![[AWS Step Functions / AWS CDK] EvaluateExpressionタスクを使って配列の操作(要素追加、結合、Map処理など)をしてみた](https://devio2023-media.developers.io/wp-content/uploads/2019/04/aws-step-functions.png)
[AWS Step Functions / AWS CDK] EvaluateExpressionタスクを使って配列の操作(要素追加、結合、Map処理など)をしてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部 IoT事業部の若槻です。
前回のエントリに引き続き、AWS Step Functions(AWS CDK)のEvaluateExpression Classを使ってみたいと思います。
今回は、EvaluateExpressionタスクを使って**配列の操作(要素追加、結合、Map処理など)**をしてみました。
やってみた
本記事ではEvaluateExpressionを利用して配列に対する次の処理を行うタスクを実装してみます。
- 要素追加
- 結合
- Map処理
- 配列長の取得
- 最大値(最小値)の要素の取得
- 要素の並べ替え
※配列のフィルターやスライス(部分選択)であればJSONPathの記述だけで実装できます。詳しくは下記をご覧ください。
実装
AWS CDK v2(TypeScript)で次のようなCDKスタックを作成します。
import { Construct } from 'constructs';
import {
aws_stepfunctions,
aws_stepfunctions_tasks,
Stack,
StackProps,
} from 'aws-cdk-lib';
export class ProcessStack extends Stack {
constructor(scope: Construct, id: string, props: StackProps) {
super(scope, id, props);
// 要素追加
const evaluateTask1 = new aws_stepfunctions_tasks.EvaluateExpression(
this,
'evaluateTask1',
{
expression: aws_stepfunctions.JsonPath.format(
'{}.concat("{}")',
aws_stepfunctions.JsonPath.stringAt('$.array1'),
aws_stepfunctions.JsonPath.stringAt('$.append'),
),
resultPath: '$.evaluateTask1',
},
);
// 結合
const evaluateTask2 = new aws_stepfunctions_tasks.EvaluateExpression(
this,
'evaluateTask2',
{
expression: aws_stepfunctions.JsonPath.format(
'{}.concat({})',
aws_stepfunctions.JsonPath.stringAt('$.array1'),
aws_stepfunctions.JsonPath.stringAt('$.array2'),
),
resultPath: '$.evaluateTask2',
},
);
// Map処理
const evaluateTask3 = new aws_stepfunctions_tasks.EvaluateExpression(
this,
'evaluateTask3',
{
expression: aws_stepfunctions.JsonPath.format(
'{}.map( d => "new" + d )',
aws_stepfunctions.JsonPath.stringAt('$.array1'),
),
resultPath: '$.evaluateTask3',
},
);
// 配列長の取得
const evaluateTask4 = new aws_stepfunctions_tasks.EvaluateExpression(
this,
'evaluateTask4',
{
expression: aws_stepfunctions.JsonPath.format(
'{}.length',
aws_stepfunctions.JsonPath.stringAt('$.array1'),
),
resultPath: '$.evaluateTask4',
},
);
// 最大値(最小値)の要素の取得
const evaluateTask5 = new aws_stepfunctions_tasks.EvaluateExpression(
this,
'evaluateTask5',
{
expression: 'Math.max(1, 3, 2)',
//expression: 'Math.min(1, 3, 2)',
resultPath: '$.evaluateTask5',
},
);
// 要素の並べ替え
const evaluateTask6 = new aws_stepfunctions_tasks.EvaluateExpression(
this,
'evaluateTask6',
{
expression: '[1, 30, 4, 21, 100000].sort()',
resultPath: '$.evaluateTask6',
},
);
// ステートマシン
