AWS セキュリティインシデント対応ガイドを要約してみた。これを読んでインシデントに備えよう
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは。
ご機嫌いかがでしょうか。
"No human labor is no human error" が大好きな吉井 亮です。
今回は AWS セキュリティインシデント対応ガイドを要約しています。
AWS 内でのセキュリティインシデントに対する準備、対応、事後対応の基本事項を説明したドキュメントです。
なんと 2023年1月1日にドキュメント更新するというオシャレなドキュメントだったので取り上げてみます。
序章
AWS には共有責任モデルがあり、お客様はクラウド内のセキュリティに責任を負います。
お客様は AWS 上で実行されるアプリケーションのセキュリティベースラインを確立し、そこから逸脱した場合には対応して調査する必要があります。
セキュリティの問題が発生する前に、クラウドチームを準備・教育する必要があります。
セキュリティインシデント対応は複雑になる可能性があるため、反復的なアプローチを実装することをお勧めします。
始める前に
AWS のセキュリティとインシデント対応に関連する標準とフレームワークをよく理解します。
セキュリティ、アイデンティティ、コンプライアンスに関するベストプラクティス
An Overview of the AWS Cloud Adoption Framework Security perspective: compliance and assurance
AWS セキュリティインシデント対応ガイドは Computer Security Incident Handling Guide SP 800-61 r2 に 従っています。NIST によって導入された概念を読んで理解することは、有益な前提条件です。
AWS インシデント対応の側面
インシデント対応が AWS とオンプレミスでどのように異なるかを理解することが重要です。
組織内のすべての AWS 利用者がセキュリティインシデント対応プロセスの基本を理解している必要があり、セキュリティスタッフは、セキュリティ問題への対応方法を理解している必要があります。
教育・トレーニング・経験は不可欠で、実際にインシデントが発生するかなり前に実装されていることが望ましいです。
- 準備
- インシデント検出を有効にし、インシデント対応チームが AWS 内のインシデントを検出し対応できるよう準備します
- 運用
- NIST のインシデント対応フェーズ (検出、分析、封じ込め、根絶、回復) に従って、セキュリティイベントと潜在的なインシデントに対処します
- インシデント後のアクティビディ
- インシデント対応の結果を反復し、有効性の改善を行い、リスクをさらに軽減します
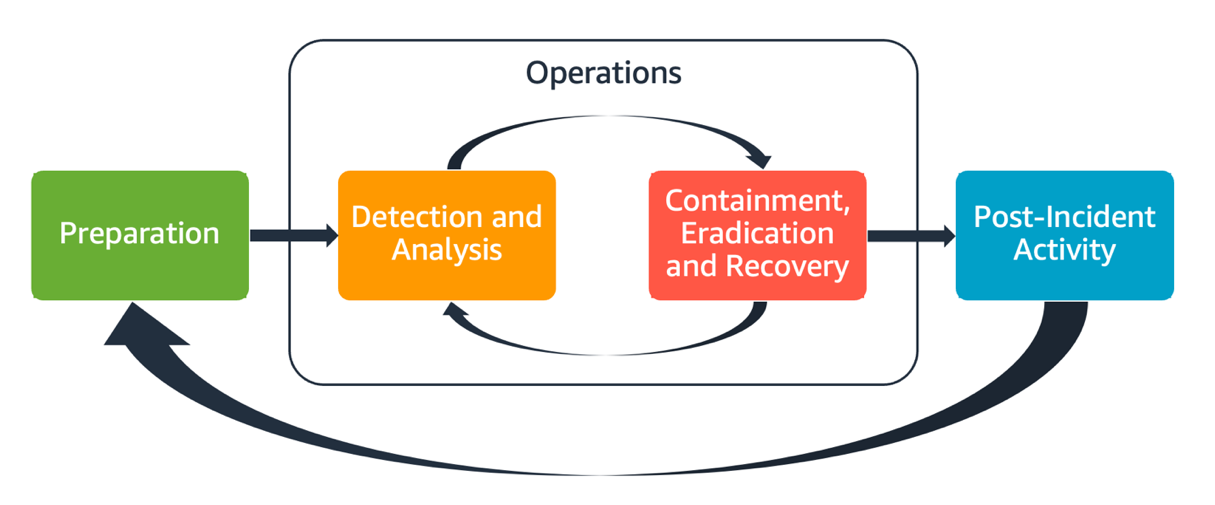
AWS インシデント対応の原則と設計目標
Computer Security Incident Handling Guide SP 800-61 r2 で一般的なプロセスとメカニズムが定義されています。 クラウド環境でのセキュリティインシデントへの対応に関する次の設計目標も検討することをお勧めします。
- 対応目標の確立
- 利害関係者、組織の長、弁護士などを強力して目標を決定します
- 一般的な目標には、問題の封じ込みと軽減、影響から回復、フォレンジック用データの保存、安全な運用への復帰、インシデントからの学習が含まれます
- クラウドを使用して応答する
- イベントとデータが発生するクラウド内に応答パターンを実装します
- 持っているものと必要なものを把握する
- ログ、リソース、スナップショット、その他証跡を一元化されたクラウドアカウントにコピー保存します
- 対象を識別するためにタグやメタデータを使用します
- デプロイメカニズムを使用する
- セキュリティ異常が構成ミスに起因する場合、修正された再デプロイによって根本原因の軽減が成功する可能性があります
- 可能な限り自動化する
- 問題が発生した際には、プログラムでトリアージし対応するメカニズムを構築します
- スケーラブルなソリューションを選択する
- 環境全体にスケーリングする検出および応答メカニズムを実装して、検出から応答までの時間を短縮します
- プロセスを学習して改善する
- プロセス、ツール、または人員のギャップを積極的に特定し、それらを修正するための計画を実装します
