordArn"].rsplit("/", 1)[-1]
logger.info("Created record %s (status=%s)", record_id, created["status"])
_wait_until_not(control, registry_id, record_id, "CREATING")
control.submit_registry_record_for_approval(registryId=registry_id, recordId=record_id)
status = _wait_until_not(control, registry_id, record_id, "SUBMITTING")
logger.info("Record %s reached status %s", record_id, status)
return record_id
SKILL.mdのフロントマターからnameとdescriptionを取り出して、コントロールプレーンのAPIでRegistryに登録しています。レコードのステータスが遷移するまで待ってからsubmitすると、自動承認で承認済みになります。
export AGENT_REGISTRY_ID="xxx"
export AWS_REGION="us-east-1"
uv run python register_skill.py skills/doc-reviewer/SKILL.md
INFO:__main__:Created record xxx (status=CREATING)
INFO:__main__:Record xxx reached status APPROVED
なお承認直後は検索インデックスに反映されておらず、今回の検証では20秒ほどラグがありました。
Registryからスキルを取得するローダー
Registryからスキルを検索して、Strandsの Skill オブジェクトに変換するローダーです。
"""Load Agent Skills dynamically from AWS Agent Registry."""
from __future__ import annotations
import logging
from dataclasses import dataclass
import boto3
from strands.vended_plugins.skills import Skill
logger = logging.getLogger(__name__)
@dataclass
class RegistrySkillLoaderConfig:
registry_id: str
region_name: str = "us-east-1"
max_results: int = 10
class RegistrySkillLoader:
def __init__(self, config: RegistrySkillLoaderConfig) -> None:
self._config = config
self._client = boto3.client("bedrock-agentcore", region_name=config.region_name)
def search(self, query: str) -> list[Skill]:
response = self._client.search_registry_records(
registryIds=[self._config.registry_id],
searchQuery=query,
maxResults=self._config.max_results,
filters={"descriptorType": {"$eq": "AGENT_SKILLS"}},
)
records = response.get("registryRecords") or []
logger.info("Fetched %d skill record(s) from registry", len(records))
return [skill for record in records if (skill := self._to_skill(record))]
def _to_skill(self, record: dict) -> Skill | None:
descriptors = record.get("descriptors") or {}
markdown = ((descriptors.get("agentSkills") or {}).get("skillMd") or {}).get("inlineContent")
if markdown:
return Skill.from_content(markdown)
name = record.get("name", "unknown")
description = record.get("description") or ""
logger.warning("Skill '%s' has no skillMd content; falling back", name)
return Skill(name=name, description=description, instructions=description)
Registryから取得したレコードの中身をそのまま Skill.from_content() に渡しています。登録時に入れたSKILL.mdの内容がそのまま返ってくるので、シンプルに変換できますね。
Agentを組み立てる(スキル有/無で比較)
"""Compare Strands Agent output with and without Skills loaded from AWS Agent Registry."""
from __future__ import annotations
import argparse
import logging
import os
from strands import Agent
from strands.models import BedrockModel
from strands.vended_plugins.skills import AgentSkills
from registry_skill_loader import RegistrySkillLoader, RegistrySkillLoaderConfig
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(name)s %(levelname)s: %(message)s")
logger = logging.getLogger(__name__)
HAIKU_MODEL_ID = "us.anthropic.claude-haiku-4-5-20251001-v1:0"
def build_model() -> BedrockModel:
return BedrockModel(
model_id=HAIKU_MODEL_ID,
region_name=os.environ.get("AWS_REGION", "us-east-1"),
temperature=0.0,
)
def build_plain_agent() -> Agent:
return Agent(model=build_model())
def build_skill_agent(search_query: str) -> Agent:
loader = RegistrySkillLoader(RegistrySkillLoaderConfig(
registry_id=os.environ["AGENT_REGISTRY_ID"],
region_name=os.environ.get("AWS_REGION", "us-east-1"),
))
skills = loader.search(search_query)
logger.info("Loaded skills: %s", [s.name for s in skills])
return Agent(model=build_model(), plugins=[AgentSkills(skills=skills)])
SAMPLE_DOC = """\
# 新機能: 社内ナレッジ検索ボット v0.3 仕様書 (ドラフト)
- 利用者: 全社員 (約1200名)
- 想定QPS: 平均3, ピーク20
- LLM: Claude Haiku / Sonnet を動的切替
- データソース: Confluence, Google Drive, Slack 過去ログ
- 認証: Slack OAuth のみ
- データ取り込み: 夜間バッチで全件再同期
- ログ: CloudWatch に会話ログを平文保存 (検索用)
- リリース予定: 来週金曜日, 段階ロールアウトなし
- 監視: なし (まずは出してみる)
- 予算: LLMコストは月上限なし
"""
PROMPT = f"下記のドキュメントをレビューしてください。\n\n{SAMPLE_DOC}"
def run(mode: str) -> None:
print(f"MODE: {mode}")
agent = build_plain_agent() if mode == "plain" else build_skill_agent("仕様書をレビューして要点・リスク・改善提案を返すスキル")
print(agent(PROMPT).message)
def main() -> None:
parser = argparse.ArgumentParser()
parser.add_argument("mode", choices=["plain", "skills"])
run(parser.parse_args().mode)
if __name__ == "__main__":
main()
Registryから取得したSkillインスタンスをそのまま AgentSkills プラグインに渡すだけで、ローカルにSKILL.mdを置かずにAgentを構成できます。
動作確認
スキル無しで実行
AGENT_REGISTRY_ID="xxx" AWS_REGION="us-east-1" uv run python agent.py plain
出力全文(plain)
# レビュー結果: 重大な懸念事項あり
このドキュメントには、本番環境への展開前に**必ず対応すべき問題**が複数あります。
## 🔴 **重大リスク(即対応必須)**
### 1. **セキュリティ**
- ❌ 認証が Slack OAuth のみ → 退職者アクセス制御なし
- ❌ 会話ログを平文保存 → 機密情報露出リスク
- **対策**: ログの暗号化、アクセス制御、保持期間設定
- **質問**: どの情報を記録する必要があるのか?