new aws_stepfunctions.StateMachine(this, 'stateMachine', {
stateMachineName: 'stateMachine',
definition: evaluateTask1
.next(evaluateTask2)
.next(evaluateTask3)
.next(evaluateTask4)
.next(evaluateTask5)
.next(evaluateTask6),
});
}
}
上記をCDK Deployしてスタックをデプロイします。これにより次のDefinitionのステートマシンが作成されます。
{
"StartAt": "evaluateTask1",
"States": {
"evaluateTask1": {
"Next": "evaluateTask2",
"Type": "Task",
"ResultPath": "$.evaluateTask1",
"Resource": "arn:aws:lambda:ap-northeast-1:XXXXXXXXXXXX:function:ProcessStack-Evalda2d1181604e4a4586941a6abd7fe42dF-HvPxBeqhWg2f",
"Parameters": {
"expression.$": "States.Format('{}.concat(\"{}\")', $.array1, $.append)",
"expressionAttributeValues": {}
}
},
"evaluateTask2": {
"Next": "evaluateTask3",
"Type": "Task",
"ResultPath": "$.evaluateTask2",
"Resource": "arn:aws:lambda:ap-northeast-1:XXXXXXXXXXXX:function:ProcessStack-Evalda2d1181604e4a4586941a6abd7fe42dF-HvPxBeqhWg2f",
"Parameters": {
"expression.$": "States.Format('{}.concat({})', $.array1, $.array2)",
"expressionAttributeValues": {}
}
},
"evaluateTask3": {
"Next": "evaluateTask4",
"Type": "Task",
"ResultPath": "$.evaluateTask3",
"Resource": "arn:aws:lambda:ap-northeast-1:XXXXXXXXXXXX:function:ProcessStack-Evalda2d1181604e4a4586941a6abd7fe42dF-HvPxBeqhWg2f",
"Parameters": {
"expression.$": "States.Format('{}.map( d => \"new\" + d )', $.array1)",
"expressionAttributeValues": {}
}
},
"evaluateTask4": {
"Next": "evaluateTask5",
"Type": "Task",
"ResultPath": "$.evaluateTask4",
"Resource": "arn:aws:lambda:ap-northeast-1:XXXXXXXXXXXX:function:ProcessStack-Evalda2d1181604e4a4586941a6abd7fe42dF-HvPxBeqhWg2f",
"Parameters": {
"expression.$": "States.Format('{}.length', $.array1)",
"expressionAttributeValues": {}
}
},
"evaluateTask5": {
"Next": "evaluateTask6",
"Type": "Task",
"ResultPath": "$.evaluateTask5",
"Resource": "arn:aws:lambda:ap-northeast-1:XXXXXXXXXXXX:function:ProcessStack-Evalda2d1181604e4a4586941a6abd7fe42dF-HvPxBeqhWg2f",
"Parameters": {
"expression": "Math.max(1, 3, 2)",
"expressionAttributeValues": {}
}
},
"evaluateTask6": {
"End": true,
"Type": "Task",
"ResultPath": "$.evaluateTask6",
"Resource": "arn:aws:lambda:ap-northeast-1:XXXXXXXXXXXX:function:ProcessStack-Evalda2d1181604e4a4586941a6abd7fe42dF-HvPxBeqhWg2f",
"Parameters": {
"expression": "[1, 30, 4, 21, 100000].sort()",
"expressionAttributeValues": {}
}
}
}
}
動作確認
次の入力を指定してステートマシンを実行します。
{
"array1": [
"ぶた",
"やぎ",
"ひつじ"
],
"array2": [
"とり",
"うさぎ"
],
"append": "うし"
}
実行が成功しました。それぞれのタスクの結果を見てみます。
{}.concat("{}")により配列への要素追加ができています!
