
AWS Entity Resolution のルールベースマッチングを試してみました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。サイロ化した複数システムのテーブルのレコードを紐づけたり、重複レコードを削除したいというニーズはデータ分析の現場では共通の課題です。本日は、AWS Entity Resolution のルールベースマッチングを下記のワークショップの内容を参考に試してみます。
なお、機械学習を用いたマッチングのブログは以下になります。
AWS Entity Resolution のルールベースマッチング とは
AWS Entity Resolution とは、複数のデータストア間の関連レコードの照合や重複したレコードを削除するためのフルマネージドサービスです。
AWS Entity Resolution のルールベースマッチングとは、一意のIDを探すためのフィールドの組み合わせであるスキーママッピングに基づき、各行を明確に識別するための必須フィールドを自動的に探索する方式です。
スキーママッピングとは、マッチングする入力フィールドとその組み合わせを定義したものです。例えば、氏名は、苗字と名前から成りますので、苗字と名前という入力フィールドを氏名というグループにマッピングします。入力フィールドをグループ化することで、マッチングの精度を高め、必須フィールドの探索数を効果的に削減します。
ルールベースマッチングの流れ
今回は、ルールベースマッチング機能を用いて、重複したレコードを削除します。その手順は以下のとおりです。
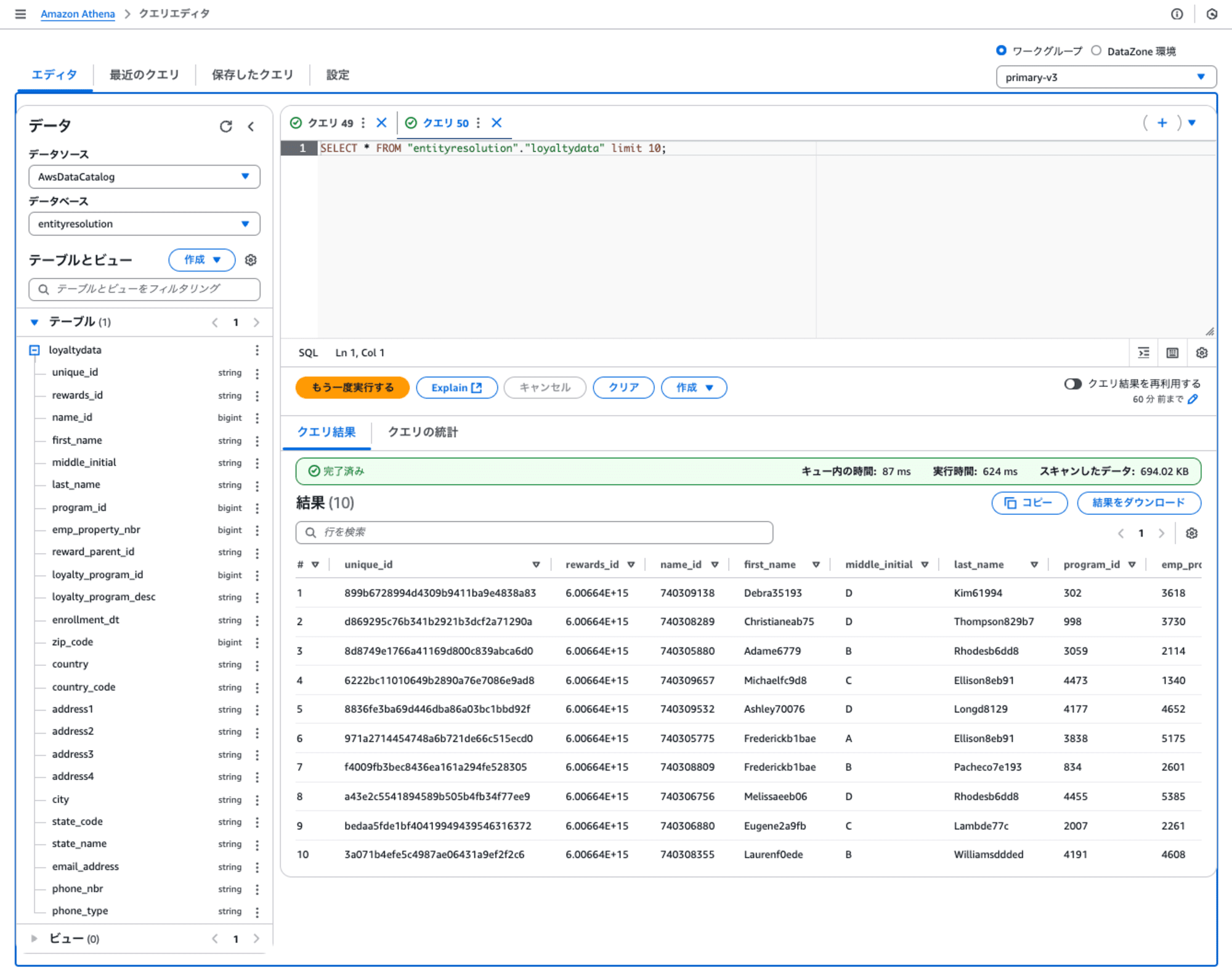
0. データの準備
重複したレコードを含むサンプルデータをS3バケットにコピーして、Glueテーブルとして作成します。そのGlueテーブルは、Athenaからデータを参照できます。
1. スキーママッピング
AWS Entity Resolution のコンソールでスキーママッピングを行いました。これは、入力データのフィールドとEntity Resolutionの属性をマッピングします。
2. マッチングワークフローの作成