クラウドの実装を計画する際には、セキュリティインシデントへの対応についてよく考えることをお勧めします。
セキュリティインシデント ドメイン
セキュリティインシデントが発生する可能性があるお客様の責任範囲には3つのドメインがあります。
ドメインが異なれば、必要な知識、ツール、対応プロセスも異なります。
- サービス ドメイン
- AWS アカウント、IAM パーミッション、リソースメタデータ、ビリング、その他
- 排他的な AWS API、または構成やパーミションのミスに根本原因がある可能性があります
- CloudTrail などのサービス志向ログを分析します
- インフラストラクチャ ドメイン
- コンピュート上のプロセスやデータ
- ネットワーク関連のアクティビティ
- デジタルフォレンジック/インシデント対応 (DFIR) ツールを利用して、フォレンジック分析と調査を行います
- アプリケーション ドメイン
- アプリケーションまたはコード
- 驚異検出と対応のプレイプックを含めます
- 自動化された取得、回復、展開を使用して管理します
AWS でのインシデント対応の主な違い
AWS とオンプレミスでの対応の違いを理解します。
違い#1 共同責任としてのセキュリティ
セキュリティとコンプライアンスの責任は、AWS とお客様の間で共有されます。
責任共有モデルの理解によってお客様の運用負荷が軽減されます。
クラウドで共有される責任が変化すると、インシデント対応も変化します。
違い#2 クラウド サービス ドメイン
サービスドメインは新しいドメインです。
サービスドメインのレスポンスは、従来のホストベースおよびネットワークベースではなく、API コールによって行われます。サービス ドメインでは、影響を受けるリソースのオペレーティングシステムと対話しません。
違い#3 インフラストラクチャをプロビジョニングするための API
AWS の利用者は、世界中の多くの地理的な場所で利用可能なパブリックおよびプライベートエンドポイントを介して RESTful API を使用して、AWS クラウドと対話します。
お客様は、AWS 認証情報を使用してこれらの API にアクセスします。
これらの API エンドポイントは、企業ネットワークの外部からアクセスできます。
これは資格情報が漏洩した際には外部から API を使用されるというインシデントに対応するために必要な知識です。
違い#4 クラウドの動的な性質
クラウドは動的です。インシデントの調査時に対象リソースが存在しなくなったり変更される可能性があります。
AWS リソースの作成・変更・削除を追跡する方法を知ることはインシデント分析によって重要です。
AWS Config を使用して AWS リソースの構成履歴を追跡可能です。
違い#5 データ アクセス
クラウドではデータアクセスも異なります。
セキュリティ調査に必要なデータを収集するために、必ずしもサーバーへログインする必要はありません。
データはネットワーク経由および API 呼び出しを通じて収集されます。API を介したデータ収集方法を理解する必要があります。
違い#6 自動化の重要性
CloudFormation などのネイティブ IaC サービスによって自動化が促進されます。
これによりインシデント対応の実装が高度に自動化されます。特に人的ミスを避けるために望ましいことです。
これらの違いへの対処
これらの違いに対処するには、次のセクションで概説する手順に従って、人、プロセス、およびテクノロジ全体のインシデント対応プログラムが十分に準備されていることを確認します。
準備
準備は効果的なインシデント対応にとって重要です。準備は、3つのドメインにわたって行われます。
- 人員
- インシデント対応に関連する利害関係者を特定します
- インシデント対応チームをトレーニングします
- スケーラブルでプロアクティブなセキリティ文化を熟成します
- プロセス
- アーキテクチャの文書化をします
- 徹底的なインシデント対応計画を策定します
- 一貫した対応のためのプレイブックを作成します
- テクノロジー
- アクセス管理を導入します
- 必要なログの集約と監視をします
- 効果的なアラートの実装をします
- 対応と調査機能の開発が必要です
この3つすべてがなければ、インシデント対応プログラムは完全ではなく、効果的ではありません。
役割と責任を定義する
人事 (HR)、経営陣、法務の代表者など、インシデントの際に責任を負い、説明責任を負い、相談を受けたり、情報を提供したりする多くの人々がいます。
