
CSVファイルの作成から、DynamoDBテーブルのインポートまでを一括実行するスクリプトを作成してみた
はじめに
大量のデータをDynamoDBに取り込む際には課題があります。
AWS CloudFormationではAmazon DynamoDBテーブルの構造は作成できますが、CloudFormationの標準機能では、データ(レコード)の作成はできません。そのため、テーブル作成後は別の手段でデータを投入する必要があります。
アプリケーションコードやスクリプトを使用してレコードを1件ずつ挿入する方法では、処理時間が長くなる上に、実装の複雑化も招くという問題がありました。
これらの課題を解決するため、Amazon DynamoDBにはAmazon S3に保存されたCSVファイルから直接データをインポートできる機能が提供されています。この機能を活用することで、大量のデータを効率的にDynamoDBテーブルに取り込むことが可能になります。
そこで今回は、DynamoDBのインポート機能を活用して初期データの投入を簡素化するスクリプトを作成しました。AWS CLIでスクリプト化することにより、テスト環境での環境構築時のセットアップを容易に行えるようになります。
本記事では、作成したスクリプトを紹介し、実際に動作を確認してみます。
なお、インポート先は新規テーブルのみとなります。既存テーブルへのインポートはサポートされていないため、既存データがある場合は別の方法を検討する必要があります。
スクリプト
今回作成したスクリプトを以下に示します。
このスクリプトは、CSVファイルの作成からDynamoDBテーブルへのデータインポートまでを一括で実行します。
# ========== 設定変数 ==========
CSV_FILE="dynamodb-import.csv" && \
PRIMARY_KEY="user_id" && \
BUCKET_NAME="cm-test-dynamodb-import" && \
TABLE_NAME="user-profile-table" && \
echo "🔧 設定確認:" && \
echo " CSVファイル: $CSV_FILE" && \
echo " プライマリキー: $PRIMARY_KEY" && \
echo " S3バケット: $BUCKET_NAME" && \
echo " テーブル名: $TABLE_NAME" && \
echo "" && \
# ========== CSVファイル作成(ヘッダー付き) ==========
echo "📝 CSVファイル作成中(ヘッダー付き)..." && \
cat > $CSV_FILE << EOF
${PRIMARY_KEY},user_name,email,department,join_date
user001,Alice Johnson,alice.johnson@example.com,Engineering,2023-04-01
user002,Bob Smith,bob.smith@example.com,Sales,2023-05-15
user003,Carol Davis,carol.davis@example.com,Marketing,2023-06-10
user004,David Wilson,david.wilson@example.com,HR,2023-07-20
user005,Emma Brown,emma.brown@example.com,Engineering,2023-08-05
user006,Frank Miller,frank.miller@example.com,Finance,2023-09-12
EOF
echo "✅ CSVファイル作成完了" && \
echo "📄 ファイル内容確認:" && \
cat $CSV_FILE && \
echo "" && \
# ========== S3準備 ==========
echo "🔍 S3バケット確認: $BUCKET_NAME" && \
if aws s3 ls "s3://$BUCKET_NAME" >/dev/null 2>&1; then
echo "✅ S3バケット既存(スキップ)"
else
echo "🚀 S3バケット作成中..." && \
aws s3 mb s3://$BUCKET_NAME && \
echo "✅ S3バケット作成完了"
fi && \
aws s3 cp $CSV_FILE s3://$BUCKET_NAME/$CSV_FILE && \
echo "✅ CSVアップロード完了" && \
echo "" && \
# ========== DynamoDBインポート ==========
echo "📊 DynamoDBインポート開始..." && \
IMPORT_RESULT=$(aws dynamodb import-table \
--s3-bucket-source S3Bucket=$BUCKET_NAME,S3KeyPrefix=$CSV_FILE \
--input-format CSV \
--table-creation-parameters '{
"TableName":"'$TABLE_NAME'",
"AttributeDefinitions":[
{
"AttributeName":"'$PRIMARY_KEY'",
"AttributeType":"S"
}
],
"KeySchema":[
{
"AttributeName":"'$PRIMARY_KEY'",
"KeyType":"HASH"
}