マッチングワークフローでは、スキーママッピングを用いて、スキーママッチングを実行するためのワークフローを生成します。
3. マッチングの実行
マッチングを実行すると、重複したレコードが削除されたサンプルデータがS3バケット作成されます。Glueテーブルとして作成して、その結果のデータをAthenaから参照できます。
ブログ「AWS Entity Resolution の機械学習を用いたマッチングを試してみました」を既にご覧の方は、「2. マッチングワークフローの作成」から読み進めてください。
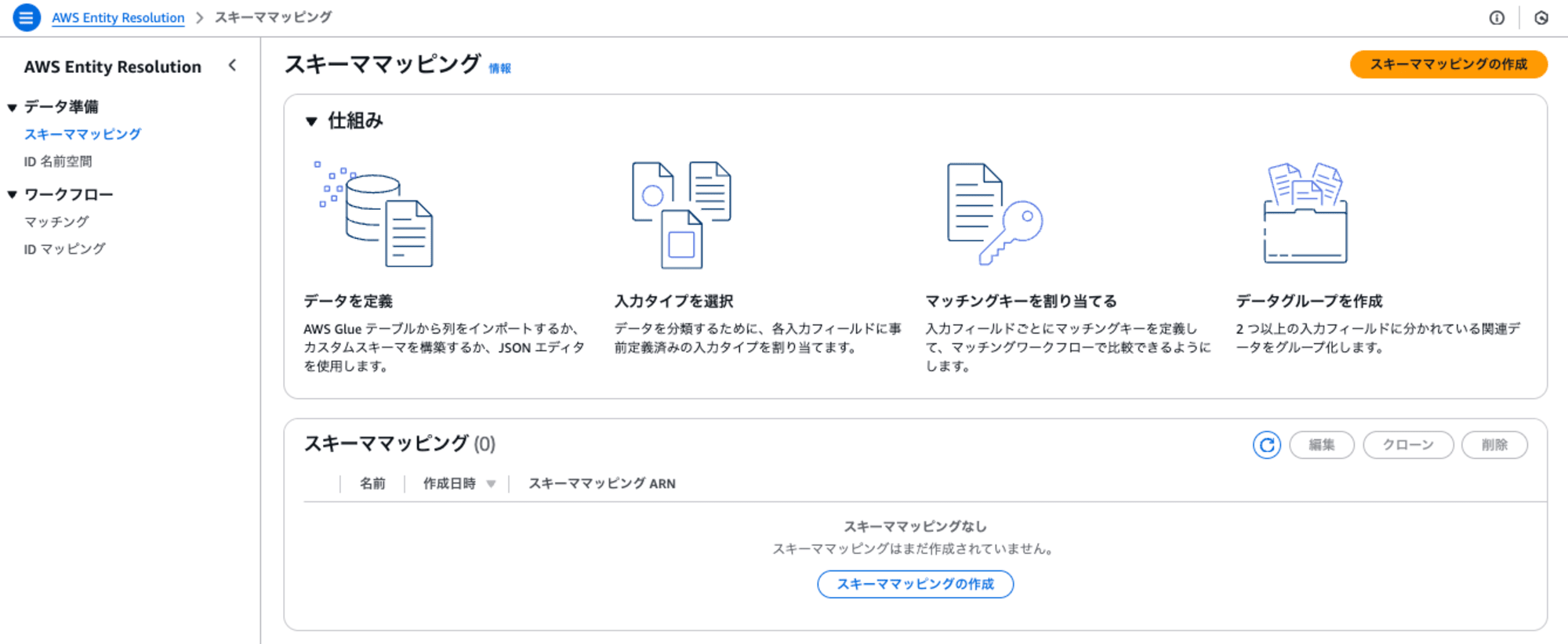
1. スキーママッピング
AWS Entity Resolution のメニューのスキーママッピングをクリックして、 [スキーママッピングの作成] を押します。
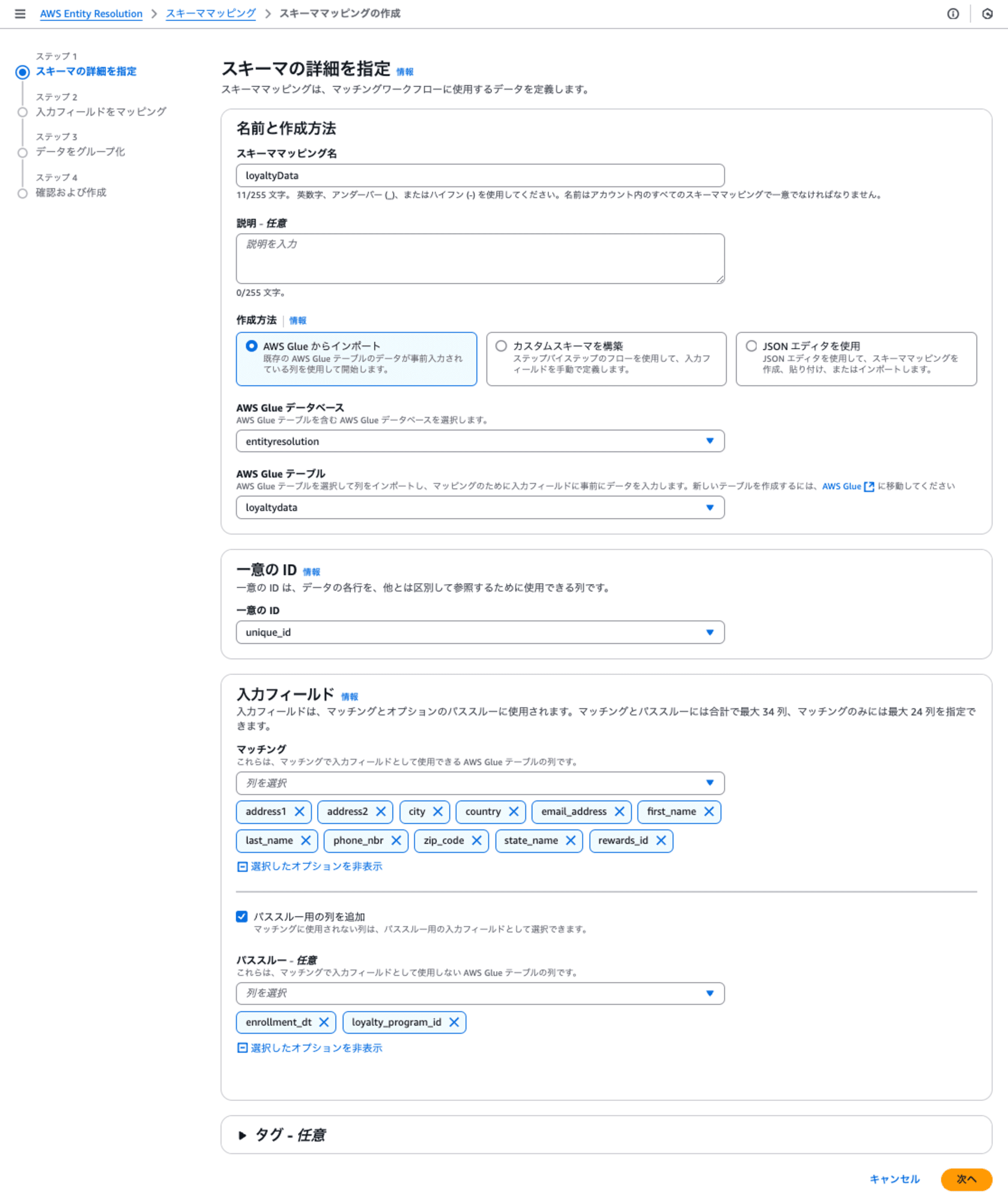
ステップ1: スキーマの詳細を指定
- スキーママッピング名は、「loyaltyData」と設定しました。
- 作成方法は、「AWS Glue からインポート」を選択して、AWS Glue データベースとテーブルを指定します。
