
AWS上で稼働する基幹システムのDisaster Recoveryについて考える
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは。
ご機嫌いかがでしょうか。
"No human labor is no human error" が大好きな吉井 亮です。
先日、前職の同僚と会話をする機会がありました。(前職では ERP 導入をしていました)
彼の顧客が大阪リージョンを利用した DR を計画しているという聞きまして、AWS 上の基幹システムの DR を改めて考えてみました。
何に備えるのか
DR の定義を「様々な災害被害を受けたシステムを復旧させること」とするとあまりに広すぎます。何に備えるかをまず初めに考え、災害とは何を指すかを定義しておきましょう。
例えば以下のような事象を想像します。他にも自組織では何をもってして災害とするかを考えてみてください。
- 自然災害によるシステムダウン(地震、洪水、火災など)
- 社会インフラの停止(停電、インターネット回線断など)
- ユーザーでは対策できない AWS 障害(リージョン、アベイラビリティゾーンレベル)
- 人的災害(マルウェア・ランサムウェア感染、テロ、ストライキなど)
- 作業ミスによるデータロスト、全損・一部損
DR 求められているので対策考えてください、というご依頼を頂戴することが稀にあります。何をもって災害とするかによって対策と費用が変わります。私はしつこくここを確認するようにしています。
DR 検討前に災害を定義しますが最終決定ではありません。後段フェーズで具体的な方式・アーキテクチャが決まってくるとコスト計算が可能になります。災害の発生確率や頻度とコストを天秤にかけて災害の定義を見直します。
見直しは運用が始まってからも継続的に実施することが理想だと考えます。
3つの指標
DR を検討するうえで大切な指標が3つあります。
何に備えるのか、次に定義します。
- RPO(Recovery Point Objective、目標復旧時点)
- 災害からの復旧時にどの時点のデータに戻っていればよいか
- 最後のバックアップから災害によるサービスダウンまでの間に許容されるデータ損失期間
- RTO(Recovery Time Objective、目標復旧時間)