何をすべきか、何をすべきでないかを規定する各地域の法律があることに注意してください。
セキュリティ対応計画のために、RACI (Responsible、Accountable、Consulted、Informed) チャートを作成すると、迅速かつ直接的なコミュニケーションが可能になり、イベントのさまざまな段階でのリーダーシップを明確に説明できます。
インシデントの通知には、影響を受けるアプリケーションとリソースの所有者/開発者を含めることが重要です。なぜなら、彼らは影響の測定に役立つ情報とコンテキストを提供できる専門家 (SME) だからです。
ただ、インシデント対応を専門家に頼る前に、所有者/開発者と練習を重ね関係を構築しておくことが重要です。 SME はセキュリティ対応チームの手に負えない状況で行動することが望ましいです。
自分たちの組織に対応するスキルが無い場合は、外部のパートナーを頼ることも検討します。
インシデント対応スタッフのトレーニング
セキュリティイベントに適切に対応するには、組織が使用するテクノロジについてインシデント対応スタッフをトレーニングすることが重要です。
AWS の基盤、IAM、AWS Organizations、AWS のログ記録と監視サービス、および AWS のセキュリティ サービスを理解することが重要です。
AWS はセキュリティワークショップを提供しています。AWS のセキュリティと監視サービスを実際に体験できます。
依存関係を回避し、応答時間を短縮するには、AWS 環境に関する内部の知識を文書化し、アクセス可能にし、セキュリティ アナリストが理解できるようにする必要があります。
これは後述します。
AWS 対応チームとサポートを理解する
AWS サポート
AWS サポートでは様々なプランを提供しています。AWS 環境の計画、デプロイ、最適化に役立つテクニカル サポートやその他のリソースが必要な場合は、最適なサポートプランを選択可能です。
AWS カスタマー インシデント対応チーム (CIRT)
CIRT は24時間365日の専門グローバル AWS チームです。
AWS サポートケースを通じて CIRT を利用できます。
DDoS 対応のサポート
AWS は AWS Shield を提供しています。これは管理された分散型サービス拒否 (DDoS) 保護サービスです。
AWS Shield には 2 つの層があります(Shield Standard と Shield Advanced)。これら 2 つの層の違いについては、Shield のドキュメントを参照してください。
AWS マネージド サービス (AMS)
AWS マネージド サービスは、AWS インフラストラクチャの継続的な管理を提供するため、アプリケーションに集中できます。
AMS は、一連のセキュリティ検出制御を展開する責任を負い、アラートへの24時間365日の最初の対応を提供します。
インシデント対応計画の策定とテスト
インシデント対応のために作成する最初の文書は、インシデント対応計画です。インシデント対応計画は、インシデント対応プログラムと戦略の基盤となるように設計されています。
- インシデント対応チームの概要
- インシデント対応チームの目標と機能の概要を説明します
- 役割と責任
- インシデント対応関係者を一覧表示し、インシデント発生時の役割を詳しく説明します
- コミュニケーション計画
- 連絡先とインシデント発生時のコミュニケーション方法の詳細を記述します
- インシデント通信のバックアップとして帯域外通信を使用することをお勧めします。帯域外通信を提供するアプリケーショの例が AWS Wickerです。
- インシデント対応のフェーズと実行するアクション
- インシデント対応のフェーズ (検出、分析、根絶、封じ込め、回復など) の列挙と、フェーズ内で実行するハイレベルアクションを記述します
- インシデントの重大度と優先度の定義
- インシデントの重大度を分類する方法、インシデントに優先順位を付ける方法、重大度の定義がエスカレーション手順に与える影響について詳しく説明します
アーキテクチャ図を文書化して一元化する
セキュリティイベントに迅速かつ正確に対応するには、システムとネットワークがどのように設計されているかを理解する必要があります。
また、ドキュメントが最新であり定期的に更新されていることを確認する必要があります。
次のような項目を含めると良いでしょう。
- AWS アカウント構造
- AWS アカウントはいくつありますか?
