
AWS ParallelCluster で Intel MPI を使用する際に必要な設定を検証してみた
AWS ParallelCluster で Intel MPI を Slurm 環境で使うときの設定を検証しました。「module load は実行時も必要?」「I_MPI_PMI_LIBRARY は必須?」といった個人的な疑問を解消するため、3 パターンで動作を確認しています。簡単な Hello するだけのサンプルプログラムで確認しています。
検証環境
| 項目 | 詳細 |
|---|---|
| AWS ParallelCluster | v3.14.0 |
| OS | Ubuntu 24.04 |
| コンピュートノード | c7i.large × 2 台(物理コア 1 個/ノード) |
| Intel MPI バージョン | 2021.16 |
クラスターコンフィグ
検証に使用したクラスターのコンフィグファイルです。
クラスター設定ファイル全文
Region: ap-northeast-1
Image:
Os: ubuntu2404
Tags:
- Key: Name
Value: cluster-v3.14.0
# ----------------------------------------------------------------
# Head Node Settings
# ----------------------------------------------------------------
HeadNode:
InstanceType: t3a.small
Networking:
ElasticIp: false
SubnetId: subnet-029f0fb0acc64043d
LocalStorage:
RootVolume:
Size: 45
Encrypted: true
VolumeType: gp3
Iops: 3000
Throughput: 125
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
# ----------------------------------------------------------------
# Compute Node Settings
# ----------------------------------------------------------------
Scheduling:
Scheduler: slurm
SlurmSettings:
ScaledownIdletime: 5
SlurmQueues:
# ------ Compute ------
- Name: test
ComputeResources:
- Name: test
Instances:
- InstanceType: t3a.micro
MinCount: 0
MaxCount: 10
DisableSimultaneousMultithreading: true
ComputeSettings:
LocalStorage:
RootVolume:
Size: 45
Encrypted: true
VolumeType: gp3
Iops: 3000
Throughput: 125
CapacityType: SPOT
AllocationStrategy: price-capacity-optimized
Networking:
SubnetIds:
- subnet-029f0fb0acc64043d
- subnet-0b9c598622ad54e61
- subnet-01559948e762bd434
PlacementGroup:
Enabled: false
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
# ------ Compute ------
- Name: p1
ComputeResources:
- Name: c7i-normal
Instances:
- InstanceType: c7i.large
MinCount: 0
MaxCount: 10
DisableSimultaneousMultithreading: true
ComputeSettings:
LocalStorage:
RootVolume:
Size: 45
Encrypted: true
VolumeType: gp3
Iops: 3000
Throughput: 125
CapacityType: SPOT
AllocationStrategy: price-capacity-optimized
Networking:
SubnetIds:
- subnet-0b9c598622ad54e61
- subnet-01559948e762bd434
- subnet-029f0fb0acc64043d
PlacementGroup:
Enabled: false
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
# ------ Compute ------
- Name: p2
ComputeResources:
- Name: c7i-prioritized
Instances:
- InstanceType: c7i.large
MinCount: 0
MaxCount: 10
DisableSimultaneousMultithreading: true
ComputeSettings:
LocalStorage:
RootVolume:
Size: 45
Encrypted: true
VolumeType: gp3
Iops: 3000
Throughput: 125
CapacityType: SPOT
AllocationStrategy: capacity-optimized-prioritized
Networking:
SubnetIds:
- subnet-0b9c598622ad54e61
- subnet-01559948e762bd434
- subnet-029f0fb0acc64043d
PlacementGroup:
Enabled: false
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
# ----------------------------------------------------------------
# Shared Storage Settings
# ----------------------------------------------------------------
SharedStorage:
- MountDir: /home
Name: efs1
StorageType: Efs
EfsSettings:
FileSystemId: fs-0f66550e47cbc924b
# ----------------------------------------------------------------
# Other Settings
# ----------------------------------------------------------------
Monitoring:
Logs:
CloudWatch:
Enabled: true
RetentionInDays: 180
DeletionPolicy: "Delete"
Dashboards:
CloudWatch:
Enabled: false
準備:Intel MPI のロードとコンパイル
ヘッドノードで作業しています。
利用可能なモジュールの確認
ParallelCluster には 3 つの MPI 実装が用意されています。
Intel MPI、Open MPI 4 系、Open MPI 5 系です。
$ module avail
---------------------------- /opt/amazon/modules/modulefiles ----------------------------
libfabric-aws/2.1.0amzn5.0 openmpi/4.1.7 openmpi5/5.0.6
---------------------------- /usr/share/modules/modulefiles -----------------------------
dot module-git module-info modules null use.own
------------------------ /opt/intel/mpi/2021.16/etc/modulefiles -------------------------
intelmpi/2021.16
Key:
modulepath
Intel MPI モジュールのロード
今回は Intel MPI を検証したいためロードします。
$ module load intelmpi/2021.16
$ module list
Currently Loaded Modulefiles:
1) intelmpi/2021.16
$ mpirun --version
Intel(R) MPI Library for Linux* OS, Version 2021.16 Build 20250513 (id: a7c135c)
Copyright 2003-2025, Intel Corporation.
