
DynamoDB を SQL と同じ感覚で使うと、ハマるポイントを調べてみた
人材育成室 育成メンバーチームで 研修中の はす です。
この間の研修で、「DynamoDBのUpdate APIを、SQLのUPDATE感覚で使うと落とし穴にハマる」 ということを教わりました。
通常は、「対象のアイテムが存在する場合は、更新」 「対象のアイテムがない場合は、エラー」 が出るはずと考えると思います。しかし、実際には、SQL でいうところの Upsert の挙動をします。
つまりは、「対象のアイテムが存在しない場合は、新しく作成する」 のです。
SQL の経験が少ない私でも、これは直感とは違うなと思いました。そこで、他にも似たようにハマるポイントがあるのでは?ということで調べてみました。
DynamoDB を触り始めた方の参考になれば幸いです。
1.PutItem
DynamoDB で 単一アイテムを書き込もうと思ったら、PutItem になります。 これが INSERT かと思いきや、実は UPSERT の挙動になります。
検証
初期状態は以下とします。

次に、既存のid: 1を指定して、新しい属性を追加した場合どうなるでしょうか。
const result = await doc.send(
new PutCommand({
TableName: TABLE_NAME,
Item: { id: "1", age: 20 }, // id: "1" は既存のアイテム
}),
);
SQL の UPDATE の感覚だと、既存の name はそのまま残り age が追加され、以下のようになるはずだと考えると思います。
{
"id": "1",
"name": "太郎",
"age": 20
}
しかし実際には、既存の属性は消されて、age のみになってしまいました。

このように、PutItem では重複した key を指定した場合、エラーになるのではなく、既存のアイテムを削除し、新しいアイテムを生成してしまいます。
解決策
解決策としては ConditionExpression で attribute_not_exists(pk) を明示的に指定することで防げます。
const result = await doc.send(
new PutCommand({
TableName: TABLE_NAME,
Item: { id: "1", name: "太郎" },
ConditionExpression: "attribute_not_exists(id)",
}),
);
もう一度 name を太郎にしてみようとすると、エラーが出て失敗します。
ConditionalCheckFailedException: The conditional request failed
2.UpdateItem
SQL の UPDATE では該当の行がなければ 0 行更新で終わりますが、DynamoDB の UpdateItem は UPSERT として動作します。更新対象のアイテムがない場合は、自動的に新規作成を行うため、意図せず不要なデータが作られる原因になります。
検証
初期状態として、以下のように複数アイテムを用意します。

id: 3 は存在しませんが、age の更新をかけてみます。
const result = await doc.send(
new UpdateCommand({
TableName: TABLE_NAME,
Key: { id: "3" },
UpdateExpression: "SET age = :age",
ExpressionAttributeValues: { ":age": 20 },
ReturnValues: "ALL_NEW",
}),
);
SQL の UPDATE の感覚だと、id: 3 は存在しないので 0 行更新で終わる か、エラーになる かのどちらかだと考えるのが自然です。
しかし実際には、age のみの不正なアイテムが作られてしまいました。
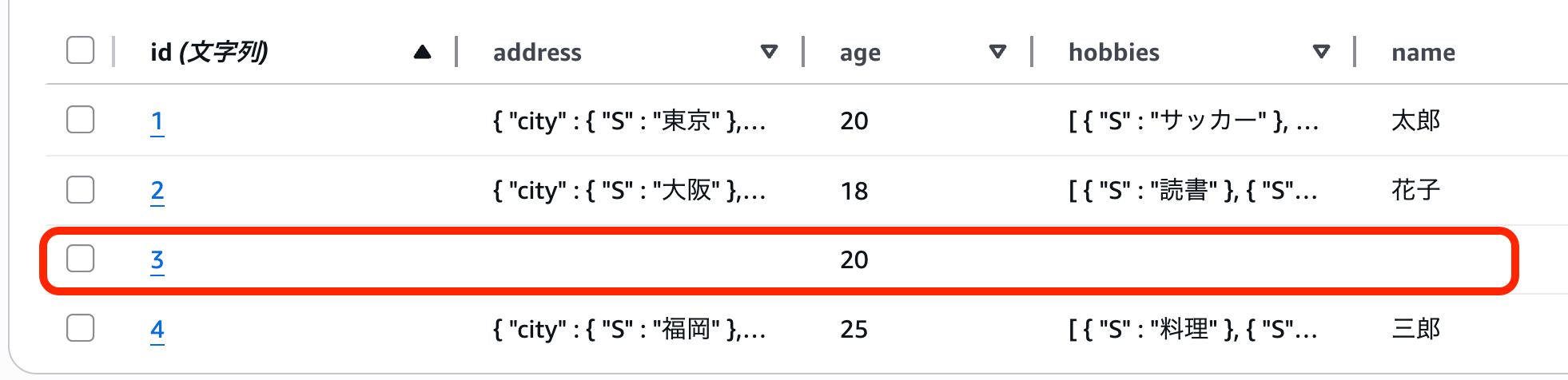
アイテム数が多いようなテーブルでは、簡単には見つけられないため、気づかず不要なデータが生成されてしまう可能性があります。
解決策
