
【AWS Glue】Glueジョブでdynamic_frameをソースに利用したらキャストエラーで困った話
データ事業本部の川中子(かわなご)です。
今回はGlueジョブのsparkにおけるdynamic_frameの利用で困ったことがあったので、
自身の備忘録的な意味も兼ねて記事として残しておこうと思います。
やろうとしたこと
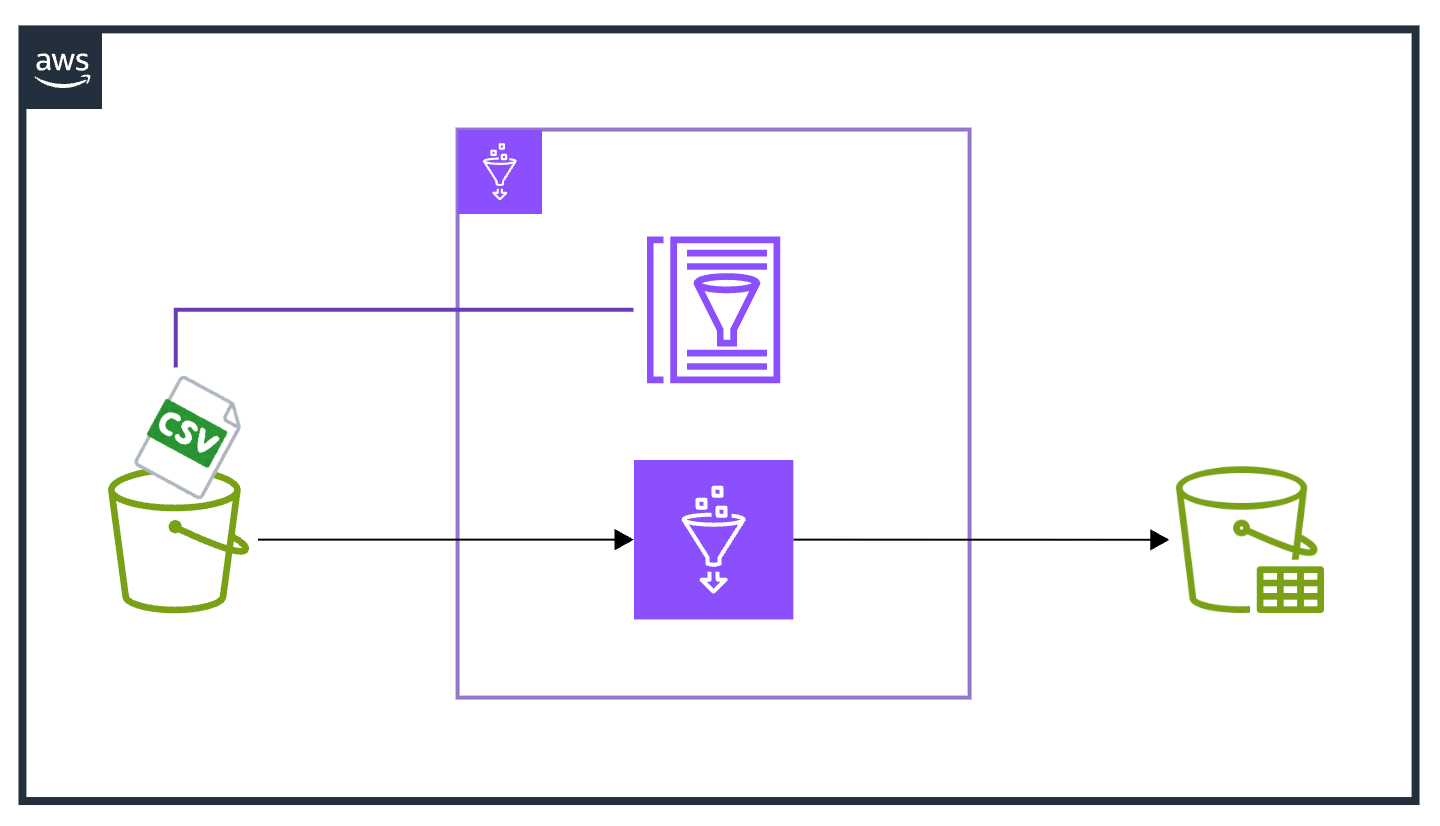
- ソースとターゲットのテーブル両方を同じデータ型で作成する
- S3に配置されたCSVファイルをソースとしてGlueカタログのテーブルを読み込む
- 読み込む際にsparkの
dynamic_frameを利用する
- 読み込む際にsparkの
- 読み込んだソースのデータフレームをIceberg形式のテーブルに連携する
発生した問題
Hive形式テーブルで定義したデータ型とは異なる形でソースのデータフレームが読み込まれてしまい、
ターゲットのIcebergテーブルとの間でデータ型エラーが発生していました。
Error Category: QUERY_ERROR; Failed Line Number: 53; AnalysisException: [INCOMPATIBLE_DATA_FOR_TABLE.CANNOT_SAFELY_CAST] Cannot write incompatible data for the table
s3tablesbucket.{name_space}.tbl_glue_data_type_test: Cannot safely castbinary_col"STRING" to "BINARY".