- 災害によるサービスダウンから復旧までの最大許容時間
- RLO(Recovery Level Objective、目標復旧レベル)
- どの程度まで復旧させるか
- サブシステムが複数存在する場合、業務上重要なシステムを復旧の対策にする
- 重要度の低いシステムは後回しにする
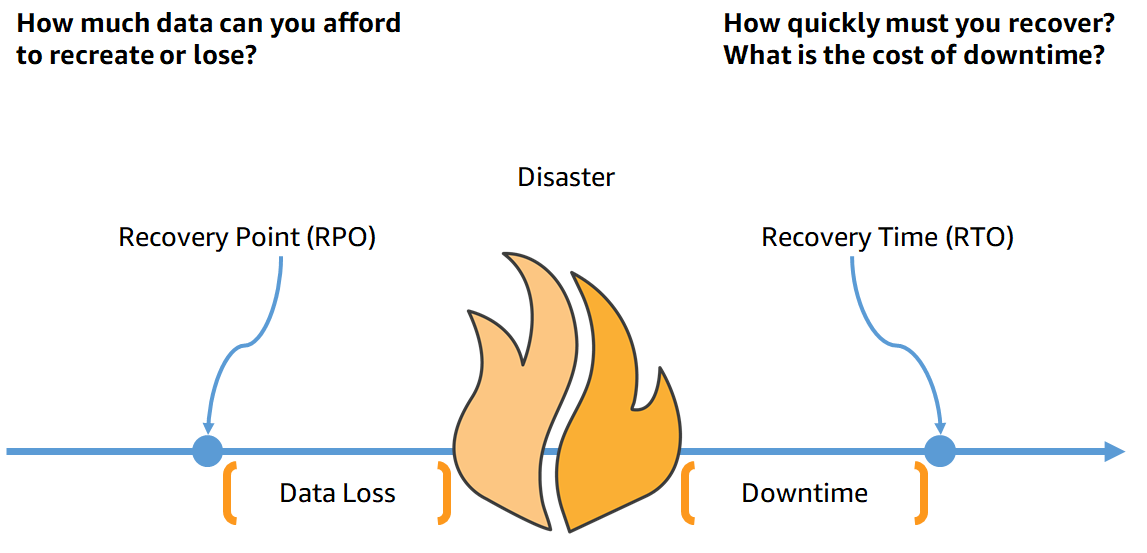
https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/business-continuity-plan-bcp.html より引用
目標値の決定
目標値は机上で全てを決めるのではなく、構築しテストをしながら少しずつ調整します。根拠の無い目標値は避けましょう。
テック的なタスク、例えばスナップショットから RDS の復旧、だけではなく DR の検知~DR 発動の意思決定~社内報知~担当者アサイン~テック的なタスク~業務的な復旧確認~社内報知までテストします。フローの正確性や所要時間を計測します。
3つの指標とコスト
3つの指標はそれぞれが関係し合っています。3つをバランスよく定義することが大切です。
例えば、サブシステムが複数あるシステムで RTO が数時間、かつ、RLO が 100% であることは (人的リソースが大量な組織以外は) 現実的ではありません。
RPO が数分~1時間未満であればスナップショットでは事足りず、データレプリケーションが必要になるかもしれません。
3つの指標の目標値を理想に近付ければ近付けるほど DR コストが増えていきます。コストと相談しながら目標値を決定します。
リージョン内冗長をまず考える
オンプレミスに仮想サーバー環境を立てることと、AWS 東京リージョンに EC2 を立てることは DR 観点でイコールではありません。
東京リージョンは3つ(一部のユーザーは4つ)のアベイラビリティゾーンが提供されています。
アベイラビリティゾーンは1つ以上のデータセンターで構成されています。各ゾーンは電源、ネットワークが高度に冗長化されており、停電等の災害に耐える構成となっています。
リージョン内で AWS リソースを適切に冗長化する、または、冗長されたマネージドサービスを使うことで複数のデータセンターを跨いだ構成をとることが可能です。
