![[セッションレポート]生成 AI オブザーバビリティのベストプラクティス #AWSSummit](https://images.ctfassets.net/ct0aopd36mqt/6mDy5OHyuWO0BYkCTdEVsb/fb81a40db3365780c00e8d5c8927d5c0/eyecatch_awssummitjapan2025_nomal_1200x630.jpg?w=3840&fm=webp)
[セッションレポート]生成 AI オブザーバビリティのベストプラクティス #AWSSummit
AWSにおける生成AIサービスのオブザーバビリティのベスプラを学びたい
おのやんです。
AWS Summit Japan 2025にて、次のセッションを聴講しましたので、内容をまとめたいと思います。
生成 AI オブザーバビリティのベストプラクティス
生成 AI の採用が進む中、信頼性、透明性、最適化を確保するための包括的な可観測性が重要になっています。このセッションでは、大規模言語モデル、Retrieval Augmented Generation(RAG)アーキテクチャ、その他の新しいアプローチを含む、さまざまな生成 AI パターンの可観測性の課題について学びます。Amazon CloudWatch を幅広いメトリクス、ログ、分散トレーシングと共に使用して、生成 AI ワークロードのライフサイクルの可視性を獲得する方法を発見します。さらに、生成 AI アプリケーションを構築するための強力なフレームワークである LangChain の役割と、Amazon Bedrock や Amazon SageMaker と組み合わせて開発およびデプロイメントパイプライン全体の可観測性を向上させる方法についても探ります。

内容
今回のセッションでは、AWSの生成AIサービスのオブザーバビリティを考える上で、Amazon CloudWatch(以下、CloudWatch)の利用をメインで考えていきます。