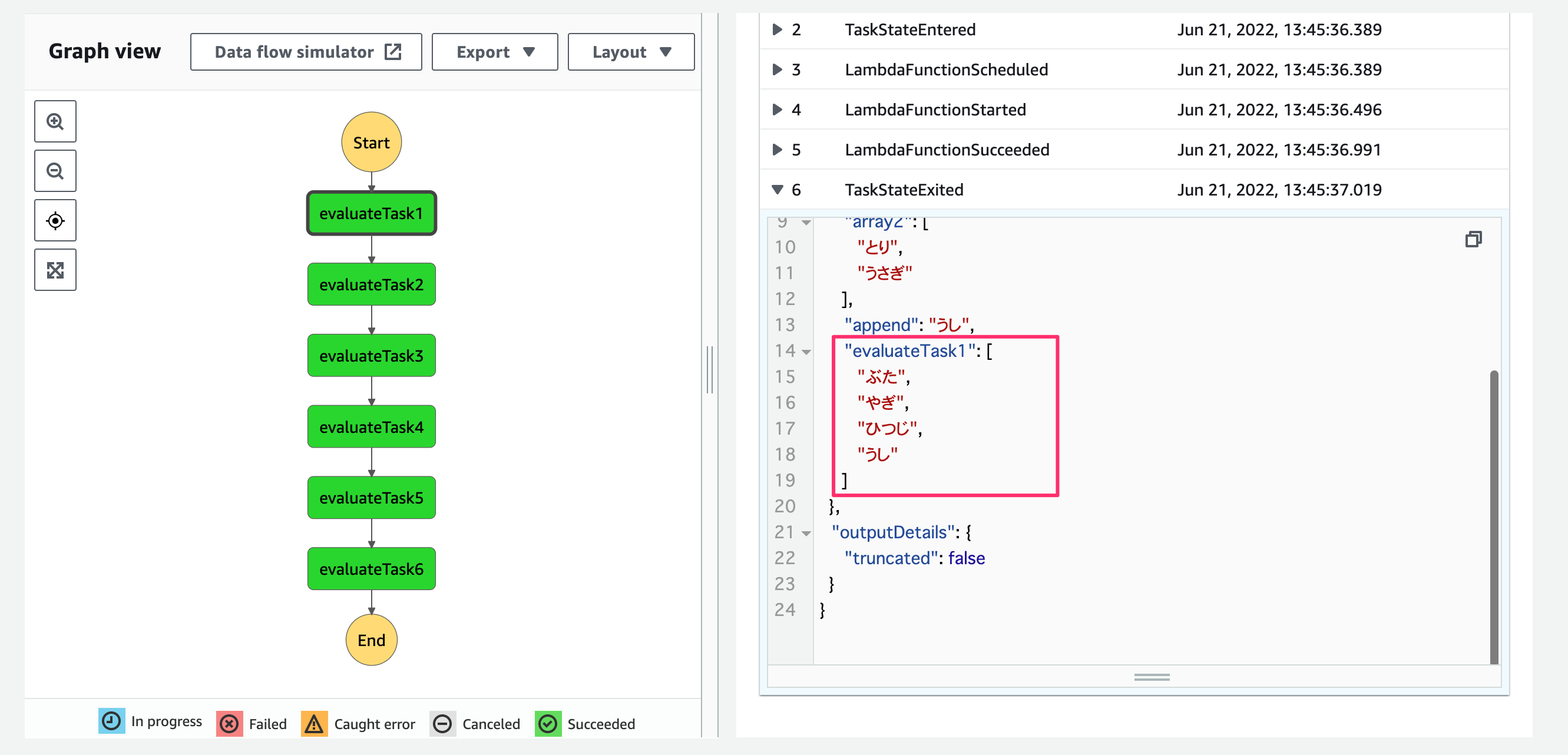
{}.concat("{}")により配列の結合ができています!