オンプレミスで東京近郊に1つのデータセンター、DR 対策で関西や北海道などの遠隔地にデータセンターを用意する戦略は正しいと思います。
AWS ではリージョンが複数データセンターで構成されているという大きな違いがあります。単一データセンター時代と同じ発想で DR を考えることはせず AWS インフラストラクチャーを考慮した DR 戦略を策定することが大切です。
東京リージョン内で適切な冗長構成を採用することをまず第一に考え、それでも DR 要件を満たせない場合に他リージョンでの DR 構成を検討することをお勧めしています。
DR選択肢
AWS での DR を検討するとしたらどのようなアプローチがあるでしょうか?
Disaster Recovery of Workloads on AWS: Recovery in the Cloud では4つのアプローチが紹介されています。
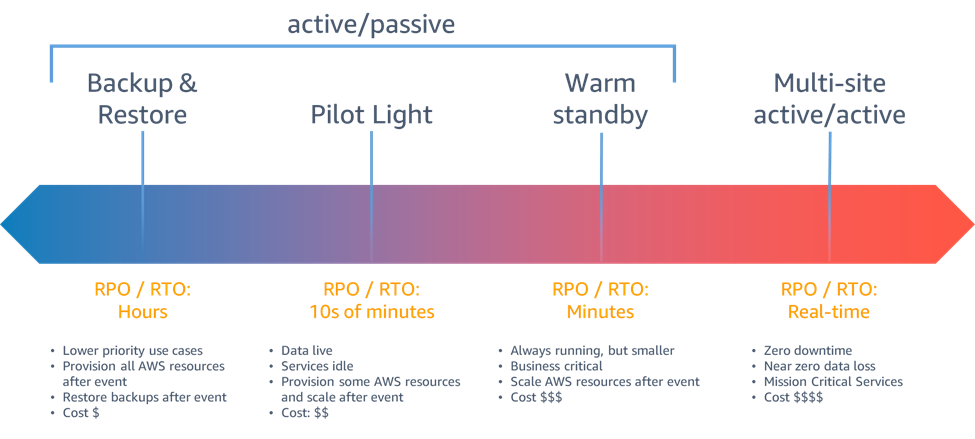
https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-options-in-the-cloud.html より引用
Backup & Restore
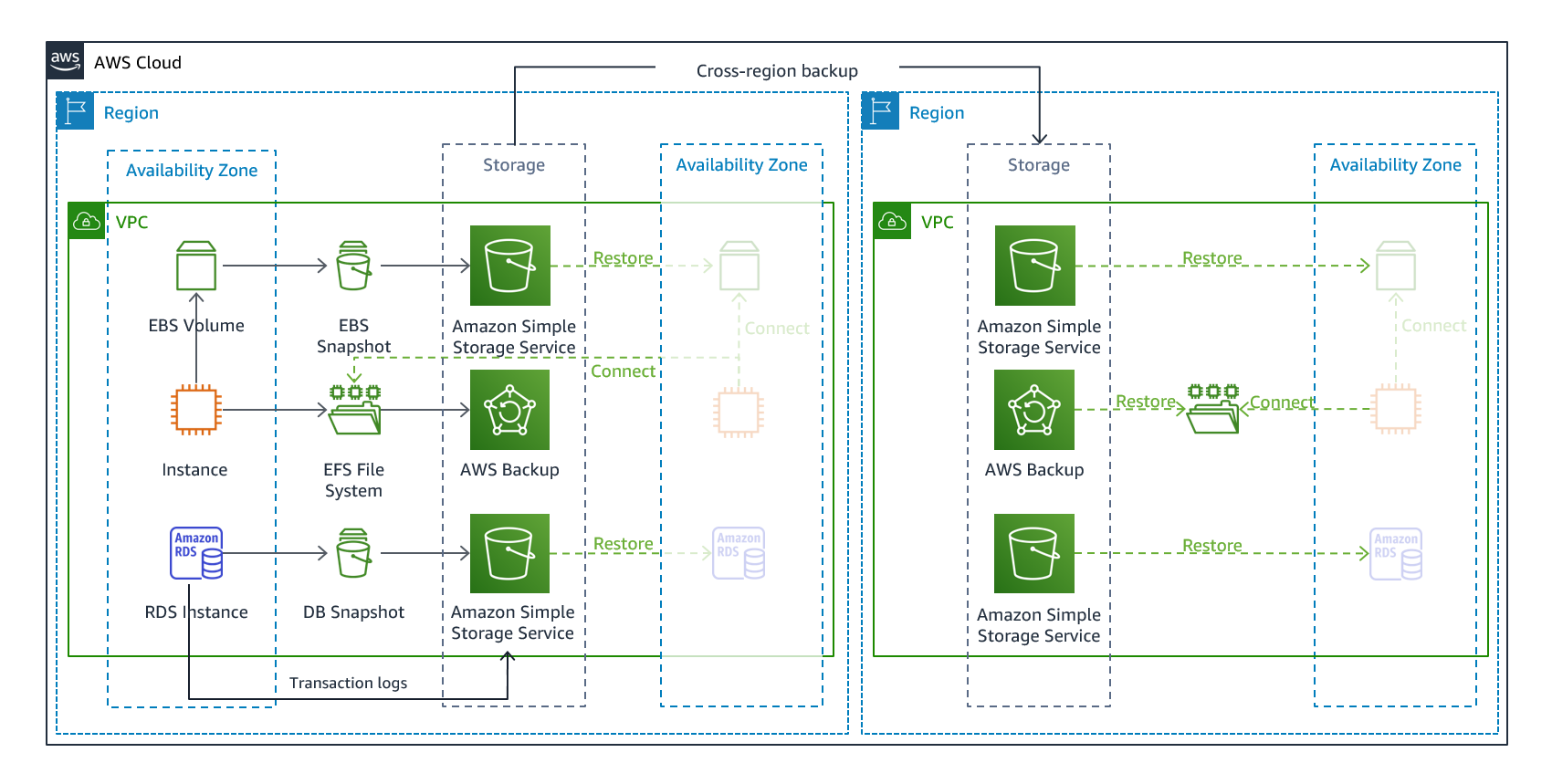
https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-options-in-the-cloud.html より引用
データを別リージョンに定期コピーしておき、データの損失や破損を回避します。オンプレミスではテープや専用回線で ”データ疎開” していたと思います。同じアプローチです。
コピーしておいたデータを使い、別リージョンでサービスを再開することも可能です。
AWS CDK や Terraform を用いてインフラをコード化しておきます。このコードでは AMI、スナップショット、または、データからインフラを復元できるような記述しておいてください。
コードは常に最新化します。本番稼働環境で行ったいかなる設定変更も必ずコードに反映します。これを必ずフロー化してください。