解決策としては PutItem の時と同様に、ConditionExpression で attribute_exists(id) を明示的に指定することで防げます。
const result = await doc.send(
new UpdateCommand({
TableName: TABLE_NAME,
Key: { id: "3" },
UpdateExpression: "SET age = :age",
ExpressionAttributeValues: { ":age": 20 },
ReturnValues: "ALL_NEW",
ConditionExpression: "attribute_exists(pk)", // 追加
}),
);
想定通り、存在しないアイテムを指定するとエラーになりました。
ConditionalCheckFailedException: The conditional request failed
3.Query/Scan の FilterExpression
SQL の WHERE はインデックスを使って読み取り量自体を減らしますが、DynamoDB の FilterExpression は異なる挙動になります。FilterExpression は Query / Scan が完了した後、結果を返す前に適用されます。
そのため、読み取りコストはフィルターされた後の量ではなく、フィルター前の Query/Scan 分消費されることになります。
検証
テーブルに以下 6 件のデータが入っている前提で検証します。
[
{ "id": "1", "name": "太郎", "age": 20 },
{ "id": "2", "name": "花子", "age": 18 },
{ "id": "3", "name": "次郎", "age": 22 },
{ "id": "4", "name": "三郎", "age": 25 },
{ "id": "5", "name": "四郎", "age": 20 },
{ "id": "6", "name": "五郎", "age": 22 }
]
Scan に FilterExpression をつけて、Count と ScannedCount、消費した読み取り容量を確認してみます。
const result = await doc.send(
new ScanCommand({
TableName: TABLE_NAME,
FilterExpression: "age = :age",
ExpressionAttributeValues: { ":age": 20 },
ReturnConsumedCapacity: "TOTAL",
}),
);
console.log("Count:", result.Count);
console.log("ScannedCount:", result.ScannedCount);
console.log("ConsumedCapacity:", result.ConsumedCapacity);
出力は以下です。
Count: 2
ScannedCount: 6
ConsumedCapacity: { TableName: 'Users', CapacityUnits: 1 }
Count はフィルター後の件数(age = 20 は 太郎と四郎の 2 件)、ScannedCount はフィルター前に読み取った件数(テーブル全 6 件)です。読み取り容量 (RCU) は ScannedCount ベースで消費される ため、FilterExpression でアイテム数が減ってもコストは下がりません。
Query の場合も挙動は同じで、KeyConditionExpression で読み取ったあとに FilterExpression が後から適用されます(RCU は ScannedCount ベース)。公式ドキュメント(Query FilterExpression) にも明記されています。
A
FilterExpressionis applied after the items have already been read; the process of filtering does not consume any additional read capacity units.
