
【セッションレポート】サービス停止を防ぐ AWS 活用術:高可用性設計の実践と課題(AWS-38)#AWSSummit
はじめに
皆様こんにちは、あかいけです。
AWS Summit Japan 2025 の二日目で行われた、
「サービス停止を防ぐ AWS 活用術: コンテナワークロードにおける高可用性設計の実践」に参加してきました。
本記事ではそのレポートをお届けします。
セッション概要
タイトル :
サービス停止を防ぐ AWS 活用術: コンテナワークロードにおける高可用性設計の実践
概要:
クラウドネイティブ時代において、マイクロサービスアーキテクチャやコンテナ技術の採用により、システムの可用性要件はより複雑化・高度化しています。本セッションでは、マイクロサービスのような分散システムで起こる障害を前提に、可用性を確保するための実践的なアーキテクチャ設計を解説します。
耐障害性や障害分離の考え方に沿いながら、基礎からゾーン独立性のような発展的なパターンまで考慮事項を踏まえながら取り扱います。
具体的な障害シナリオに対してアーキテクチャがどのように機能するのかを確認します。
分散システムの信頼性を支える技術リーダーの方々に、実践的な知見をお届けします。
スピーカー :
堀内 保大
セッションレベル :
Level 400: 上級者向け
資料
AWS公式から資料や動画がアップされたら追記します。
レポート内容
本セッションについて
セッションの対象者:
- コンテナワークロードにおいてマイクロサービスを実装している、または実装予定の方
- アーキテクチャの可用性設計改善に取り組みたい技術リーダー
セッションのゴール:
- トレードオフを理解した上で高可用性設計のパターンを習得する
- 実践的なアーキテクチャの可用性設計改善に取り組めるようになる
セッションアジェンダ
- 障害の定義
- 可用性設計の検討ポイント
- 障害シナリオの分析
- まとめ
1. 障害の定義
Everything fails, all the time.

まず、高可用性設計の基本原則として 「すべてのものはいつか必ず壊れる」 という考え方が紹介されました。
これは、障害が発生することを前提として設計を行う重要性を強調しています。
- 障害の発生は避けられない
- 障害が発生する前提でシステムを設計する必要がある
高可用性と災害対策の違い
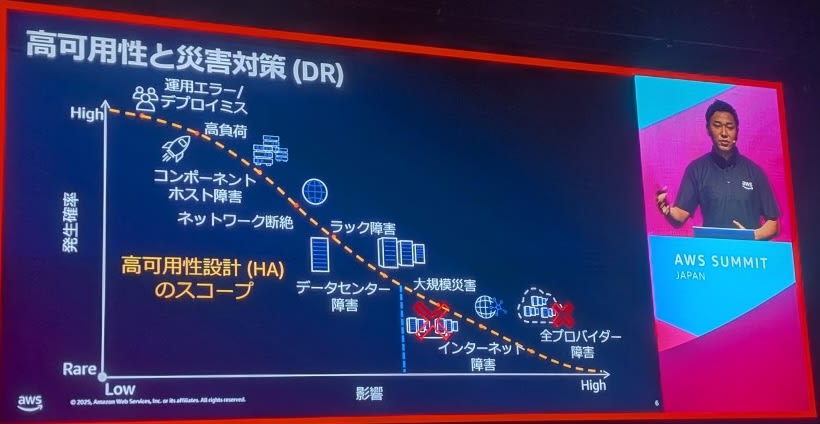
高可用性(High Availability):
- 継続的なサービス提供を目指す
- 障害時の自動復旧や迅速な切り替えが重要
- 短時間でのサービス復旧が目標
災害対策(Disaster Recovery):
- 大規模災害時のデータ保護と復旧が目的
- 長期間のサービス停止を前提としたバックアップ戦略
- データの完全性と復旧可能性が重要
グレー障害について