],
"BillingMode":"PAY_PER_REQUEST"
}' \
--output json) && \
IMPORT_ARN=$(echo $IMPORT_RESULT | jq -r '.ImportTableDescription.ImportArn') && \
echo "✅ インポート開始完了" && \
echo "" && \
# ========== 削除保護有効化 ==========
echo "⏳ テーブル作成完了を待機中..." && \
aws dynamodb wait table-exists --table-name $TABLE_NAME && \
echo "🔒 削除保護を有効化中..." && \
aws dynamodb update-table \
--table-name $TABLE_NAME \
--deletion-protection-enabled && \
echo "✅ 削除保護が有効化されました" && \
echo "" && \
# ========== S3クリーンアップ ==========
echo "🧹 S3リソースクリーンアップ開始..." && \
echo "🗑️ S3ファイル削除中..." && \
aws s3 rm s3://$BUCKET_NAME/$CSV_FILE && \
echo "✅ S3ファイル削除完了" && \
echo "🗑️ S3バケット削除中..." && \
aws s3 rb s3://$BUCKET_NAME && \
echo "✅ S3バケット削除完了" && \
echo "🧹 ローカルCSVファイル削除中..." && \
rm -f $CSV_FILE && \
echo "✅ ローカルファイル削除完了" && \
echo "" && \
# ========== 結果表示 ==========
echo "🎉 完了!作成されたリソース:" && \
echo " 🔑 プライマリキー: $PRIMARY_KEY" && \
echo " 📊 DynamoDBテーブル: $TABLE_NAME" && \
echo " 🔗 インポートARN: $IMPORT_ARN" && \
echo "" && \
echo "🧹 削除されたリソース:" && \
echo " 📄 ローカルCSVファイル: $CSV_FILE" && \
echo " 🪣 S3バケット: $BUCKET_NAME" && \
echo " 📁 S3ファイル: s3://$BUCKET_NAME/$CSV_FILE" && \
echo "" && \
echo "✅ DynamoDBテーブルのみが残されました"
このスクリプトでは、以下のDynamoDBテーブルとサンプルデータを作成します。
- テーブル名:
user-profile-table - プライマリキー:
user_id - データ内容: ユーザープロフィール情報(ID、名前、メール、部署、入社日)
CSV_FILE="dynamodb-import.csv" # CSVファイル名
PRIMARY_KEY="user_id" # プライマリキー名
BUCKET_NAME="cm-test-dynamodb-import" # S3バケット名(一意である必要があります)
TABLE_NAME="user-profile-table" # DynamoDBテーブル名
スクリプトの動作内容
このスクリプトは以下の手順で動作します。
-
設定変数の定義
- CSVファイル名、プライマリキー、S3バケット名、テーブル名を設定
-
CSVファイルの作成
- ヘッダー付きのCSVファイルをローカルに作成
- サンプルユーザーデータ(6件)を含む
-
S3の準備
- S3バケットの存在確認(既存の場合はスキップ)
- CSVファイルをS3にアップロード
-
DynamoDBインポート
import-tableコマンドでテーブル作成とデータインポートを同時実行- オンデマンド課金モードで作成
-
削除保護の有効化
- 誤削除防止のため削除保護を有効化
- ※
import-tableコマンド実行時には削除保護を設定できないため、別途実行
-
クリーンアップ
- 不要なS3リソース(ファイル・バケット)を削除
- ローカルCSVファイルも削除
実行結果の確認
AWS CloudShellからスクリプトを実行すると、以下のような出力が表示されます。
✅ CSVファイル作成完了
📄 ファイル内容確認:
user_id,user_name,email,department,join_date
user001,Alice Johnson,alice.johnson@example.com,Engineering,2023-04-01
user002,Bob Smith,bob.smith@example.com,Sales,2023-05-15
user003,Carol Davis,carol.davis@example.com,Marketing,2023-06-10
user004,David Wilson,david.wilson@example.com,HR,2023-07-20
user005,Emma Brown,emma.brown@example.com,Engineering,2023-08-05
user006,Frank Miller,frank.miller@example.com,Finance,2023-09-12
🔍 S3バケット確認: cm-test-dynamodb-import
🚀 S3バケット作成中...
