
AWS Entity Resolution の機械学習を用いたマッチングを試してみました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。先日に引き続き、AWS Entity Resolution の機械学習を用いたマッチングを下記のワークショップの内容を参考に試してみます。
先日のルールベースマッチングのブログは以下になります。
AWS Entity Resolution の機械学習を用いたマッチングとは
AWS Entity Resolution とは、複数のデータストア間の関連レコードの照合や重複したレコードを削除するためのフルマネージドサービスです。
機械学習を用いたマッチングは、入力されたすべてのデータ間でレコードを照合しようとする事前設定されたプロセスです。機械学習ベースのマッチングワークフローを使用すると、機械学習モデルを活用して平文データを比較し、幅広いマッチングを見つけることができます。
このアプローチでは、従来の厳密なルールベースのマッチングよりも柔軟で効果的な照合が可能となります。機械学習モデルは、データの微妙な類似性やパターンを認識し、人間が事前に定義したルールでは捉えきれない可能性のある関連性を見出すことができます。
機械学習を用いたマッチングの流れ
今回は、機械学習を用いたマッチング機能を用いて、重複したレコードを削除します。その手順は以下のとおりです。
0. データの準備
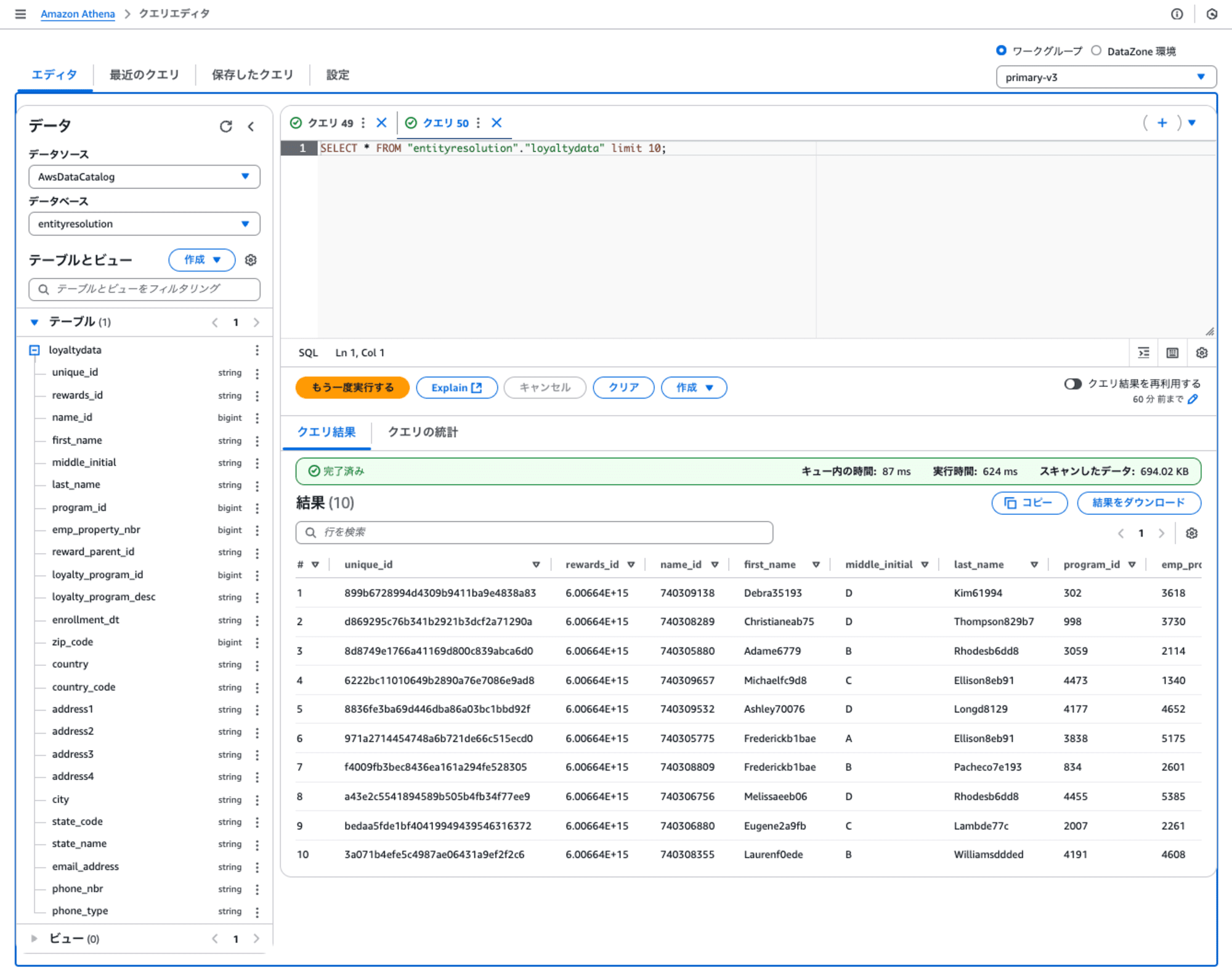
重複したレコードを含むサンプルデータをS3バケットにコピーして、Glueテーブルとして作成します。そのGlueテーブルは、Athenaからデータを参照できます。
1. スキーママッピング
AWS Entity Resolution のコンソールでスキーママッピングを行いました。これは、入力データのフィールドとEntity Resolutionの属性をマッピングします。
2. マッチングワークフローの作成
マッチングワークフローでは、スキーママッピングを用いて、スキーママッチングを実行するためのワークフローを生成します。
3. マッチングの実行
マッチングを実行すると、重複したレコードが削除されたサンプルデータがS3バケット作成されます。Glueテーブルとして作成して、その結果のデータをAthenaから参照できます。
ブログ「AWS Entity Resolution のルールベースマッチングを試してみました」を既にご覧の方は、「2. マッチングワークフローの作成」から読み進めてください。