サンプルプログラム
各 MPI プロセスが自分のランク番号とホスト名を表示するシンプルなプログラムを用意しました。
/*
* シンプルなMPIプログラム
* 各プロセスが自分のランク(番号)とホスト名を表示します
*/
#include <mpi.h>
#include <stdio.h>
#include <unistd.h>
int main(int argc, char** argv) {
int world_size; // 全体のプロセス数
int world_rank; // 自分のプロセス番号(ランク)
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
// MPIの初期化
MPI_Init(&argc, &argv);
// 全体のプロセス数を取得
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// 自分のランク番号を取得
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
// 実行中のホスト名を取得
MPI_Get_processor_name(processor_name, &name_len);
// 各プロセスが情報を表示
printf("Hello from rank %d out of %d processes on host %s\n",
world_rank, world_size, processor_name);
// MPIの終了処理
MPI_Finalize();
return 0;
}
コンパイル
コンパイル時には module load intelmpi/xxx を実行する必要があります。先ほどロード済みなのでそのままいきます。
$ mpicc -o hello_mpi hello_mpi.c
実行ファイルが作成できました。この実行ファイルをコンピュートノードで実行して検証します。
$ ll hello_mpi
-rwxrwxr-x 1 ubuntu ubuntu 16208 Oct 18 01:35 hello_mpi*
検証1: module loadあり + I_MPI_PMI_LIBRARYあり
目的
私の思う無難な設定で動作を確認します。
ジョブスクリプト
#!/bin/bash
#SBATCH --job-name=hello_mpi # ジョブ名
#SBATCH --partition=p1 # p1キューを使用
#SBATCH --output=hello_mpi_%j.out # 標準出力ファイル(%j はジョブID)
#SBATCH --error=hello_mpi_%j.err # 標準エラー出力ファイル
#SBATCH --nodes=2 # 使用するノード数(c7i.large × 2台)
#SBATCH --ntasks-per-node=1 # ノードあたりのタスク数(物理コア1個 = 1プロセス)
#SBATCH --cpus-per-task=1 # タスクあたりのCPU数
# ジョブ情報の表示
echo "=========================================="
echo "ジョブID: $SLURM_JOB_ID"
echo "ジョブ名: $SLURM_JOB_NAME"
echo "パーティション: $SLURM_JOB_PARTITION"
echo "ノード数: $SLURM_JOB_NUM_NODES"
echo "総タスク数: $SLURM_NTASKS (= ノード数 × ntasks-per-node)"
echo "使用ノード: $SLURM_JOB_NODELIST"
echo "=========================================="
echo ""
# Intel MPIモジュールのロード
module load intelmpi/2021.16
# PMIライブラリの設定
export I_MPI_PMI_LIBRARY=/opt/slurm/lib/libpmi.so
# デバッグ情報の出力を有効化
export I_MPI_DEBUG=5
# プログラムの実行
echo ""
echo "プログラム実行開始..."