ここ数年で、生成AIの活用が爆発的に普及し、さまざまな組織で生成AIを利用した取り組みが行われていますが、その4分の3は本番移行がうまくいかず立ち往生しているそうです。回答が一定ではありませんし、ハルシネーションなどを起こすので回答正確ではない場合があります。
生成AIアプリケーションでは、レイテンシーも問題になります。歴史の中では、15秒がコンピュータ応答時間のゴールドスタンダードだった時代もありますが、現代ではマイクロ秒単位でレイテンシーを調整することもあり、生成AIの推論に時間がかかることについて改善の取り組みがなされているようです。
さらに、推論時にはコストもかかるため、上記3つを確実に許容できる範囲に収めることが求められます。
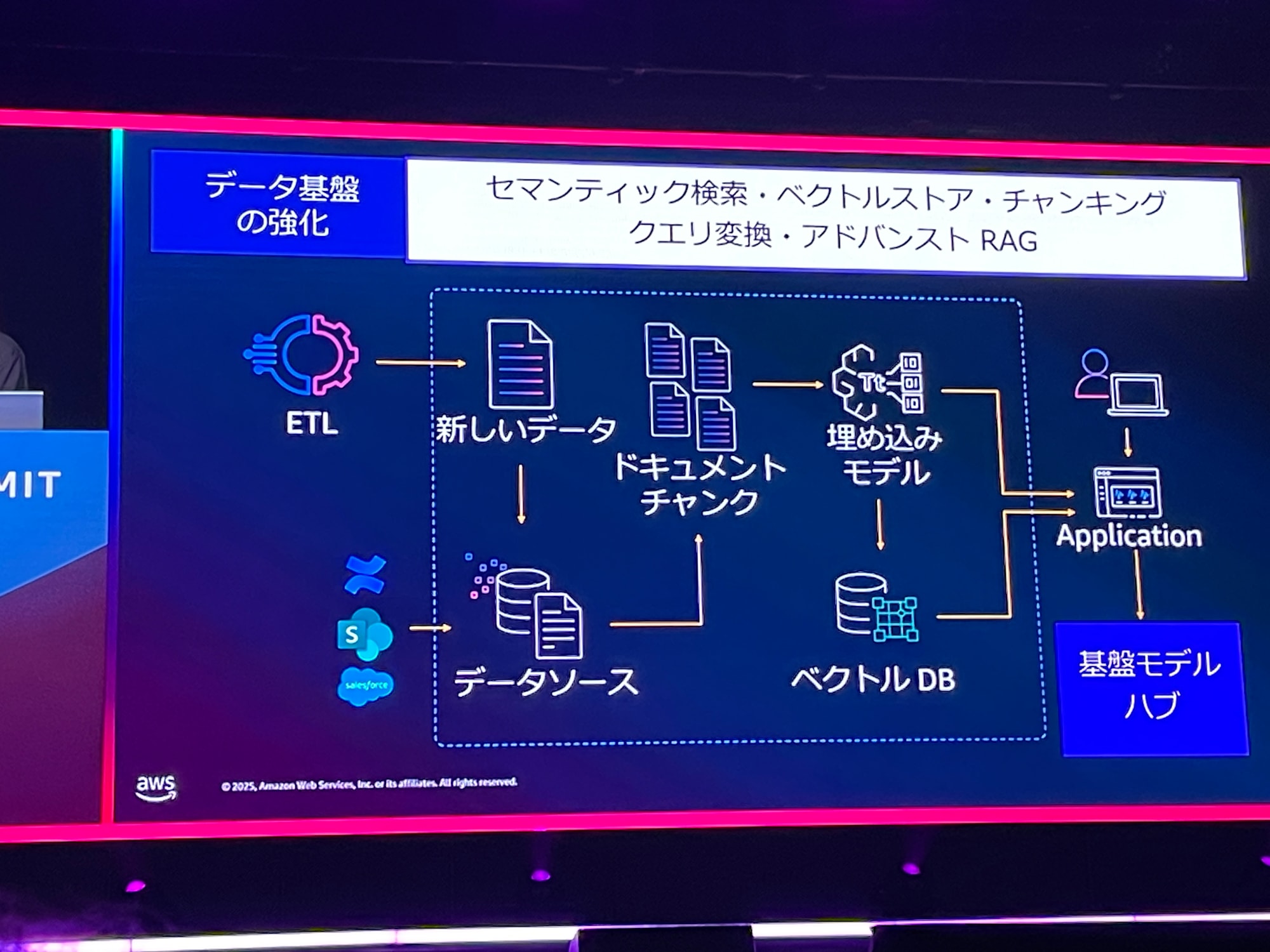
