
【登壇資料】「AWSで推進するデータマネジメント」というタイトルで登壇しました #devio2025
データ事業本部の川中子(かわなご)です。
先日クラスメソッド大阪にてDevelopersIO 2025 Osakaというイベントがありました。
幅広くIT技術について語らい合うオフラインイベントです。
その中で 「AWSで推進するデータマネジメント」 というタイトルで登壇したので、
発表した内容について、こちらでも簡単に紹介させていただきます。
なぜ今「データマネジメント」が必要なのか?
まず、本セッションの核となる「データマネジメント」について簡単におさらいします。
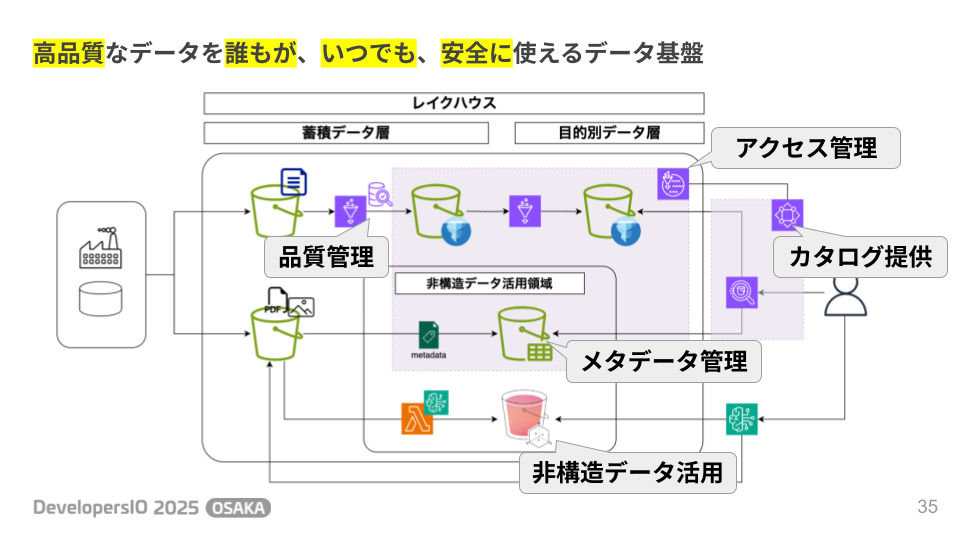
データマネジメントとは、 「高品質なデータを、誰もが、いつでも、安全に使える状態を保つ活動」 です。
企業が持つデータを価値ある資産として活用するために、品質、セキュリティ、可用性、ガバナンスなどを体系的に管理する取り組みを指します。
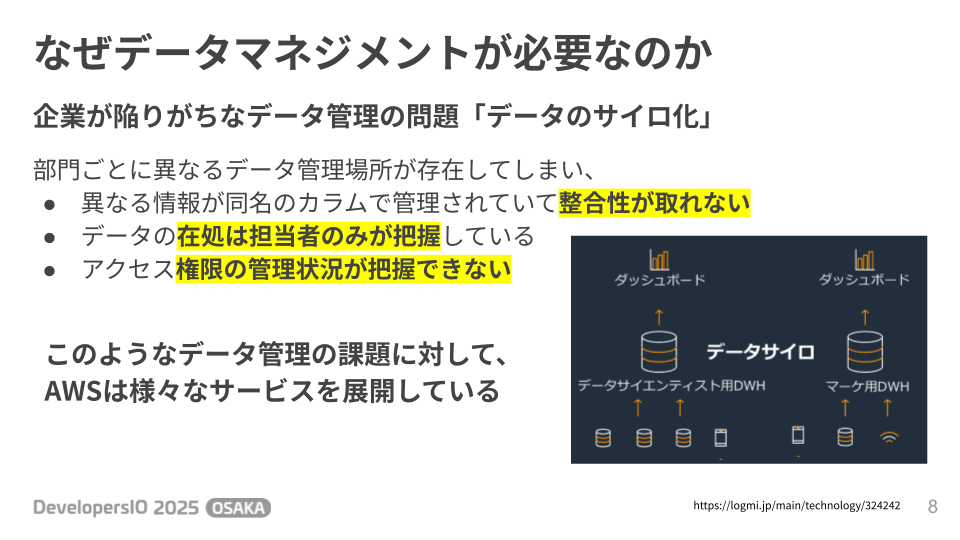
しかし、多くの組織では部門ごとにデータがバラバラに管理される 「データのサイロ化」 という課題に直面しています。
サイロ化が起こると、以下のような問題が発生します。
- 部門間でデータの定義が異なり、統合できない
- データのありかが担当者しかわからず、属人化する