srun ./hello_mpi
echo ""
echo "プログラム実行完了"
実行結果
正常に動作しました。
- Intel MPI の libfabric を使用(
libfabric version: 2.1.0-impi) - TCP プロバイダーを使用(
libfabric provider: tcp) - Rank 0 と 1 が存在し、ノード間通信に成功
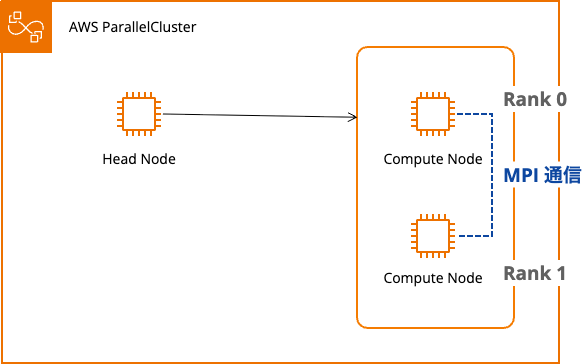
以下のメッセージで確認できます。
Hello from rank 0 out of 2 processes
Hello from rank 1 out of 2 processes
==========================================
ジョブID: 33
ジョブ名: hello_mpi
パーティション: p1
ノード数: 2
総タスク数: 2 (= ノード数 × ntasks-per-node)
使用ノード: p1-dy-c7i-normal-[1-2]
==========================================
プログラム実行開始...
[0] MPI startup(): PMI API: pmi
[0] MPI startup(): Intel(R) MPI Library, Version 2021.16 Build 20250513 (id: a7c135c)
[0] MPI startup(): Copyright (C) 2003-2025 Intel Corporation. All rights reserved.
[0] MPI startup(): library kind: release
[0] MPI startup(): libfabric version: 2.1.0-impi
[0] MPI startup(): libfabric provider: tcp
[0] MPI startup(): Load tuning file: "/opt/intel/mpi/2021.16/opt/mpi/etc/tuning_skx_shm-ofi_tcp.dat"
[0] MPI startup(): Number of NICs: 1
[0] MPI startup(): ===== NIC pinning on p1-dy-c7i-normal-1 =====
[0] MPI startup(): Rank Thread id Pin nic
[0] MPI startup(): 0 0 enp39s0
Hello from rank 1 out of 2 processes on host p1-dy-c7i-normal-2
[0] MPI startup(): ===== CPU pinning =====
[0] MPI startup(): Rank Pid Node name Pin cpu
[0] MPI startup(): 0 2526 p1-dy-c7i-normal-1 {0}
[0] MPI startup(): 1 2504 p1-dy-c7i-normal-2 {0}
[0] MPI startup(): I_MPI_ROOT=/opt/intel/mpi/2021.16
[0] MPI startup(): I_MPI_HYDRA_BOOTSTRAP_EXEC_EXTRA_ARGS=--external-launcher
[0] MPI startup(): I_MPI_HYDRA_BOOTSTRAP=slurm
[0] MPI startup(): I_MPI_DEBUG=5
[0] MPI startup(): I_MPI_PMI_LIBRARY=/opt/slurm/lib/libpmi.so
Hello from rank 0 out of 2 processes on host p1-dy-c7i-normal-1
プログラム実行完了
検証2: module loadなし + I_MPI_PMI_LIBRARYあり
目的
実行時に Intel MPI のモジュールをロードする必要があるかどうかを確認します。
検証方法
ヘッドノードでロードしたモジュールをクリアし、ジョブスクリプト内でもmodule loadをコメントアウトします。
$ module list
Currently Loaded Modulefiles:
1) intelmpi/2021.16
$ module purge
$ module list
No Modulefiles Currently Loaded.
ジョブスクリプト
#!/bin/bash
#SBATCH --job-name=hello_mpi # ジョブ名
#SBATCH --partition=p1 # p1キューを使用
#SBATCH --output=hello_mpi_%j.out # 標準出力ファイル(%j はジョブID)
#SBATCH --error=hello_mpi_%j.err # 標準エラー出力ファイル
#SBATCH --nodes=2 # 使用するノード数(c7i.large × 2台)
#SBATCH --ntasks-per-node=1 # ノードあたりのタスク数(物理コア1個 = 1プロセス)
#SBATCH --cpus-per-task=1 # タスクあたりのCPU数
# ジョブ情報の表示
echo "=========================================="
echo "ジョブID: $SLURM_JOB_ID"
echo "ジョブ名: $SLURM_JOB_NAME"
echo "パーティション: $SLURM_JOB_PARTITION"
echo "ノード数: $SLURM_JOB_NUM_NODES"
echo "総タスク数: $SLURM_NTASKS (= ノード数 × ntasks-per-node)"
echo "使用ノード: $SLURM_JOB_NODELIST"
echo "=========================================="
echo ""
# Intel MPIモジュールのロード
# module load intelmpi/2021.16
# PMIライブラリの設定
export I_MPI_PMI_LIBRARY=/opt/slurm/lib/libpmi.so
# デバッグ情報の出力を有効化
export I_MPI_DEBUG=5
# プログラムの実行
echo ""
echo "プログラム実行開始..."