コード化の他に AWS Elastic Disaster Recovery というサービスもあります。EC2 (EBS) をブロック単位でリアルタイム複製しておき復旧可能な状態にしてくれます。復旧操作を行うことで複製先リージョン内に EC2 を起動します。
Pilot Light
https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-options-in-the-cloud.html より引用
DR 先リージョンでは本番稼働環境と同じリソースを作っておき、停止状態にしておきます。(停止できないリソースは稼働のまま)
AWS 利用料金は少々発生しますが Backup & Restore と比較すると DR 復旧時間が短くなります。
図にある通り、DB を継続的にレプリケーションしておくとさらに復旧時間が短くなると思います。
EC2 は AutoScaling を採用するなどの工夫をし、AMI から起動すれば復旧するといったアーキテクチャしておくことがポイントです。コンテナやサーバーレスを採用することで DR 復旧に強くなると思います。
Pilot Light でもインフラのコード化は必須です。
Warm standby
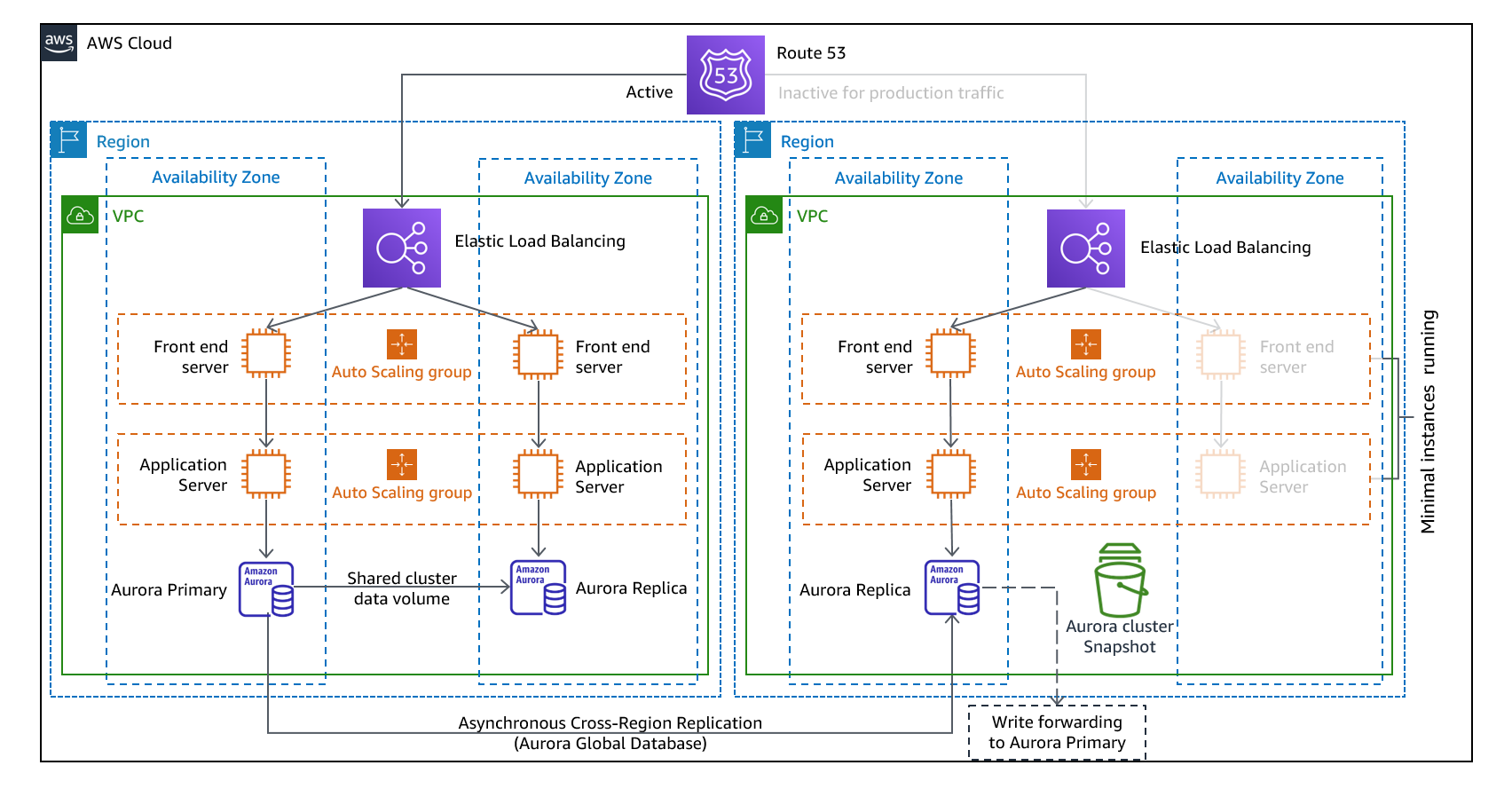
https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-options-in-the-cloud.html より引用
DR 先リージョンで本番稼働環境と同じ構成を縮小した状態で稼働しておきます。 DR 復旧時に本番環境環境と同等のスペックや台数に戻して運用します。
DB やファイルなどのデータは常に継続的にレプリケーションしておきます。
AWS リソースは稼働している状態なので、DR 復旧までの時間は Pilot Light に比べ短くなります。引き換えに AWS 利用料金は大きくなります。
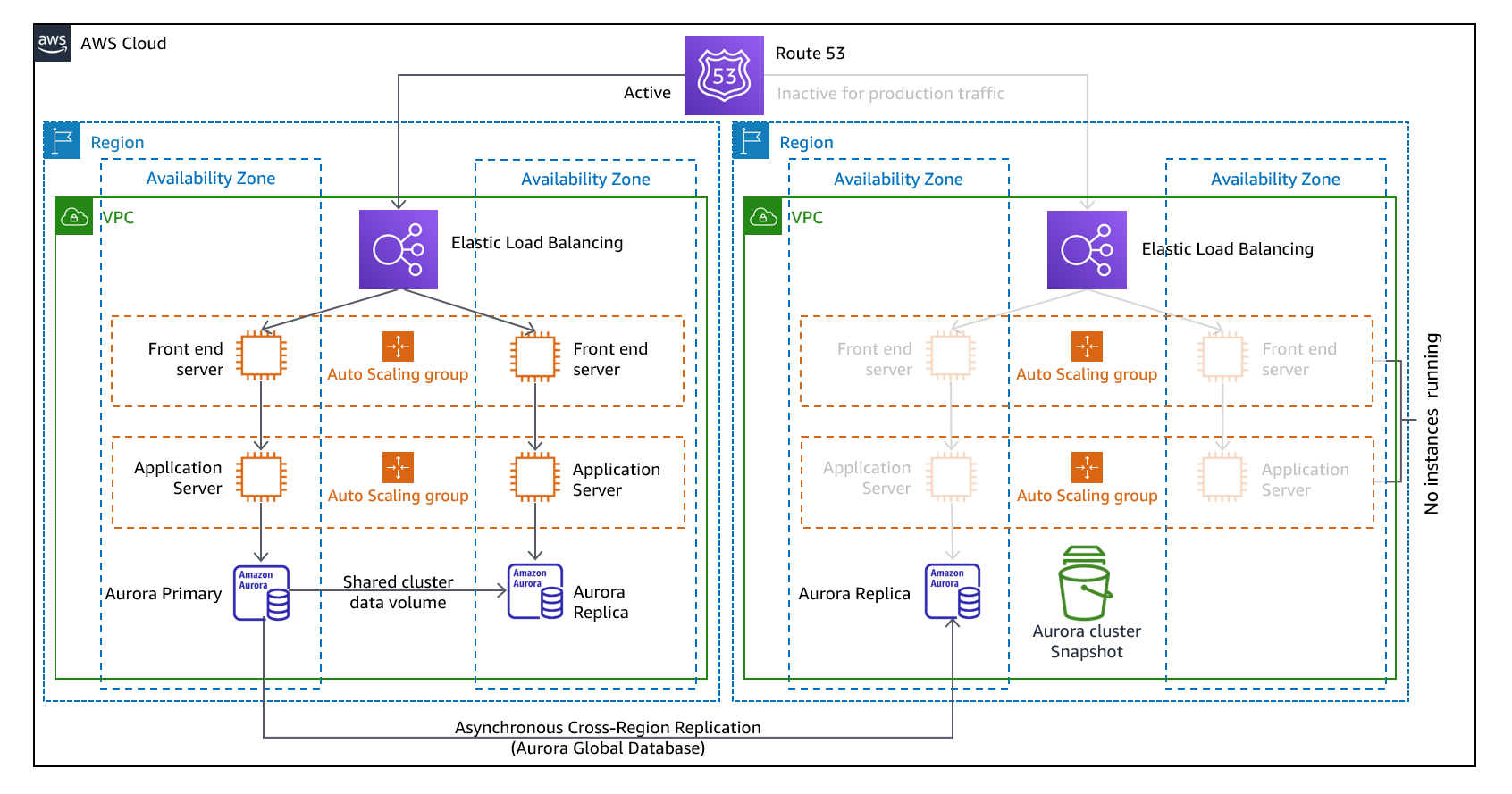
Multi-site active/active
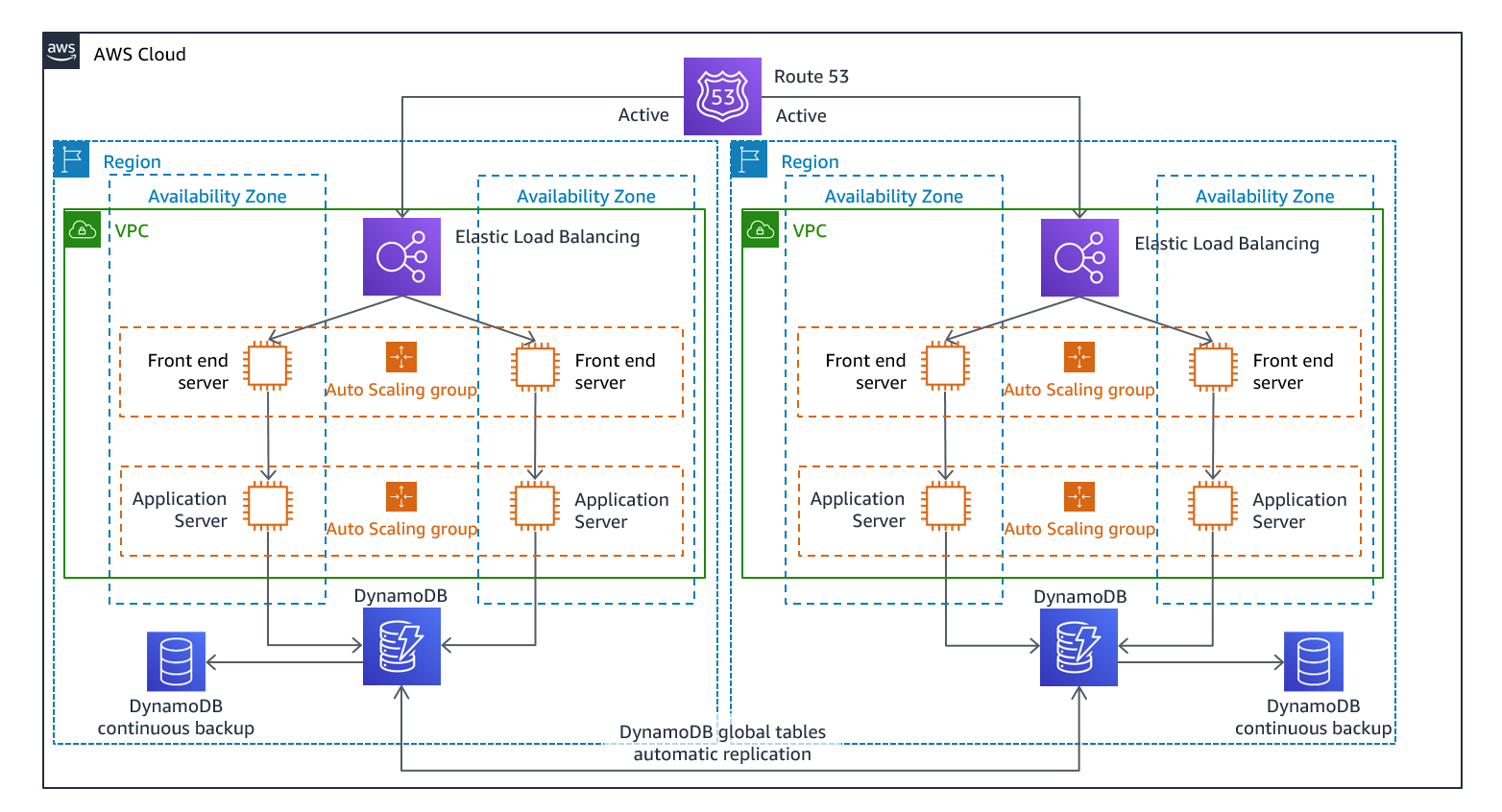