使用したアセット
ソースデータには以下のcsvファイルを利用しました。
| binary_col | boolean_col | date_col | decimal_col | double_col | float_col | int_col | bigint_col | string_col | timestamp_col |
|---|---|---|---|---|---|---|---|---|---|
| SGVsbG8gV29ybGQ= | true | 2023-01-01 | 123.45 | 123.456789 | 123.45 | 42 | 9223372036854775807 | Hello World | 2023-01-01 12:34:56 |
| QW1hem9uIEF0aGVuYQ== | false | 2023-02-15 | 456.78 | 456.789012 | 456.78 | 100 | 1234567890 | Amazon Iceberg | 2023-02-15 09:30:00 |
| QVdTIENsb3Vk | true | 2023-03-20 | 789.01 | 789.012345 | 789.01 | 200 | 9876543210 | Big Data Processing | 2023-03-20 18:45:30 |
| RGF0YSBBbmFseXRpY3M= | false | 2023-04-10 | 234.56 | 234.567890 | 234.56 | 300 | 1122334455 | Data Lake | 2023-04-10 07:15:45 |
| SWNlYmVyZyBGb3JtYXQ= | true | 2023-05-05 | 567.89 | 567.890123 | 567.89 | 400 | 5544332211 | Apache Iceberg | 2023-05-05 14:20:10 |
| UGFycXVldCBGaWxlcw== | false | 2023-06-20 | 890.12 | 890.123456 | 890.12 | 500 | 6677889900 | Data Analytics | 2023-06-20 22:05:30 |
| QmlnIERhdGE= | true | 2023-07-15 | 345.67 | 345.678901 | 345.67 | 600 | 1357924680 | AWS Cloud | 2023-07-15 11:40:15 |
| QW5hbHl0aWNz | false | 2023-08-30 | 678.90 | 678.901234 | 678.90 | 700 | 2468013579 | Database | 2023-08-30 16:55:25 |
| U3RyZWFtaW5n | true | 2023-09-12 | 901.23 | 901.234567 | 901.23 | 800 | 9870123456 | Streaming Data | 2023-09-12 03:10:50 |
| Q2xvdWQgQ29tcHV0aW5n | false | 2023-10-25 | 432.10 | 432.109876 | 432.10 | 900 | 5647382910 | Cloud Computing | 2023-10-25 19:25:40 |
ターゲットになるS3 Tables上のIcebergテーブルは以下のメタデータをもとに作成しました。
{
"tableBucketARN": {table_bucket_arn},
"namespace": {name_space},
"name": "tbl_glue_data_type_test",
"format": "ICEBERG",
"metadata": {
"iceberg": {
"schema": {
"fields": [
{
"name": "binary_col",
"type": "binary",
"required": true
},
{
"name": "boolean_col",
"type": "boolean",
"required": true
},
{
"name": "date_col",
"type": "date",
"required": true
},
{
"name": "decimal_col",
"type": "decimal(10,2)",
"required": true
},
{
"name": "double_col",
"type": "double",
"required": false
},
{
"name": "float_col",
"type": "float",
"required": false
},
{
"name": "int_col",
"type": "int",
"required": false
},
{
"name": "bigint_col",
"type": "long",
"required": false
},
{
"name": "string_col",
"type": "string",
"required": false
},
{
"name": "timestamp_col",
"type": "timestamp",
"required": false
}
]
}
}
}
}
作成の際はboto3から直接上記のメタデータをインプットにして作成しています。
s3tables_client = boto3.client('s3tables')
s3tables_client.create_table(**metadata_info)
ソースデータを読み込むためのGlueカタログ上のテーブルは、
以下のSQL文をAthenaから実行して作成しています。
CREATE EXTERNAL TABLE {source_database}.tbl_glue_data_type_test (
binary_col binary,
boolean_col boolean,
date_col date,
decimal_col decimal(10,2),
double_col double,
float_col float,
int_col int,
bigint_col bigint,
string_col string,
timestamp_col timestamp
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '{source_bucket}'
TBLPROPERTIES ('skip.header.line.count'='1');
Glueのジョブには以下の簡単なスクリプトが設定されています。
処理の流れとしては以下のイメージです。
- ソースとなるGlueカタログ上のテーブルを
dynamic_frame経由で読み込む - データフレームをソースとして、ターゲットのテーブルに
INSERTする
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from pyspark.context import SparkContext