srun ./hello_mpi
echo ""
echo "プログラム実行完了"
実行結果
module load なしでも実行できました。
ただし、Intel MPI モジュールをロードした場合と比べて違いがありました。
- Intel ではなく Amazon の libfabric を使用(
libfabric version: 2.1.0amzn5.0) - ソケットプロバイダーが使われている(
libfabric provider: sockets) - Rank 0 と 1 が存在し、ノード間通信に成功(ここは同じ)
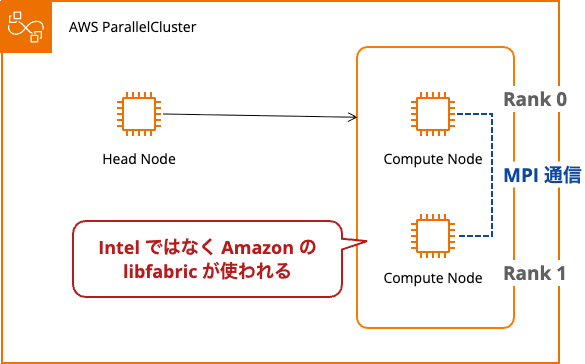
以下のメッセージで確認できます。
Hello from rank 0 out of 2 processes
Hello from rank 1 out of 2 processes
==========================================
ジョブID: 31
ジョブ名: hello_mpi
パーティション: p1
ノード数: 2
総タスク数: 2 (= ノード数 × ntasks-per-node)
使用ノード: p1-dy-c7i-normal-[1-2]
==========================================
プログラム実行開始...
[0] MPI startup(): PMI API: pmi
[0] MPI startup(): Intel(R) MPI Library, Version 2021.16 Build 20250513 (id: a7c135c)
[0] MPI startup(): Copyright (C) 2003-2025 Intel Corporation. All rights reserved.
[0] MPI startup(): library kind: release
[0] MPI startup(): libfabric version: 2.1.0amzn5.0
[0] MPI startup(): libfabric provider: sockets
[0] MPI startup(): Load tuning file: "/opt/intel/mpi/2021.16/opt/mpi/etc/tuning_skx_shm-ofi.dat"
[0] MPI startup(): Number of NICs: 1
[0] MPI startup(): ===== NIC pinning on p1-dy-c7i-normal-1 =====
[0] MPI startup(): Rank Thread id Pin nic
[0] MPI startup(): 0 0 enp39s0
Hello from rank 1 out of 2 processes on host p1-dy-c7i-normal-2
[0] MPI startup(): ===== CPU pinning =====
[0] MPI startup(): Rank Pid Node name Pin cpu
[0] MPI startup(): 0 2529 p1-dy-c7i-normal-1 {0}
[0] MPI startup(): 1 2494 p1-dy-c7i-normal-2 {0}
[0] MPI startup(): I_MPI_HYDRA_BOOTSTRAP_EXEC_EXTRA_ARGS=--external-launcher
[0] MPI startup(): I_MPI_HYDRA_BOOTSTRAP=slurm
[0] MPI startup(): I_MPI_DEBUG=5
[0] MPI startup(): I_MPI_PMI_LIBRARY=/opt/slurm/lib/libpmi.so
Hello from rank 0 out of 2 processes on host p1-dy-c7i-normal-1
プログラム実行完了
なぜ module load なしで動作したのか
調べてみると、コンパイル時に実行ファイルへ RUNPATH が埋め込まれているためでした。
$ readelf -d hello_mpi | grep -E '(RPATH|RUNPATH)'
0x000000000000001d (RUNPATH) Library runpath: [/opt/intel/mpi/2021.16/lib]
実行はできましたが、Intel MPI 最適化版の libfabric を利用する方が望ましいと考えられます。
検証3: module loadなし + I_MPI_PMI_LIBRARYなし
目的
I_MPI_PMI_LIBRARY環境変数でパスを指定する必要性を確認します。