- これらの AWS アカウントはどのように編成されていますか?
- AWS アカウントのビジネス所有者は誰ですか?
- SCP を使用していますか?もしそうなら、SCP を使用してどのような組織的ガードレールが実装されていますか?
- 利用できる地域やサービスを限定していますか?
- ビジネス ユニットと環境 (開発/テスト/本番) の間にはどのような違いがありますか?
- AWS サービスパターン
- AWS のどのサービスを使用していますか?
- 最も広く使用されている AWS のサービスは何ですか?
- アーキテクチャパターン
- どのようなクラウド アーキテクチャを使用していますか?
- AWS 認証パターン
- 開発者は通常、AWS に対してどのように認証しますか?
- IAM ロールまたはユーザー (またはその両方) を使用していますか?
- AWS への認証は ID プロバイダー (IdP) に接続されていますか?
- IAM ロールまたはユーザーを従業員またはシステムにどのようにマッピングしますか?
- 誰かが承認されなくなった場合、アクセスはどのように取り消されますか?
- AWS 認可パターン
- 開発者はどの IAM ポリシーを使用していますか?
- リソースベースのポリシーを使用していますか?
- ロギングとモニタリング
- どのログソースを使用しており、それらはどこに保存されていますか?
- AWS CloudTrail ログを集約していますか? もしそうなら、それらはどこに保管されていますか?
- CloudTrail ログをどのようにクエリしますか?
- Amazon GuardDuty を有効にしていますか?
- GuardDuty の調査結果 (コンソール、チケット システム、SIEM など) にどのようにアクセスしますか?
- 調査結果またはイベントは SIEM に集約されていますか?
- チケットは自動的に作成されますか?
- 調査のためにログを分析するために、どのようなツールが用意されていますか?
- ネットワークトポロジー
- ネットワーク上のデバイス、エンドポイント、および接続は、物理的または論理的にどのように配置されていますか?
- ネットワークはどのように AWS に接続されていますか?
- ネットワーク トラフィックは環境間でどのようにフィルタリングされますか?
- 外部インフラストラクチャ
- 外部向けアプリケーションはどのようにデプロイされますか?
- どの AWS リソースがパブリックにアクセスできますか?
- 外部に面しているインフラストラクチャを含む AWS アカウントはどれですか?
- どのような DDoS または外部フィルタリングがありますか?
インシデント対応のプレイブックを作成する
インシデント対応プレイブックは、セキュリティイベントが発生したときに従うべき一連の規範的なガイダンスと手順を提供します。
プレイブックは、次のようなインシデントシナリオ用に作成する必要があります。
- 予想されるインシデント
- サービス拒否 (DoS)、ランサムウェア、資格情報の侵害などのインシデント用プレイブック
- 既知のセキュリティの検出結果またはアラート
- GuardDuty の検出結果など、既知のセキュリティの検出結果およびアラート用プレイブック
プレイブックには、潜在的なセキュリティインシデントを適切に調査して対応するために技術的な手順が含まれている必要があります。
プレイブックに含める項目は次のとおりです。
- プレイブックの概要 – このプレイブックで対処するリスクまたはインシデントのシナリオは? プレイブックの目標は何ですか?
- 前提条件 – このインシデントシナリオには、どのようなログと検出メカニズムが必要ですか? 予想される通知は何ですか?
- 利害関係者情報 – 誰が関与しており、その連絡先情報は? 各利害関係者の責任は何ですか?
- 対応手順 – インシデント対応のフェーズ全体で、どのような戦術的手順を実行する必要がありますか? アナリストはどのようなクエリを実行する必要がありますか? 望ましい結果を得るには、どのコードを実行する必要がありますか?
- 検出 – インシデントはどのように検出されますか?
- 分析 – 影響の範囲はどのように決定されますか?
- 封じ込め – 範囲を制限するために、インシデントをどのように分離しますか?
- 根絶 – 環境から脅威をどのように除去しますか?
- 回復 – 影響を受けたシステムまたはリソースをどのように本番環境に戻すか?
- 期待される結果 – クエリとコードが実行された後、プレイブックの期待される結果は何ですか?