1. スキーママッピング
AWS Entity Resolution のメニューのスキーママッピングをクリックして、 [スキーママッピングの作成] を押します。
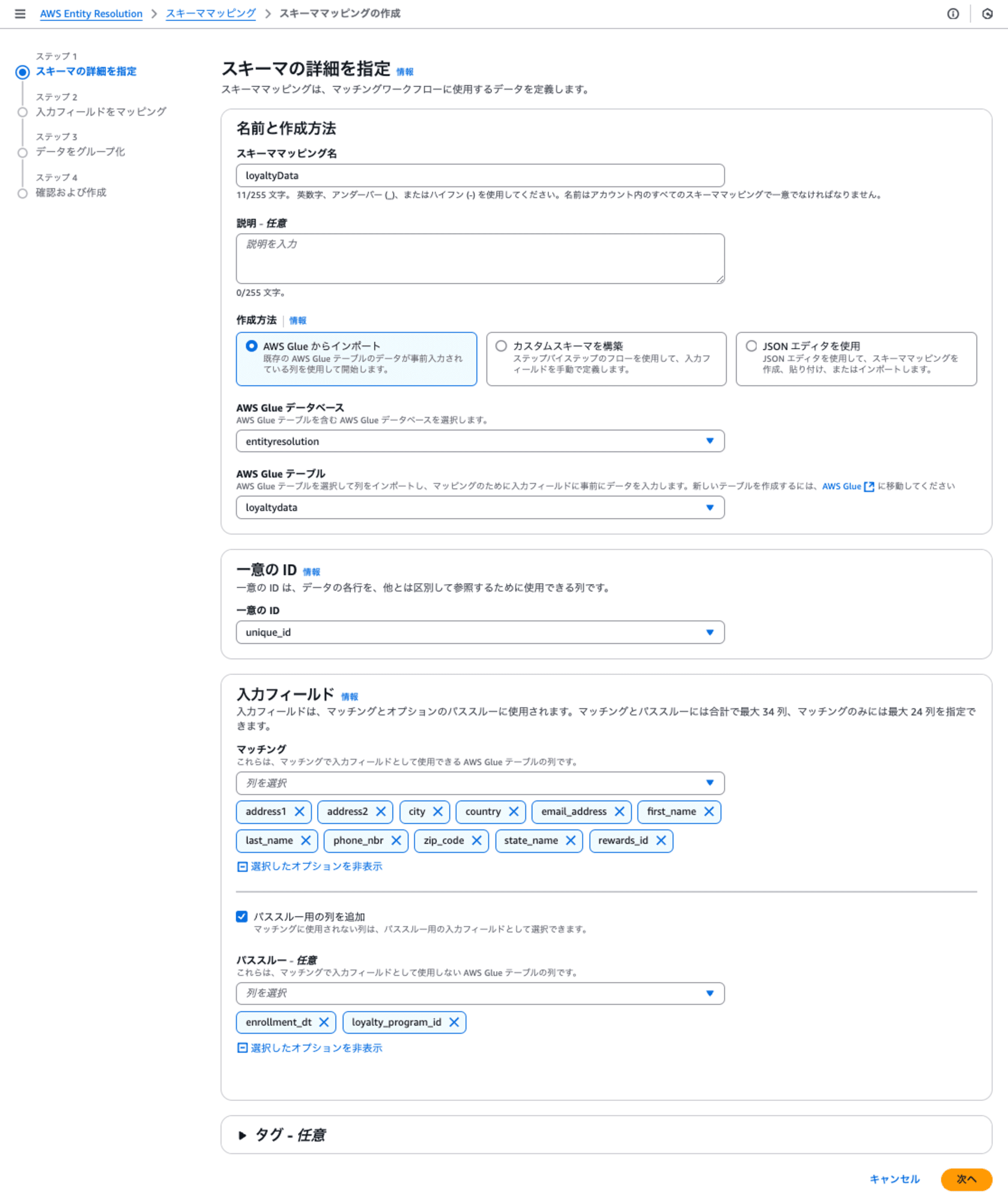
ステップ1: スキーマの詳細を指定
- スキーママッピング名は、「loyaltyData」と設定しました。
- 作成方法は、「AWS Glue からインポート」を選択して、AWS Glue データベースとテーブルを指定します。
- 一意のIDには、各レコードを一意に決めるフィールド「unique_id」を指定します。
- 入力フィールドのマッチングは、各行を明確に識別するための必須フィールドになる可能性のあるフィールドを指定します。
- 入力フィールドのパススルーは、マッチングに使わないけれども出力出力したいフィールドを指定します。
ステップ2: 入力フィールドをマッピング
入力フィールドはGlueテーブルのカラム名にあたり、入力フィールドに属性タイプ(以下のプルダウン)と一覧から選択すると、自動的にマッチキー名が設定されます。
もし、属性タイプの中にない場合はCustom String を選択することで、任意のマッチングキーを入力することができます。