- 一意のIDには、各レコードを一意に決めるフィールド「unique_id」を指定します。
- 入力フィールドのマッチングは、各行を明確に識別するための必須フィールドになる可能性のあるフィールドを指定します。
- 入力フィールドのパススルーは、マッチングに使わないけれども出力出力したいフィールドを指定します。
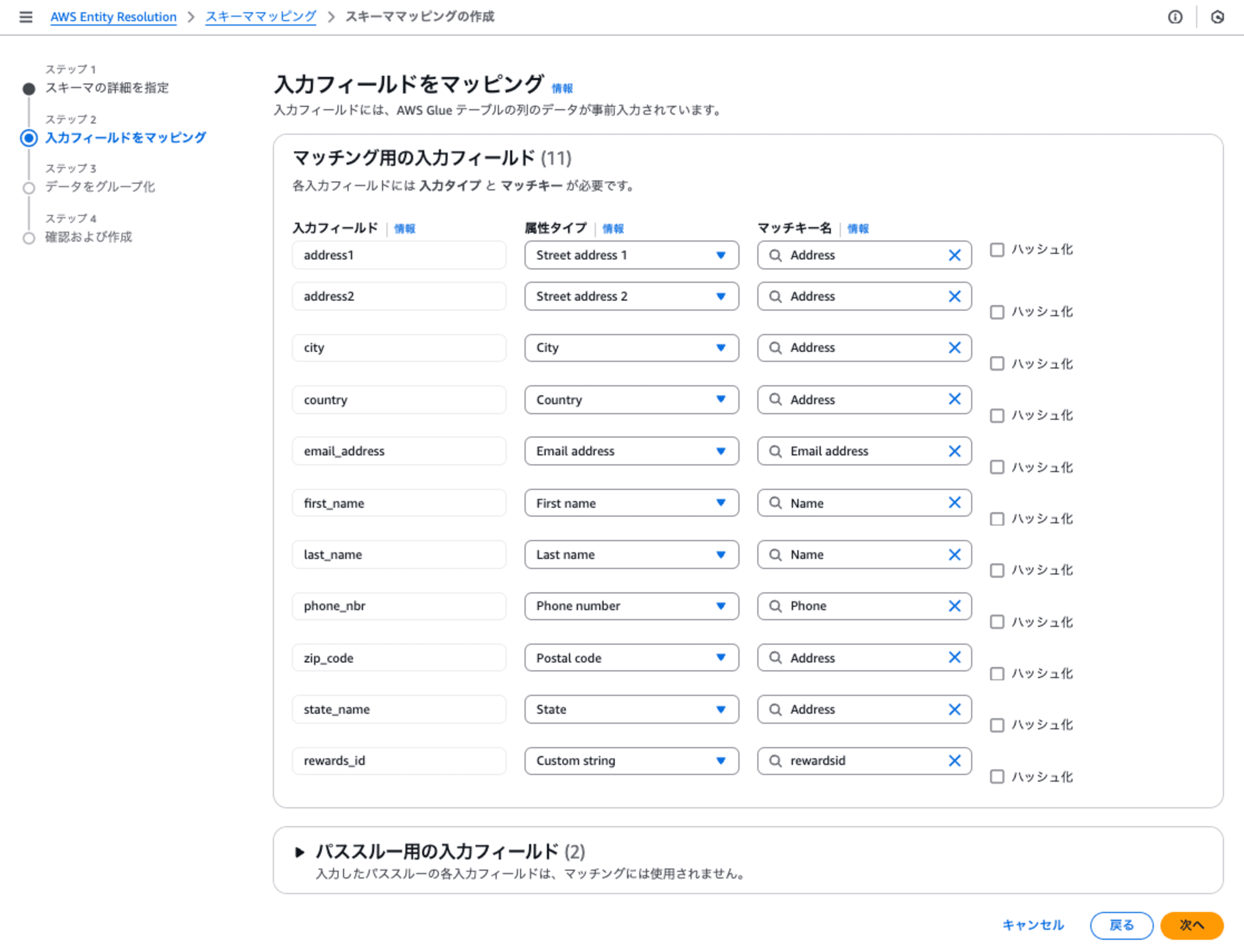
ステップ2: 入力フィールドをマッピング
入力フィールドはGlueテーブルのカラム名にあたり、入力フィールドに属性タイプ(以下のプルダウン)と一覧から選択すると、自動的にマッチキー名が設定されます。
もし、属性タイプの中にない場合はCustom String を選択することで、任意のマッチングキーを入力することができます。
ハッシュ化は、ハッシュ関数(単方向の関数)を用いて難読化する場合に指定します。
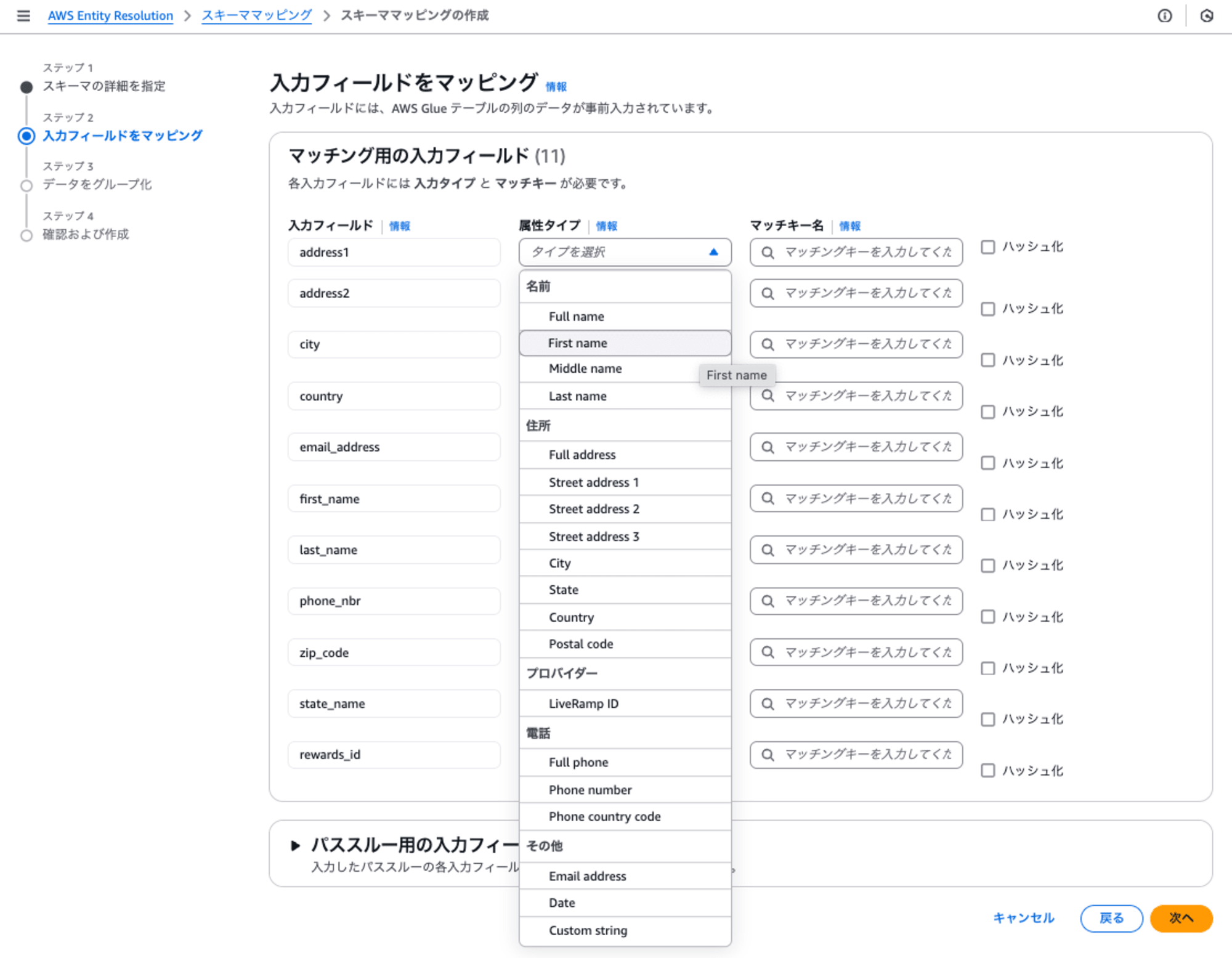