上記3つを改善できるアーキテクチャの例が次の構成図です。例えばSalesforceの既存の文章を読み込ませたり、ETLプロセスで新しいデータを作成する場合もあります。取り込み時はドキュメントをチャンクに分割し、チャンクを検索できるように埋め込みモデルを設定します。このチャンクをベクトルDBへ保存し、インデックス化する、という構成になっています。
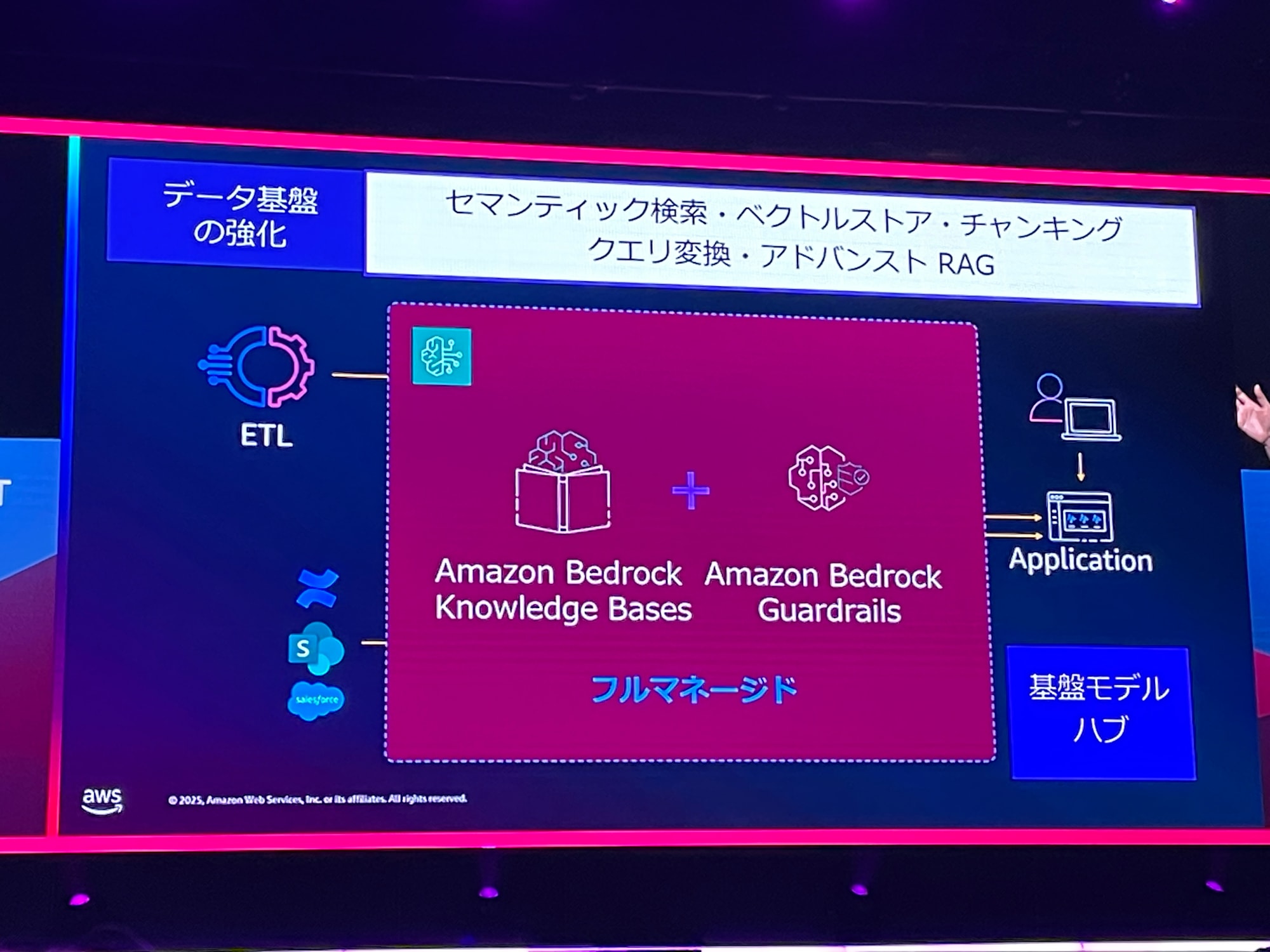
この構成は、AWSプラットフォームを使うことでビジネスユースケースに集中できます。Amazon Bedrock Knowledge BasesやAmazon Bedrock Guardrailsはマネージドですので、楽に管理できます。
では、明日から生成AIアプリケーションを本番運用してねと言われた場合、何から始めるべきでしょうか?このアプローチを、本セッションでは4つのレイヤーに分けて、ステップバイステップで実施するという提案をしています。これらを、CloudWatchで実装する運用管理の負荷なく使っていただけるとのことです。