解決策
FilterExpression は RCU は減らせない ものの、クライアントへの通信量や、アプリ側で保持するデータ量(メモリ消費)を減らせる という役割はあります。そのため無意味というわけではなく、不要な属性や行をレスポンスに含めない用途としては有効です。
一方、RCU 自体を抑えたい場合はキー設計側で対応 する必要があります。
- パーティションキー / ソートキーで絞り込めるようにテーブル設計する
- GSI (Global Secondary Index) を使って読み取り対象を絞る
4.LimitパラメーターSQLのLIMIT とは全く違う
SQL の LIMIT は WHERE で絞り込んだ後に個数制限をかけます。
しかし DynamoDB では、FilterExpression で絞り込む前に Limit が適用されます。
例えば、最新の投稿を5件とってこようとした時に、Limit: 5 を指定すると全体のうち 5件から探すような挙動になってしまいます。
検証
検証用に、20歳の人を複数人用意します。
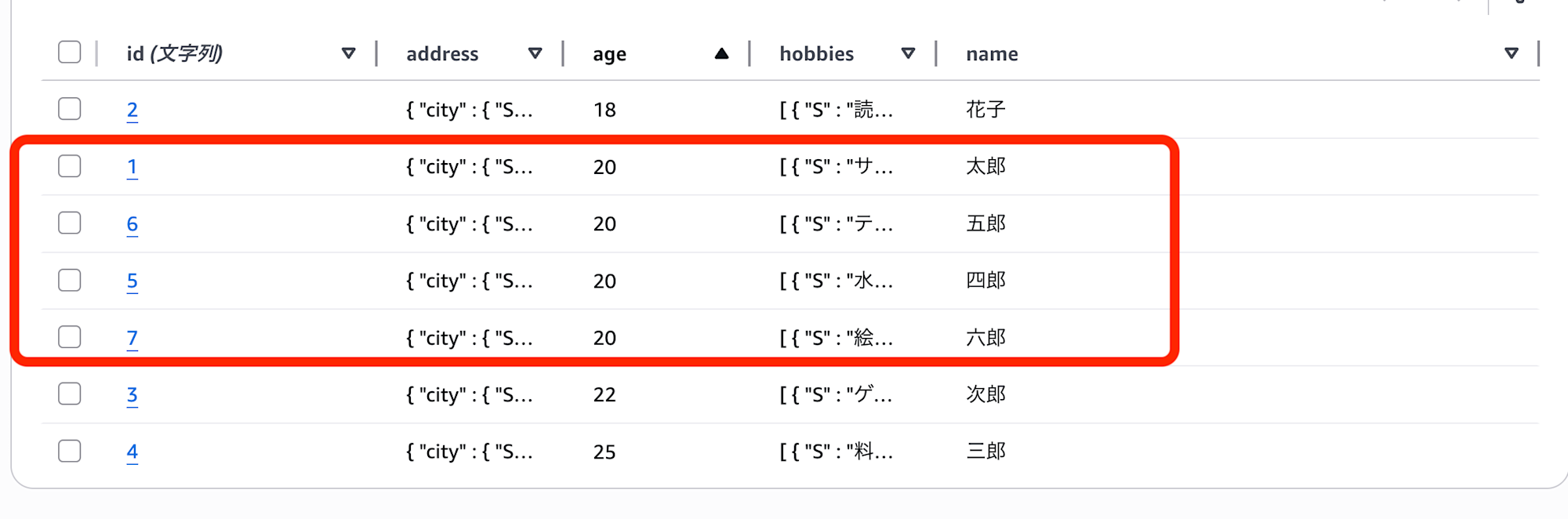
20歳の人を3件取得してみます。
const result = await doc.send(
new ScanCommand({
TableName: TABLE_NAME,
Limit: 3,
FilterExpression: "age >= :age",
ExpressionAttributeValues: { ":age": 20 },
}),
);
SQL の LIMIT の感覚だと、年齢が 20 歳の人に絞り込んでから 3 件取得できるはずだと考えると思います。
[
{ "id": "1", "name": "太郎", "age": 20 },
{ "id": "5", "name": "四郎", "age": 20 },
{ "id": "6", "name": "五郎", "age": 20 }
]
しかし実際には、2 件しか取れていません。
[
{
"hobbies": ["サッカー", "音楽"],
"address": { "city": "東京", "street": "千代田区1-1-1", "postalCode": "123-4567" },
"id": "1",
"name": "太郎",
"age": 20
},
{
"hobbies": ["テニス", "登山"],
"address": { "city": "仙台", "street": "青葉区6-6-6", "postalCode": "678-9012" },
"id": "6",
"name": "五郎",
"age": 20
}
]
このとき result.ScannedCount は 3 でした。
これは、FilterExpression の前に Limit が適用されているためです。
解決策
まず Limit は FilterExpression より先に適用される という仕様を理解した上で使う必要があります。そして、用途によって取るべきアプローチが変わります。
- 「最大 N 件までしか読み取らない」 という読み取りコスト上限を固定したい用途であれば、そのまま
Limit+FilterExpressionで問題ありません。フィルタ後の件数が N より少ない(0 件もあり得る)のは仕様通りの挙動として許容します。 - 「条件に合う N 件を確実に取得したい」 場合(ページネーション UI で「1 ページ 10 件表示」など)は、
LimitとFilterExpressionの組み合わせだけでは不足です。LastEvaluatedKeyを使ってページングしながら、クライアント側で目標件数に達するまで読み進める必要があります。 - 条件に合う上位 N 件を頻繁に取るアクセスパターンがあるなら、パーティションキー / ソートキー / GSI の設計 で対応するのが根本的な解決策です。
詳しくはこちらの記事をご覧ください。
5. BatchWriteItem
SQL の複数行 INSERT / DELETE の感覚で BatchWriteItem を使うと、独自の制約に引っかかります。
- 1 リクエストあたり最大 25 件、合計 16MB まで
- Put / Delete のみサポート(Update は不可)
- ConditionExpression が使えない(PutItem の時のような重複防止はできない)
- 部分的に失敗することがある — 呼び出し自体は成功扱いで戻ってくるが、
UnprocessedItemsに未処理のリクエストが含まれる
検証
25 件を超えるリクエストを送ると、バリデーションエラーになります。
const items = Array.from({ length: 26 }, (_, i) => ({
PutRequest: { Item: { id: `${i + 1}`, name: `user ${i + 1}` } },
}));
const result = await doc.send(
new BatchWriteCommand({
RequestItems: { [TABLE_NAME]: items },
}),
);
console.log("BatchWrite result:", result.UnprocessedItems);
