
AWS Glue for Spark のチュートリアルをまとめてみた(ワークアラウンドとデータ確認手順付き)
こんにちは、リテールアプリ共創部のmorimorikochanです。
AWS Glueナンモワカラン状態の私がAWS Glueに入門したく、AWS Glue for Spark のチュートリアルをやってみましたが、いくつかハマりどころや書き込んだデータがどのようになっているかわからない部分あったので、自分なりにまとめてみます。
※とにかくチュートリアルを終えることにフォーカスしているため色々省略しています。適宜チュートリアルの方をご確認ください。
対象読者
- AWS Glue for Sparkを使ってみたい方
- AWS Glue for Sparkのチュートリアルをやってみたい方
- AWS Glue for Sparkのチュートリアルをやってみたけど、うまくいかなかった方
以下、ジョブと書いているものは全てPySparkジョブのことを指します。
1. CloudFormationで必要なリソースを作成
はじめにCloudFormationを使って、チュートリアルに必要なリソースを作成します。
上記のチュートリアルでは、以下のAWS公式ブログに掲載されているCloudFormationのテンプレートを利用するように記載がありますが、現在は利用できません(テンプレートファイルが保管されているS3へアクセスできなくなっています)。
ですが、幸いなことに以下のGitHubリポジトリに同名のCloudFormationのテンプレートファイルが保管されているため、こちらを利用させていただきます。
CloudFormationのテンプレートを利用してスタックを作成すると、いくつかリソースが作成されます。
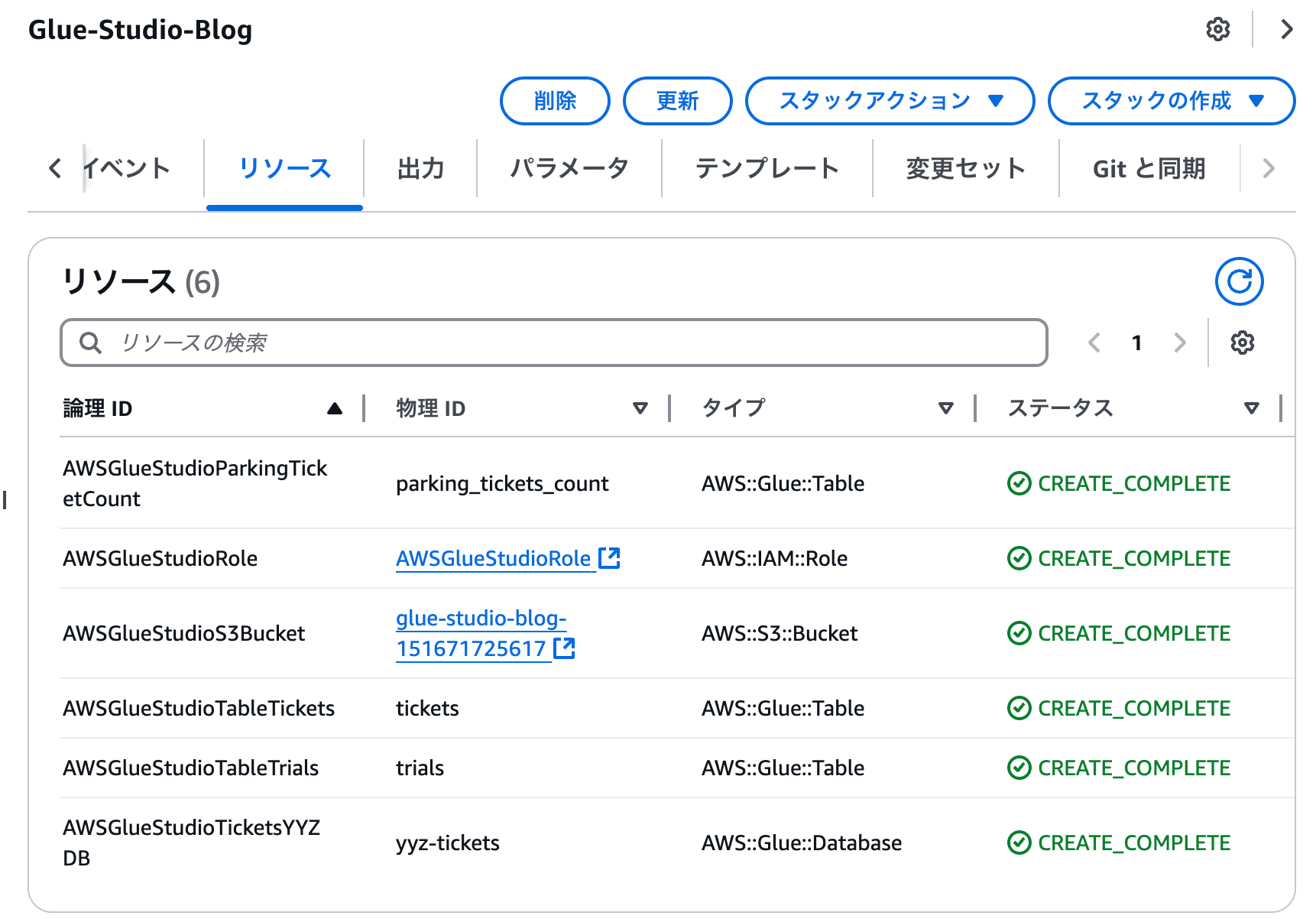
