
深夜2時のアラート対応、AWS DevOps Agent があればどう変わるのか比べてみた
こんにちは、kaz です。
はじめに
先日、AWS DevOps Agent が GA(一般提供)になり、機能紹介記事はすでにたくさん出ています。
なので、この記事では少し違う角度から書いてみます。
テーマはシンプルで「深夜2時にアラートが鳴った」という、運用をやっている人なら誰もが経験したことのあるシナリオを使って、DevOps Agentがあるのとないのとで何が違うかを比較してみます。
DevOps Agent とは(30秒でわかる概要)
ひとことで言うと「自律的に動く運用チームメイト」です。
インシデントが発生すると、DevOps Agent はログ・メトリクス・デプロイ履歴・コードなどの情報を横断的に分析し、根本原因の特定から対処の提案までを自律的に行ってくれます。
さらに、過去のインシデントから学習して予防策を提案する機能も備えています。
DevOps Agent がない世界線
「深夜2時、本番環境でアラートが鳴った」
深夜2時にオンコール担当のあなたのスマホが鳴ります。
眠い目をこすりながらスマホを確認すると「本番環境のエラーレートが急上昇」のアラート通知。飛び起きます。
PCを開き、まず監視ダッシュボードを確認します。確かにエラーレートが跳ね上がっている。しかしダッシュボードだけでは原因まではわかりません。
次にログを確認します。複数のロググループを開き、タイムスタンプを頼りにエラーログを探します。怪しいログを見つけても、それが原因なのか結果なのか深夜の頭ではすぐに判断がつきません。
「最近デプロイしたっけ?」と思い、Git のコミット履歴を確認。夕方に同僚がデプロイしていたことがわかる。でも、デプロイから数時間経ってからのエラー急増なので本当にそれが原因かどうか確信が持てない。
依存しているサービスの状態も気になるので、関連するメトリクスやステータスページも巡回します。
ここまでで、すでに1時間近く経過しています。
ようやく「おそらくこれが原因だろう」という仮説にたどり着き、対処を行い、エラーレートが落ち着いたことを確認して Slack に報告。
時計を見ると午前4時。ポストモーテムは後日で・・・。
この世界線の問題
この流れ、運用経験のある方なら「あるある」と感じるのではないでしょうか。整理すると以下のような問題があります。
- ログ、メトリクス、デプロイ履歴、コードがそれぞれ別のツールに存在し、手動で横断的に確認する必要がある
- 調査の品質が個人の経験やスキルに大きく依存する。ベテランなら30分で見つけられる原因も、経験の浅いメンバーだと数時間かかることも
- 深夜対応の疲労で、ポストモーテムや再発防止策の検討が先延ばしになりがち
- 夜間対応の頻度が高いと、エンジニアの離職や燃え尽き症候群につながるリスクもある
これらは個人の努力ではなく、運用の仕組みそのものの限界だと思います。
DevOps Agent がある世界線
同じ深夜2時、同じ「エラーレート急上昇」のアラートが発火します。
しかし、この世界線ではアラートが鳴った瞬間に DevOps Agent が自動で調査を開始します。
Agent はまず、関連するログ・メトリクス・デプロイ履歴を横断的に収集・分析します。世界線A ではオンコール担当が手動で巡回していた作業を、Agent が数分で完了させます。
さらに、収集した情報を相関分析し、「夕方のデプロイで導入された変更が、特定の条件下でエラーを引き起こしている」という根本原因の仮説を立て、その根拠となるログやメトリクスとともに Slack に調査サマリを通知します。
オンコール担当のあなたも、同じようにアラートで目を覚まします。残念ながらここは変わりません。
しかし、スマホを確認すると、すでに Agent が調査を進めている。PC を開く頃には調査サマリが Slack に届いていて、「何が起きているのか」「原因は何か」がまとまっています。あとはその内容をレビューして対処方針を判断するだけです。
DevOps Agent がない世界線では原因特定まで1時間以上かかっていた作業が、大幅に短縮されます。