make_bucket: cm-test-dynamodb-import
✅ S3バケット作成完了
upload: ./dynamodb-import.csv to s3://cm-test-dynamodb-import/dynamodb-import.csv
✅ CSVアップロード完了
📊 DynamoDBインポート開始...
✅ インポート開始完了
⏳ テーブル作成完了を待機中...
🔒 削除保護を有効化中...
{
"TableDescription": {
"AttributeDefinitions": [
{
"AttributeName": "user_id",
"AttributeType": "S"
}
],
"TableName": "user-profile-table",
"KeySchema": [
{
"AttributeName": "user_id",
"KeyType": "HASH"
}
],
"TableStatus": "ACTIVE",
"CreationDateTime": "2025-06-02T06:58:33.338000+00:00",
"ProvisionedThroughput": {
"NumberOfDecreasesToday": 0,
"ReadCapacityUnits": 0,
"WriteCapacityUnits": 0
},
"TableSizeBytes": 0,
"ItemCount": 0,
"TableArn": "arn:aws:dynamodb:ap-northeast-1:アカウントID:table/user-profile-table",
"TableId": "214669ba-dcb5-4362-add6-ab2078b28680",
"BillingModeSummary": {
"BillingMode": "PAY_PER_REQUEST",
"LastUpdateToPayPerRequestDateTime": "2025-06-02T06:59:47.798000+00:00"
},
"DeletionProtectionEnabled": true,
"WarmThroughput": {
"ReadUnitsPerSecond": 12000,
"WriteUnitsPerSecond": 4000,
"Status": "ACTIVE"
}
}
}
✅ 削除保護が有効化されました
🧹 S3リソースクリーンアップ開始...