公式ドキュメントにはサンプルのプレイブックが紹介されています。参考にどうぞ。
Appendix B: AWS incident response resources
定期的なシミュレーションを実行する
組織のインシデント対応能力を継続的に見直すための手段の1つがシミュレーションです。
シミュレーションには、主に次の3つのタイプがあります。
- 卓上演習
- ディスカッションベースのセッションです
- プロセス、人、およびコラボレーションに焦点を当てています
- パープルチームの演習
- ブルーチーム(インシデント対応者)とレッドチーム(脅威アクター)の分かれて協力的に実施します
- 検出メカニズム、ツール、およびインシデント対応の取り組みをサポートする標準操作手順に焦点を当てます
- レッドチームの演習
- レッドチームがシミュレートされた攻撃を実施します
- ブルーチームは演習の範囲と期間について必ずしも知っているわけではありません
- 実際のインシデントにどのように対応するかについて、より現実的な評価を行います
エクササイズのライフサイクル
シミュレーションのタイプに関係なく、シミュレーションは通常、次の手順に従います。
- 主要な演習要素を定義する
- 主要な利害関係者を特定する
- シナリオを構築してテストする
- シミュレーションを促進する
- アフターアクションレポート (AAR) を作成する
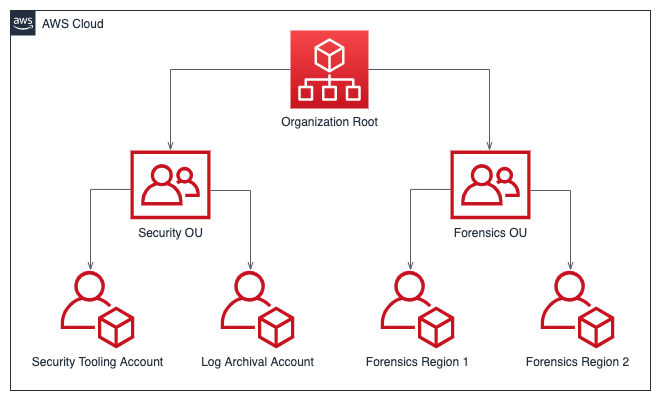
AWS アカウント構造の開発
AWS Organizations を使いアカウントと一元的に管理します。
インシデント対応の場合、セキュリティ OU とフォレンジック OU を含む、インシデント対応の機能をサポートする AWS アカウント構造を持つと役立ちます。
セキュリティ OU
セキュリティ OU 内には、次のアカウントが必要です。
- ログアーカイブ
- セキュリティツール
- セキュリティサービスを一元化
フォレンジック OU
ビジネスおよび運用モデルに最適な方法に応じて、単一のフォレンジック アカウントを実装するか、運用する地域ごとにアカウントを実装するオプションがあります。
次の図はアカウント構造のサンプルです。
タグ付け戦略の開発と実装
タグを作成して、目的、所有者、環境、処理されるデータの種類、および選択したその他の基準によってリソースを分類します。
一貫したタグ付け戦略を使用すると、AWS リソースに関するコンテキスト情報をすばやく識別して識別できるため、応答時間が短縮されます。タグは、応答の自動化を開始するメカニズムとしても機能します。
AWS アカウントの連絡先情報を更新する
セキュリティ、請求、運用などのトピックに関する AWS からの重要な通知を適切な関係者が受け取れるように、正確で最新の連絡先情報を保持することが重要です。
連絡先情報の違いや更新方法は Updating contact information を参照ください。
AWS アカウントへのアクセスを準備する
インシデントの間、インシデント対応チームは、インシデントに関係する環境とリソースにアクセスできる必要があります。
チームが遂行できるよう事前に最小権限を持った IAM ユーザーまたはロールを用意しておきます。
これらは日常の活動には利用しません。
脅威モデルの開発
脅威モデルを開発することで、組織は、権限のないユーザーよりも先に脅威と軽減策を特定できます。
脅威のモデル化には多くの戦略とアプローチがあります。 How to approach threat modeling を参照ください。
サイバー脅威インテリジェンスを統合して使用する
サイバー脅威インテリジェンスは、攻撃者の意図、機会、および能力に関するデータと分析です。
インシデントを早期に検出し、攻撃者の行動をよりよく理解するのに役立ちます。
サイバー脅威インテリジェンスには、IP アドレスやマルウェアのファイル ハッシュなどの静的指標が含まれます。また、行動パターンや意図などの高レベルの情報も含まれます。多数のサイバー セキュリティ ベンダーやオープンソース リポジトリから脅威インテリジェンスを収集できます。
分析とアラート用のログを選択して設定する
セキュリティ調査のために関連するログをキャプチャします。
CloudTrail はAWS アカウントに対して行われた API 呼び出しを追跡するログサービスです。
CloudTrail イベント履歴から取得できる管理イベントは90日です。それより長く保持するには S3 バケットへトレイルを保存するよう設定変更をします。また、CloudTrail Lake を作成して最大7年間保持することも可能です。
VPC フローログを作成しネットワークトラフィックを保持します。
VPC、サブネット、またはネットワーク インターフェイスの VPC フロー ログを作成できます。
Route 53 リゾルバークエリログを使用して DNS ログを保持します。
こちらにロギングの詳しい情報が記載されています。参照ください。