- 誰がどのデータにアクセスできるのか管理が不十分になる
こうした課題を解決し、データを真の資産として活用するために、データマネジメントの重要性が高まっています。
サイロ化を解消する「Lakehouseアーキテクチャ」
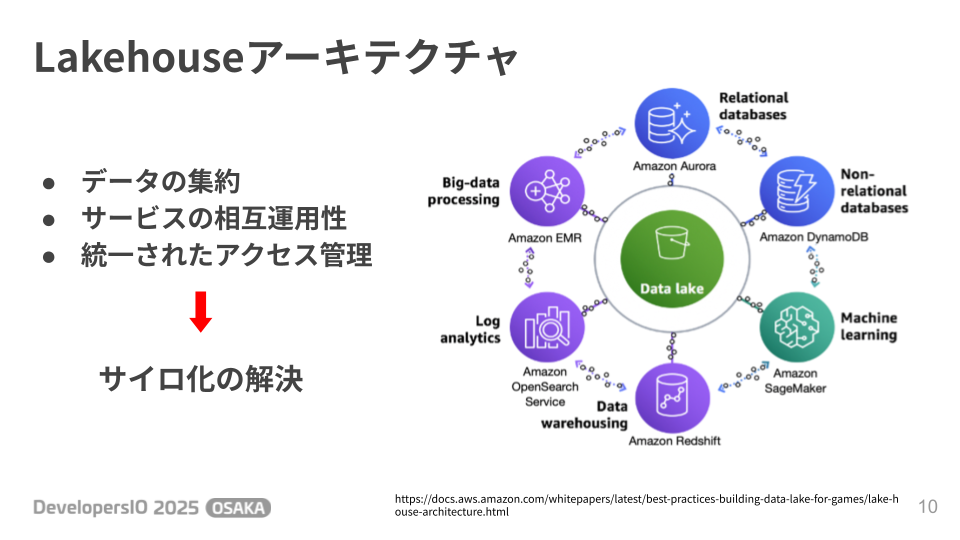
データのサイロ化に対する有効な解決策として、AWSでは 「Lakehouse(レイクハウス)アーキテクチャ」 を推奨しています。
これは、あらゆるデータを一元的に格納する「データレイク」を中心に、データウェアハウスや各種分析・機械学習サービスがシームレスに連携する構成です。
このアーキテクチャにより、データの集約、サービス間の相互運用性、そして統一されたアクセス管理が実現され、サイロ化を解消します。
レイクハウスを支える中核サービス
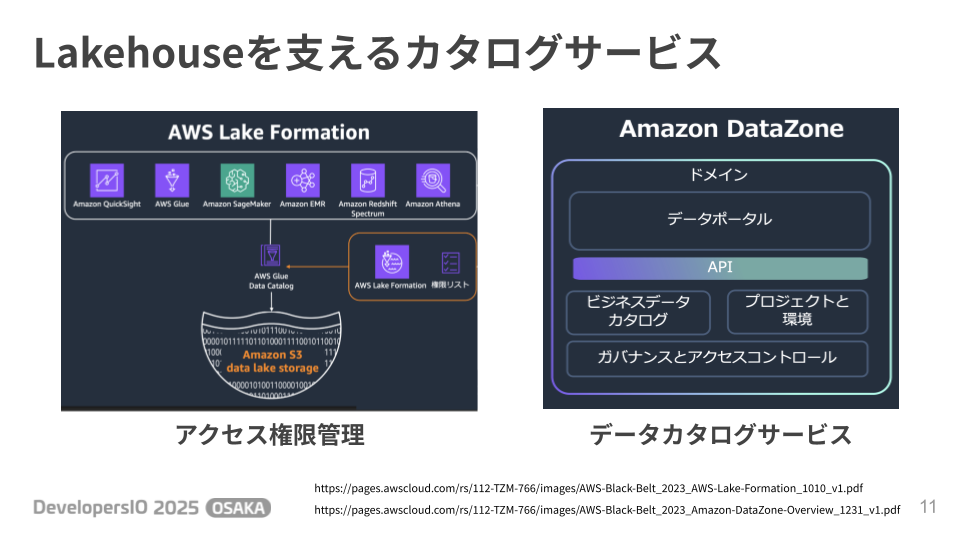
このレイクハウスアーキテクチャの実現において、データガバナンスを支える中心的なサービスが 「AWS Lake Formation」 と 「Amazon DataZone」 です。
1. データアクセスを一元管理する「AWS Lake Formation」
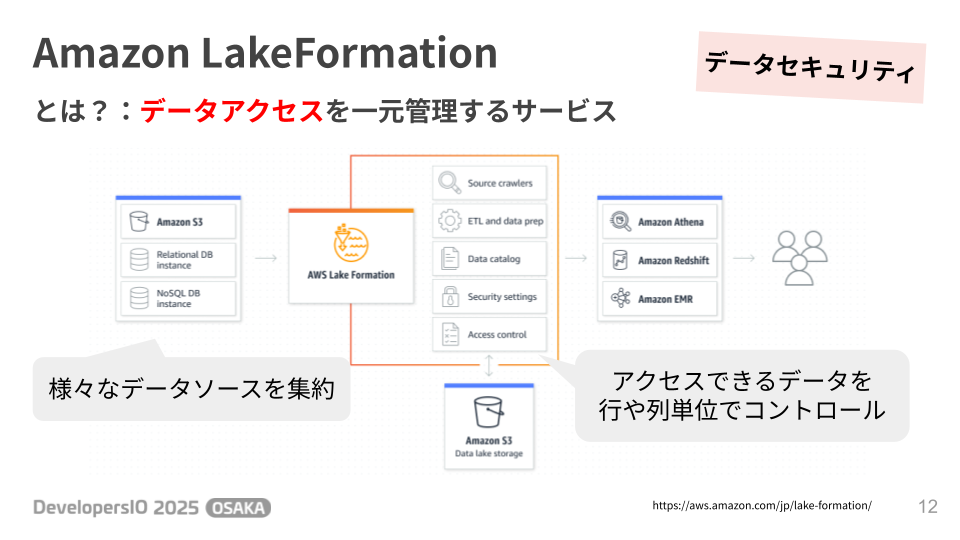
Amazon S3上のデータレイクや各種データベースへのアクセス権限を、一元的に管理するサービスです。