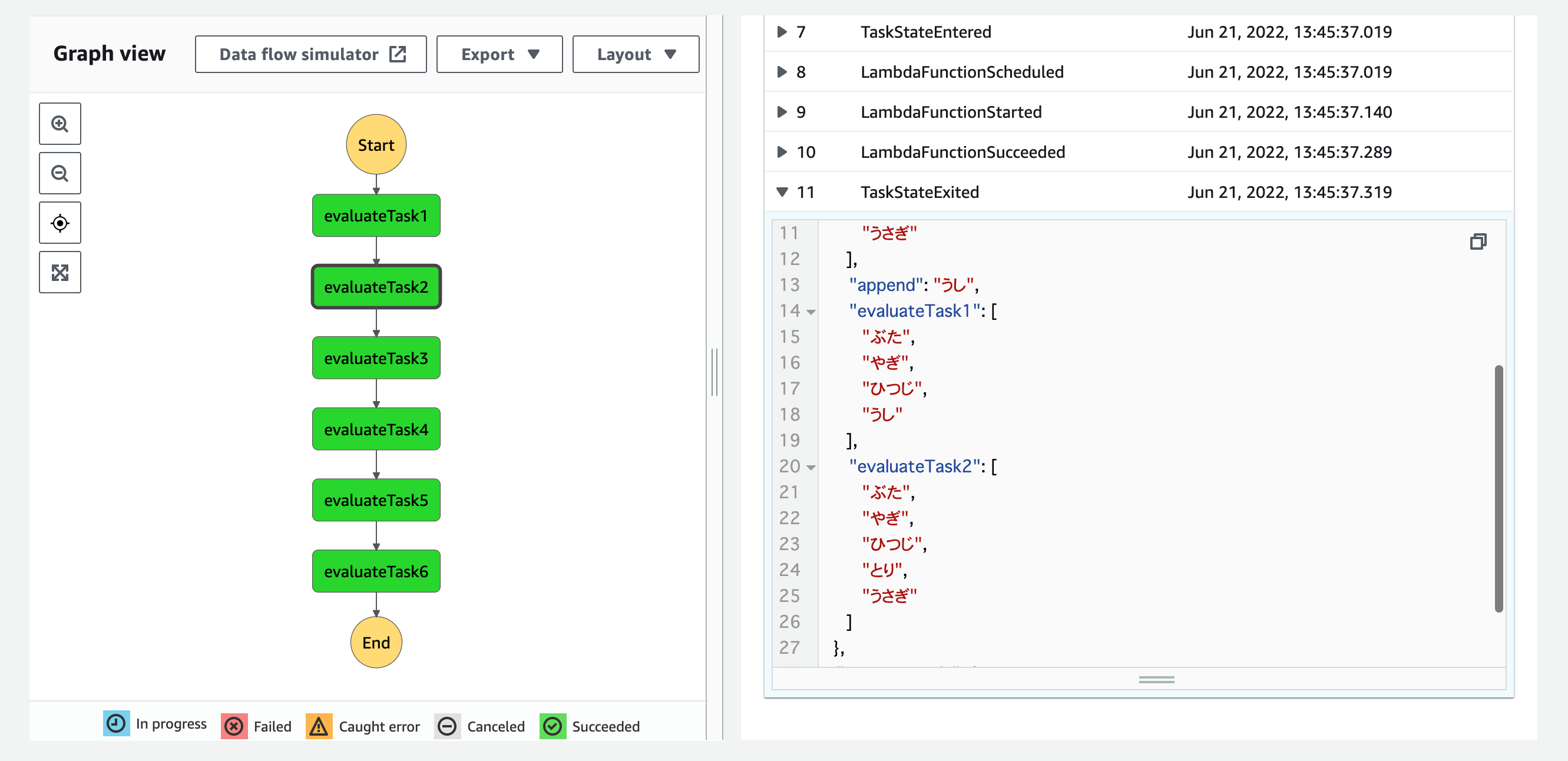
{}.map( d => "new" + d )により配列のMap処理ができています!