from pyspark.conf import SparkConf
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'warehouse'])
conf = SparkConf()
conf.set("spark.sql.catalog.s3tablesbucket", "org.apache.iceberg.spark.SparkCatalog")
conf.set("spark.sql.catalog.s3tablesbucket.catalog-impl", "software.amazon.s3tables.iceberg.S3TablesCatalog")
conf.set("spark.sql.catalog.s3tablesbucket.warehouse", args["warehouse"])
conf.set("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
sc = SparkContext(conf=conf)
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
params = {
"source_database": ************,
"source_table": "tbl_glue_data_type_test",
"target_database": ************,
"target_table": "tbl_glue_data_type_test"
}
try:
# SQL文を定義
SQL_QUERY = f"INSERT INTO s3tablesbucket.{params['target_database']}.{params['target_table']} SELECT * FROM input_table;"
# データフレーム作成
source_df = glueContext.create_dynamic_frame.from_catalog(
database = params["source_database"],
table_name = params["source_table"],
transformation_ctx = "source_df"
).toDF()
# データ処理
if not source_df.isEmpty():
# データ型を出力
print("データ型")
source_df.printSchema()
source_df.createOrReplaceTempView("input_table")
spark.sql(SQL_QUERY)
else:
print("No data to process")
job.commit()
except Exception as e:
raise
問題の詳細
実際に上記のアセットでジョブを実行すると、冒頭に記載したエラーになります。
Error Category: QUERY_ERROR; Failed Line Number: 53; AnalysisException: [INCOMPATIBLE_DATA_FOR_TABLE.CANNOT_SAFELY_CAST] Cannot write incompatible data for the table
s3tablesbucket.{name_space}.tbl_glue_data_type_test: Cannot safely castbinary_col"STRING" to "BINARY".
dynamic_frameからデータフレームに変換した直後のスキーマ情報をログから確認してみると、
本来binary型として読み込まれるはずのカラムがstring型として読み込まれていることが分かります。
このbinary_colをターゲットテーブルに連携する際に、キャストエラーになっていたようです。
root
|-- binary_col: string (nullable = true)
|-- boolean_col: boolean (nullable = true)
|-- date_col: string (nullable = true)
|-- decimal_col: decimal(5,2) (nullable = true)
|-- double_col: double (nullable = true)
|-- float_col: float (nullable = true)
|-- int_col: integer (nullable = true)
|-- bigint_col: long (nullable = true)
|-- string_col: string (nullable = true)
|-- timestamp_col: string (nullable = true)
また他にもdate型やtimestamp型がstring型に変わってしまっていたり、
decimal(10,2)が実際のソースデータに合わせてdecimal(5,2)に変換されています。
問題を解決するには、dynamic_frameからデータフレームを読み込んだあとに、
ターゲットへ連携する前に、本来のデータ型にキャストしてあげる必要がありそうです。
スクリプトの修正
Glueジョブのスクリプトを以下の内容に修正しました。
主な修正点は以下のとおりです。
- boto3経由でソーステーブルのスキーマ定義を取得
- ソースデータの各カラムを正しいデータ型の定義にキャスト
- キャストエラーで
NULLに変換されたカラムがないか判定
import sys
import boto3
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from pyspark.context import SparkContext
from pyspark.sql.functions import col, count, when, isnull, lit
from pyspark.conf import SparkConf
from awsglue.job import Job
def get_null_counts(df):
"""各列のNULL値をカウントして辞書型で返す"""
exprs = [count(when(isnull(col(c)), lit(1))).alias(c) for c in df.columns]
null_counts_row = df.agg(*exprs).collect()[0]
null_counts_dict = {col_name: null_counts_row[col_name] for col_name in df.columns}
return null_counts_dict
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'warehouse'])
conf = SparkConf()
conf.set("spark.sql.catalog.s3tablesbucket", "org.apache.iceberg.spark.SparkCatalog")