この世界線の特徴
- アラート発火の瞬間から調査が始まり、エンジニアの依存がなくなる
- ベテランも新人も関係なく、同じ品質の調査結果が得られる
- 過去のインシデントパターンを学習し、類似の問題が再発しないよう予防策を提案する
- インシデントの消火活動から解放され、改善や開発といった本来の業務に時間を使える
比較してみる
2つの世界線を観点ごとに並べてみます。
| 観点 | ない世界線 | ある世界線 |
|---|---|---|
| 初動速度 | 人が起床してPCを開いてから開始 | アラート発火と同時に自動開始 |
| 情報収集 | 複数ツールを手動で巡回 | ログ・メトリクス・コードを横断的に自動収集 |
| 根本原因特定 | 個人の経験とスキルに依存 | 体系的な相関分析で一貫した品質 |
| 属人性 | 高い(ベテラン依存) | 低い(チーム全体が同品質の調査結果を得られる) |
| 予防・学習 | 余裕がないと後回し | 継続的に学習し、予防策を自動提案 |
| エンジニアの負荷 | 夜間対応で心身ともに消耗 | 起きる必要はあるが、調査済みの状態からスタートできる |
| ナレッジの蓄積 | 個人の記憶や散在するドキュメント | 調査結果が構造化されて蓄積される |
図にするとこんな感じでしょうか。
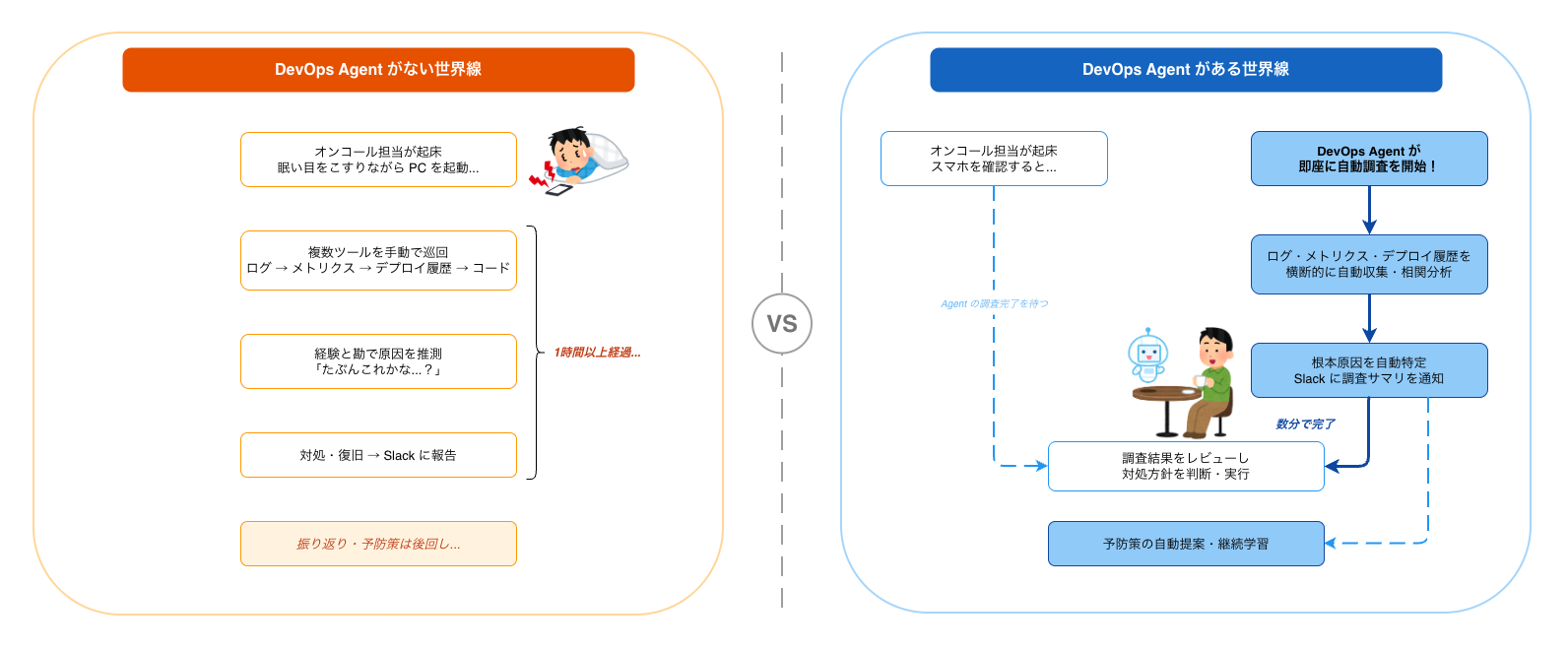
これらを眺めて改めて感じるのは、DevOps Agent の価値は「速くなる」だけではないということです。
属人化の解消や予防への転換、エンジニアの負荷軽減など、これらは運用チームが長年抱えてきた課題であり、ツールの導入だけでは解決しづらかったものだと思います
DevOps Agent は、これらの課題に対して「人を増やす」のではなく「仕組みで解決する」アプローチを提供してくれるのだと思います。
個人的に感じた「ここが変わる」ポイント
実際に触ってみて、特に印象に残ったことを3つ挙げます。
1. 「チームメイト」という位置づけが絶妙
DevOps Agent は完全な自動化ツールではありません。
調査と分析は自律的に行いますが、最終的な判断と対処は人が行います。
この「調査は任せるけど、判断は人がする」というバランスが、現場の運用にはちょうどいいと感じました。
完全自動化は信頼性の面で不安がありますし、かといってすべて手動では限界がある。その中間を埋めてくれる存在だと思います。
2. 運用のパラダイムが「消火活動」から「予防活動」に変わる
従来の運用はインシデントが起きてから対処する「リアクティブ」なスタイルが中心でした。
ポストモーテムや予防策の検討は重要だとわかっていても、日々の対応に追われて後回しになりがちです。
DevOps Agent は過去のインシデントパターンを学習し、予防策を提案してくれます。
つまり、運用チームの仕事が「問題を解決すること」から「問題を未然に防ぐこと」にシフトできるということです。
これは単なる効率化ではなく、運用の考え方そのものの転換だと思います。
3. 新しいメンバーのオンボーディングが変わる
属人化の解消という観点で見ると、新しくチームに入ったメンバーが即座に過去のインシデント対応の知見にアクセスできるのは大きいですね。
従来は「あのときの障害は〇〇さんに聞いて」という暗黙知に頼りがちでしたが、DevOps Agent の調査結果が蓄積されていればチームの知見が構造化された状態で残ります。
まとめ
DevOps Agent は、インシデント対応を「人が頑張る」から「仕組みで支える」アプローチに転換してくれるサービスだと感じました。
速度や効率だけでなく、属人化の解消やエンジニアの負荷軽減といった構造的な課題にアプローチできる点が従来のツールとの大きな違いです。
まだ GA になったばかりのサービスですが、運用のあり方を考え直すきっかけとしてぜひ一度触ってみてください!
なお、DevOps Agent のスキルや MCP を活用した実践的な使い方については以下の記事で紹介しています。あわせてどうぞ!