ValidationException: 1 validation error detected: Value '{...}' at 'requestItems' failed to satisfy constraint: Map value must satisfy constraint: [Member must have length less than or equal to 25, Member must have length greater than or equal to 1]
25 件以下で正常に処理されれば、UnprocessedItems は空 object {} で返ります。
const items = Array.from({ length: 25 }, (_, i) => ({
PutRequest: { Item: { id: `${i + 1}`, name: `user ${i + 1}` } },
}));
const result = await doc.send(
new BatchWriteCommand({
RequestItems: { [TABLE_NAME]: items },
}),
);
console.log("BatchWrite result:", result);
BatchWrite result: {
UnprocessedItems: {},
'$metadata': { httpStatusCode: 200, ... }
}
公式ドキュメント によると、UnprocessedItems に中身(失敗した WriteRequest)が入るのは バッチ内の一部だけ失敗した場合(一部の Provisioned throughput 超過または内部処理エラー)だけです。全件失敗時は HTTP 200 ではなく ProvisionedThroughputExceededException などの例外が投げられます。
| ケース | 戻り方 | UnprocessedItems |
|---|---|---|
| 全件成功 | HTTP 200 | {}(空) |
| 一部だけ WCU 超過 / 内部エラー | HTTP 200 | 失敗分の WriteRequest[] が入る |
| 全件 WCU 超過 | 例外 | 見れない |
| バッチ全体 reject(25件超など) | 例外 | 見れない |
中身があれば 呼び出し側で再送する責任がある 点に注意が必要です。
解決策
- 25 件を超える場合は chunk 分割する
UnprocessedItemsが空になるまで 指数バックオフ付きでリトライ する- 条件付き書き込みが必要な場合は
TransactWriteItemsを検討する
指数バックオフ(Exponential Backoff)とは
リトライ間隔を 失敗するたびに指数関数的に伸ばしていく アルゴリズムです。1 回目の失敗後は 1 秒、2 回目は 2 秒、3 回目は 4 秒 ... と待ち時間を延長していきます。
- スロットリング回復を待つ時間を確保できる: 即時リトライだと DynamoDB 側がまだスロットリングしている可能性が高く、また失敗しやすい
- 負荷集中(サンダリングハード)を回避: 複数クライアントが同時に失敗して一斉にリトライするのを防ぐため、ランダムな待ち時間(ジッター)も加えるのが定番
- 無限リトライを防ぐ: リトライ回数の上限を設けてそこで諦める
AWS SDK v3 は HTTP レイヤーの失敗(ThrottlingException や 5xx など、リクエスト自体が失敗したケース)に対しては、デフォルトで指数バックオフ付きのリトライを自動で行います。
ただし、UnprocessedItems は HTTP 200(部分成功) として返るため、SDK は自動で再送しません。呼び出し側で UnprocessedItems を取り出して再送するロジックを実装する必要があります。
「単にリトライすればいいのでは?」と思うかもしれませんが、UnprocessedItems に中身が入る原因の多くは 個別テーブル / パーティションの一時的な throttling です。即時リトライすると DynamoDB 側がまだスロットリング中でまた失敗する可能性が高いため、公式 API リファレンス (BatchWriteItem) と エラーハンドリングガイド (Batch Operations) の両方で、指数バックオフを strongly recommend しています。
If you retry the batch operation immediately, the underlying read or write requests can still fail due to throttling on the individual tables. If you delay the batch operation using exponential backoff, the individual requests in the batch are much more likely to succeed.
BatchWriteItem と TransactWriteItems の違い
| 項目 | BatchWriteItem | TransactWriteItems |
|---|---|---|