下記の通り、入力フィールドに対して属性タイプを設定しました。一番最後のrewards_idのみ、属性タイプにCustom String を選択して、rewardsidという任意のマッチキー名を指定しました。
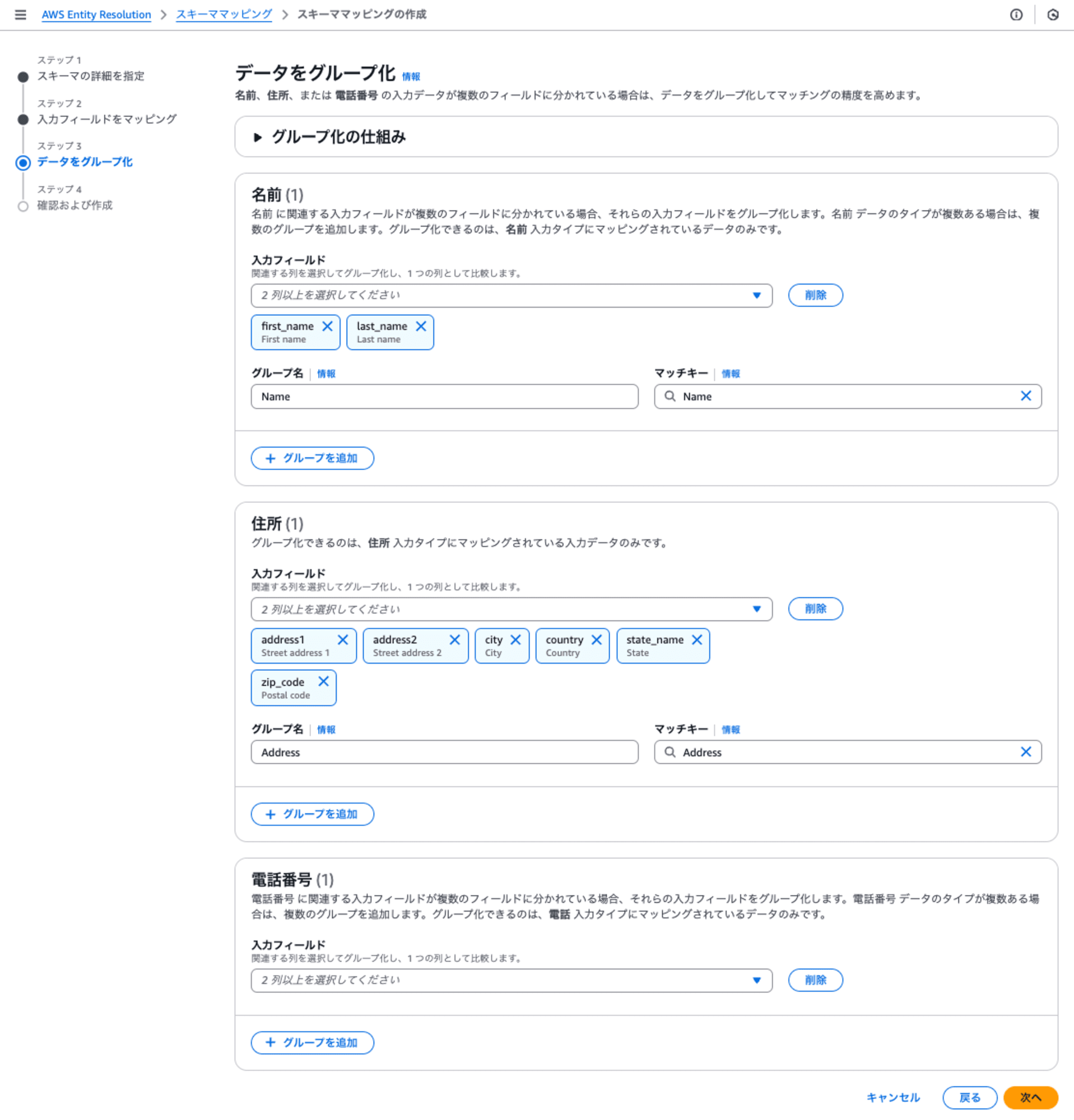
ステップ3: データをグループ化
名前、住所、または 電話番号 の入力データが複数のフィールドに分かれている場合は、データをグループ化してマッチキーを作ります。
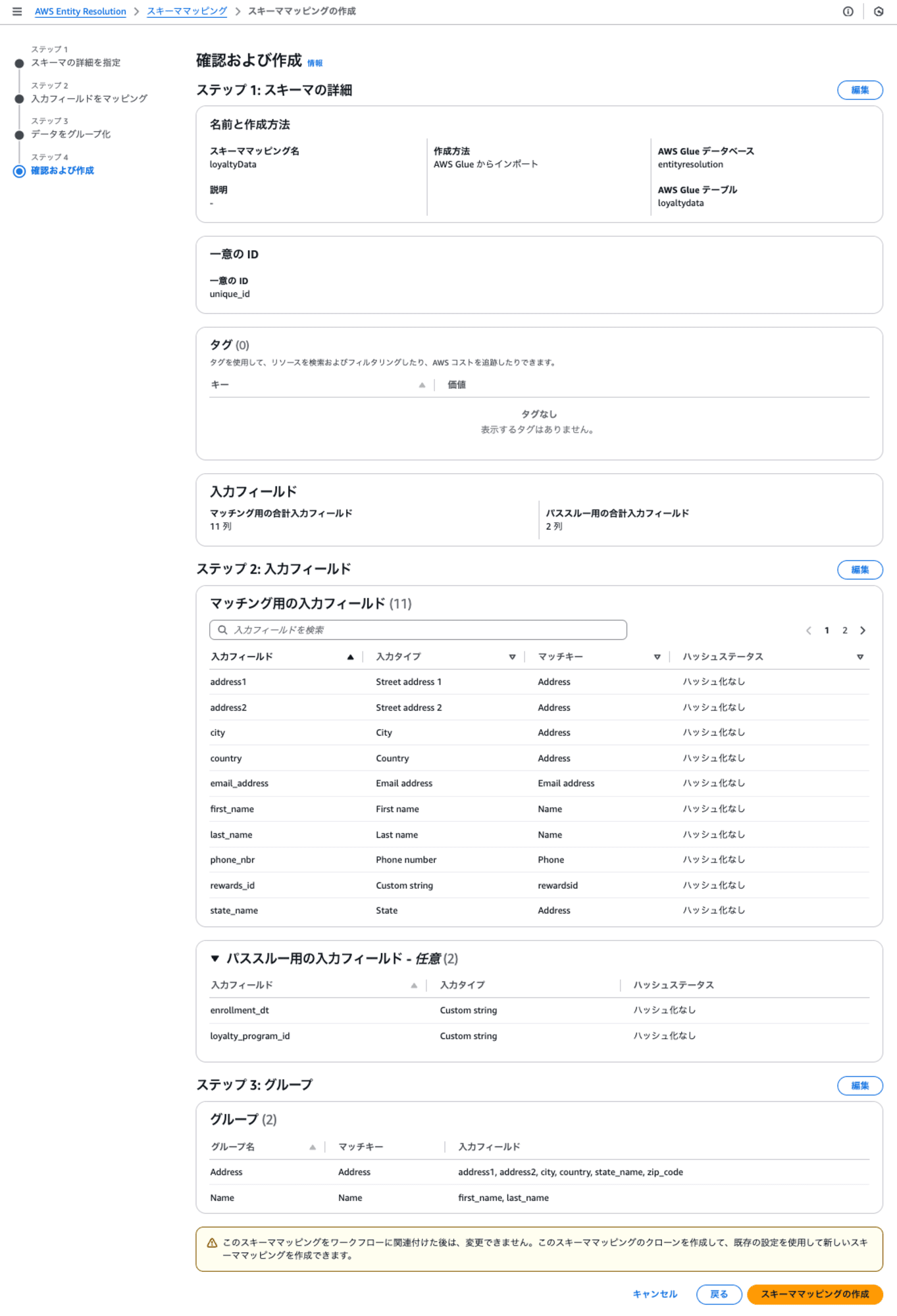
ステップ4: 確認および作成
最終確認で、[スキーママッピングの作成]をクリックすると作成されます。
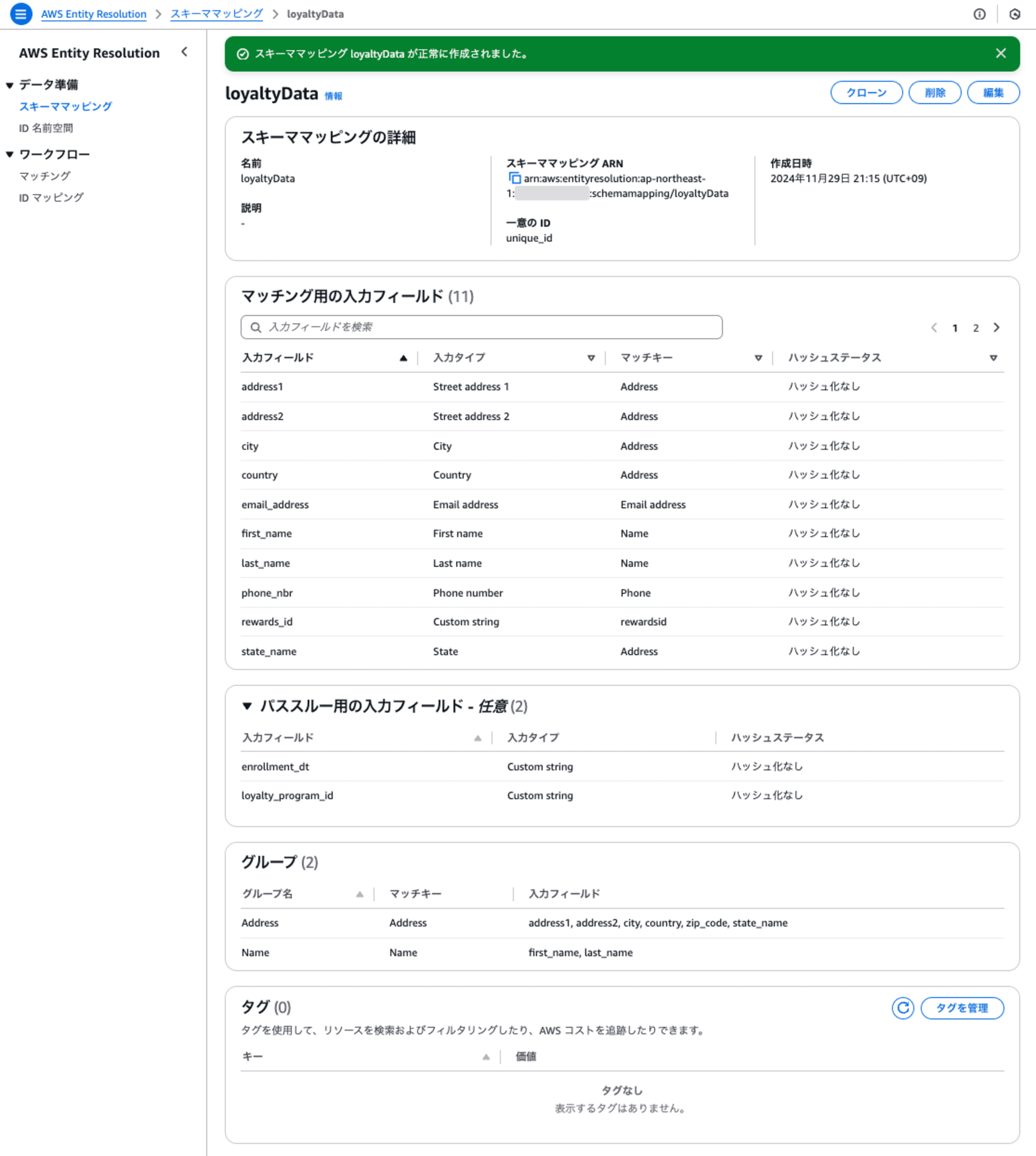
作成された結果は以下のとおりです。
2. マッチングワークフローの作成
AWS Entity Resolution のメニューのマッチングをクリックして、 [マッチングワークフローの作成] を押します。
ステップ1: マッチングワークフローの詳細を指定
- マッチングワークフロー名は、「loyaltyData_rule」と設定しました。