conf.set("spark.sql.catalog.s3tablesbucket.catalog-impl", "software.amazon.s3tables.iceberg.S3TablesCatalog")
conf.set("spark.sql.catalog.s3tablesbucket.warehouse", args["warehouse"])
conf.set("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
sc = SparkContext(conf=conf)
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
params = {
"source_database": ************,
"source_table": "tbl_glue_data_type_test",
"target_database": ************,
"target_table": "tbl_glue_data_type_test"
}
try:
# SQL文を定義
SQL_QUERY = f"INSERT INTO s3tablesbucket.{params['target_database']}.{params['target_table']} SELECT * FROM input_table;"
# データフレーム作成
source_df = glueContext.create_dynamic_frame.from_catalog(
database = params["source_database"],
table_name = params["source_table"],
transformation_ctx = "source_df"
).toDF()
# データ処理
if not source_df.isEmpty():
# 変換後のデータ型を出力
print("変換前のデータ型")
source_df.printSchema()
# 変換前の各列の欠損値の数をカウント
null_counts_before = get_null_counts(source_df)
# boto3経由でソーステーブルの型情報を取得する
glue_client = boto3.client('glue')
response = glue_client.get_table(
DatabaseName=params["source_database"],
Name=params["source_table"]
)
columns = response['Table']['StorageDescriptor']['Columns']
# データフレームの型をカタログ上で指定したデータ型に変換する
for clmns in columns:
source_df = source_df.withColumn(clmns["Name"], col(clmns["Name"]).cast(clmns["Type"]))
# 変換後のデータ型を出力
print("変換後のデータ型")
source_df.printSchema()
# 変換後の各列の欠損値の数をカウント
null_counts_after = get_null_counts(source_df)
# 変換の前後で各列の欠損値の数を比較
cast_error_counts = 0
for col_name in source_df.columns:
if null_counts_before[col_name] < null_counts_after[col_name]:
# キャストエラーをカウント
cast_error_counts += 1
# 1列でもキャストエラーが起こっていた場合はエラー
if 0 < cast_error_counts:
raise ValueError("Data type casting error occurred")
source_df.createOrReplaceTempView("input_table")
spark.sql(SQL_QUERY)
else:
print("No data to process")
job.commit()
except Exception as e:
raise
上記のスクリプトでジョブを実行してキャスト前後のスキーマ情報を見てみると、
全てのカラムが想定通りの型に変換されて、ジョブも問題なく稼働しました。
# 変換前のデータ型
root
|-- binary_col: string (nullable = true)
|-- boolean_col: boolean (nullable = true)
|-- date_col: string (nullable = true)
|-- decimal_col: decimal(5,2) (nullable = true)
|-- double_col: double (nullable = true)
|-- float_col: float (nullable = true)
|-- int_col: integer (nullable = true)
|-- bigint_col: long (nullable = true)
|-- string_col: string (nullable = true)
|-- timestamp_col: string (nullable = true)
# 変換後のデータ型
root
|-- binary_col: binary (nullable = true)
|-- boolean_col: boolean (nullable = true)
|-- date_col: date (nullable = true)
|-- decimal_col: decimal(10,2) (nullable = true)
|-- double_col: double (nullable = true)
|-- float_col: float (nullable = true)
|-- int_col: integer (nullable = true)
|-- bigint_col: long (nullable = true)
|-- string_col: string (nullable = true)
|-- timestamp_col: timestamp (nullable = true)
さいごに
今回はGlueジョブのsparkにおけるdynamic_frame利用時の注意点について書いてみました。
個人的にdynamic_frameは他のデータフレームライブラリとは少し異なる挙動をする点が多く感じます。
ただGlueでpysparkを利用することでブックマーク機能や分散処理が使えるため、
利用用途によっては強力なツールであることは間違いないと思いますので、
仕様上の大事なポイントをしっかり押さえて、上手く活用していきたいですね。
本記事が少しでも開発時の参考になれば幸いです。
最後まで閲覧いただきありがとうございました。