ログのクエリメカニズムを選択して実装する
AWS でログクエリに使用できる主なサービスは、CloudWatch Logs Insights、Athena、OpenSeach です。サードパーティの SIEM を使用することも可能です。
ログクエリツールを選択するプロセスでは、セキュリティ操作の人、プロセス、およびテクノロジの側面を考慮する必要があります。運用、ビジネス、およびセキュリティの要件を満たし、長期的にアクセス可能で保守可能なツールを選択してください。
フォレンジック機能の開発
セキュリティインシデントが発生する前に、セキュリティイベントの調査をサポートするフォレンジック機能の開発を検討してください。
Guide to Integrating Forensic Techniques into Incident Response に沿ってガイダンスします。
AWS でのフォレンジック
従来のオンプレミスフォレンジックの概念が AWS にも適用されます。 Forensic investigation environment strategies in the AWS Cloud はフォレンジックの専門知識を AWS に移行するための重要な情報を提供します。
次の4つのフェーズでフォレンジックに適した方法論を実行するために必要なテクノロジーを定義します。
- 収集
- 調査
- 分析
- レポート
バックアップとスナップショットをキャプチャする
重要なシステムとデータベースのバックアップを取得することは、セキュリティインシデントからの回復とフォレンジックにとって重要です。バックアップがあれば、システムを以前の安全な状態に復元できます。
バックアップを保護するガイダンスは Top 10 security best practices for securing backups in AWS を参照ください。
AWS でのフォレンジックの自動化
多数のインスタンスとアカウントにわたって関連する証拠を迅速に収集および分析するためにフォレンジックの自動化を導入する必要があります。
フォレンジック自動化に役立つ情報は Appendix B: AWS incident response resources に記載されています。参照ください。
運用
運用は、インシデント対応を実行するための中核です。
検出
アラートソース
アラートは、検出フェーズの主要コンポーネントです。インシデント対応プロセスを開始するためのアラートを生成します。
以下のソースを利用してアラートを定義します。
- AWS サービス
- GuardDuty、Security Hub、Macie、Inspector、Config、IAM Access Analyzer、Network Access Analyzer など
- ログ
- 請求
- パートナーツール
- AWS trust and safety
- AWS サポートは悪意のある活動を特定した場合、お客様に連絡する場合があります
- 連絡窓口
- セキュリティ異常をセキュリティチームに知らせるためのツール。チケットシステム、問い合わせフォーム等
セキュリティ制御エンジニアリングの一環としての検出
検出メカニズムは、セキュリティ コントロール開発の不可欠な部分です。発見的および応答的コントロールを構築する必要があります。
(例)
GuardDuty を使用しています。
「Impact:EC2/SuspiciousDomainRequest.Reputation」が検知されています。
EC2 が疑いのあるドメイン名を照会していることが判明しました。
GuardDuty の重大度は低く設定されています。
調査をしたところ、アカウントが攻撃され数百の EC2 インスタンスが起動されていました。
インシデント対応チームは、このアラートの重大度を高めて対応しています。
ここでのポイントは、GuardDuty の重大度は変更できないということです。アラートメカニズムで重大度を上げるよう設定しないといけません。
GuardDuty の重大度が低だとしても、それが短い時間の間に大量に発生しているようであれば重大度:高でアラートするようにします。
検出制御の実装
検出制御がどのように実装されているかを理解することが重要です。
- 行動検出
- AI/ML を用いた検出
- 必ずしも実際のイベントを反映しているとは限りません
- ルールベースの検出
脅威モデル内のすべてのアクティビティに対して常にルールベースのアラートを実装できるとは限らないため、行動ベースのアラートとルールベースのアラートの両方を組み合わせて実装することをお勧めします。
人物ベースの検出
もう1つの重要な検出源は、顧客の組織の内部または外部の人々からのものです。
- 内部
- 従業員
- 請負業者
- 外部
- セキュリティ研究者
- 法執行機関
- ニュース
- ソーシャルメディア
分析
検出に使用されるログの多くは分析にも使用され、クエリツールの構成が必要になります。