グレー障害の特徴:
- 部分的な停止を伴う障害
- 観測箇所によって見え方が異なる
- システム側では正常に見えても、顧客側でエラーが発生
- システムレベルでのヘルスチェックが困難
- 外形監視によるSLO(Service Level Objective)の劣化監視が重要
対策:
- 多角的な監視の実装
- ユーザー体験に基づいた監視指標の設定
- 外形監視による実際のサービス品質の測定
2. 可用性設計の検討ポイント
可用性目標とトレードオフ
復旧速度の重要性:
- 障害発生時にいかに早く復旧できるかが最重要課題
- 完全な障害回避よりも、迅速な復旧を優先する設計思想
可用性実現のトレードオフ:
- コスト:冗長化によるインフラ費用の増加
- 工数:設計・実装・運用の複雑化
- 複雑性:システム全体の理解と保守の困難化
重要な考え方:
- 可用性が高ければ良いわけではない
- 目標とシステムの特性に合った適切な設計が重要
- ビジネス要件に見合った可用性レベルの設定
高可用性に向けた設計検討ポイント
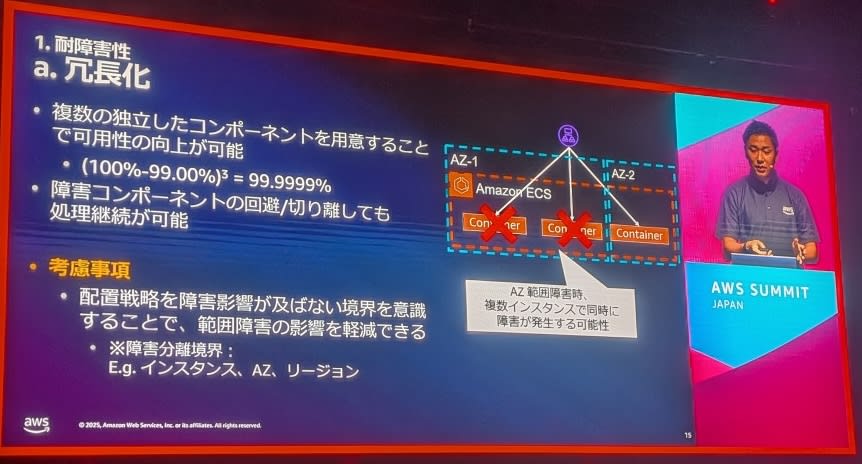
1.冗長化
基本原則:
- 複数のコンポーネントでの冗長化
- 配置戦略が重要:障害影響が及ばない範囲を意識
- Single Point of Failure(SPOF)の排除
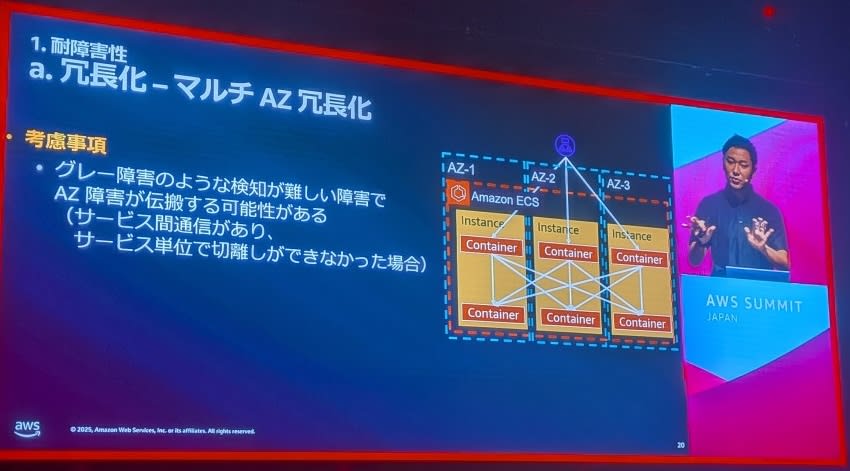
2.マルチAZ冗長化
目的:
- AZ(Availability Zone)範囲障害の回避
- 地理的分散による障害影響の局所化
コンテナレベルの冗長化:
ECS(Elastic Container Service):
- タスク再配置戦略の設定
- 複数AZへの分散配置
- Auto Scalingとの連携
EKS(Elastic Kubernetes Service):
- Pod Topology Spread Constraintsの活用
- Node Affinityとの組み合わせ
- Cluster Autoscalerとの連携
インスタンスレベルの冗長化:
- ECS Auto Scaling:動的なキャパシティ調整
- EKS Auto Mode:自動化されたノード管理