ユーザーごとに行単位・列単位で緻密なアクセスコントロールが可能で、データセキュリティの基盤を担います。
2. データを見つけ、使えるようにする「Amazon DataZone」
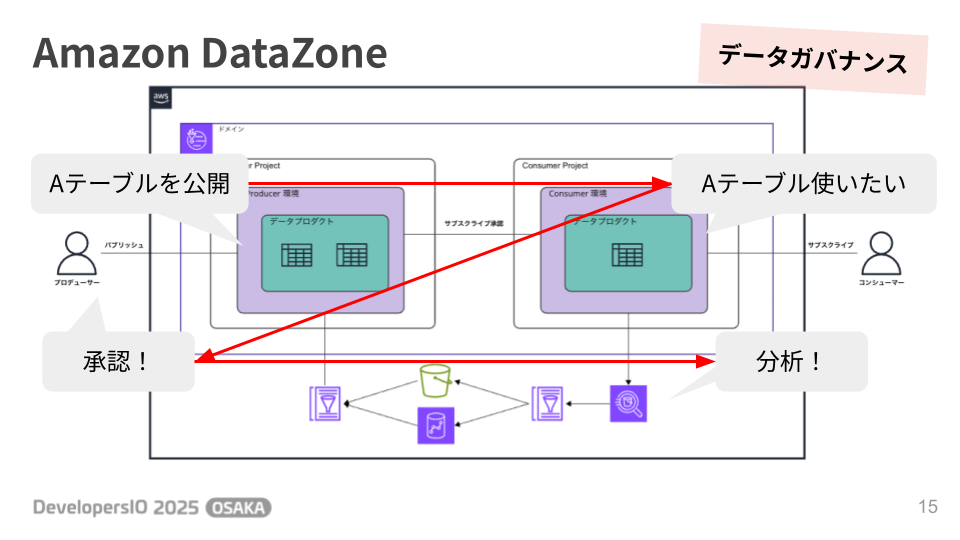
組織内のデータ資産をカタログ化し、利用者がセルフサービスでデータを発見・利用申請できるようにするサービスです。
- データ提供者(プロデューサー): 管理するデータをDataZoneに公開(カタログ登録)します。
- データ利用者(コンシューマー): 公開されたカタログを検索し、必要なデータを見つけて利用申請を行います。
これにより、データガバナンスを効かせつつ、組織全体でのデータ活用を安全かつスムーズに促進できます。
データ利活用の未来像:次世代SageMaker
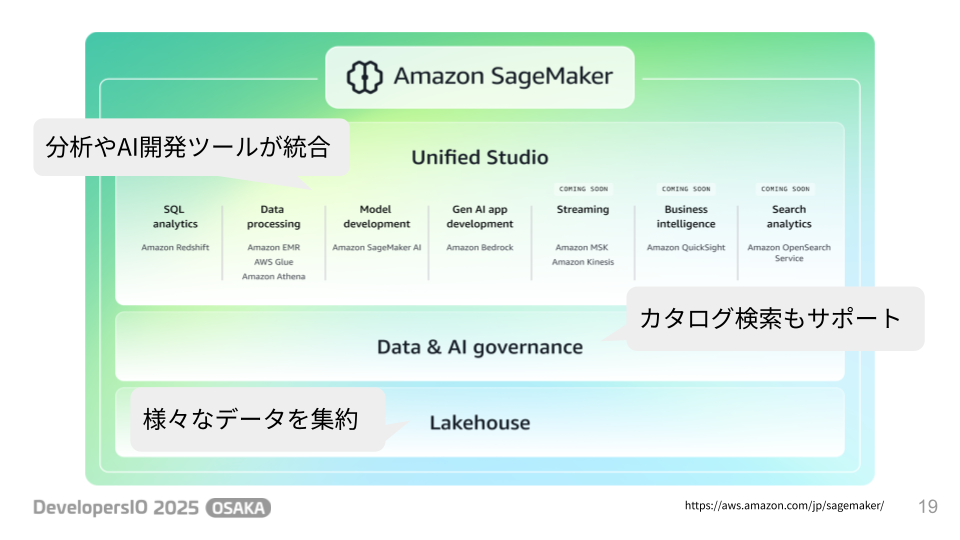
そして、今後のデータ利活用の中心になる可能性を秘めているのが、
発表されたばかりの 次世代Amazon SageMaker です。
これは、データの探索から準備、モデル開発、生成AIアプリ開発まで、データとAIに関わるあらゆるコンポーネントを統合したプラットフォームです。Lakehouseを基盤とし、DataZoneと連携したカタログ検索もサポートしており、今後ますます重要な役割を担っていくことが予想されます。
データレイクを進化させるサービス活用例