分析フェーズでは、アラートの検証、範囲の定義、侵害の可能性の影響の評価を目的として、包括的なログ分析を実行します。
証拠の収集と分析
フォレンジックとは、インシデント対応中に証拠を収集して分析するプロセスです。
フォレンジックプロセスには、次の基本的な特徴があります。
- 一貫性
- 逸脱することなく正確な手順に従います
- 反復可能
- 同じアーティファクトに対して実行すると同じ結果が生成されます
- 通例
- 公に文書化され、広く採用されています
関連するアーティファクトを収集する
関連するアラートと影響と範囲の評価に基づいて、さらなる調査と分析に関連するデータを収集する必要があります。
- サービス/コントロールプレーンログ
- CloudTrail
- S3 データイベント
- VPC フローログ
- データ
- S3 メタデータとオブジェクト
- リソース
- データベースインスタンス
- EC2 インスタンス
EC2 インスタンスからデータを取得して保持するための手順例です。
- インスタンス メタデータの取得 (インスタンス ID、タイプ、IP アドレス、VPC/サブネット ID、リージョン、AMI ID、アタッチされたセキュリティ グループ、起動時間)
- インスタンスの保護とタグを有効にします
- 終了保護などのインスタンス保護を有効
- 接続された EBS ボリュームの 終了時の削除 属性を無効
- 適切なタグ付け、例えば「検疫中」など
- EBS スナップショットの取得
- メモリダンプの取得
- (オプション) ライブ レスポンス/アーティファクト コレクションを実行します
- ビジネス上または運用上の正当な理由がある場合にのみ、リモートシェルでアーティファクトを収集
- インスタンスの廃止
- AutoScaling グループからインスタンスを切り離します
- ロードバランサーから切り離します
- インスタンスプロファイルを最小権限に変更
- インスタンスを分離または封じ込めます
- 組織で予め決められた処理を行います
最終レポート
分析と調査中に、実行されたアクション、実行された分析、および特定された情報を文書化して、後続のフェーズで使用し、最終的にはレポートにします。
封じ込め
NIST SP 800-61 Computer Security Incident Handling Guide では適切な封じ込め戦略を決定するためのいくつかの基準を解説しています。
そのなかでも、AWS のサービスに関しては、基本的な封じ込め手順を3つのカテゴリに絞り込むことができます。
- ソースの封じ込め
- 分離用セキュリティグループを作成しておき、対象リソースに適用します (元のセキュリティグループは外す)
- S3 バケットポリシーを制限し、疑わしいソースからのアクセスを禁止します
- AWS WAF で疑わしい IP アドレスまたはネットワーク範囲をブロックします
- アクセスの封じ込め
- セキュリティイベント発生中は、IAM プリンシパルに割り当てられているポリシーをさらに厳格にします
- アクセスキーが侵害された可能性がある場合は、アクセスキーを取り消します
- 一時的なセキュリティ認証を使用している場合は、厳格な IAM ポリシーを適用します
- SQL インジェクションやクロスサイトスクリプティング (XSS) を含むリクエストなど、一般的な悪意のあるトラフィックパターンを AWS WAF でブロックします
- 宛先の封じ込め
- NACL に拒否ルールを追加して、特定のアクセスをブロックします
- リソースをシャットダウンして、不正使用の影響を抑えます
- 分離 VPC を事前に作成しておきます。セキュリティイベント中に対象リソースを分離 VPC に移動します。
根絶
根絶とは、アカウントを安全な状態に戻すために、疑わしいリソースまたは許可されていないリソースを削除することです。
NIST SP 800-61 Computer Security Incident Handling Guide では根絶のためのいくつかの手順を紹介しています。
- 悪用されたすべての脆弱性を特定して軽減します
- マルウェアや不適切なコンポーネントを削除します
- 検出と分析の手順を繰り返して、影響を受ける他のすべてのホストを特定し、それらのインシデントを封じ込めます
根絶の最初のステップは、AWS アカウント内で影響を受けたリソースを特定することです。
リソースのリストを特定したら、それぞれを評価して、リソースが削除または復元された場合のビジネスへの影響を判断します。
ビジネスへの影響分析が完了したら、適切な修復を実行する必要があります。
特定された影響を受けるリソースを根絶したら、AWS はアカウントのセキュリティレビューを実行することをお勧めします。
根絶は、インシデント対応プロセスの 1 つのステップであり、インシデントと影響を受けるリソースに応じて、手動または自動で行うことができます。
回復