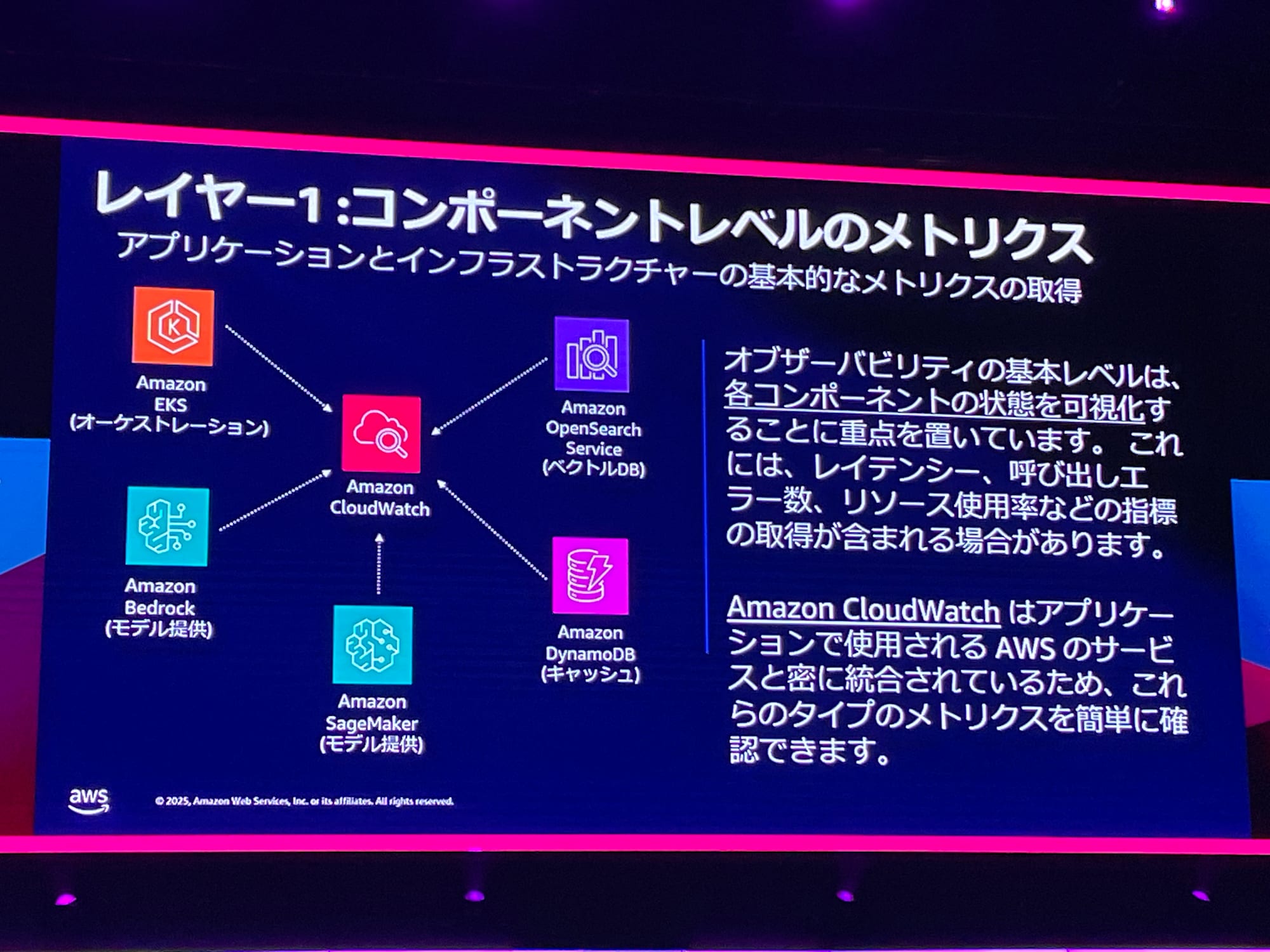
レイヤー1
レイヤー1は、各サービスで取得できるCloudWatchの情報を利用します。AWSサービスは、デフォルトでメトリクスやログを出力できる仕様になっています。
利用しているAWSサービスでどんなメトリクスを取れるかは、Vended metricsのページで確認可能です。

メトリクスにはディメンションという機能もあり、メトリクスの絞り込みで活用できます。例えば、HaikuとSonnetでモデルごとのトークン数を別々に出力してカウントしたいなどの場合に、ディメンションを使って統計情報を詳細化できます。

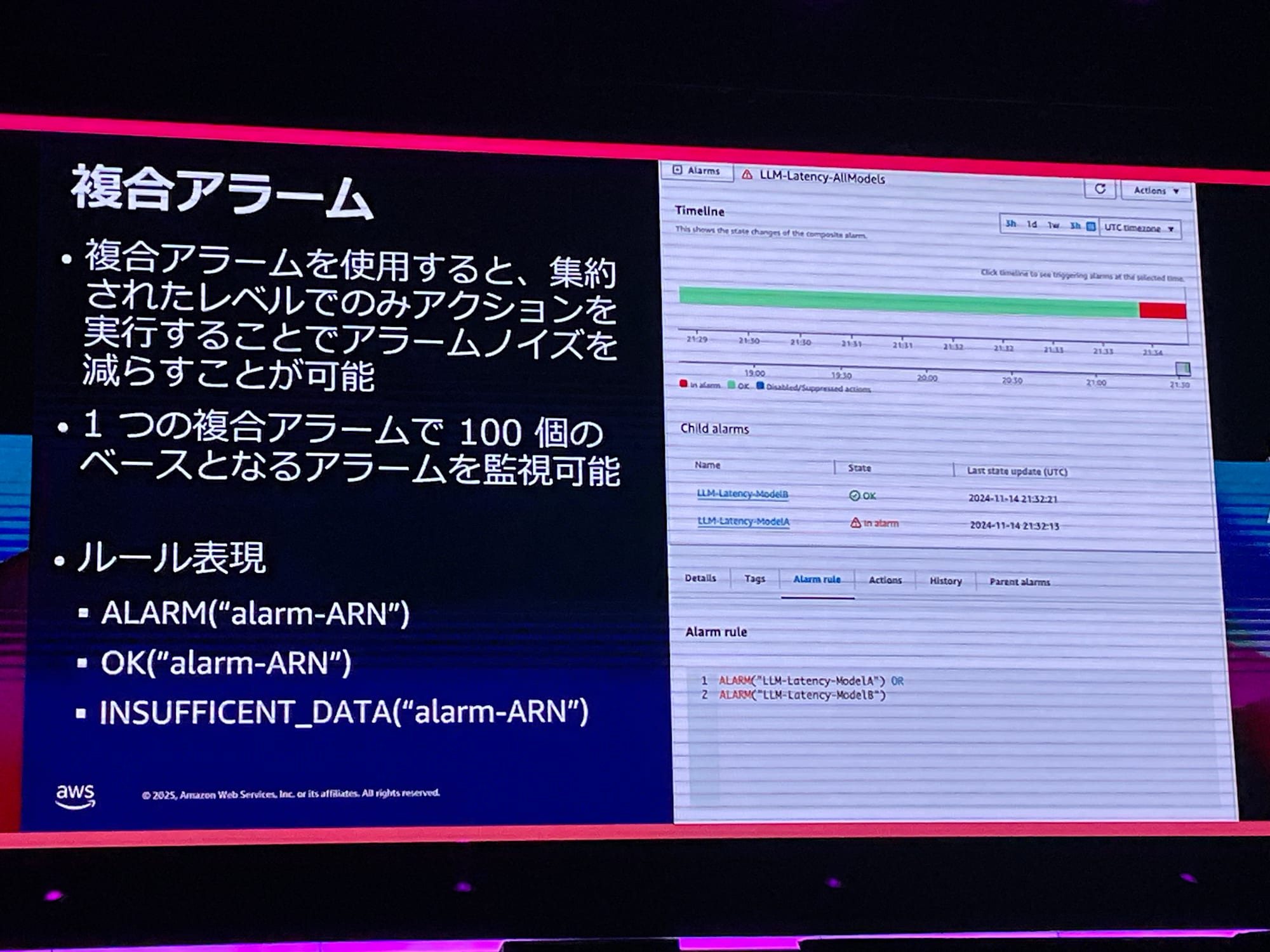
複数のアラームをまとめられる、複合アラーム機能も便利です。大した問題ではないアラームでもアラームの数が多くなると確認が大変なので、ノイズを減らしたいという場合に利用するといいとのことで、アラームAとアラームBが同時になった時に通知する、みたいな設定が可能です。