ハッシュ化は、ハッシュ関数(単方向の関数)を用いて難読化する場合に指定します。
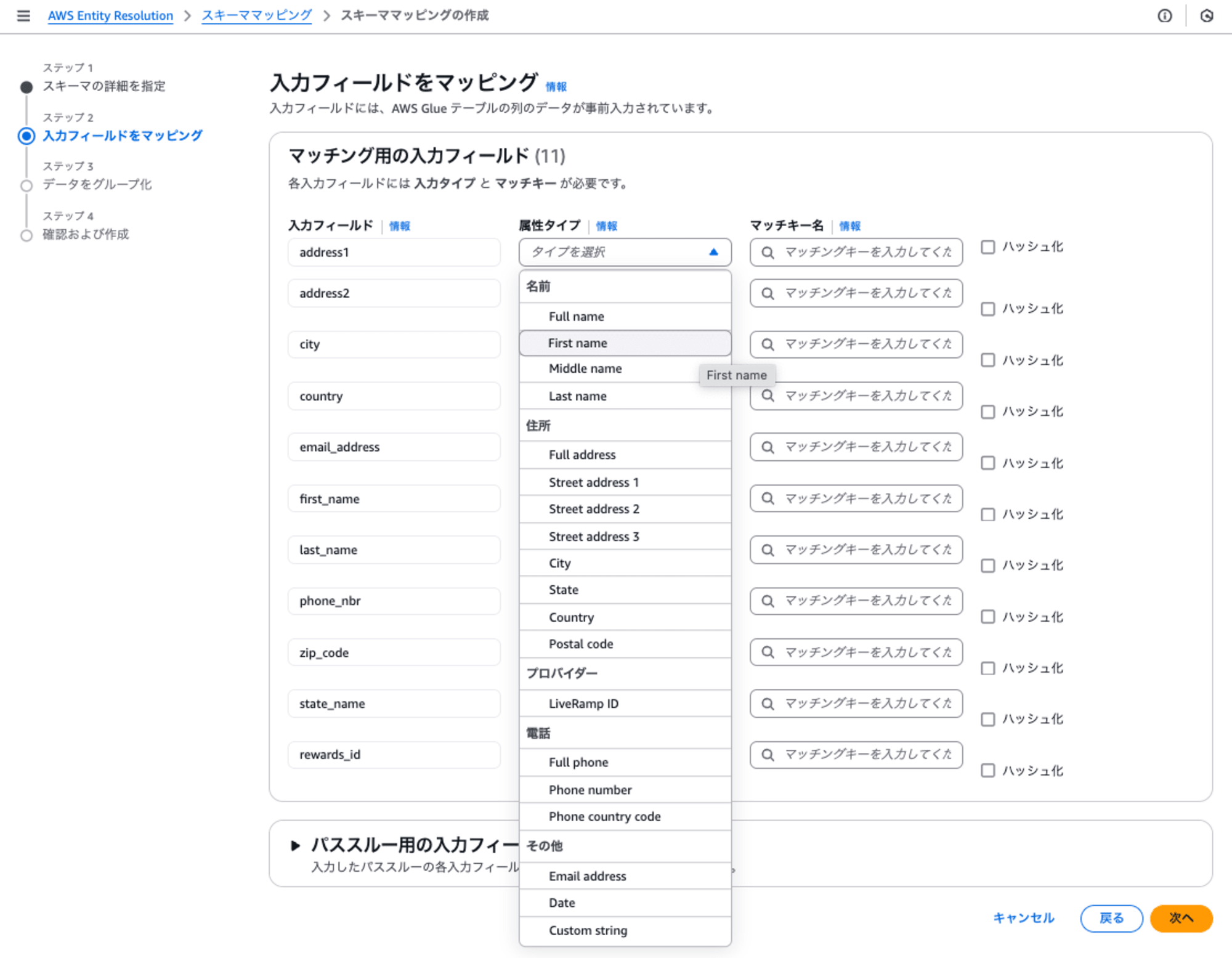
下記の通り、入力フィールドに対して属性タイプを設定しました。一番最後のrewards_idのみ、属性タイプにCustom String を選択して、rewardsidという任意のマッチキー名を指定しました。
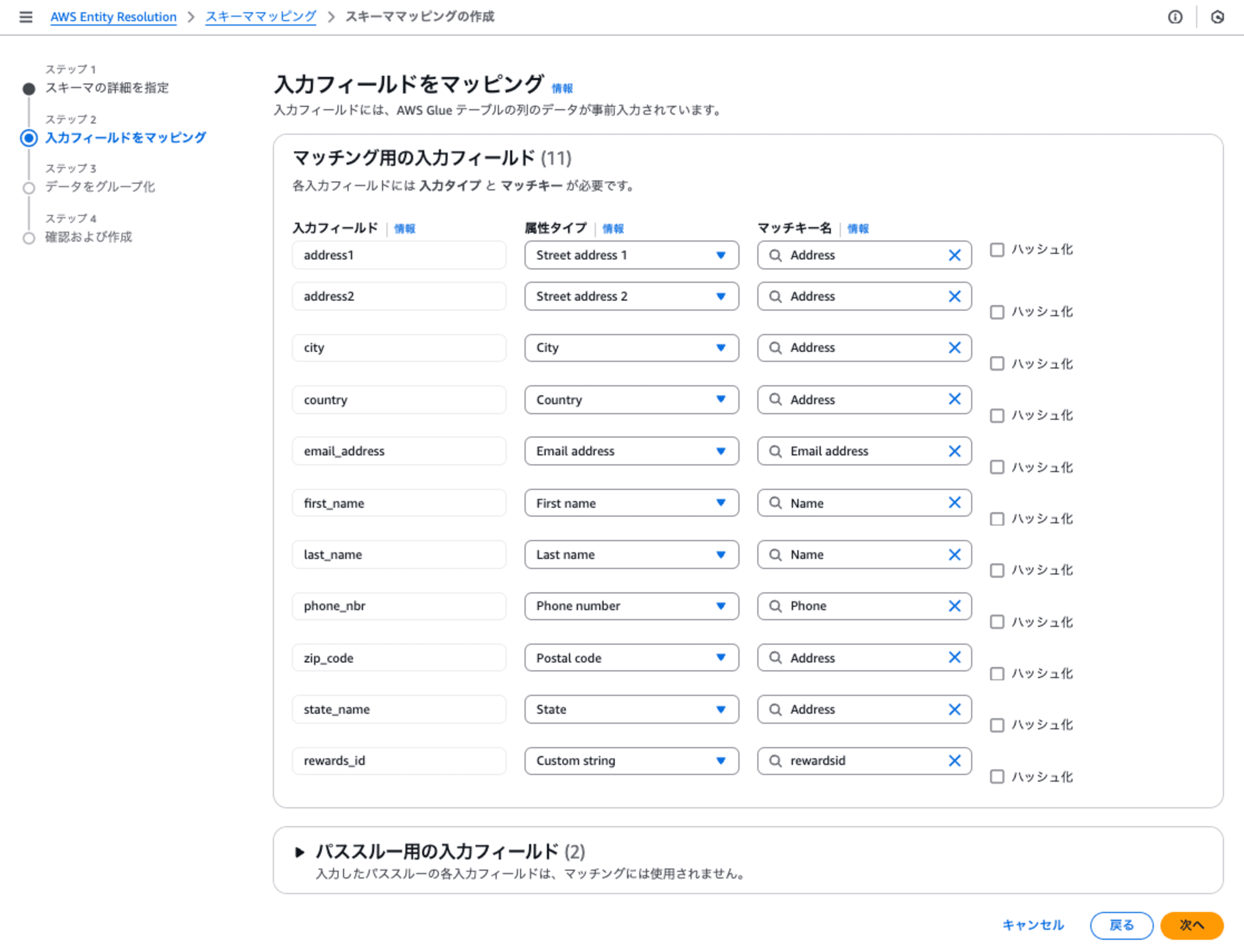
ステップ3: データをグループ化
名前、住所、または 電話番号 の入力データが複数のフィールドに分かれている場合は、データをグループ化してマッチキーを作ります。
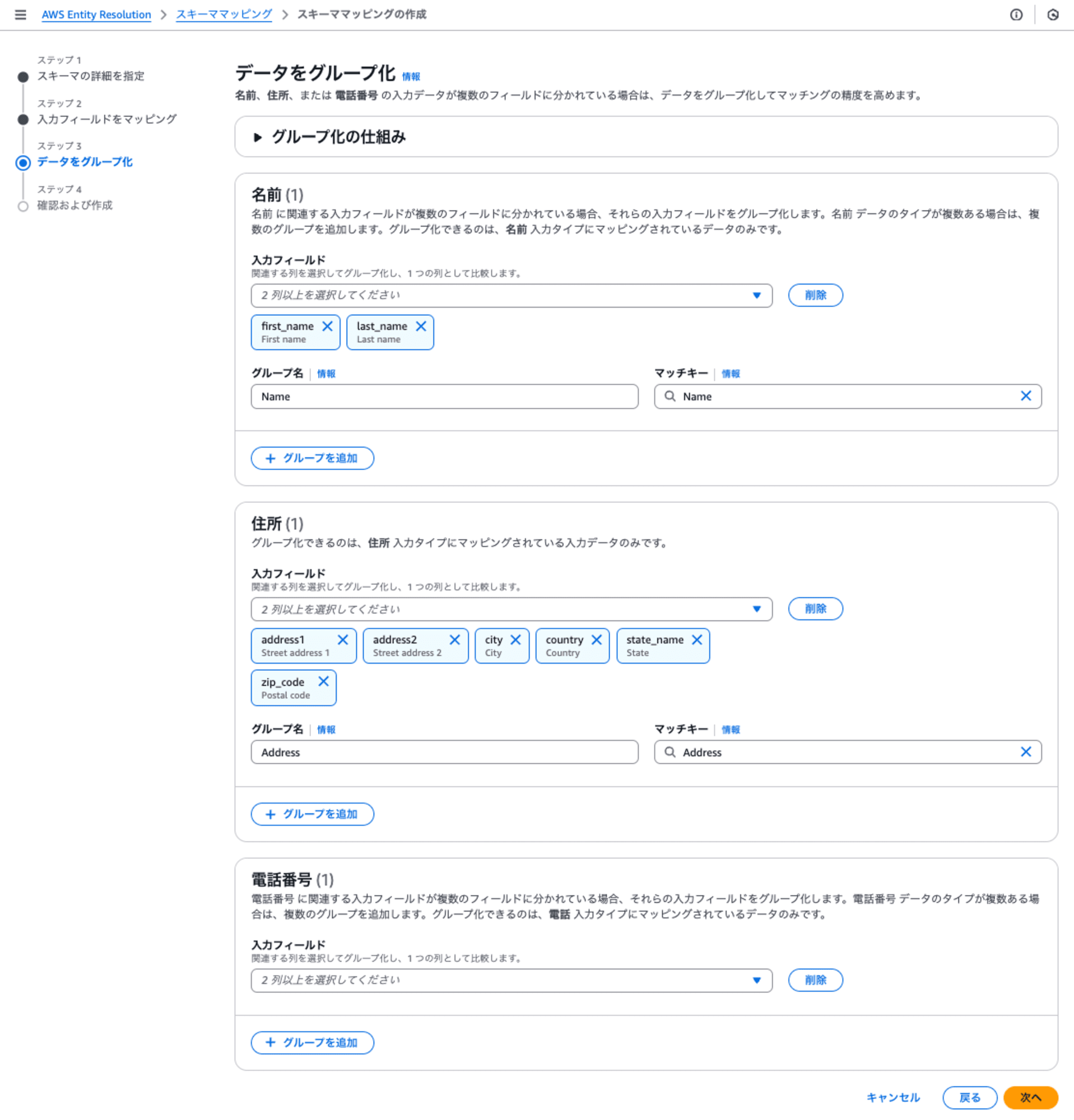
ステップ4: 確認および作成
最終確認で、[スキーママッピングの作成]をクリックすると作成されます。
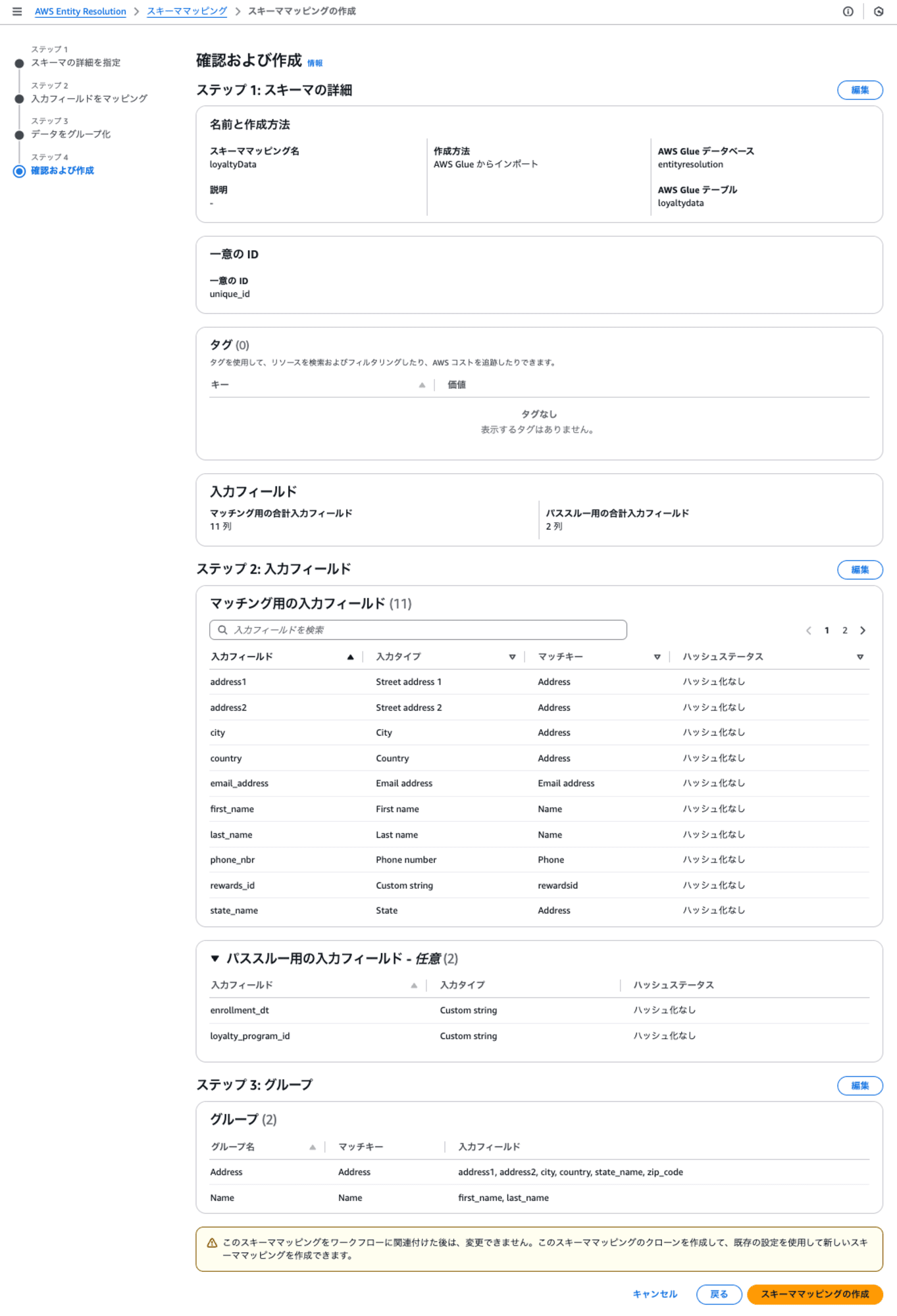
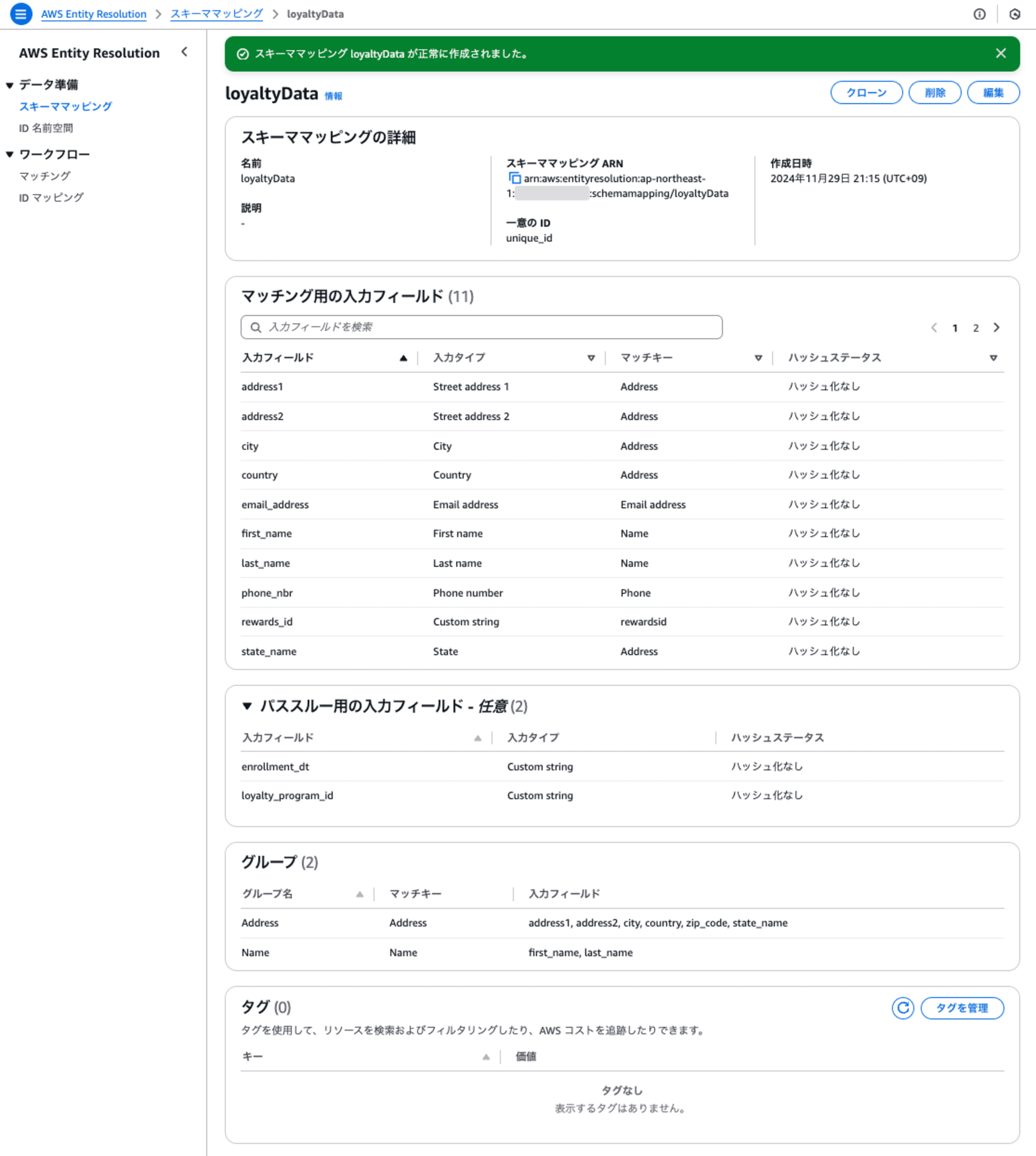
作成された結果は以下のとおりです。
2. マッチングワークフローの作成