| アクション種別 | Put / Delete のみ | Put / Update / Delete / ConditionCheck |
| 最大件数 | 25 件 | 100 アクション |
| 最大サイズ | 16 MB | 4 MB |
条件式 (ConditionExpression) |
使えない | 使える |
| 原子性 | 個々に成功 / 失敗(部分失敗あり) | All or Nothing(1 つでも失敗すれば全体ロールバック) |
| RCU / WCU 消費 | 通常分 | 2 倍 |
ざっくり言うと、BatchWriteItem は「並列に多件書き込みたい」用途、TransactWriteItems は「複数の書き込みを原子的に行いたい」用途 です。条件チェックや原子性が必要なら TransactWriteItems、コスト重視で大量書き込みなら BatchWriteItem を使います。
6. BatchGetItem
こちらも SQL の IN 句一括取得のつもりで使うと制約に引っかかります。
- 1 リクエストあたり最大 100 件、合計 16MB まで
- レスポンスが 16MB を超えた分は
UnprocessedKeysとして返される ConsistentReadはテーブル単位で指定
検証
100 件を超えるキーを投げるとバリデーションエラーになります。
const keys = Array.from({ length: 101 }, (_, i) => ({ id: `${i + 1}` }));
const result = await doc.send(
new BatchGetCommand({
RequestItems: { [TABLE_NAME]: { Keys: keys } },
}),
);
console.log("BatchGet result:", result.UnprocessedKeys);
ValidationException: 1 validation error detected: Value at 'RequestItems.<TableName>.member.Keys' failed to satisfy constraint: Member must have length less than or equal to 100
100 件以下で正常に処理されれば UnprocessedKeys は空 object {} で返ります。公式ドキュメント によると、UnprocessedKeys に中身が入るのは リクエスト自体は HTTP 200 で返ってくるが、一部のアイテムだけ取得しきれなかった 場合です。DynamoDB の設計上、BatchGetItem は「バッチ内の一部のアイテム処理が完了しなかった」ケースを例外ではなく HTTP 200 + UnprocessedKeys という形で返す仕組みになっています。具体的には以下のケースが該当します:
- レスポンスサイズが 16MB を超えた: 上限に収まる分だけ
Responsesに入り、残りがUnprocessedKeysで返る - DynamoDB サービス側の一時的な内部処理エラー: AWS SDK 内部のエラーではなく、DynamoDB サーバー側の一時的な失敗で、一部のアイテムだけ処理されなかった
いずれも リクエスト全体としては HTTP 200(例外は出ない)なので、SDK は自動リトライせず、呼び出し側で UnprocessedKeys を見て再送する必要があります。
一方、全テーブルで provisioned throughput 不足の場合は HTTP 200 ではなく ProvisionedThroughputExceededException が投げられます(BatchWriteItem と同じ設計思想)。
解決策
- 100 件を超える場合は chunk 分割する
UnprocessedKeysが空になるまで指数バックオフ付きでリトライする(詳細はセクション 5 参照)ProjectionExpressionで取得属性を絞り、レスポンスサイズを抑える- 強整合性が必要なければ
ConsistentReadは既定のまま(trueにすると RCU 消費が 2 倍)
7. Query / Scan の Select:COUNT
SQL の COUNT(*) は統計情報やインデックスで高速化されることがありますが、DynamoDB の Select: "COUNT" は 項目を返さないだけで、読み取りコストはフル発生 します(Query / Scan どちらも同じ挙動)。
- 内部的には該当アイテムを全件スキャンしてから件数だけ返す
- 1MB を超えると
LastEvaluatedKeyでページングを継続する必要がある
検証
Select: "COUNT" を指定して、消費した RCU を確認してみます。
同じテーブルに対して、項目を全部取る Scan(Select 省略 = デフォルトの ALL_ATTRIBUTES)と 件数だけ数える Scan(Select: "COUNT")を実行し、消費 RCU (CapacityUnits) を比較してみます。
const all = await doc.send(
new ScanCommand({
TableName: TABLE_NAME,
ReturnConsumedCapacity: "TOTAL",
}),
);