考慮事項:
- グレー障害では検知が困難
- AZ障害が他のAZに伝播する可能性
- 障害分離によるリスク軽減が必要
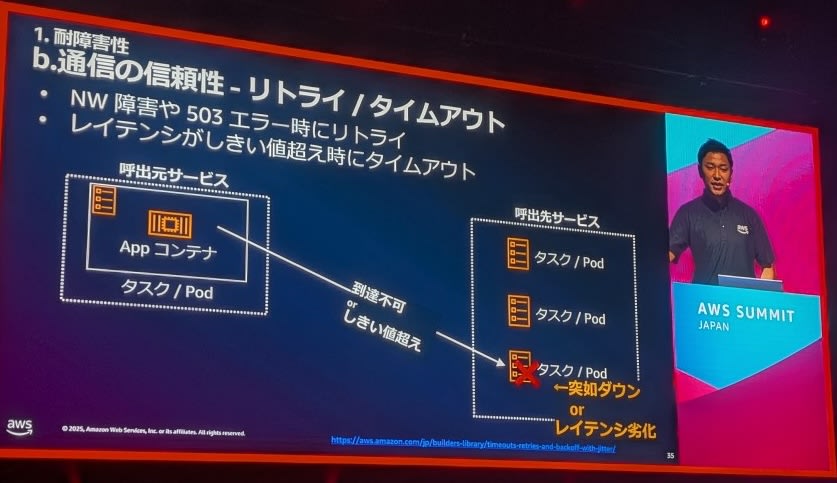
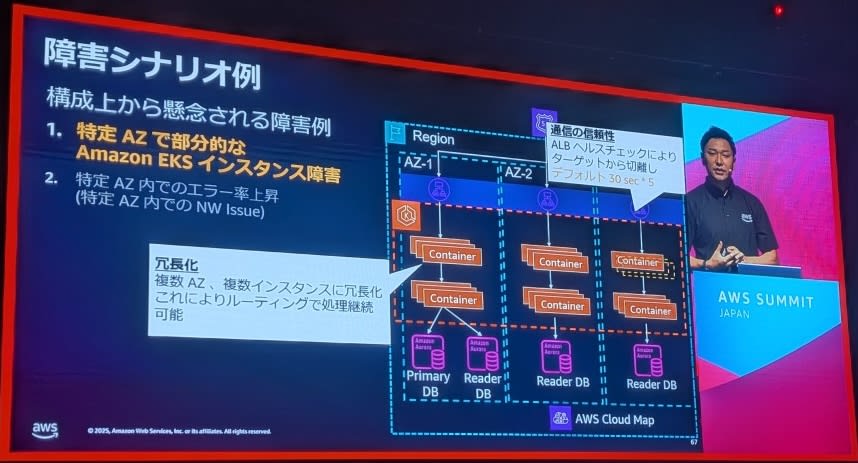
3.通信の信頼性

1. コンテナヘルスチェック:
- アプリケーションレベルでの生存確認
- Liveness Probe、Readiness Probeの設定
- ヘルスチェック間隔と閾値の調整
2. Service Discoveryヘルスチェック:
- サービス間通信での健全性確認
- 動的なエンドポイント管理
- 障害サービスの自動除外
3. ロードバランサーヘルスチェック:
- 外部からのアクセス可能性確認
- 複数のヘルスチェック手法の組み合わせ
- 地理的分散環境での一貫性確保

4. サーキットブレイカー

仕組み:
- リクエストエラーが連続した場合の保護機構
- 一時的にルーティング先から障害サービスを除外
- 障害の連鎖拡大を防止
実装方法:
- サービスメッシュ:Istioなどの活用
- ライブラリ:アプリケーションレベルでの実装
- Amazon ECS Service Connect:マネージドサービスメッシュの活用