https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-options-in-the-cloud.html より引用
複数のリージョンで同時に本番環境を稼働します。1つのリージョンが仮にダウンしてもサービスへの影響はほぼ無いと想定します。
紹介した4つの選択肢のなかで最も AWS 利用料金は大きくなり、アーキテクチャが複雑になります。
図中では DB が DynanoDB になっています。すべてのリージョンで書き込みを可能にする場合は DynanoDB Global tables が選択肢にあがります。
Aurora Global Database は単一のリージョンが書き込みになります。別のリージョンでは書き込み転送を有効にし Writer へ書き込みを転送します。Aurora Global Database のフェイルオーバーは手動実行になります。
検出
DR 発動条件の検出はとても困難です。
「何に備えるのか」で定義した条件にあてはまる事象に陥ったことは人間は判断するしかありません。
例えば、AWS リージョン障害が発生したとします。可用性の対策としてシステムダウンを検知し、その原因解析を行いリージョン内での復旧を試みます。復旧が思う通りに進まない結果、どうやらリージョン全体がサービスレベルダウンしていると判明します。ここで DR 発動の判断を行います。 DR 発動の判断はとても基準が難しく Multi-site active/active の構成を除き自動化は難しいと考えます。組織としての判断が求められるはずです。
システム運用体制のなかで DR 発動フローを定めておく必要があります。
- システムダウンの検知
- 原因の調査
- リージョン内での復旧を実施
- DR 発動必要性の認識
- システムダウン検知から○○時間はリージョン内での復旧を試みる
- ○○時間経過後、復旧の目処が立たないならば DR 発動
- 社内・社外関係各所に DR 事象発生の報知
- DR 復旧作業の開始
- DR 復旧作業の完了
- 社内・社外関係各所に DR 復旧の報知
- DR 先での運用
- フェイルバック実施可否、時期の判断
- フェイルバック計画
- 社内・社外関係各所にフェイルバックの報知
- フェイルバック実施