検証方法
ジョブスクリプト内から export I_MPI_PMI_LIBRARY= をコメントアウトします。
ジョブスクリプト
#!/bin/bash
#SBATCH --job-name=hello_mpi # ジョブ名
#SBATCH --partition=p1 # p1キューを使用
#SBATCH --output=hello_mpi_%j.out # 標準出力ファイル(%j はジョブID)
#SBATCH --error=hello_mpi_%j.err # 標準エラー出力ファイル
#SBATCH --nodes=2 # 使用するノード数(c7i.large × 2台)
#SBATCH --ntasks-per-node=1 # ノードあたりのタスク数(物理コア1個 = 1プロセス)
#SBATCH --cpus-per-task=1 # タスクあたりのCPU数
# ジョブ情報の表示
echo "=========================================="
echo "ジョブID: $SLURM_JOB_ID"
echo "ジョブ名: $SLURM_JOB_NAME"
echo "パーティション: $SLURM_JOB_PARTITION"
echo "ノード数: $SLURM_JOB_NUM_NODES"
echo "総タスク数: $SLURM_NTASKS (= ノード数 × ntasks-per-node)"
echo "使用ノード: $SLURM_JOB_NODELIST"
echo "=========================================="
echo ""
# Intel MPIモジュールのロード
# module load intelmpi/2021.16
# PMIライブラリの設定
# export I_MPI_PMI_LIBRARY=/opt/slurm/lib/libpmi.so
# デバッグ情報の出力を有効化
export I_MPI_DEBUG=5
# プログラムの実行
echo ""
echo "プログラム実行開始..."
srun ./hello_mpi
echo ""
echo "プログラム実行完了"
実行結果
シングルトンモードで実行されました。MPI の動作としては期待と異なるため失敗です。
- ノード間で MPI 通信が成立していない(各ノードが独立実行)
Hello from rank 0 out of 1 processesが 2 件出力
- 両方のノードが Rank 0(本来は Rank 0 と 1 になるべき)
PMI server not found警告メッセージが出力(各ノードで 1 件ずつ)
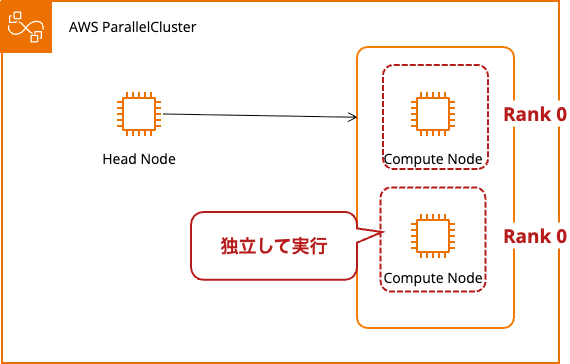
==========================================
ジョブID: 32
ジョブ名: hello_mpi
パーティション: p1
ノード数: 2
総タスク数: 2 (= ノード数 × ntasks-per-node)
使用ノード: p1-dy-c7i-normal-[3-4]
==========================================
プログラム実行開始...
MPI startup(): PMI server not found. Please set I_MPI_PMI_LIBRARY variable if it is not a singleton case.
[0] MPI startup(): PMI API: pmi
[0] MPI startup(): Intel(R) MPI Library, Version 2021.16 Build 20250513 (id: a7c135c)
[0] MPI startup(): Copyright (C) 2003-2025 Intel Corporation. All rights reserved.
[0] MPI startup(): library kind: release
MPI startup(): PMI server not found. Please set I_MPI_PMI_LIBRARY variable if it is not a singleton case.
[0] MPI startup(): PMI API: pmi
[0] MPI startup(): Intel(R) MPI Library, Version 2021.16 Build 20250513 (id: a7c135c)
[0] MPI startup(): Copyright (C) 2003-2025 Intel Corporation. All rights reserved.