console.log("--- Scan (Select: ALL_ATTRIBUTES) ---");
console.log("Items length:", all.Items?.length);
console.log("ScannedCount:", all.ScannedCount);
console.log("CapacityUnits:", all.ConsumedCapacity?.CapacityUnits); // ← 比較ポイント
const count = await doc.send(
new ScanCommand({
TableName: TABLE_NAME,
Select: "COUNT",
ReturnConsumedCapacity: "TOTAL",
}),
);
console.log("--- Scan (Select: COUNT) ---");
console.log("Count:", count.Count);
console.log("ScannedCount:", count.ScannedCount);
console.log("CapacityUnits:", count.ConsumedCapacity?.CapacityUnits); // ← 比較ポイント
出力は以下です(本プレイグラウンドのテーブルに 25 件入っている状態で実行):
--- Scan (Select: ALL_ATTRIBUTES) ---
Items length: 25
ScannedCount: 25
CapacityUnits: 2
--- Scan (Select: COUNT) ---
Count: 25
ScannedCount: 25
CapacityUnits: 2
どちらも CapacityUnits: 2 で同じ です。つまり、Select: "COUNT" を指定して項目を返さないようにしても、消費 RCU は項目をすべて取ってきた場合とまったく変わりません。コスト削減効果はなく、「項目をクライアントに返さない」だけの機能 だと分かります。
COUNT- Returns the number of matching items, rather than the matching items themselves. Note that this uses the same quantity of read capacity units as getting the items, and is subject to the same item size calculations.
解決策
- 集計テーブルを別途用意し、DynamoDB Streams で同期する: 元テーブルへの変更をトリガーに集計側を更新するパターン。ただし Streams は 別途課金 されるので、コストと相談して採用を判断する必要があります
- 概算で良ければ
DescribeTableのItemCountを使う: 対象テーブルのメタデータに含まれる近似値(約 6 時間ごと更新)。別テーブルを作るわけではなく、追加コストなしで取得できます
8. TransactWriteItems
SQL の BEGIN; ... COMMIT; では件数・サイズの制限はほぼなく、同一行の複数更新もネストもでき、追加コストも発生しません。
一方、DynamoDB の TransactWriteItems には以下のような制限があります。
- 1 リクエストあたり最大 100 アクション、合計 4MB まで
- 1 つでも条件 NG なら全アクションがロールバック(All or Nothing)
- 同一アイテムに対する複数アクションは不可
- 消費する RCU / WCU は通常の 2 倍
- エラー時は
TransactionCanceledException.CancellationReasonsで原因を確認する
検証
片方の条件が満たされないケースで、全体がロールバックされることを確認してみます。
await doc.send(
new TransactWriteCommand({
TransactItems: [
{
Put: {
TableName: TABLE_NAME,
Item: { id: "1001", name: "マイク" },
ConditionExpression: "attribute_not_exists(id)",
},
},
{
Update: {
TableName: TABLE_NAME,
Key: { id: "999" },
UpdateExpression: "SET age = :age",
ExpressionAttributeValues: { ":age": 30 },
ConditionExpression: "attribute_exists(id)",
},
},
],
}),
);
実行すると TransactionCanceledException が投げられ、CancellationReasons フィールドで各アクションの結果を確認できます。
TransactionCanceledException: Transaction cancelled, please refer cancellation reasons for specific reasons [None, ConditionalCheckFailed]
...