5.リトライ/タイムアウト戦略
6.障害分離
目的:
- 障害範囲の早期分離
- 復旧速度の向上
- 全体影響の最小化

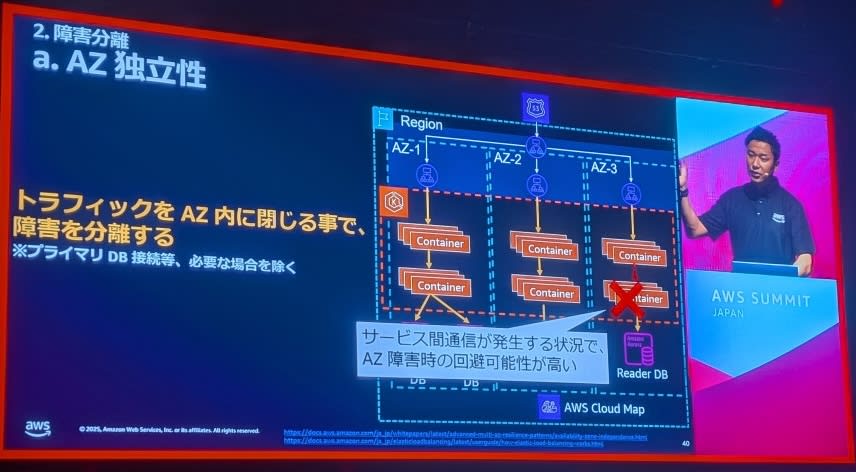
AZ独立性の実現
基本コンセプト:
- 障害分離境界による影響範囲の限定
- トラフィックをAZ内に閉じることによる障害回避
- 各AZの自律的な運用
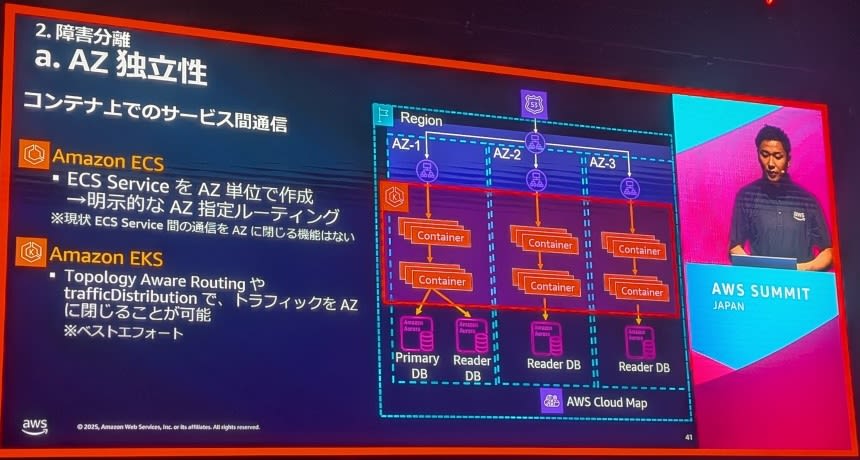
コンテナサービス間通信の設定:
ECS実装:
- ECS ServiceでのAZ指定
- タスク配置制約の活用
- Service Discoveryとの連携
EKS実装:
- Kubernetesの機能でAZ指定
- Node Selector、Node Affinityの活用
- Pod Topology Spread Constraintsの設定
ロードバランサー設定:
- ELBのクロスゾーン負荷分散無効化
- 特定AZへのトラフィック限定
- ゾーン固有のターゲットグループ
データベース接続管理:
- AWS Cloud Mapによる接続点管理
- AZ固有のデータベースエンドポイント
- 読み取り専用レプリカの活用
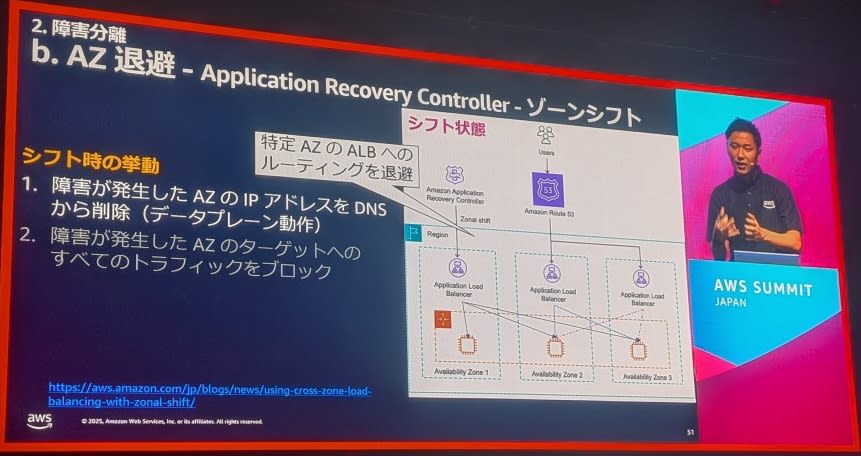
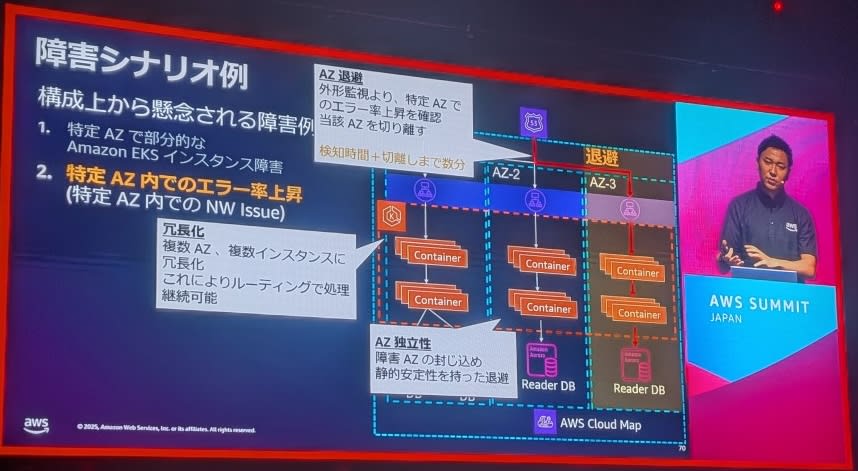
AZ退避戦略
基本方針:
- 静的安全性の確保が重要