2. 書き込み用S3バケットの作成
ジョブで変換したデータを書き込むためのS3バケットを作成します。
また、ジョブで利用するIAM Role(1の段階でAWSGlueStudioRoleという名前で作成済)に、このS3バケットへの書き込み権限を忘れずに付与してください。そうしないとジョブの中でこのS3バケットに書き込むことができません。
3. Glue Studioでジョブを作成
次に、Glue Studioを使ってジョブを作成します。
Glue Studioは、AWS Glueのジョブを作成するためのツールです。
Glue StudioのトップページからScript editorを選択し、ダイアログ内でSparkを選択し作成します。このとき、1でリソースを作成したリージョンと同じリージョンになっていることを確認してください(違うリージョンだと実行時にデータベースが見つからない旨のエラーが出ます)。
作成後、上記チュートリアルに従ってスクリプトを用意します。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node S3 bucket
S3bucket_node1 = glueContext.create_dynamic_frame.from_catalog(
database="yyz-tickets", table_name="tickets", transformation_ctx="S3bucket_node1"
)
# Script generated for node ApplyMapping
ApplyMapping_node2 = ApplyMapping.apply(
frame=S3bucket_node1,
mappings=[
("tag_number_masked", "string", "tag_number_masked", "string"),
("date_of_infraction", "string", "date_of_infraction", "string"),
("ticket_date", "string", "ticket_date", "string"),
("ticket_number", "decimal", "ticket_number", "float"),
// ②
("officer", "decimal", "officer_name", "decimal"),
("infraction_code", "decimal", "infraction_code", "decimal"),
("infraction_description", "string", "infraction_description", "string"),
("set_fine_amount", "decimal", "set_fine_amount", "float"),
("time_of_infraction", "decimal", "time_of_infraction", "decimal"),
],
transformation_ctx="ApplyMapping_node2",
)
# Script generated for node S3 bucket
S3bucket_node3 = glueContext.write_dynamic_frame.from_options(
frame=ApplyMapping_node2,
connection_type="s3",
format="glueparquet",
// ①
connection_options={"path": "s3://morimorikochan-aws-glue-test-20250412", "partitionKeys": []},