[0] MPI startup(): library kind: release
[0] MPI startup(): libfabric version: 2.1.0amzn5.0
[0] MPI startup(): libfabric provider: sockets
[0] MPI startup(): Load tuning file: "/opt/intel/mpi/2021.16/opt/mpi/etc/tuning_skx_shm-ofi.dat"
[0] MPI startup(): Number of NICs: 1
[0] MPI startup(): ===== NIC pinning on p1-dy-c7i-normal-3 =====
[0] MPI startup(): Rank Thread id Pin nic
[0] MPI startup(): 0 0 enp39s0
[0] MPI startup(): ===== CPU pinning =====
[0] MPI startup(): Rank Pid Node name Pin cpu
[0] MPI startup(): 0 2458 p1-dy-c7i-normal-3 {0}
[0] MPI startup(): I_MPI_HYDRA_BOOTSTRAP_EXEC_EXTRA_ARGS=--external-launcher
[0] MPI startup(): I_MPI_HYDRA_BOOTSTRAP=slurm
[0] MPI startup(): I_MPI_DEBUG=5
Hello from rank 0 out of 1 processes on host p1-dy-c7i-normal-3
[0] MPI startup(): libfabric version: 2.1.0amzn5.0
[0] MPI startup(): libfabric provider: sockets
[0] MPI startup(): Load tuning file: "/opt/intel/mpi/2021.16/opt/mpi/etc/tuning_skx_shm-ofi.dat"
[0] MPI startup(): Number of NICs: 1
[0] MPI startup(): ===== NIC pinning on p1-dy-c7i-normal-4 =====
[0] MPI startup(): Rank Thread id Pin nic
[0] MPI startup(): 0 0 enp39s0
[0] MPI startup(): ===== CPU pinning =====
[0] MPI startup(): Rank Pid Node name Pin cpu
[0] MPI startup(): 0 2454 p1-dy-c7i-normal-4 {0}
[0] MPI startup(): I_MPI_HYDRA_BOOTSTRAP_EXEC_EXTRA_ARGS=--external-launcher
[0] MPI startup(): I_MPI_HYDRA_BOOTSTRAP=slurm
[0] MPI startup(): I_MPI_DEBUG=5
Hello from rank 0 out of 1 processes on host p1-dy-c7i-normal-4
プログラム実行完了
検証結果まとめ
| 設定 | 検証1 | 検証2 | 検証3 |
|---|---|---|---|
module load intelmpi |
あり | なし | なし |
I_MPI_PMI_LIBRARY |
あり | あり | なし |
| 実行結果 | 成功 | 成功 | 失敗 |
| プロセス認識 | 2 processes | 2 processes | 1 processes × 2(独立) |
| ノード間通信 | 成功 | 成功 | 失敗 |
| 警告メッセージ | なし | なし | PMI server not found |
| libfabric version | 2.1.0-impi | 2.1.0amzn5.0 | 2.1.0amzn5.0 |
| libfabric provider | tcp | sockets | sockets |
module load の有無による違い
検証 1 と検証 2 を比較しました。module load の有無で使用される libfabric に違いがありました。
module loadあり(検証 1): Intel MPI 付属の libfabric(2.1.0-impi)+ tcp プロバイダーmodule loadなし(検証 2): AWS 提供の libfabric(2.1.0amzn5.0)+ sockets プロバイダー
どちらも正常に動作します。ただし、Intel MPI 用の libfabric を使用する方が最適化の観点から推奨されます。
必要な設定
| 設定項目 | コンパイル時 | 実行時 | 理由 |
|---|---|---|---|
module load intelmpi |
必須 | 不要 | コンパイル時は必須。実行時は RUNPATH で代替可能 |
I_MPI_PMI_LIBRARY |
不要 | 必須 | Slurm との通信に必須 |
実行時に module load が不要なのは、Intel MPI が自動的に RUNPATH を埋め込むためです。ただし、libfabric のことを考えると module load することを推奨します。
まとめ
AWS ParallelCluster で Intel MPI を使用する際のポイントは以下の通りです。
- コンパイル時:
module load intelmpi/xxxが必須 - 実行時:
export I_MPI_PMI_LIBRARY=/opt/slurm/lib/libpmi.soが必須 - 推奨: sbatch で実行するスクリプト内で
module load intelmpi/xxxを記述
おわりに
MPI を使って Hello するだけなのですが、Intel MPI を使う場合はどうなのか経験がなかったので検証していた結果のまとめです。まだ理解不十分なので説明に誤りがあるかもしれません、経験者の方がご覧になったさいはフィードバックいただければ幸いです。