AWS Entity Resolution のメニューのマッチングをクリックして、 [マッチングワークフローの作成] を押します。
ステップ1: マッチングワークフローの詳細を指定
- マッチングワークフロー名は、「loyaltyData_ML」と設定しました。
- データ入力は、「AWS Glue からインポート」を選択して、AWS Glue データベースとテーブルを指定します。スキーママッピングはさきほど作成したloyaltyDataを指定します。
- サービスアクセスで、サービスロール名を指定します。ここでは作成していないため新しいサービスロールを作成して使用します。

ステップ2: マッチングの手法を選択
ここでは特に変更せずに次に進みます。
今回のマッチング方法のresolutionタイプは、機械学習ベースのマッチングを選択します。実行頻度は手動のみです。

ステップ3: データ出力を指定
- データの出力先と形式のAmazon S3 の場所は、S3 URI にS3バケットのURIを指定します。
- システムの生成出力は、MatchIDとConfidenceLevel(機械学習における信頼度のレベル)が出力されます。
- データ出力は、出力されるフィールドが表示されます。

ステップ4: 確認および作成
最終確認画面です。[作成して実行] ボタンを押します。

[作成して実行]ボタンを押すと実行が開始されます。

3. マッチングの実行
マッチングワークフローが実行開始してから23分程度で完了しました。入力レコード2878に対して、一意のマッチIDが生成されたレコードが1552でした。

出力ファイルをGlueテーブルとして登録し、Athenaで結果を確認します。ここで実行しているクエリは、ConfidenceLevel(機械学習における信頼度のレベル)が0.8以上の条件でmatchidのレコード毎を参照しています。matchidが同じレコードは、ConfidenceLevelがどれくらいであるかを確認できます。
MLベースのマッチングは、レコード全体をより包括的に分析し、従来のルールベースのマッチングエンジンでは見つけられないエラーや欠落情報を考慮に入れることができます。これにより、より正確で柔軟なマッチングが可能になります。機械学習を用いたマッチングでは、「一致した/しない」ではなく、どれくらい一致しているのか定量的に判断できます。
では、適切なConfidenceLevel(機械学習における信頼度のレベル)のしきい値をどう判断するかというと、要件に基づき、最初は0.9、0.8、0.7 ...と実際のレコードを見てしきい値を探ることになります。