### 2. **データプライバシー**
- ❌ Confluence/Drive/Slack の全データを無制限に学習
- **対策**: データ分類、アクセス権限に基づくフィルタリング
- **質問**: 個人情報・機密情報の除外ルールは?
### 3. **スケーラビリティ**
- ⚠️ ピーク20QPS で Haiku/Sonnet 動的切替 → コスト爆発の可能性
- **対策**: レート制限、キューイング、キャッシング戦略の明記
- **質問**: 月間コスト試算は?
### 4. **リリース計画**
- ❌ 段階ロールアウトなし + 監視なし = 本番障害時に全社影響
- **対策**:
- 段階ロールアウト(10% → 50% → 100%)
- 基本的な監視(エラー率、レイテンシ、コスト)
---
## 🟡 **中程度の懸念**
| 項目 | 問題 | 推奨対応 |
|------|------|--------|
| **データ同期** | 夜間バッチのみ → 情報が最大24時間遅延 | 増分同期の検討 |
| **LLM選択** | Haiku/Sonnet の切替基準が不明 | 明確な判定ロジック定義 |
| **エラーハンドリング** | 記載なし | フォールバック戦略を定義 |
| **ユーザー教育** | 記載なし | 利用ガイド、制限事項の周知 |
---
## 📋 **推奨される追加項目**
```
- [ ] セキュリティレビュー(情報セキュリティ部門)
- [ ] データ保持ポリシー(法務・コンプライアンス)
- [ ] コスト試算と予算承認プロセス
- [ ] インシデント対応計画
- [ ] ユーザーフィードバック収集方法
- [ ] 段階ロールアウトスケジュール
- [ ] 基本的なダッシュボード(エラー、コスト、利用状況)
```
---
## ✅ **良い点**
- 想定QPS の明記
- 複数データソースの統合
- 段階的な LLM 選択
---
## 🎯 **次のステップ**
**来週金曜日のリリースは現実的ではありません。** 以下を推奨します:
1. **今週中**: セキュリティ・プライバシーレビュー実施
2. **来週**: 修正 + 限定ユーザー(10-20名)でのパイロット
3. **2週間後**: 段階ロールアウト開始
ご質問があればお答えします。
レビューしてくれました。スキル無しだと見出しをモデルが自由に決めるので、実行するたびに構成が変わります。
スキル有りで実行
AGENT_REGISTRY_ID="xxx" AWS_REGION="us-east-1" uv run python agent.py skills
registry_skill_loader INFO: Fetched 1 skill record(s) from registry
__main__ INFO: Loaded skills: ['doc-reviewer']
...
doc-reviewer スキルを使用して、このドキュメントを構造化レビューします。
Tool #1: skills
Registryから doc-reviewer が1件取得され、エージェントが skills ツールを読み込まれましたね!
出力結果も確認してみます。
出力全文(skillsあり)
## 🎯 要点 (TL;DR)
- 全社1200名向けの社内ナレッジ検索ボット、来週金曜日リリース予定
- Claude Haiku/Sonnetで複数データソース検索、Slack OAuth認証
- 監視・段階ロールアウト・予算管理なし、本番環境への準備不足
## ⚠️ リスク
- **監視なし** — 障害検知遅延、ユーザー影響の把握不可、原因特定困難
- **段階ロールアウトなし** — 1200名同時アクセスで障害発生時、全社影響、ロールバック困難
- **会話ログ平文保存** — 機密情報漏洩、個人情報保護方針違反、コンプライアンスリスク
- **LLMコスト上限なし** — プロンプトインジェクション攻撃時の無制限課金、予算超過
- **夜間バッチ全件再同期** — 古い情報提供、削除済みデータの復活、データ一貫性問題
## 🛠 改善提案
- `[P1]` CloudWatch ログの暗号化・アクセス制御導入、機密情報マスキング機能追加
- `[P1]` 段階ロールアウト計画策定(初期100名→500名→全社)、ロールバック手順確立
- `[P1]` 基本的な監視設定(エラー率、レイテンシ、API呼び出し数)、アラート閾値定義
- `[P2]` LLMコスト上限設定、プロンプトインジェクション対策、レート制限実装
- `[P3]` 増分同期への移行検討、データ削除ポリシー明確化、キャッシュ戦略導入
SKILL.mdで定義した3セクション固定のフォーマットにきっちり揃っていますね!
Agent Registryから取得したスキルを動的にインポートすることに成功しました。
エージェント側のコードを変更しなくても、Registryに承認済みのスキルを追加・更新するだけでエージェントの振る舞いを変えられるのが嬉しいポイントですね。スキルの管理をRegistry側に寄せることで、エージェント開発とスキル開発を分離できそうです。
おわりに
今回の実装はAgent構築時に1回Registryをフェッチしています。リクエスト単位でAgentを組み立てるなら毎回最新のスキルが取得されますし、セッション単位で組み立てるならセッションの切り替わりで反映されます。どの粒度でフェッチするかは検討の余地がありそうですね。
MCP ServerやAgentもRegistryに登録して活用するユースケースも今後試していきます!
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございました!