format_options={"compression": "gzip"},
transformation_ctx="S3bucket_node3",
)
job.commit()
①の箇所のpathには、2で作成したS3バケットを指定してください。
②の箇所ではofficerというカラムがofficer_nameというカラムにマッピングされています
それ以外の、このスクリプトで具体的にどのような処理を行なっているかは、冒頭に記載した公式のチュートリアルをご覧ください。 。
つづけてJob Details のタブで Basic properties > IAM Role にAWSGlueStudioRoleを設定します。
また、費用に影響する可能性があるため念のため Basic properties > Requested number of workers は最小の2にしておきましょう
4. 実行
保存後にジョブを実行すると1分ほどでジョブが完了します。
実行結果はGlue StudioのJob runsタブから閲覧でき、Succeededと表示されれば成功です。
S3バケットには何やら色々ファイルが配置されますが、正直これでは正しくデータが加工されているのか確認できません。
そこで、クローラーとAthenaを使って加工後のデータを確認してみます。
5. クローラー実行
AWS GlueのサイドメニューのCrawlersからCreate Crawlerを選択し、クローラーを作成します。
- Data source configurationでは
Not yetを選択し、2で作ったS3バケットを新たなデータソースを追加します。
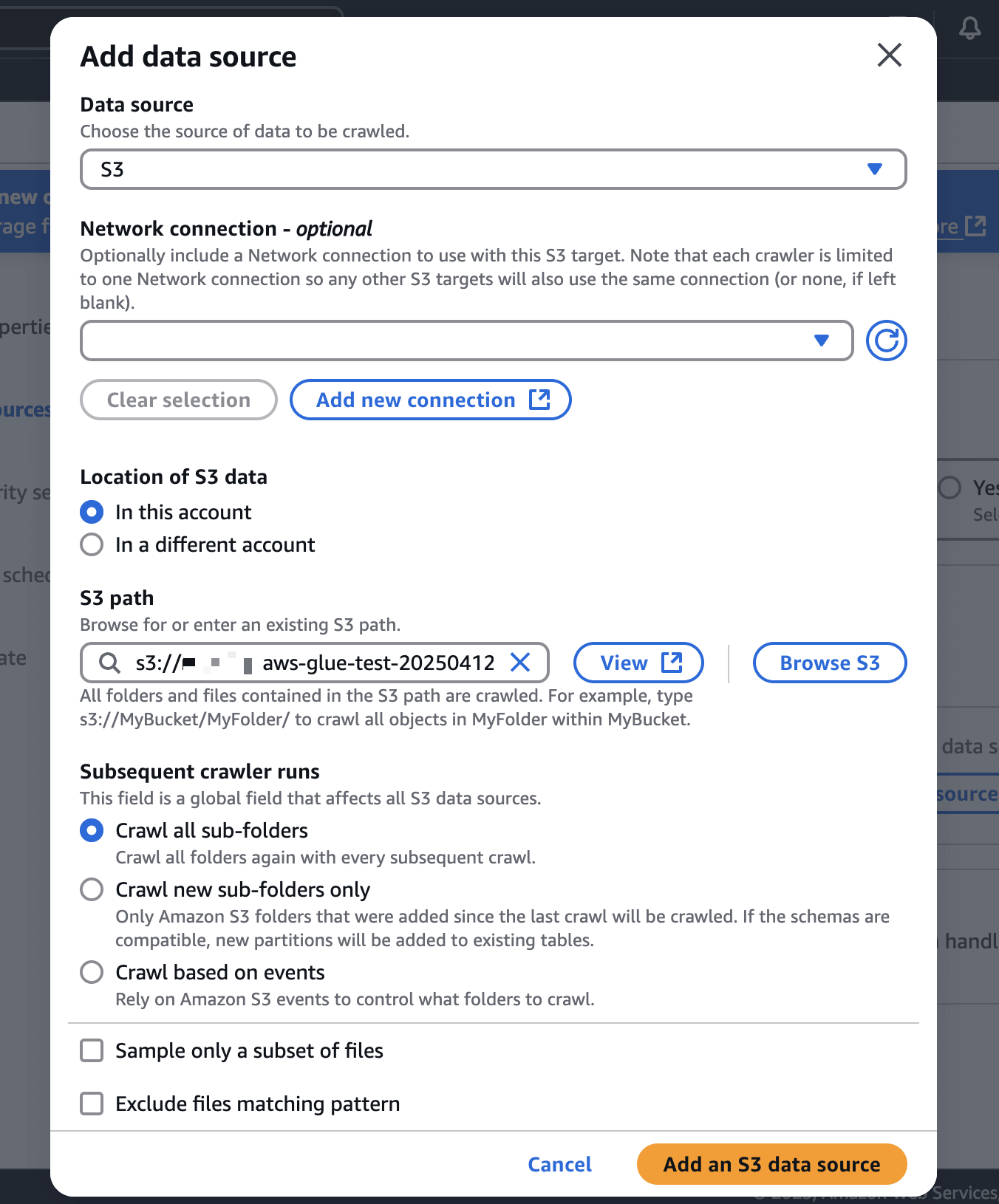
- IAM Roleは