このあたりのCloudWatchの機能、詳しくは知らなかったので非常に勉強になります。
特定のモデルの呼び出しに時間がかかるなどの場合は、ログを見に行くかと思います。Amazon Bedrock(以下、Bedrock)ではワンクリックでログの出力を有効化でき、Bedrock4つのAPI全てが記録されます。

ログパターン分析では、裏側で機械学習が動いていて、呼び出しログを集計してどんなログ形式が多いかを分析可能です。

レイヤー2
生成AIサービスが複数になってくると、サービス全体をまとめた可視化も重要になっていきます。ここではトレースという概念を提案しているのですが、生成AIでいうトレースとはワークフローの入出力・トークン集などの出力情報をイメージしています。オブザーバビリティの3本の柱のトレースは、マイクロサービス間のマッピングやデータの流れを可視化することなので、すこし文脈が違います。
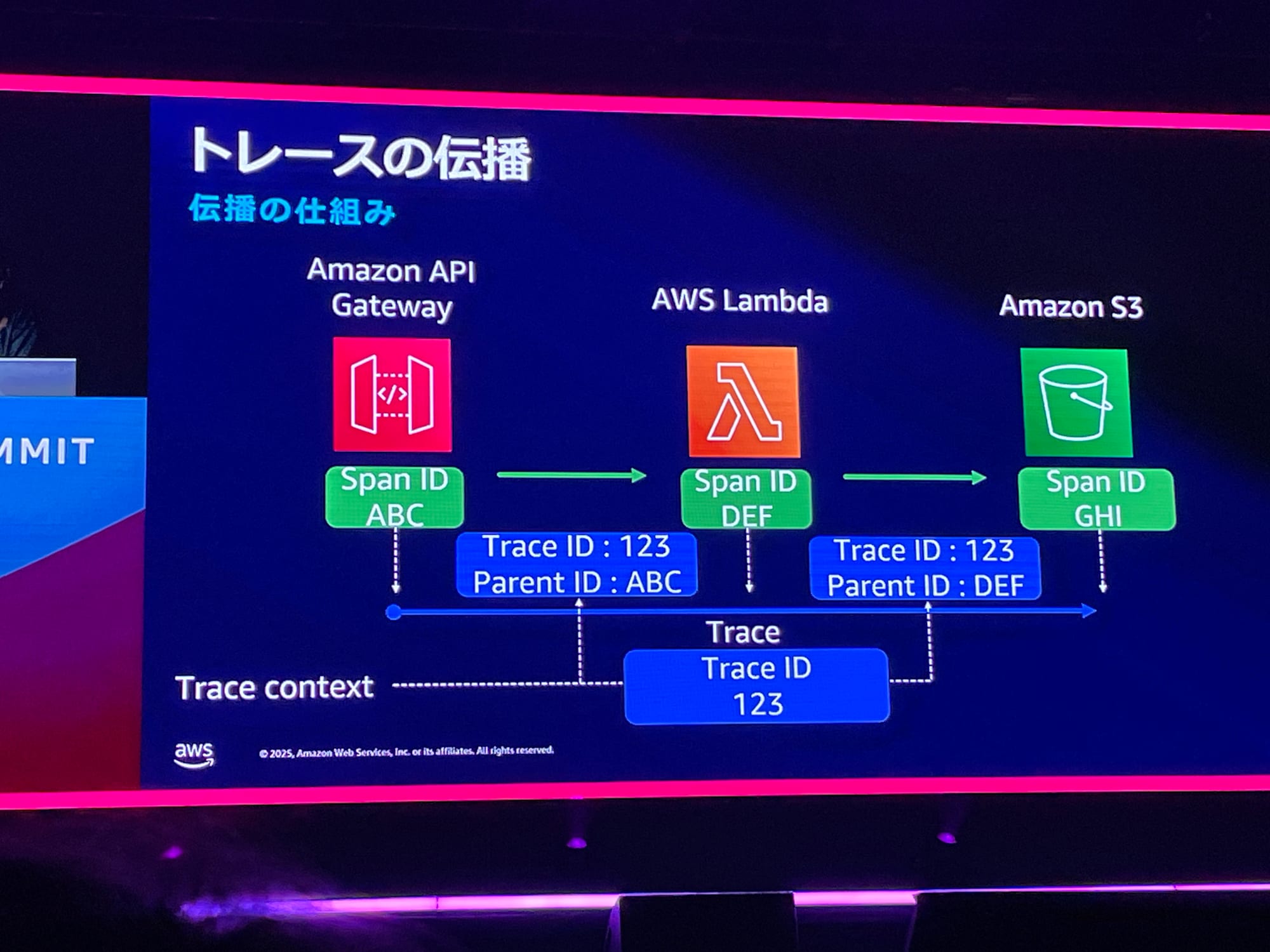
マイクロサービスでは、Spanどうしののコンテキストの欠落が発生するため、システムの全体感把握に苦労します。これは、OpenTelemetryやLangfuseで可能です。
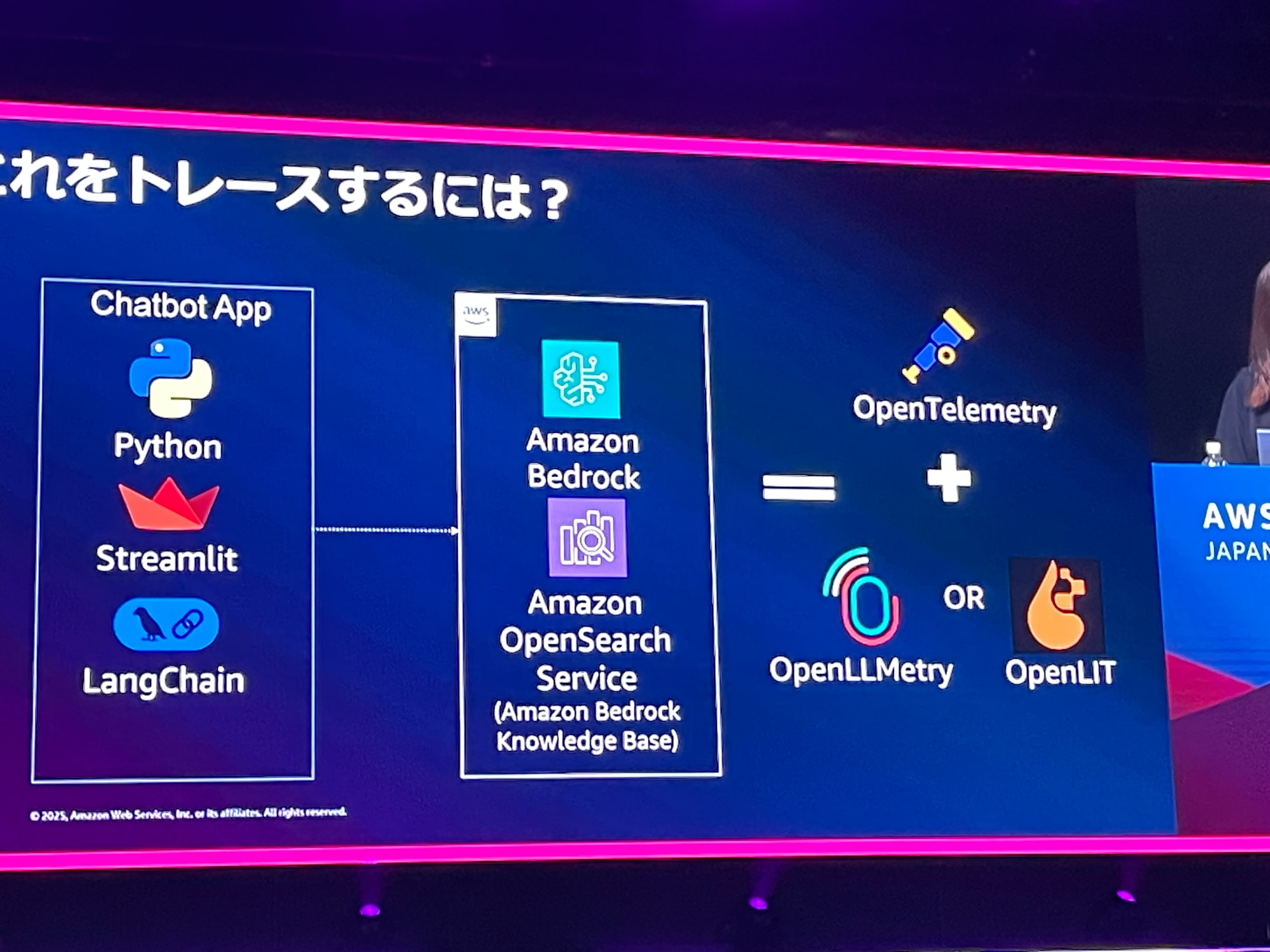
例えば、RAGにない情報を問い合わせると「回答ができません」などと出力されます。こういう時には、3秒以上かかったトレースを調べ、BedrockとAgentへの応答時間も見ることができます。
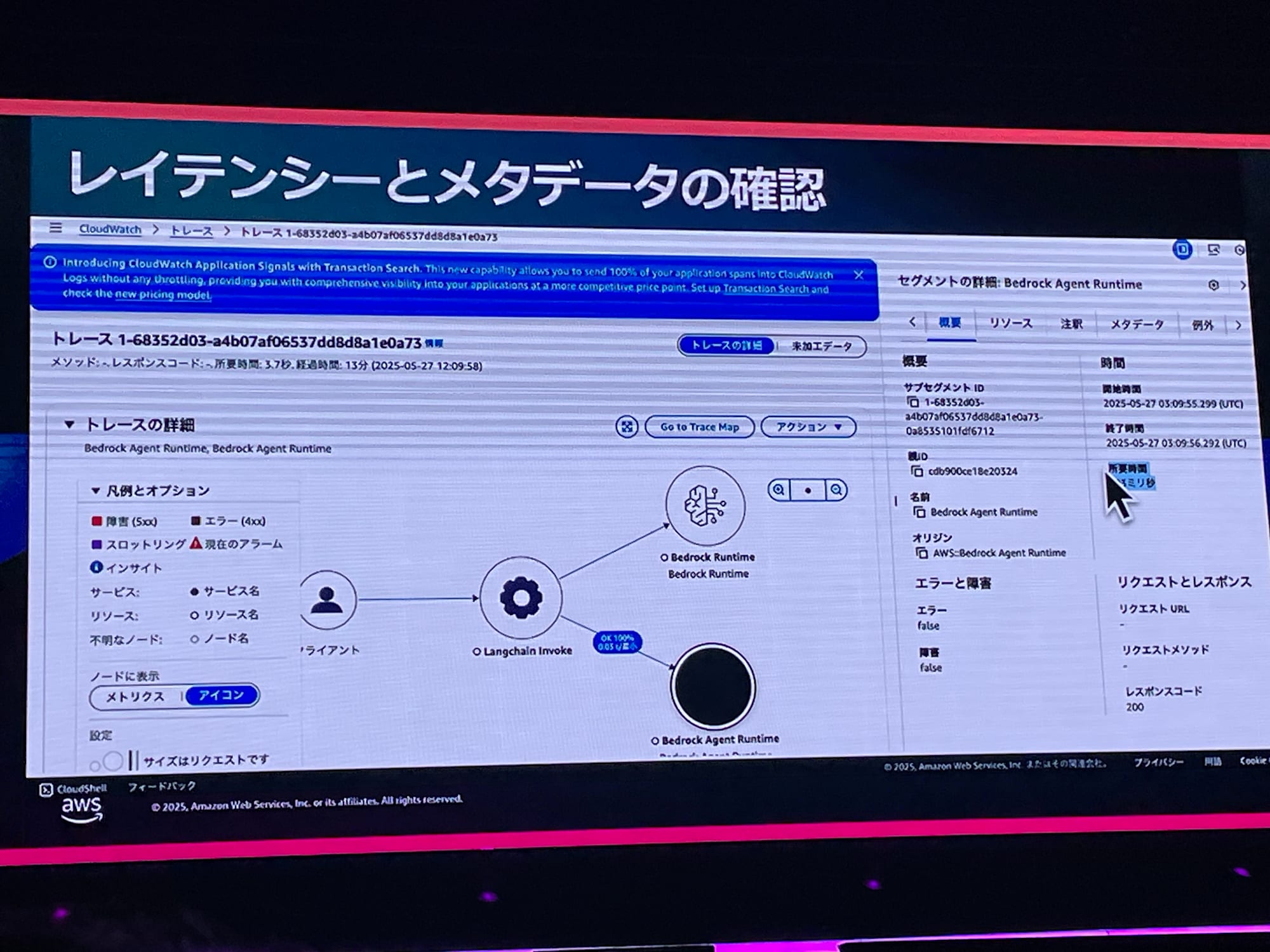
レイヤー3
レイヤー3では、Bedrock Guardrailsで得られるメトリクスを利用し、ディメンションで区分けして確認できます。デモでは、RAGとしてアメリカの税金控除の資料を食わせていました。ここでBedrock Guardrailsを有効化すると、脱税の方法を調べてみてもBlockされます。