静的安全性の原則:
- 新規リソース作成の最小化:障害の拡大を防止
- コントロールプレーン依存の排除:AWSのAPIに依存しない仕組み
ゾーンシフト機能
AWS提供の機能:

ECS対応:
- サービスレベルでのゾーンシフト
- 手動・自動両方の対応
- タスクの再配置制御
EKS対応:
- ノードレベルでのゾーンシフト
- Cluster Autoscalerとの連携
- Pod再配置の自動化
障害検知の方法

1. システムメトリクス:
- CPU、メモリ、ネットワーク使用率
- レスポンス時間、エラー率
- リクエスト処理量
2. 外形監視:
- 実際のユーザー体験の監視
- 複数地点からの監視
- SLO/SLIに基づく評価
3. AWSマネージドサービス:
- Service Health Dashboard:AWS側の障害情報
- オートシフトオブザーバー通知:自動化された障害検知
設計時の考慮事項
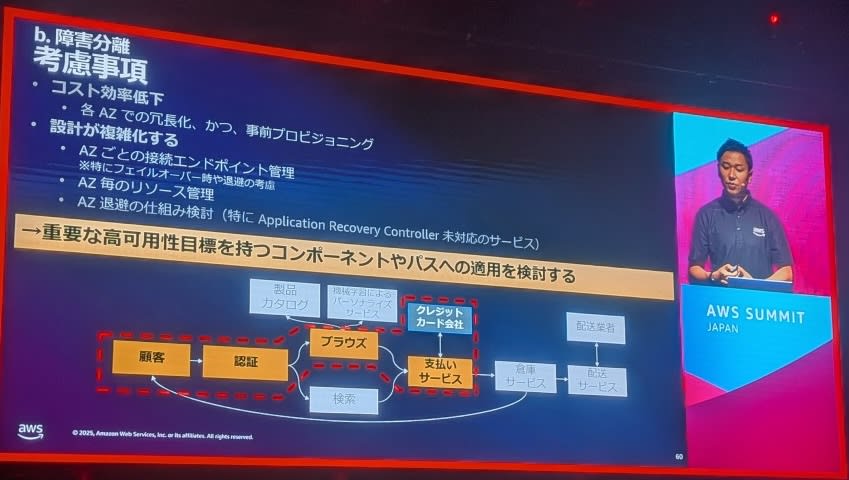
トレードオフの理解:
- コスト効率の低下:冗長化に伴うインフラ費用増加
- 設計の複雑化:運用・保守の難易度上昇
- クリティカルパスの識別:重要度に応じた選択的適用
3. 障害シナリオ分析
想定障害シナリオ

シナリオ1:特定AZ上での部分的なEKSインスタンス障害
- 一部のワーカーノードが応答しない状態
- ALBによる健全なターゲットへのルーティング
- 自動復旧機能との連携
シナリオ2:特定AZ内でのエラー率増加
- グレー障害の典型例
- 外形監視による早期検知
- 段階的な対応策の実施
障害シナリオ例
復旧戦略
4. まとめ

核心となる設計原則
1. 障害前提の設計:
- 障害は必ず発生するという前提でシステムを構築
- 完全な障害回避よりも迅速な復旧を重視
2. 高可用性に向けた設計要素:
耐障害性(Fault Tolerance):
- 冗長化:Single Point of Failureの排除
- 通信の信頼性:多層的なヘルスチェック機構
障害分離(Fault Isolation):
- AZ独立性:障害の影響範囲を限定
- AZ退避:迅速な障害回復戦略
3. 実践的なアプローチ:
- 障害シナリオと復旧目標の明確化
- ビジネス要件に応じた設計パターンの選択
- 継続的な改善とモニタリング
さいごに
本セッションを通じて、コンテナワークロードでの高可用性設計について、より深く実践的な理解を得ることができました。
- 主な学び
- 障害は避けられないものとして受け入れ、それを前提とした設計の重要性
- 単純な冗長化だけでなく、障害分離やAZ独立性といった高度な設計パターンの価値
- トレードオフを理解した上での適切な設計選択の重要性
特に、AZ独立性の実現やゾーンシフト機能の活用など、実践的な手法について具体的な実装方法を学べたことは大きな収穫でした。
これらの知見を活かして、より信頼性の高いシステムの設計に取り組んでいきたいと思います。