Lakehouseアーキテクチャでは、「データをどう貯めるか」という点も非常に重要です。
ここでは、構造データと非構造データの管理・活用に役立つ主要なサービスをご紹介します。
構造データ:テーブル管理と品質担保

データレイク上でテーブル形式のデータを扱う際の課題(パフォーマンス劣化やコスト増加)を解決するのが 「Amazon S3 Tables」 です。
これは、オープンテーブルフォーマットであるApache Icebergの利用するAWSのマネージドサービスで、ファイルの最適化やアクセス管理を自動化し、クエリ性能とストレージ効率を最適化してくれます。
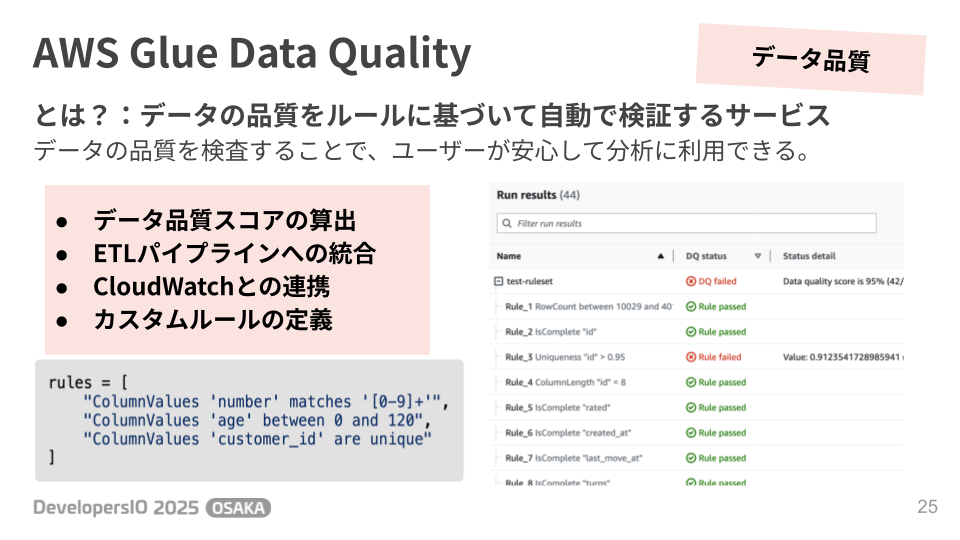
また、「AWS Glue Data Quality」 を使えば、「この列の値は必ずユニークであること」といったルールを簡単に定義し、データの品質を自動で検証できます。
これにより、信頼性の高いデータをユーザーに提供することが可能になります。
非構造データ:ベクトル検索とメタデータ管理
近年活用の幅が広がっている画像やドキュメントなどの非構造データについては、以下の新サービスが注目されています。
Amazon S3 Vectors: 生成AIなどで利用されるベクトルデータを、従来のベクトルデータベースよりも大幅に低コストで保存・検索できるサービスです。

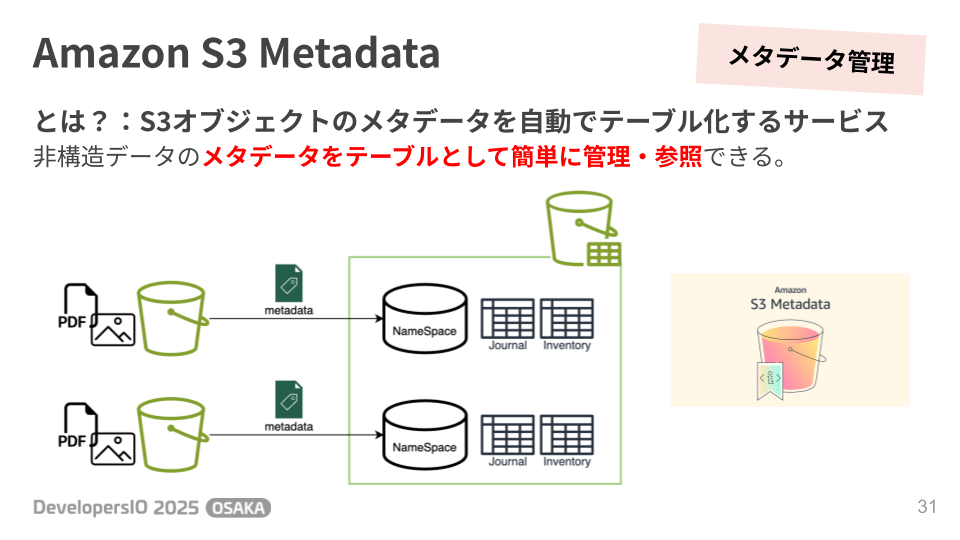