システムを既知の安全な状態に復元し、復元前にバックアップが安全であるかインシデントの影響を受けていないことを検証し、復元後にシステムが正常に動作していることをテストして検証し、セキュリティイベントに関連する脆弱性に対処するプロセスです。
NIST SP 800-61 Computer Security Incident Handling Guide には、システムを回復するためのいくつかの手順が記載されています。
- クリーンバックアップからのシステム復元
- 復元する前にバックアップを評価し、被害を受けていないことを確認します
- 定期的な復元テストを行い、バックアップメカニズムが適切に機能しており、データの整合性が RPO を満たしていることを確認します
- 新しい AWS アカウントでゼロから再構築します
- 侵害されたファイルをクリーンなバージョンに置き換えます
- 回復しようとしているファイルが完全にクリーンであることを確認します
- パッチの適用
- パスワードの変更
- 悪用された可能性がある IAM プリンシパルを含みます
- ネットワーク境界セキュリティの強化
回復が完了したら、インシデント対応のポリシー、手順、およびガイドに学んだ教訓を取り入れます。
インシデント後のアクティビディ
脅威の状況は常に変化しており、環境を効果的に保護する組織の能力においても動的であることが重要です。
インシデントとシミュレーションの結果を反復しましょう。
インシデントから学ぶためのフレームワークを確立する
教訓から学ぶ方法論を確立することは、インシデント対応能力の向上に役立つだけでなく、インシデントの再発防止にも役立ちます。
ハイレベルで教訓フレームワークを実装します。次は例です。
- レッスンはいつ開催されますか?
- 教訓のプロセスには何が含まれますか?
- 学んだ教訓はどのように実行されますか?
- プロセスには誰がどのように関与していますか?
- 改善の領域はどのように特定されますか?
- 改善が効果的に追跡され、実施されることをどのように保証しますか?
ハイレベルな事項だけはなく、実用的な改善につながら質問を繰り返します。
- 事件は何でしたか?
- インシデントが最初に特定されたのはいつですか。
- どのように特定されましたか?
他のすべての質問は 公式ドキュメント を参照ください。要約では書ききれない有用な質問が列挙されています。
成功の指標を確立する
運用の改善に取り組む組織にとってインシデント対応に共通するいくつかの指標があります。
- 平均検出時間
- セキュリティインシデントの可能性を発見するのにかかる平均時間
- 平均承認時間
- セキュリティインシデントの可能性を認識および優先順位付けするのにかかる平均時間
- 平均応答時間
- セキュリティインシデントの可能性への初期対応を開始するのにかかる平均時間
- 平均収容時間
- セキュリティインシデントの可能性を封じ込めるのにかかる平均時間
- 平均回復時間
- セキュリティインシデントの可能性から安全なオペレーションを完全に戻すまでにかかる平均時間
- 攻撃者の滞留時間
- 攻撃者がシステムまたは環境にアクセスした平均時間
侵害の指標(IOC)を使用する
侵害の指標 (Indicator of Compromise) はインシデントを識別するアーティファクトです。
- ネットワークレベルのアーティファクト
- IP アドレス
- ドメイン
- TCP フラグ
- ペイロード
- システムまたはホストレベルのアーティファクト
- 実行可能ファイル
- ファイル名とハッシュ
- ログファイルエントリ
- レジストリエントリ
- 特定のファイルまたは一連のファイルとレジストリアイテム
- その他
- 特定の順序で実行されるアクション
- 特定のサーバーからのシステムへのログイン
- 特定の異常なコマンドの連続
IOC を積極的に特定、収集、保存し、より包括的な脅威インテリジェンスプログラムの一部として IOC データベースを構築します。
教育と訓練を継続する
教育とトレーニングは、進化する継続的な取り組みであり、意図的に追求し、維持する必要があります。
1つのアプローチは、継続的な教育をチームの目標と運用の標準的な部分として採用することです。教育は「一度で終わり」ではありません。教育を継続的に追求する必要があります。
もう1つのアプローチは、シミュレーションが定期的に (たとえば、四半期ごとに) 実行され、ビジネスの特定の結果に焦点を当てていることを確認することです。
おまけ
公式でサマリーされていました。このドキュメントは本当に素晴らしいです。気に入りました。
Summary of preparation items
Conclusion operations
Conclusion Post-incident activity
参考
MITRE ATT&CK®
NIST threat intelligence
NIST SP 800-61 Computer Security Incident Handling Guide
以上、吉井 亮 がお届けしました。