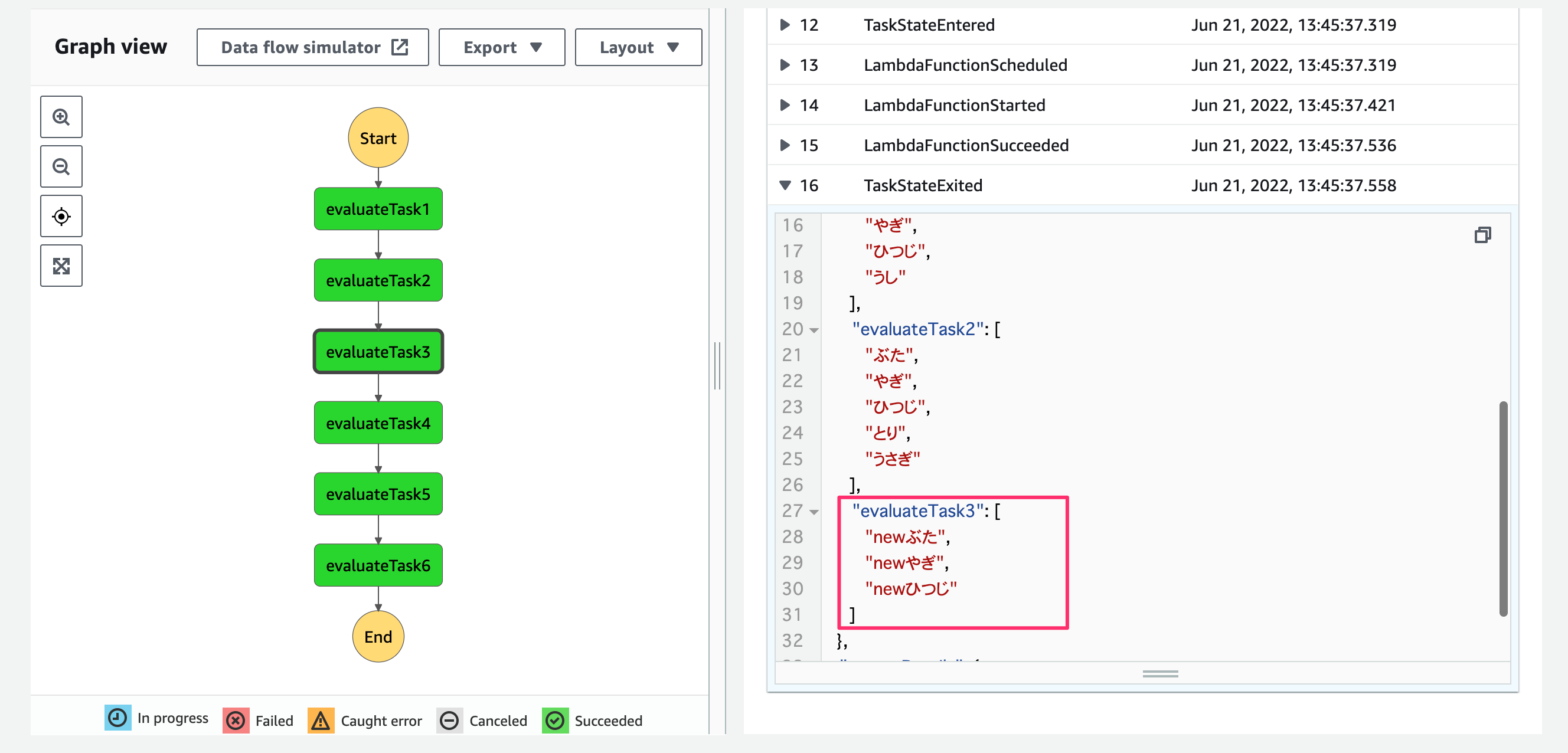
{}.lengthにより配列長の取得ができています!