Amazon S3 Metadata: S3オブジェクトのメタデータ(ファイル名、サイズ、作成日など)を自動でテーブル化し、管理や検索を容易にするサービスです。
まとめ:目指すべきデータ基盤の姿
今回ご紹介した様々なサービスを組み合わせることで、安価なS3というストレージを中心に 「高品質なデータを、誰もが、いつでも、安全に使えるデータ基盤」 を構築することも可能です。
- データマネジメント は、データを資産として活用するために不可欠
- サイロ化の解決策として Lakehouseアーキテクチャ が有効
- Amazon S3 Tables や AWS Glue Data Quality により、データレイク上で高品質なテーブル管理が可能
- Amazon S3 Vectors や Amazon S3 Metadata など、非構造データを活用するためのサービスも進化している
これらのAWSサービスを適切に選択・活用することで、社内のデータを守り、その価値を最大限に引き出すことができます。
さいごに
以上が登壇スライドでお話ししたおおまかな内容となっています。
本記事で記載した内容は一部となっていますので、
併せてスライド資料の方も見ていただけますと幸いです。
これらのAWSサービスを上手く活用して、
データマネジメント活動をどんどん加速していきたいですね。
本資料が少しでも参考になれば幸いです。
最後まで記事を閲覧頂きありがとうございました。