CancellationReasons: [
{ Code: 'None' },
{ Code: 'ConditionalCheckFailed', Message: 'The conditional request failed' }
]
1 つ目の Put(id: "1001"、attribute_not_exists(id))は 条件を満たしている ので Code: 'None'、2 つ目の Update(id: "999"、attribute_exists(id))は条件を満たさないので ConditionalCheckFailed。それでも 全体がキャンセル扱いになり Put も書き込まれていません。これが All or Nothing の挙動です。
公式ドキュメント によると、CancellationReasons は TransactItems と同じ順序で並び、成功したアクションは Code: 'None', Message: null、失敗したアクションは ConditionalCheckFailed / TransactionConflict / ProvisionedThroughputExceeded / ThrottlingError / ItemCollectionSizeLimitExceeded / ValidationError などの Code が入ります。1 つでも失敗があれば残りのアクションも含めて全体がロールバック されます。
設計指針
- 原子性が本当に必要な操作だけ
TransactWriteItemsにする(RCU / WCU 2 倍消費を抑える)。独立な書き込みはBatchWriteItemや単発 API に逃がす - 100 件 / 4MB の上限を超えそうなケースでは、Saga パターンなど 分散トランザクション のアプローチに置き換える(TransactWriteItems では扱えないケースの代替)
Saga パターンと分散トランザクションとは
分散トランザクション: 複数のデータベース / サービスにまたがる処理を、あたかも 1 つのトランザクションのように扱う仕組み。DynamoDB の TransactWriteItems は 1 リクエストに収まる分は原子的に処理してくれますが、件数・サイズ上限を超える場合はアプリ層で分散トランザクションを組む必要があります。
Saga パターン: 分散トランザクションの代表的な設計パターン。「一連のローカルトランザクションの連鎖」として実装し、途中のステップが失敗したら 補償トランザクション(Compensating Transaction) を順に実行して巻き戻します。
例: 注文処理で「在庫確保 → 決済 → 発送手配」の 3 ステップがあるとき、決済が失敗したら「在庫確保を取り消す」補償処理を走らせて巻き戻す、といった流れです。
使う時の注意点
- リトライ時の二重実行を防ぐために
ClientRequestTokenで冪等性を持たせる
リトライ時の二重実行とClientRequestToken
TransactWriteItems の All or Nothing は「1 回のリクエスト内」の原子性 を保証するもので、「同じリクエストが複数回送られる」ケースまではカバーしません。
例えばサーバー側では成功していたのに、ネットワーク障害などでレスポンスがクライアントに届かず、クライアントがリトライを投げると、同じ内容の TransactWriteItems が 2 回実行されて重複適用される 恐れがあります(例: 注文確定を 2 回投げると在庫が 2 回引かれる)。1 回目も 2 回目も個別には全成功で矛盾なく終わりますが、結果として重複してしまいます。
ClientRequestToken を指定すると、同じトークンで 10 分以内に送られた同一内容のリクエストは「重複」と判定され、1 回分だけ実行されます(冪等性保証)。リトライ時の二重実行を防ぐための仕組みです。
まとめ
今回 DynamoDB の API を触ってみて、SQL の感覚とは異なる挙動があることを学びました。API ごとに独自の制約やクセがあり、「SQL ではこう動いたから」という前提で使ってしまうと、意図しない書き込みや無駄な読み取りコストにつながってしまいます。
私と同じように DynamoDB を触り始めた方の参考になれば嬉しいです。
次回は、なぜ DynamoDB がこのような API 設計になったのか、その歴史的な背景や経緯を紐解いていけたらと思います。