- 社内・社外関係各所にフェイルバック完了の報知
体制
DR 体制を整えておきます。
- DR 発動責任者 (社内的にかなり上位の役職者)
- DR 実施責任者 (本部長、部長クラス)
- DR 復旧作業チーム (システムに精通しているエンジニア)
- DR 連絡窓口 (社内・社外との連絡窓口)
- DR 改善委員会
DR が自然災害や停電に備えるものだとしたら、復旧作業チームは遠隔地に配置するべきです。これはかなりのハードルですが、停電で PC もインターネットも使えない状態で復旧作業はできないはずです。
体制は自社リソースで揃えるべきだというが私の持論ですが、外部 MSP などの委託する場合はスキルトランスファーを十分に行い、非難訓練も頻繁に実施したほうが実際の成功率は上がると思います。外部ベンダー任せにするのは危険です。
過去のAWS障害と影響時間
過去に発生した大規模な AWS 障害とその影響時間を調べてみます。
| タイトル | 日付 | サービス影響があった時間帯(最大) |
|---|---|---|
| Summary of the AWS Service Event in the Northern Virginia (US-EAST-1) Region | December, 10th 2021 | 7:30 AM - 6:40 PM PST |
| Summary of AWS Direct Connect Event in the Tokyo (AP-NORTHEAST-1) Region | September, 2nd 2021 | 7:30 AM - 1:42 PM JST |
| Summary of the Amazon Kinesis Event in the Northern Virginia (US-EAST-1) Region | November, 25th 2020 | 5:15 AM - 10:23 PM PST |
| Summary of the Amazon EC2 and Amazon EBS Service Event in the Tokyo (AP-NORTHEAST-1) Region | August 23, 2019 | 12:36 PM - 18:30 PM JST |