- データ入力は、「AWS Glue からインポート」を選択して、AWS Glue データベースとテーブルを指定します。スキーママッピングはさきほど作成したloyaltyDataを指定します。
- サービスアクセスで、サービスロール名を指定しますが、まだ作成していないため自動的に作成します。
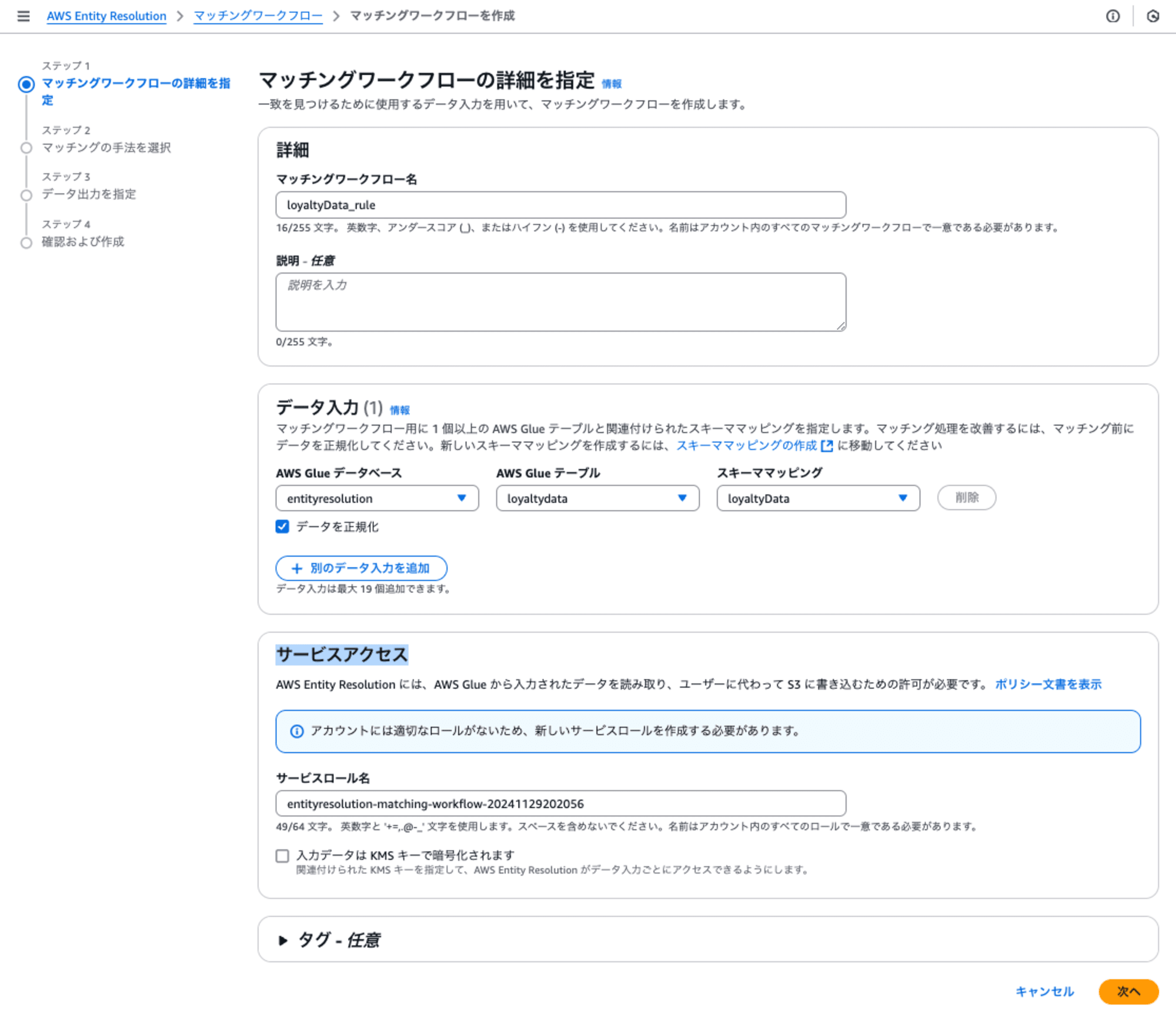
ステップ2: マッチングの手法を選択
ここでは特に変更せずに次に進みます。
今回のマッチング方法のresolutionタイプは、ルールベースマッチングを選択します。実行頻度は一度きりなので手動ままです。
ステップ3: データ出力を指定
- データの出力先と形式のAmazon S3 の場所は、S3 URI にS3バケットのURIを指定します。
- システムの生成出力は、MatchIDとどのMatchRuleに適合しているかが出力される。ハッシュ化を指定した場合はHashingProtocolに変換に用いたハッシュアルゴリズムが出力される。