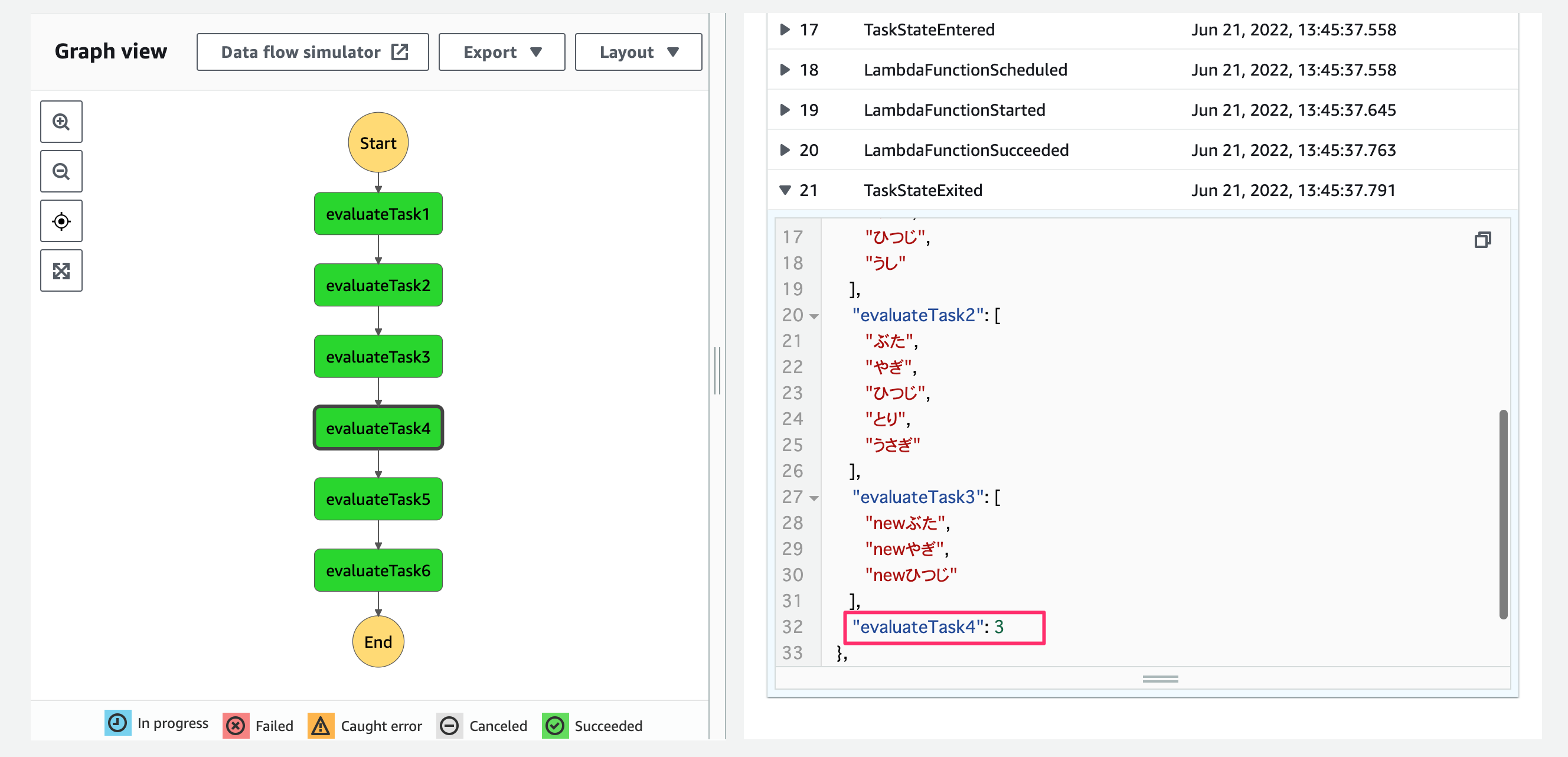
Math.max(1, 3, 2)により最大値の取得ができています!