🗑️ S3ファイル削除中...
delete: s3://cm-test-dynamodb-import/dynamodb-import.csv
✅ S3ファイル削除完了
🗑️ S3バケット削除中...
remove_bucket: cm-test-dynamodb-import
✅ S3バケット削除完了
🧹 ローカルCSVファイル削除中...
✅ ローカルファイル削除完了
🎉 完了!作成されたリソース:
🔑 プライマリキー: user_id
📊 DynamoDBテーブル: user-profile-table
🔗 インポートARN: arn:aws:dynamodb:ap-northeast-1:アカウントID:table/user-profile-table/import/01748847497570-146847ed
🧹 削除されたリソース:
📄 ローカルCSVファイル: dynamodb-import.csv
🪣 S3バケット: cm-test-dynamodb-import
📁 S3ファイル: s3://cm-test-dynamodb-import/dynamodb-import.csv
✅ DynamoDBテーブルのみが残されました
実行後は、AWS コンソールでテーブルとデータが正常に作成されていることを確認できます。このスクリプトは100行程度のデータでも問題なく処理できることを確認済みです。
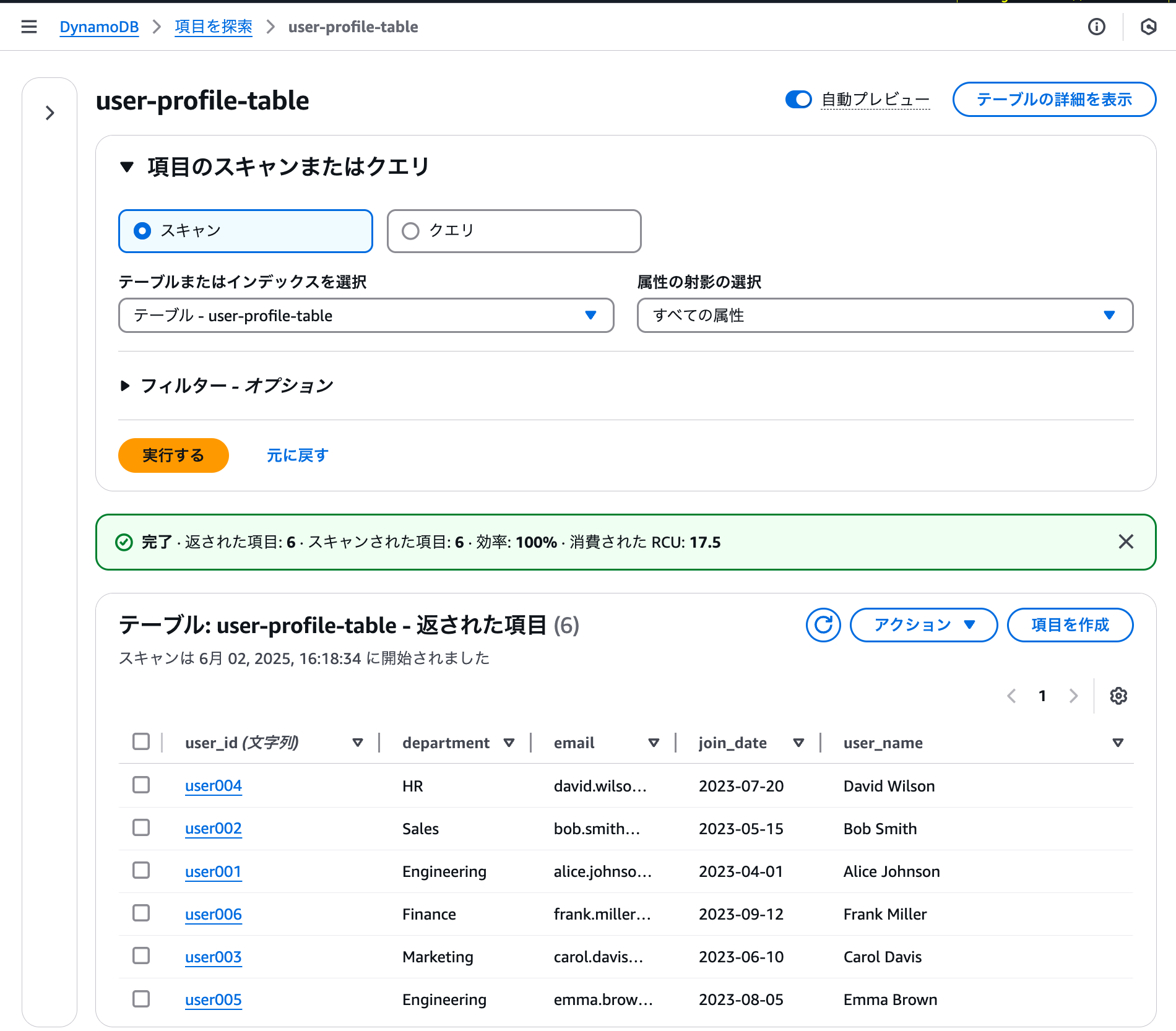
テーブルの削除
テーブルが不要になった場合は、以下のコマンドで削除できます。
aws dynamodb update-table \
--table-name $TABLE_NAME \
--no-deletion-protection-enabled && \
aws dynamodb delete-table \
--table-name $TABLE_NAME && \
echo "✅ テーブル削除完了: $TABLE_NAME"
まとめ
今回紹介したスクリプトにより、CSVファイルの作成からDynamoDBテーブルのインポートまでを一括で自動化できました。
このスクリプトを活用することで、テスト環境のセットアップ時に、毎回同じデータを手動で投入する手間がなくなり、環境構築時の初期データ投入作業を大幅に効率化できます。
なお、スクリプトの設定変数を変更するだけで、異なるデータセットやテーブル構成にも対応可能です。
参考