レイヤー4
レイヤー4では、ユーザーからの評価を感情値として0と1で数値化するなどして、CloudWatch Embeded Metrics Formatを活用します。
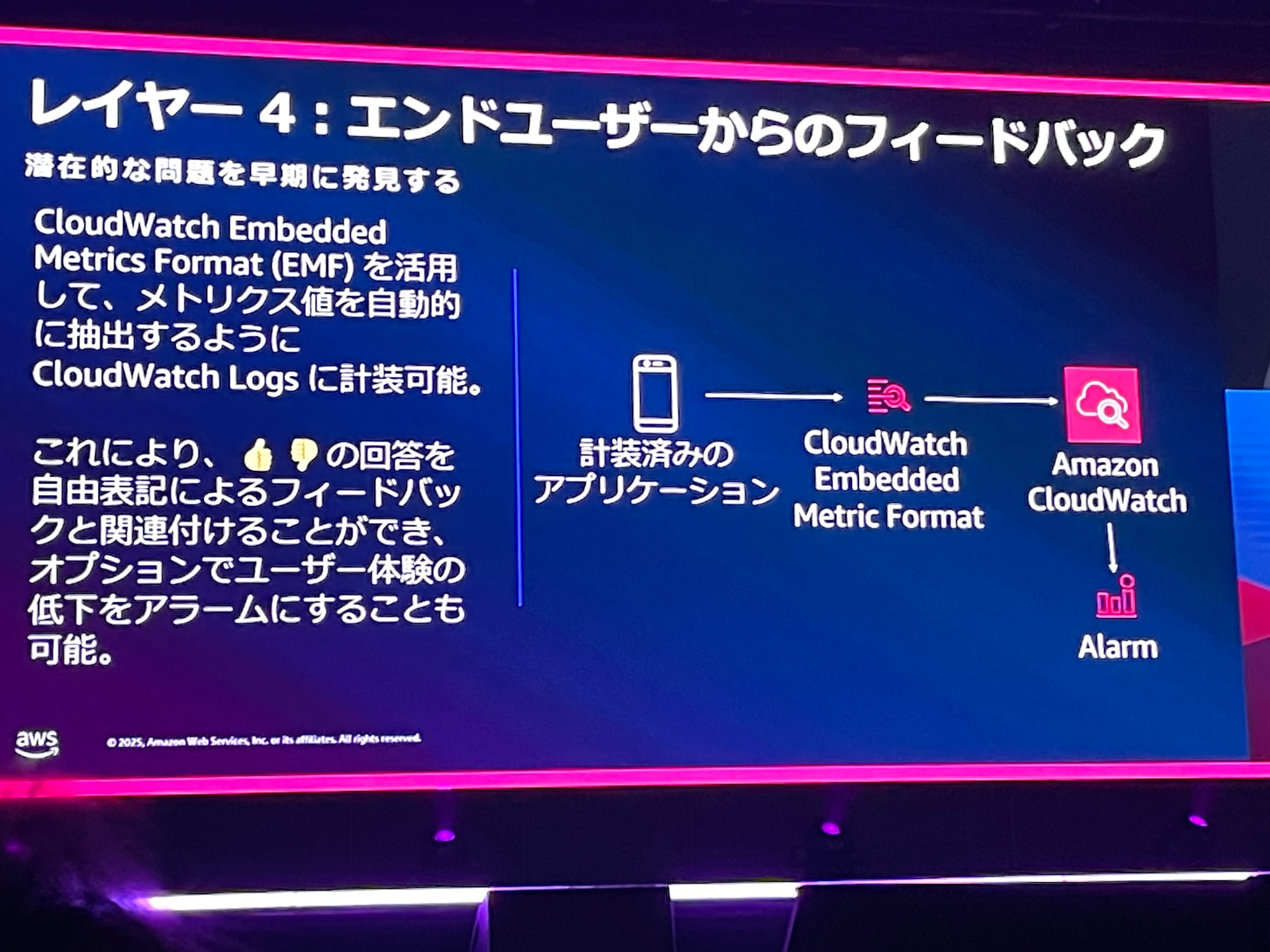
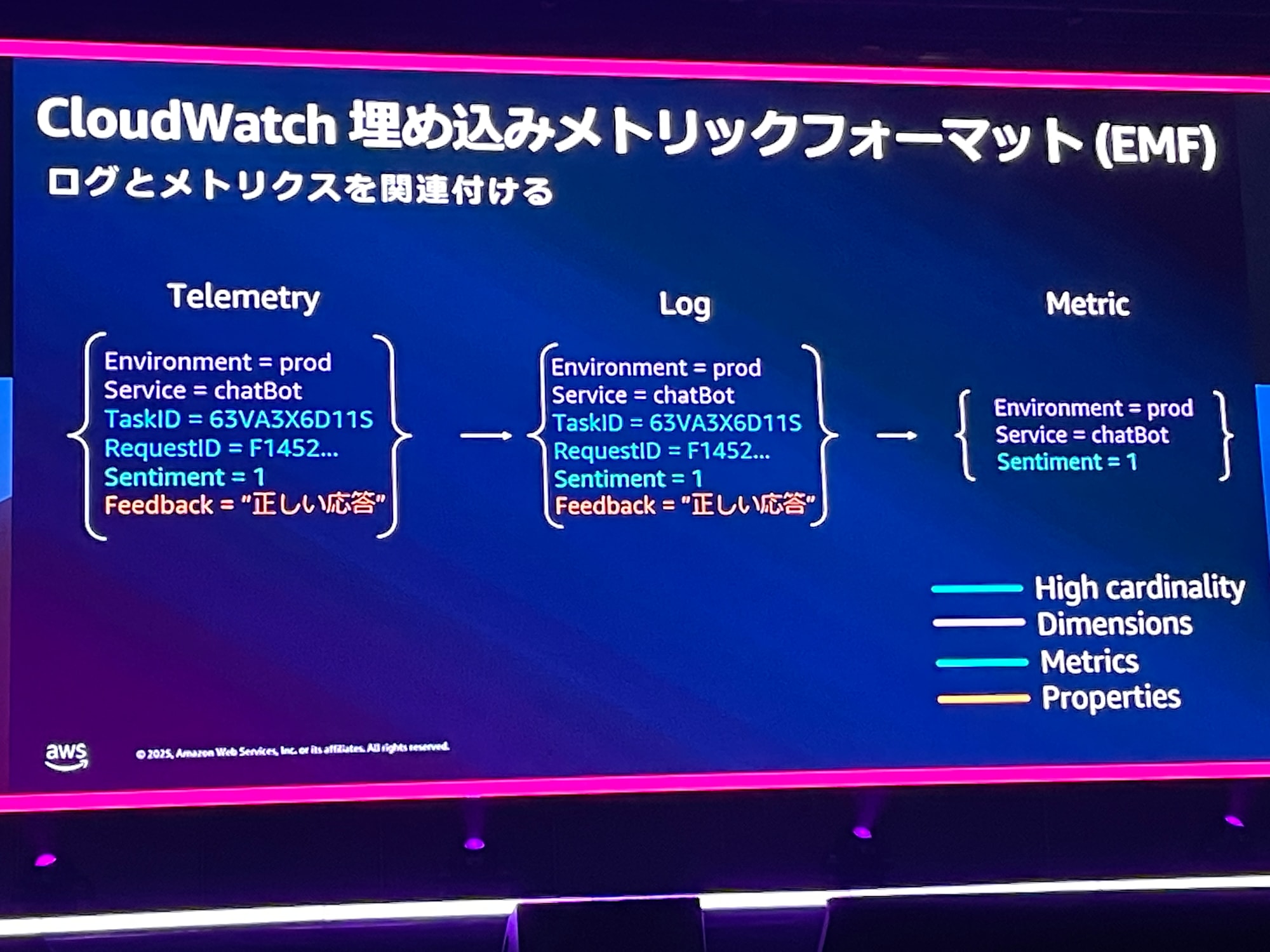
ここでは、ログの構造に基づいて、どの項目をメトリクスにするか設定して、メトリクスとログの相関関係を新しく作成できたりします。
まとめ
これらの4つのステータスを段階的に踏むことで、生成AIアプリケーションのオブザーバビリティを高めることができます。恋Jん敵には、AWSサービス間のトレースの話や、CloudWatchの少しマイナー(?)な機能は、生成AIの文脈以外でも活用できそうで、非常に勉強になりました!