- データ出力は、出力されるフィールドが表示されます。
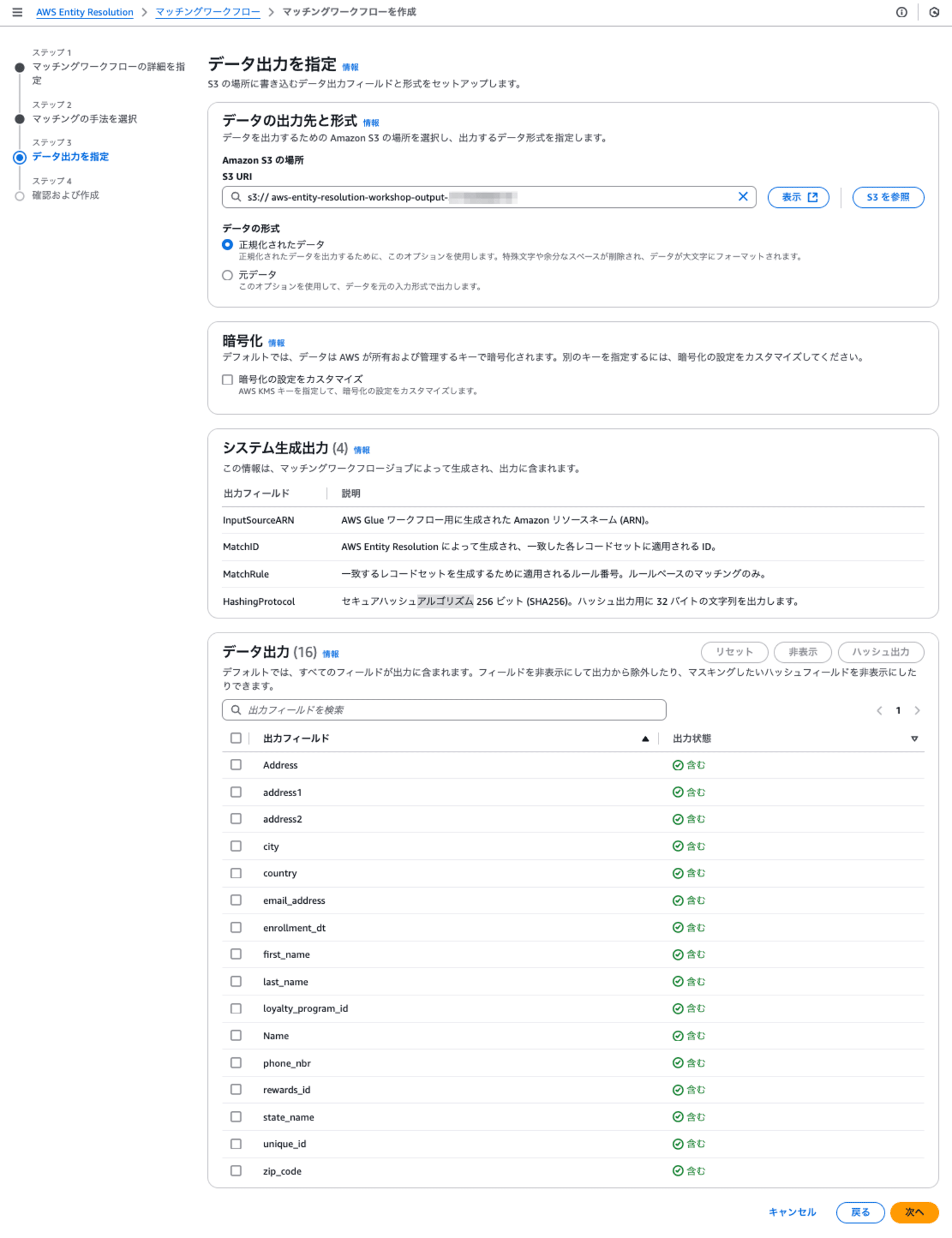
ステップ4: 確認および作成
最終確認画面です。[作成して実行]ボタンを押します。
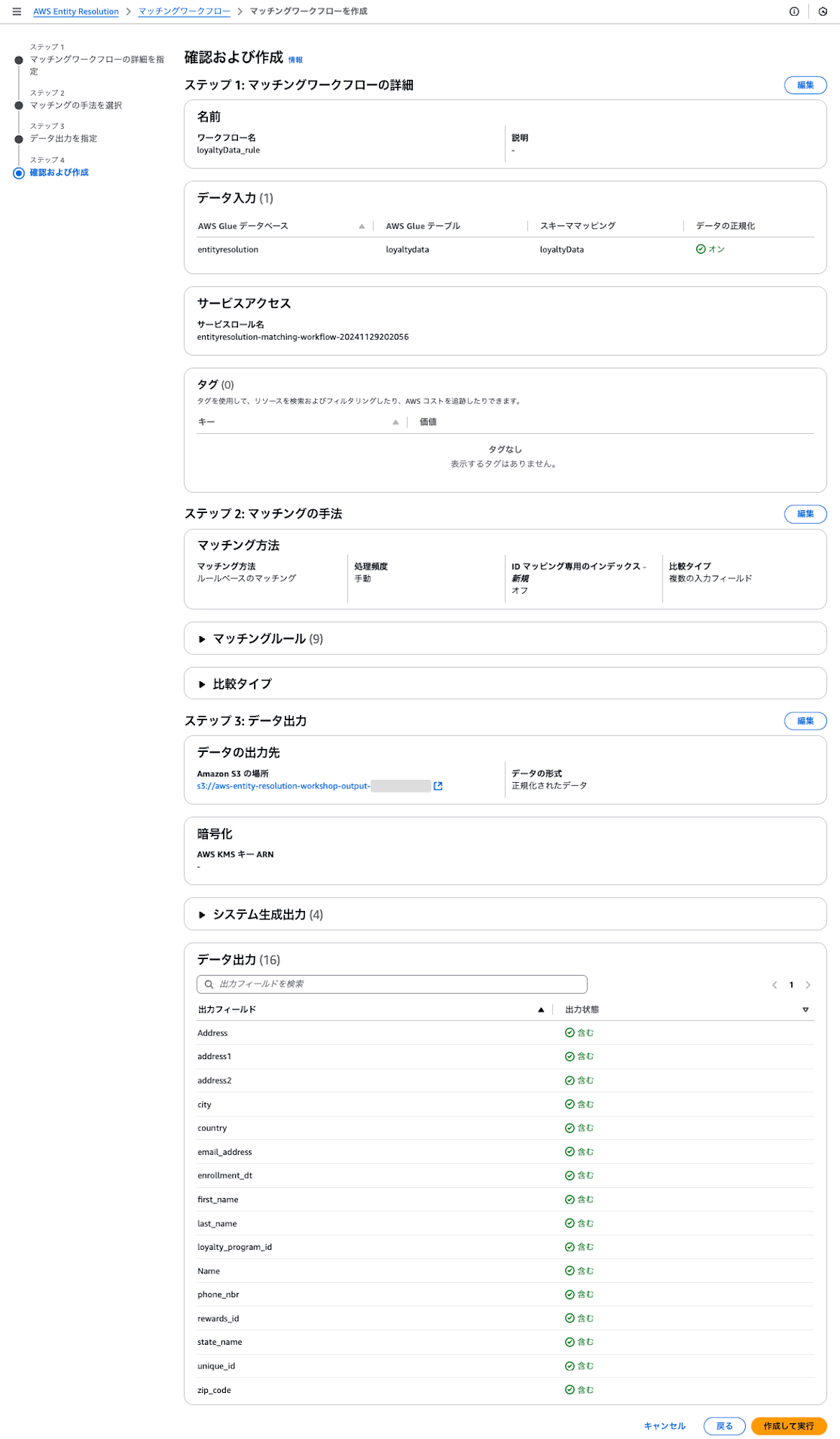
なお、上記の ▶ マッチングルール の3角部分をクリックして、開くと以下のように自動生成されたマッチングルールが確認できます。

[作成して実行]ボタンを押すと実行が開始されます。
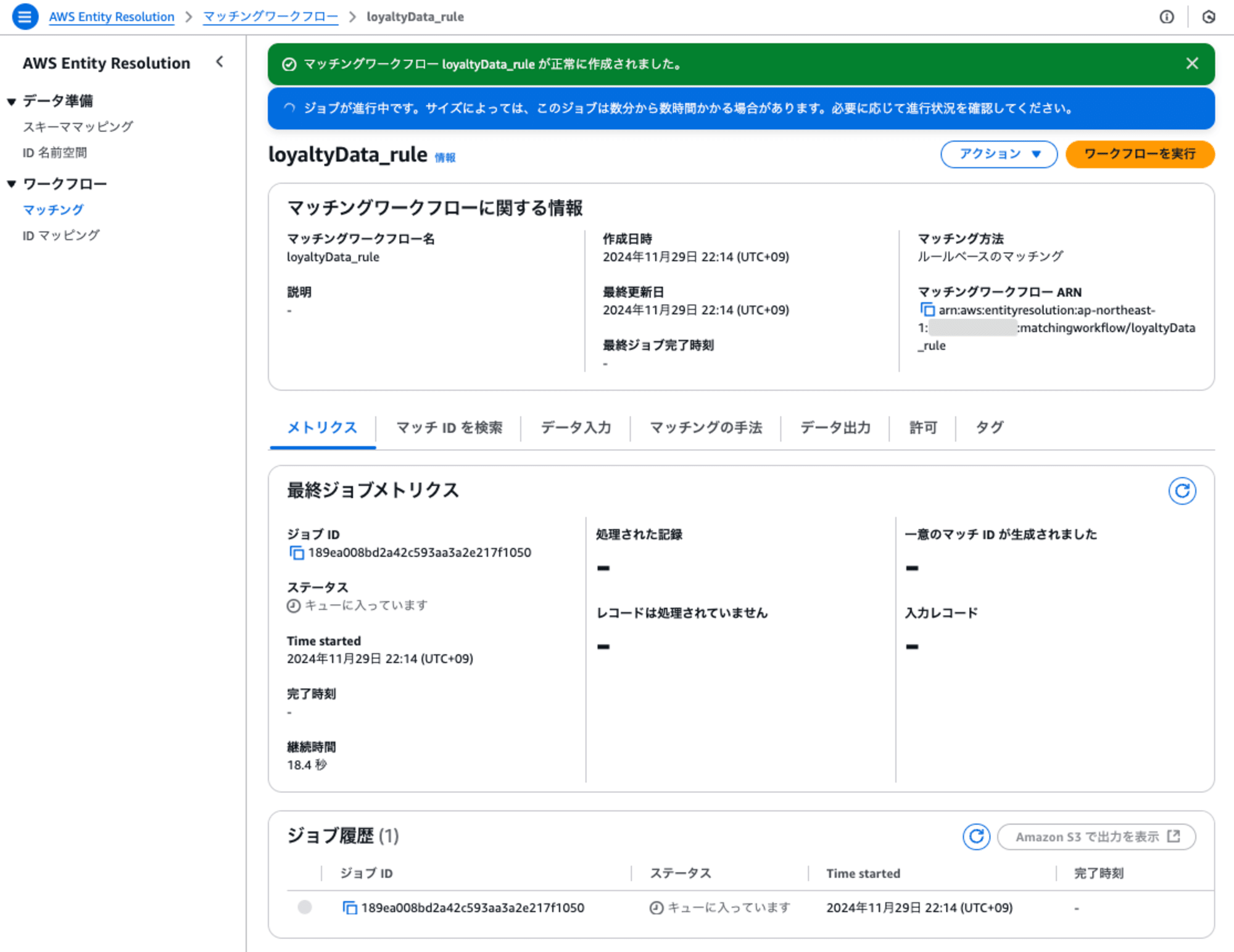
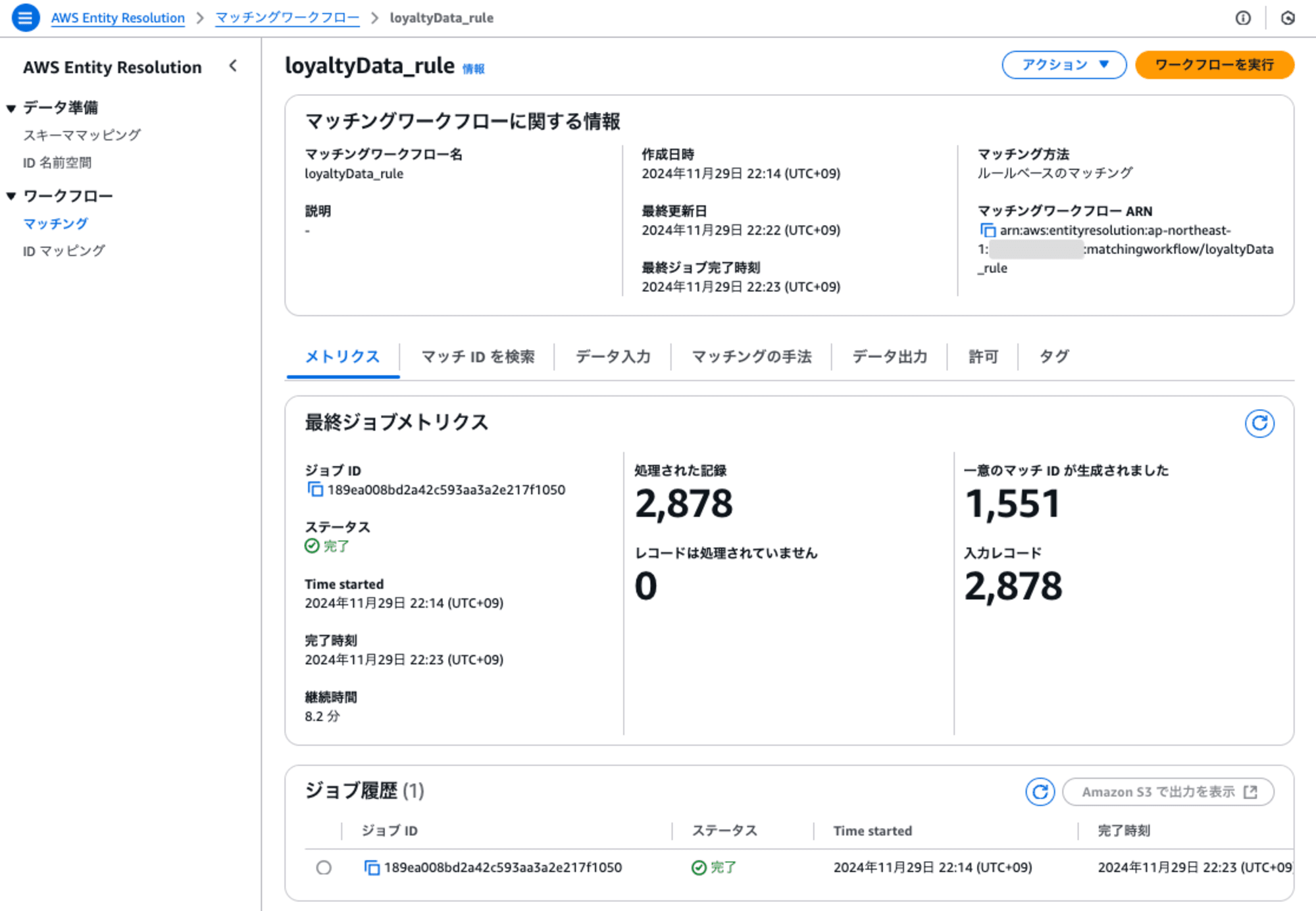
3. マッチングの実行
マッチングワークフローが実行開始してから10分程度で完了しました。入力レコード2878に対して、一意のマッチIDが生成されたレコードが1551でした。
出力ファイルをGlueテーブルとして登録し、Athenaで結果を確認します。ここで実行しているクエリは、Rule1の条件にしたがってmatchidのレコードを参照しています。matchidが同じレコードは、カラムの内容が同じ、違うなどを確認できます。