| Summary of the Amazon EC2 DNS Resolution Issues in the Asia Pacific (Seoul) Region (AP-NORTHEAST-2) | November 24, 2018. | 8:19 AM - 9:43 AM KST |
| Summary of the Amazon S3 Service Disruption in the Northern Virginia (US-EAST-1) Region | February 28, 2017. | 9:37 AM - 1:18 PM PST |
直近 (2017年まで) のものについて調べました。
リージョン丸ごと落ちるような事態は起きていないようです。リージョン内の特定サービスが影響を受けています。
数時間~最大17時間の影響時間でした。なぜ影響時間を調べたかという話をします。
DR の判断をしてから復旧を完了させるまでの時間を計測してほしいです。おそらくですが、復旧を待ったほうが良いパターンのほうが多いのではないでしょうか。
DR 復旧手順が高度に自動化されて訓練も万全であれば17時間待つよりかは速いですが。。。
記憶に新しい2019年8月の東京リージョン大規模障害でも (公式発表では) 6時間で復旧しています。この時は1つのアベイラビリティゾーンでのイベントでしたので、Multi-AZ 構成にしておけばサービス提供には影響が無いかもしれません。
DR を検討する際にこのような観点でも議論をしてほしいと思っています。
大規模まではいかないですが、Health Dashboard に乗るような障害の確認方法は以下のエントリを参照ください。
大阪リージョンの存在
日本で大阪リージョンが一般公開されたことは DR 観点でとても大きな意味があります。DR 用のリージョンであればオレゴンやソウルでも要件は満たせるはずです。ただ、データを国内に留めるといった要件があるケースでは大阪リージョンでの DR が選択肢です。
注意していただきたいのは、東京リージョンで展開されている全てのサービスが大阪リージョンでも展開されているわけではないということです。大阪リージョンで展開されているサービスは以下を参照ください。頻繁に更新されていますので必ず最新情報を参照ください。