ルールベースマッチングと機械学習ベースマッチングの使い分け
この表は、AWS Entity Resolutionの2つのマッチング手法の主な違いは以下のとおりです。ルールベースマッチングはより柔軟でカスタマイズ可能ですが、セットアップにはルールの設定が必要です。一方、機械学習ベースマッチングは、セットアップが簡単で高速ですが、カスタマイズ性が低く、主に個人データに最適化されています。
ルールベースマッチングと機械学習ベースマッチングは、どちらが良いというわけではなく、相互補完的な関係であり、マッチングするデータの種類や理解度によって使い分けることになりそうです。
AWS Entity Resolutionのルールベースマッチングと機械学習ベースマッチングの主な違いを以下の表にまとめました。
| 特徴 | ルールベースマッチング | 機械学習ベースマッチング |
|---|---|---|
| マッチング方法 | ユーザーが定義した階層的なルールセット | 事前設定されたMLモデル |
| データ形式 | 平文またはハッシュ化されたデータ | 平文のみ(ハッシュ化データは非対応) |
| カスタマイズ性 | 高い(ルールの追加、削除、優先順位変更が可能) | 低い(モデルの変更や訓練は不可) |
| 処理頻度 | 手動または自動 | 手動のみ |
| 出力結果 | マッチID、適用されたルール番号 | マッチID、信頼度レベル(0.0-1.0) |
| セットアップの複雑さ | より複雑(ルールの設定が必要) | 比較的簡単(設定不要) |
| 適用範囲 | 柔軟(様々なデータタイプに適用可能) | 主に個人データ(名前、メール、電話番号、住所、生年月日)に最適化 |
| 処理速度 | データとルールの複雑さに依存 | 一般的に高速 |
最後に
機械学習ベースのマッチングの特長は、従来のルールベースマッチングよりも柔軟で包括的な分析が可能なことです。ConfidenceLevel(信頼度レベル)という指標を用いることで、マッチングの精度を定量的に評価でき、ユーザーのニーズに応じて適切なしきい値を設定することができます。
この機能は、ダークデータに対する企業が直面するデータの品質と一貫性の課題に対する効果的な解決策となります。ただし、最適なConfidenceLevelの設定には試行錯誤が必要であり、各企業の具体的な要件に基づいて慎重に調整していくことが重要です。
合わせて読みたい