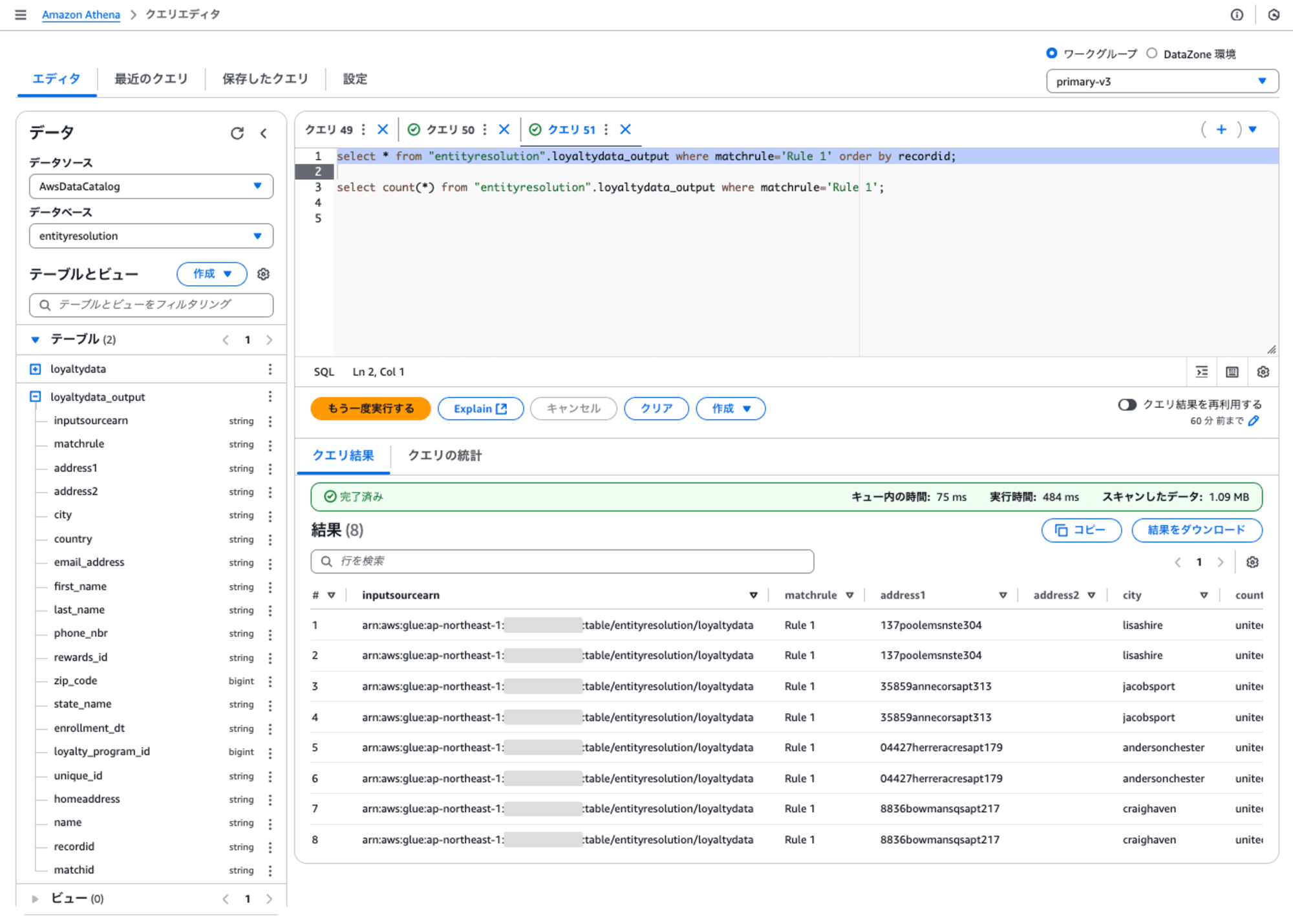
(再掲)Rule1の条件のマッチングキーは以下のとおりです。
最後に
AWS Entity Resolutionのルールベースマッチング機能は、データ分析における重要な課題である重複レコードの削除や関連レコードの照合を効率的に解決するサービスです。スキーママッピングによる入力フィールドと属性タイプの柔軟なマッピング、そしてデータのグループ化による精度向上です。
本来であればマッチングルールを自分で考え、様々なパターンを検証する必要がありますが、このプロセスを自動化できるのは心強い機能です。そして、何よりも直感的に安心して使える点が好印象です。今回は、手動実行ですが、定期実行も可能です。
AWS Entity Resolutionは、企業のデータ管理と分析の質を大きく向上させる可能性があり、データドリブンな意思決定を支援する重要なツールとして期待されます。
合わせて読みたい