AWS リージョン別のサービス表
このサービス表に載っていたとしても注意が必要です。例えば、EC2 は対応しているように思えますが、Graviton2 搭載のインスタンスは大阪リージョンでは使えません。(2022年7月6日時点)
大阪リージョン DR 目的であれば東京リージョンでも Graviton2 以外のインスタンスファミリーを選択する必要があります。
2022年8月9日 一部の Graviton2 インスタンスファミリーが大阪リージョンで利用可能になりました。
AWS Graviton2-based Amazon EC2 C6g, C6gd, and M6gd are now available in additional regions
EC2 以外にも同様のパターンはある可能性がありますので、机上ではなく大阪リージョンで実際に構築してみることをおすすめします。
まとめ
「DR」という言葉は一人歩きします。
発言する人、受け取る人、役割や立場によって解釈が異なります。解像度を合わせておくことが何より大切です。
オンプレミスと同じ意識で「大阪で DR」とは気軽に言えないと思います。
本エントリを執筆していて感じましたが、DR を確実に行うためには元々のアーキテクチャ見直しから始めることも大切です。
EC2 ベースのシステムより、コンテナやサーバーレスを採用したほうが DR の復旧手順が簡略化され所要時間を短縮すると思います。
参考
Disaster Recovery of Workloads on AWS: Recovery in the Cloud
AWS でのディザスタリカバリ (DR) アーキテクチャ、パートI:クラウドでのリカバリの戦略
AWS のディザスタリカバリ (DR) アーキテクチャ、パート II: 迅速なリカバリによるバックアップと復元
AWS のディザスタリカバリ (DR) アーキテクチャ、パート III: パイロットライトとウォームスタンバイ
AWS のディザスタリカバリ (DR) アーキテクチャ、パート IV: マルチサイトアクティブ/アクティブ
【小ネタ】AWSで過去に発生した障害の履歴を確認する方法
AWS リージョン別のサービス表
以上、吉井 亮 がお届けしました。