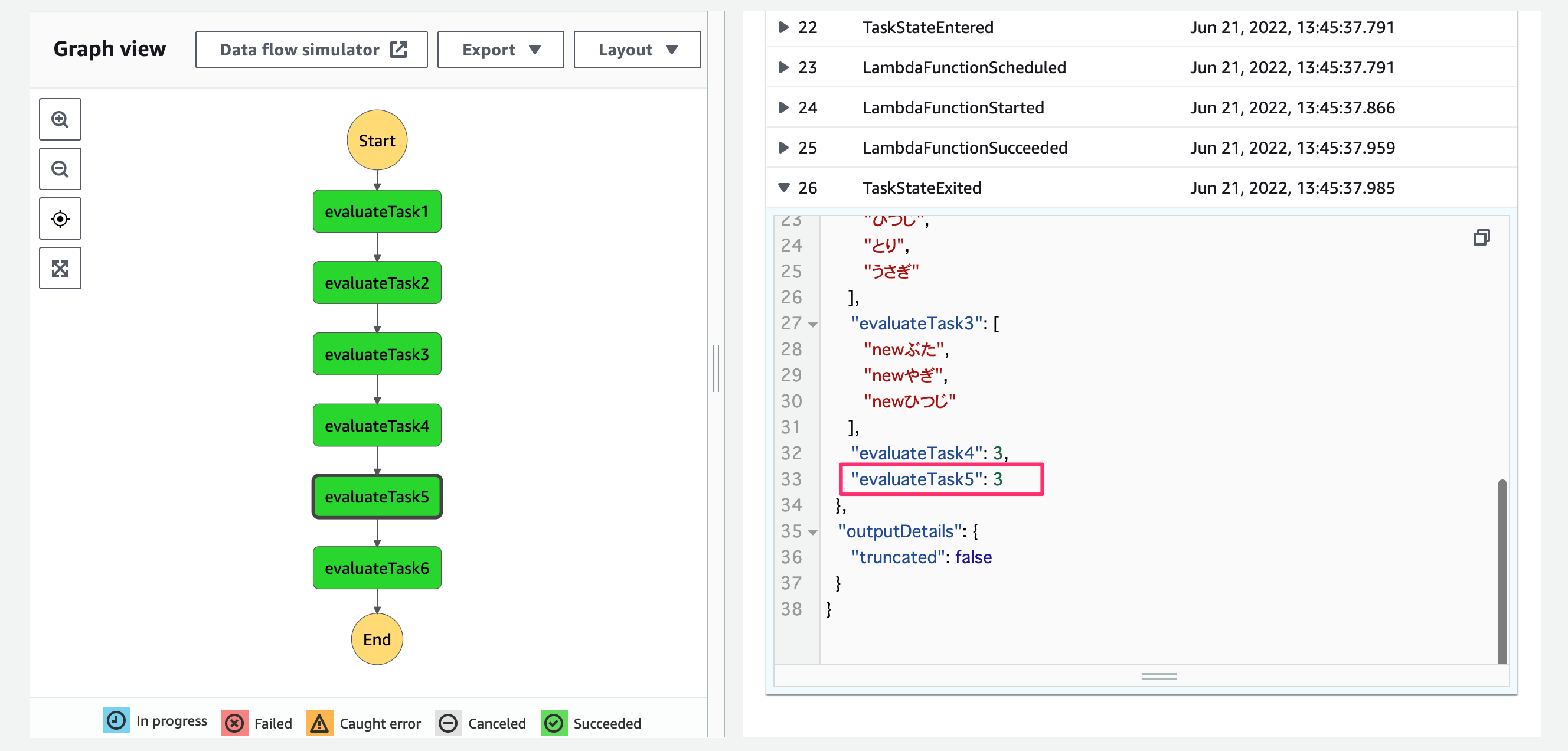
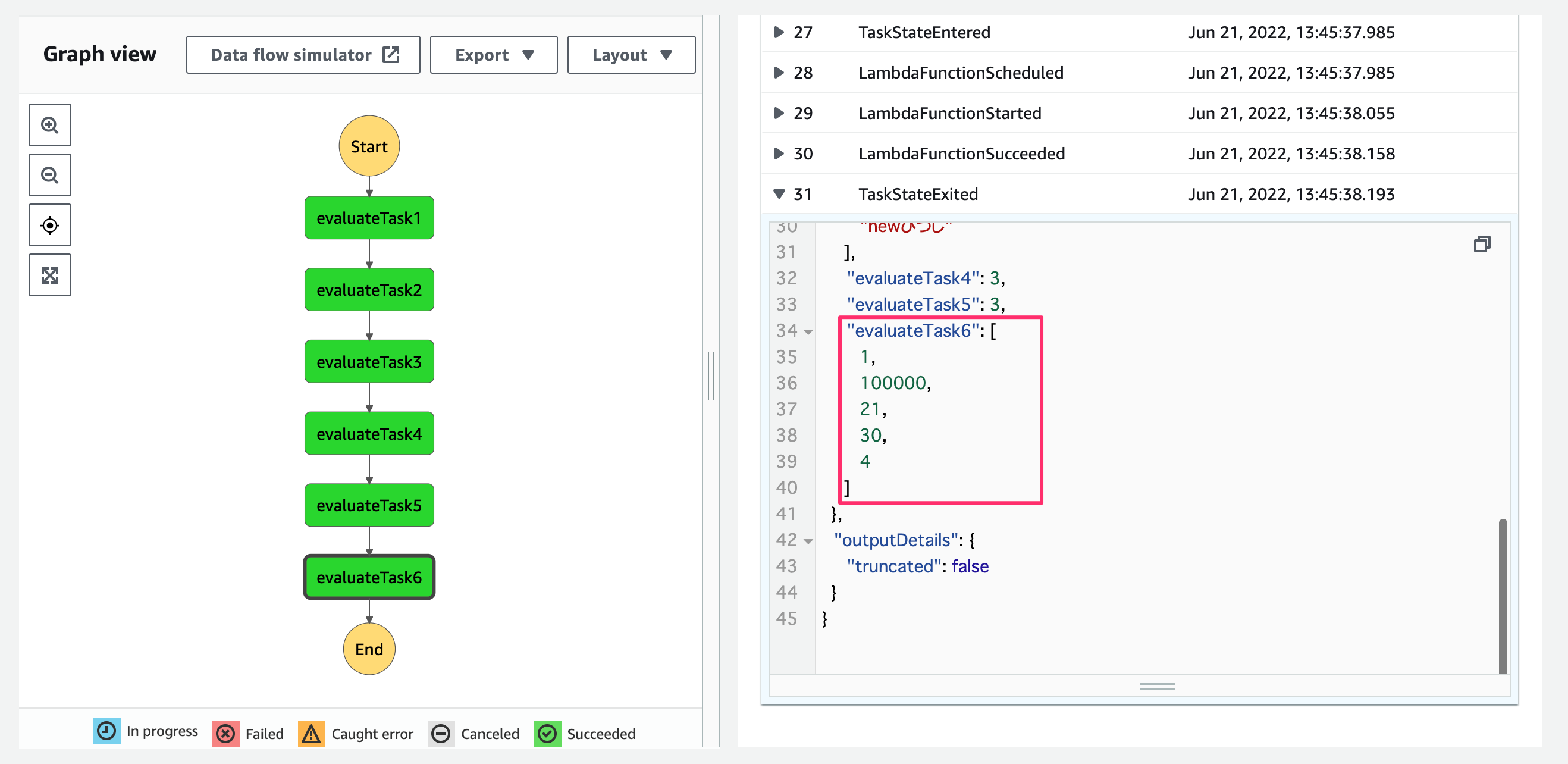
[1, 30, 4, 21, 100000].sort()により要素の並び替えができています!
おわりに
EvaluateExpressionタスクを使って配列の操作(要素追加、結合、Map処理など)をしてみました。
以前に下記のエントリを書いたのですが、今回のEvaluateExpressionを使えば簡潔な記述で無駄なテーブルリソースの作成やテーブルアクセスを行わずに同じことを実装できます。便利ですね。
以上