Create new IAM Roleを選択しIAM Roleを作成します。 - Crawler scheduleは
On demandを選択します。
作成後、早速クローラーを実行します。
1,2分でクローラーが実行され、Glueのデータカタログに新たにテーブルが作成されます。
6. Athenaでクエリ実行
Athenaにアクセスし、データベースにAwsDataCatalog、テーブルにyyz-ticketsを選択すると、今回クローラーによって作成されたテーブルが表示されています。
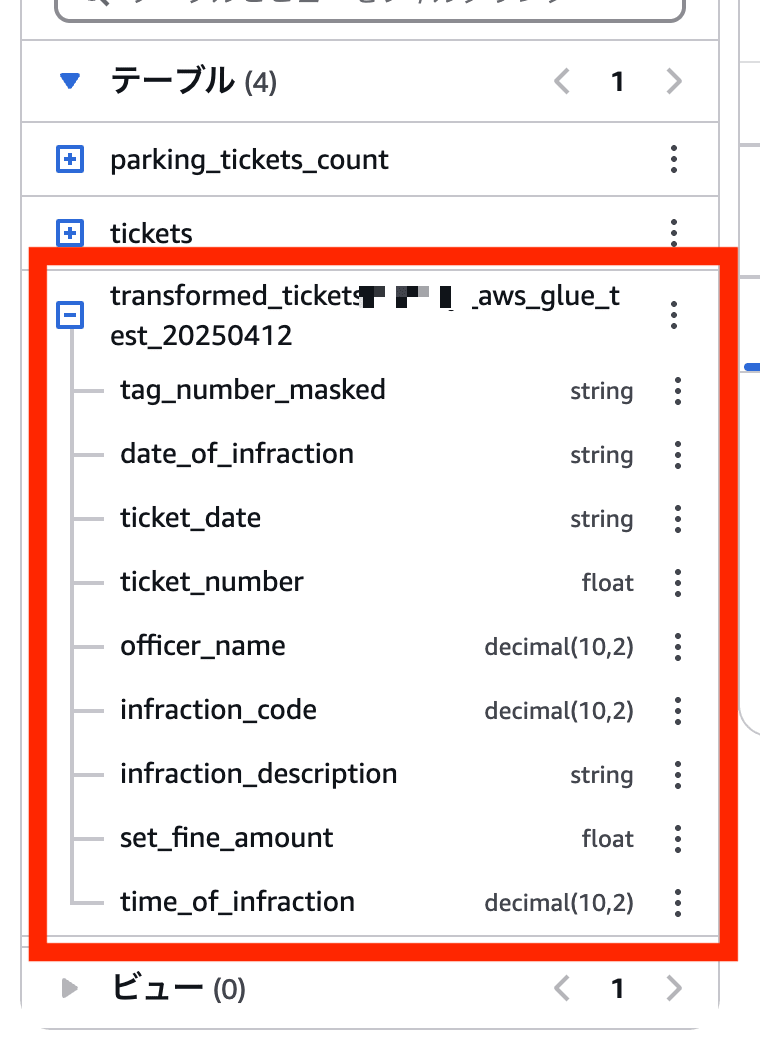
それではクエリを実行してみましょう。
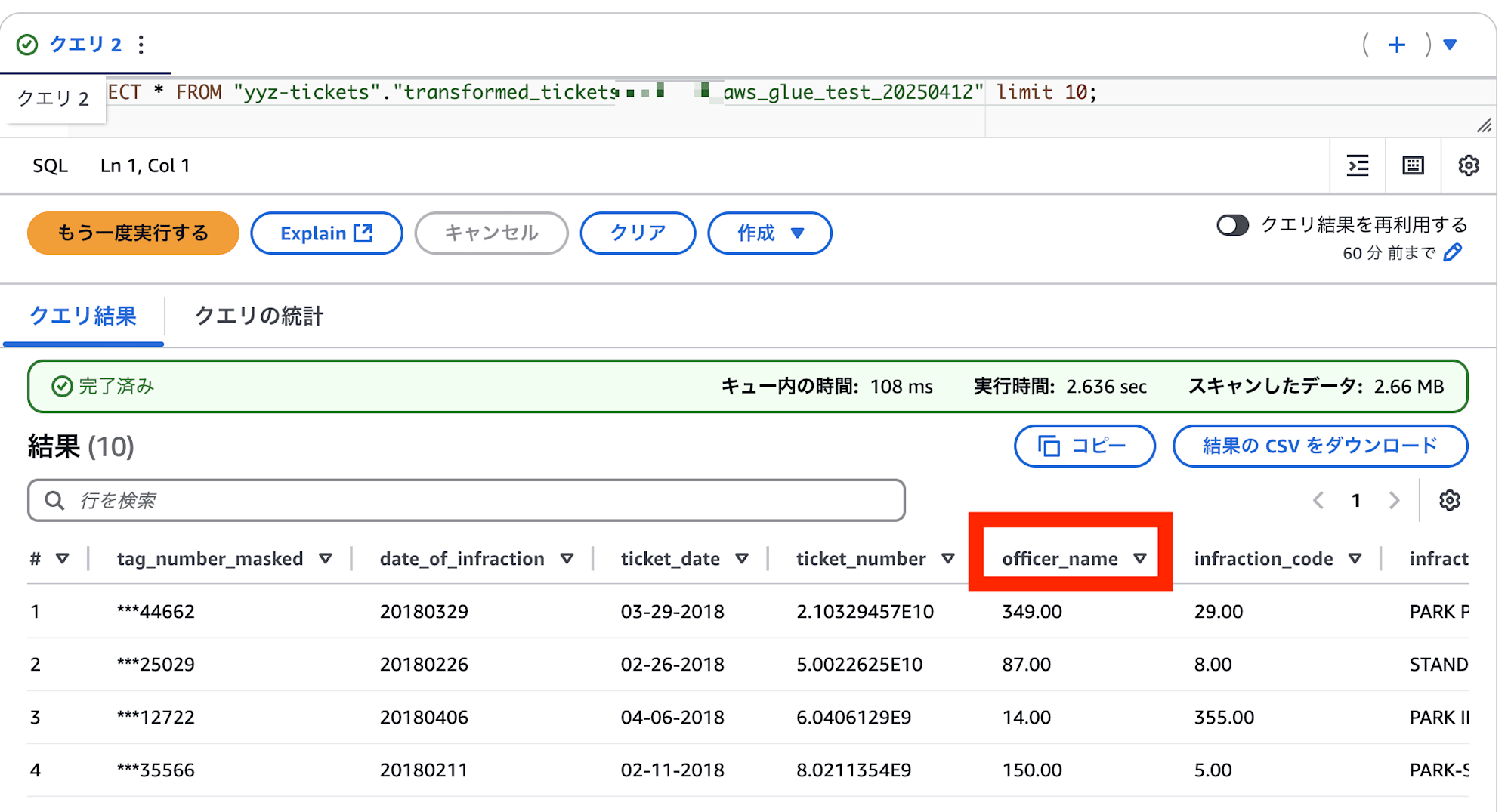
SELECT * FROM "yyz-tickets"."transformed_ticketsmorimorikochan_aws_glue_test_20250412" limit 10;
以下のように、出力されました。
officer_nameというカラムが存在しており、ジョブによってofficerがofficer_nameに変換されていることがわかります。
まとめ
いかがでしたでしょうか。AWS Glue for Sparkのジョブを実行し、加工されたデータをAthenaで確認することができました。
AWS GlueやAWS Glue for Sparkは多機能で色々なサービスの上に動作しているため、私のようなあまり詳しくない人が触るとふとしたところでつまづいてしまうので、こういったチュートリアルの存在は非常に重要だと感じます。
これを機にみなさんがもっとAWS Glue for Sparkを利用していただければと思いますし、私ももっと勉強していかなければならないなと感じました。








